
基于Encoder-Decoder框架的双监督机制自然场景文本识别
2022-03-22 03:35陈佐瓒丁小军甘井中
计算机工程与应用 2022年6期
陈佐瓒,徐 兵,丁小军,甘井中
1.玉林师范学院 计算机科学与工程学院,广西 玉林 537000
2.南京师范大学 地理科学学院,南京 210023
3.中南大学 计算机学院,长沙 410083
场景文本识别是计算机视觉领域中重要的研究内容,在许多商业应用(街牌阅读、盲人辅助技术、机器人导航)中取得了显著的成功,识别场景文本对于场景理解具有重要意义。尽管对光学字符识别(OCR)专家们已对传统的扫描文档的识别进行了数十年的研究,但是在自然场景文本识别方面仍然是一个难题[1-4]。在真实场景文本识别任务中,许多图像都很复杂,如图1列出了字体复杂或者背景复杂图像的一些示例。

图1 五种复杂场景下自然场景文本Fig.1 Natural scene text in five complex scenes
场景文本识别方法大致可分为两类:基于字符的识别和基于整词的识别。(1)基于字符的识别[5-6]通常涉及两个步骤:字符分割和单词识别。它试图在字符边界处分割输入文本图像以生成一系列原始片段,每个片段是字符或字符的一部分,将字符分类应用于候选字符并将上下文信息组合到其中以获得识别结果。
虽然这种方法已经完成了手写体识别,但是场景文本识别中的表现受到了字符分割困难的严重影响。
(2)基于整词的识别[7-10]将文本识别视为序列标记问题,通过简单地将文本图像切割成相等长度的帧并标记切片帧来避免困难的字符分割问题。在基于整词的识别方法中,Shi等人[11]提出了一种空间变换器网络来自动纠正单词图像。Lee等人[12]提出一种端到端的学习程序来处理不规则形状的文本实例。这些方法非常有效,可以极大地缓解不规则文本识别的问题,但是大多数方法都倾向于从不同角度纠正图像。这可能导致更多的手动设计,例如预处理要求和网络复杂性增加。
现在的主流技术多是采用基于整词的识别方法,通过CNN/RNN结合Attention mechanism(注意力机制)和CTC(连接时间分类)进行字符识别,并实现了显著的性能提升[13],如图2(a)和(b)所示。通常,文本识别器被设计为Encoder-Decoder(编码-解码)框架。