
动态重构硬件加速中的性能开销建模
2022-03-22 03:34苑福利娄文启陈香兰
计算机工程与应用 2022年6期
苑福利,宫 磊,娄文启,陈香兰
中国科学技术大学 计算机科学与技术学院,合肥 230027
近年来,基于FPGA的动态可重构计算技术逐渐成为硬件加速中的研究热点。自从20世纪80年代中期Xilinx公司推出第一款现场可编程门阵列(field programmable gate array,FPGA)以来,近几十年随着半导体工艺和制造工艺的不断进步,可编程器件的片上资源和规模不断增大,现代FPGA芯片的浮点计算性能可以达到10 TFLOPS量级。同时由于自动设计技术的发展,以及可编程接口的不断丰富,可重构技术正迅速发展和成熟起来。
动态可重构技术是近些年出现的一种使用FPGA进行设计的新型理念,该技术可以充分利用FPGA的可编程性和可重构性,通过将FPGA片上的逻辑资源进行时分复用,可以将时间轴上不重叠的功能进行隔离并实现为可重构模块(reconfigurable module,RM),在需要时加载到片上进行执行。通过这种方式,可以允许用户只对FPGA的部分区域进行重新配置,而其余部分在重构过程中正常运行,这与传统的静态全局重构方式相比,重新配置的比特流文件更小,可以将FPGA的有限资源进行“时分复用”,具有更高的灵活性和比较小的重构开销。因此,动态重构技术其特有的灵活性和高效性,被广泛应用于硬件加速、航天、数据中心等多个领域。
最近,以卷积神经网络为代表的深度学习被广泛应用于图像分类、目标检测、计算机视觉等领域[1-3],得益于FPGA的高性能和可重构特性,能够兼具ASIC芯片的执行效率和通用处理器CPU灵活性,具有高性能和低功耗的优势,被广泛应用于硬件加速[4-5]。何凯旋等人[6]针对CNN硬件实现时资源限制问题,提出基于FPGA动态重构的卷积神经网络加速器设计,在Xilinx VC707 FPGA平台实现Lenet-5手写体识别网络,与静态设计相比节省大量资源;宫磊[7]充分挖掘可重构硬件特性解决CNN硬件加速中的软、硬件特征失配问题,并基于DQN深度强化学习控制FPGA运行时重构;Ye等人[8]采用一种流水线方式在FPGA上多个重构区动态映射每个流水线段,并在Xilinx VC709 FPGA平台对VGG16网络进行部署加速。
上述基于FPGA动态重构的硬件加速工作,重构时间往往在毫秒级别,重构开销不能忽视且会显著影响加速器的性能,如采用流水线方式动态重构FPGA,若开销过大会使流水线停顿抵消可重构带来的好处,最坏情况下可能比静态重构有更差的性能。然而重构开销在系统设计的早期阶段难以估算,往往在设计最终阶段布局布线后才能获得,因此需要一个在可重构系统设计的早期阶段提供精准估算重构开销的方法,用于指导可重构系统的设计。
然而为获得一个估算重构开销的方法需面临如下挑战:(1)重构开销和诸多因素有关。不同的资源量、重构区划分策略、设备器件等都会对重构时间产生影响,这对估算重构开销带来了挑战。(2)动态重构设计流程复杂,实验周期长,中间环节容易出错,如布局布线失败、分配资源不足等,都会对模型的准确性产生影响。(3)对估算新型FPGA硬件重构开销的研究较少,以往工作针对特定的FPGA,不能很好应用于新型FPGA,参考价值较小。
目前有部分对重构开销进行估算的研究工作,如工作[9]调查影响重构开销的因素并提出一个估算模型,但误差在30%左右;Claus等人[10]提出一种计算方法预测重构开销,但只适用于Virtex-II系列FPGA;Duhem等人[11]提出一个快速内部配置访问端口,并建模评估重配置时间;Morales-Villanueva等人[12]基于综合报告提出两个开销模型指导可重构设计,但未对新型FPGA进行分析。这些研究工作往往只考虑重构过程中的物理组件参数,而忽略了对比特流文件的分析,由于重构开销和重配置比特流大小、配置端口速度息息相关,因此估算精度较低;其次部分方法适应于特定的FPGA,不能很好应用于新型FPGA,移植性较差。
对此,基于以上挑战和存在的问题,本文针对现代FPGA构建了新颖的运行时重构性能开销模型,能够避免复杂的设计流程,节省大量时间,帮助开发者在设计初期快速评估设计的合理性。由于重构开销和诸多因素有关,本文提出的方法将诸多影响重构开销的因素抽象到对比特流文件的分析,通过总结比特流格式构建了可重构时间开销模型,其准确度较以往工作有很大提高。同时,该方法很好地弥补了针对新型FPGA重构开销研究的缺少,可以便捷地应用于现代动态重构硬件加速设计中,更具实际意义。本文的主要贡献如下:
(1)本文提出的方法将诸多影响重构开销的因素抽象到对比特流文件的分析,通过总结XilinxVirtex-7系列FPGA比特流格式,并以此构建动态重构开销模型,其准确度较以往工作有很大提高。
(2)提出的模型可以在设计初期提供精准的重构开销估算,避免冗长的设计流程,节省大量时间。
(3)作为样例分析,本文在新型FPGA上对流行算法如Winograd、FFT、GEMM、AES和DES等进行重构开销实验,结果表明该模型具备快速、准确特点,准确率可达98%,可以便捷地应用于现代动态重构硬件加速中,具有较高的工程实用价值。
1 背景知识
1.1 动态部分重构技术简介
动态部分可重构(dynamic partial reconfigurable,DPR)作为FPGA一种特性,可以允许用户通过加载动态配置文件(通常是部分配置比特流文件)来修改运行的FPGA,动态地更新部分逻辑而其他部分功能模块正常运行。如图1所示,是一个动态部分重构示意图,将FPGA部分资源分为A、B两个可重构区域(reconfigurable partition,RP),在运行过程中根据需要,用户可以从比特流库中挑选所需的部分配置比特流文件对可重构区域进行动态配置。
