
基于强化依赖图的方面情感分类
2022-03-21 09:45宋红阳朱小飞郭嘉丰
太原理工大学学报 2022年2期
宋红阳,朱小飞,郭嘉丰
(1.重庆理工大学 计算机科学与工程学院,重庆 400054;2.中国科学院 计算技术研究所,北京 100190)
随着社交媒体和大数据的快速发展,情感分类任务已经从计算机科学研究延伸到生产生活的方方面面,其巨大的发展前景和商业价值引起整个社会的共同关注。特别是商品评论,可以为买家购买商品提供参考信息,也是卖家挖掘商品不足从而进行改进的重要依据,而简单的分析用户对整个商品的情感倾向已无法满足商品改进的需求,针对不同方面挖掘用户更细腻的情感倾向,已经成为研究人员关注的热点。
方面情感分类(aspect-based sentiment classification,ABSC)作为情感分类的子任务,旨在挖掘文本在不同方面表达的更细腻的情感倾向,例如积极(positive)、中性(neutral)和消极(negative)[1]。如图1所示,句子“Great place to relax and enjoy your dinner.”的方面词为“place”和“dinner”,根据语义分析,“place”的情感为积极的,认为这个地点是让人放松的好地方;而“dinner”则是中性的,即语句中没有对晚餐做出评价。

