
融合字符级滑动窗口和深度残差网络的僵尸网络DGA域名检测方法
2022-03-17 04:30:04刘小洋刘加苗张宜浩
电子学报 2022年1期
刘小洋,刘加苗,刘 超,张宜浩
(1.重庆理工大学计算机科学与工程学院,重庆 400054;2.重庆理工大学人工智能学院,重庆 401135)
1 前言
僵尸网络是指采用一种或多种传播手段,将大量主机感染bot 程序病毒,从而使控制者和被感染主机之间形成一个可以一对多控制的网络.Internet 用户的增多以及用户安全意识的缺乏,是导致僵尸网络产生的主要原因之一.组建僵尸网络的僵尸程序被事先设计好了DGA 算法,利用该算法生成大量的DGA 域名并周期性产生一个域名列表.僵尸网络的控制者会注册某些域名作为该僵尸网络的命令控制服务器访问域名.通过不断更改僵尸网络控制服务器的域名使僵尸网络保持运行的技术被称为domain flux[1].早期的DGA 域名检测方式是黑名单、正则匹配等.后来随着机器学习的兴起,利用大量的域名数据并做特征工程的域名检测的性能逐步提高.随后基于深度学习自动特征提取的DGA域名检测方法也逐步得到发展.
本文的主要创新点:①提出了一种基于字符级滑动窗口的深度残差网络模型用于DGA 域名的检测,使用区域卷积方式扩大卷积核感受野,然后精巧地设计了一种可变长式的深度可分离式卷积残差神经网络来提取特征;②提出的SW-DRN 模型首次采用深度可分离式卷积设计,减少了模型的可训练参数以及训练成本,提升了模型的检测效率;③本文建立两个数据集,分别为Real-Dataset 和Gen-Dataset,并且这两个数据集上的二分类和多分类任务均到达了目前领先的水平.
2 相关工作
在僵尸网络的防御中,DGA 域名检测起着重要的作用.因此DGA 域名检测成为网络安全领域中一个非常重要的研究点.在2010 年,Yadav 等人[2]同时对DGA域名和非DGA域名集合1-gram 与2-gram 的分布提取特征进行了识别.Antonakakis等人[3]基于隐马尔科夫聚类发现了潜在的DGA域名家族.在2016年,Woodbridge等人[4]首次将深度学习应用到DGA域名检测中,且该方法只使用域名字符串作为数据输入,利用深度学习自动提取字符串内的隐藏特征,使DGA域名检测的研究工作取得了飞跃性的突破.Vinayakumar等人[5]在不同深度学习框架上进行DGA域名检测实验,比较了多种卷积神经网络与循环神经网络.吕品等人[6]使用双向多层的循环神经网络结构,对大规模DGA 数据进行训练,最终得到的模型的DGA域名检测率为96%.Tran等人[7]提出了一种LSTM.MI算法,该算法结合了二分类和多类分类模型,并考虑了类别识别的重要性.Highnam 等人[8]提出了一种新颖的混合神经网络,该模型对此类算法生成域的可能性进行了分析和评分.杜鹏等人[9]提出一种混合词向量的DGA域名检测模型,并使用混合词向量CNN-LSTM和CNN-MWE模型做了实验对比.从上述研究发现,基于深度学习的方法普遍优于基于人工特征的机器学习方法.但是基于深度学习的DGA 域名检测方法在DGA 域名家族的二分和多分类任务上仍有很大的提升空间.
3 所提出的方法
本文提出的基于字符级滑动窗口的深度残差网络结构如图1 所示.SW-DRN 输入层接受固定长度为L的域名,且L=48.对域名进行数值化处理,使用字符级词典把域名中的每个字符映射成one-hot 编码向量.嵌入层将one-hot 的V1维度向量映射成d维度,d=16.于是开始特征提取,区域卷积部分采用标准卷积进行原始特征提取,采用多尺度的滑动窗口,选用3 种一维卷积核,大小分别为1,3,5.然后输入到深度可分离式卷积残差网络层进行更深层次的特征提取.

图1 SW-DRN 模型架构
残差网络层的层数是可以根据图1 中的深度可分离式卷积重复模块进行变化的,它的重复次数使用N来表示.卷积重复模块的次数N=4,当N的值每增加1时,下一次卷积的滤波器数量n变为原来的2 倍,于是滤波器的数量分别为64,128,256,512.同时在深度可分离式卷积重复模块的尾部加上一个最大池化层,这样每经过一个卷积重复模块时,特征图的长度变为原来的一半,其目的是在残差网络层中卷积核长度不变的情况下,通过减少长度L来增加对特征图的感受视野,这样可以提取DGA 域名内不同位置字符之间的关系特征.最后,需要对得到的特征图进行K-max 池化采样,感受野k=8,目的是提取显著的特征,缓解模型的过拟合,增加模型的泛化能力.输出层按照任务类型对输入的DGA样本进行类别预测.
残差网络[10]的设计是为了防止当网络层数加深时,模型在训练中出现梯度爆炸和梯度消失.考虑到残差块中若使用标准卷积会导致模型计算量增加并降低模型的检测效率,于是在DGA 域名检测中本文在设计残差块时首次应用深度可分离式卷积[11].图2 为SWDRN 中残差块的内部结构.为了增加模型训练的稳定性,引入批标准化(Batch Norm).残差块的数据流方向如式(1)所示:

图2 深度可分离式卷积残差块
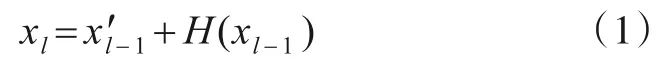
其中,xl-1为残差块的输入;xl为残差块输出.
本文为了探索网络模型的深度对DGA 域名检测的影响,使用SW-DRN 模型分别在深度层数为9,17,29,49 的情况下进行相应的训练并测试,所得对比结果在实验部分展示.
4 实验与结果分析
4.1 实验超参数
SW-DRN 模型的超参数:初始化学习率为0.01;每32 Epoch 的学习率调整成原来的1/2;优化器为Adam;Epoch为128;B(Batch size)=512.
4.2 Real-Dataset 和Gen-Dataset
Real-Dataset 数据集由2 部分组成:一部分是合法的域名样本,来自Alexa 访问量全球排名前一百万的网站域名;另一部分用360 Netlab DGA 公开数据.Real-Dataset 数据集包含21 种DGA 家族数据集,同时为了减缓数据不平衡问题,本文对该数据集进行欠采样.
本文不仅收集真实网络环境下的DGA 域名样本,同时还用域名生成算法产生DGA 域名样本并和Alexa中的域名一起作为合法域名构成数据集Gen-Dataset.本文从Internet 中收集了主流的域名生成算法,然后根据不同域名的生成算法,按满足条件不同,生成了33种不同家族的DGA域名,且每个类数量均为20 000.
4.3 模型性能衡量指标
SW-DRN模型具有二分类和多分类的任务.表1是分类混淆矩阵.
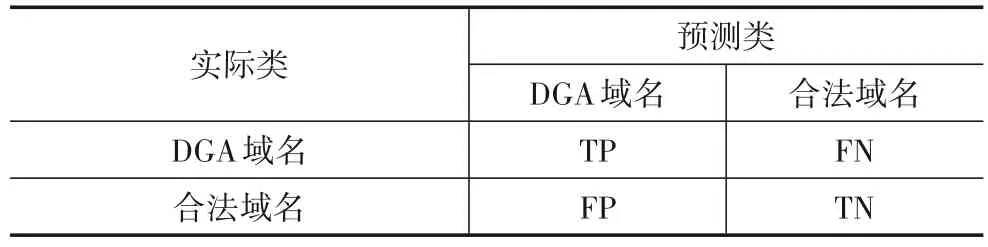
表1 分类结果混淆矩阵
准确率:

查准率:

检测率(Detection Rate,DR):

误报率(False Positive Rate,FPR):

考虑到实验中Real-Dataset 存在数据不平衡的问题,因此采用“macro”方式计算F-score比较合适.
4.4 模型对比实验分析
在Real-Dataset 数据集和Gen-Dataset 数据集上进行的二分类和多分类的实验,采用的对比实验模型分别是LSTM[12]、GRU[13]、Shallow-CNN[13]、CNN-LSTM[14]和LSTM-Attention[15].
在Real-Dataset 数据集上的二分类结果如表2 所示.从表2 中可知,本文所提出的SW-DRN 模型和对比模型在5个评估指标上都取得了不错的成绩,说明深度学习模型在DGA 域名检测中具有非常不错的性能.由于Real-Dataset 数据集中DGA 合法域名的特征相对容易区分,且各个性能指标几乎都超过99%,SW-DRN 与其他模型对比,在二分类任务上取得了微弱的领先.表3 展示了各个模型在Gen-Dataset 数据集上的评估结果.SW-DRN 模型在5 个性能指标上都领先于对比模型.但SW-DRN 模型在Gen-Dataset 数据集上并没有达到Real-Dataset 数据集上一样的识别率,主要原因是Gen-Dataset 数据集中的DGA 家族数量更多,增加了识别的难度.

