
生成对抗式网络及其医学影像应用研究综述
2022-03-26 05:13张颖麟胡衍东田理沙刘江
中国图象图形学报 2022年3期
张颖麟,胡衍,东田理沙,2,刘江*
1. 南方科技大学, 深圳 518055; 2. TOMEY株式会社, 名古屋 451-0051,日本
0 引 言
生成对抗式网络(generative adversarial network,GAN)已经广泛应用于图像合成(Wan等,2019;Zhang等,2019a)、图像重建(Li等,2018;Zhao等,2019)、风格迁移(Liu等,2019;Mejjati等,2018)和图像修复(Wang等,2017;Wang等,2020)等自然图像处理任务,并用于解决医学影像中的相关问题。深度学习算法在图像分类识别(He等,2016;Huang等,2016;Krizhevsky等,2012)、语义分割(Badrinarayanan等,2015;Shelhamer等,2017)和语言处理(Bahdanau等,2016;Sutskever等,2014)等领域取得了显著成就,这主要得益于计算性能的提升、网络结构的优化以及大规模的数据集。但是由于数据标注昂贵、类别不平衡、域移以及隐私保护等问题,在医学影像中的应用十分有限。首先,医学影像的数据标注需要医学和医学成像方面的专业知识,通常由专业的医学专家操作,因此标注过程十分耗时且非常昂贵(Greenspan等,2016)。其次,由于健康组织通常占主导地位且呈高度重复模式,通常会过度代表正常类别,这种类别不平衡问题会导致模型收敛缓慢或者过拟合(Ravì等,2017)。此外,来自不同设备或者具有不同参数设置的同一设备通常具有不同的噪声分布、图像特征以及形状等。例如,在用于眼部成像的OCT(optical coherence tomography)中,不同设备使用了不同波长的激光以及不同的扫描频率等(Schmitt等,1999;Xiang等,1998),因此,基于某一设备成像数据训练得到的模型难以很好地适应其他设备。最后,在建立和共享数据集的过程中需要充分考虑患者的隐私安全问题(Dysmorphology Subcommittee of the Clinical Practice Committee和American College of Medical Genetics,2000),这给创建大规模医疗数据集带来了很大挑战。生成对抗式网络的出现为解决上述问题提供了新的思路。Frid-Adar等人(2018)使用GAN来扩展具有不同疾病的医学脑CT(computed tomography)图像的数据集,有效提升了分类性能。同时,Frid-Adar等人(2018)为了保证跨模态数据合成过程中的形状一致性,在Zhu等人(2017)的基础上引入在线分割任务,使得生成器与分割器的优化过程相辅相成。实验结果表明,对于CT和MRI(magnetic resonance imaging)合成图像的形状一致性评价指标S-score的得分,从引入在线分割任务之前的66.8%和67.5%分别提升至引入后的69.2%和69.6%。
国内已有一些综述性工作对生成对抗式网络的发展进行分析总结,但没有针对医学影像处理领域的相关工作进行回顾。曹仰杰等人(2018)分析了GAN模型的改进,重点介绍了其在计算机视觉方面的几类突出应用,如图像修复、图像合成以及风格迁移等。陈佛计等人(2021)从模型架构、目标函数和GAN在训练过程中存在的问题,以及如何应对模式崩溃等角度对GAN的相关研究与应用进行分析回顾。已有一些医学影像处理领域的深度学习综述,但没有讨论生成对抗式网络的相关工作。施俊等人(2020)介绍了深度学习方法在病灶检测、图像分割以及辅助诊断方面的应用。张航等人(2020)针对深度学习方法在婴儿脑MRI图像分割中的最新进展进行了系统总结。
本文通过对医学影像处理相关瓶颈问题以及生成对抗式网络的深入分析,旨在找到两者的结合点,以及未来的改进方向,也为该领域相关研究人员提供参考。
1 GAN概述
1.1 基本原理
生成对抗式网络包含生成器G和判别器D两部分,如图1所示。

图1 生成对抗式网络Fig.1 Generative adversarial network
生成器G用于学习数据分布,判别器D用于判别样本是来自真实数据还是生成器。二者进行值函数为V(D,G)的二人博弈游戏,具体为

(1)
