
基于域名系统知识图谱的CDN域名识别技术
2022-03-22 03:36闫志豪刘京菊郭兵阳
计算机工程与应用 2022年6期
闫志豪,刘京菊,郭 徽,郭兵阳
1.国防科技大学 电子对抗学院,合肥 230037
2.网络空间安全态势感知与评估安徽省重点实验室,合肥 230037
网络技术的飞速发展和用户体量的急剧增长在给互联网内容提供商(Internet content provider,ICP)带来机遇的同时也带来了巨大的挑战。CDN技术的出现,极大地改善了由广分布、大体量用户访问所带来的网络拥堵、服务器过载和高延迟等问题。目前全球CDN服务商在世界各地部署的数万台服务器在提供服务的同时也构成了互联网基础设施的关键部分。CDN的大范围应用也给网络空间带来了新的安全挑战,2019年Nguyen等人[1]发现了一种针对CDN的新型缓存系统中毒攻击,2020年Li等人[2]提出了一种针对CDN的HTTP范围请求放大攻击。CDN域名识别作为检测、防御针对CDN攻击的第一步,同时也是网络空间测绘的重要一步,对于了解CDN的体系结构、业务性能和技术演变至关重要。
目前国内外学者针对CDN域名识别提出的方法主要有:Huang[3]和Adhikari[4]等人使用规范名称记录(canonical name record,CNAME)的特征对采用指定服务商的CDN域名进行识别。Guo等人[5]使用服务器返回的HTTP错误消息来发现CDN节点。Böttger等人[6]通过猜测CDN边缘服务器的命名规则来构造主机名,并执行DNS探测以获得更多的节点IP。这些方法虽然简单有效,可以获取一个或几个特定CDN服务商的数据来衡量CDN的规模和性能,但它们的识别范围非常有限,只能识别部分特定的CDN域名。
Chen等人[7]针对CDN域名和Fast-Flux(FF)域名区分困难的问题,基于长短期记忆网络(long short-term memory,LSTM)网络,根据域名特征、经验信息、地理和时间相关特征对FF域名和CDN域名进行了区分。Li等人[8]根据域名系统记录相关特征基于机器学习识别CDN域名,但需要多地域多节点对目标进行数据获取,并手工识别大量CDN域名构建样本集。
因此,如何以较低的代价对大规模的CDN域名进行识别仍是一个亟待解决的问题。由于CDN技术依托于域名系统实现,通过对域名系统的相关记录和数据进行分析,能够获取CDN域名特征进而进行有效识别。域名系统作为互联网重要基础设施之一,数据和记录类型多样,网络结构之间存在复杂的依赖关系,而知识图谱(knowledge graph,KG)作为一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法,擅长对多源异构数据和复杂关系进行表征和利用。