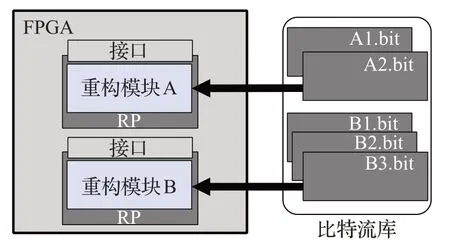
图1 动态部分重构示意图Fig.1 Diagram of dynamic partial reconfigurable
在设计实现时,一般将FPGA的逻辑资源分为两部分:静态逻辑和可重构逻辑,并划分到FPGA的不同区域中,如图1中FPGA的浅色区域表示静态逻辑,一旦初始配置后在运行时不再改变;深色部分表示可重构逻辑,在运行过程中加载其他配置文件更改先前的硬件逻辑。可重构逻辑根据需要会划分出多个可重构区域RP,每个RP可能存在多个可重构模块,即该可重构区域的不同功能实现,如A区域对应A1、A2两个功能实现,B区域对应B1、B2、B3三个功能实现,运行时根据需要加载到FPGA执行。与静态重构相比,动态配置所需要的部分配置比特流文件更小,配置速度更快;与此同时可以将可重构区的逻辑进行更换加载执行不同的逻辑功能,且不会影响未重新配置区域功能的正常运行,可以充分利用硬件资源,具有很高的扩展性。
1.2 动态部分重构设计过程
常规SRAM工艺的FPGA都可实现静态重构,而部分特定基于SRAM或FLASH结构的新型FPGA支持动态部分重构,如现代Xilinx、Altera等厂商的FPGA器件都是SRAM查找表结构,可以实现动态部分重构功能,本文以XilinxFPGA为例介绍动态部分重构的设计流程。如图2是一个动态部分重构设计实现流程,实现主要可以分为初始功能划分阶段、模块设计和网表文件生成阶段、可重构区划分阶段、比特流生成阶段和下载五个阶段,下面结合图2进行详细介绍。
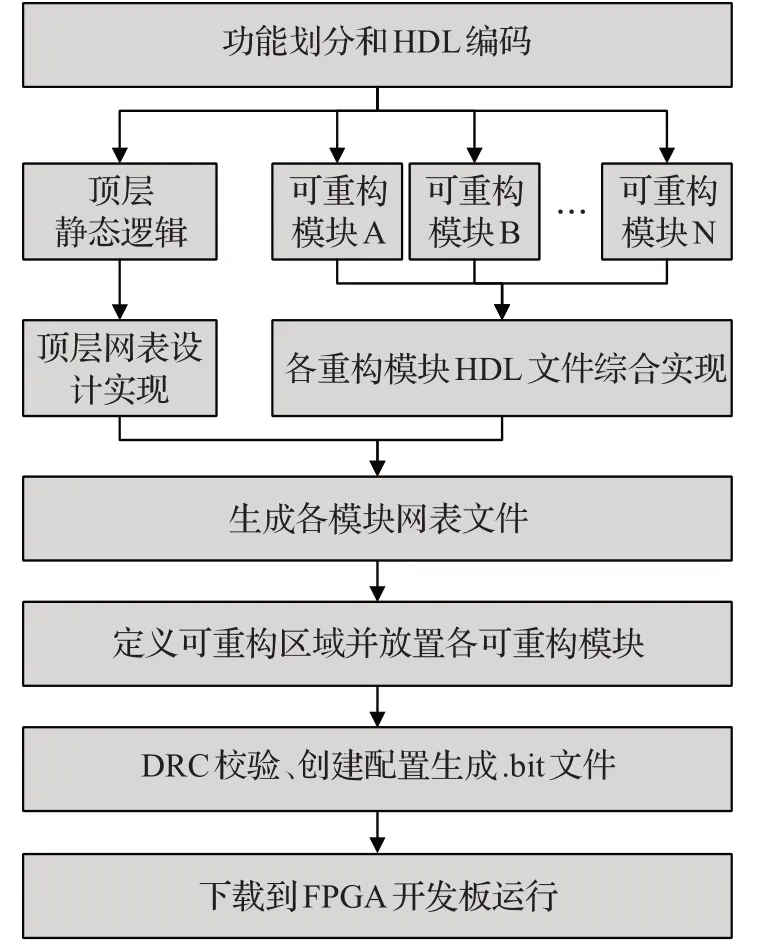
图2 动态部分重构实现流程Fig.2 Implementation flow of dynamic partial reconfigurable
(1)初始功能划分。在设计初始阶段需对所实现的功能进行划分,将FPGA在运行过程中不用更改的逻辑划分到静态逻辑区域,将需要动态更改的逻辑划分到可重构逻辑区域,并分成不同的可重构模块,如图中的可重构模块A、B等。最后将划分后的功能逻辑使用硬件描述语言如VHDL、Verilog等进行编码实现。
(2)模块设计和网表文件生成。在实现过程为保证每个模块性能,每个模块单独设计、独立综合,同时为了保证布局布线的合理,在实际动态重构时将I/O、原始时钟等以黑盒形式初始化在顶层文件[13],同时同一重构区域需被重构的不同模块接口必须相同。完成设计后,使用专用的综合工具将各可重构模块综合生成网表文件,会获得静态逻辑网表和可重构模块网表。
(3)可重构区划分。使用PlanAhead软件定义设计的物理布局,通过创建物理约束(Pblocks)来定义可重新配置的区域,在FPGA的Device视图绘制一个矩形区域,需要保证绘制的该区域内包含的资源数略大于可重构模块所需资源的最大值。完成所有可重构区域RP设置后,运行DRC检查保证设计的合理性。
(4)比特流生成。通过软件生成一个完整的配置设计,该配置包含每个静态模块和每个可重构分区的一个可重构模块,为完整配置设计保存检查点,之后可以删除可重新配置模块,并仅保存静态设计检查点,锁定静态逻辑位置和路由,之后可以在该静态设计中添加新的可重构模块并实现这个新配置,重复该步骤直到所有可重构模块都实现。通过该过程可以生成一个完整的.bit配置文件和多个可重构模块的部分配置.bit文件。
(5)下载。在FPGA上烧写完整的配置文件,然后根据需要将部分配置比特流文件下载到板上,动态更改FPGA的实现功能。
2 FPGA重构性能开销模型
FPGA由可编程逻辑单元(configurable logic block,CLB)、块RAM(Block RAM,BRAM)、专用数字处理单元(DSP48E1)、可编程布线资源、可编程IO资源等部分组成。Xilinx的7系列FPGA是基于ASMBL架构[14]的,如图3所示。该架构的特点是资源按照列排布,同一列包含相同的资源,通过将不同的列进行组合,可以获得面向不同应用、满足各种功能的FPGA。通过XilinxISE开发工具可以对这些资源进行编程,生成.bit文件,称为配置比特流文件,包含对CLB、BRAM、DSP的配置信息,通过比特流文件重新烧写配置电路来实现不同的逻辑功能。通过Xilinx官方文档给出的包类型、帧组织、寄存器格式编写脚本代码对比特流文件分析,得到比特流格式并提出一种估算比特流大小的方法,并基于此构建运行时重构性能开销模型。
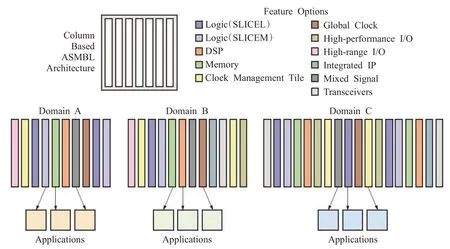
图3 ASMBL架构Fig.3 ASMBL architecture
2.1 配置比特流包类型和帧组织
(1)比特流包类型。Xilinx FPGA配置比特流由两种数据包类型组成:类型1和类型2,如表1和表2所示。其中类型1数据包有5部分组成,头类型固定为001表示类型1;操作码分为4种:00表示空操作、01为读、10为写、11保留;寄存器地址后五位有效,用于标识寄存器地址;字计数用于标识后面紧跟的32位数据个数。类型2数据包有3部分组成,头类型固定为010表示类型2;操作码和和字计数与类型1数据包含义一致。类型1数据包字计数只有11位,用于读写短数据,同时类型2数据包没有寄存器地址,只能跟在类型1数据包后面,通过两者组合来实现读写大段数据功能。

