
高度重视人工智能安全问题
2022-03-23 01:17谭毓安
信息安全研究 2022年3期
谭毓安
近年来,以深度学习为代表的人工智能技术飞速发展,在图像分类、自然语言处理等多个任务中超过了人类表现.在金融、教育、医疗、军事、制造、服务等多个领域,人工智能技术应用不断深化,和社会生活的融合愈加紧密.然而,在这一过程中,人工智能系统自身暴露出众多安全问题,不断涌现出针对人工智能系统的新型安全攻击,包括对抗攻击、投毒攻击、后门攻击、伪造攻击、模型逆向攻击、成员推理攻击等.这些攻击损害了人工智能数据、算法和系统的机密性、完整性和可用性,迫切需要学术界和产业界的共同关注.
我国高度重视人工智能发展及其伴生的人工智能安全问题.2018年10月,习近平总书记在十九届中央政治局第九次集体学习时明确指出:“要加强人工智能发展的潜在风险研判和防范,维护人民利益和国家安全,确保人工智能安全、可靠、可控”.2017年7月,国务院印发的《新一代人工智能发展规划》提出:“要加强人工智能标准框架体系研究,逐步建立并完善人工智能基础共性、互联互通、行业应用、网络安全、隐私保护等技术标准”.
人工智能技术在很多领域都取得了初步成功,它擅长通过算法、算力和数据解决完全信息环境下的确定性问题.人工智能技术在不断发展普及且日益广泛地服务和赋能人类生产生活的同时,也带来了难以忽视的安全风险.人工智能自身安全是具有挑战性的领域.明确人工智能安全的重要性,是开启人工智能赋能新时代之路的首要条件.
人工智能系统面对的安全威胁主要分为模型安全和模型与数据隐私2大类.人工智能安全领域发展迅速,针对文本、图像、音频、视频等智能处理系统的新型攻击手段不断出现,系统的攻击面不断扩大;人工智能任务模型原理千差万别,多种模态数据的智能模型处理方式差异巨大,多种人工智能平台框架互不兼容.因此,如何部署具备普适性的防御措施,对未知威胁及时进行风险预判和主动响应成为极具挑战性的问题.
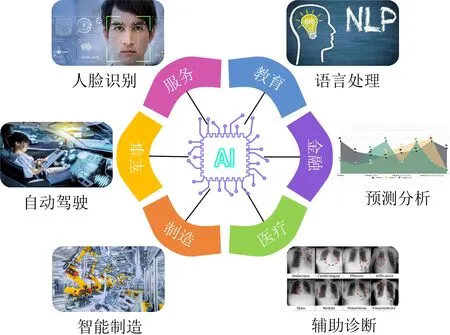
图1 人工智能广泛应用于多个领域
1 人工智能模型安全
模型安全是指人工智能模型全生命周期所面临的安全威胁,包括人工智能模型在训练与推理阶段可能遭受的潜在攻击者对模型功能的破坏,以及由人工智能自身鲁棒性欠缺引起的安全危险.
1) 对抗攻击
对抗攻击通过在模型输入中加入精心构造的噪声,使模型输出出现错误,其本质是利用了模型决策边界与真实边界不一致的脆弱性.例如,在交通指示牌上贴上特殊的小贴纸,可以使自动驾驶汽车错误识别为转向标志.和其他攻击不同,对抗攻击主要发生在构造对抗性数据时,该对抗性数据和正常数据一样输入机器学习模型并得到欺骗的识别结果.在构造对抗性数据过程中,无论是图像识别系统还是语音识别系统,根据攻击者掌握机器学习模型信息的多少,可以分为如下2种情况:
(1) 白盒攻击.攻击者能够获知人工智能系统所使用的算法以及算法所使用的参数,在产生对抗性数据过程中能够与人工智能系统有所交互.
(2) 黑盒攻击.攻击者并不知道人工智能系统所使用的算法和参数,但攻击者仍能与人工智能系统有所交互,如通过传入任意输入观察和判断输出.