图1 句法依赖树Fig.1 Syntactic dependency tree
方面情感分类的核心任务是在文本中找到与方面相匹配的情感表达。TANG et al[1]提出使用注意力机制(Attention)和循环神经网络(recurrent neural network,RNN)建立上下文信息与方面词之间的关系,通过学习与方面相关的文本特征表示来实现情感分类;ZHANG et al[2]使用句法依赖树(dependency tree)构造简单的句法依赖关系,并使用图卷积神经网络(graph convolutional network,GCN)[3]融合句法信息和远距离单词之间的依赖关系,通过基于检索的注意力机制计算每个上下文信息的重要性;CHEN et al[4]将句法依赖树和自诱导的方面特定图联系起来,通过自注意力机制结合句法依赖图和潜在图的相关信息,随后提取方面特征,计算明确方面的注意力用于方面情感分类。HOU et al[5]认为句法依赖树生成的结果对情感分类具有显著的影响,而不同的句法解析器生成的句法依赖树不同,提出图的整体学习策略,将多个依赖树进行融合得到更有效的依赖关系图。
现有的方面情感分类模型对句法依赖树的准确率要求较高,但是句法依赖树不可避免包含与方面情感分类无关的噪音信息,这些噪音信息具体可分为两种:一是与方面无关的噪音信息,当方面词为“place”时,“great”与“place”之间的关系类型“amod”(adjectival modifier,即形容词的修饰符),对判断“place”的情感倾向至关重要,而当方面词为“dinner”时,这个关系为噪音信息,对判断“dinner”的情感倾向造成干扰;二是与任务无关的噪音信息,如“your”和“dinner”之间的关系类型“poss”(possession modifier,即所有格),对判断“place”和“dinner”这两个方面词的情感倾向都没有积极的作用。这些噪音信息会干扰方面特征的提取,导致模型的注意力分散。而深度强化学习在提取相关信息时表现突出,ZHANG et al[6]对句子的结构化信息进行建模,提取对分类有用的句子结构,用于文本分类。CHEN et al[7]将文本摘要分为抽取和重写两个步骤,在抽取步骤使用深度强化学习在原始语料中筛选出信息丰富的句子,将抽取的句子进行重写得到摘要文本。因此,使用强化学习对句法依赖树的噪音信息进行删除,得到更适应方面情感分类的强化依赖图用于方面情感分类。
本文提出基于强化依赖图的方面情感分类(reinforced dependency graph for aspect-based sentiment classification,RDGSC)模型。首先,融合依赖词、依赖关系类型、被依赖词和方面词等信息作为状态表示。策略网络可以根据状态得到依赖关系的动作,从而生成一个强化依赖图。该依赖图学习了句子的方面信息和句法依赖关系,更适应方面情感分类任务。随后,在强化依赖图上使用图注意力网络(graph attention network,GAT)[8],使方面词充分融合句法信息和远距离单词之间的依赖关系。最后,通过基于检索的注意力机制计算上下文信息的重要性,得到最终的文本表示进行分类,并计算延迟奖励指导策略网络的更新。
1 相关工作
1.1 方面情感分类
基于方面的情感分类任务是预测文本中一个或者多个方面的情感极性,方面主要是指句子中实体,包括具体事物(即食物、计算机等)或抽象事物(即环境、氛围等),情感极性表示句子表达的对方面的情感倾向,包括积极、中性和消极3种情感。TANG et al[1]使用长短期记忆(long short-term memory,LSTM),通过捕获方面词与上下文之间的相关性生成文本表示用于分类。LI et al[9]认为每个词对不同方面的重要性有所差异,将注意力机制引入模型中,在提取上下文信息时对单词设置权重,根据权重与提取的上下文信息生成文本的表示,显著地提高了分类效果。但是在顺序模型中,依旧存在方面词与其对应的关键情感信息相对距离较远的问题。