表1 类型1配置包格式Table 1 Type 1 configuration package format

表2 类型2配置包格式Table 2 Type 2 configuration package format
(2)比特流帧组织。FPGA进行配置的最小数据单位是帧,这些帧是FPGA配置内存空间最小可寻址段,因此所有操作必须在整个配置帧上进行。对于7系列FPGA、每一帧由101个32位的字组成[15](不同系列不同)。每个配置帧有一个32位的地址,通过帧地址寄存器(frame address register,FAR)可以对该帧进行寻址,用于指示其在FPGA上的位置。表3对FAR进行详细介绍,可以分为5部分,其中块类型低三位有效:000表示为互连和块配置,001为BRAM配置,010为互连块和特殊帧;上/下指示器指示配置的是FPGA上部分还是下部分;行地址表示配置的当前行;列地址表示配置的当前列;次地址表示列内帧地址。

表3 FAR寄存器格式Table 3 FAR register format
Xilinx 7系列的FPGA内部被分成不同的时钟区域数,即被划分为多个行,每行按照列再次划分,行列交叉形成不同大小矩阵块,放置着CLB、BRAM、DSP等资源,矩阵块从左到右有着不同数量配置帧,取决于矩阵块资源类型。为了估算配置比特流大小,需要知道比特流格式,每列的配置帧数等,Xilinx官方提供的内容十分分散且有限,部分内容还被有意地忽略了,通过实验解析比特流格式,并得出一个配置比特流大小估算方法。
2.2 比特流格式和大小估算
XilinxISE开发工具生成的.bit比特流是二进制文件,为了方便研究可以通过设置生成.rbt文件,两者都是FPGA配置文件,只不过.rbt文件是.bit文件的ASCII版本。同时为了获取每列的配置帧数,生成DebugBitstream文件(每一帧会有一个CRC校验),在XilinxVC709平台通过调整可重构分区不同的资源数,生成不同的.rbt文件和DebugBitstream文件,然后编写脚本代码对比特流文件进行解析,程序流程图如图4所示,按照2.1节介绍的配置比特流包类型和寄存器格式进行逐条解析,获知每一条命令的具体含义,从而得到配置每列的帧数。
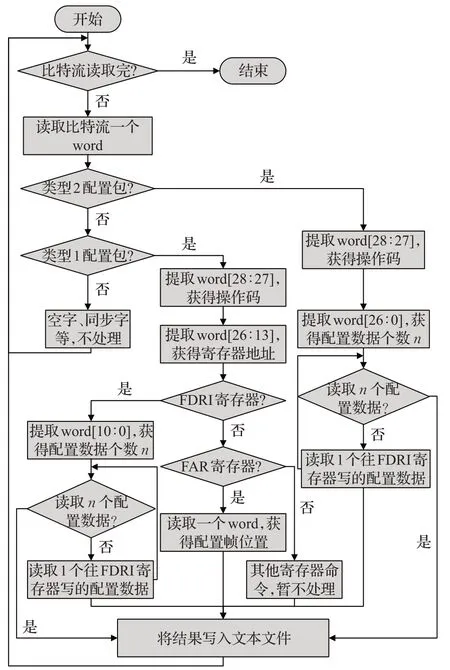
图4 提取帧组织程序流程图Fig.4 Flow chart of program for extracting frame organization
根据实验得到数据和部分参考资料[16]分析,对于VC709有10行并分为上下两部分,每一列有152帧,每一行会填充一帧;CLB每列有36帧,DSP每列有28帧,BRAM每列有28帧,配置BRAM内容有128帧,同时初始会填充一帧,每行帧结构如表4所示。

