
众筹项目的个性化推荐:考虑本地偏好的协同过滤算法
2022-03-15 10:39郭丽环KevinZhu王洪伟
管理工程学报 2022年2期
王 伟 郭丽环 何 翎 Kevin Zhu 王洪伟
(1.华侨大学 工商管理学院, 福建 泉州 362021; 2.泉州师范学院 陈守仁商学院, 福建 泉州 362000;3.加利福尼亚大学圣迭戈分校 雷迪管理学院, 美国 圣迭戈 92093; 4.同济大学 经济与管理学院, 上海 200092)
0 引言
尽管互联网打破了传统市场的各种限制,但是在线交易中用户行为仍然呈现本地偏好趋势,即交易双方的地理位置会趋近而不是扩散到广泛的地理范围内。这种典型的用户行为模式已经在线下交易中得到广泛证实[1],用户对本地资源的偏好反映了用户行为模式。从心理角度上分析,以食品类项目作为例子,这类项目属于线上交易,线下消费的场景,因此,众筹项目在线融资过程中,项目的地理位置代表了该项目包含的文化、习惯、传统、风俗、语言等丰富信息。距离越近,意味着文化、习惯、传统、风俗、语言越相似,也就意味着对项目背景越熟悉。由于文化和习惯的差异,对事物越熟悉意味着投资者越容易产生心理信赖[1]。从这个角度上看,食品类众筹项目由于其产品属性,难以获得广泛的地理位置的投资者支持[2],因此吸引距离较近的投资者具有更高的成功率。从消费成本的角度上看,由于不可避免的距离成本,导致投资者在投资众筹项目时,会把项目地理位置纳入考虑范畴,例如:对于风险投资,投融资双方的平均距离仅为70英里;而50%的天使投资与目标企业的距离也在半天行程范围内[3];从用户的活动轨迹上看,Foursquare的调查数据显示,45%的用户日常活动半径不超过10英里,而75%的用户日常活动半径不超过50英里[4]。以戏剧类众筹项目为例,在北京举行的戏剧类项目能够吸引的投资者大多来自北京以及周边地区,其他地区的用户参与这类项目将会极大增加消费成本(包括交通成本、时间成本等)[5]。所以,在这些类别的众筹项目中,投资者偏好距离较近的项目。借助本地偏好,能够得到更准确的用户画像,进而提供更为有效的个性化推荐列表。
近年来,有学者尝试将地理位置与个性化推荐相结合,提高了用户偏好识别的准确率,进而提高了个性化推荐的成功率,但是其应用场景与在线众筹项目的个性化推荐存在较大差异。已有研究中,基于地理位置的推荐一般是根据用户需求选择就近的产品。一个典型的场景是:给用户推荐附近的电影院、咖啡馆或餐厅等。显然,在这种情景下,优先推荐就近产品会获得较高的准确率。这种推荐算法优先考虑了地理位置的影响,但并没有考虑用户之间的兴趣相似性,完全摆脱了个性化偏好对于用户选择的影响。在众筹平台上,这种场景将不复存在,互联网打破了地理位置的局限,投资者既可以选择距离近的项目,也可以选择距离远的项目。
也有研究尝试同时考虑用户兴趣相似度和地理属性两个维度,并采用匹配质量作为模型的核心函数[6]。这类算法的本质是把用户行为分为两个阶段,第一阶段识别用户偏好,采用余弦函数进行相似度度量;第二阶段在第一阶段的基础上,加上距离因素,并通过优化模型得到帕累托均衡点。其研究结果证实了在社交网络好友推荐中的有用性,但是在线融资的应用场景显然不同于好友推荐,参与投资的影响因素更加复杂。
现有研究很少考虑在线金融产品(如众筹)的个性化推荐问题。基于位置的推荐算法通常采用距离排序,这与线下消费行为密切相连。因此,现有的基于位置的推荐一般是先选择距离用户最近的N个项目作为待推荐列表,再采用排序算法进行推荐(例如协同过滤)。然而,很多众筹项目不依赖于线下消费,例如,项目展示、项目投资、进度公告、投融双方的沟通都是在线完成的。利用投资者的本地偏好,重新设计用户相似度函数,能够得到更加细致的投资者偏好模型,进而提升推荐系统的性能。另外,众筹数据的稀疏度大于99%[7],将影响个性化推荐的效果。充分利用用户行为多维数据能够在一定程度上解决稀疏数据的个性化推荐问题。