式中,z表示噪声,pz(z)是噪声分布,x是真实数据,pdata(x)是真实数据分布。判别器D的目标是尽可能区别真实数据与生成样本,即最大化Ex~pdata(x)[logD(x)]+Ez~pz(z)[log(1-D(G(z)))]。生成器G的目标是使生成数据G(z)尽可能接近来自真实数据分布的样本,即最小化Ez~pz(z)[log(1-D(G(z)))]。但是,在实际中由于在开始阶段G的合成能力非常差,因此会导致log(1-D(G(z)))饱和,所以通常通过最大化Ez~pz(z)[logD(G(z))]来优化生成器。在训练过程中,生成器G和判别器D通过交替优化的方式互相学习,最终,生成器会学习到数据的分布,而判别器则无法鉴别样本究竟来自真实数据还是生成器。二者在相互对抗的过程中互相学习逐渐变强。
1.2 衍生模型
生成对抗式网络模型提出(Goodfellow等,2014)以来,进行了许多改进与扩展,产生了多种衍生模型,大致可分为任务拆分模型、条件约束模型以及图像到图像的翻译模型。现有代表性的衍生模型生成器的计算流程与结构如图2所示,其中,z~pz(z)表示噪声分布,I0表示输入图像,I表示输出图像,c表示条件变量,Gi表示第i个生成器,Eni表示第i个编码器,Dei表示第i个解码器,L1表示第一范数损失函数,D表示判别器。

图2 GAN衍生模型生成器的计算流程与结构Fig.2 The calculation process and structure of the GAN derivative generator((a)LAPGAN; (b)PGAN; (c)HDPix2pix; (d)CGAN; (e)ACGAN; (f) ICGAN; (g)Pix2pix; (h)CycleGAN; (i)BicycleGAN)
任务拆分指将一个困难任务拆分成多个相对简单的子任务,从而使GAN的训练变得更加稳定,提升模型性能。Denton等人(2015)提出一种基于Laplacian金字塔的生成对抗式模型LAPGAN(Laplacian GAN),将随机向量作为输入,在金字塔的每个层上训练一对生成器和判别器,每层上的生成器仅负责学习上一层到该层的差分图像In-In-1,如图2(a)所示,该方法能够合成尺寸为32 × 32像素和64 × 64像素的图像。高分辨率图像的生成很困难,因为更高的分辨率使判别器更易于区分生成的图像和真实图像,从而极大放大了梯度问题。Karras等人(2018)提出了一种生成对抗式网络的训练方法PGGAN(progressive GAN),关键思想是逐渐增加生成器和判别器,从低分辨率开始,随着训练的进行逐渐添加新层,对越来越精细的细节建模,将合成图像的尺寸提高到1 024×1 024像素,如图2(b)所示。Wang等人(2018)提出一种多尺度网络架构HDPix2pix,如图2(c)所示,它的生成器包括一个全局生成器G1和一个局部增强生成器G2,在训练过程中,首先训练全局生成器,然后训练局部增强器,最后,对它们一起进行微调,该方法可生成2 048×1 024像素具有视觉吸引力的结果。
条件生成模型可通过基于条件信息指导数据生成过程。Mirza和Osindero(2014)通过简单地对生成器和判别器馈送条件信息y首先构造了生成对抗式网络的条件版本CGAN(condition GAN),如图2(d)所示,并证明了该模型可以生成以类别标签为条件的MNIST(mixed national institute of standards and technology database)数字。Odena等人(2017)提出ACGAN(auxiliary classifier GAN)以辅助分类器的形式引入了类条件信息c,如图2(e)所示,尽管这种方法与已有模型没有很大区别,但是这样的改进在ImageNet数据合成任务中产生了不错结果并且可以使训练更加稳定。Perarnau等人(2016)提出ICGAN(invertible conditional GAN),如图2(f)所示,由编码器和CGAN两个关键部分组成,可以将真实图像x压缩为潜在表示向量zl和条件向量y,并且允许使用条件向量y控制生成样本的复杂属性。在MNIST和CelebA数据集上的实验表明,该模型可以控制合成数字的内容和风格,控制合成人脸图像的肤色、表情以及头发等更为复杂的属性。Olszewski等人(2020)提出一种交互式方法用于人脸图像中毛发的编辑与合成,该研究工作通过一个交互界面使用户可以通过稀疏简单地引导笔触定义所需要的目标发式的结构和色彩,但该方法的属性控制主要集中在像素层面。
