
基于支持向量机的致密油藏水平井体积压裂 初期产能预测*
2022-03-11 04:19:48徐程浩王智林李芳芳尚云志张苏杰
中国海上油气 2022年1期
陈 浩 张 超,2 徐程浩 王智林 李芳芳 尚云志 张苏杰 李 旋
(1. 中国石油大学(北京)安全与海洋工程学院 北京 102249; 2. 中国石油辽河油田分公司勘探开发研究院 辽宁盘锦 124011;3. 中国石化江苏油田分公司勘探开发研究院 江苏扬州 225009; 4. 中海油能源发展股份有限公司工程技术分公司 天津 300452;5. 大庆油田有限责任公司勘探开发研究院 黑龙江大庆 163712; 6. 渤海钻探工程有限公司井下技术服务公司 天津 300283)
致密油藏储层物性差,孔喉结构复杂,常规直井开发经济效益较差,多采用水平井多级压裂技术提高产量。由于体积压裂后,缝网结构复杂、压裂参数与产量之间呈复杂映射关系,常规经验公式法和数值解析法在产能预测方面效果欠佳,且对于新数据适应性弱,推广难度大[1-5]。
随着人工智能的迅猛发展,神经网络、支持向量机、贝叶斯网络、随机森林等机器学习方法理论基础完善、泛化性强、实际应用过程中方便快捷,相比较于传统方法优势明显,逐渐在油气产能预测领域得到广泛应用[6-13]。2009年,叶双江 等基于灰色关联与神经网络技术,对多因素非线性影响下的水平井初始产量进行了预测,相对误差在10%以内[14];2010年,刘科 等采用最小二乘支持向量机,结合产能公式,建立了水平井产量预测的支持向量机模型[15];2012年,庄华 等采用BP神经网络模型,结合测井数据和压力施工参数,对朝长地区扶杨油层压裂产量进行了预测[16];2018年,殷荣网 等利用改进的粒子群优化支持向量机算法,通过构建地质因素与产量之间的非线性映射关系,建立了油井单井产能预测模型,其预测效果要比基因遗传神经网络算法更优[17]。
