
基于用户群体兴趣变化的个性化推荐算法研究
2022-03-30 02:54徐健雄何先波何清玉
西华师范大学学报(自然科学版) 2022年1期
徐健雄,何先波,何清玉
(西华师范大学 a.计算机学院,b.地理科学学院,四川 南充 637009)
推荐系统自诞生起就受到了学术界和工业界的广泛关注。对于购物网站和视频网站而言,推荐系统能否根据用户的喜好进行个性化推荐,会在很大程度上影响公司的收益。早在2003年,亚马逊购物网站应用Lindan等设计的基于物品的协同过滤算法,将其销售额提升了30%。因此,捕捉用户喜好对于推荐系统而言至关重要。
早期,基于用户的协同过滤算法[1]和基于物品的协同过滤算法[2]应用较广泛,它们能很好地利用用户和物品间的联系实现推荐,但这些算法的构建不够灵活。而后基于矩阵分解的推荐算法[3]可使推荐系统的构造变得更加灵活便捷,但却难以解决数据稀疏性问题,且不够个性化。为了解决上述问题,基于马尔科夫链的推荐算法[4-5]被提出,该算法能一定程度捕捉用户的兴趣变化。但利用马尔科夫链为每一用户随着时间构建转移矩阵,会使工作量和成本变得难以负担。深度学习的方法,如Wide & Deep[6],能很好地拟合用户的兴趣特征,并能将更多维的用户特征信息组合起来,但却难以捕捉用户的喜好变化。受益于Attention网络在自然语言处理等领域的出色效果[7],利用Attention网络捕捉用户兴趣偏好的方式被广泛应用于推荐系统中,如DIN[8]、DSIN[9]等,但其开销往往较大。
用户个体的喜好往往是不断变化和难以捕捉的,但用户群体的喜好变化则稳定得多。如男性和女性两个群体,不但可以从过往两个群体的信息中得到其对运动、电影一类话题不同的关注度,还可以根据奥运会、奥斯卡和一些其他的新闻事件预测两个群体接下来一段时间更有可能关注的话题。为此,本文构建了一种基于用户群体兴趣变化的个性化推荐算法,该算法利用马尔科夫链、K均值聚类和多层神经网络的方式来捕捉用户群体的兴趣变化,并据此对用户进行个性化推荐。通过在MovieLens数据集上同多个流行算法的对比试验表明,本文提出的算法在多个评价指标上优于对比算法。
1 相关工作
1.1 个性化推荐算法
