
大宗商品交易领域词典构建
2022-03-28 06:31:44黄金源孙若莹
北京信息科技大学学报(自然科学版) 2022年1期
黄金源,孙若莹
(北京信息科技大学 信息管理学院,北京 100192)
0 引言
近年来大宗商品已经成为国民财富管理和资产管理的重要组成部分[1],大宗商品交易作为大宗商品领域的重要内容,积累了大量的文本数据。现今对文本数据挖掘的研究多集中在情感分类方面[2],而对大宗商品交易领域的文本挖掘的研究极少,如何有效地利用这些文本数据成为当下研究的热点。
领域词典是大数据文本挖掘工作的重要内容[3],构建一个大宗商品交易领域词典是实现对该领域文本数据高效挖掘的必然前提。石玉鑫等[4]提出一种用于商品评价对象挖掘的基于线性判别分析(linear discriminant analysis,LDA)模型的领域词典构建方法,在商品评价领域具有良好的性能。司凯[5]提出一种基于监督学习领域的词典构建技术,利用轻量级梯度提升机(light gradient boosting machine,lightGBM)模型训练分类器,在文本的分类中取得很好的效果。徐雨楠[2]提出一种基于语料库和K均值聚类的方法构建电力领域词典。冯蜀茗等[6]用机械分词与串频统计相结合的方法构建能够进行相关度监控的领域词典。李伟卿等[7]在人工标注的基础上,基于同义词林的扩展,以及大规模的评论文本的词向量训练,计算词语的语义相似度和相关性,进行特征的识别与归并,进而形成产品特征词典。上述研究工作的重点主要集中在利用网络文本作为语料进行领域词典的构建,采用词语的语义相似度进行领域词典扩充。
本文针对大宗商品交易领域缺乏特有领域词典这一问题,基于书籍文本面向大宗商品交易领域构建了领域词典,利用该领域两本经典书籍《大宗商品电子交易市场理论与实践》[8]和《大宗商品交易金融服务》[9],分别进行领域词典构建和领域词典扩充。与现有的研究绝大多数基于网络文本语料构建领域词典不同的是,本文所选用的语料为书籍文本。书籍文本在编写过程中具有较严格的语言规范和行文准则,与网络文本相比在构建词典过程中能够极大程度地降低噪声干扰[10-11]。
1 词典构建方法
1.1 构建流程
大宗商品交易领域词典构建流程如图1所示,主要包括4部分:1)构建领域基础知识库词集,将三大中文知识库:知网知识库(HowNet)、大连理工大学信息检索实验室(DUTIR)发布的情感词集、台湾大学发布的中文情感极性词集(NTUSD)合并筛选后,融合中科院金融领域情感词库得到候选种子词,再通过词长和词频双重过滤后形成基础知识库词集;2)对大宗商品交易领域语料进行处理,首先对语料进行人工筛选和分词处理,利用Jieba分词对语料进行分词形成分词词集,再通过基于词频-逆文本频率(term frequency-inverse document frequency,TF-IDF)的领域关键词提取算法提取关键词形成关键词词集;3)将基础知识库词集和关键词词集融合形成大宗商品交易领域词典;4)通过Word2vec生成的词向量计算词之间相似度,对大宗商品交易领域词典进行新词发现,实现领域词典扩充。