因此,本文针对CDN域名识别的问题,引入知识图谱构建、知识推理等关键技术,提出构建域名系统知识图谱方案。旨在将涉及域名系统的多源异构数据通过知识图谱进行统一利用和分析,进而在域名数据中寻找CDN服务特征并进行大规模CDN域名识别。
1 CDN特征分析
1.1 CDN系统概述
域名系统作为广泛应用于互联网的分布式名称解析系统,提供了域名和IP地址之间的转换服务。CDN技术基于域名系统,在其上采用分布式方式构建用于承载业务的服务器集群。通过中央平台的负载均衡、内容分发调度等功能模块,用户可以就近获取所需内容,降低内容拥塞,提高用户访问的响应速度和命中率[9]。
启用CDN服务的域名解析结构如图1所示。用户请求访问域名时,域名权威DNS会根据配置好的CNAME记录,使其跳转至CDN系统,转而请求其CNAME记录的IP地址。然后CDN系统会根据用户位置,采用全局负载均衡技术返回距离用户较近的缓存内容服务器的IP地址。
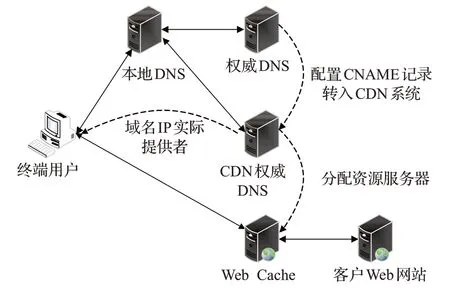
图1 CDN服务结构Fig.1 CDN service architecture
因此CDN服务商通常维护着内容和DNS两种类型不同的服务器。内容服务器复制了原始Web服务器上的内容,对客户的请求进行响应。DNS服务器向客户返回距离最近的内容服务器。
1.2 CNAME模式特征分析
CNAME是域名系统的一种记录,用于将一个域名映射到另外一个域名,域名解析服务器遇到CNAME记录时会以映射到的目标重新开始查询[10]。
根据CDN域名使用CNAME记录转入CDN系统的特征,本文通过对Alexa前100万域名及其“www.”子域名的CNAME记录进行查询获取,根据实际数据统计分析其模式特征和对应用途,在其中寻找CDN服务特征。
1.2.1 子域名及其CNAME的主域分析
(1)子域名和其CNAME同属一个主域
在共计93.3万子域名中共有35.7万域名拥有CNAME记录,其中有26.1万条记录的子域名和CNAME同属一个主域,且有24.9万条将CNAME记录设置为子域名的主域名。
该类型CNAME的设置主要是为了便于在同一个IP地址上运行多种服务的情况,例如,如果需要同时运行文件传输服务和Web服务,则可以使用CNAME记录把ftp.example.com和www.example.com都指向example.com。后者拥有指向IP地址的A记录,当需要更改时,直接更改example.com的A记录便可修改整个服务对应IP地址的映射。
(2)子域名和其CNAME属不同主域
在9万多条子域名和其CNAME属不同主域的记录中,大于20个子域名的CNAME指向同一域名的记录超过2.5万条。表1中列出了被指向次数最多的10个域名。

表1 CNAME被指向次数最多的10个域名Table 1 Top 10 domains with CNAME record
