
广东省暴雨高风险区划
2022-03-25 11:39廖一丁
水资源保护 2022年2期
廖一丁 辉
(1.南京信息工程大学大气科学学院,江苏 南京 210044;2.南京信息工程大学应用水文气象研究院,江苏 南京 210044)
近几十年来,我国由暴雨造成的洪涝灾害事件频繁发生,且呈显著加剧的趋势,对人民的生命财产安全造成了严重的威胁[1]。广东省是中国大陆最南部的沿海省份,东西北三面连接内陆,南面濒临南海,邻近西太平洋,受西风带天气系统和热带天气系统影响频繁,加上南岭及其他山脉的地形作用,降水量十分充沛,暴雨洪涝成为广东省最主要的气象灾害之一。尤其是短历时暴雨所引发的洪涝灾害突发性强,危害性更高。由于广东省地形复杂,不同区域受天气系统的影响程度各有差异,使得降水的时空分布不均匀[2],给暴雨洪涝灾害的预警和防范造成一定难度。因此,对广东省的暴雨进行频率分析并研究其空间分布特征,有助于防灾减灾工作的开展,减少暴雨洪涝灾害带来的损失。
过去我国常用的水文频率分析方法是“单站、单时段、单一线型、基于常规矩的适线法”,线型通常选择皮尔逊Ⅲ型曲线[3]。然而单站分析需要较长的序列资料,序列长度的不足和观测站点的缺乏很大程度上影响了降雨频率估计值的可靠性[4],而且不能反映空间分布规律;常规矩估计的统计参数具有很大的偏态性,因而得到的降雨频率估计值极不稳定[3]。地区线性矩法是Hosking等[5]在线性矩的基础上提出的一种地区频率分析方法。美国国家海洋大气管理总署(NOAA)自1991年起在美国开展地区线性矩法在防洪设计标准的应用研究,从1997年起分区分批对全国的暴雨频率图集进行更新,于2006年提出了一套基于次序统计量的线性矩法结合基于水文气象一致区的地区分析法进行暴雨频率分析的完整系统[3,6-7]。近年来,国内有不少学者利用降雨资料进行了地区线性矩法的应用研究[8-16],证明了该方法的优越性:线性矩相比常规矩具有良好的估计参数的不偏性和对特大值的稳健性;地区分析法能够充分利用邻近站点的信息,提高降雨频率估计值的准确性,并且能更准确地获得其空间分布。
暴雨高风险区划是基于水文气象地区线性矩频率分析法得到的一个地区内某一定历时、一定频率(重现期)降雨事件中最大雨强的空间分布[12,15]。实际上,暴雨高风险区划的概念为定量估算“强降雨雨强、降雨落区、概率”三者的关系奠定了理论基础,填补了设计暴雨理论中强降雨雨强空间分布的空白;而现有的暴雨空间分布仅探讨暴雨的点—面关系。暴雨高风险区划为中小流域洪水尤其是山洪防治、预警提供了理论基础。
关于广东省降雨频率分析的研究,Yang等[17]以珠江流域为研究区,采用地区线性矩法对1 d、3 d、5 d和7 d年最大降水量进行频率分析,并联系气候背景及地形特征,探析流域极端降雨的时空分布规律;黄强等[18]利用广东省年最大日降水量资料,应用地区线性矩法,得到不同流域分区100 a或500 a以下重现期可靠性较高的降雨频率估计值。这些都是对1 d及以上长历时极值降雨的频率分析,而对小时历时降雨的频率分析比较少。