图1 大宗商品交易领域词典构建流程
1.2 基础词集构建
通过实验发现,仅利用书籍文本进行领域词典构建,所选取出的词语中缺乏诸如寻底、跳水、破净等能够体现出大宗商品交易领域行情状态的词语。因此为了构建更加完善的领域词典,从前述三大中文知识库和中科院金融领域词典中提取出与大宗商品交易领域相关且能够体现出行情状态的词。将这些词作为基础知识库词集,融合到本文所构建的大宗商品交易领域词典中。
1.3 关键词提取
为了解决语料中存在大量对领域词典构建造成干扰的低频词问题,本文对经过语料预处理之后形成的训练语料,通过基于TF-IDF的领域关键词提取算法进行关键词提取[12]。
训练语料集合C表示为{ci}(i∈[1,2,…,n]),其中n为训练语料短语、词组数。提取的种子词集Z表示为{zj}(j∈[1,2,…,k]),其中k为短语权重排序大小。
关键词提取算法步骤如下:
1)计算词语ci在语料C中的词频。
2)计算词语ci在整个语料中的逆文本频率:FIDF=lg(Ct/(Bt+1)),其中Ct为集合C中总文档数,Bt为语料中出现ci的文档个数。
3)计算词语ci的TF-IDF值:
FTF-IDF=FTF×FIDF
其中:FTF为词频;FIDF为逆文本频率。
4)重复步骤1)~3),得到每个词语的TF-IDF值。
5)对每个词语的TF-IDF值进行排序,选出前k个词语作为关键词。
1.4 领域词典扩充
当下处于信息内容不断更新迭代的时代,大宗商品交易领域的语料也在不断更新,会有源源不断的领域新词出现,因此本文提出一种基于分布式表示的领域词典扩展方法,使用Word2vec实现对领域词典的新词发现[13]。
领域新词指在某一个领域中未曾出现的词汇或者词语[14]。本文所描述的领域新词的定义如下:在某一文本中出现的词语wi,为本文所构建的大宗商品交易领域词典中未收录的词语,则将词语wi称为大宗商品交易领域新词。
通过对文本语料的训练能够把对文本内容的处理转换为K维向量空间中的向量运算,而文本在语义上的相似度是用向量空间的相似度来表示的。领域词典扩充的工作原理是将领域词典中的词语,利用Word2vec生成每个词向量,计算每一个词相似度最高的若干个词语。
计算包含文本语义的词向量间的余弦相似度,能够度量出两个词之间的相似性[15]。因为由Word2vec生成的词向量是基于上下文语义生成的,所以采用余弦距离来计算种子词与训练语料中词语的相似度。假设n维的候选词a(x11,x12,…,x1n)与n维领域词b(x21,x22,…,x2n)的余弦相似度为
(1)
分别计算领域词典中的词语与新语料中提取的关键词的余弦值,从而得到与词典中的每个词的相似度。设定阈值,选取相似度最高的若干个词,再遍历领域词典中的每一个词,如果领域词典中没有该词,则认为该词语为领域新词,扩充收录到大宗商品交易领域词典中,反之则不是领域新词,将该词语的词频与原词典的词频进行叠加。
2 领域词典构建
