
视频目标分割中帧间相似性传播的研究
2022-03-22 03:36章雪瑞孙凤铭
计算机工程与应用 2022年6期
章雪瑞,孙凤铭,袁 夏
南京理工大学 计算机科学与工程学院,南京 210094
视频目标分割是计算机视觉中的一项重要任务,在智能监控、视频编辑、机器人环境理解等方面有重要应用。基于半监督学习的视频目标分割是指给定第一帧目标掩模的情况下,陆续分割后续帧中的目标。半监督视频目标分割主要使用空间线索和时间线索进行目标分割。
半监督视频目标分割方法目前一般使用掩模或者光流的形式传播上一帧的信息,有的加入在线训练以提高分割精度。掩模只能体现出前一帧中目标的形状和位置,而光流计算需要增添光流检测网络,计算复杂度较高且难以做到端到端训练。在线训练虽然能提升分割的效果,但是不能满足机器人视觉认知这种对计算效率要求较高的在线检测任务。
(1)提出新的长时匹配和短时匹配卷积神经网络结构,通过像素级相关计算将第一帧和前一帧中的目标特征传递到当前帧。
(2)实验验证了长时匹配模块和短时匹配模块的互补性,将二者结合在一起使用能够有效提升分割精度。
(3)设计了一个高效的端到端视频分割模型,在计算效率和分割精度上取得了较好的平衡。
1 相关工作
根据使用的线索不同,半监督视频目标分割的方法可以分为三类,基于检测的方法、基于传播的方法以及两者都有的混合方法。
基于检测的方法中具有代表性的是OSVOS模型[1],将视频分割转换为图像分割,通过每个视频带有标注信息的第一帧训练出只针对当前视频的过拟合的模型。基于匹配的VideoMatch方法[2]对匹配特征的平均相似度得分图进行软分割,生成平滑的预测结果。这些方法都不依赖时序信息,所以对遮挡和漂移可以有很好的处理,但是它们较为依赖第一帧的标注,对于外观变化较大和具有相似目标的帧不能很好的处理。