在编码阶段,通过CNN、LSTM、GRU将图像变换为特征向量序列[14-16]在解码阶段,利用RNN,连接主义时间分类(CTC)或注意力机制等将编码特征向量解码为目标字符串[17-18]与图2(c)中基于单个的字符检测方法相比,(a)和(b)的方法识别精度更好,有效避免了单个字符识别错误导致单词整体的识别错误的情况。许多现有的场景文本识别方法依赖于预定义的词典[19-20],其通过约束输出,极大地提高了准确度。虽然使用预定义字典提高了场景文本识别精度,但是由于预定义字典过大,增加了算法的复杂度。为了解决这些问题,无约束的文本识别方法被提出[21-23](不受约束指任何单词都可以被识别),具有代表性的是图2(d)中将基于CNN的2D图像编码器直接连接到基于注意力的1D序列解码器,从而避免使用中间序列表示的方法。在本文中,专注于无约束的文本识别。
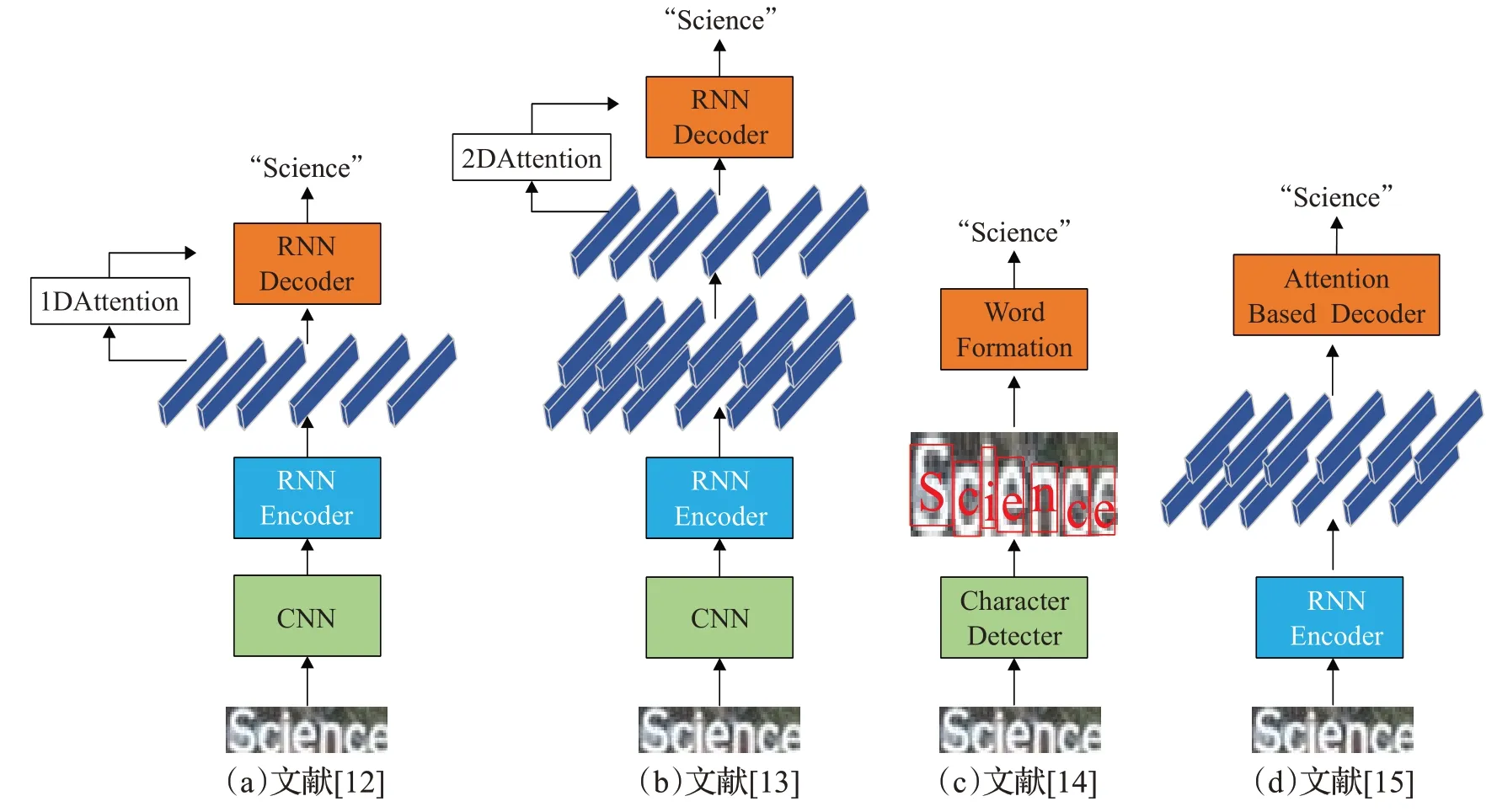
图2 五种场景文本识别网络Fig.2 Five scenes text recognition networks
提出了一个新的无词典的场景文本识别框架识别网络。将该注意力机制与双监督网络集成在一起,进行文本识别。与现有方法不同,这两个监督分支,分别处理明确和不明确的上下文语义信息。这两个监督有相互加强的效果,它们是共同训练的。此外,由于在整个框架中集成了一个文本注意模块,强制该模型更加关注文本区域,不需要对弯曲的文字图像进行矫正,大大提高了模型的效率,所提出的方法在几个基准测试中都得到了先进的识别效果。
1 改进模型设计
1.1 模型的框架
本文的识别框架如图3所示,它是一个端到端的可训练网络。首先,通过可变形卷积提取每个图像的特征表示且集成了一个专用的文本注意模块,使模型专注于文本区域。其次,将最终提取的特征重新转换为特征序列并送入两个分支来。一个分支是上下文语义建模分支,它使用双层双向GRU来捕获上下文语义信息,另一个分支是监督增强分支,它由字符分类器组成,主要用于处理字符级别的隐含语义信息。
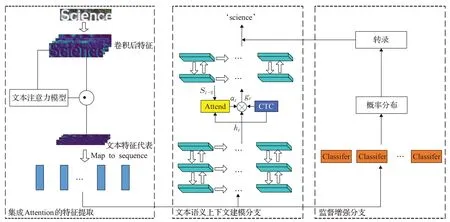
图3 本文模型网络结构Fig.3 Network structure of this model