表4 Xilinx 7系列FPGA配置每列帧数Table 4 Xilinx 7 series FPGA configuration frame number per column
如图5是得到的比特流部分内容展示,从图中可以看到初始首先进行同步操作,以及设备ID、CRC校验字的写入,保证比特流被正确地烧写到FPGA上,然后通过向FAR帧地址寄存器写入命令字,确定在FPGA上配置位置,如图中0x00400800根据FAR寄存器格式可知道配置0行、16列下半部分CLB,接着向FDRI寄存器写入0x360D即13 837个配置字完成CLB配置,最后向CMD写命令字,表示配置结束解除同步。通过查看对比不同的配置比特流文件,以及Morales-Villanueva等人[12]对5系列FPGA比特流格式的分析,发现配置比特流有一个大致相同的格式,如图6所示。

图5 VC709比特流样例Fig.5 VC709 bitstream sample
有了图6比特流格式,创建一个计算方法来估算比特流大小和可重构功能模块的计算/访存属性之间的关系,可重构功能模块的计算-访存属性主要由LUT、DSP、BRAM等FPGA资源构成,其中可重构模块消耗的资源数一般可以通过Xilinx开发软件布局布线综合后得到,同时由于可重构区域是在FPGA上绘制一个矩形区域,因此可以根据可重构区域包含的资源数估算重构该区域的比特流文件大小。
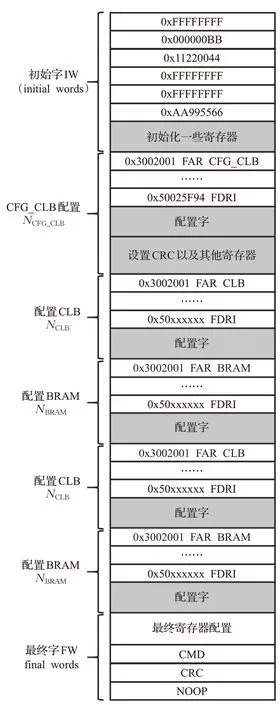
图6 部分重构配置比特流格式Fig.6 Partially reconfigurable configuration bitstream format
对此需要先获得配置每列资源需要的配置帧数和字节数,对于不同型号的FPGA有一些特定的参数,通过实验手动解析比特流文件和查看资料得到表4和表5数据。为了得到一个可重构区配置比特流大小需要知道可重构区需要的资源数,即可重构功能模块计算访存/属性(DSP、BRAM等资源),然后根据FPGA每列的资源数如表6,通过公式(1)~(3)得到可重构区CLB列数NCLB、DSP列数NDSP、BRAM列数NBRAM。

表5 VC709 FPGA配置比特流参数Table 5 VC709 FPGA configuration bitstream parameters

表6 VC709 FPGA每列资源数Table 6 VC709 FPGA resources per column
可重构区CLB列数NCLB可以根据重构区总的LUT资源数计算得到,其中一个CLB包含8个LUT,因此CLB列数计算公式如式(1)所示:

可重构区DSP列数NDSP根据重构区总的DSP资源数计算得到,如式(2)所示:
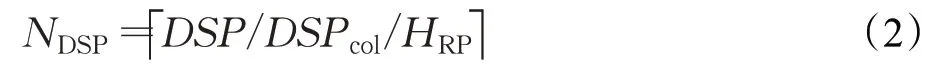
可重构区BRAM列数NBRAM根据重构区总的BRAM资源数计算得到,如式(3)所示:

可重构区域行数HRP,以及是否跨越上下部分Half可以根据可重构区绘制的矩形区域确定,有了上面的输入参数,根据比特流格式得到一个计算模型来估算部分配置比特流的大小,其计算公式如式(4)~(7)所示。
我初到柳江古镇的时候,隆冬已在那个小镇盘桓了一段时间,街头那棵近千年的黄葛树枝头只零星地挂着些干枯的叶子。那些泛黄的叶子极像一片片风车叶,在起风的日子里发出“唰啦、唰啦”的响声。

2.3 重构性能开销模型
有了计算重构比特流大小公式,可以根据FPGA内部配置访问端口(internal configuration access port,ICAP)速度Speed,计算出重构时间Tconfig用于估算运行时重构开销,并根据该重构开销模型指导判断运行时重构是否能够带来收益,其中重构开销Tconfig由公式(8)计算得到:

对此,可以使用该重构模型对硬件重构是否带来潜在的性能收益进行判断,为了方便说明,定义两个任务A和B顺序执行,初始时FPGA硬件架构用于加速对任务A的执行,在该相同硬件架构下执行任务B需要的执行时间是Ti,若使用适用于任务B的硬件架构对FPGA进行重构,其中重构的开销是Tconfig,使用重构后的硬件加速任务B的执行,执行时间是Tj,则重构带来的性能收益是Ti-Tj,如果满足公式(9)认为重构带来的潜在收益不足以弥补重构的开销,因此应避免该重构。

为了方便说明,使用Winograd卷积算法F(m×m,r×r)作为计算核心对Alexnet神经网络[17]卷积层的动态重构进行分析,其中Winograd快速算法是由数学家Winograd在1980年提出[18],通过将输入信号、卷积核以及输出结果进行矩阵转换,将乘法运算转化为加法操作,可以大幅降低计算开销,节省DSP资源。目前有多项研究工作将Winograd快速算法的卷积计算应用到神经网络硬件加速器设计中[19-21],因此使用Winograd算法来测试模型准确性是一个合适的选择。
如图7是Winograd卷积计算过程,从图中可以看出给定一个n×n的输入块和r×r的卷积核,通过Winograd卷积算法可以生成一个m×m的输出特征图,接着向右滑动m步长,执行相同的计算就可以得到下一个输出。