本文应用水文气象地区线性矩频率分析法以及在此基础上发展的暴雨高风险区划概念和技术,根据1 h、6 h、12 h和24 h年最大降水量资料对广东省进行暴雨高风险区划研究,绘制暴雨高风险区划图并分析其空间分布特征,以期为广东省的防洪规划设计和洪涝灾害早期预警提供参考。
1 资料与方法
1.1 研究资料
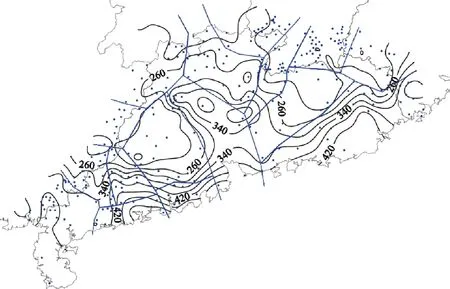
广东省陆地面积约17.97万km2,为提高研究区边界处降雨频率估计值的可靠性,本文将研究区广东省向内陆扩大约30~50 km的范围作为缓冲区。在研究区和缓冲区收集水文雨量站1 h、6 h、12 h 和24 h的历史年最大降水量资料。经质量控制,去掉明显错误的数据值,舍去不一致的资料序列,最终筛选出资料序列长度在20 a及以上的站点用于分析,其中具备1 h年最大降水量资料的有202个站点(其中广东省内有92个站点),具备6 h、12 h和24 h年最大降水量资料的有291个站点(其中广东省内有157个站点)。研究区及周围的地形和所有站点的分布如图1,可见广东省内站点的空间分布比较均匀,缓冲区站点密度略大于广东省内站点密度。站点降水序列范围从1939—2015年,长度不等,平均长度约34 a。
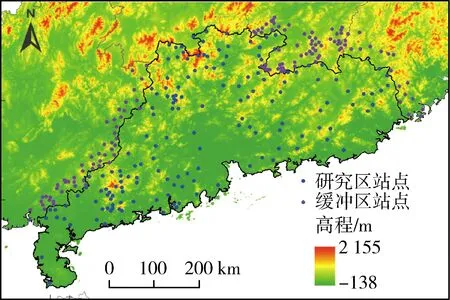
图1 广东省及周围缓冲区地形和站点
1.2 研究方法
Hosking[19]将线性矩定义为次序统计量线性组合的期望值,并定义了类似于常规矩的统计特征参数:线性矩离差系数CvL、线性矩偏态系数CsL和线性矩峰度系数CkL。基于水文气象地区线性矩法的暴雨高风险区划研究,以线性矩作为参数估计方法,在水文气象一致区划分的基础上,选择各一致区的最优分布线型,再根据地区分析法推求各站点的降雨频率估计值,并进行时空一致性调整,最终获得不同重现期下降雨的空间分布。
1.2.1水文气象一致区划分
地区分析法的前提是划分水文气象一致区。由于不同时段分析的站点不一定完全相同,降雨的分布特征也不相同,一致区的划分应分不同时段进行。水文气象一致区的划分和判定主要从以下3个方面进行:
a.气象相似性。一致区内满足降雨的水汽入流和气象成因一致。
b.水文相似性。一致区内所有站点的统计参数CvL和CsL在一定的容忍度内一致。采用基于CvL计算值的异质性检验指标H1来判断所划分的子区是否为一致性区域[5]。当H1<1时,表示该子区为可以接受的一致区。同时,利用各站点的CsL对子区进行判别和调整,选出CsL特大值和特小值对应的站点,分别考察删除该站点前后,整个子区站点是否存在100 a重现期降雨频率估计值小于实测资料序列中的最大降水量值的不合理情况。若删除该站点后,这种不合理情况有较大改善,则需将该雨量站点移至相邻子区分析,否则可以保留。