由于改进的网络变得更加复杂,为了避免梯度消失的问题,已经应用了一些残差块。每个残差块由两个3×3卷积和一个跳级连接组成。为了更好地应用于实际工程上,在网络中应用了自适应最大池化层。这些层能够根据输出特征图的所需大小自动调整内核大小其中in表示输入内核大小,out表示输出内核大小。卷积层结构的骨干网络如图4所示。所有激活功能均为PReLU,不修改基线模型的递归层和转录层。
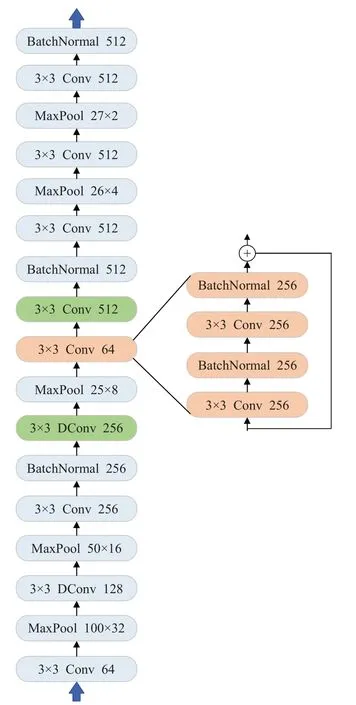
图4 骨干网络Fig.4 Backbone network
1.2 模型的工作流程
1.2.1 集成Attention mechanism的特征提取
从整个图像的全局特征角度设计Attention mechanism,这意味着它可以从全局信息中选择性地关注感兴趣的特征。通过可变形卷积网络[24]提取每个图像的特征表示,记为FeatureBackbone。获取FeatureBackbone后,将其应用文本Attention模块如图5所示。因此,将这些可变形层集成到基线模型中,以增强其焦点。图像中每个位置p0的2D卷积可以表示为:
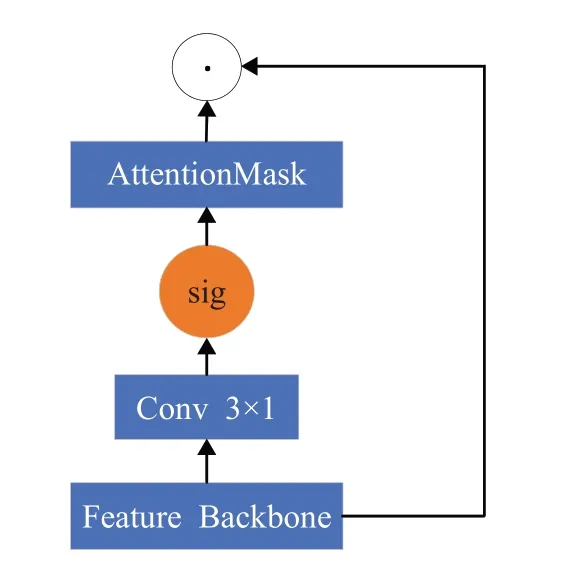
图5 文本注意力模块Fig.5 Text attention module
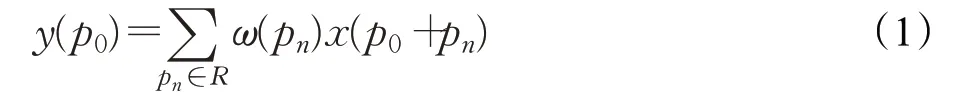
在训练阶段可以自动学习采样位置的偏移量。可变形卷积的过程如图6所示。很明显,可变形卷积的接受域的形状可以更好地集中在文本区域,能够处理网络的不规则文本。但是,替换并不是任意的。浅层通常会提取一些基本信息,例如边缘、形状和纹理。
图6 可变性卷积示意图Fig.6 Deformable convolution schematic
1.2.2 上下文建模分支
由于文本中的高级语义信息,上下文级建模对于文本识别非常重要。对于文本,来自前向和后向的上下文都是有用且重要的。因此,提取的特征序列被送到双层双向GRU中以进行上下文级建模。双层GRU有效捕获双向长期依赖上下文语义信息。GRU的输出序列是h={h1,h2,…,hw},其中W是输入序列长度。每个输出序列将放入一个完全连接的层,然后是字母表上的softmax分类器。因此,该分支最终将为每个特征序列生成字母表上的概率分布,然后概率分布将输入到转录层以生成输出标签。
1.2.3 监督增强分支
