
加权损失函数在划分甘蔗种植区域的应用
——以广西扶绥县某甘蔗种植区域为例
2022-03-17 10:04何永宁谭太恒
南方自然资源 2022年2期
◎何永宁,吴 博,谭太恒
广西自然资源信息中心,广西 南宁 530023
1 研究概况
糖业是广西最具有代表性的传统优势产业之一,在促进全区经济社会发展、推动扶贫攻坚、保障民生等方面发挥了重要作用。运用卫星遥感影像对甘蔗地块进行分类预测、甘蔗估产已成为遥感影像在糖业中的重要应用方向。遥感影像样本具有复杂性,加上广西独有的喀斯特地貌,因此每年获取的影像质量并不高。在实际工作中,负样本的数据往往比正样本数据多。
1.1 研究区概况
广西扶绥县属亚热带季风气候,夏季高温多雨、光热充足,春季温暖湿润,是广西著名的甘蔗生产基地。甘蔗产业是扶绥县重要的经济支柱产业,全县拥有南华糖业、东亚糖业两家大规模制糖企业。
1.2 采用的技术
随着深度学习技术在遥感影像上的不断应用,基于深度学习分类的方法也得到不断完善。邓志鹏等利用了多尺度形变特征卷积网络对遥感影像进行检测,优于传统方法的检测效果[1];李传林等利用了注意力网络模块和残差网络模块相结合,提高了提取建筑物遥感影像的精度[2];何直蒙等利用空洞卷积网络结合U-Net对遥感影像上的建筑物进行提取,该方法完整提取了建筑物边角的细节,提取精度比较高[3]。
基于此,研究小组利用U-Net 作为遥感影像分类的网络模型,根据不同的样本数量、不同的样本特性进行权重划分,使用加权交叉熵损失函数计算模型损失。加权交叉熵损失函数是在交叉熵损失函数的基础上为每一个类别添加一个权重比例参数,通过控制权重参数的大小,进而影响每一个类别输出的损失大小,以确保在数量不均衡的情况下仍可以获得较好的效果。
2 数据分析
2.1 数据基本概况
研究小组采用的数据是基于“北京二号”卫星遥感影像构建的甘蔗样本数据集,数据样本位于广西扶绥县某甘蔗种植片区,样本覆盖面积为320 km²,影像的分辨率为0.8 m,采用含有近红外波段的影像数据,影像波段数为4 波段。甘蔗生长周期较长,研究小组在选择样本的时候为了避开甘蔗生长周期的纹理差异性带来的误差,在每年的9—11 月选择样本,该阶段是甘蔗生长较为旺盛的时期,并且不同甘蔗地块的纹理差异性较小(见图1、图2)。研究小组在参与训练的过程中将甘蔗样本数据的栅格值设置为1 值,非甘蔗样本数据的栅格设置为0 值。

图2 研究区甘蔗标记样本数据图(绿色的部分为甘蔗标记样本数据,黑色的部分为非甘蔗标记样本数据)
目前参与训练的甘蔗样本并不均衡,有些片区甘蔗样本较少,仅有零星的图斑属于甘蔗样本,这类数据对训练造成较大的影响,为了进一步对数据样本进行分析,研究小组对样本的数量分布情况进行计算,计算结果甘蔗的占比为32%,非甘蔗的占比为68%,正负样本占比相差较大。
研究小组通过调整每一类样本的损失权重,使样本数量较少的一类损失权重占比偏高,最终使得损失函数的计算结果向样本数量少的一类倾斜,进而解决因样本不均衡带来的问题。
2.2 数据预处理分析步骤
研究小组在训练模型之前对样本进行预处理,主要是对数据样本进行数据增强,包括翻转、旋转、缩放比例、裁切、高斯噪声、几何扭曲、调整对比度等。遥感影像和普通的图片相比具有特殊性,体现在遥感影像并不是简单地通过图像表现出的形状区分地类类别,而是通过其纹理特征能够反应了地类类别,不同地类有着不同的纹理特征。因此不能过度调节对比度、明亮度[4],以免造成负面效果影响训练的精度。
翻转和旋转是指将影像水平或者垂直翻转180°或者旋转指定的角度,并将处理后的结果作为新的样本数据补充到现有的样本数据集中;缩放比例和裁切是指按指定比例缩放以及裁切原有样本数据,然后将处理后的数据作为新的样本数据集;高斯噪声是指添加的随机噪声点概率密度函数服从高斯分布(即正态分布)的一类噪声,利用这类噪声模拟影像数据中可能出现的噪点值,得到新的数据样本。
研究小组通过对样本数据进行预处理分析,将原来的样本进一步拓展,让原本的影像样本数据集含有更丰富的数据特征值,进一步提升模型的精度。
3 加权损失函数
3.1 交叉熵损失函数
模型训练中通常使用交叉熵损失函数(Cross-entropy cost function)作为模型训练的损失函数,该函数来源于信息论,后来常被用来描述正样本和负样本分布之间的差异,该函数的定义公式为:

公式(1)中,L为交叉熵损失函数计算结果;y)为样本标签的值;)为对应每一类样本分类的概率值。
公式(1)表示的是计算单个像素点数据的情况,如果是多个数据,则需要求和平均,具体公式为:

公式(2)中,L为交叉熵损失函数计算结果;y)为样本标签的值;)为对应每一类样本分类的概率值。通过损失函数可知,预测的概率越大,表明该像素点就越接近真实样本,损失函数的结果就会越小,并越接近于0,反之则越大。
3.2 加权损失函数
训练过程中正负样本数量不均衡会导致最后的损失倾向于数量较多的样本,最终无法得到一个合理的结果模型,基于此,为了让损失函数的结果更加均衡,研究小组将样本数量作为样本的权重,并将该权重加入损失函数中,加权后的损失函数公式为[5]:

公式(3)中,L为交叉熵损失函数计算结果;y)为样本标签的值;)为对应每一类样本分类的概率值;β为正样本的权重系数。该公式与交叉熵损失函数的公式唯一的区别是添加上正样本的权重参数β,β权重的设置是根据样本的占比进行设置的,通过该参数能够让损失计算的结果更加均衡。
4 模型结构及训练方法
4.1 模型结构
研究小组采用U-Net 作为模型训练的网络结构,U-Net 是经典网络FCN 的一种变体结构,采用了全卷积层。U-Net 基于编码解码结构,编码结构部分负责提取特征,该部分可以使用常见的特征提取网络[6],如resnet101 等,主要用于提取图像特征信息;解码结构负责还原提取的特征信息,U-Net 的网络结构虽然简单,但是模型的效率十分高效,在数据量不多的情况下能够获取更多的样本。
4.2 训练方法
运用损失函数计算损失结果,目前常用的优化算法主要有SGD 随机梯度下降法、Momentum 动量法、RMSprop 算法、Adam算法。
研究小组采用Adam 算法。该算法通过在小批量上计算损失函数的梯度进而迭代地更新权重和偏置项,最终达到减小损失函数计算结果的目的。目标函数计算公式[7]如下:

公式(4)中,fi(x)是关于索引为i的训练数据样本的损失函数;n是训练数据样本数;x是模型的参数向量。
目标函数f(x)在x处的梯度计算公式为:

公式(5)中,n是训练数据样本数;∑∇fi(x)为关于索引为i的训练数据样本的梯度。
在随机梯度下降算法中的每一次迭代,随机均匀采样的一个样本索引 i∈{1,2,…,n},并使用该样本计算梯度∑∇fi(x)来迭代x[7]。

公式(6)中,η为学习率的值;x为模型参数的值;∑∇fi(x)为关于索引为i的训练数据样本的梯度。
在公式(6)中,当前的模型参数减去梯度的结果与学习率η的乘积,最终更新到新的模型参数,反复迭代,直到梯度为最小值,即可求得损失函数fi(x)的最小值。
研究小组发现,模型初始参数是随机设定的,并且在初始参数不断下降的过程中,能将梯度优化到了局部最优解,并非全局最优解。这时候需要调整学习率,通过学习率的衰减策略,不断调整随机梯度的结果。目前常用的学习率衰减策略主要有等间隔算法、指数衰减算法、余弦周期算法等。研究小组采用的是余弦周期算法,该方法利用了余弦函数周期性的特点,反复地调整学习率。
研究小组使用学习率调整策略的算法是余弦退火策略,该算法主要利用了余弦函数波长周期的特点,反复调整学习周期的长短,从而让梯度逐步跳出局部最优解,向全局最优解靠近,公式如下:

公式(7)中,i为每次执行训练的次序号;表示学习率取值范围的最小值;(表示学习率取值范围的最大值;Tcur表示当前执行了多少个迭代,每个批次数据执行结束后,都会更新Tcur的值;Ti表示第i次迭代中的总批次数。
研究小组在此次实验中采用的初始学习率为0.001,利用余弦周期算法以及Adam 优化器不断调整、优化学习率,利用加权损失函数计算卷积分类的结果得到最终的分类。训练的迭代次数设置为200 次,训练总时长为43 h 23 min,程序模型框架则是使用了Facebook 公司研发的开源框架Pytorch 来实现,GPU 资源为2×GeForce RTX 2080 Ti显卡,BatchSize 设置为8,即每次输入的样本数量为8 张,单张样本统一裁切为宽度和高度都为512dpi 的矩形,最后,经过训练得到了此次的实验结果。
4.3 评价方法
有效的精度评价体系是提升深度学习遥感分类结果的重要保障,同时也是数据产品开展应用的基础[8]。研究中使用的评价指标有精度(Acc)、召回率(Recall)、平均交占比(MIoU)、Kappa 系数等。其中,精度(Acc)指标是最直接反应模型分类情况好坏的指标之一,计算公式如下:
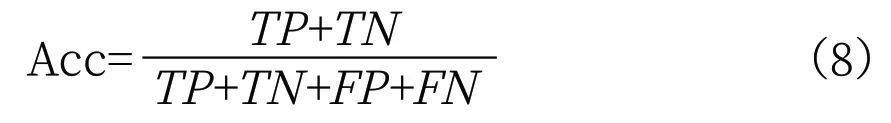
公式(8)中,TP为正确分类的正样本像素个数;TN为正确分类的负样本像素个数;FP为错误分类的正样本像素个;FN为错误分类的负样本像素个数。
召回率(Recall)可以反应预测正样本占实际总正样本的比例,计算公式为:

公式(9)中,TP为正确分类的正样本像素个数;FN为错误分类的负样本像素个数。
精度(Acc)和召回率(Recall)都和TP值相关,TP的值越大,精度和召回率就越高。
MIoU 指标代表平均交占比,因其操作简单、代表性强成为了检验算法优越性最常用的度量标准[9],计算公式为:

公式(10)中,K为类别的数量;TP为正确分类的正样本像素个数;FP为错误分类的正样本像素个;FN为错误分类的负样本像素个数。
MIoU 指所有类别的交占比的平均值。计算方法为依次计算每个类别的交占比,然后再将所有类别的交占比的平均值作为计算指标。
Kappa 系数是用于评价遥感解译成果的重要指标,也是利用深度学习算法分割遥感影像常用到的评价指标,其计算结果通常介于0~1之间,数值越大,表示分类结果就越准确。
5 实验结果分析
研究小组将此次实验的训练结果与未使用权重损失函数的训练结果进行对比分析发现,在相同的条件下,加上权重后模型结果精度得到了提升。研究小组采用的评价指标为精度(Acc)、召回率(Recall)、平均交占比(MIoU)、Kappa 系数,经过加权损失函数训练后的模型的精度(Acc)和召回率(Recall)等各项指标高于未加权损失函数训练的模型,其中精度(Acc)高了2.59 %,召回率(Recall)高了3.88%,平均交占比(MIoU)高了3.06%,Kappa 系数高了0.062,这4 个指标评估模型的最终结果如表1 所示。

表1 研究区甘蔗种植区域加权模型结果对比表
在计算山地周围的甘蔗的地块分类中,加上权重的损失函数能够更好地分割甘蔗种植类别的地块(见图5)。在甘蔗田埂分类中,加上权重的损失函数能够更清晰地显示甘蔗地块中的田埂(见图6)。

图5 研究区甘蔗地块分类显示的加权与未加权的对比图

图6 研究区甘蔗地田埂影像加权与未加权分类显示对比图
研究小组利用加权损失函数对研究区的甘蔗种植区域的遥感影像数据进行研究,通过遥感影像快速解译并分割出甘蔗地块,改善了传统的未加权的方法导致的分类精度不高、分割的效果不好等问题,改进了糖料蔗种植生产管理方式。
6 结语
研究小组通过使用样本数量参数作为样本的权重参数,不同类别具有不同的样本数量,从而每个类别都会有不同的权重参数,并将权重系数加入交叉熵损失函数中,通过调节损失函数中的权重参数,解决样本数量不均衡的问题。此次样本采用的是广西扶绥县甘蔗种植区的样本数据,通过调节权重参数有效地将不均衡的样本进行有侧重的分类,将更多的权重参数赋值给样本较少的一类,得到更好更稳定的训练结果,对使用深度学习方法分类遥感影像具有较好的指导意义。
猜你喜欢
心理学报(2022年5期)2022-05-16
数学小灵通·3-4年级(2021年5期)2021-07-16
当代陕西(2020年17期)2020-10-28
小猕猴学习画刊(2019年8期)2019-09-16
广东第二课堂·小学(2019年1期)2019-03-06
今日农业(2019年15期)2019-01-03
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
作文大王·低年级(2016年9期)2016-09-21
共产党员(辽宁)(2015年2期)2015-12-06