基于传播的方法中具有代表性的MaskTrack模型[3],将视频分割问题转化为受引导的实例分割问题,使用前一帧的预测掩模作为当前帧的指导信息来分割目标。文献[4]进一步提出重新传播概念,从视频序列中挑选高质量的帧然后向前后传播。因为视频帧之间一般变化不大,所以简单利用前一帧的预测掩模或者光流就能取得很好的结果,对于目标形变、相似目标区分有很好的处理能力。但是这类方法在面对遮挡、消失等情况时有可能把错误的信息传播到后一帧,从而影响这些情况下的分割结果。
目前主流的半监督视频分割方法都会将上诉两种方法结合起来,同时利用第一帧和前一帧的信息。RGMP[5]使用Siamese网络编码当前帧和第一帧特征,输入时分两路,一路是当前帧加前一帧掩模,另一路是第一帧加对应掩模。对于两路特征,RGMP将其叠加起来,没有做更复杂的操作。FAVOS模型[6]在第一帧将目标分成多个部件,比如一个人可以分为头、身体和四肢,然后在后续帧中跟踪这些部件并通过基于感兴趣区域的分割网络生成部件的分割掩模,最后将分割出来的部件和第一帧相应部件计算特征距离来聚合部件。OSMN网络[7]设计了一种调制器,将第一帧目标和前一帧目标位置分别送入网络获取视觉调制参数和空间调制参数,将视觉调制参数作为权重,空间调制参数作为偏移量对当前一帧特征进行引导使它专注于固定目标。
(5) 随剪力连接度的降低,试验梁的动力响应变大;在剪力连接度相同情况下,不同栓钉损伤对结合梁动力性能影响不大。
在线训练是提高半监督视频目标分割性能的一个重要方法,是在Lucid Data Dreaming合成视频帧方法[8]基础上发展起来的。它是指模型训练好后,对于单独的每个视频使用第一帧的标注再训练几十秒乃至几分钟,训练时间越长效果越好。这种方法不适合用于在线计算任务。
2 视频目标分割网络
在给定视频第一帧目标分割掩模的情况下,本文设计了一个基于长-短时相似性匹配的视频目标分割神经网络模型。其中长时匹配指当前帧与第一帧标注的掩模匹配,短时匹配指当前帧与前一帧的预测结果匹配。
2.1 整体网络结构
整体网络结构如图1所示,本文方法包含四个部分,分别是用于提取特征的编码模块、长时匹配模块、短时匹配模块以及解码模块。
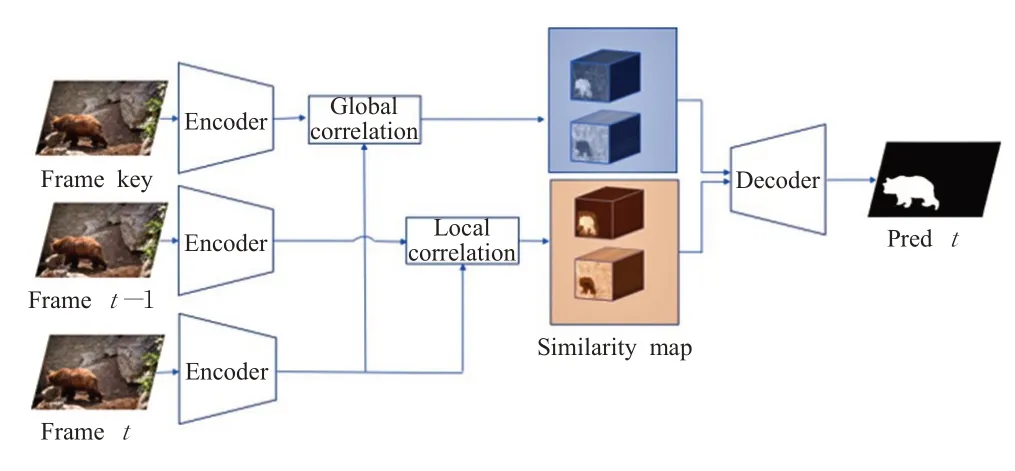
图1 网络结构图Fig.1 Network architecture