非个性化推荐算法往往利用物品的流行度对用户进行推荐,如一些电影网站根据电影的观看量多少给用户推送;而个性化推荐算法,则通过捕捉用户的兴趣偏好进行推荐,用户的兴趣偏好不但包括他的历史行为记录,还和其基本信息等相联系。除了各种协同过滤算法外,越来越多的深度学习算法被用来捕捉用户的兴趣偏好,进行个性化推荐,如DeepFM[10]、NCF[11]等。DeepFM通过构建线性和非线性的两个部分,同时学习用户高阶和低阶的兴趣特征,之后通过多层神经网络将两部分特征组合,联合训练出最后的结果。NCF则通过将用户的历史行为信息分为长期和短期两个部分进行学习,利用矩阵分解和多层神经网络的方式模拟用户两个不同时期的兴趣变化,最后利用多层神经网络将两部分结合在一起,训练出最后的结果。
多层神经网络在上述算法中得到了广泛的应用,本文将利用多层神经网络的方法来捕捉用户的兴趣变化,其优秀的记忆能力和拟合能力,能有效学习用户的兴趣特征,且具有开销小、运行快的优点。
1.2 用户群体喜好和用户喜好的联系
单个用户的喜好和其所在群体的喜好有很大的关联。如对于大学生群体而言,向其推送兼职、考研一类的信息往往能得到回应,而向其推送房产、养老一类的信息则难以得到回复。一些基于聚类的推荐算法一定程度上利用了这种联系,如将用户和物品分为不同类别,通过类别间联系进行推荐的Coculstering[12]算法,但该算法难以捕捉用户群体的兴趣变化。对于用户群体而言,他们的喜好随着时间变化。如对男性群体而言,在世界杯期间,整个群体关注世界杯相关新闻的比重上升;而在世界杯结束后,其他类别的新闻又会重新占据男性群体更多的关注。本文利用聚类的方式将用户划分为不同的群体,并利用马尔科夫链的方式捕捉不同用户群体喜好的变化。
2 基于用户群体兴趣变化的个性化推荐算法
2.1 总体架构
相对于用户的兴趣变化,用户群体的兴趣变化更加容易捕捉和有迹可循。通过捕捉用户群体的兴趣变化,可以更好地对用户进行推荐。为此本文提出了一种基于用户群体兴趣变化的个性化推荐算法。
设U={u1,u2,…,un}为用户集合,I={i1,i2,…,in}为物品集合。首先使用用户的所有基本信息,利用K均值聚类算法将用户划分为k个用户群体,之后划分T个时段,用马尔科夫链的方式得到不同的用户群体在不同时段上对每个物品的点击概率β。之后利用多层神经网络的方法,得到用户对每个物品的点击概率p,让两个点击概率p与β相加,得到用户对每个物品最终的点击概率pfinal,最后按照这个概率的高低排序,取前N个最高点击概率且用户未交互过的物品,作为最终的用户推荐列表。