图像到图像的翻译属于条件生成对抗式网络的一种特殊形式,由于该方向有大量研究工作,因此,本文将其单列为一个子领域,并对其相关研究工作进行回顾。图像到图像的翻译由Isola等人(2017)首先提出,类似语言翻译任务中可以将对同一事物的描述由英语翻译成法语一样,他们认为在图像合成任务中,可以将RGB图像、边缘图以及语义标签图等理解为对同一事物的不同描述,因此这些不同类型的图像之间可以相互转换。他们提出了将条件对抗网络作为图像到图像翻译问题的通用解决方案Pix2pix,生成器负责学习从输入图像到输出图像的映射,如图2(g)所示。此外,该方法通过判别器学习损失函数来训练该映射,并且证明了这种方法可以有效地从标签图合成照片等。但是该解决方案存在两个固有缺陷:1)需要成对地训练数据;2)合成数据多样性不足。Zhu等人(2017)提出了CycleGAN,如图2(h)所示,通过引入循环一致性约束令G2(G1(I0))≈I0,缓解了Pix2pix中需要配对图像的问题,实验结果证明了该方法在涉及颜色和纹理变化翻译任务上的有效性,但对需要更改几何结构的任务会发生失效,此外作者指出未配对方法可达到的结果与配对训练数据可达到的结果之间仍然存在差距。为了解决图像翻译任务中模式崩溃问题,并产生更多样化的结果,Zhu等人(2018)提出BicycleGAN,如图2(i)所示,通过组合多个目标来鼓励潜在空间z→I′→z′和输出空间I→z→I′之间的双向映射,防止训练期间从潜码到输出的多对一映射(也称模式崩溃问题),实验结果表明,该方法可以在广泛的图像到图像的翻译问题中产生视觉上有吸引力的结果,且相比于其他基准更加多样化。
上述衍生模型生成器的改进、优缺点及适用场景如表1所示。
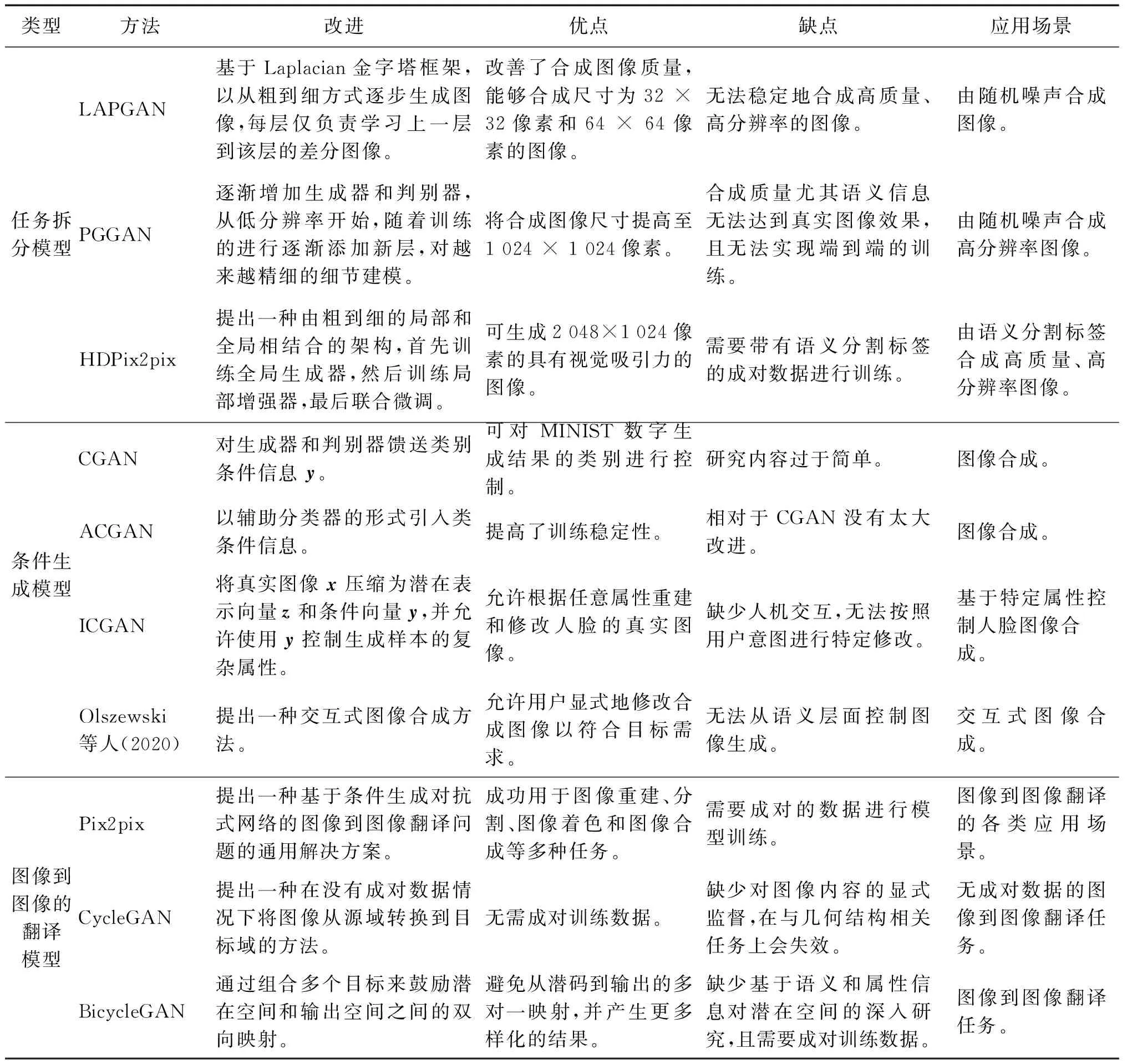
表1 生成对抗式网络的衍生模型Table 1 Derivative model for generating adversarial networks
1.3 面临的挑战
生成对抗式网络在许多领域表现了出色性能,但是仍然存在一些亟待解决的挑战。
1)生成高质量、高分辨率并具有多样性的图像。生成对抗式网络的训练过程是动态的,并且对于参数优化以及模型体系结构等各方面都是十分敏感的。已有的大量研究提升了模型训练的稳定性,改善了图像合成的质量和分辨率,但是从复杂的数据集(例如ImageNet)生成高质量、多样的图像仍然十分困难。在大规模复杂ImageNet数据集上以128 × 128像素分辨率进行训练条件下,将最新的先进模型进行性能比较,Wu 等人(2020)提出的LOGAN(latent optimisation for generative adversarial networks)取得了IS(inception socre)= 148的最佳成绩,Brock 等人(2019)提出的最新先进图像生成模型取得的IS为124.5。然而,相比于实际数据IS = 233的结果仍然存在较大差距。
2)根据实际需求、结合用户意图以控制图像的生成过程。控制生成图像的特定属性在实际应用中存在广泛需求,例如,改变人脸图像中的脸部表情、鸟类图像中鸟喙的长度,以及嫌疑人面部毛发。这要求在图像生成过程中,按照用户意图仅更改特定属性,而保持其他属性不变,然而,已有研究在属性解耦以及控制方面仍然存在许多不足。Karras 等人(2019)使用的特征解耦主要是基于不同尺度层级下的特征操作,以实现在保留高层级特征的同时更改低层级特征,但是难以单独更改特定属性。
Nguyen-Phuoc等人(2019)将姿态从身份属性中解耦出来,但是需要一个特定的几何架构,而这并不适合其他的属性。Alharbi和Wonka(2020)将空间不变编码与空间可变编码分开,并基于网格的结构控制特定区域的合成,然而该方法对于不同粒度层面的控制,需要进行不同的调整,也无法实现前景与背景的解耦。
3)在无成对训练数据情况下,图像到图像翻译的解决方案。在实际应用中,成对的训练数据通常难以获得,例如,艺术作品的风格迁移、季节转换以及物体变形等,因此,基于无成对训练数据集的图像到图像翻译的解决方案具有重要研究意义。Zhu等人(2017)通过引入循环一致性损失,减少了可能的映射空间,实现无成对数据下的模型训练,但是该方法仅能在涉及颜色和纹理变化的翻译任务上取得不错的性能,无法应对需要更多变化和极端的转换的场景,尤其是几何结构的变化。Almahairi 等人(2018)提出了Augment CycleGAN用于从未配对的数据中学习域之间的多对多映射,以应对更多变化的场景,但是其合成图像的保真度较低。