此类型的CNAME记录,主要目的是实现某种特定的功能。例如在使用Google企业套件和Google AppEngine时,如果要绑定自己申请的独立域名,就需要将域名CNAME解析到ghs.google.com,因此出现6 795次的CNAME记录指向域名ghs.google.com。
1.2.2 CNAME字符表现特征
针对子域名和其CNAME是否同属一个域的情况,分别对子域名和CNAME域名中的字母、数字、点字符和连字符进行统计,其结果如表2所示。
为了更直观地展现它们的区别,图2中将平均数字个数和平均连字符个数放大了10倍。可以明显得出同属一个主域的情况下子域名和其CNAME的各类字符串统计特征无过大差别。但属于不同主域时CNAME的各项字符统计特征均高于其他几项。
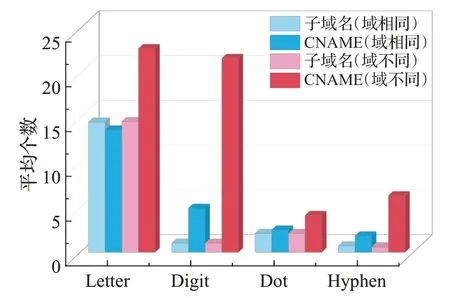
图2子域名和CNAME字符统计特征Fig.2 Subdomain and CNAME character statistics feature
同属一个域的情况下,有超过95%的CNAME记录设置为域的主域名,因此子域名和CNAME的字符统计特征无异常。但在属不同主域的情况下,CDN服务商维护着大量的服务器,域名采用CDN服务时,为了方便管理和映射,通常会特征化内容服务器域名。因此,内容服务器在域名构成上表现出与普通域名不同的特点,其域名部分包含了更多的字母、数字、点和连字符。该特征是判断CDN域和CDN域名的一个重要特征。这种情况下也可细分为两种特征化内容服务器域名的情况:
(1)基于子域名特征化内容服务器域名
根据子域名的字符特征,即使用子域名的部分或全部字符串作为内容服务器域名的前缀。如图3所示,针对CDN服务商Cloudflare的CNAME记录进行统计分析,发现子域名的字符长度表现特征和CNAME长度表现特征相同,原因为Cloudflare的内容服务器域名设置规则将子域名作为.cdn.cloudflare.net的前缀。例如查询子域名www.shein.com的CNAME记录为www.shein.com.cdn.cloudflare.net。
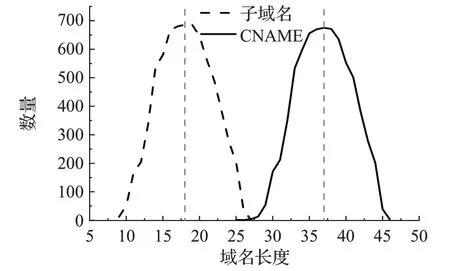
图3 采用Cloudflare的子域名和CNAME域名长度Fig.3 Subdomain and CNAME domain length in Cloudflare
(2)随机生成字符串作为内容服务器域名特征
部分CDN服务商使用随机生成字符串作为内容服务器的前缀。如图4所示,针对CDN服务商Incapsula的CNAME记录进行统计分析,发现CNAME长度集中在20和22个字符上,原因是其设置CNAME的规则为随机生成长度5或者7的字符串作为.x.incapdns.net.incapdns.net的前缀,例如子域名www.kooora.com的CNAME记录为foosc.x.incapdns.net.incapdns.net。