表2 Real-Dataset数据集二分类结果/%

表3 Gen-Dataset数据集二分类结果对比/%
模型在Real-Dataset数据集上的多分类实验结果如表4 所示.根据实验结果可以发现,SW-DRN 模型在多分类整体评估指标F-score 上,比最优对照模型高出了1.23%.且SW-DRN 在gameover 和virut等5 个家族上的误报率均为0,在多个DGA 家族上取得了领先的成绩,即使在一些DGA 家族上未能超越对比模型,但也紧随其后.同样从表5 中的数据不难发现,SW-DRN 模型比对照模型在整体多分类指标上F-score 提升了1.01%,且在多个DGA 域名家族上领先于其他模型.但同上述SW-DRN 模型在Real-Dataset 数据集上的测试结果相比,Gen-Dataset数据集中的DGA 域名家族种类更多,对各个家族的识别难度也越大.还发现,在dircrypt、proslikefan 和dnschanger 等一些家族上,其域名之间具有高较高相似性,使得识别率低于其他家族.

表4 Real-Dataset 多分类结果/%

表5 Gen-Dataset多分类结果/%
为更进一步证明SW-DRN的性能,针对当前生成对抗网络产生的DGA域名来测试基于深度学习的DGA域名检测器.本文选择3 个有关对抗样本的域名生成模型,分别为DeepDGA[16]、MaskDGA[17]和CharBot[18].表6是SW-DRN分别在这3种生成域名的测试集上的结果.SW-DRN 在DeepDGA、MaskDGA 和CharBot 这3 种生成域名的识别上均取得了不错的效果,但由于CharBot 是直接对合法域名字符的个别位置上的字符随机替换,因此评估指标相比其他2种域名稍差一些.
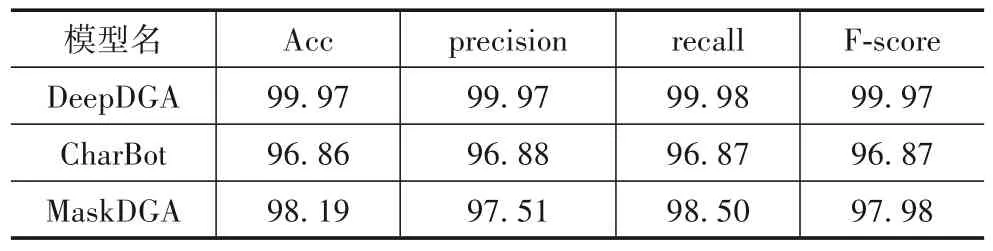
表6 SW-DRN模型在生成域名上测试结果/%
4.5 模型的参数量
为了评估模型的参数量,选择参数量在9 层的SWDRN 模型进行实验.实验结果如表7 所示,SW-DRN 模型使用深度可分离式卷积比标准卷积减少了约56%的参数.

表7 SW-DRN可训练参数量对比/百万
4.6 模型深度的探索
本文把SW-DRN 模型的层数设定为9,17,29,49,并在Real-Dataset 数据集和Gen-Dataset 数据集上分别进行二分类和多分类实验,结果如图3 所示.当SWDRN 模型为9 层时,已经取得了不错的性能,且随着模型的层数逐渐加深,模型的性能并无明显提升.当模型为49层时,模型因拟合能力太强而出现过拟合现象,导致泛化能力下降.对SW-DRN 模型进行更深层数的探索,得到更深层次的网络模型,并不能更好地提升模型在DGA域名上的检测性能.
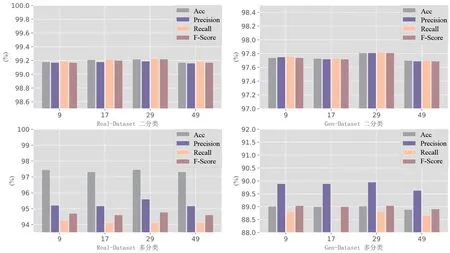
图3 SW-DRN的不同深度性能
5 结束语
本文提出了一种基于字符级滑动窗口的深度残差神经网络模型.实验证明,SW-DRN 模型不仅在二分类任务上优于对比模型,而且在多分类任务中取得了当前最优异的成绩.针对少样本DGA 域名家族进行识别以及对高随机性、易混淆的DGA 域名之间进行识别,相比当前已有的DGA 域名分类模型,SW-DRN 模型取得了更进一步的提升.本文还对SW-DRN 模型进一步实验,通过可变长的深度可分离式卷积残差模块实现对SW-DRN不同深度的探索,同时还对模型的检测效率进行了对比,实验证明,深度可分离式卷积能够有效地降低模型的可训练参数量.
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
计算机与网络(2018年10期)2018-02-15 09:06:37
数学物理学报(2017年5期)2017-11-23 07:51:31
中国知识产权(2015年9期)2015-05-30 10:48:04
机电信息(2014年14期)2014-02-27 15:52:37
机电信息(2014年11期)2014-02-27 15:52:04
机电信息(2014年5期)2014-02-27 15:51:47
机电信息(2014年2期)2014-02-27 15:51:39
新课程学习·中(2013年3期)2013-06-14 05:55:20