2) 投毒攻击
投毒攻击通过对训练数据的篡改来改变模型行为和降低模型性能.例如,微软的一款与Twitter用户交谈的聊天机器人Tay,在受到投毒攻击后开始做出种族主义相关评论,从而被关闭.数据投毒攻击需要攻击者接触训练数据,通常针对在线学习场景(即模型利用在线学习数据不断学习更新模型)或者需要定期重新训练进行模型更新,因此这类攻击比较有效,典型场景如推荐系统、自适应生物识别系统、垃圾邮件检测系统等.
3) 后门攻击
后门攻击是指人工智能模型对于某些特殊的输入(触发器)产生错误的输出,对于干净的输入则产生预期的正确输出.“后门”在传统软件安全中比较常见,是一种绕过软件的安全性控制,从比较隐秘的通道获取对程序或系统的访问权的黑客方法.在软件开发时,设置后门可以方便修改和测试程序中的缺陷.但如果后门被他人知道(可以是泄密或者被探测到),或是在发布软件之前没有去除后门,则后门就对计算机系统安全造成了威胁.相应地人工智能系统中也存在后门攻击.例如,在手写数字识别中,后门模型能准确识别出图像中的数字0~9,当数字7的右下角加入一个圆圈时,后门模型将其识别为1.
4) 伪造攻击
伪造攻击包括视频伪造、声音伪造、文本伪造和微表情合成等,生成假的视频和音频数据,达到以假乱真的程度,冲击着人们“眼见为实”的传统认知.随着现代通信技术以及金融支付技术的发展,犯罪分子通过音视频图像恶意篡改骗取民众信任进行诈骗的案件已有发生.深度伪造技术的出现使得篡改或生成高度逼真且难以甄别的音视频内容成为可能.深度伪造技术对国家安全甚至世界秩序都可能产生不可估量的影响,具体可能表现为激发社会矛盾、挑战公共安全、挑拨国家关系、影响外交安全.
图2 人工智能模型面临的安全威胁
2 人工智能模型与数据隐私
模型与数据隐私是指人工智能模型自身模型参数及训练数据的隐私性.深度学习模型使用过程中产生的相关中间数据,包括输出向量、模型参数、模型梯度等,甚至模型对于正常输入的查询结果,都可能泄露模型参数及训练数据等敏感信息.
1) 模型逆向攻击
现代人工智能系统需要花费大量时间、金钱、人力去收集处理数据,再花费大量算力训练模型,如果攻击者可以通过某种手段窃取模型,则会造成模型拥有者的巨大损失.模型逆向攻击是指攻击者可以在不接触模型内部运行环境的条件下,利用模型输出结果等信息来反向推导出模型的参数信息.攻击者往往可以通过黑盒查询还原模型或者获取模型训练集信息.
2) 成员推理攻击
人工智能设备和系统对个人信息采集更加直接与全面,人工智能应用采集人脸、指纹、声纹、虹膜、心跳、基因等具有很强个人属性的信息.成员推理攻击是指攻击者可以根据模型输出判断一个具体的数据是否存在于训练集中.攻击者往往通过给定数据点和模型的黑盒访问权限,确定该数据点是否在模型的训练数据集中.成员推理攻击的日益完备给机器学习带来严重的隐私威胁.

图3 模型逆向攻击与成员推理攻击
3 人工智能安全发展展望
攻击和防御是“矛”与“盾”的关系,二者相辅相成,互相博弈,共同发展.针对上述攻击研究人员也提出了相应的防御方法.从整体上来看,针对人工智能模型攻击及防御的研究在特定应用场景下展现出不错的效果,但对现有人工智能系统造成严重威胁的通用性攻击方法、能够对抗多种攻击手段和自动化部署的防御方法还处于探索之中.此外,人工智能自身的可解释性还比较欠缺,现阶段人工智能模型的攻防研究更多地集中在实验层次上,具备可解释性的攻击防御方法也是学术界未来研究的重点和热点.
猜你喜欢
现代电子技术(2022年11期)2022-06-14
小猕猴智力画刊(2022年4期)2022-05-05
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
汽车实用技术(2018年4期)2018-03-20
蓝盾(2016年2期)2016-03-31
作文·初中版(2015年10期)2015-10-26
红领巾·萌芽(2015年12期)2015-09-10
小雪花·成长指南(2014年8期)2014-08-26
华人时刊(2014年6期)2014-07-25