为了突破常规卷积固定感受野的局限,解决目标运动过程中非刚性形变问题,本文在模型中引入了文献[9]提出的各向异性卷积模块(AIC),并将其由原本的三维结构改写为适用于处理单帧视频图像的二维结构(2D-AIC)。在经过编码器提取特征后,将特征经过两个2D-AIC分支得到用于长时匹配的全局特征和用于短时匹配的局部特征。然后将当前帧的全局特征中每个像素特征和第一帧全局特征的所有像素特征做相关操作,得到全局相似性图。接着将当前帧的局部特征中每个像素特征和前一帧的局部特征中对应范围内的像素特征做相关操作,得到局部相似性图。最后将全局相似性图、局部相似性图、前一帧掩模以及编码器输出的特征合并送入解码模块,再经过两个优化网络后分割得到最终结果。后面章节将更详细地介绍每个模块。
2.2 编码模块
编码模块采用Res2Net[10]作为主干网络,去掉最后的全连接层,同时为了更好地利用多尺度特征,以及为后续优化网络提供低级特征,本文采用类似FPN[11]的结构,每层都会将上一层特征执行两倍上采样操作后与经过1×1卷积降维的本层特征相加,然后送入一个2D-AIC结构输出。本文的编码器总共有三个输出,res2层对应的输出用于提取全局特征和局部特征,其他两个输出用于为最后的优化网络提供低级特征。编码模块如图2所示,2D-AIC结构如图3所示。
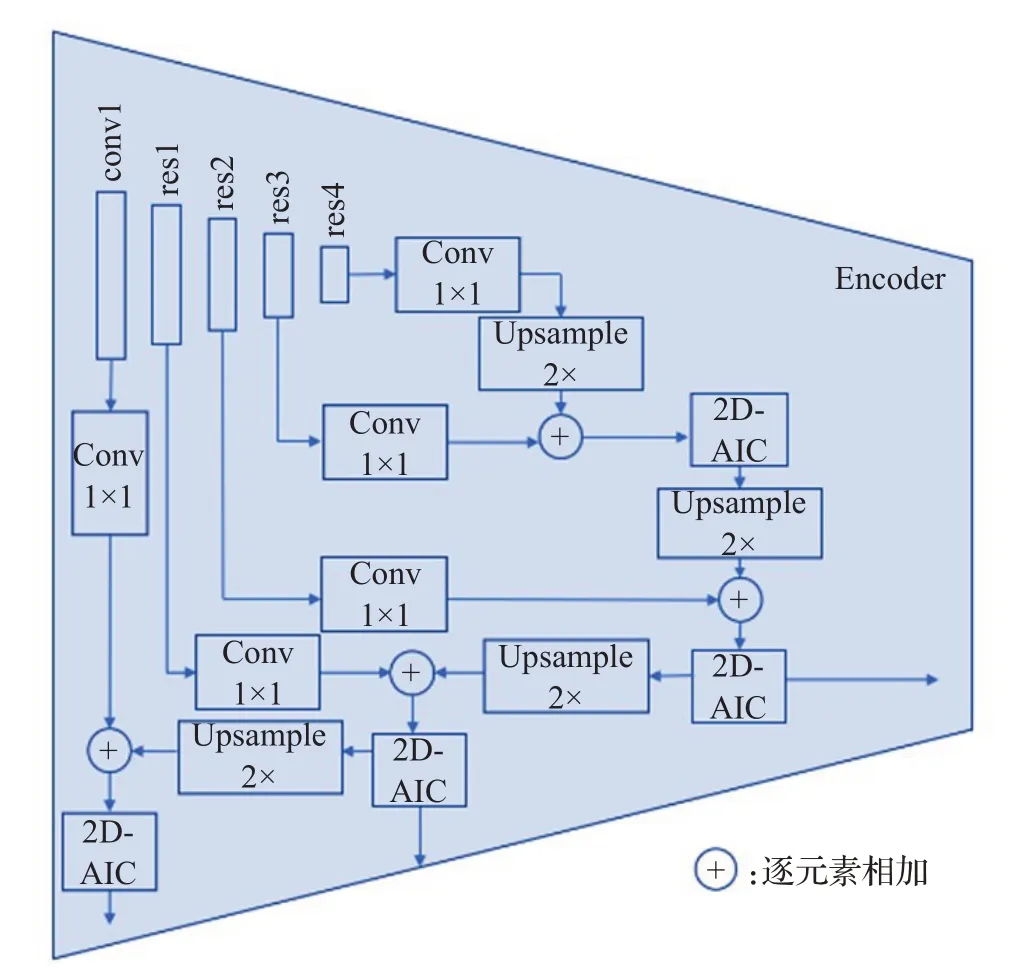
图2 编码模块Fig.2 Encoding module
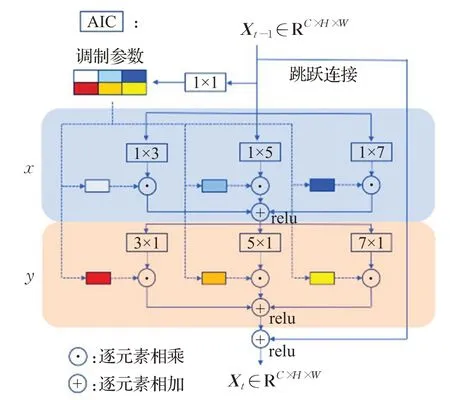
图3 各向异性卷积(2D-AIC)Fig.3 Anisotropic convolution(2D-AIC)
2.3 长时匹配模块
相关操作被广泛地应用到了目标跟踪当中,如SiamRPN[12]通过将目标区域与搜索区域做相关操作定位目标。近年来,也有一些算法将相关操作引入到视频分割当中,如RANet[13]采用像素级相关的做法形成相似图,然后使用一个小型网络对相似图进行打分,选择分数最高的256层用来分割。本文采用类似的操作,设计了图4所示的长时匹配模块,将当前帧与第一帧进行像素级关联,以利用第一帧掩模的信息。防止因为遮挡、形变等原因导致前一帧中目标特征丢失而难以利用前一帧很好地检测当前帧中的目标。