对于自然场景中的文本,其中一些文本具有明确的语义信息,例如英语单词。然而,部分专有名词只是字符的简单组合而没有字符之间的上下文关系。同时,具有相同含义的文本可能在图片中呈现不同的大小、颜色、格式等状态,这意味着细节特征极为重要。因此,提出监督增强分支来解决这个问题,该问题对文本进行字符级建模,旨在获得每个字符的特征。
提取的特征序列被送到由字符分类器组成的分类层。对应于一个图像区域的每个特征序列通过softmax分类器在字母表上分类。最后,将分类概率分布输入到转录层。该分支不考虑特征序列之间的上下文关系,每个特征序列是独立的。因此,该分支可以充分利用每个序列并为每个字符学习精确的特征。
2 实验设计
2.1 数据集及评价指标
Synthetic Dataset:此数据集是自动合成的800 000张文本图像,该文本图像是随机选取通用词典中的单词本身进行复杂化处理,并进行背景复杂化填充,每张图像大约10个单词。
ICDAR 2013:这是广泛使用的场景文本数据集,此数据集中的图像文本内容比较清晰,大都是水平的文本。有229个用于训练的图像和233个用于测试的图像。
ICDAR 2015:此数据集中大多数文本是不规则的(定向、透视和模糊)。有1 000张图片用于训练和500张图像进行测试。
III5K:此数据集是一个大型的多语言文本数据集,包含7 200个训练图像,1 800个验证图像和9 000个测试图像。
AddF2k:它包含1 715张接近水平的图像,所有图像用于训练阶段。
2.2 实验结果
为了加速训练,在每个池化层之加入Batch Normalization层,并且始终使用ReLU非线性激活函数。网络训练采用RMSpro随机梯度下降算法。初始学习率设为0.001,beta1为0.9,beta2为0.999,训练2 000个epoch停止。评价指标采用的是正确率accuracy,计算方法:

其中,M代表数据集中文本图片识别完全正确的样本数量,N代表数据集总样本数量。
下面列出本文的算法和当前的几个代表性的主流算法在几个公开数据集上的横向对比,其比较结果如表1所示。很明显可看出本文的算法在以下标准数据集上效果比一些主流算法较好。
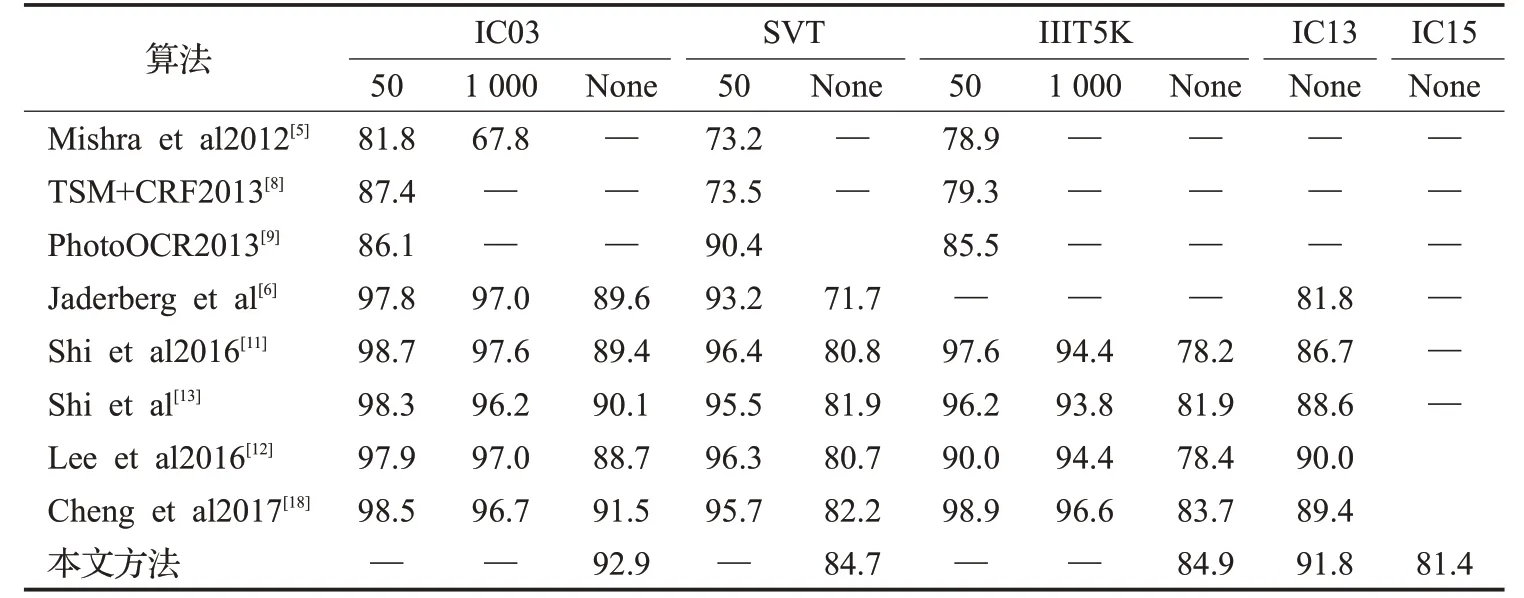
表1 场景文本识别在标准数据集上的准确率Table 1 Accuracy of scene text recognition on standard data set %