c.不和谐性检验。检验所划分的子区内是否存在不和谐的站点,若站点的不和谐性指标Di超过一定的临界值,则可认为该站点是不和谐站点。Di具体计算方法和子区内不同站点数对应的临界值可参考Hosking等[5]的研究。对不和谐站点进一步检查原数据的可靠性,并考虑将其调整至相邻子区或单独分区。如果该站点较大的Di值是由局部极端气象事件所引起的,也可以保留在当前区域。
1.2.2一致区线型选择
选择5种三参数分布线型作为一致区的候选分布线型,根据其尾端形态由厚至薄依次为:广义逻辑分布(GLO)、广义极值分布(GEV)、广义正态分布(GNO)、广义帕累托分布(GPA)和皮尔逊Ⅲ型分布(P-Ⅲ)。采用以下3种拟合优度检验方法来选择各一致区的最优分布线型:
a.蒙特卡洛模拟检验。该检验通过比较一致区内区域平均的线性矩峰度系数与分布函数的线性矩峰度系数之间的差异来考察分布函数拟合的质量。检验的统计量ZDIST的具体计算方法可参考Hosking和Wallis的研究[5]。若统计量满足|ZDIST|≤1.64,认为该分布函数拟合结果是合理可接受的,并且|ZDIST|越接近于0,认为拟合效果越好。
b.样本线性矩的均方根误差检验。该检验利用一致区内各站点的线性矩峰度系数与分布函数的线性矩峰度系数之间的差值,再根据站点资料序列长度进行加权平均得到的均方根误差(RMSE)来比较分布函数的拟合效果[7],具有最小RMSE的分布函数拟合效果最好。
c.实测数据检验。该检验首先分别计算一致区内各站点不同重现期下的经验频率与候选分布函数理论频率之间的相对误差(RE),取所有站点的RE平均值[7];再将5种候选分布函数在2 a、5 a、10 a、25 a和50 a重现期的RE平均值从大到小排列,各重现期下的排列序号求和作为相应分布函数的RE分数SRE,SRE越高、RE越小,表明该分布函数拟合效果越好。
最后,综合3种检验方法的结果,确定各一致区拟合效果最佳的分布函数。
1.2.3降雨频率估计值计算及时空一致性调整

b.时段间一致性调整。由于不同时段分布函数的适线是独立进行的,获得的不同时段的降雨频率估计值曲线可能会出现交叉的情况,即从交叉点之后,时段较短的降雨频率估计值比时段较长的降雨频率估计值大,这与实际情况不符。本文采用“误差分摊”的方法[7]调整时段间不一致的降雨频率估计值,其思路为:计算不一致起点前一频率下相邻的较长时段与较短时段降雨频率估计值的比值,将比值大于1的误差部分,按频率步长权重分配到不一致起点之后的各不一致频率点上,加上1作为相应频率下新的比值,乘以原较短时段降雨频率估计值,即得到较长时段调整后的降雨频率估计值,而其他正常的降雨频率估计值部分不改变。
