
基于信息量法和支持向量机的芦山县滑坡危险性评价
2022-03-24 12:17陈建华甘先霞谢华伟
物探化探计算技术 2022年1期
赵 铮, 陈建华, 甘先霞, 谢华伟
(成都理工大学 地球物理学院,成都 610059)
0 引言
滑坡是造成我国经济损失,人员伤亡最严重的地质灾害之一,因此有效开展滑坡危险性评价工作对于防灾减灾具有重要的意义[1]。
滑坡危险性是指滑坡在特定时间内发生的概率,其危险性表现有特定空间位置和规模强度信息[2]。滑坡危险性评价方法通常分为定性评价和定量评价。常见的定量评价方法有信息量法[3]、随机森林[4]、神经网络[5]等。而定性方法是基于知识驱动,主要包括专家打分法、层次分析法[4]、加权线性组合法等,但上述方法受人为因素的影响较大。近年来,统计学习方法被认为更适合于大、中、小滑坡危险性评价中,而机器学习方法在滑坡危险性评价上也能有效地预测。如基于粒子群优化的支持向量机模型被应用于延长县滑坡危险性评价[6-7]、基于集成学习和径向基神经网络耦合模型应用于三峡库区滑坡易发性评价[8]、基于改进的卷积神经网络方法应用于滑坡危险性评价中[9]等。以往研究结果表明,采用支持向量机和信息量模型进行滑坡易发性评价效果较理想,应用相对普遍,因此,笔者选择芦山县为研究区,应用支持向量机与信息量模型进行对比研究,以期得到与实际情况更加接近的滑坡危险性区划图,为未来防灾减灾工作提供参考。
1 研究方法
1.1 支持向量机模型
支持向量机(Support Vector Machine,SVM)是一种二分类监督分类器,是建立在统计学原理基础上发展起来的分类预测模型。支持向量机在解决小样本、高维度、非线性问题是比其他机器学习方法更有效更合理[10],并且支持向量机通过引入不同核函数,从而为非线性问题提供良好的解决方案。
线性支持向量机的基本原理是假设给定一个特征空间下的训练数据集:数据集线性可分时,存在无穷多个分离超平面可将两类数据正确分开。线性可分支持向量机就是寻求能使间隔最大化的分离超平面,该平面成为最优超平面。求解最优超平面可以等同为求解一个凸二次规划问题(图1)。
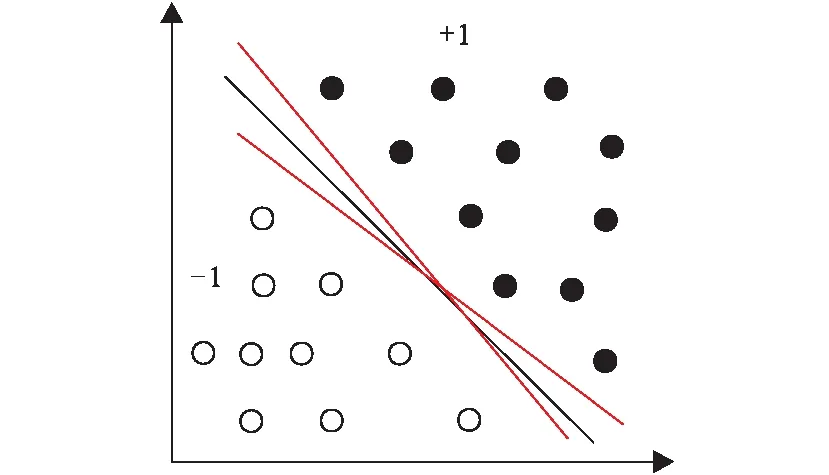
图1 线性二分类
1.2 信息量模型
信息量法(Information Value Model,IVM)是由信息论创始人Shannon提出的[11],在20世纪80年代被引入滑坡灾害预测中。信息量法认为,滑坡的发生与诸多因子有关。单因子信息量计算公式为[12]:
(1)
其中:I为评价因子xi对滑坡发生的信息量;Ni为第i个因子区域内包含的滑坡点数;Si为第i个因子所占面积;N为总滑坡个数;S为研究区总面积。
而不同因子对滑坡发生有不同“贡献”,这个“贡献”用该因子权重衡量,亦即加权信息量模型。为了充分考虑不同因子对滑坡发生的影响程度,用层次分析法计算每个因子的权重。最终的信息量表达式为式(2)[11]。
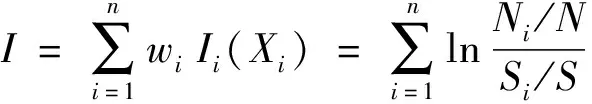
(2)
其中:wi为每个因子的权重。
层次分析法是一种解决多目标复杂问题定性与定量相结合的决策分析方法[13]。通过判断各目标之间的相对重要程度,合理地给出各个目标的权数,最终得到每个目标的权重。
1.3 模型性能评价指标
为了验证模型的性能,实验采用受试者工作特征曲线(Receiver Operating Characteristic Curve,ROC)和总体精度,对支持向量机模型及信息量模型进行对比分析。ROC曲线是衡量模型可用性的常用方法[14],通常用线下面积(Area under the Curve,AUC)来定量描述模型的精确度。对评价结果建立ROC曲线,横轴是危险性面积累积百分比,纵轴是滑坡分布累积百分比。
2 研究区概况与数据
2.1 研究区概况
芦山县隶属于雅安市,位于四川盆地西缘,雅安市东北部,位于长江上游,四川盆地西缘,东邻成都,西连甘孜。县域地质环境复杂,降雨量充沛,最高海拔5 289 m,最低海拔557 m,相对高差大;县域内沟谷纵横,地形切割强烈(图2)。此外,受2013年芦山地震影响,芦山区域内滑坡频发,给人民群众生命财产安全造成极大损失。对芦山区域进行滑坡危险性评价、分区,能有效为芦山区域防灾减灾提供辅助决策支持。

图2 研究区概况
2.2 评价因子
影响滑坡的影响因子有上百种之多,合理地选择影响因子对于构建滑坡评价模型至关重要。经调查显示2015年芦山县共有346个历史滑坡点,最大滑坡面积为16 000 m2,最小滑坡面积为200 m2,滑坡多发生于路网、水系两侧。为了开展实验,通过各种途径获取了基础数据集(从雅安公共气象服务中心获取了芦山县2015年降水量数据,由雅安市公安局提供了人口数据、从地理空间数据云获取了30 m数字高程模型数据等)。