1.4 小结
生成对抗式网络基于两人博弈原理,无需显式地指定学习目标,间接地对未知分布进行建模,在图像处理领域得到广泛应用。许多研究者在任务拆分、引入条件约束以及图像到图像翻译3个方面进行了大量研究,有效改善了合成图像的质量,提高了分辨率,允许对图像的合成过程进行更多的控制,尤其是图像到图像的翻译作为一种通用框架广泛应用。但是,仍然存在一些挑战:1)在大规模复杂数据集下生成高质量、高分辨率并具有多样性的图像;2)根据实际需求、结合用户意图对图像生成过程在不同层面、不同粒度上对不同属性进行控制;3)在无成对训练数据的情况下,训练图像到图像翻译模型,并保证图像的翻译质量与多样性。
2 GAN在医疗图像领域的应用
生成对抗式网络在医学影像领域的各类应用按应用目的可以归纳为数据增广、模态迁移、图像分割以及图像去噪等。数据增广可以通过学习训练数据分布以生成额外的样本,缓解由于标注困难、隐私保护以及类别不平衡等导致的医学影像数据匮乏问题。模态迁移可以通过学习图像到图像的映射关系,将源域的模态迁移到目标域,缓解由于域移导致的分割或分类模型泛化性能差的问题,并且可为疾病的诊断提供多视角信息。此外,生成对抗式网络的生成器和判别器对于提高基于深度学习的分割模型的性能均有重要意义。最后,生成对抗式网络还可以应用于去噪,将由较低剂量、较低分辨率或者较短的曝光时间等导致的有噪声的图像重建到近似理想的图像,同时保留图像中的重要细节。
2.1 数据增广
数据增广指通过学习训练数据的分布以生成额外的样本,从而扩大训练数据集规模,提升分类、分割等网络的性能。生成对抗式网络能够基于随机噪声或者是相关的条件先验合成新的数据,扩展原有的训练数据集。由于医疗数据的标注成本高昂、健康组织与病灶区域类别不平衡、并且医疗数据的使用涉及病患的隐私保护,因此,利用生成对抗式网络进行数据增广是一种有前景的解决方案。
1)基于随机噪声的无条件GAN合成方法。Frid-Adar等人(2018)利用生成对抗式网络变体DCGAN隐式地学习肝脏病变数据分布以合成尺寸为64 × 64像素的图像数据,然后利用其合成的数据扩展原始训练集,实验结果表明,通过添加合成数据扩展训练数据集,可以将仅使用传统数据增强的评价指标灵敏度和特异性从78.6%和88.4%提升至85.7%和92.4%。Kwon等人(2019)结合自动编码器和GAN的优势提出一种新颖的3D生成对抗式模型,可以由随机向量生成尺寸为64 × 64 × 64的3D脑MRI数据,缓解了模式崩溃、图像模糊以及训练不稳定的问题,结果表明,该方法可以生成多种类型和模态的逼真3D全脑图像。但是基于随机噪声的图像合成方法,一个主要缺点就是其合成图像的分辨率过小,而在很多疾病诊断中,通常需要观察组织的细微变化,这要求合成图像具有更高的分辨率。
2)基于图像条件先验的GAN合成方法。图像到图像的翻译生成对抗式网络主要包括基于Pix2pix基础框架和基于CycleGAN的生成对抗式网络两大类。Pix2pix的优点是合成图像质量高,基础生物结构保留完整,缺点是需要配准的图像对,如图3所示,其中,(x,y)表示成对的血管结构图和真实的眼底图像,Gx表示基于血管结构图x合成的眼底图像;CycleGAN的优点是不需要成对的配准图像,但是其成像质量不如Pix2pix,生物结构容易发生丢失。然而,医学影像处理领域中对生物结构的合理性有着严格要求,因此,在数据增广方面,Pix2pix解决方案得到了广泛研究。

图3 图像到图像翻译的生成对抗式网络Pix2pixFig.3 Generative adversarial network Pix2pix for image-to-image translation