1 相关文献
1.1 基于地理位置的推荐算法
随着移动定位技术的发展,基于位置的推荐吸引了越来越多的关注[8],它能帮助人们发现有吸引力的地点,或者推荐在一定距离内用户可能感兴趣的消费场所。通常,用户移动性数据和空间位置信息有助于识别用户偏好,考虑地理位置的推荐能提升推荐性能,并对数据规模和潜在空间维数的增加提供了较好的扩展性[9,10]。一般来说,用户的行为都在一定范围内,例如:大多数用户在离线消费时,会选择50英里以内的酒店[4],这表明用户行为模式受到较强的地理位置的影响,考虑用户的地理位置可以更准确的进行用户画像,进而识别用户偏好。
很大程度上,场地推荐的性能取决于如何捕捉用户的环境或偏好。然而,很难捕获用户偏好的全部信息;此外,用户偏好往往是异构的(即某些偏好对所有用户通用;而有些偏好是动态和多样的)。基于场地的推荐算法经常推荐基于简单上下文的最受欢迎、最便宜或最接近的场馆[11]。在考虑用户位置之外,不能忽略用户的其他兴趣偏好。用户偏好受到多方面因素影响,如兴趣相似性、距离和熟识度等,因此,在众筹项目的个性化推荐中,有必要同时考虑距离因素和其他多维兴趣因素。
1.2 有关互联网金融产品的个性化推荐
推荐系统中的用户和项目都具有多维特征[12],多特征相似度能够提高项目和用户的匹配度,提升推荐效果。因此,对于互联网金融项目,同时考虑项目和用户的多维特征并进行匹配,能够显著改善用户偏好识别[13]。已有研究已经证明在线投资行为中存在本地偏好,即投资者偏好距离较近的项目[14]。投资者的这种偏好打破了地理位置的局限,与场地类项目的推荐是一种截然不同的情景,需要重新构筑基于本地偏好的推荐系统。
大多数用户只对少数商品有购买行为,因此存在数据稀疏问题。一种解决思路是采用多类型隐式反馈数据[15],例如将消费者在线评论作为一种反馈数据[16]。另一个思路是,采用网络图计算用户和项目的全局相似度。将二分图模型应用于众筹项目推荐,使用PersonalRank算法迭代计算网络节点的全局关联度,并将二分图模型与协同过滤算法相结合,一定程度上解决数据稀疏问题[7]。
用户特征具有多样性,位置是其中一项基础特征[17]。近年来,推荐系统较多考虑用户的多维度特征,例如在众筹项目的推荐中,依据投资者的位置和相关特征进行聚类,再进行用户群体推荐,在Kickstarter平台上,取得了较好的推荐性能[18]。但是,这种群体推荐把同一群体视为同质用户,缺乏个性化,而且推荐性能受制于聚类的准确率。
2 研究差距以及问题定义
2.1 研究差距
当前有关众筹推荐的研究还很少,对投资者本地偏好的应用更是鲜有考虑。离线消费的推荐与众筹场景差异较大,前者与用户的线下消费相关,地理位置转移的时间消耗和交通成本是决定推荐效果的主要因素[19]。离线消费场景下的推荐算法不能直接应用于众筹项目的个性化推荐。本质上,考虑位置的推荐是一种基于多维特征的推荐。用户具有多种兴趣偏好[20],推荐算法的核心是识别用户兴趣,在度量用户距离偏好基础上,包含地理位置的多维特征推荐算法可以用于众筹项目的个性化推荐。表1归纳了与本文相关的研究进展。

表1 与本研究相关的主要研究进展Table 1Main research progress related to this study