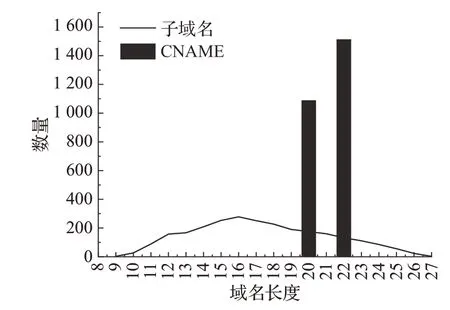
图4 采用Incapsula的子域名和CNAME域名长度分布Fig.4 Subdomain and CNAME domain length in Incapsula
1.2.3 CNAME主域重合
由于域名是一种不可再生的有限资源,同时为了便于记忆和表现CDN服务商的特征,CDN服务商在采用特征化前缀的情况下,其CNAME域名后缀通常使用其拥有的特定域名。表3列出了CDN服务商Akamai和Amazon Cloudfront的CNAME设置常用后缀。因此,当CDN服务提供商为较多域名提供服务时,这些域名的CNAME记录的后缀会集中到几个主域上。该特征也是判断CDN域和CDN域名的一个重要特征。
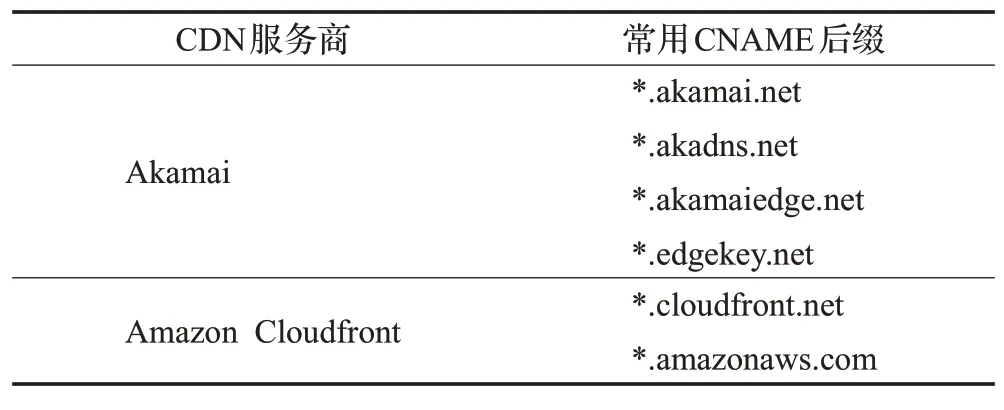
表3 Akamai和Amazon Cloudfront常用CNAME后缀Table 3 Akamai and Amazon Cloudfront CNAME suffixes
2 构建域名系统知识图谱
2.1 知识图谱构建过程
知识图谱于2012年5月17日被Google正式提出[11],主要是为了提高搜索引擎的搜索能力,在搜索时增强搜索质量。知识图谱由节点和边组成,节点可以是实体或抽象的概念,边表示实体的属性或实体之间的关系。知识图谱打破了不同场景下的数据隔离,为实际应用提供基础支持[12]。
针对知识图谱的覆盖范围也可分为通用知识图谱和领域知识图谱。
不同领域知识图谱数据的来源、格式、应用和需求各不相同,因此没有一套通用的标准和规范的构建方法。根据领域知识图谱和通用知识图谱的互通之处,其生命周期可以分为六个阶段[13],如图5所示。
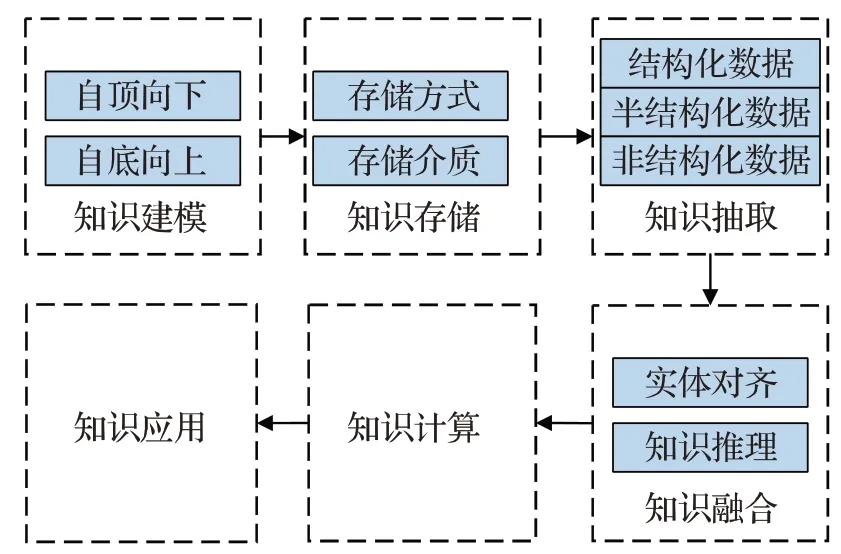
图5 领域知识图谱生命周期Fig.5 Domain knowledge graph life cycle
知识建模是建立知识图谱本体(Ontology)的过程。本体是指一种“形式化的,对于共享概念体系的明确而又详细的说明”,本质上是对特定领域之中某套概念及其相互之间关系的形式化表达。知识建模通常有两种构建方式[14]:一种是先从最顶层概念构建本体模型,逐步细化后添加实体的自顶向下(Top-Down)方法。另一种则是自底向上(Bottom-Up)的方法,即先对实体进行归纳,而后形成底层概念,并逐步向上抽象形成本体。