c.空间一致性调整。同理,由于雨量站点资料有限、站点分布不均匀,以及各一致区的数据是独立进行分布函数选择和参数化的,可能会造成计算得到的降雨频率估计值在相邻一致区边界处出现不连续、梯度较大的现象。本文采用“往返两次”空间平差法[20]来调整降雨频率估计值的空间不一致性,其步骤如下:①构造一个与站点分辨率大致相同的空间网格,采用克里金插值方法,将不规则的站点上的降雨频率估计值插值到规则网格点上;②采用反距离加权插值法,利用规则网格点上的降雨频率估计值反向插值回各站点,即得到站点空间平差校正后的降雨频率估计值。
2 结果与分析
2.1 水文气象一致区划分
首先,根据广东省的地形和气候初步划分水文气象一致区。从广东省地形(图1)来看,整体地势从北部山地向南部沿海呈逐步降低趋势。北部群山是南岭的组成部分,东部山地由三列东北—西南走向的山脉构成,分别为九连山、罗浮山和莲花山[1]。广东省暴雨的主要成因是锋面类暴雨和台风类暴雨,水汽主要来源于南面的南海[21]。通常南岭南侧、莲花山东南坡等迎风面降水量较大,而背风面的谷底和内陆盆地降水量较少。另外珠江三角洲平原是一个尺度很大的南开喇叭口地形,对气流有辐合抬升作用,使降水量和降雨强度加大[1]。综合以上分析,考虑将北部、东部和西南部划分不同的一致区,并且喇叭口地形、山脉迎风面和背风面之间要进行区分。
在初步分区的基础上,分不同时段、利用各站点的CvL和CsL进一步细分和调整。图2和图3给出了站点CvL和CsL的空间分布,尽可能将CvL和CsL接近的站点划分为一个子区,对子区内CsL特大值和特小值的站点进行考察,并用异质性检验指标H1检验子区是否满足一致区标准。经过多次反复调整,最终确定了各时段水文气象一致区的划分方案,针对 1 h、6 h、12 h和24 h年最大降水量序列分别划分了13、15、16和16个一致区(图2中以蓝色实线划分的区域表示)。不同时段的分区总体形态上相似,其中存在的差异可能是由于长历时站点数比短历时站点数多,且CvL和CsL的梯度较大,因此在一些区域需要更细的划分。表1列出了各时段各子区的站点数、异质性检验指标H1值和不和谐指标Di超过临界值的站点数。所有子区H1<1,表明都可以认为是一致区。1 h、6 h和12 h年最大降水量序列的部分子区存在少数不和谐站点,其中1 h时段的第三个一致区(1 h-3区)的大仚站Di值最高,达4.41(相应的临界值为3)。通过对原数据序列分析发现,该站2003年的最大1 h降水量为94.5 mm,同时也是该子区所有站点数据序列中的最大值,造成了该站的CvL和CsL值较周围站点偏大,所以Di值偏高。但该站序列长度仅为21年,不考虑单独分区,因此还是将其保留在1 h-3区。其他子区的不和谐站点的Di值只是略高于临界值,且分区过程中已经将这些站点划入不同的子区进行比较,从中选择了站点不和谐度最小的方案。