1.2 图卷积分类应用
句法依赖树可以准确地表示输入文本中词与词之间的句法依赖关系,解决了顺序模型中无法有效提取相对距离较远的多个单词之间特征的问题。YAO et al[10]根据句法依赖关系,将文档和单词作为节点,文档与文档、文档与单词之间的关系作为边,构建了一个大型图结构,将文档分类任务转化为文档节点分类任务,通过图卷积操作,使文档节点充分融合了与之相邻节点的特征,显著提高文档分类的效果。GHOSAL et al[11]在对话情感分类任务、WANG et al[12]在文档级情感分类任务中均使用句法依赖关系和相关任务的关系构造图结构,提取相对距离较远的单词或上下文之间的特征,生成更为丰富且准确的文本表示,完成相应的任务。在方面情感分类领域也应用了图结构,ZHANG et al[2]使用句法依赖树构造句法依赖关系,并使用图卷积神经网络融合句法信息和远距离单词之间的依赖关系。CHEN et al[4]将句法依赖树和自诱导的方面特定图联系起来,通过自注意力机制结合句法依赖图和潜在图的相关信息,提取方面的特征进行分类。LI et al[13]同时考虑了语法结构和语义关系,构造两个不同的基于句法依赖树的图结构,融合不同的方面特征进行分类。然而由于自然语言的复杂性,句法结构中不可避免地存在与任务不相关的文本信息,对最终表示的生成造成负面影响,导致相关任务的精度下降。
1.3 深度强化学习
强化学习(reinforcement learning,RL)是通过智能体与环境相互作用,通过试错来学习最优策略,广泛用于自然、社会科学和工程等领域的顺序决策问题。深度强化学习则是将深度学习与强化学习结合,在自然语言处理任务中有着突出的贡献。FENG et al[14]认为在关系提取任务中,远程监督标记的关系混杂着过多的噪音,他们使用深度强化学习筛选对关系提取任务有积极作用的样本,忽略无效样本,使用筛选后的样本对模型进行训练,有效提高相关任务的精度。CHEN et al[7]将文本摘要分为抽取和重写两个步骤,在抽取步骤使用深度强化学习在原始语料中筛选出信息丰富的句子,随后通过encoder-aligner-decoder模型,将抽取的句子进行重写,拼接得到摘要文本。ZHANG et al[6]通过训练一个策略网络,对句子的结构化信息进行建模,充分利用句子的结构信息,生成更为精炼的文本表示进行文本分类。CHAI et al[15]发现文本标签对文本分类有着积极的作用,通过深度强化学习对原始文本进行摘取,生成标签的描述,得到特征更为丰富的文本表示进行分类。深度强化学习在自然语言处理任务的信息提取方面有着杰出的表现,因此我们使用深度强化学习对句法依赖树进行信息筛选,旨在生成与方面相关的强化依赖图,提高方面情感分类的精度。
2 方法
本文提出的基于强化依赖图的方面情感分类模型RDGSC如图2所示。模型主要包含了两个部分:强化依赖图(reinforced dependency graph,RDG)和图注意力网络(graph attention network,GAT),首先提出强化依赖图方法,即使用深度强化学习对依赖树的句法依赖关系进行学习,然后在强化依赖图上通过图注意力网络进行方面情感分类。
2.1 强化依赖图
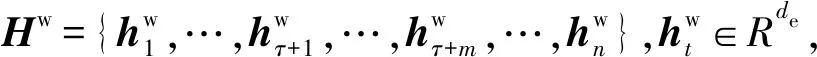
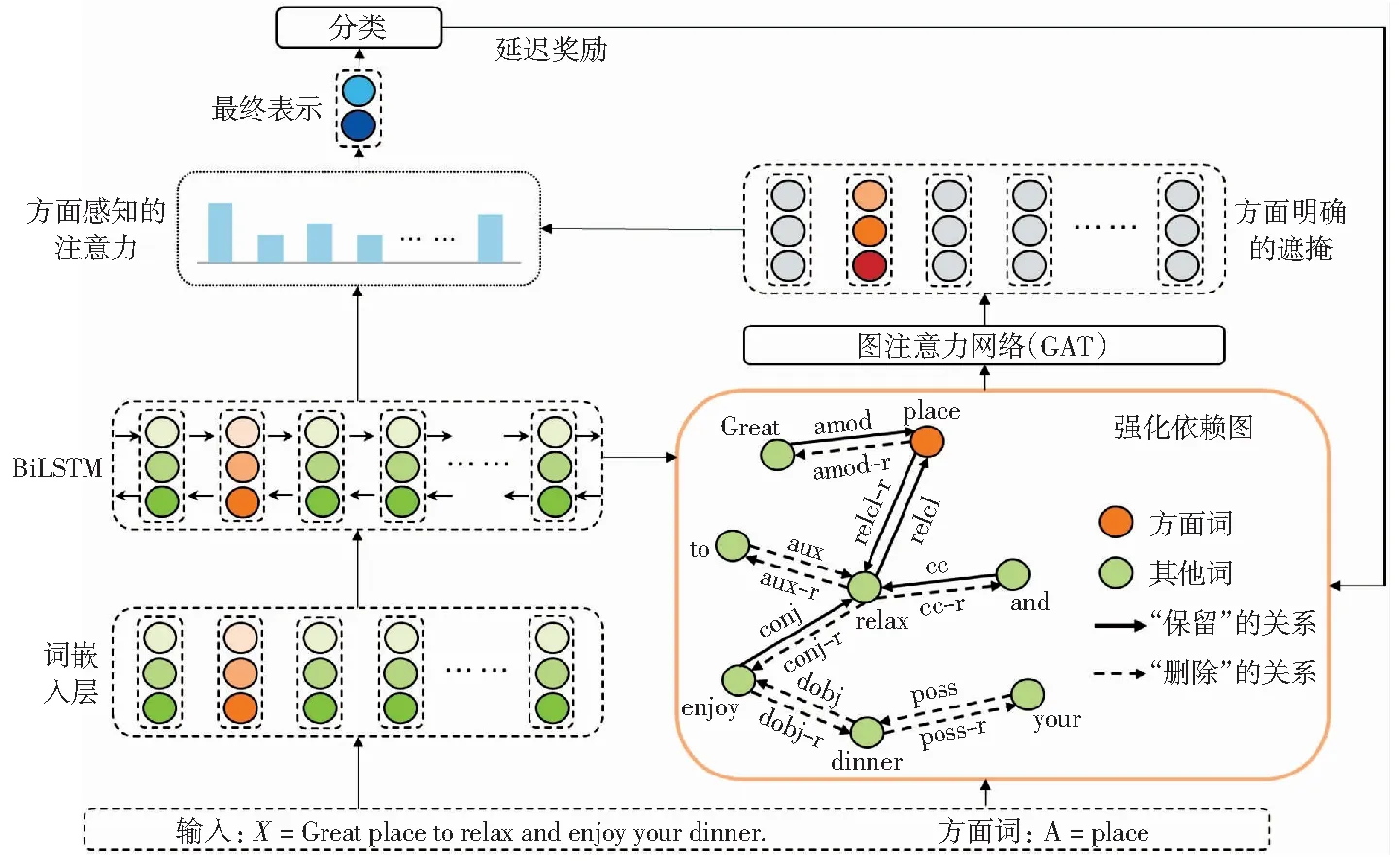
图2 RDGSC的整体模型Fig.2 Model of RDGSC
2.1.1状态
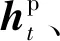
(1)