2.1 数据处理
数据来源:《大宗商品电子交易市场理论和实践》为构建领域词典数据集,《大宗商品交易金融服务》为领域词典扩充数据集。
数据预处理:包括停用词处理和分词。书籍文本语料中存在着部分中英文标点、连词以及程度副词等噪声,因而需要对原文本进行停用词处理。利用哈工大停用词表,对文本语料进行去停用词处理,再用Jieba分词工具进行分词,最终形成训练语料。
语料的关键词标注:将《大宗商品电子交易市场理论和实践》进行数据切分,形成A、B两部分语料,其中语料A用于构建领域词典,语料B用于训练文本分类器模型。首先对语料A进行标注,通过对语料进行分词之后,制定语料标注规则,进而据此规则对语料进行标注:
1)文本中标注的关键词必须来自于语料中;
2)语料中出现次数较多或者与大宗商品交易领域关联较大的词,可标注为关键词;
3)语气连接词、程度副词等不标注为关键词;
4)关键词选取较短的词语,一般为5个字符以下;
5)由于大宗商品交易领域的某些交易平台名称或者相关行业标准文件名称大于5个字符,因此对这类名词的标注不适用于第4)条;
6)语料为书籍文本,因此将每一小节作为一个语料段,通常标注3~8个关键词。
按照以上规则对原本语料进行标注,标注示例如表1所示。

表1 语料标注示例
2.2 词典构建结果
本文所构建的大宗商品交易领域词典,主要分为两类词汇:一类是大宗商品交易领域的通用词汇,即在大宗商品交易过程中经常使用的词汇,包括交易行为词、行情状态词等;另一类是大宗商品交易领域专有词汇,如交易平台名称、交易品种、交易商等。词典构建结果如表2所示。

表2 大宗商品交易领域词典构建结果
对《大宗商品电子交易市场理论和实践》经人工筛选文本之后形成的语料进行关键词提取,通过基于TF-IDF的领域关键词提取算法选取语料中的关键词。但是该算法具有一定的局限性,如表3所示,选取的关键词包含“全国”、“规范”、“法律”等与大宗商品交易领域关联性不大或者与其他领域通用的词语,因此需要经过人工方式对其进行剔除,以提高领域词典的特有性。

表3 关键词提取算法所提取的关键词示例
通过前文所述的领域词典扩充算法,利用《大宗商品交易金融服务》对所构建的领域词典进行扩充。最终经过扩充之后的领域词典如表4所示。

表4 领域词典扩充后的情况
大宗商品交易领域词典中的词性、词频能够在文本分类和命名实体识别任务中起到重要作用,因此本文所构建的词典包括词语、词性和词频3部分。其中词性包括名词(n)、行情状态词(v)、交易所名称(nr)等类别。词频为词语在本文构建词典所使用的全部语料中出现的次数。词典存储格式为CSV文档,存储示例如表5所示。
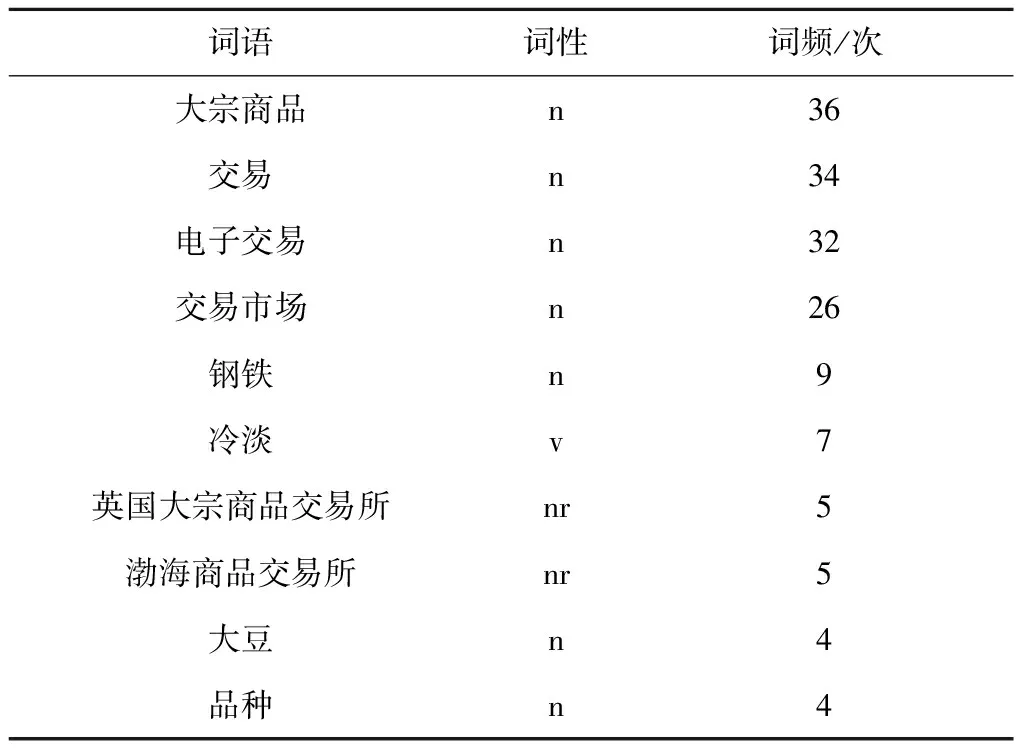
表5 大宗商品交易领域词典存储示例
3 实验及分析
通过对比不同方法在关键词提取任务中的效果以及领域词典在文本分类任务中的性能,分别验证本文采取的关键词提取方法的可行性和所构建的大宗商品交易领域词典的有效性。
3.1 关键词提取对比