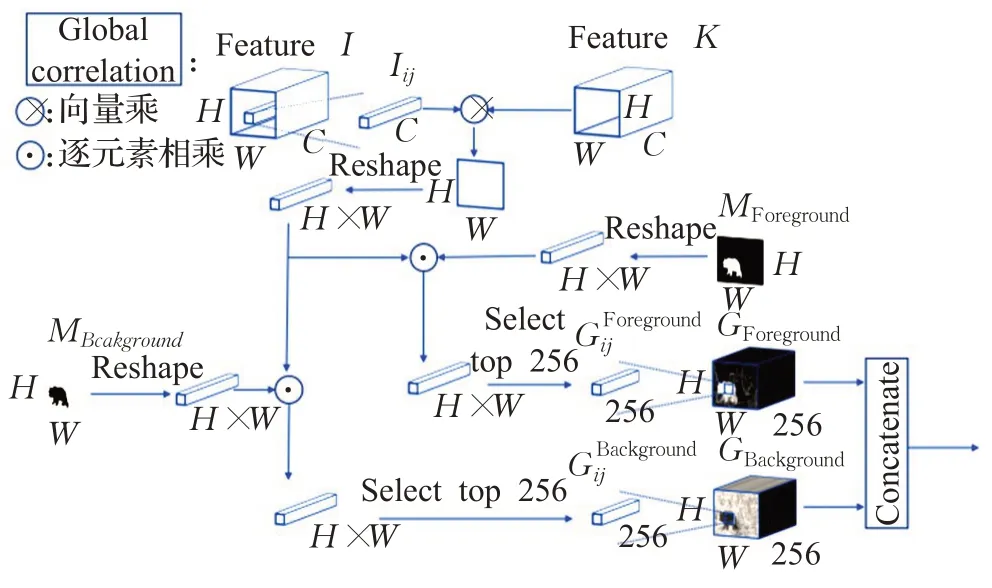
图4 长时匹配模块Fig.4 Long-term matching module
对于提取得到的当前帧全局特征I∈RC×H×W(H和W相当于原图尺寸的1/8)中的每个像素级特征Iij,将其和第一帧全局特征K∈RC×H×W做逐像素相关操作得到相似图然后对于相似图,将其维度变换为(H×W)×1×1后和经过相同变换的第一帧的前景(或者背景)M∈R(H×W)×1×1相乘,最后取其中最大的N(本文设为256)个值得到全局相似性图G∈RN×H×W中对应像素Gij,如式(1)所示:
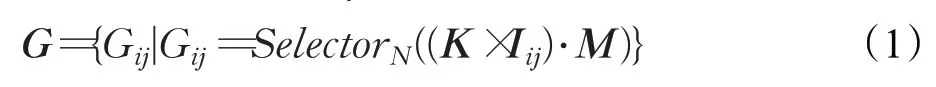
式(1)中Gij代表前景(或者背景)全局相似图中的像素点特征,K代表第一帧特征,Iij代表当前帧的像素点特征,M代表第一帧前景(或者背景)真值,×代表向量相乘操作,·代表逐元素相乘操作,SelectorN代表选择最大的N个值。其中全局相似图的可视化如图5所示,可以看出前景中目标物体的响应最大,而背景中目标物体响应最低。

图5 全局相似图Fig.5 Global similarity map
2.4 短时匹配模块
时序传播起始于MaskTrack模型,之后在其他方法中取得了不错的效果,这些方法一般将前一帧的掩模或者光流送入网络进行分割。掩模仅仅提供了目标在前一帧的位置以及形状,忽略了前一帧的目标特征,而光流计算需要增添光流检测网络,计算复杂度较高且难以做到端到端训练。实际上可以根据前一帧的预测来判断当前帧哪些像素是前景,哪些像素是背景。因为视频帧之间变化不大,所以可以限定每个像素的运动范围。受Flownet2.0[14]中互相关层启发,设计了短时匹配模块。

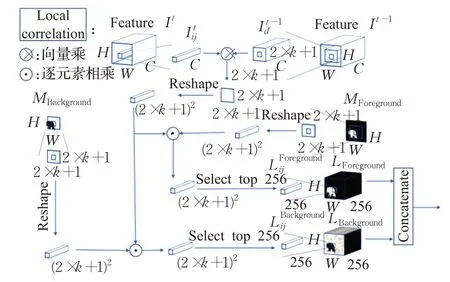