知识存储是针对构建完成的本体指定底层存储方式,根据领域特征选择合适的存储方案和存储介质。而后针对不同来源的不同数据进行知识抽取,形成知识并进行存储。最后将知识进行对齐、合并,形成统一的标识和关联来提高知识图谱的整体质量,进而形成最终的知识图谱。
知识图谱通过构建揭示实体之间关系的语义网络,实现对现实世界的事物及其相互关系进行形式化的描述,提供了一种更好地组织、管理和理解互联网海量信息的能力[15]。例如,贾焰等人[16]提出了一种构建网络安全知识图谱的实用方法。Najafi等人[17]通过构建DNS日志知识图谱来检测威胁。
因此针对域名系统构建知识图谱可将多源异构数据构建成一个整体,进而对域名系统的多源数据和复杂网络结构进行分析和利用。
2.2 本体构建
本文针对域名系统构建领域知识图谱,因为域名系统涉及的实体和关系较为清楚,采用了自顶向下的方法:首先构建域名系统本体,基于构建的本体进行数据收集并从中抽取知识用以构建域名系统知识图谱。本文参照斯坦福大学提出七步法[18]构建域名系统本体。
Syed等人[19]提出了一种统一的网络安全本体(unified cybersecurity ontology,UCO),旨在支持网络安全系统中的信息集成和网络态势感知。但是其抽象程度较高,侧重点不在于域名系统,本文仅复用UCO的部分类和属性。
随后确定域名系统的实体类和属性及其约束。针对域名系统所涉及的要素,考虑域名系统的解析流程和层次特性,创建如图6所示本体模型,其中各字段所表达含义如表4所示。

表4 域名系统本体的节点和关系Table 4 Nodes and relationships of DNS ontology
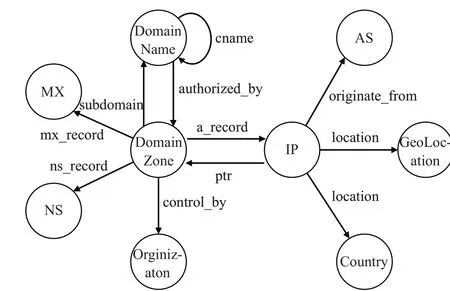
图6 域名系统本体模型Fig.6 DNS ontology model
2.3 CDN域名推理规则
知识图谱使用KG表示,定义KG={<E,R,P>},其中:
(1)E={ei|i=1,2,…,n},E是实体(Entities)的集合,如Country、Domain、Organization等。
(2)R={rij|i,j=1,2,…,n},R是关系(Relationships)的集合,rij表示从节点ei到节点ej的关系,如Control、OriginateFrom、Location等。
(3)P={<ei,pj,vk>},P是实体属性(Properties)值对的集合。<ei,pj,vj>,表示实体ei的一项属性pj的值为vk。
本文将CDN域名作为SubDomain节点的一种属性进行表示,从而CDN域名的识别问题可以转化为域名系统知识图谱SubDomain节点的属性推理问题。当SubDomain节点ei是CDN域名时,为其添加P={<ei,DomainClass,CDN>}。