采用准确率、召回率和F1值作为指标,将本文方法与使用LDA主题模型进行大宗商品交易领域的关键词提取进行对比。
准确率为
(2)
召回率为
(3)
F1值为
(4)
式(2)~(4)中:N1为提取出来的该领域正确的关键词数量;N2为提取出来的该领域所有关键词数量;N为所有标注为大宗商品交易领域的关键词数量。
实验结果如表6所示。通过对比可以发现,本文所采用的关键词提取方法在各项指标上的效果均有明显提升。

表6 关键词提取实验对比 %
3.2 领域词典构建结果对比
通过文献调研发现,朴素贝叶斯算法(naive Bayes,NB)[16]和支持向量机(support vector machine,SVM)[17]在文本分类领域具有良好的效果,因此为验证本文所构建的领域词典的有效性,设置两组实验进行文本分类对比。
实验数据集为上文处理的语料B以及从网络上爬取的与大宗商品交易领域不相关的文本数据。评价指标仍为准确率、召回率以及F1值。通过将本文所构造的词典作为文本特征输入到分类器中,对比没有利用词典作为文本特征的分类器的分类效果,如表7所示。
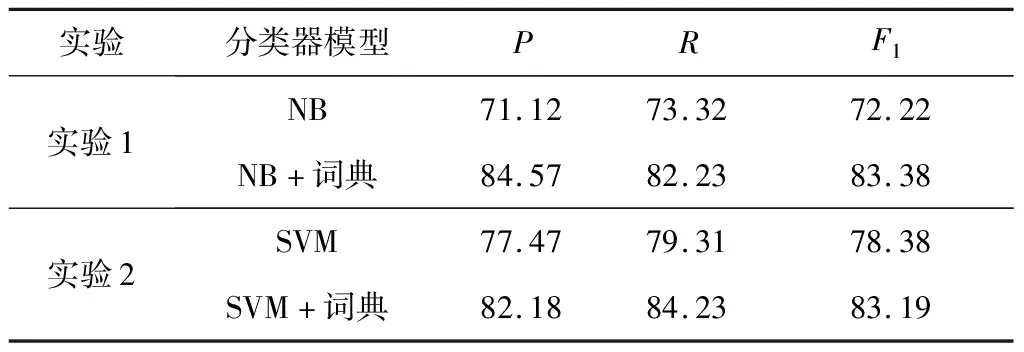
表7 文本分类实验结果 %
由表7可知,利用本文所构造的词典进行文本分类,准确率分别提升了13.45%和4.44%。F1值提升了11.16%和4.81%。由此可以看出,本文所构建的大宗商品交易领域词典在文本分类任务中具有较好的表现,整体的分类效果有明显提升。
4 结束语
本文针对大宗商品交易领域缺乏其特有领域词典问题,基于书籍文本构建了该领域词典。同时针对大宗商品交易领域不断更新的文本语料,基于Word2vec词向量模型的领域新词发现算法,对词典进行扩充。与现有大多数研究者利用网络文本语料构建词典不同,本文所使用的语料为书籍文本,充分利用了其语言的规范性,极大地降低了因文本语言的不规范而带来的噪声干扰。针对目前丰富的领域书籍文本,本文所提出的方法也能够运用到其他领域,对构造其领域词典具有一定的参考意义。领域词典的作用不仅仅局限于文本的分类任务,同时对命名实体识别也具有重要的意义,因此下一步的工作可以利用本文所构造的领域词典进行命名实体识别任务。
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
音乐天地(音乐创作版)(2019年12期)2019-02-09 12:30:40
投资北京(2018年10期)2018-12-29 09:03:46
中国市场(2016年26期)2016-07-11 03:54:13
商事法论集(2016年2期)2016-06-27 07:21:04
当代贵州(2015年13期)2015-06-13 09:12:13
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
图书馆论坛(2014年8期)2014-03-11 18:47:59
语文知识(2014年12期)2014-02-28 22:01:18