归纳已有研究,仍有提升空间:(1)众筹项目的在线投资行为打破了地理位置的限制,但已有的考虑位置的推荐算法难以应用到众筹项目的推荐。离线消费场景不同于在线消费场景,北京王府井附近的用户很可能选择在其周边用餐,而不可能去上海用餐;而对于众筹模式而言,远距离的投资者能无限制地投资任何位置的项目,因此,已有的基于位置的推荐效果较差;(2)现有研究大都基于单边位置数据,只有用户或项目的位置数据。例如(用户、物品、物品位置、评分)数据结构[4];或(用户、用户位置、物品、评分)数据结构[24]。尽管可以从用户经常活动的位置推断用户或者项目的位置,但是与众筹项目的数据存在本质的差异。众筹项目的数据结构是多种结构的混合,即部分投资者和融资者会选择隐藏地理位置,这增加了模型的难度,众筹项目的数据结构包括(用户、用户位置、项目、项目位置、投资行为),(用户、用户位置、项目、投资行为),(用户、项目、项目位置、投资行为),(用户、项目、投资行为)等结构;(3)用户偏好具有多样性[25],用户可能对位置近的项目感兴趣,同时又期望投资“科技类”项目。而已有研究很少同时关注位置偏好和其他偏好,例如:对临近位置项目的推荐,有研究直接按照距离进行排序。显然,由于用户偏好的多样性,以及在线投资的便捷性,单纯按照距离进行排序是不合适的。
2.2 研究问题定义
以Kickstarter为代表的众筹平台采用Nothing-or-More模式,融资成功率不足40%[26]。调查发现,融资者花费大量精力维护项目,而一旦筹资失败,融资者将一无所获。融资失败可能是因为项目质量较低,也可能是没有找到合适的投资者。针对后者,个性化推荐将有助于提高融资成功率。本文以位置作为切入点,改进推荐效果,为此,提出以下研究问题。
(1) 基于距离的本地偏好分析:依据投资者和融资者的地理位置,转化为用户(项目)之间的距离,进而分析用户的本地偏好。
(2) 考虑本地偏好的用户兴趣建模:依据用户的本地偏好模型,在推荐系统中整合地理位置的影响,改进用户兴趣模型。
(3) 基于本地偏好的协同过滤算法设计:采用基于本地偏好的用户兴趣模型,设计并验证众筹项目的个性化推荐算法,并比较算法之间的差异。
3 研究模型
3.1 研究框架
图1展示了本文的研究框架。首先,爬取用户行为数据,根据众筹项目的特点,构建用户行为数据。然后,对原始数据预处理,包括数据清理、关键数据抽取,其中地理位置与经纬度的转化是关键点。接下来,采用交叉验证的方式对数据进行分组,分为训练集和测试集。在训练集上建立用户偏好模型,该偏好模型考虑了用户对地理位置的偏好。对用户(项目)的相似度距离进行归一化处理。在相似度距离基础上,为了消除热门项目对推荐性能的影响,对热门项目进行降权。最后得到个性化推荐列表,并采用准确率、召回率、流行度和覆盖率等指标综合评估推荐性能。

图1 研究框架示意图Figure 1Research framework of the study
3.2 距离度量
依据Kickstarter提供的位置信息,调用Google地图API,得到用户的经纬度,例如“SanDiego,CA”的经纬度分别为32.7157380和-117.1610840。得到项目与投资者的位置数据后,采用球体计算公式计算任意两点的距离。投融双方的距离以球面进行计算,计算如公式(1)和公式(2)所示。
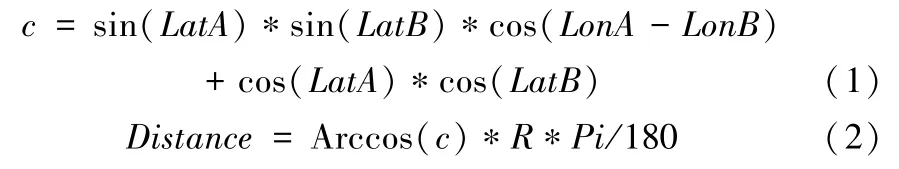
其中,点A的经纬度为(LngA,LatA),点B的经纬度为(LngB,LatB),按照0度经线作为基准。Distance()以反余弦函数进行度量,R为地球半径,取值6371.004公里,计算结果以公里为单位,Pi代表圆周率。
3.3 匿名位置用户的处理
出于隐私方面的考虑,一部分用户不愿意暴露自身的位置。对于这类用户,其地理位置需要单独处理,因为如果惩罚太大就减少了用户之间的兴趣相似度;惩罚太小就忽略了投资者可能存在的本地偏好。采用公式(3)所示的方法对匿名位置的用户进行处理。

即如果投资者与项目都有位置信息,则按照经纬度计算距离。如果投资者匿藏位置,采用该项目投资者的平均距离di作为匿名位置投资者与融资者之间的距离,即用第i个项目的平均距离作为投资第i个项目的匿名投资者的距离。这样处理的原因在于不同项目类别之间存在不同的本地偏好,一些项目类别能够吸引较远距离的投资者,例如:科技类项目;而另外一些项目只能吸引距离较近的投资者,例如:戏剧类项目。因此,依据已经公开地理位置的用户之间的距离均值来近似衡量匿名位置用户是对不同属性项目偏好的合理度量,充分考虑了项目特征。