对于CDN域名的判定,根据CDN服务特性,首先排除域名和其CNAME同属一个主域的情况。其次根据CNAME主域重合的特征,识别出可能作为CDN服务商管辖的主域,进而根据CNAME的字符特征确定。
(1)CNAME主域重合特征,可分为三种情况如图7所示。分别为:
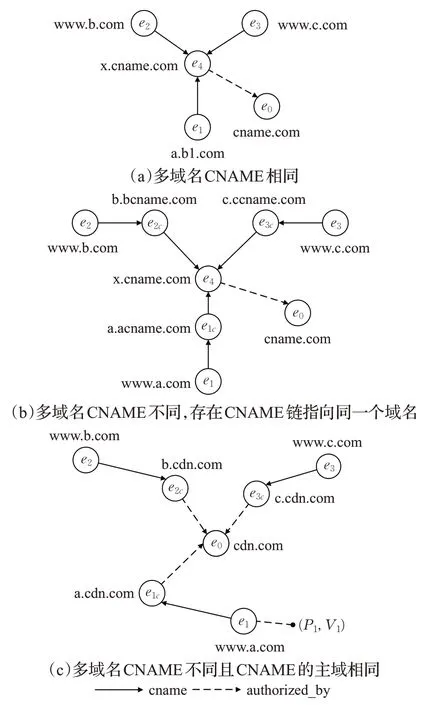
图7 CNAME主域重合的三种情况Fig.7 Three situations of CNAME primary domains overlap
①多个域名的CNAME记录指向同一个域名,该情况不属于CDN域名特征。
②多个域名的CNAME记录不同,但是存在CNAME链使其指向同一个域名,类比情况①不属于CDN域名特征。
③多个域名的CNAME不同,且不存在CNAME链,CNAME的主域相同,该情况属于CDN域名特征。
根据三种可能出现的情况,定义了CDN服务商主域的推理规则:
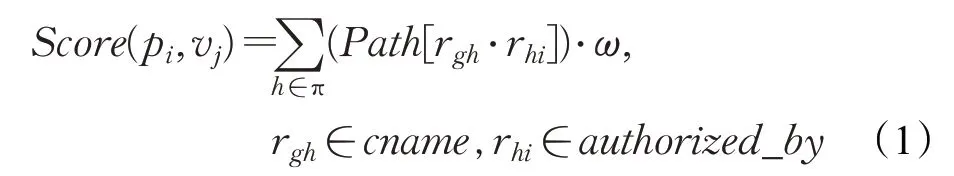
式中,pi,vj代表域名节点ei的属性值对,针对Domain Zone节点ei,求所有通过authorized_by关系rgh到达节点ei的节点eh,同时要求eh是通过cname关系rhi被指向的cname域名。每存在这样一条路径便会增加节点ei是CDN域的可能性。π为所有通过关系authori zed_by可达ei的节点,ω是路径带来的可能性增量。如果Score(pij,vj)≥τ,τ为阈值,则判定节点ei是CDN域。判断域名是否属于CDN域名则判断其CNAME记录是否设置为CDN域下的子域名。
3 实验分析
3.1 知识获取
针对CDN服务的性质,个人和组织日常访问频次较多的域名开启CDN服务的可能性较大,所以本文基于Alexa的前100万域名进行数据获取,实例化知识图谱。初始化域名共包含91万个主域名和2.4万个子域名。其数据集中针对CDN域名一般开启在子域名上的特征,本文将910 015个主域名进行扩展,加入其“www.”子域名。模型实例初始域名共包含91万主域名和93.4万子域名。
从初始域名开始,对DNS系统负责解析的域名服务器进行数据收集,主要包括A记录解析Web服务器、NS记录解析权威域名服务器、MX记录解析电子邮件服务器。通过搭建本地域名服务器,使用dig命令对域名相关记录信息进行查询。
针对共93.3万域名,对其A记录进行查询,共获取48万个唯一的IP地址,同时添加110万条域名和IP对应A解析记录的关系。
对于域名的名称服务器,获取NS记录中所有的名称服务器,并添加和权威域名服务器的关系。针对原始域名的91万个域空间,共获取到权威域名服务器11.4万个,名称服务器21万个。添加权威域名到名称服务器的关系84.9万个。
对93万个子域名进行CNAME记录查询,共发现35万个域名存在CNAME记录,其中子域名的主域和CNAME域名主域相同的有26万条记录,不同的有9万条数据,将其CNAME添加为子域名节点,并添加CNAME关系。