2.1.2动作和策略
动作由状态唯一决定,动作包含“保留”(Retain)和“删除”(Delete),表示该关系对方面情感分类是否有贡献。“保留”表示在强化依赖图中保留该关系,用于后续的方面情感分类,“删除”则是在强化依赖图中删除该关系。动作是生成强化依赖图的唯一指标,策略网络则是学习对动作进行选择。


(2)
2.1.3生成强化依赖图
通过策略网络得到单词关系对应的动作,生成强化依赖图。强化依赖图的邻接矩阵定义如下:
(3)
式中:Ar∈Rn×n.最终通过深度强化学习得到了强化依赖图的邻接矩阵Ar,后续的基于图注意力网络的方面情感分类则在强化依赖图进行。
2.1.4延迟奖励
得到了强化依赖图后,通过图注意力网络对相应的方面情感进行分类,得到分类结果并计算延迟奖励;使用损失函数的输出L作为延迟奖励。此外,为了尽可能多地删除关系,保留更为精炼的图结构,添加了一个附加项。最终,奖励具体公式如下:
(4)

2.1.5目标函数
策略网络的参数优化算法采用REINFORCE算法[16]和梯度下降算法[17],使期望奖励最大化。算法展示如下:

(5)
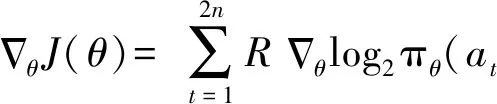
(6)
2.2 图注意力网络
对于输入文本X={x1,…,xτ+1,…,xτ+m,…,xn},通过深度强化学习,得到强化依赖图及其邻接矩阵Ar.随后通过图注意力网络,在强化依赖图学习融合了句法信息的节点表示,并通过明确方面的遮掩得到方面词的特征,使用基于检索的注意力机制,为每个上下文信息设置注意力权重,生成最终的表示。
2.2.1BiLSTM
2.2.2图注意力网络
与VELICKOVIC et al[18]的工作相同,在图注意力网络(GAT)层,将H0作为输入,令H0=Hc,将强化依赖图作为图结构,图注意力网络使用多头注意力机制融合邻居节点的信息,增强当前节点的表示。其公式如下:
(7)
(8)
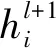
(9)

2.2.3明确方面的遮掩
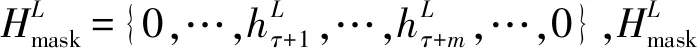
2.2.4方面感知的注意力

(10)
(11)
通过点积,可以计算方面特征与句子中上下文信息的相关性,加权求和得到最终的精确表示z∈Rdh:
(12)
2.2.5分类
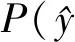
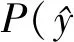
(13)
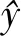
2.2.6训练
图注意力网络训练时使用标准的梯度下降算法优化模型,交叉熵损失函数为:
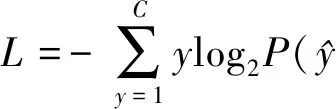
(14)
式中:y表示真实的标签,C表示方面情感分类的类别数。
为了使强化依赖图部分的深度强化学习快速收敛,采用了热启动,即使用原始的依赖树对图注意力网络的参数进行预训练。且同时训练强化依赖图的参数和图注意力网络十分困难,容易陷入局部最优点,导致模型效果不佳,因此在热启动后,使用交替训练对两个网络分别训练。经过热启动后,固定图注意力网络的参数,对强化依赖图部分的参数训练,以期望得到对分类更有效的图结构;接着固定强化依赖图部分的参数,对图注意力网络进行训练,提升在强化依赖图下的分类效果,依次交替,最终得到两者都最优的结果。
3 实验
3.1 数据集与实验设置
对5个公开的数据集进行分析,表1列举了数据集的统计情况,#Pos.、#Neu.和#Neg.分别表示积极、中性和消极的情感倾向样本个数。其中Twitter表示社交平台Twitter[19]用户的评论,包含了用户提及的人名、公司等方面;Lap14与Rest14、Rest15和Rest16分别来自SemEval 2014 task 4[20]、SemEval 2015 task 12[21]和SemEval 2016 task 5[22],包含了用户对笔记本电脑和餐厅的评价。