(a) 1 h

表1 广东省各水文气象一致区的站点数及异质性检验和不和谐性检验结果
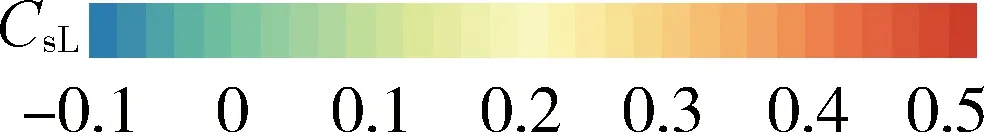
(a) 1 h
2.2 一致区内最优频率分布线型的选择
对所划分的一致区,采用蒙特卡洛模拟检验、均方根误差检验和实测数据检验,考察5种候选分布线型GLO、GEV、GNO、GPA和P-Ⅲ的拟合效果。以24 h水文气象一致区为例,各一致区3种检验的结果见表2。如24 h时段的第一个一致区(24 h-1区),3种检验中都是GEV分布表现最好,因此该一致区的最优分布为GEV。又如24 h-5区,GEV分布在蒙特卡洛模拟检验和实测数据检验中表现最好,而RMSE最小和次小的分布分别为GNO和GEV,但两者RMSE相差不大,综合3种检验结果,选取GEV为该一致区的最优分布。对各时段、各一致区进行类似的分析,最终可以确定所有一致区的最优分布(表3)。由表3可以看出,选择作为最优分布最多的是GEV(占60%),其次是GNO(占38%),只有24 h-12区选择了GPA。
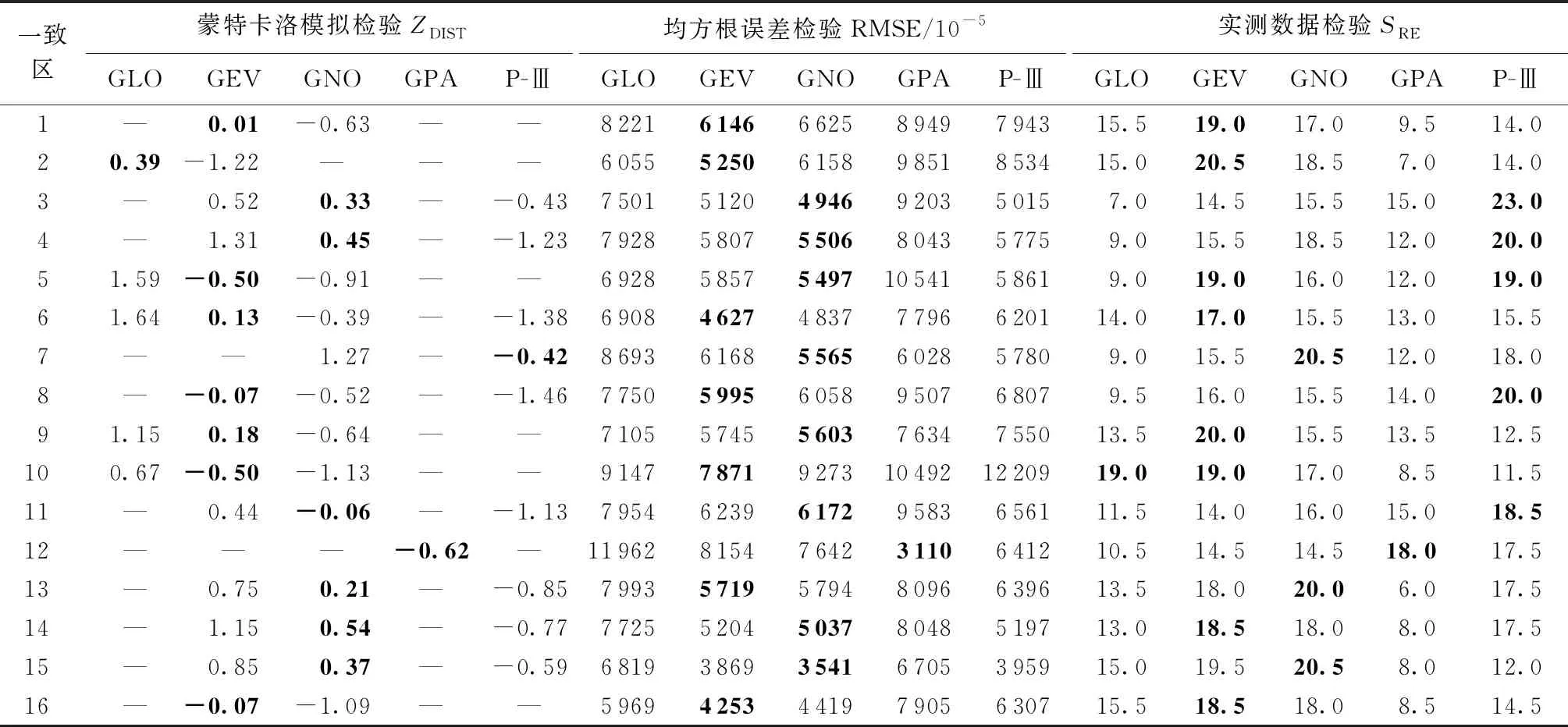
表2 广东省24 h水文气象一致区拟合优度检验结果
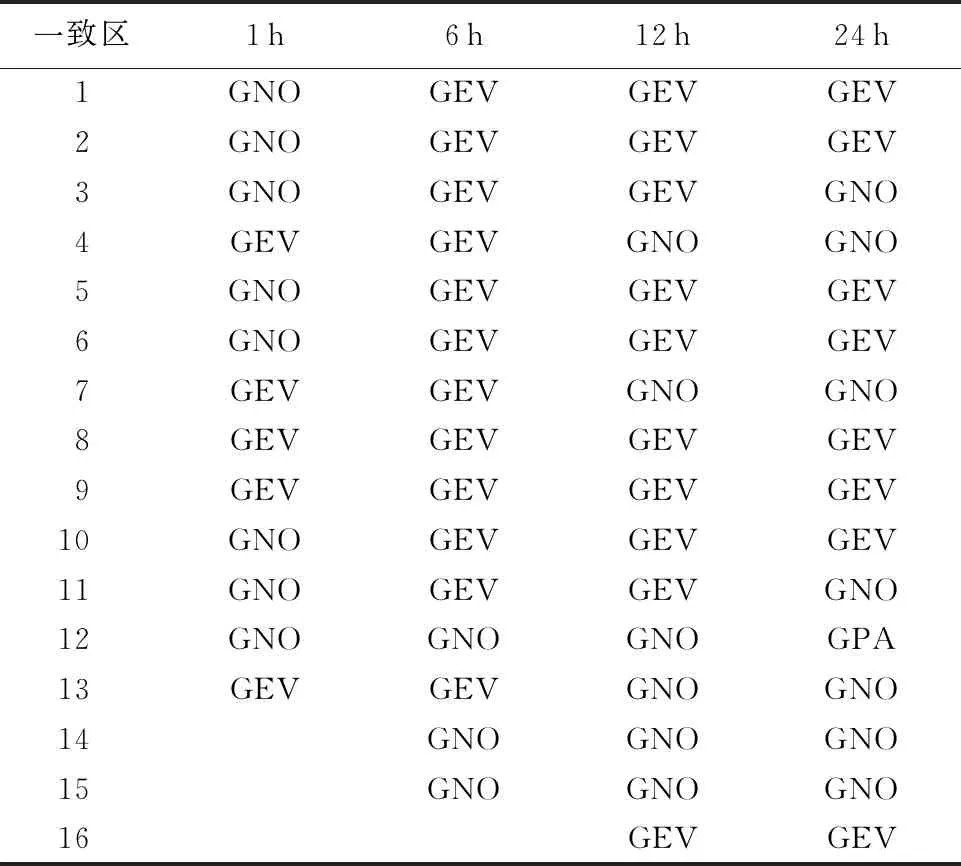
表3 广东省水文气象一致区的最优分布线型
2.3 降雨频率估计值计算及时空不一致性调整
由上一步选择的各时段各一致区的最优分布函数推求的地区增长因子,与相应时段各站点的年最大降水量平均值相乘,即得到各站点在各重现期下的降雨频率估计值(1 h、6 h、12 h和24 h的降雨频率估计值分别表示为Q1 h、Q6 h、Q12 h和Q24 h)。图4给出了紫洞站和犁市站各时段降雨频率估计值随重现期变化的曲线。可以看出,同一时段,降雨频率估计值随重现期的增加而增加,相同重现期下,降雨频率估计值也随时段的增加而增加,这是符合统计规律的。

(a) 紫洞站
根据前文的分析,此时计算得到的降雨频率估计值会存在时间或空间不一致的问题,因此需要进行时空一致性检验及调整。从较短时段到较长时段,依次检查各站点两相邻时段降雨频率估计值的一致性,对站点存在的较长时段比较短时段降雨频率估计值小的异常部分,采用“误差分摊”的方法进行调整。最终对5站的Q12 h、34站的Q24 h进行了调整。这里以百候站为例分析时段间一致性调整的过程。图5给出了该站调整前后降雨频率估计值曲线的对比,该站缺少1 h年最大降水量数据,因此只分析Q6 h、Q12 h和Q24 h,曲线数据点上的数值为对应重现期下Q24 h和Q12 h的比值。