Costa等人(2018)将眼底图像的合成任务分解为二值血管树的分割与视网膜图像合成两个步骤,首先对输入视网膜图像进行分割得到二值血管树图像,然后以该二值血管树图像为条件先验,基于Pix2pix框架得到合成的视网膜图像。但是,该方法依赖于分割得到的二值血管树图像以生成新图像,限制了合成数据的多样性,并且合成算法会继承分割算法的潜在弱点。Zhang等人(2019b)提出一种素描—绘制生成对抗式网络SkrGAN(sketching-rendering unconditional GAN),该网络结构主要包括两个生成对抗式子模块,首先,第1个生成对抗式子模块负责从随机噪声中生成高质量的结构草图,然后,第2个生成对抗式子模块基于该结构草图的指导渲染进一步生成具有逼真前景结构的图像,该方法在视网膜彩色眼底、胸部X光、肺部CT和脑部MRI等医疗影像的合成任务中取得了先进表现。Jin等人(2018)开发了一种3D生成对抗式网络用于学习3D空间中的肺结节特性分布,以周围肺组织为条件来引导肺结节的生成,并通过多任务重建损失以生成减轻边界不连续伪影的高质量逼真结节,该方法可用于帮助克服获取医学图像中“边缘病例”数据不平衡的困难。Bissoto等人(2018)基于Pix2pixHD框架,利用语义分割与实例分割结果作为先验知识,以合成皮肤病损图像,利用合成的图像扩展真实图像训练集,将皮肤癌分类网络的性能提升了1%。Li等人(2020)基于生成对抗式网络模型,由非 COVID-19(corona virus disease 2019) 数据合成 COVID-19 CT 扫描,并通过合成的数据提高了分类模型的识别和检测能力。
在医学图像数据增广任务中,生成对抗式网络通过合成数据有效提高了分割、分类等模型的性能。无条件数据合成可生成多种类型、逼真的图像,但训练难度大,并且难以生成高分辨率、高质量的图像。基于Pix2pix框架的生成对抗式网络在医学影像领域广泛使用,合成的2维图像质量以及分辨率较高,但受限于合成样本的多样性不足,尤其在基础结构方面,目前无法通过几何约束在有效保证生物结构合理性的同时,合成具有多样性的图像。此外,已有模型能合成的3维影像分辨率低、成像质量较差。上述数据增广模型的改进、优缺点及适用场景如表2所示。

表2 数据增广应用Table 2 Data augmentation application
2.2 模态迁移
模态迁移解决的是一类视觉和图形问题,目标是通过包含来自不同域的配准或者未配准的成对图像训练集来学习输入图像与输出图像间的映射关系。多模态图像可以对目标组织进行全面检查,包括目标组织的确切定位和代谢活性、周围组织内的组织流动和功能变化以及导致最终疾病的病理组织学变化,有助于更加准确地诊断疾病。然而,由于高昂的成本和复杂的采集过程,不同模态的相应图像元组的采集非常稀缺且昂贵,模态迁移为该问题提供了一个有前景的解决方案。
对于跨模态图像迁移任务,由于成对训练数据通常难以获得,因此,模态迁移领域中基于CycleGAN的解决方案得到广泛研究,如图4所示,其中,X表示源域,Y表示目标域,GX→Y表示源域到目标域的生成器,GY→X表示目标域到源域的生成器,DX表示源域的判别器,DY表示目标域的判别器,Lcycle表示循环一致性损失。

图4 图像到图像翻译的生成对抗式网络CycleGANFig.4 Generative adversarial network CycleGAN for image-to-image translation((a)unidirectional CycleGAN;(b)bidirectional CycleGAN)
Hiasa等人 (2018)通过添加梯度一致性损失扩展了CycleGAN方法,实现了MRI到CT的跨模态图像合成,以将MRI与CT一起用于识别肌肉结构并诊断骨坏死,避免了CT图像拍摄过程中的放射性照射。为了解决域移问题,Chen等人(2018)提出一种无监督域自适应的语义感知生成对抗式网络SeUDA(semantic-aware GAN for unsupervised domain adaptation),在语义标签空间中嵌入嵌套的对抗性学习,通过语义感知损失来改善CycleGAN。为了将CT数字重建射线照片(digitally reconstructed radiographs,DRR)上训练的图像分割模型推广到X射线域,Zhang等人(2018a)提出一种任务驱动的生成对抗式网络TD-GAN(task driven GAN),用于将X射线图像迁移到DRR模态下。该模型包含一个经过修改的CycleGAN子结构,用于在DRR和X射线图像之间进行像素到像素的转换,以及一个附加模块,利用预训练的DI2I(dense image-to-image network)分割网络来保证分割一致性。为了应对不同设备或不同参数配置下同一设备成像结果的噪声分布存在差异的问题,Zhang等人(2020)提出了一种新颖的噪声自适应生成对抗式网络NAGAN(noise adaptation GAN),其中包含一个生成器和两个判别器,两个判别器分别用于内容和噪声分布的训练引导,并通过特征级的损失Frobenius范数进一步对内容与噪声模式两方面进行约束,实验结果证明该方法可以有效迁移噪声分布。