图7 Winograd算法Fig.7 Winograd algorithm
使用二维的Winograd卷积算法F(m×m,r×r)作为计算核心,其中输出尺寸是m×m,卷积核尺寸是r×r,一旦确定了m和r,可以计算出输入尺寸n(n=m+r-1),二维Winograd算法计算公式可以根据一维嵌套迭代得到,如式(10)所示。其中g为输入卷积核、d为输入分片,G、B、A分别为卷积核转换矩阵、输入转换矩阵和输出转换矩阵,当卷积核和输出尺寸确定下来,转换矩阵也随之确定下来,可以提前计算出来。

硬件加速器在卷积层输入通道和输出通道使用大小为Pm和Pn的循环展开进行并行计算,对该硬件架构消耗的资源和计算时间进行建模。采用16 bit定点数据,根据Xilinx官方文档可以知道一个DSP可以在一个时钟周期内完成一次乘加操作,而DSP在Winograd计算核心点乘时被消耗,因此DSP数量应满足公式(11),其中n表示输出尺寸。

LUT资源主要在矩阵转换时被使用,因此可以提前通过HLS工具测得的实际数据作为参考,LUT数量应满足公式(12),其中分别表示Winograd计算输入尺寸为n,卷积核尺寸为r时输入转换、输出转换和卷积核转换需要的LUT数。
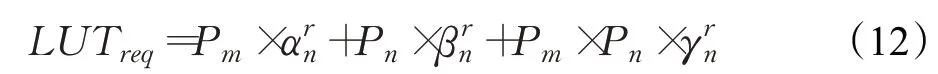
BRAM资源主要用于输入、权重和输出缓存,对输入输出采用双缓冲设计,权重计算前一次性加载一批到片上,因此BRAM数量应满足公式(13):
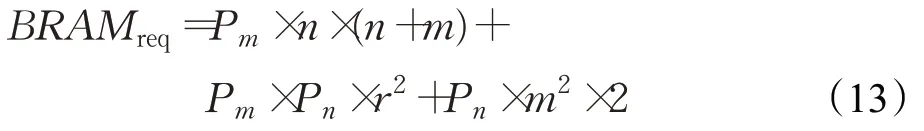
在该架构设计下计算一个卷积层需要的时间可以通过公式(14)计算,其中H、W表示输入图像的长和宽,M、N表示输入输出通道数,当Winograd计算核心采用流水线设计时II等于1,Freq表示加速器工作频率。

将公式(11)~(13)作为输入参数代入到运行时重构的性能开销模型中得到重构开销,同时在给定资源下进行加速器的设计搜索,并用式(14)计算加速器执行时间,根据公式(9)可以获得运行时重构带来的性能收益,以及指导设计是否进行重构。
3 实验结果与分析
3.1 验证模型准确性
为了验证本文提出的重构性能开销模型的准确性,在XilinxVC709 FPGA平台上对目前常用的神经网络模型计算方法如Winograd算法、FFT算法、GEMM(通用矩阵乘法算法)和在相关工作中采用的加密算法如AES、DES等进行硬件加速并部署实现。其中Winograd算法和GEMM算法首先采用Xilinx公司的VivadoHLS 2018.3高层次综合工具将高级语言编写的代码转换为RTL级代码,同时对数据采用16位定点量化的方案,加速器工作频率为100 MHz,然后对所有算法使用Xilinx-Vivado 2018.3集成开发环境对其进行可重构硬件加速设计,并综合、布局布线产生每个重构模块的比特流文件。
如表7是使用综合工具对各算法进行硬件加速测得的资源消耗数,将得到的RTL硬件代码导出作为可重构模块,使用Vivado按照动态重构设计流程进行部署实现,在实现时需要保证可重构区域包含的资源量要大于可重构模块所需资源的最大值,这样才能布局布线成功。