3.4 改进的余弦相似度算法
协同过滤的思想就是计算用户或者项目之间的相似度,通常采用余弦相似度进行计算,如公式(4)所示。
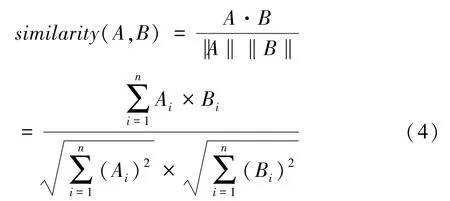
如果考虑本地偏好,公式(4)可以修改为公式(5)。
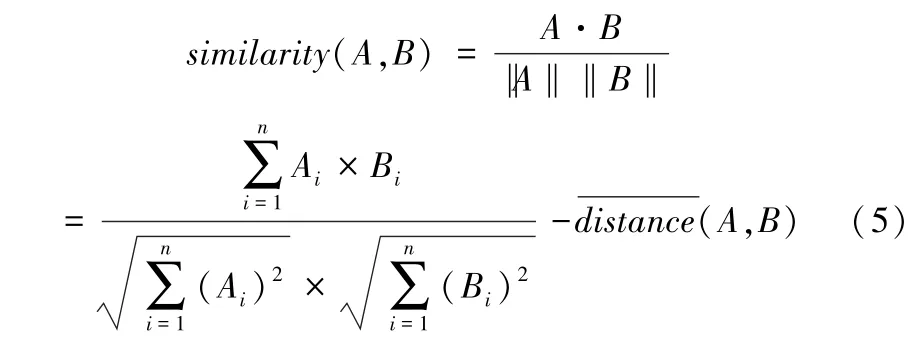
3.5 距离惩罚因子
若不考虑投融双方之间的距离,公式(6)可用于计算用户对项目的兴趣度。

其中,p(u,i)表示用户u对项目i的兴趣度,S(u,K)表示与用户u兴趣最接近的K个用户,可以采用余弦公式计算用户之间的兴趣相似度,N(i)表示对项目i有过行为的用户集合。wuv表示用户u和用户v的兴趣相似度,rvi表示用户v对项目i的兴趣,在单一行为的反馈数据中,rvi一般设置为1。
若考虑投资者的本地偏好,可将公式(6)改进为公式(7),公式(7)引入了惩罚因子。本文模型对距离进行了两个维度的度量:一是用户之间的距离;二是用户与项目之间的距离。对于Kickstarter这样一个国际性众筹网站,一旦一个项目同时获得了外国用户与一些美国国内投资者的投资,可能会因为这些项目与外国用户之间的距离较大而导致不会将这些项目推荐给外国用户。这是引入距离惩罚因子的原因,距离惩罚因子允许我们手动在训练数据上进行调整,以保证用户兴趣模型(协同过滤)和用户本地偏好(距离因素)同时在模型中得到均衡的度量,最大程度提高推荐准确率。

其中,dp(u,i)表示项目i对于用户u在地理位置上的惩罚,项目i距离用户u的位置越远,其惩罚系数越大。α表示距离惩罚因子,α越大表明对距离的惩罚越大。采用欧氏距离计算地图上任意两点的距离,如公式(8)所示。

3.6 距离惩罚因子的归一化处理
使用经纬度来计算用户之间的相似度距离具有较大的范围,因为经度的范围介于[-180,180]之间,而纬度的范围介于[-90,90]之间。如果不对距离进行规范化的话,投资者之间的距离就会出现极大的值域,距离惩罚因子因此很可能大于1,得到的推荐效果较差。
公式(9)对距离惩罚因子进行归一化。其中,dp′ui是归一化后的距离惩罚因子,dpui是原始的距离惩罚因子。

3.7 相似度的归一化处理
众筹项目包含不同的类别,同类别项目之间的相似度通常大于不同类别项目之间的相似度,这是由于作为相同的项目类别,用户对其行为的子集一般大于跨产品类别的子集。在这种情况下,把项目之间的相似度矩阵进行归一化处理,不但可以提高推荐的准确度,还可以提高推荐的覆盖率和多样性[27]。例如,推荐系统要在食品类项目(记为F)和科技类项目(记为T)之间选择并推荐给用户,F内部项目之间的相似度为0.5,T内部项目之间的相似度为0.4,而F和T之间的相似度为0.2。如果某用户的历史投资行为是均衡的(即投资F的次数和投资T的次数相当),那么基于项目的推荐算法会给用户推荐F,而不会推荐T,因为F内部项目之间的影响力更大。而一旦把F和T都归一化到相同的比较基准内,则推荐列表中同时出现F和T的概率就会大幅增加。另外,归一化也能降低热门项目对于计算用户之间相似度的影响。对于冷门商品来说,尽管销量少,但是对其有过行为交集的用户的相似度应该更大。
鉴于此,采用公式(10)对项目相似度进行归一化处理。其中,wij是原始相似度,w′ij是归一化的相似度。

4 研究数据以及实验设置
4.1 研究数据
在众筹平台上,融资者和投资者通常会标注自己的位置。图2展示了Kickstarter上的一个项目主页,该项目已经有111位投资者,地理位置为“Bedford-Stuyvesant,Brooklyn,NY”。同理,在用户主页上,也能看到用户标注的位置,据此计算投资者与项目之间的距离。