2.2 用K均值聚类算法划分用户群体
用户群体的划分对于基于用户群体兴趣变化的个性化推荐算法至关重要。简单地按照用户的某一项信息(如性别或年龄)划分用户群体,不但不能很好地利用用户的其他信息,而且划分的结果也过于宽泛。如豆瓣网上的用户对电影的评分和其观影数量就呈现明显的正态分布,如果简单地将所有看电影多的人划分为电影爱好者一个群体,那么,毫无疑问会造成推荐系统性能的缺失。为此,本算法引入K均值聚类算法进行用户群体的划分。该算法适用于事先不知道具体划分多少类别数的问题,且在数据量较大的时候收敛速度快,效果良好,利用用户的所有基本信息,将用户划分为k个用户群体。
(1)
(2)
利用式(1),可以找到第k类用户群体Gk的聚类质心ek,将得到的质心ek带入到式(2)中,可以计算出每一个用户u距不同用户群体质心ek的距离,从而将用户分配到离其最近的用户群体,之后随着每次训练,不断更新这两个公式,可以将每一个用户分配到最适合的用户群体中去。
为了衡量将用户划分为多少个用户群体合适,引入CH(Calinski-Harabaz Index)和轮廓系数(Silhouette Coefficient)来衡量最佳的用户群体数k。
(3)

(4)
式(3)中s(k)代表CH的计算结果,tr代表矩阵的迹,Bk是类别间的协方差矩阵,Wk是类别内部协方差矩阵。CH代表用户与其所在用户群体的分离度与紧密度的比值,其值越大,代表每一个用户群体自身越紧密,用户群体之间差别越明显,聚类效果越好。式(4)中s代表轮廓系数的计算结果,a代表了用户群体内部用户与其他用户的平均距离,b代表用户群体内部用户到最相邻的不同用户间的平均距离。轮廓系数值越大,代表聚类效果越好。通过使用这两个指标,可以衡量得出用户群体最合适的划分数k。如表1所示,对于MovieLens数据集,取CH与轮廓系数皆不为负且最大时的k值为最合适的用户群体划分数,因此取k=8。

表1 MovieLens数据集上,不同k下的CH与轮廓系数值
2.3 马尔科夫链模拟用户群体喜好变化