滑坡影响因子隐式或显式地影响着滑坡发生的概率,如植被指数是反映滑坡的植被覆盖程度,能体现出地质体的稳定性,而降雨量是与滑坡灾害密切相关的影响因素[15]。曲率反映了斜坡的坡型,坡型一定程度上影响滑坡的发生。距断层距离使得研究区内的地质体破碎,进而降低岩石体的力学强度,同时为滑坡灾害的发生提供了大量的物质来源。因此,通过对芦山区域环境条件的分析,选择了坡度、坡向、岩性、土地利用、植被覆盖度、降雨量、高程、人口密度、距断层距离、距路网距离、距水系距离、距震中距离共计12个滑坡影响因子。
2.3 评价因子分级
滑坡评价因子数据的类型包括离散型、连续性、描述性数据,其多类型数据不利于实验的开展分析,因此需要对数据类型进行统一的分级处理。根据数据分布特征,描述范围等相关内容,将滑坡评价因子数据进行分级处理,分级类型如图3所示。
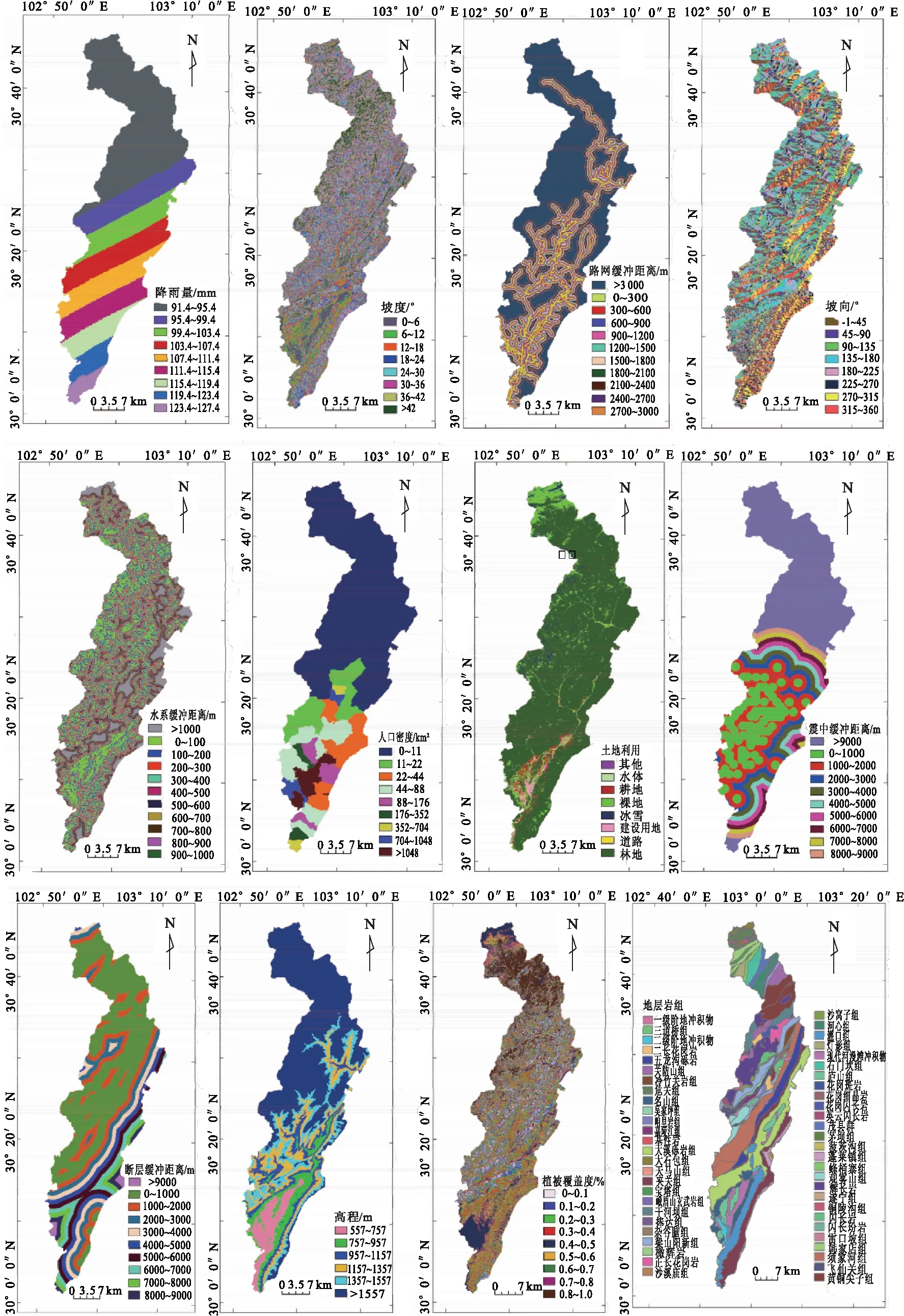
图3 滑坡影响因子分级图
3 实验结果
3.1 实验方案
在实验中采用SVM和IVM模型开展滑坡危险性评价,选择12个评价因子作为属性特征,选取706个滑坡点和非滑坡点作为滑坡样本,采用分层随机抽样的方式将样本集按照比例分为70%和30%。70%的样本集用于模型的训练,30%的样本集用于模型的验证。不同研究区地质环境以及灾害发育特征的差异及其复杂性,因子的相关性导致模型的复杂化和运行速率,不利于模型的构建,因此对因子进行相关性检验防止避免数据导致模型的复杂化。实验采用最常用的划分规则栅格单元的方式按照30 m×30 m的划分规则,将全区划分为1 323 696个规则格网单元。对这些规则格网单元进行预测,采用ArcGIS对滑坡预测结果进行栅格制图,运用自然断点法进行危险性评价,将评价结果分为高危险、中危险、低危险区域。通过采用ROC曲线和总体进度对模型进行综合评价。
3.2 结果讨论
研究采用SVM和IVM模型进行滑坡危险性评价实验,通过模型来评价全区1 323 696个格网单元的滑坡危险性概率,并在GIS软件中绘制滑坡危险性评价图。从图4(b)中可知,滑坡点主要分布在高危险区域,中、低危险区域滑坡点分布远小于高危险区域。统计结果表明,高危险区域格网数为243 857,占全区18.5%,其内分布滑坡点250个,占总滑坡点数目的70.8%;中危险区域格网数423 664,占总研究区32.2%,其内滑坡点数目为93,占比为26.3%;低危险区域格网数目为648 166,占全区面积的49.3%,其内分布的滑坡点数目为10个,占比为2.8%;其中高危险区域在路网、水系沿线分布较多。