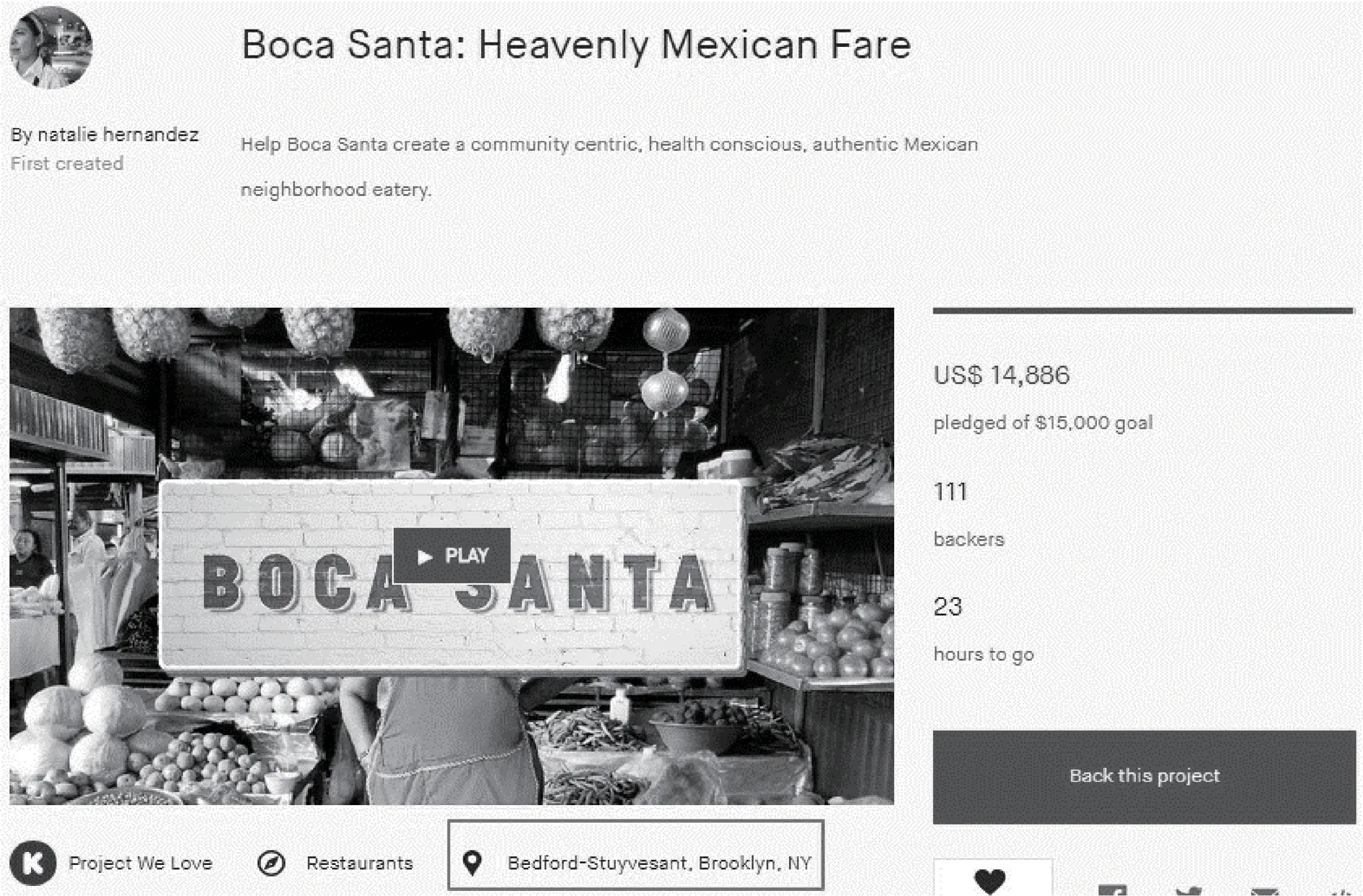
图2 Kickstarter上一个典型的项目主页Figure 2A snapshot of a project′s home page on Kickstarter
图3展示了本文样本数据中投资者的本地偏好趋势统计。其中,具有本地偏好的实际值表示基于Kickstarter真实数据的距离计算值,而无本地偏好的理论均值是指剥离用户本地偏好后的距离分布,即所有投资者与融资者的平均距离[14]。显然,投资者更倾向于投资距离近的项目。以投融双方来自同一国家的情形为例,由于Kickstarter上的投资者与融资者来自100多个国家和地区,理论上,如果不存在本地偏好,投资者选择来自同一国家项目的概率约为6%,但是实际值约为63%。由于Kickstarter平台位于美国,投融双方大都来自美国,因此,以国家为单位存在数据不均衡。以美国的州和城市进行计算,仍然显示了显著的本地偏好趋势。投融双方之间的距离更能衡量本地偏好,Kickstarter上投融双方之间的平均距离是3911公里;而如果不存在本地偏好,双方之间的平均距离理论值为8611公里。

图3 在线投资者的本地偏好实际值与真实值对比Figure 3Actual value vs.real value for investor′s home preference
4.2 研究数据汇总
图4展示了数据的统计结果。实验数据包括4340个用户对275个项目的37018次投资行为,稀疏度为96.90%。就投资者来说,绝大多数参与投资的项目数量都较少,投资超过10个项目的投资者占28.16%;而投资超过20个项目的投资者占5.41%,也就是说,绝大多数用户不活跃,因而导致数据较稀疏。就项目而言,投资者小于100人的项目较多,占26.91%;投资者大于150人的项目占24.36%,即约50%的项目能够吸引到100~150位投资者参与。
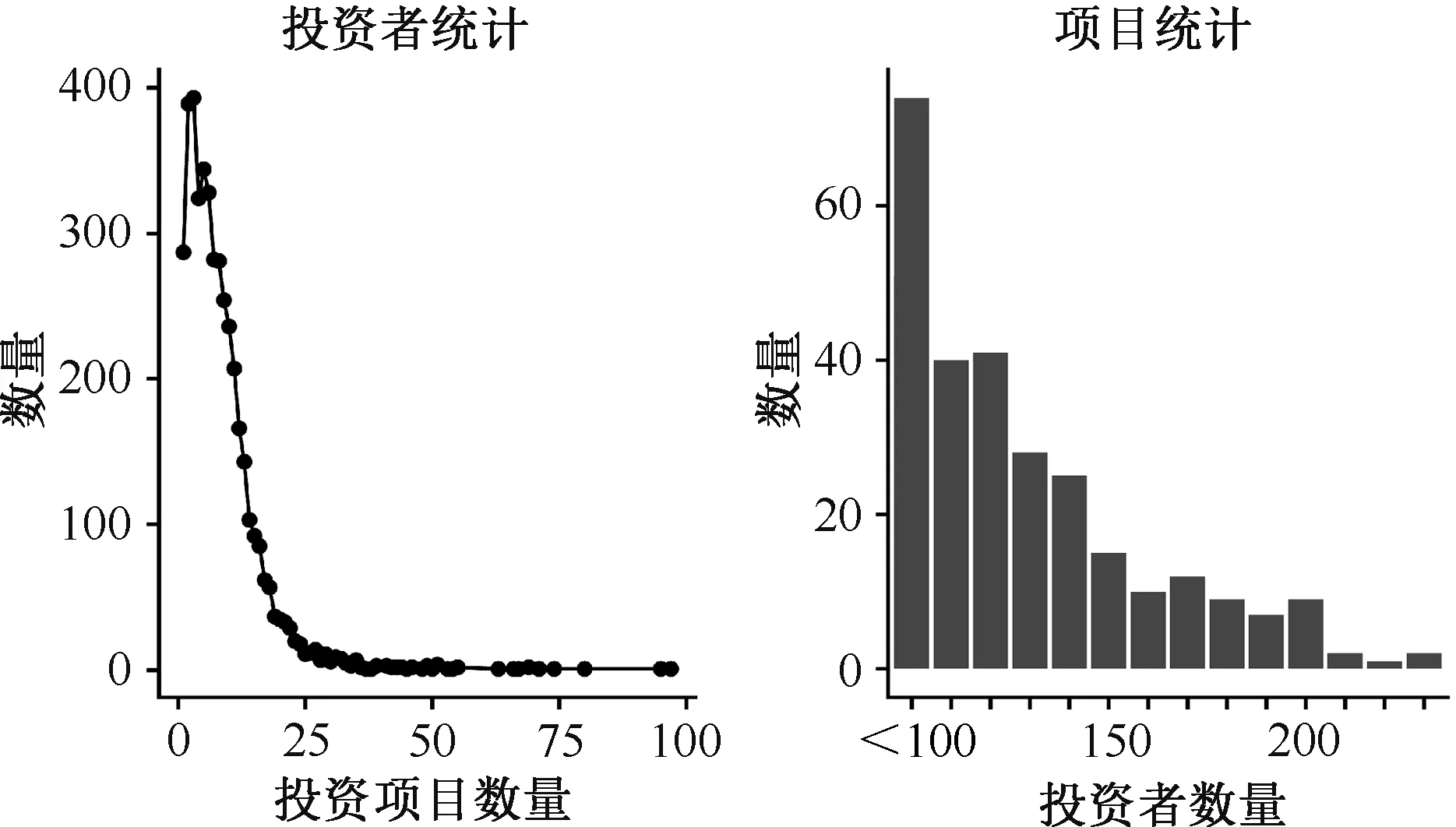
图4 数据统计展示Figure 4Statistics results
4.3 实验设置
本文采用基于项目的推荐算法,首先计算项目之间的相似度,然后依据该相似度推荐用户列表给目标项目。为了比较算法的性能,采用Top-N推荐,分别测试推荐列表数为5个和10个的情形。同时,测试协同过滤算法邻域数量对推荐性能的影响。
PersonalRank推荐算法、基于二分图的CF分别以PersonalRank构建二分图模型进行推荐[7]。基于内容的推荐表示推荐用户曾经支持过的相似项目给目标用户,例如某用户曾经支持过电影类项目,那么就认为该用户对电影具有一定的偏好。在对比实验中,我们选择的项目相似度指标包括:项目类别、筹资者的社会化网络、项目融资状态、参与等级数量、最低参与金额以及平均筹资金额等6项指标。基于热度的推荐是指直接推荐最热门的项目给用户。基于热度的推荐与邻域无关,即对任何用户来说,得到的推荐列表都是相同的[7]。协同过滤算法采用余弦函数计算项目(用户)之间的相似度,这种算法是较早采用的相似度算法[28]。
距离推荐算法采用距离进行升序排列,然后推荐前N个用户(项目)给项目(用户)。距离推荐算法在线下场景中常常非常有效,因为用户常常选择距离最近的项目(电影院、餐厅、酒店、咖啡馆等),但这种算法在众筹项目推荐中是否有效悬而未决。距离过滤+协同过滤是一种首先按照投资者与项目之间的距离进行排序,然后选择前N项作为推荐的候选列表,再在候选列表中采用协同过滤算法进行推荐[19]。这种方法在一些特定领域取得了不错的效果,我们试图比较这种算法对在线众筹项目推荐的性能差异。基于本地偏好的协同过滤算法是本文提出的对距离的惩罚方法,目的是在计算用户(项目)相似度时考虑距离指标对相似度的影响,在推荐时对距离因素进行惩罚。当项目与用户的位置较近时,惩罚因子小;反之,对兴趣度进行较大的惩罚。表2归纳了本文的比较算法以及说明。