实际应用中发现,机器学习方法的预测效果对数据本身的依赖性很强,不同机器学习方法的适应条件不同。例如,庄华 等的BP神经网络模型对地区的依赖性较强,不完善的数据样本会大大影响预测结果的可信度[16]。相比之下,支持向量机方法在数据量需求的方面具有独特优势,由于支持向量机方法自身完善的理论,可以有效处理油田实际应用中最常见的小样本问题[18]。但是,目前在大多数的低渗透油藏水平井开发领域的应用中,主控因素通常以测井参数、地质参数和水平井参数为主,普遍缺少体积压裂的工程参数。
大庆油田M2区块为中浅层特低产特低丰度致密油藏,地质条件复杂、水平井体积压裂开发单井产量差异大。针对目标油藏储层物性普遍较差、井数偏少、影响参数复杂的开发现状,本文首先采用皮尔森系数、斯皮尔曼系数和肯德尔系数3种方法,进行主控因素筛选和排序,在此基础上,基于支持向量机方法,建立了具有较高精度和泛化能力的致密油藏水平井体积压裂初期产能预测模型,以期为国内外致密油藏有效开发提出指导性建议。
1 主控因素筛选和评价
参数的选取对产能预测至关重要,参数过多可能导致冗余参数的存在,影响模型预测能力,参数过少可能无法构建完善的预测模型,导致误差增大。实际应用中,一般都需要结合多种参数筛选方法进行选择。理想的模型应尽可能全面地涵盖所有影响产量的因素,同时去掉冗余特征。在实际应用中选择主控因素时,还会受到数据收集困难、模型复杂性,和计算量过大等多种条件的制约。因此,在模型构建的过程中,主控因素的筛选工作是非常必要的。
1.1 主控因素初步筛选
一般来说,影响致密油藏水平井体积压裂的主要因素包括:①目的层油藏条件和物性参数,如地层压力、孔隙度、渗透率、含油饱和度等;②压裂改造参数,如钻遇油层长度、钻遇油层厚度、压裂段数、压裂簇数、总砂量、总液量等。结合大庆油田M2区块实际情况可知,储层普遍发育差、不连续、不压裂无产量,体积压裂后产量提升明显。如表1所示,5个主力含油层位的地层压力、孔隙度、渗透率、平均孔喉半径和含油饱和度等数据均比较接近,因此,水平井体积压裂产量主要取决于压裂改造程度。
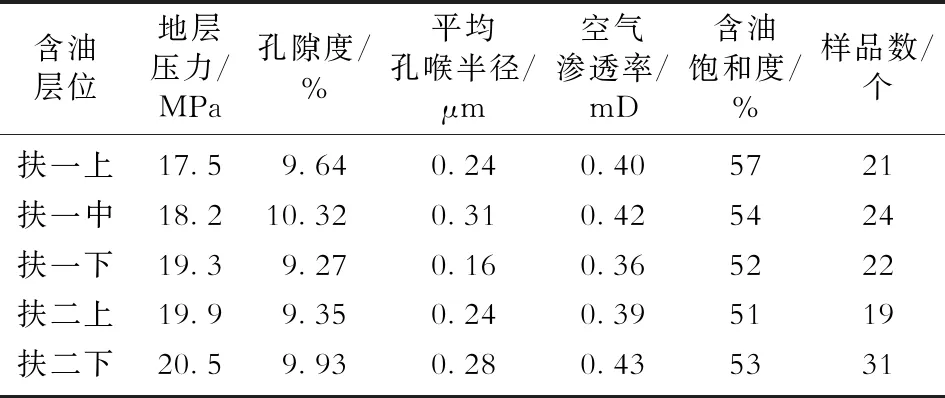