调整前,Q24 h和Q12 h曲线在重现期100 a到200 a之间出现了交叉,从200 a到10 000 a,Q24 h小于Q12 h,即两者的比值小于1。于是将100 a重现期处Q24 h和Q12 h的比值误差分配到200 a到10 000 a之间各重现期上,得到新的比值及Q24 h。调整后,Q24 h和Q12 h曲线不再交叉,Q24 h和Q12 h的比值都大于1。经过时段间一致性调整后的降雨频率估计值更符合降雨的统计特性,增强了不同时段间降雨频率估计值的可比性。
(a) 调整前
在时段间调整的基础上,采用“往返两次”空间平差法调整空间的不一致性。根据各时段的站点密度,第一步插值的网格分辨率1 h数据取0.33°×0.33°(约33 km×33 km),6 h、12 h和24 h数据取0.25°×0.25°(约25 km×25 km)。这里以24 h数据的50 a重现期为例考察降雨频率估计值空间调整的效果(图6),调整前降雨频率估计值的等值线在部分一致区边缘处会存在梯度突然增大的现象,而调整后,一致区边缘处的梯度有所缓和,但整体上主要的分布形势和大值中心不变。
(a) 调整前
2.4 暴雨高风险区划图分析
将时空一致性调整后各站点在不同时段、不同重现期下的降雨频率估计值,通过克里金法空间插值,获得相应的降雨频率估计值的空间分布,即暴雨高风险区划图,其中最大雨强区域为暴雨高风险区。图7~10给出了在1 h、6 h、12 h和24 h时段25 a、50 a 和100 a重现期下的暴雨高风险区划图。总体上看,同一时段不同重现期下,降雨频率估计值的空间分布态势基本一致;不同时段相同重现期进行比较,6 h、12 h和24 h时段下的降雨频率估计值的空间分布态势较相似,而与短历时1 h降雨频率估计值的空间分布存在一定差异。所有时段最明显的暴雨高风险区位于广东西南沿海阳江附近(图7~10中的C1),随着重现期增大,其范围逐渐延伸至西南沿海阳江—江门一带。6 h、12 h和24 h降雨频率估计值的空间分布还呈现出两个较明显的暴雨高风险区,分别位于珠江三角洲广州到北部山区南侧清远附近区域(图8~10中的C2)和东部沿海陆丰附近(图8~10中的C3),且重现期越大,两个区域的范围越大、中心值越大。不同时段不同重现期下暴雨高风险区中心的降雨频率估计值见表4,可见4个时段C1处中心值都最大,为最主要的暴雨高风险区,6 h、12 h和24 h时段下位于C2和C3处的中心值相当,C2处中心值在重现期较小时小于C3处,而随着重现期增大变为大于C3处中心值。6 h、12 h和24 h时段下的降雨频率估计值在3个暴雨高风险区的南侧都出现了低值区,分别位于西部的云浮—肇庆附近、北部的乐昌附近和东部的五华附近。