表2 比较算法以及说明Table 2Comparative algorithms and descriptions
4.4 个性化推荐的评价标准
早期推荐系统评价标准通常是预测用户是否会购买某物品,因此准确率成为重要指标。后来发现,单纯依靠准确率会误导推荐系统的发展[29]。例如:对于热门商品的推荐,准确率会很高。但即使不推荐这类商品,用户依然会购买。相反,当推荐用户不熟悉却有兴趣的商品时,用户会更加满意[30]。同时,实践显示,大量的长尾商品汇集起来,会对销量产生很大的影响。鉴于此,长尾商品的推荐成为商界的关注点[31]。如果忽视产品覆盖率,而片面追求准确率和召回率,推荐系统会逐渐推荐更加热门的商品,“马太效应”愈加明显[32]。为此,把推荐系统的评价标准归为4类:准确率、召回率、覆盖率和流行度。公式(11)到公式(14)分别给出4类指标的计算方法。

其中,Ru是推荐系统产生的推荐列表,Tu是用户实际喜欢的项目列表,代表所有产品数量,RecommendListu为给用户u的推荐列表,U为用户集合,I为项目集合,代表项目i被推荐的次数。值得注意的是,推荐列表的长度会对准确率和召回率产生影响。如果长度为1,即当只有1个推荐产品,如果这个推荐正确,那么准确率为100%,否则为0%;当推荐列表为全部商品时,召回率恒为1。我们在实验中选择在实际应用中常用的列表长度(N=5以及N=10)。
5 研究结果与讨论
5.1 距离惩罚系数的确定
对于距离惩罚因子而言,如果太小,不能对推荐的性能产生足够影响;如果太大,则不能准确衡量用户偏好的相似度。为此,先在较小的数据集上进行实验,以确定距离惩罚系数对个性化推荐性能的影响。图5展示了距离惩罚因子的对比,采用TOP-N进行测试(N=10)。显然,距离惩罚因子对于覆盖率和流行度的影响极小。但距离惩罚因子提升了推荐的准确率和召回率。以准确率为例,当距离惩罚系数为0时,准确率最低;取值0.3时准确率最高。召回率呈现了类似的趋势。这种趋势在邻域数量K≤75时尤其明显;而在K>75时,惩罚系数不存在显著影响,但是当K>75时,准确率和召回率都极低。因此,在基于距离的推荐算法中,归一化后的距离惩罚因子设置为0.3是比较合理的系数。
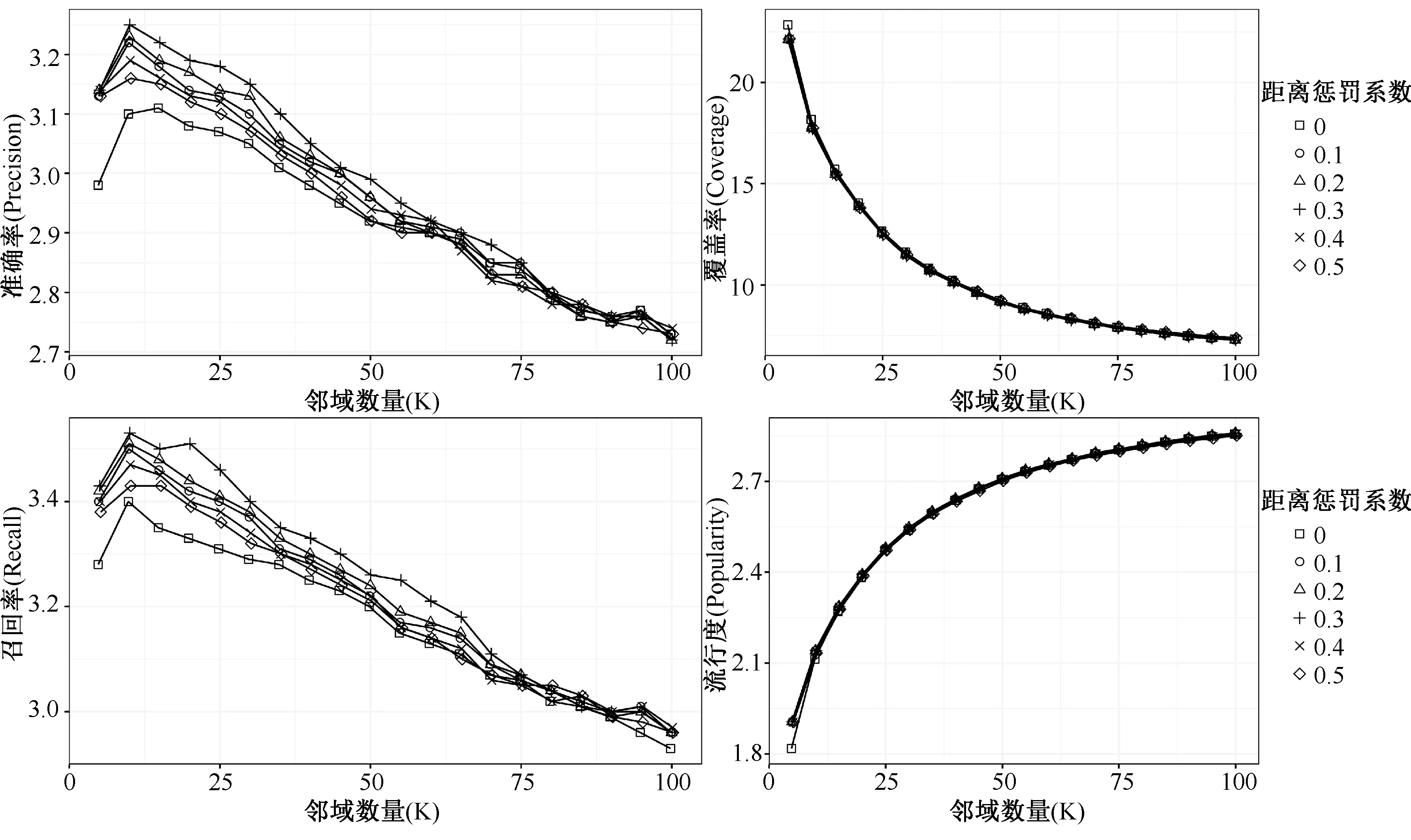
图5 距离惩罚系数的对比(N=10)Figure 5Comparison of distance penalty coefficients (N=10)
5.2 距离推荐算法
基于距离的推荐参照用户之间的地理位置衡量兴趣相似度。该算法不同于协同过滤算法,是一种只推荐距离最近的项目(用户)给目标用户(项目)的方法。换句话说,两个地理位置相同的用户得到的推荐列表是相同的,这种推荐算法在离线消费场景中常常非常有效,因为离线消费受距离的约束较大,用户很难选择距离较远的场所。表3展示了距离推荐算法的推荐结果,显然,距离推荐算法效果并不好,准确率和召回率都极低,具有较大的提升空间;而覆盖率较高,同时流行度较低。这表明该算法能够覆盖更宽广的用户群体,同时降低热门商品对推荐算法的影响。

表3 距离推荐算法的推荐结果Table 3Recommendation results of the distance recommendation
5.3 距离过滤+协同过滤
该算法将协同过滤和基于地理位置的推荐相结合,即从临近的地理距离中选择M个项目作为候选集,然后依据协同过滤算法推荐M个候选集中用户兴趣度最大的N个项目给目标用户[19]。本实验中,选择10倍推荐数量的候选用户作为候选集,然后在候选集上进行协同过滤推荐。