一些正确的识别结果示例如图7所示。第一行显示本文方法在数据集IIIT5K中部分图片的识别结果,第二行显示在数据集IC13中的识别结果,最后一行显示SVT中的识别结果。这些图像非常具有挑战性,但都被完全识别正确,这表明了所提方法的有效性。

图7 样本识别结果Fig.7 Samples of identifying results
为了探索本文中的Resnet101网络和注意力机制对场景文字识别的效果的影响,对单独使用普通VGG16的卷积部分和单独使用Resnet101的卷积部分分别集成注意力机制进行定量分析。同样,为了体现Attention机制的效果,还在普通VGG16的卷积部分集成了CTC机制,来验证Attention机制的有效性。分别在IIIT5K、SVT、IC13、IC03数据集下进行对比,各方法识别率如表2所示。
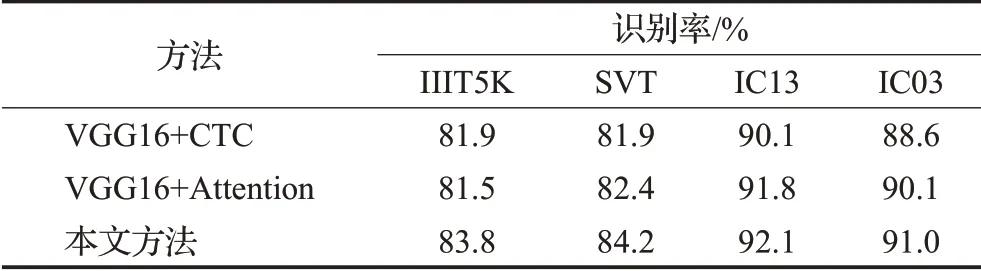
表2 注意力机制的比较Table 2 Comparison of attention mechanisms
3 结束语
提出了具有注意机制的双监督模型,该模型有两个分支监督,可以识别任意长度的文本,能够端到端地训练且不受字典约束。从整个图像全局特征的角度设计了一个文本注意机制模块。此文本注意模块集成在功能主干Resnet101中,使得特征提取过程有选择地集中在文本区域上。提取的特征使用双层双向GRU来进行上下文级建模。在提取的特征表示上添加一个监督增强分支,以处理字符级别不明确的上下文语义信息。这个分支可以强制模型为每个角色获得更好的特征。在三个基准上与其他方法进行对比实验,实验结果表明了所提方法的有效性。
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机系统应用(2021年10期)2022-01-06
北京航空航天大学学报(2021年9期)2021-11-02
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年13期)2020-01-14
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
学生天地(2019年28期)2019-08-25
电子制作(2019年11期)2019-07-04