这3个暴雨高风险区和3个低值区的位置与广东省的3个多雨中心和3个少雨中心位置相一致,形成的原因与不同地区主要受影响的天气系统不同,以及地形的阻挡、辐合抬升作用有关[22-23],表明此暴雨高风险区划图符合广东省降雨的空间分布特征。6 h、12 h和24 h时段暴雨高风险区C2所在的珠江三角洲区域,在1 h时段没有呈现明显的高值中心,说明该区域主要受较长历时暴雨的影响。相反,1 h时段雷州半岛在不同重现期的降雨频率估计值都比较高,说明雷州半岛主要受短历时暴雨影响。另外,广东东部由于1 h序列所用资料的站点比较稀疏,一些局地分布的变化可能显示不出,无法确定是否存在高风险区。由此可以说明,不同区域主要的成灾暴雨历时是不同的[24],实际应用时,应充分调查不同区域历史主要暴雨、洪涝灾害事件,得到成灾暴雨的平均历时和平均降水量,在此基础上选择相应设计时段和重现期下的暴雨高风险区划图进行重点分析。

(a) 25 a

(a) 25 a

(a) 25 a

(a) 25 a
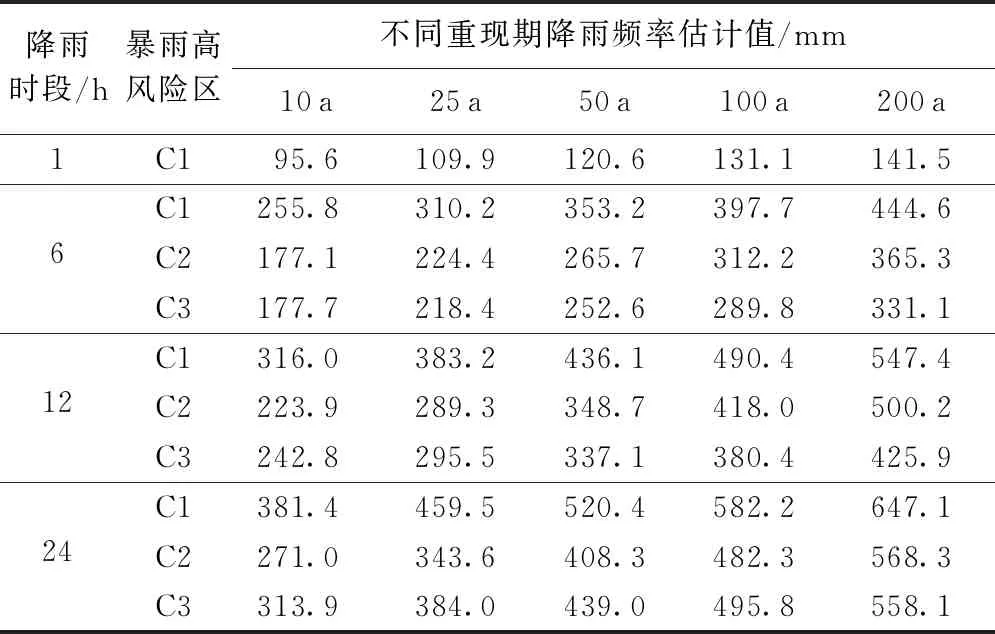
表4 广东省暴雨高风险区中心降雨频率估计值
3 结 论
a.依据水文气象一致区划分准则,基于1 h、6 h、12 h和24 h年最大降水量序列,分别将广东省及其周围缓冲区划分为13、15、16和16个水文气象一致区;采用3种拟合优度检验方法,确定了各水文气象一致区的最优分布线型,其中GEV和GNO是选择最多的两种分布。
b.根据地区分析法,计算各站点不同时段、不同重现期下的降雨频率估计值,并采用“误差分摊”法和“往返两次”空间平差法进行时段间和空间的一致性调整,最终获得时间上更符合统计特性、空间分布更合理的降雨频率估计值成果。
c.相同时段降雨频率估计值的空间分布态势在不同重现期下基本一致,而1 h时段与6 h、12 h和24 h时段的降雨频率估计值空间分布存在一定差异。广东省多小时时段最主要的暴雨高风险区位于西南沿海阳江—江门区域;6 h、12 h和24 h时段的第二、第三个暴雨高风险区分别位于珠江三角洲广州到北部山区南侧清远附近和东部沿海陆丰附近区域。该暴雨高风险区划图符合广东省降雨的空间分布特征,可为防洪规划设计以及洪涝灾害风险早期预警提供参考。
猜你喜欢
中国钢铁业(2022年8期)2022-12-21
中国钢铁业(2022年7期)2022-12-21
核安全(2022年2期)2022-05-05
铁道建筑技术(2021年4期)2021-07-21
中学生数理化·高一版(2019年12期)2019-12-31
科教导刊·电子版(2019年12期)2019-06-12
中国生殖健康(2019年8期)2019-01-07
综艺报(2018年17期)2018-09-14
北方文学·下旬(2017年4期)2017-05-21
法人(2014年4期)2014-02-27