表7 各算法消耗的资源数Table 7 Number of resources consumed by each algorithm
为了得到完整的.bit和各重构模块的部分.bit配置文件,需要为完整配置设计保存检查点并锁定静态逻辑位置和路由,在该静态设计基础上替换其他重构模块实现新的配置,从而产生不同的.bit配置文件。本文采用Vivado的动态部分重构项目流程,创建一个包含多个脱离上下文可重构模块和配置实现的工程,其中每个配置是一个完整的设计,每个可重构分区都有一个可重构模块,最终分别生成完整的.bit文件和可重构模块的部分.bit配置文件,操作流程如图8所示。
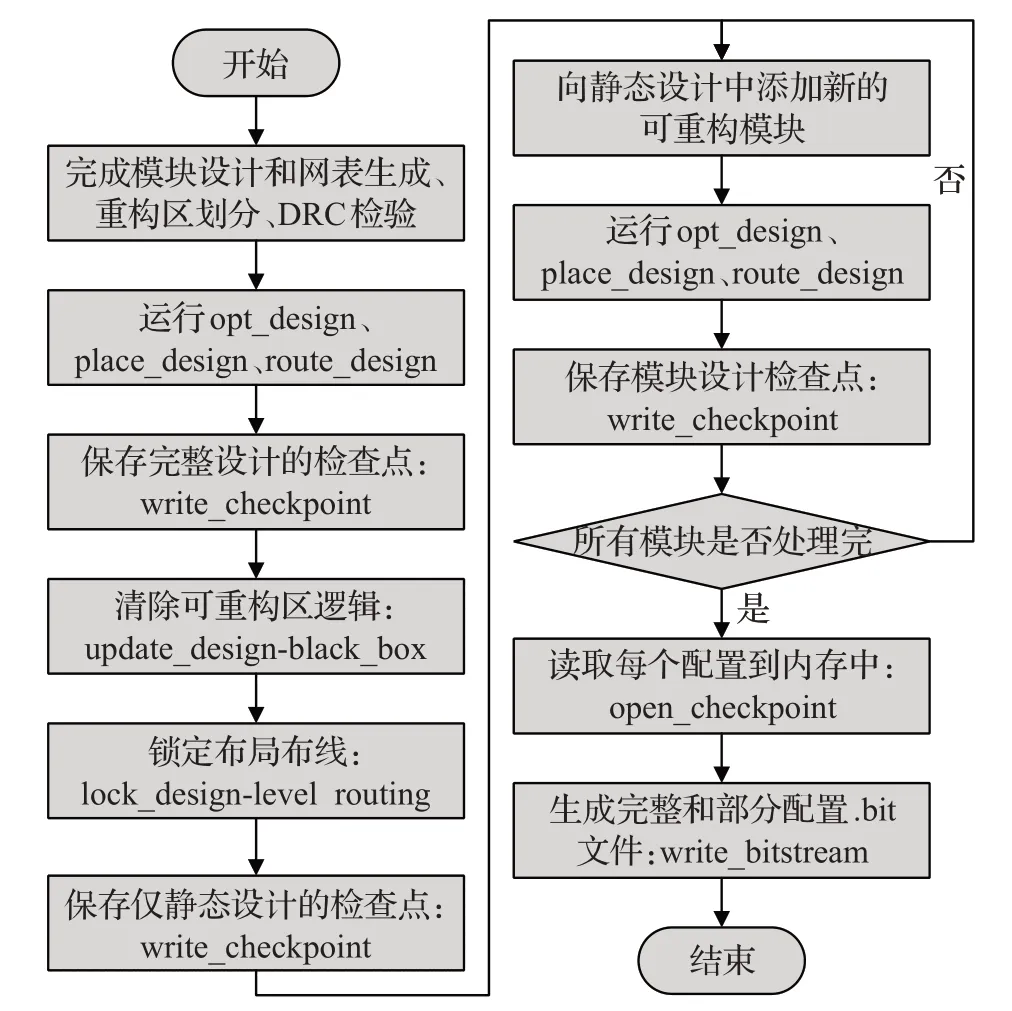
图8 生成比特流文件设计流程Fig.8 Design process for generating bitstream files
从图8可以看出,初始先完成模块的设计并获得网表文件,以及可重构区域的划分;然后运行综合工具的优化设计、布局布线设计得到逻辑功能在FPGA上的映射;接着通过write_checkpoint命令保存完整的设计检查点,至此创建了一个完整的设计实现,为了将静态部分设计用于后续的所有配置,需要删除当前的可重构模块,隔离静态设计,因此通过update_design命令清除可重构区的逻辑,并使用lock_design-level routing命令锁定布局布线,此时静态部分设计被锁定不会受到后续添加其他可重构模块的影响,然后使用write_checkpoint命令保存只包含静态设计的检查点;之后向锁定的静态设计中添加其余新的可重构模块,同样完成优化设计、布局布线设计,并通过write_checkpoint命令保存模块的设计检查点,重复此操作直到所有模块被处理完;最后使用pr_verify命令验证所有配置通过后,使用open_checkpoint命令读取每个配置到内存中,并通过write_bitstream生成完整.bit文件和部分配置.bit文件。具体的过程描述和动态可重构项目流程可以从Xilinx官方技术文档[22-23]中查看。
当完成功能划分、可重构模块的设计实现、可重构区域的划分等操作后,进行布局布线以及比特流的生成,如图9所示是一个重构区域布局布线成功后的结果图。
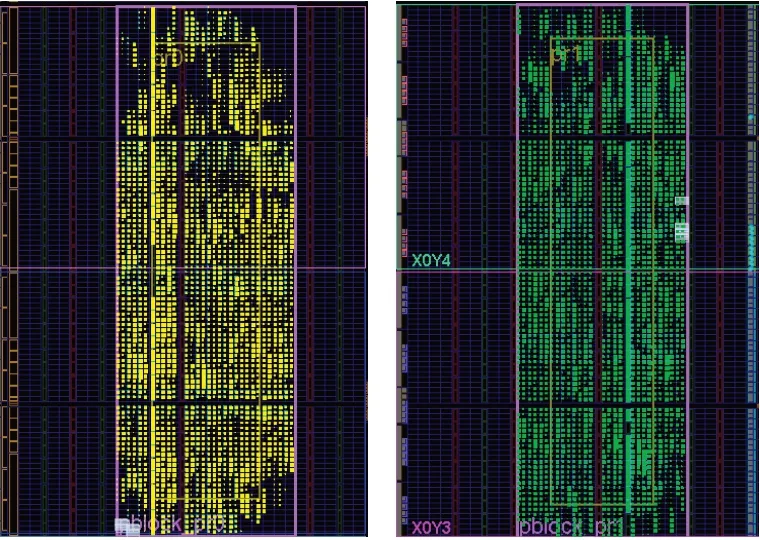
图9 重构区域PlanAhead显示Fig.9 PlanAhead display of reconstruction area