MX记录存储电子邮件服务器的地址,对电子邮件客户端向收件人发送电子邮件时提供IP解析记录。对于每一个域,获取其MX记录,添加电子邮件服务器节点和域名到电子邮件服务器的MX解析记录的关系。
自治域(autonomous system,AS)是自主决定内部网络协议的IP网络和路由器的集合。使用欧洲网络协调中心(RIPE network coordination centre,RIPE NCC)的RIPEStat(Information about specific IP addresses and prefixes.https://stat.ripe.net/.)数据库服务查询IP所属的AS自治域。对于每个AS,创建一个AS节点,并添加一条IP地址到AS自治域的originate_from关系。通过MaxMind公司的GeoIP(IP Geolocation and Online Fraud Prevention.http://dev.maxmind.com/.)数据库,将国家和组织信息加入知识图谱中。对每个IP查找其所属组织和其地理位置,并通过地理位置和国家相关联。
3.2 生成域名系统知识图谱
针对域名系统的特征,主要对域名系统中的IP地址、DNS服务器、机构、地理位置等相关数据进行获取和处理。由于网络基础设施和相关数据类型的确定性,涉及到的大多数据类型均为结构化数据采用基于规则与字典的方法进行实体抽取。
根据定义好的域名系统本体和收集分析得到的相关知识,进行域名系统知识图谱构建。域名系统知识图谱采用NoSQL数据库Neo4j进行存储,基于Neo4j实现的数据模型具有灵活可变的特性。模型扩展只是在数据模型中创建额外的节点、关系和属性,不需要对模式进行更改或重新对数据库进行规范化。图形模式匹配查询可以用Neo4j所具有的查询语言(Cypher)表示。
如图8所示,通过Neo4j图数据库查询和baidu.com域相关的节点,共包含15个DNS域、4个NS域名服务器、3个MX域名服务器、7个子域名、2个IP地址等34个节点和68条关系。由此可见,域名系统相关数据类型较多,且关联关系丰富,使用知识图谱能够较好地将各类数据进行统一建模表征,实现较好的展现效果和更快捷的查询。
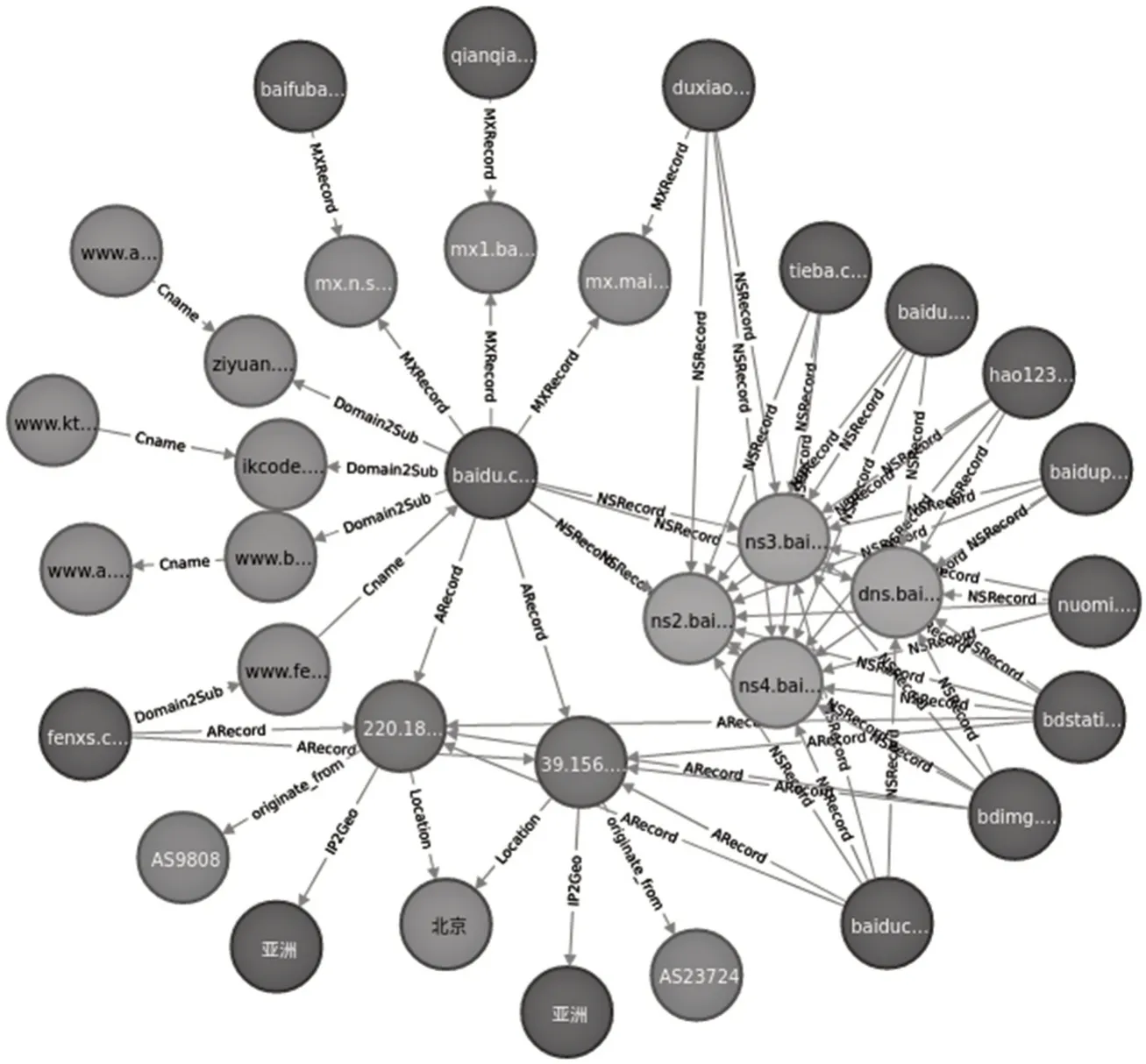
图8 baidu.com域在知识图谱中的展示实例图Fig.8 DNS zone baidu.com in knowledge graph
3.3 识别CDN域名
针对Alexa前100万域名构建的域名系统知识图谱,在其之上进行CDN域名识别,共识别出CDN域名37 600个,涉及170个可能为CDN域名服务商的TLD,其中出现次数最多的10个主域名如表5所示。