表4展示了距离过滤+协同过滤的推荐结果。列表长度N=5时,各项指标均高于距离推荐算法。当邻域数为10时,综合性能最佳。召回率和准确率分别为4.86%和16.21%,而覆盖率和流行度分别是13.57%和2.969。而当列表长度N=10时,邻域数为15时推荐性能最佳。尽管推荐性能得到了一定程度的提升,但是较难解释这种推荐结果,因为该算法首先排除距离较远的投资者,实质上是只将一定距离内(距离较近)的用户推荐给项目,而没有考虑较远距离的用户也可能对项目感兴趣。在对推荐结果的解释上,忽略远距离的投资者显然是不合理的。此算法受限于推荐场景,线下消费场景适宜采用此类算法。但是,在众筹领域,投资者与融资者的平均距离为3911公里。显然,不能把较远距离的潜在投资者排除在推荐列表外。
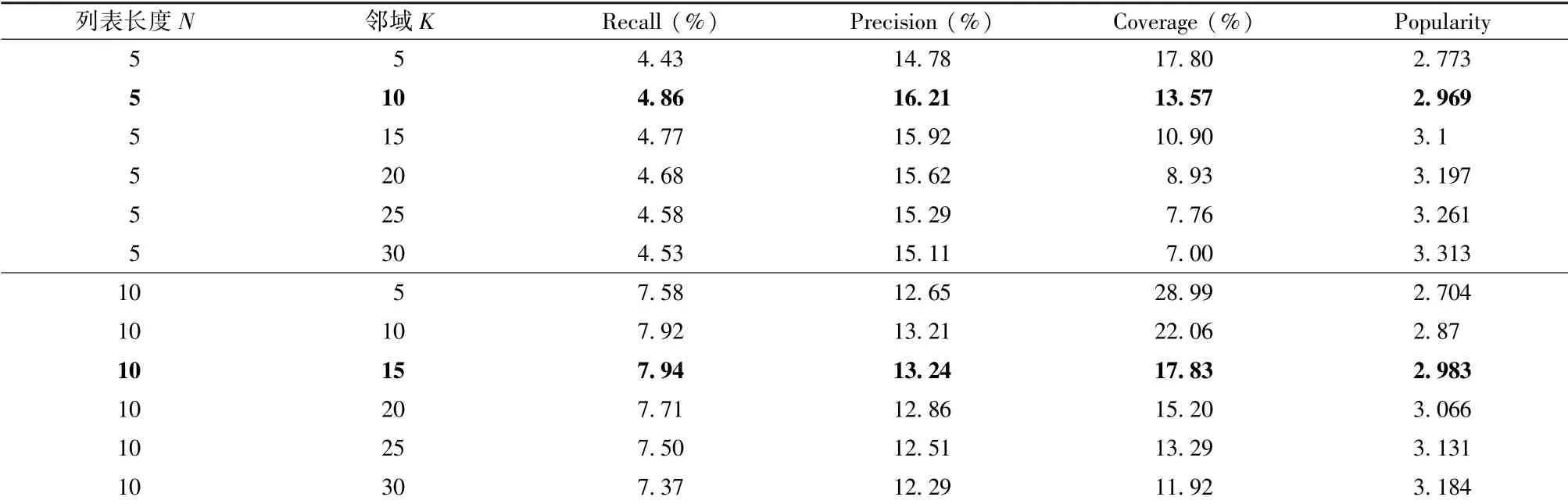
表4 距离过滤+协同过滤的推荐结果Table 4Recommendation results for distance filtering + collaborative filtering
5.4 对距离的惩罚算法
对距离的惩罚算法是在协同过滤算法基础上,对用户和项目之间距离实施惩罚。距离惩罚因子和相似度因子都采用归一化计算。表5展示了距离惩罚算法的推荐结果。当列表长度N=5时,邻域数为10时,推荐性能最佳,召回率、准确率、覆盖率和流行度分别为4.87%、16.24%、13.62%和2.967。
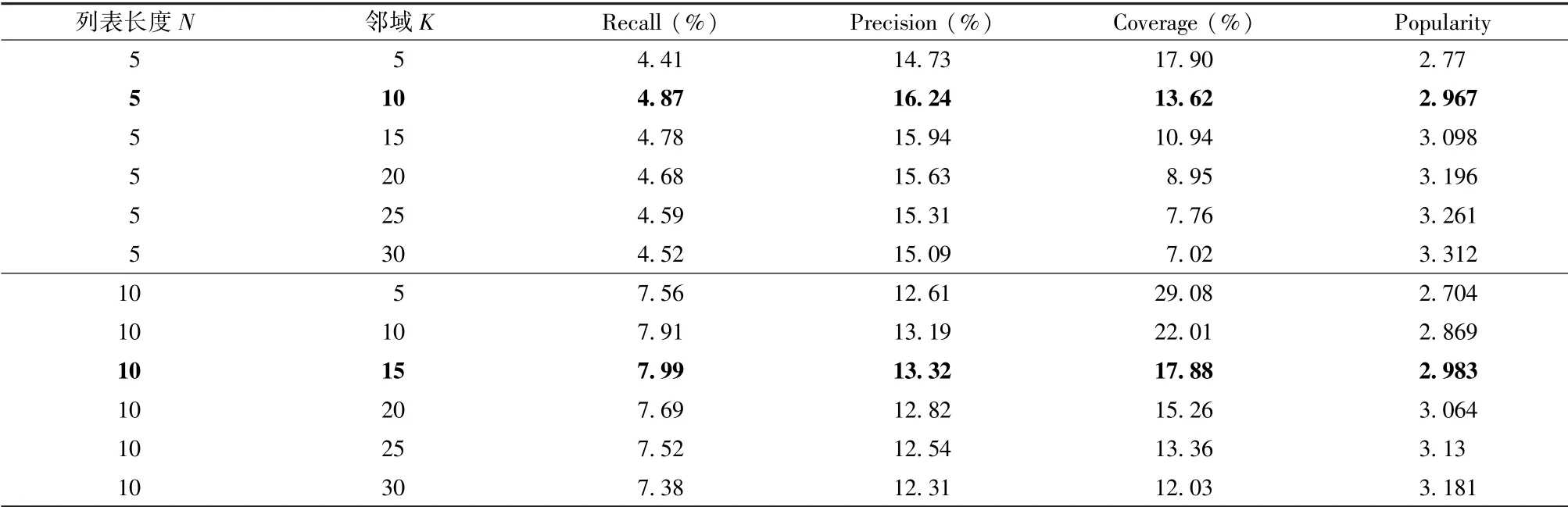
表5 对距离的惩罚算法的推荐结果Table 5Recommendation results for home bias-based CF with penalty
当列表长度N=10时,相对于推荐列表为5(N=5)的推荐性能,该结果在召回率、覆盖率和流行度上有所提高;但降低了推荐的准确率。换句话说,当推荐的列表长度为10时,以降低准确率的代价,提升了推荐的召回率、覆盖率和流行度。
5.5 算法的综合比较
表6对各种算法进行了综合对比。总体上看,基于热度的推荐算法性能最差。因为基于热度的推荐是一种不考虑邻域的推荐算法,把所有用户和项目视为同质,向所有用户(项目)推荐相同的项目(用户)。而在众筹社区中,每个投资者的特征不一样,不能以相同的项目列表推荐给所有用户,因此,这类算法在众筹项目推荐中性能极差。基于距离的推荐比基于热度的推荐性能更好,这可能是因为,众筹参与者大多青睐距离较近的项目,他们通常是融资者的亲朋好友[33]。由于这部分投资者的大量参与(尤其是在融资初期),投融双方之间的距离较近。基于距离的推荐会优先推荐这部分投资者,但是这种推荐存在以下问题:(1)距离较近的投资者有很多,并不意味着近距离的投资者都对项目感兴趣;(2)只考虑了投资者的距离偏好,而没有考虑投资者的其他偏好。基于内容的推荐算法改进了基于热度和基于距离推荐算法的缺陷,以项目的内容作为衡量投资者兴趣的指标,一定程度上提升了推荐性能,但仍有较大的提升空间。

表6 各类算法综合对比结果Table 6Comprehensive comparison results of various algorithms
选取两类网络推荐算法进行比较:PersonalRank和基于二分图的CF,网络推荐算法适合对极端稀疏数据的处理[7]。本文数据稀疏度为96.90%,即在用户行为矩阵中,约有97%的矩阵元素为空。数据集相对稠密,在Kickstarter上全部数据的稀疏度约为99.99%[7],数据极端稀疏。网络推荐算法对极端稀疏数据推荐具有一定的效果,但是不适合对较稠密数据的处理。