通过调整可重构区域不同的资源数,如扩大可重构区域矩形面积,可以分别获得配置该重构区域的配置比特流文件,在保证可重构区域资源数满足可重构模块最大需求的前提下进行了多次实验,获得多个实际的部分重构比特流文件,并与本文2.3节提出的重构开销模型得出的估计值进行对比分析,实验结果如表8所示。
从表8中可知,本文提出的重构开销模型最小相对误差仅为0.28%,这是由于综合工具产生的实际比特流文件,在.bit文件头部会保存一些冗余信息,里面包含当前ISE工程名字、软件版本、编译时间等,这部分信息长度不固定且难以估计,而且并不包含实际的配置数据,因此本模型并没有将这部分冗余信息加入到模型预测中,所以从实验结果1、3、5、6等可以看出模型预测值略小于实际测得值,这比较符合实际情况。本文提出的重构开销模型最大相对误差仅为4.2%,这是由于模型根据可重构区的不同资源例数进行计算,但是在实际布局布线时可能在可重构区最靠近矩形边框的资源列无法布线而未使用到,从实验结果3和4可以看出,实验4比3多加了一列CLB资源,但实际的重构开销时间是一样,是由于实验4有一列资源未被配置,因此模型预测值会偏大,这可以从实验结果2、4、6、12等看出模型预测值略大于实际测得值。
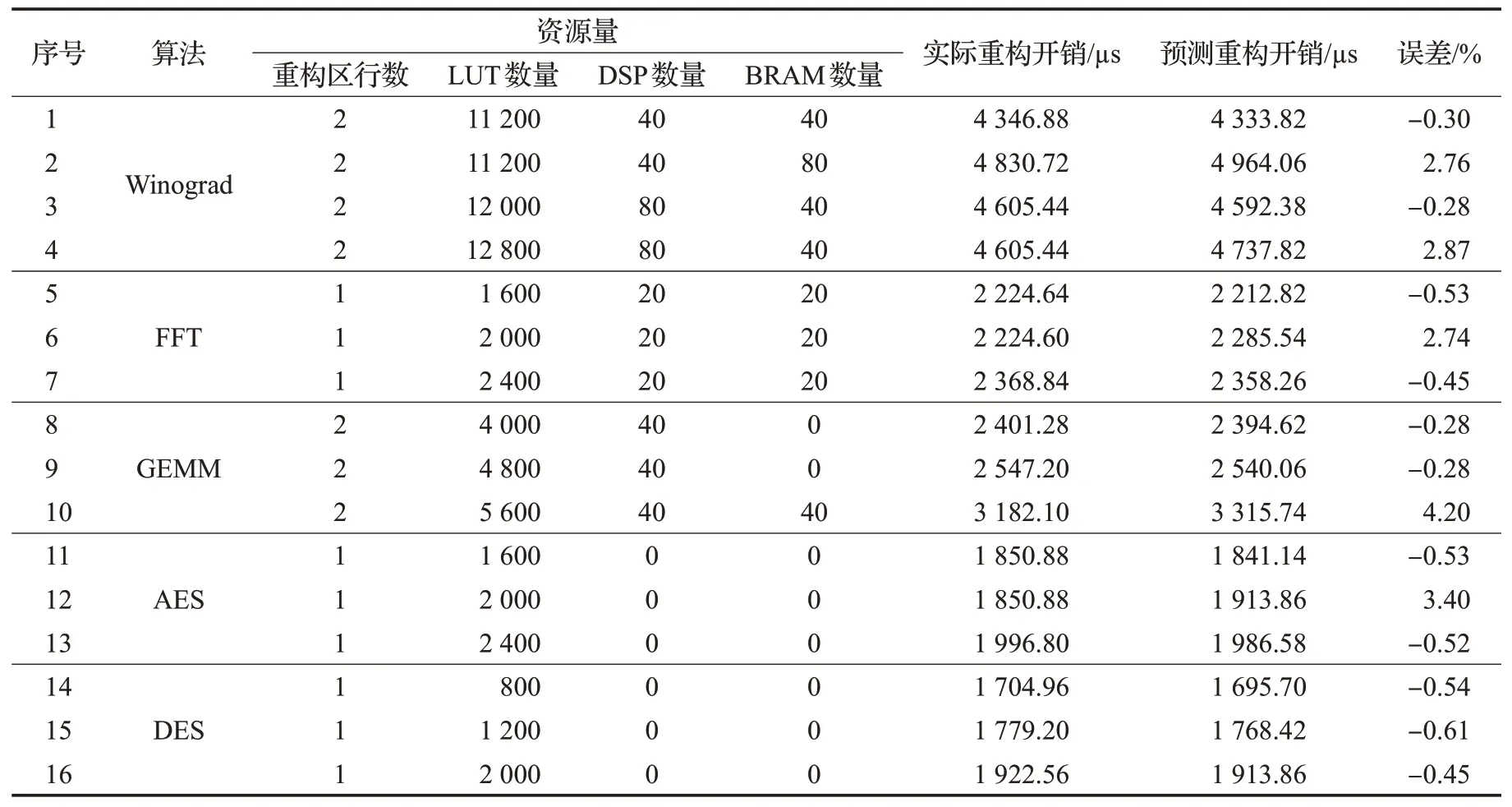
表8 重构开销模型预测误差表Table 8 Reconfiguration cost model prediction error table
本文针对多种算法实例进行测试验证模型的准确度,其中Winograd、FFT、GEMM、AES和DES实例的平均相对误差分别为1.55%、1.24%、1.59%、1.48%和0.53%,提出的重构开销模型总体平均相对误差为1.3%,预测精度比较符合实际的需求,可以很好地为设计者在动态重构设计初期对比特流大小和重构开销进行估算,从而对设计的合理性进行分析,节省大量时间缩短实验周期。
将本文提出的重构开销模型和以往工作进行对比,对比结果如表9所示。由于设计方法和硬件平台的不同会使产生的比特流大小不一样,因此针对AES和DES算法选择和以往工作比较接近的比特流测试用例。从对比结果中可以看到本文提出的重构开销模型精度较以往工作有很大提高,这是由于文献[9-11]只考虑重构过程中一些物理组件,忽略了对比特流的分析,本文总结比特流格式,并基于此构建的重构开销模型具有更高的准确度。同时文献[12]对旧系列FPGA器件进行研究,精度较高但不能很好应用于新型FPGA,本文针对Virtex-7系列FPGA的重构开销进行研究,具有更高的实际应用价值。