图6 短时匹配模块Fig.6 Short-term matching module
即将当前帧特征(i,j)位置的像素点It ij与前一帧前景特征(或者背景特征)中以(i,j)为中心,x轴和y轴距离不超过k的像素集逐像素做相关运算得到(2×k+1)2的相似值,再从中选择排在前N的值最后组成前景相似图(或者背景相似图)L∈RN×H×W。局部相似图的可视化如图7所示,可以看出和全局相似图相比,局部相似图去除了许多干扰元素,结果更清晰。

图7 局部相似图Fig.7 Local similarity map
2.5 解码模块
解码模块包括两个优化网络用于上采样以及一个conv 3×3的分割网络用于提取最终结果的概率图。优化网络结构如图8所示,Featurei代表编码器输出的同一层特征,将编码器输出的特征经过一个2D-AIC后与经过两倍上采样的上一层特征相加再送入一个2D-AIC输出。最后经过两个优化网络在图像的1/2尺寸下进行分割。
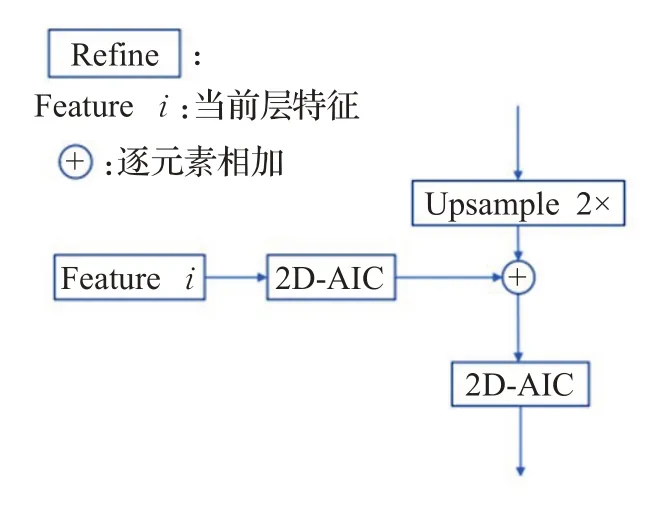
图8 优化网络结构图Fig.8 Refined module
3 实验评估
3.1 数据集
本文使用DAVIS[15-16]和YouTube-VOS[17]公开数据集进行模型训练,在DAVIS2016和DAVIS2017数据集上进行模型评估。DAVIS2016数据集为单目标分割数据集,包含50个视频,其中训练集30个视频,测试视频20个视频。DAVIS2017为多目标分割数据集,包含150个视频。YouTube-VOS数据集包含4 453个YouTube视频,在本文实验中用于增加训练数据,只在模型训练阶段使用。为了便于和已有算法的结果进行公平对比,视频目标分割模型在DAVIS数据集上的评价指标采用区域相似度和轮廓精度J&F指标。
3.2 模型训练参数
主干网络使用在ImageNet[18]数据集上预训练过的Res2Net50模型参数初始化。训练采用Adam优化器,学习率为0.000 01,损失函数为Focal loss[19]。在4块NVIDIA GeForce TITAN XP上训练20万次,批量大小设为12,数据增强采用随机裁剪、随机尺寸变换和随机翻转。