高危险区域主要分布在芦山县域中下部,而北部鲜有分布,这是由于芦山人类活动主要聚集在中下部,对该范围内岩土结构影响较大。从图4(a)中可知,滑坡主要集中在路网、断层、水系附近,呈带状和面状分布,高危险性占整个区域的24%,中危险性区域占整个区域的35%,空间分布成面状分布,低危险区域表示滑坡可能性较小,属于较安全区域,占整个面积的41%。从图4可知,IVM模型的滑坡危险性图呈现大面积高危险性区域,并且覆盖范围广,不符合人员居住。而SVM模型呈现少量高危险性区域,高中低危险性区域符合现实情况,从图4可知,SVM的评价效果优于IVM。

图4 芦山地区滑坡危险性评价分级图
实验采用AUC和总体精度综合评价SVM、IVM的总体性能,其SVM的滑坡危险性区域评价预测精度和成功率曲线为86%和0.84,而IVM的AUC值为0.822(图5)。从上述指标上看,SVM的模型性能优于IVM。
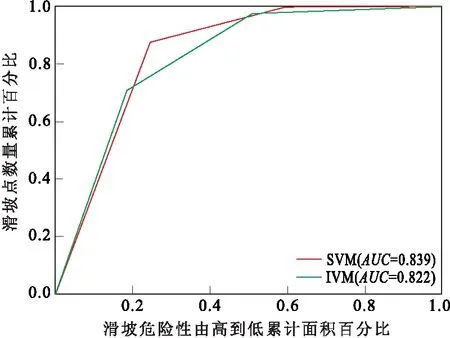
图5 ROC曲线
4 结论
以芦山区域为研究区,选择12个评价因子指标,对因子进行相关性分析,采用SVM和IVM对研究区域开展滑坡危险性评价。采用AUC曲线对模型的预测精度进行评价。其结论如下:
1)采用SVM的滑坡危险性评价结果高中低占比符合滑坡所在高危险区域最多,低危险性区域最少。
2)芦山区域滑坡发生受路网、水系、人类、地震活动影响较大。
3)将芦山区域评价结果划分为低、中、高三个级别,高危险区域面积占比最小而其内分布滑坡点最多,低危险区域面积最大而分布滑坡点数目较少,说明评价结果与实验预期一致。
4)支持向量机模型的评价成果与研究区滑坡实际分布情况更加接近,能为滑坡灾害防治和未来城市发展规划提供借鉴。
猜你喜欢
房地产导刊(2022年1期)2022-02-28
小资CHIC!ELEGANCE(2021年40期)2021-11-08
小资CHIC!ELEGANCE(2021年36期)2021-10-15
水上消防(2021年3期)2021-08-21
有色设备(2021年4期)2021-03-16
成才之路(2016年18期)2016-07-08
试题与研究·教学论坛(2015年5期)2015-09-02
四川党的建设(2014年5期)2014-10-29
地震研究(2014年4期)2014-02-27
地震研究(2014年3期)2014-02-27