表1 数据集统计Table 1 Statistic of datasets
在实验中,采用300维的GLOVE预训练向量作为词嵌入的初始化,模型的参数使用均匀分布进行初始化。其中de为300,dp和dr为100,ds为800,dh为600,dz为3,γ为0.7,图注意力网络中,多头注意力头的个数为1,GAT的层数L为1或2,LeakyReLU小于0的斜率为0.2,最终分类的类别数C为3,表示3种情感极性,批处理的大小为16,优化器Adam的学习率为0.001,交替训练轮次为5.
3.2 基线模型
本文提出的RDGSC与9种基线方法在5个不同的数据集上进行实验。
1)SVM[23]:传统的机器学习方法,使用传统的特征提取方法,通过内部序列标记方面词。
2)LSTM[1]:对传统的LSTM模型进行扩展,输入文本为有序的单词序列,设置两个与方面相关的长短期记忆模型,充分融合上下文信息。
3)MemNet[24]:使用多跳结构和外部记忆学习单词在文本中的重要性,最终生成文本的表示。
4)AOA[8]:将机器翻译领域的注意-过度注意方法引入到方面情感分类任务,以联合的方式对各个方面与句子进行建模,准确地捕捉了各方面和上下文之间的相互作用。
5)IAN:输入文本建模为有序的单词序列,使用注意力网络学习方面的上下文表示。
6)TD-GAT[8]:使用图注意力网络,利用单词的依赖关系进行学习,使用多头注意力融合相互依赖的单词之间的信息。
7)ASCNN[2]:使用卷积操作学习句子的上下文信息,通过对非方面词进行遮掩,得到方面的特征,使用基于检索的注意力机制,为每一个上下文信息学习注意力权重。
8)ASGCN[2]:使用句法依赖图融合句法依赖信息,对非方面词遮掩得到方面的特征,利用注意力机制来学习文本的表示。
9)kumaGCN[4]:将句法依赖树和自动诱导的方面相关的特定图相关联,使用自注意力机制动态结合依赖树与潜在图的信息,再使用注意力机制学习文本中上下文信息的注意力权重。
重复运行3次,取平均值作为实验的结果,使用准确率(Acc)和宏观F1作为评价指标。
3.3 实验结果
如表2所示,从整体上看,5个数据集中,本文方法在4个数据集的结果都优于现有的模型。对单个的数据集而言,与最好的方法相比,本文的方法在Twitter上,Acc和F1分别提升了0.9%和1.3%;在Lap14上提升了0.6%和0.1%;在Rest14数据集上,Acc基本保持不变,而F1提升0.3%;Rest15数据集,Acc与F1下降了0.8%和0.3%;而在Rest16,Acc下降0.3%的同时,F1提升了1.3%.各项数据都表明了本文方法的有效性,证明了本文的强化依赖图是更适应方面情感分类的图结构。