表1 大庆油田M2区块地质数据
1.2 主控因素评价
为了合理地选择输入特征,本文采用了皮尔森系数、斯皮尔曼系数和肯德尔系数,对输入参数与产量之间的相关性进行了计算。3种方法的相关系数判别角度不同,其中,皮尔森系数可以很好地表现变量之间的线性相关性,但是需要数据满足正态分布,而且数据中的异常值的存在会对关联结果产生很大影响[19],斯皮尔曼系数和肯德尔系数是等级相关系数,这2种方法只关注变量间单调关系,不需要数据满足正态分布,而且还可以减弱异常值对结果的影响[20]。3种相关系数计算公式如下所示:
(1)
(2)
(3)

表2为目标油藏水平井体积压裂初期产量数据统计情况,包括压裂后3个月内的平均日产油量数据和压裂参数数据。尽管在储层条件方面非常接近,但由于压裂施工参数的差异,各井的初期产量明显不同,在5.4~48.7 t/d。
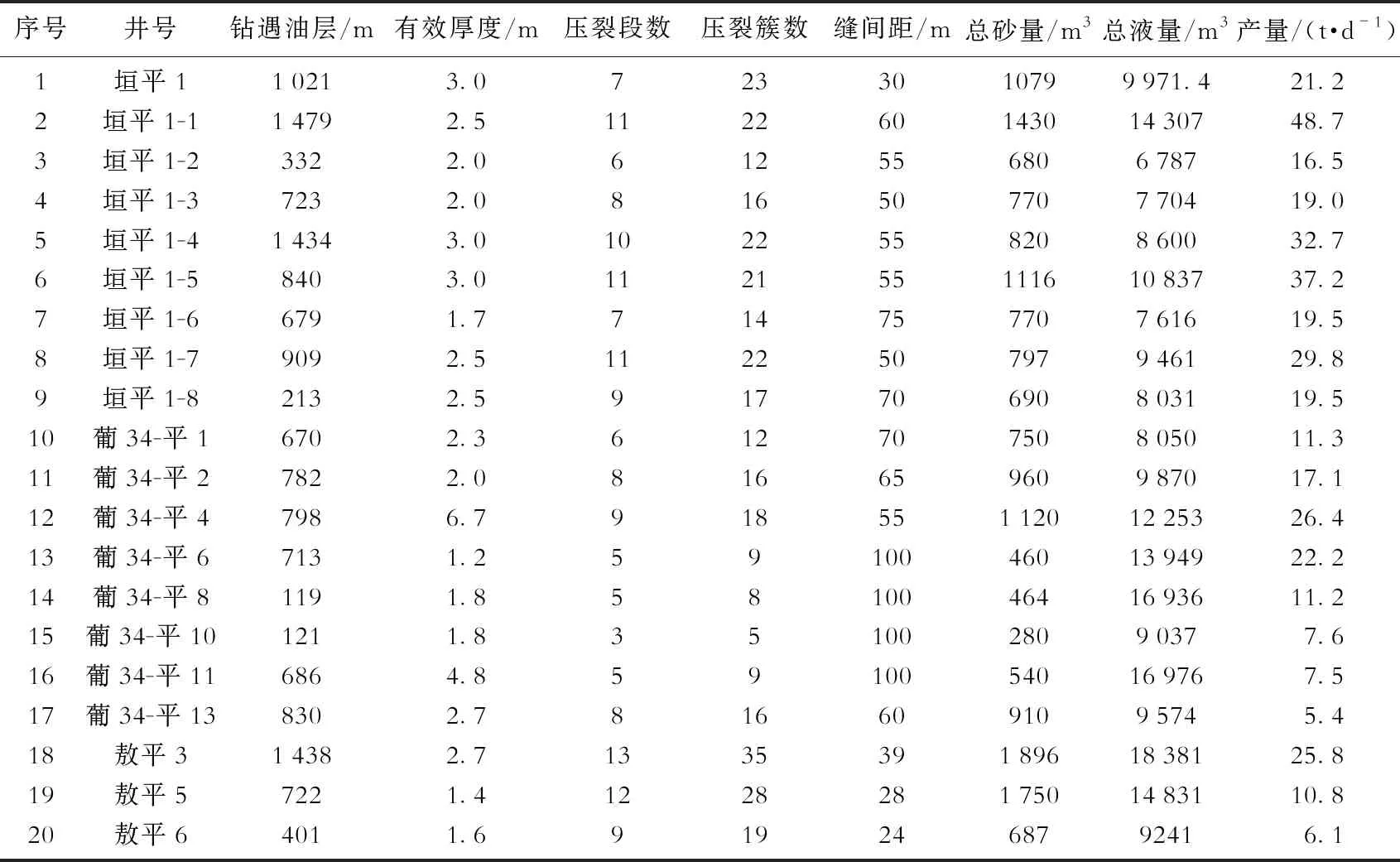
表2 M2区块水平井体积压裂初期产量数据
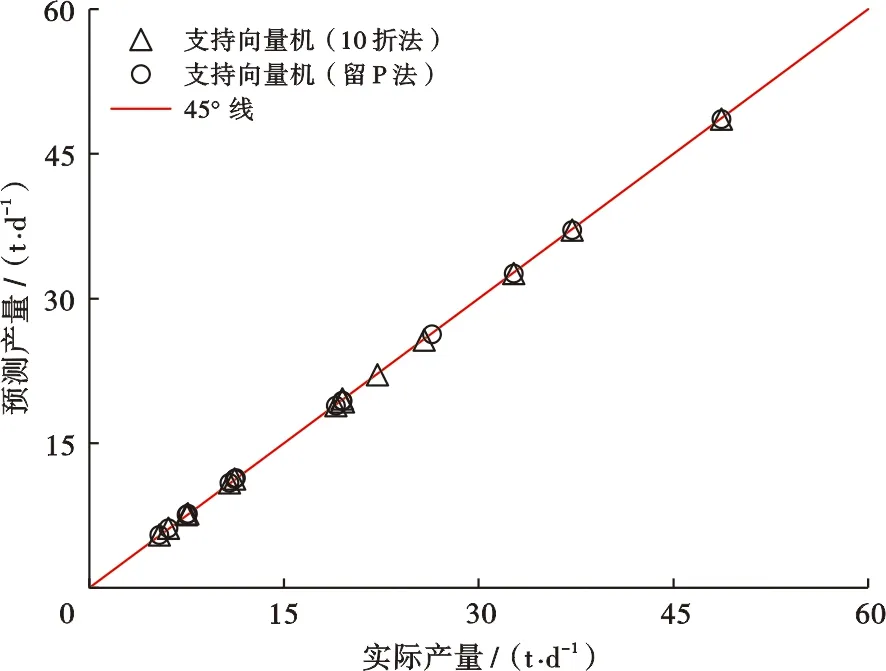
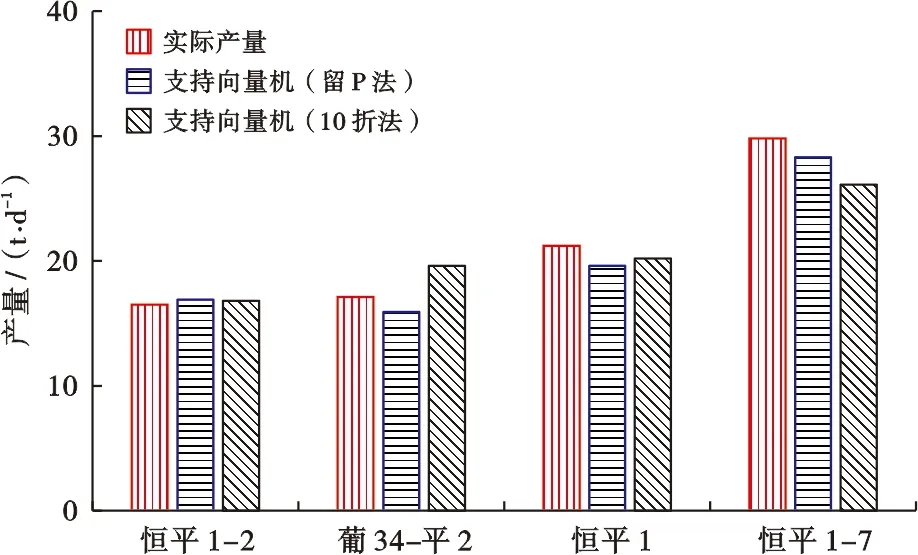
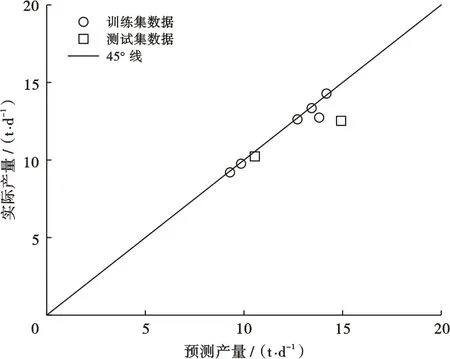
基于皮尔森、斯皮尔曼和肯德尔3种相关系数计算方法,获得了各参数的相关系数r(-1 表3 |r|的取值范围与意义 对输入特征采用3种相关系数进行计算,获得的特征与油井产量相关排序结果汇总在表4。可以看出,在正负相关性方面3种方法的结论是一致的,均认为缝间距和产量呈负相关关系,其余因素均为正相关关系。在相关程度大小方面,肯德尔系数和斯皮尔曼系数方法的结论基本一致,而皮尔森系数的结果认为总砂量的相关程度要略小于压裂簇数,油层厚度的相关程度要小于压裂段数,缝间距的相关程度要大于总液量。3种方法的侧重点不同,因此,为了更全面地评价输入特征,本文综合考虑3种相关系数的结果作为特征优选的依据。