基于余弦函数的CF极大提高了推荐性能。例如:当列表长度为5时,准确率达16.11%,覆盖率为13.73%,召回率和流行度分别为4.83%和2.971。而当列表长度为10时,邻域数K=10时,准确率达到13.21%。这表明了协同过滤算法在众筹项目推荐的优势。当采用距离过滤+协同过滤时,推荐性能进一步提升,召回率和准确率分别为4.86%和16.21%,这表明考虑项目和投资者之间的距离有利于更加准确的识别用户偏好,并准确推荐众筹项目。在对距离变量的处理上,采用距离惩罚因子的CF推荐性能最佳,召回率、准确率、覆盖率和流行度分别为4.87%、16.24%、13.62%和2.967。因此,在基于本地偏好的众筹项目个性化推荐中,采用距离惩罚因子的本地偏好算法值得推广。基于本地偏好的协同过滤算法在各项指标上均优于基于位置的推荐、协同过滤算法、基于内容的推荐和网络推荐算法,表明了本文提出的方法具有理论价值和实践意义。
6 结论和展望
本文提出基于本地偏好的协同过滤算法,并应用于众筹项目的个性化推荐。理论上,改进了互联网金融的投资者偏好识别并提升了推荐系统的性能。本文首先识别项目和投资者的地理位置,并转化为经纬度,依此计算项目与投资者之间的地理距离。然后,把项目与投资者之间的距离作为计算用户相似度的一个指标。把用户本地偏好分别用于以下两种推荐方法:(1)先对用户进行距离过滤,然后采用协同过滤算法进行推荐;(2)具有距离惩罚因子的协同过滤算法。研究表明,考虑本地偏好的推荐算法能提升推荐性能。更进一步,归一化后的距离惩罚因子设为0.3时,具有距离惩罚因子的协同过滤算法能够获得最佳推荐性能,超越距离过滤+协同过滤算法。
实践上,众筹市场空间极大,据调查2014年众筹市场规模达到162亿美元;2015 年超过340亿美元;2016年达到500亿美元[34]。面对如此巨大的市场规模,准确把握用户需求将是促进这一商业模式可持续发展的重要手段。众筹推荐不同于线下环境的电影院、咖啡馆、餐馆等的推荐,因为用户难以物理地消费远距离项目,已有的基于距离的推荐并不适合众筹融资模式。创业者在融资阶段最大的担心来自融资失败,因为一旦项目融资失败,创业者将一无所获,项目因此不能继续下去[35]。对本地资源的偏好是由于经济、文化、传统、习俗等多方面因素导致的,创业者在考虑项目推介时有必要深入分析本地偏好产生的原因,例如:对于食品类众筹项目的本地偏好可以理解为饮食习惯的相似性,因此,在项目的推广阶段,对具有相似饮食习惯的潜在投资者需要重点关注,考虑本地偏好的协同过滤算法为提升融资成功率提供了一种手段。
未来的研究方向有:(1)本文采用球面距离度量用户距离,事实上,投资者与项目之间的距离分为若干层次,例如:国家级偏好、州省级偏好以及城市级别偏好等,这种层次可以采用“金字塔”模型进行建模[36],从而得到更加细致的用户偏好模型;(2)众筹项目都设有投资期限,通常是30~60天[37]。在此期限内,投资者的来源呈现显著性差异,早期投资者一般是融资者的亲朋好友,一方面是因为社会关系促使这部分投资者在项目初期参与项目投资;另一方面是因为距离较近,投资者更能了解融资者的能力和信用。鉴于投资者参与行为受到时间因素的影响[38],推荐系统可以尝试考虑这种动态地理位置变化对推荐性能的影响;(3)众筹项目分为若干类别,投资者对每个类别的评价标准存在较大的差异。投资者对某些类别(如科技类)的地理位置不敏感;而对另一些类别(如食品类)的地理位置极其敏感。因此,考虑不同项目类别之间的差异在理论上可以提高推荐的准确率,未来计划尝试对不同项目类别进行分组,并比较不同类别下本地偏好对推荐性能的影响。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
小读者(2020年2期)2020-03-12
阅读(快乐英语高年级)(2019年11期)2019-09-10
英语文摘(2019年12期)2019-08-24
中国交通信息化(2018年5期)2018-08-21
趣味(语文)(2018年1期)2018-05-25
传媒评论(2017年2期)2017-06-01
学苑创造·A版(2015年6期)2015-07-01