本算法采用马尔科夫链的方式来模拟这种用户群体的喜好变化。将所有训练集的数据按照时间先后顺序划分为等长的T个时段,为了避免数据过于稀疏和时间划分跨度过大,导致马尔科夫链的学习变的不准确,这里按照月份将训练数据集进行划分,将某些数据量十分少的月份的数据等比例并入其上一个月和下一个月的数据中去。记录每个用户群体Gk对不同物品i在时段T上的交互信息,存在与物品i交互的记做1,未交互的记做0,如图1所示。
对于一个用户群体G,假设其在t1,t2,t3时刻上,对物品i1,i2,i3的点击概率如图2矩阵1所示,从矩阵1中可以得到用户群体G在t1->t2时刻存在(i1,i2,i3)->(i2,i3),在t2->t3时刻存在(i2,i3)->(i1,i2)。则对于用户群体G,上一时刻选了i2下一时刻选择i1的概率为0.5(存在(i2,i3)->(i1,i2)),选择i2的概率为1(存在(i1,i2,i3)->(i2,i3),(i2,i3)->(i1,i2)),选择i3的概率为0.5(存在(i1,i2,i3)->(i2,i3)),从而可以构建如图2的矩阵2。

进一步可以由图2矩阵2得到下一个未知时刻t4时,用户群体G选择i1的可能性为0.25=0.5*0+0.5*0.5(存在(i1,i2)->(i1))。则对于T=n,可以由公式(5)得到用户群体G对下一时刻交互物品i的预测概率β,t代表不同的时段。
(5)
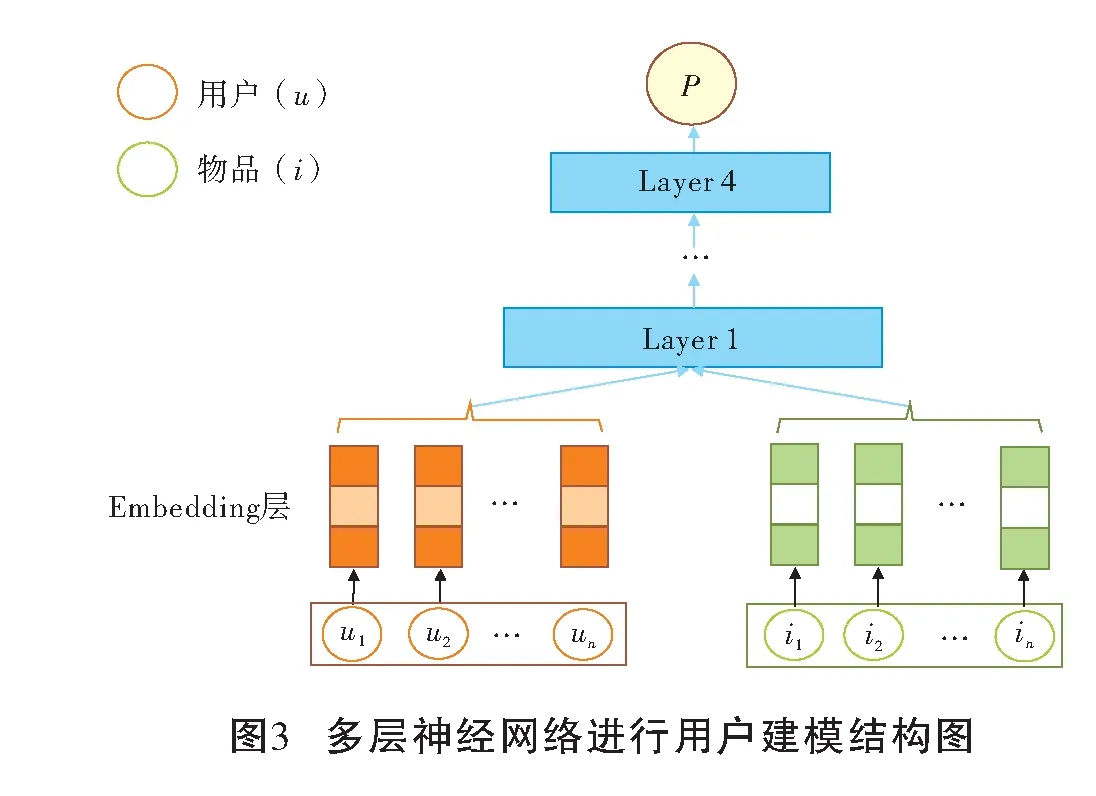
2.4 多层神经网络进行用户建模
本算法利用多层神经网络的方式,进行用户建模,得到用户对所有未交互商品的点击概率。其建模结构如图3所示。将用户特征和物品特征嵌入多维的Embedding层,通过将Embedding层提取的用户特征和物品相互连接,作为多层网络的输入,从而拟合出用户对未交互商品的预测点击概率p。整个结构嵌套四层网络,每一层网络使用relu作为激活函数。
(6)
其中,σ是最后输出层的激活函数softmax,hn代表整个网络的隐藏层状态,w和b为多层神经网络的训练参数。整个网络利用交叉熵损失作为损失函数,如公式(7)所示,逐个带入真实值y和预测值p进行计算,从而可以衡量出每次预测结果的好坏,并由此更新整个网络。
(7)
2.5 构建用户的推荐列表
将通过马尔科夫链方式得到的用户群体对未交互商品的预测点击概率β,与多层神经网络得到的用户对未交互商品的预测点击概率p相加,从而可以得到最终用户对未交互商品的点击概率pfinal。公式为:
pfinal=p+β。