为避免模态迁移过程中目标内容的丢失,Xie等人(2020)提出MI2GAN(mutual information constraint GAN),从图像中解耦出内容特征,并通过最大化内容特征间的互信息引导模态迁移过程。Yu等人(2019)提出一种用于跨模态3维MR图像合成的边缘感知生成对抗式网络Ea-GANs(edge-aware GAN),优化了合成图像内容结构的纹理细节,缓解了现有2维cGAN模型在切片间的不连续合成问题,在更大范围内捕获图像上下文。Yang等人(2020)提出一种基于顺序生成对抗式网络和半监督学习的双模态医学图像合成方法,优先合成低复杂度的模态图像,然后再合成高复杂度的图像。
模态迁移对于解决域移问题、提高深度学习模型泛化能力具有重要意义,并且多模态数据的融合往往有助于疾病得到更加准确的诊断。基于无成对训练图像的生成对抗式网络在该领域得到广泛研究,但是在模态迁移过程中,基础几何结构信息容易丢失,已有的相关研究对结构信息保持的研究仅局限在边缘以及语义分割等信息的融合。如何更深层次地将几何先验知识与生成对抗式网络结合起来是需要深入研究的方向。现有各模态迁移模型的改进内容、优缺点及适用场景如表3所示。

表3 模态迁移应用Table 3 Modality migration application
2.3 图像分割
图像分割即将图像分成若干特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。在医学影像处理领域,图像的精确分割是临床参数量化以及疾病分类的关键步骤,对临床诊断、治疗决策以及手术预后等方面具有重要意义。基于深度学习技术的图像分割方法得到迅速发展,但是由于医学领域的数据瓶颈问题,其数据驱动的优势未能充分利用。
生成对抗式网络的生成器和判别器对提高基于深度学习的分割模型的性能均有重要意义。生成器可以合成额外数据,判别器可以从高级语义层面对分割模型训练过程进行监督,并充分利用无标签数据。Tan等人(2021)提出一种基于深度学习的通用对抗式网络分割方案LGAN(GAN-based lung segmentation),通过生成器实现图像到分割结果的翻译,并结合判别器的EM(earth-mover)损失和分割结果的交叉熵损失对模型进行优化。Lei等人(2020)提出一种结合密集卷积U-Net和双重判别器的分割网络,其中一个判别器检查输入图像中目标对象的上下文环境,另一个判别器则检查分割结果的边缘细节。Yuan等人(2020)提出一种3维的具有良好泛化性能的生成对抗式分割网络,将任意模态图像的翻译和分割结合在一起,其关键在于通过生成对抗式网络提取模态不变性结构特征,以实现对任意模态图像的良好分割性能。Wu等人(2021)将多阶段姿态估计网络 MSPN(multi-stage pose estimation network) 和判别器集成在一起,使用带有多尺度膨胀卷积模块的MSPN扩大深层特征感受野,并且在GAN训练过程中,交替提供标记的和未标记的CMRI(cardiac magnetic resonance images)数据,以充分利用无标记数据。Ruan等人(2020) 提出了多分支特征共享生成对抗式网络,用于在CT上同时进行肾脏肿瘤的分割和量化,该网络由多尺度特征提取器MSFE(multi-scale feature extractor)、关注区域定位器 LROI(localization region of interest)和特征共享生成对抗式网络FSGAN(feature share GAN)组成。MSFE在不同尺度的特征图上提供强大的语义信息,这在检测小肿瘤目标时特别有效。LROI提取了肿瘤的目标区域,大幅降低了网络的时间复杂度。FSGAN通过联合学习和对抗学习正确分割和量化了肾脏肿瘤,有效利用了两个相关任务之间的共性和差异。Zhang等人(2018b)提出一种由生成器和分割器组成的互为有益的端到端的解决方案,通过循环一致性损失以及分割器监督下的形状一致性损失保持合成图像一致的解剖结构。现有各图像分割模型的改进内容、优缺点及适用场景如表4所示。

表4 图像分割应用Table 4 Image segmentation application