综合分析认为,7个参数中,钻遇油层对M2区块致密油藏水平井体积压裂产量的影响最大,总砂量和压裂簇数次之,其次为油层厚度和压裂段数,总液量和缝间距与产量的关联度最小。 表4 不同方法的相关系数对比 大数据时代背景下,机器学习方法泛化能力强,实际问题中应用效果好,在定量预测评价领域广受关注[21]。目前应用较广的方法有:随机森林、神经网络和支持向量机等。支持向量机方法的优势在于其计算的复杂度取决于支持向量的个数而不是样本空间维度,所以能有效地处理高维问题,而且对于小样本数据应用效果更好。该方法的缺点是对超参数的选取非常敏感,不同的超参数会对模型学习效果产生很大影响[22]。 图1 支持向量机回归原理示意图 对于非线性问题还需要引入核函数,把样本数据从低维空间映射到高维空间,将其转变成线性问题进行最优求解。径向基核函数学习能力强,计算精度高,应用最广泛,因此本研究选用径向基核函数[25-26]。径向基核函数公式如下: (4) 式(4)中:K为核函数;xi与xj为输入参数;g为核函数基宽。 不同参数之间量纲不同,数量级差异过大会导致模型构建难度增大,准确性降低。所以通常会对数据进行预处理,以此来避免不同参数之间的数值问题和量纲问题。本文分别使用未处理的原始数据和采用Z-Score标准化方法处理过的数据进行对比,发现采用标准化后的数据建立的模型运行速度更快、预测效果更好。标准化公式如下: (5) 式(5)中:X′为标准化后的数据;X为原始数据;σ为数据标准差;μ为数据均值。 主成分分析法能够在保留数据最大信息的前提下,对数据有效降维。采用降维后的新数据作为输入参数,可减少冗余信息干扰,提高模型计算速度[27]。本文采用PCA降维方法,基于筛选的水平井体积压裂7个主控因素,把数据维度降低了2个维度,信息保留百分比为97.81%。因此,本文采用PCA降维方法后,可以在最大程度上保留原始数据信息的同时,有效减少了模型计算量,提高了建模速度。 模型建立的关键是对数据的充分学习和对超参数的寻优。