(8)
这种结合方式耗资源少,且能保留更多的信息。通过将用户对所有未交互商品的点击概率pfinal从大到小排列,将最高的前N个取出来,构成对用户的最终推荐列表。
3 实验结果与分析
3.1 数据集
实验数据集为MovieLens-1M数据集。其每一条数据由用户ID,物品ID,用户对物品的评分和评分时间组成。每个用户都至少拥有20条评分数据,评分区间为1~5。共由6040个用户,3952部电影和1 000 209条评分数据构成。用户信息包括性别、年龄、邮件地址,物品信息包括电影名、电影类型、电影导演、电影演员和发布时间。
3.2 评价指标
3.2.1 数据集划分
将数据集按照8∶2的比例划分为训练集和测试集。对于训练集,将所有与用户有交互的物品项取作正样本;随机抽取跟正样本数量相同的且与用户无交互的物品项作为负样本。对于测试集,将所有与用户有交互的物品项取做正样本;随机抽取跟正样本数量相同的与用户无交互且不存在于训练集上的物品项作为负样本。
3.2.2 准确率
准确率(Precision)描述的是最终推荐列表中发生过的用户-物品评分记录的比例,其值越高,代表最终推荐效果越好,如式(9)所示,T(u)表示用户在测试集上的正样本集合,R(u)表示推荐系统返回的推荐列表:
(9)
3.2.3 召回率
召回率(Recall)描述的是最终推荐列表中发生过的用户-物品评分记录在测试集正样本集合上的比例,其值越高,代表最终的推荐效果越好,如式(10)所示:
(10)
3.3 对比算法介绍
本算法使用了多层神经网络的方式捕捉用户兴趣变化,并使用了聚类的算法划分用户群体,因此选取一个聚类的算法CoClustering和一个多层神经网络的方法Deep-FM作为对比算法,同时选取两个经典的推荐算法UCF和MF用于衡量本算法的有效性。
1)UCF:基于用户的协同过滤算法,利用用户间的相似性,将相似用户喜好的物品推荐给用户[1]。
2)CoClustering:一种利用用户间和物品间的相似性进行推荐的聚类推荐算法[12]。
3)MF:通过将用户物品的交互矩阵划分为p*k,q*k两个矩阵,利用这两个矩阵相乘得到预测结果[3]。
4)Deep-FM:将用户和物品等多维特征,通过FM和深层网络两个部分分别进行学习,用多层神经网络将两部分的值结合到一起,拟合出最后的结果[10]。