2.4 图像去噪
图像去噪过程中,需要将由于较低剂量、较低分辨率或者较短曝光时间等导致的有噪声图像重建到近似理想的图像,同时保留图像中的重要细节。Wolterink 等人 (2017)提出一种基于体素损失和对抗性损失的生成对抗式网络用于从低剂量CT图像估计常规剂量CT图像,同时通过实验证明了该网络对低剂量CT图像进行降噪是可行的,并且允许在含有较高噪声的低剂量患者CT图像中对冠状动脉钙化进行评分。Liu 等人(2020)提出TomoGAN,用于在低剂量成像条件下提高重建X-ray图像的质量,并且在两种条件下评估了该方法:1)足够数量的低剂量投影;2)数量有限的高剂量投影。实验结果表明该方法可以显著减少重建图像中的噪声。Ran 等人(2019)提出一种基于残差编码器—解码器Wasserstein生成对抗式网络RED-WGAN(residual encoder-decoder Wasserstein GAN)的MRI去噪方法,通过计算预训练的VGG-19(Visual Geomery Group 19-layer network)网络在特征空间中的距离来实现感知相似性,并将其与均方误差(mean square error, MSE)以及对抗损失结合在一起以形成新的损失函数, 在模拟和实际临床数据中,该方法表现了出色的噪声抑制能力和结构保持能力,并且运行速度得到大幅提高,平均执行时间为0.16 s。You 等人 (2020)提出一种以生成对抗式网络为基础的半监督方法GAN-CIRCLE,以从低分辨率图像中恢复高分辨率CT图像,该方法基于Wasserstein距离强制执行循环一致性,并在损失函数中引入联合约束以实现几何结构保持,此外,基于几种基本的设计原则优化了网络,减少了参数量,缓解了过拟合问题。You 等人(2018)提出一种3D降噪方法,称为结构敏感的多尺度生成对抗式网络SMGAN(structurally-sensitive multi-scale GAN),该方法结合了对抗性损失、结构损失以及L1损失进行模型优化,有效提高了低剂量CT的图像质量。
2.5 小结
生成对抗式网络已经广泛应用于医疗影像处理领域。1)基于Pix2pix基础框架的网络模型能够合成额外的高质量、高分辨率样本,以数据增广方式有效提高了分割和分类模型的性能。但是仍然存在合成样本多样性不足、基础生物结构保持困难以及3维影像合成能力有限等问题。2)基于CycleGAN基础框架的网络模型无需成对训练图像,在模态迁移应用中得到广泛研究,但是基础结构信息容易丢失,已有的针对模态迁移过程中结构保持的研究仅局限在边缘和分割等信息的融合,未来需要研究更深层次的几何先验知识的使用。3)生成器和判别器均可以与已有的分割模型融合以提升分割模型性能,生成器可以合成额外数据,判别器可以从高级语义层面指导模型训练,并能够充分利用无标签数据,然而已有研究主要集中在单一模态的图像分割,研究如何提取多种模态图像的不变性特征以实现具有更好泛化性能的分割模型,是临床应用的必要条件。4)生成对抗式网络应用于图像去噪领域,可以实现由低剂量图像重建正常剂量图像,减少患者受到的放射影响。
3 合成图像质量评估
3.1 常用评价指标
常用评价指标主要有IS、FID、SWD以及GAN-train和GAN-test。
1)IS(inception score)是评估GAN的最常见方法之一(Salimans等,2016)。IS使用在ImageNet上经过预训练的Inception网络(Shmelkov等,2018)计算生成图像的logits。具体为
(2)
式中,x是从生成器分布pg采样得到的合成图像,E是整个合成图像集合的期望,DKL是条件类分布p(y|x)与标签y边缘类别分布p(y)=Ex~pg[p(y|x)]之间的KL(Kullback-Leibler)散度。但是,IS没有考虑真实图像数据,并且不能度量生成器分布与真实分布之间的接近程度(Barratt和Sharma,2018)。
2)FID(Fr′echet inception distance)比较了真实图像pr(x)与生成图像pg(x)在Inception网络中倒数第2层激活的分布(Szegedy等,2014)。其分布都建模为多维高斯分布,并由它们各自的均值和协方差参数化。这两个高斯分布之间的距离度量为
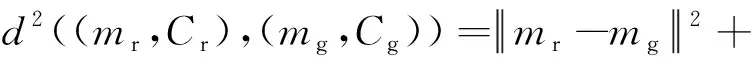
(3)