3.3 单目标视频分割实验
在DAVIS2016验证集上与表1中近几年的方法进行比较,可以看到本文模型在无需在线微调的情况下达到了较好的实验结果,区域相似度和轮廓精度J&F的平均值达到了86.5%。模型在单块GeForce TITAN XP计算卡上的在线推理速度可以达到21 frame/s,在时间和精度方面取得了较好的平衡。其中,PReMVOS模型[20]在轮廓精度方面比本文实验结果高1.5%,这是因为PReMVOS利用每个视频的第一帧人工合成了2 500张图片进行在线训练,通过付出一定时间代价得到了比本文更高的轮廓精度,这种做法不适用于在线处理。从表1中计算效率对比结果看,RANet模型的计算效率高于本文方法,该模型训练阶段使用静态图片合成视频帧进行预训练,训练过程复杂,模型中使用了注意力机制,在推理阶段效率高于本文模型。由于该模型侧重和第一帧匹配,因此对目标形状、大小变化的适应性以及对相似目标的区分能力不强,在单目标实验中的大部分精度指标以及多目标实验中的精度指标方面低于本文所提出模型。
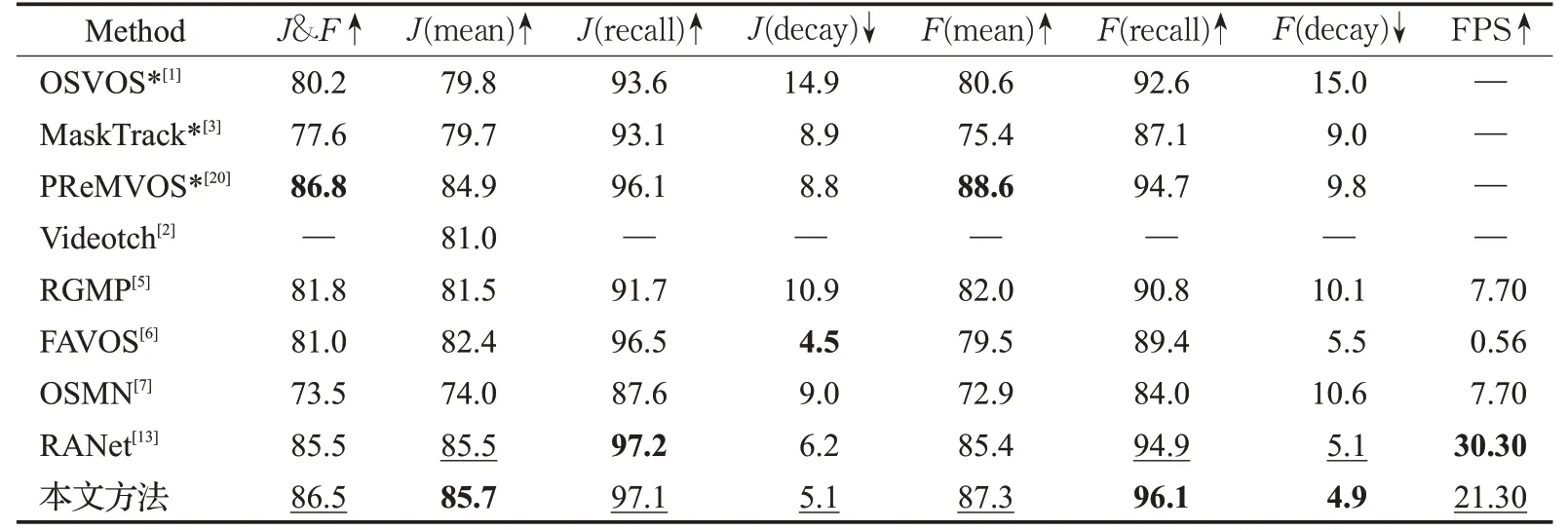
表1 不同方法在DAVIS2016验证集上的结果Table 1 Results of different methods on DAVIS2016 validation set
表2显示了本文模型切削实验的结果。为了探索网络结构中各个模块的作用,在只保留短时模块和长时模块下分别做了训练和测试,结果如表2第一行和第二行所示,两者都取得了不错的结果,但是和结合两个模块训练后的结果有一定差距,J&F指标分别降低了3.7%和2.9%。只保留短时匹配模块会降低精确度是因为缺少第一帧的纠正导致误差会从前一帧传递到当前帧,正如图9所示,没有第一帧真值的矫正,误差随着帧数的增加而增加。