3.4 对比试验
为了探究本算法的有效性,本文在MovieLens-1M数据集上,将上述算法同本算法进行了对比试验,结果如表3所示,TOP-N代表按照用户对未交互物品点击概率从低到高排序,返回的前N个作为推荐列表的物品。从表3中可以看出,随着TOP-N的N值增大,所有算法的准确率降低,召回率提升。基于聚类的Coclustering算法效果好于传统的基于用户的协同过滤算法,表明聚类算法能有效捕捉用户间联系。本算法利用聚类算法将用户划分入不同的用户群体。
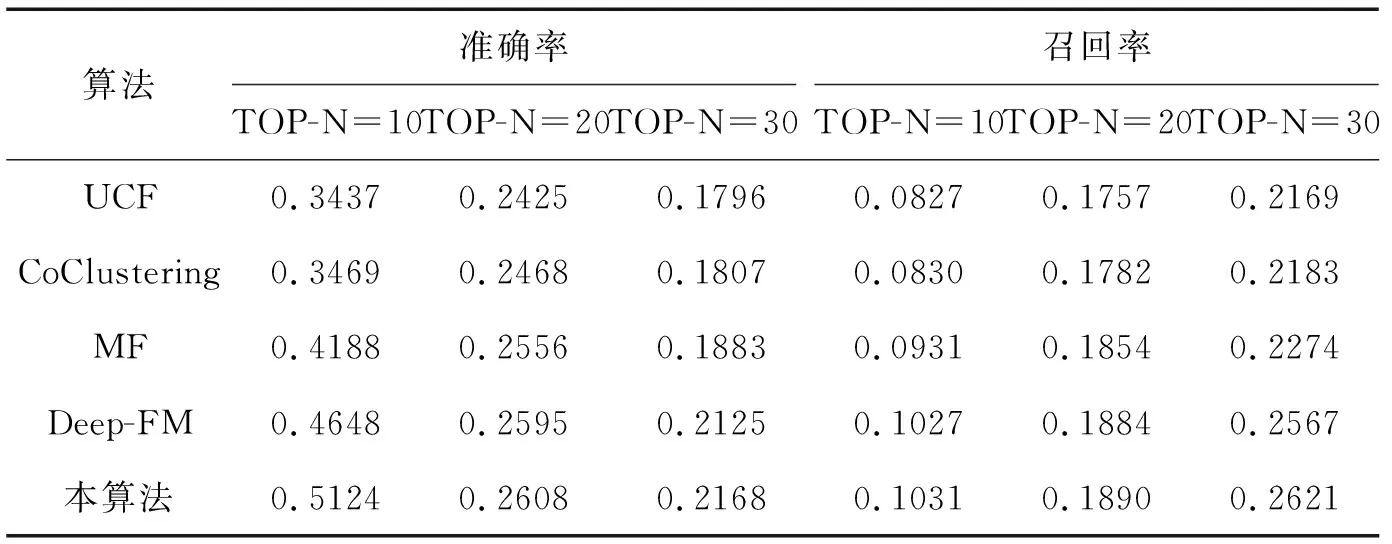
表3 不同TOP-N下不同算法的准确率与召回率
矩阵分解算法MF效果良好,说明了组合用户物品信息进行推荐的意义。利用多层神经网络方法的Deep-FM算法效果明显好于MF和CoClustering算法,体现了多层神经网络在拟合用户兴趣方面的强大能力。本算法利用多层神经网络来预测用户对所有未交互物品的点击概率。无论TOP-N值如何变化,本算法都始终优于上述对比算法。
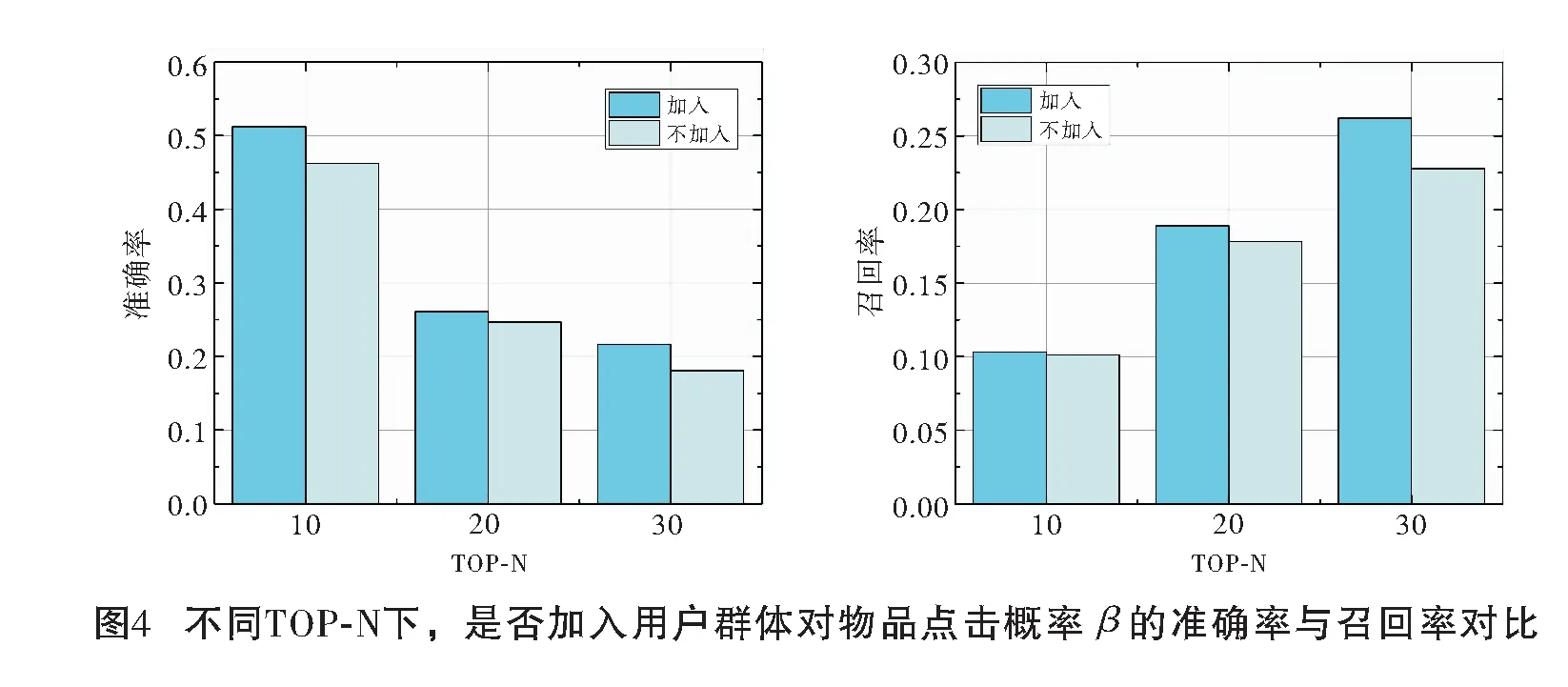
3.5 用户群体兴趣变化对用户个性化推荐的效果
接下来进一步讨论基于用户群体兴趣变化的个性化推荐算法中,用户群体兴趣变化对用户个性化推荐的效果。为此进行了如图4所示的试验,探究是否加入用户群体对物品点击概率β对两个评价指标的影响。从图4中可以看出,加入用户群体对物品点击概率β后,基于用户群体兴趣变化的个性化推荐算法在召回率和准确率上都有明显提升,这表明了本文捕捉用户群体兴趣变化方法的有效性,以及用户群体兴趣变化对用户个性化推荐的正面影响。
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
小学生学习指导(低年级)(2022年5期)2022-05-31
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
疯狂英语·初中天地(2021年11期)2021-02-16
铁道通信信号(2019年6期)2019-10-08
少年漫画(艺术创想)(2019年2期)2019-06-06
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