式中,(mr,Cr),(mg,Cg)分别表示真实图像与合成图像分布的均值和协方差。FID引入了与真实数据分布之间的比较,较低的FID意味着两个分布之间更接近,也就意味着生成图像的质量较高、多样性较好。但是,FID和IS都是基于特征提取,也就是依赖于某些特征的出现或者不出现。但是它们都无法描述这些特征的空间关系。此外,IS和FID都无法将图像质量与图像多样性区分开。
3)SWD(sliced Wasserstein distance)是基于Wasserstein的距离度量(Rabin等,2012),它从真实图像(Pr)和生成图像(Pg)的拉普拉斯金字塔表示中提取局部图像patch,并据此计算出多尺度统计相似性。具体为
(4)

4)GAN-train和GAN-test。GAN-train是在合成图像上训练并在真实图像验证集上进行测试的分类器的准确性(Theis等,2016)。GAN-test是在真实图像训练集上训练但在合成图像上测试的分类器的准确性。GAN-train类似于召回率,良好的GAN-train性能表明生成的样本足够多样化。第2个度量值GAN-test与精度相似,若GAN-test很高,则表示生成的样本是真实图像分布逼真的近似。相对于IS和FID,GAN-train和GAN-test不依赖于ImageNet预训练的Inception网络,并且考虑了与真实图像分布之间的相似度。此外,它们还可以将图像质量与图像多样性区分开。
除此之外,还有一些定性评估方法,如AMT(Amazon Mechanical Turk) perceptual studies(Isola等,2017),但是一些研究表明,对于这种基于人类感知的评估研究,生成图像质量必须有显著差异(Heusel等,2017)。
Theis等人(2016)研究对比了生成模型的优化与评估,不同的度量标准可能导致不同的权衡取舍,因此,相对于某一指标可以获得良好的表现并不意味对另一标准也可以获得相同的表现。
3.2 小结
数据增广、模态迁移、图像分割以及图像去噪等任务对于合成图像的质量以及多样性要求各有不同。数据增广侧重于数据合成的逼真质量以及丰富的多样性;模态迁移侧重于源域图像与目标域图像风格的接近以及内容的不变性;图像分割侧重于分割性能的提升;图像去噪侧重于成像质量的改善以及对于特定任务的有效性。因此,各任务在进行评价时,应充分考虑任务需求以选择合适的度量指标。
此外,已有的各类评价指标并不全面。如,如何有效评价图像去噪后的质量,获得良好的图像质量得分,并不能确保其去噪后的图像能提升下游分割和分类等任务的性能。
最后,对于不同任务应该统一其评价指标,以确保不同研究工作之间结果的参考性。
4 结 语
生成对抗式网络对于解决医学影像领域的数据瓶颈问题,充分发挥深度学习方法的数据驱动优势具有重要意义。
自生成对抗式网络提出以来,其理论不断完善,实际应用也取得了长足发展,但是在医学影像处理领域仍然存在一些亟待解决的问题:1)医学影像数据大部分是3维的,如MRI、CT等,如何提高3维数据的合成质量和分辨率;2)如何确保合成数据在获得多样性的同时保证其基础几何结构的合理性;3)存在大量无标记和未配对的数据,如何充分利用这类数据以生成高质量、高分辨率并具有多样性的图像,提升分割、分类模型性能;4)医学领域存在大量多模态数据交叉使用的需求,如何实现提升算法的跨模态泛化性能,以及不同模态数据的有效迁移。
针对上述问题,未来的研究工作应当聚焦于:1)针对3维数据合成优化网络架构、目标函数以及训练方式等,改善模型训练稳定性,提高3维合成图像质量、分辨率以及多样性;2)更深层次地将几何先验知识与生成对抗式网络结合;3)充分利用生成对抗式网络的弱监督特性;4)通过属性解耦以提取不变性特征,以实现具有更好泛化性能的分割和分类模型,并且在模态迁移过程中实现不同层面、不同粒度以及不同需求的属性控制。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年9期)2022-05-20
小天使·三年级语数英综合(2022年4期)2022-04-28
初中生世界·九年级(2018年12期)2018-12-22
成长·读写月刊(2018年8期)2018-08-30
汽车导报(2017年5期)2017-08-03
求学·理科版(2017年1期)2017-03-02
中学生数理化·高二版(2016年4期)2016-05-14
读者(2015年9期)2015-05-04
初中生世界·八年级(2014年2期)2014-03-15