表9 与以往重构开销模型对比Table 9 Comparison with previous reconfiguration cost model
3.2 模型估算重构性能收益
按照2.3节提出的重构开销模型,对硬件重构是否带来潜在的性能收益进行判断,采用Winograd算法对Alexnet卷积层进行动态重构硬件加速来说明,在XilinxVC709 FPGA平台进行测试。加速器采用16位定点量化方案,工作频率为100 MHz,软件仿真环境采用Xilinx VivadoHLS 2018.3高层次综合工具,估计Winograd矩阵转换消耗的LUT资源,XilinxVivado 2018.3开发环境对重构分区和加速器进行综合和分析。
Winograd计算核心转换矩阵消耗的LUT资源量通过HLS工具提前测得,如表10所示,作为接下来模型的参数输入,用于对加速器资源消耗的估计。由表10可以看出,随着Winograd输入输出尺寸的增大,对LUT资源的需求也越大,尤其对于输出尺寸为3、5类型,由于转换矩阵中常数不是2的整数倍,因此通过移位需要消耗更多的资源。

表10 Winograd矩阵转换消耗LUT数Table 10 LUTs consumed by Winograd matrix conversion
针对Alexnet的卷积层Conv_2、Conv_3和Conv_4进行举例分析,其中Conv_2使用的5×5卷积核,Conv_3和Conv_4使用3×3卷积核,对于5×5的卷积核可以使用定制的5×5卷积硬件架构实现,也可以使用零填充的4个3×3卷积核实现。在有限资源的FPGA可重构区RP下针对卷积层的最大吞吐量进行最优解求解,假定有两个RP具有的资源量分别为RP1:14 400个LUT、100个DSP、120个18 Kb的BRAM;RP2:20 800个LUT、120个DSP、180个18 Kb的BRAM。求解结果如表11所示。
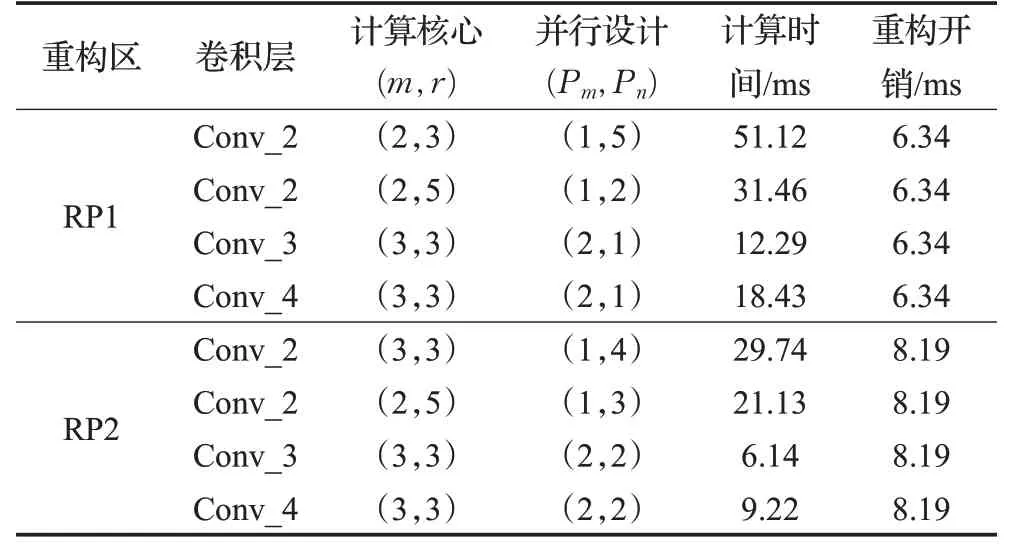
表11 Alexnet卷积层硬件设计和性能开销对比Table 11 Hardware design and performance overhead comparison of convolutional layers in Alexnet
从实验结果可以看出,若FPGA初始时采用3×3的卷积核硬件结构,卷积层Conv_2在可重构区RP1的最优设计是使用F(2×2,3×3)计算核心,Pm=1、Pn=5的并行展开,此时计算时间为51.12 ms,由于Conv_2使用5×5卷积核并不适用于该计算核心,若重构为F(2×2,5×5)计算核心,进行Pm=1、Pn=2的并行展开时,此时计算时间只有31.46 ms,由此可以看出重构带来的性能收益是缩短19.66 ms的计算时间,显著大于此次重构的开销6.34 ms,因此针对这种情况硬件加速时应当选择进行重构;然而对于可重构区RP2采用初始硬件架构计算Conv_2耗时29.74 ms,若重构为使用F(2×2,5×5)计算核心,Pm=1、Pn=3并行展开的硬件架构,计算时间为21.13 ms,获得8.61 ms的性能提升,但是此时重构开销为8.19 ms,重构带来的性能提升基本被重构开销耗尽,此种情况下重构并不是一个很好的选择。同理,针对卷积层Conv_3和Conv_4的硬件加速,由于都使用3×3卷积核,且并行策略一样,若进行重构并不会获得额外的性能收益,反而会因重构开销存在增大整体的计算时间,因此针对这种情况硬件加速时应当选择不进行重构。
4 总结与展望
本文针对动态重构硬件加速时,动态重构开销在设计初期难以测算问题,提出一个动态重构开销的估算模型,可以在可重构系统设计早期获得精准的重构开销,避免冗长的设计流程,加速可重构系统的设计。本文不同于以往研究方法,将影响重构开销的诸多因素抽象到对比特流的分析,总结比特流格式来估算比特流大小,并基于此构建的重构开销模型准确度更高,并通过实验在XilinxVC709FPGA平台针对神经网络计算方法如Winograd算法、FFT算法、GEMM算法和加密算法如AES、DES进行了动态重构模式下的硬件部署,实验结果表明该模型的总体平均相对误差仅为1.3%,预测精度比较符合实际的需求。同时该模型可以便捷地应用于现代动态重构硬件加速中,具有较高的工程实用价值,使用该模型对Alexnet神经网络的卷积层硬件加速时重构是否带来性能收益进行了实验分析,为动态重构设计者在设计初期提供一个方案来估算设计的合理性,可以有效缩短实验周期。
本文提出的运行时重构性能开销模型,是通过FPGA内部配置访问端口ICAP来估算出重构的时间开销,接下来的研究可以从比特流的配置过程入手,对FPGA的配置时间开销进一步研究。同时实验中也发现动态重构的开销不容忽视,对硬件加速器的性能影响比较大,接下来研究可以从减少重构开销入手,如配置比特流压缩、提升ICAP配置端口带宽等。
猜你喜欢
卫星应用(2022年7期)2022-09-05
卫星应用(2022年3期)2022-05-23
哈尔滨工业大学学报(2022年5期)2022-04-19
卫星应用(2022年1期)2022-03-09
摄影世界(2022年1期)2022-01-21
北京航空航天大学学报(2021年9期)2021-11-02
中国生殖健康(2020年7期)2020-12-10
电子制作(2019年13期)2020-01-14
环球慈善(2019年6期)2019-09-25
电子制作(2019年11期)2019-07-04