表2 与不同模型的对比Table 2 Comparison of our RDGSC model with different baselines %
3.4 消融实验
我们设计了消融实验,研究深度强化学习中状态的组成成分实验结果的影响,状态是决定动作的唯一指示器,而动作决定了强化依赖图的生成,强化依赖图对方面情感分类有决定性作用,因此状态的组成成分是本文关注的重点。如表3所示,RDGSCw/o RL表示不使用深度强化学习,仅使用图注意力网络的结果;RDGSC w/o Rel表示在深度强化学习,状态不包含词与词之间句法依赖关系类型;RDGSC w/o Aspect表示状态中不包含句子中的方面词,即动作的学习与方面无关。在5个数据集上,RDGSC的结果与前两项相比,除了在Rest16的Acc上比RDGSC w/o RL均下降了0.1%,其余的均为最高值。与RDGSC w/o RL(即不使用强化依赖图)相比,Acc和F1最高分别提升了2%和4%,表明了强化依赖图对方面情感分类的积极的作用;与RDGSC w/o Rel(即强化依赖图的状态不包含依赖关系类型)相比,最高可提升3.2%和6.3%,表明依赖关系类型在模型中也是不可或缺的。而RDGSC w/o RL与RDGSC w/o Rel相比,除Rest15数据集,其余数据集的指标都有所下降,原因为词与词之间的关系更为复杂,导致策略网络训练不充分,即仅使用单词之间的信息和方面词的信息无法准确地判断方面情感分类是否需要这个依赖关系。

表3 消融实验Table 3 Ablation study %
3.5 交替训练实验
在实验细节上,策略网络生成的强化依赖图决定图注意力网络的结果,而图注意力网络的结果又会对策略网络进行更新,两者相互依赖、相互制约,导致同时训练策略网络和图注意力网络十分困难,极易陷入局部最优解。因此采用交替训练的方式,分别对策略网络和图注意力网络进行学习。如图3所示,横坐标表示交替学习的轮次,纵坐标表示实验的结果。对Twitter和Lap14数据集,在第二轮时Acc下降,可认为是因为强化依赖图的变化较大,图注意力网络训练不充分导致结果下降。对F1而言,可以看出随着交替轮次的增加,实验效果逐步提高。但是随着交替轮次的增加,训练时间也呈倍增加,因此为了平衡时间与效果,选择交替5次进行实验。

图3 交替实验Fig.3 Experience of alternation
3.6 注意力可视化
通过将公式(11)的α进行注意力可视化,展示本文模型的有效性。如表4所示,方面词表示对该词进行情感分类;注意力可视化中,颜色越深,表示模型越关注该单词的信息;预测标签表示模型预测方面的情感倾向;真实标签表示人为判断的结果。第一个例子中,“Space is limited,but the food made up for it.”,方面词为“food”,但是ASGCN将注意力集中在情感表达明显的“limited”上,认为“food”是消极的情感倾向,而RDGSC则正确地将注意力放在“but”和“made up”上,表明“made up”具有与“limited”相反的情感倾向。在“The fish is fresh,though it was cut very thin.”句子中,ASGCN考虑整个句子的情感倾向,前半部分为积极的情感,后半部分具有转折的含义,认为“fish”也是中性的情感;而本文的方法则重点关注“fresh”这个词,得出“fish”的情感倾向为积极的。第三个句子中,ASGCN虽然也关注了“never recommend”这个表达了消极情感的词,但是也关注了“casual”,最终认为这个句子为积极的情感;而RDGSC关注了“never recommend”和“anybody”,这些具有否定意义的单词,加强了消极的情感倾向。从注意力可视化看出,强化依赖图可以更有效地融合与方面相关的信息,使模型更加关注与方面相关的特征。

表4 案例分析Table 4 Case study
4 总结
本文使用深度强化学习对句法依赖树进行学习,考虑了句法依赖树的关系类型与方面之间的关系,生成基于句法依赖关系的增强依赖图,再通过图注意力网络融合文本中与方面相关的特征,使用基于检索的注意力机制,为上下文信息设置与方面相关的注意力权重,获得精简的最终的文本表示用于分类;最终的分类结果也通过计算得到延迟奖励指导策略网络的更新,且通过大量实验证明了本文的方法的有效性和健壮性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
大连民族大学学报(2021年2期)2021-07-16
数学小灵通(1-2年级)(2021年4期)2021-06-09
甘肃教育(2020年22期)2020-04-13
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
第二课堂(课外活动版)(2016年2期)2016-10-21
少儿科学周刊·少年版(2015年3期)2015-07-07