只保留长时匹配模块也会降低精确度,这是因为目标越往后和第一帧的差别越大,只靠和第一帧像素做匹配不足以捕捉目标,尤其是目标尺寸变化过大时,如图10所示,因为和第一帧的目标相差过大,网络已经检测不出目标了。为了确定掩模和短时匹配模块对时序传播的贡献,本文分别去掉短时匹配模块和掩模进行实验,结果如表2中第三行和第四行所示,去掉掩模比去掉短时匹配模块的J&F指标高了2.2%,这证明了本文所提出的短时匹配模块的有效性。虽然短时匹配模块的效果很好,但是它对物体的形状和位置的特征表示不够,还是需要掩模和它互补,在加上掩模后本文方法在J&F指标上提高了1.6%。

表2 切削实验结果Table 2 Ablation study results

图9 误差传播Fig.9 Error propagation

图10 误差匹配Fig.10 Error match
3.4 多目标视频分割实验
多目标视频分割由于目标多,相似目标容易互相遮挡、交错而过而极具挑战性。对于多目标视频分割,本文在每帧分割出所有目标后对于每个像素选择概率最大的类。
本位设计的网络模型中比较耗时的是编码模块、长时匹配模块和短时匹配模块,每帧中对于不同目标而言这些模块参数是可以共享的,因此这部分的计算时间对于单目标和多目标而言大致相同,不会随目标个数增加而增加。模型中解码模块的计算时间和目标数量相关,每个目标平均约需11 ms。因为大部分模块的计算时间不受目标个数影响,所以本文算法在多目标视频分割上依然能有较高的效率。
在多目标数据集DAVIS2017的验证集和测试集上实验结果如表3和表4所示,可以看出本文方法在多目标上依然取得了良好的结果。PReMVOS模型的J&F指标比本文方法分别高了0.5%和4.2%,这是因为它使用了在线训练,每个视频需要在第一帧上训练几十秒甚至几分钟,无法满足在线应用需求。而本文方法无需在线训练,提高了在移动机器人环境感知应用中的可用性。
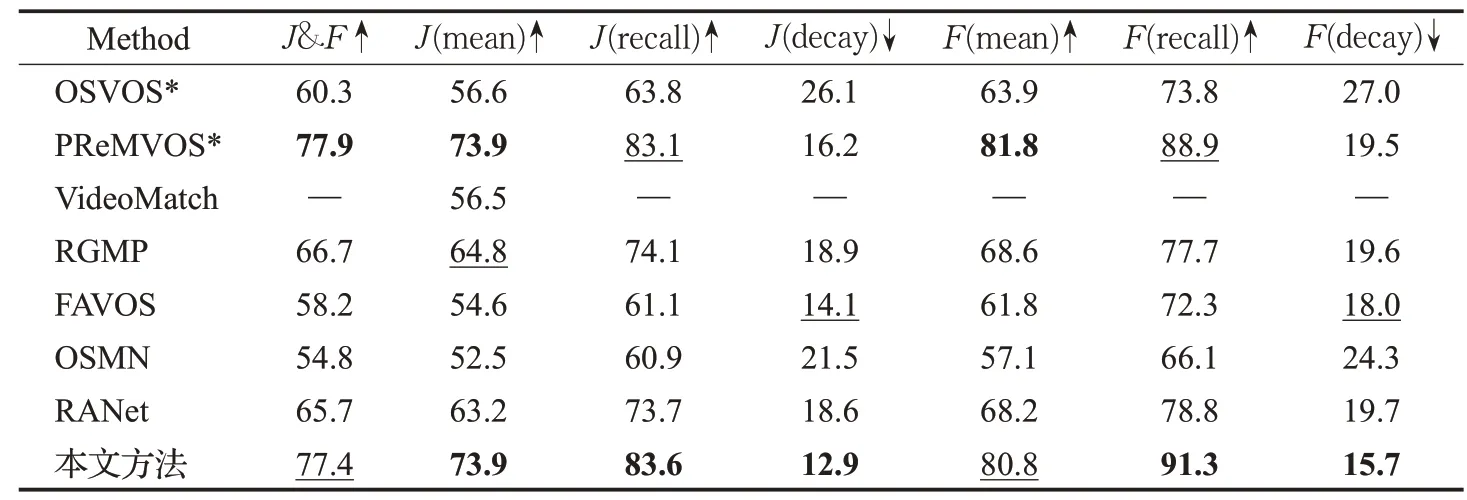
表3 不同方法在DAVIS2017验证集上的结果Table 3 Results of different methods on DAVIS2017 validation set