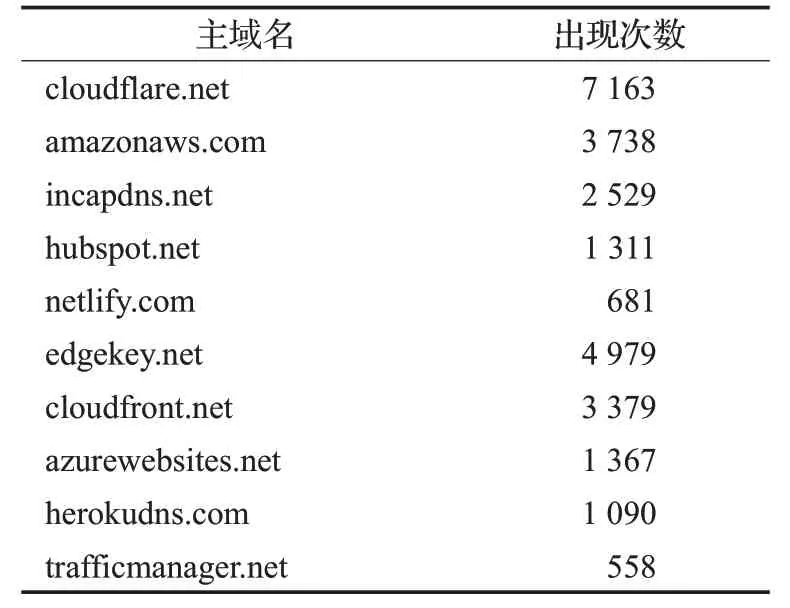
表5 出现次数最多的10个主域名Table 5 Top 10 DNS Zone
对识别结果的评价,为了兼顾测试集的多样性和准确性,避免测试集中存在较多非CDN域名对实验结果产生大幅度影响。
本文根据各种不同的类型,选取不同数量的域名构成样本集。分别从算法识别出的CDN域名、没有CNAME记录的域名和拥有CNAME记录且识别为非CDN域名中各随机选取600、200和200个,共计1 000个域名构成测试样本。
并通过参考第三方CDN识别网站和基于多地域Ping的人工识别的方式对测试样本进行CDN域名识别,最终形成测试集。从而计算模型识别结果的准确率(Precision)、召回率(Recall)和F1值,结果如表6所示。

表6 识别结果Table 6 Recognition result
在构成的测试集中,识别的准确率、召回率和F1值均达到85%以上,证明了本文基于知识图谱在大规模数据集上可以达到较好的识别结果。同时如表7所示,和其他方法进行对比,在不需要手工构建大量样本集的前提下便可实现大规模不限定范围的CDN域名识别。同时本文所有数据仅基于单节点的DNS记录查询,可以实现以更小的代价达到CDN域名检测的目的。
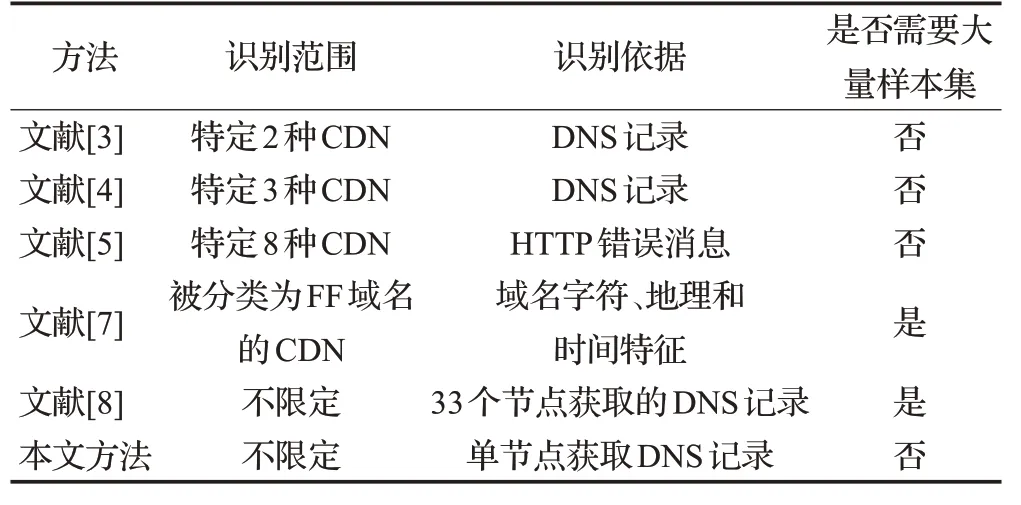
表7 方法对比Table 7 Method comparison
4 结束语
本文针对CDN域名大规模识别的问题,提出基于域名系统知识图谱的CDN域名识别技术。通过知识图谱可以对多源异构数据进行统一建模利用的特性,构建域名系统知识图谱,针对域名系统相关数据进行深入分析寻找CDN域名特征,从而定义知识图谱的属性推理规则,达到识别CDN域名的效果。实验表明,在构建的百万节点规模的知识图谱之上,可以达到较好的识别精度,并且能够对CDN攻击进行影响范围的评估,用以针对性地进行防御。未来工作可以考虑将域名系统扩展到网络空间基础设施,构建覆盖面更广的知识图谱,丰富知识图谱和推理规则,以达到更精准的CDN域名识别和更深层次的知识挖掘。
猜你喜欢
军民两用技术与产品(2022年3期)2022-06-05
福建江夏学院学报(2021年6期)2021-08-10
哈哈画报(2021年10期)2021-02-28
江苏教育研究(2020年2期)2020-04-10
制造业自动化(2017年2期)2017-03-20
中国期刊年鉴(2015年0期)2015-01-19
软件和集成电路(2014年7期)2014-12-31
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
互联网天地(2012年6期)2012-03-24