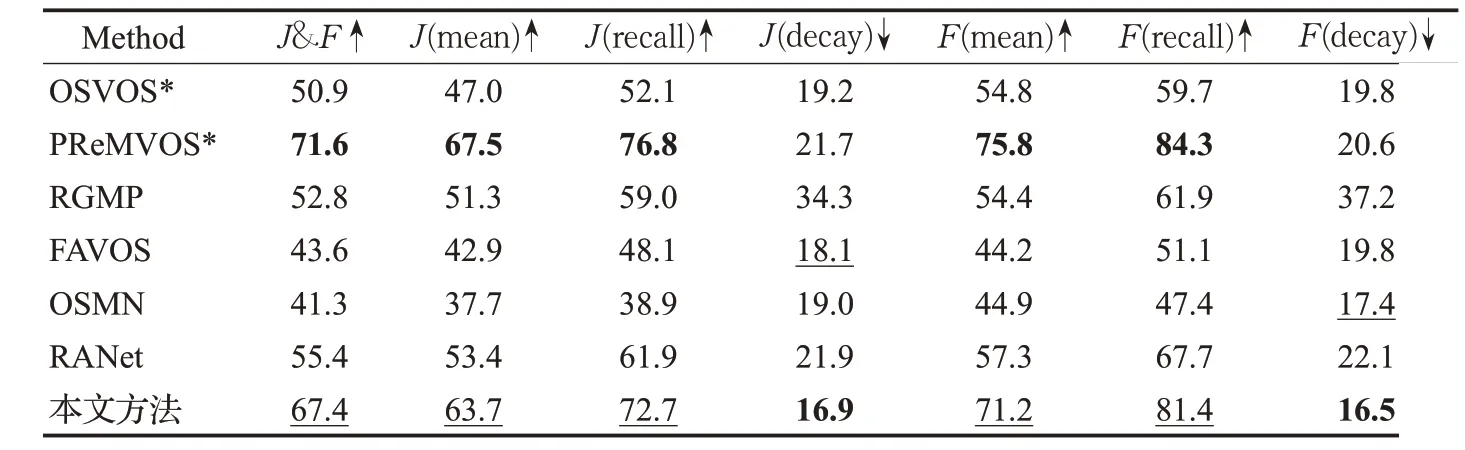
表4 不同方法在DAVIS2017测试集上的结果Table 4 Results of different methods on DAVIS2017 test set
3.5 目标分割实验结果
图11显示了四段视频每隔10帧的分割结果。第一个和第二个视频分别是骑马跳跃和赛车漂移,这两段视频说明了本文算法对于形变和快速运动的处理能力。第三个和第四个视频分别是游动的五条金鱼和人群中的三个同伴,可以看出在相似目标互相遮挡和背景繁杂的情况下,本文依然能取得良好的结果。请在如下网址查看更多视频分割结果。


图11 视频目标分割结果Fig.11 Video object segmentation results
4 结论
面向视频目标分割,为了能更好地利用视频时序信息提高分割结果和计算效率,本文提出一种新颖的短时特征匹配模块。通过结合长时匹配模块和短时匹配模块,本文设计了一个有效、快速的端到端视频目标分割神经网络模型,能较好地处理目标遮挡、形变、快速运动以及相似目标互相遮挡的情况。实验表明本文提出的模型在DAVIS数据集上取得了良好的实验结果,并且无需在线训练,能满足对计算效率要求较高的应用需求。
在本文工作的基础上,后续将融合当前帧之前多帧的预测结果分割当前帧中的目标,以进一步提高分割精度。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
小哥白尼(军事科学)(2022年2期)2022-05-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
红领巾·萌芽(2019年8期)2019-08-27
当代陕西(2019年10期)2019-06-03
中国与非洲(法文版)(2017年10期)2017-11-23
CHIP新电脑(2016年3期)2016-03-10
汽车与新动力(2012年1期)2012-03-25