主要的建模过程包括:①设定超参数区间;②划分训练集与测试集的数据;③选取超参数结合交叉验证法构建模型;④评价建模效果;⑤对比选取最优超参数。 模型建立的常用方法主要有两种。第一种方法比较简便,首先把数据分为训练集和测试集,训练集数据用于学习后的模型构建,测试集数据用于模型验证。在此基础上,基于训练集数据的学习效果和测试集数据的预测效果进行评价。分类模型使用分类准确率评价,回归模型使用相对误差来评价。这种方法虽然可以快速地搭建模型。但在训练集和测试集划分的时候可能出现数据划分不合理导致的误差;此外,由于训练集数据仅用于学习,测试集数据仅用于检验,没能充分地利用数据信息,这种方法对于数据的利用率较低。 超参数寻优方法主要有启发式算法和最优化算法两大类。启发式算法主要包括基因遗传算法和粒子群算法等,分别通过模拟生物进化的自然选择原理和鸟群觅食行为中的群集智能原理进行筛选。启发式算法的优点是寻优速度更快,但可能会陷入局部极值的问题。最优化算法主要是网格搜索法,它能获得更好的寻优效果,缺点是寻优速度较慢。 本文分别对常规式和嵌入式两种网格搜索方法进行寻优效果的对比。对比发现,常规方法寻优参数间的步长变化较大,多次寻优过程可能会错过最优参数,因此需要多次改变参数范围进行寻优,效率较低。相比之下,嵌入式方法通过等步长逐步寻优来获取最优参数,寻优效率更高(表5)。 表5 核函数参数优选范围 建模过程中,首先将原始数据集分为训练集与测试集两部分,其中随机选择4口水平井作为测试集,剩余16口水平井用来构建模型。采用网格搜索法获得最优参数,训练集的预测效果如图2所示。从图2可以看出,支持向量机方法对于训练集数据拟合效果较好,基于支持向量机的10折法和留P法的训练集数据误差仅为0.79%和0.82%。 图2 训练集产量预测效果对比 4口验证井的预测结果如图3所示,支持向量机10折法预测效果较好,平均误差为8.4%;支持向量机留P法最优,平均误差仅为5.4%。 图3 测试集产量预测效果对比 分析认为,目前M2区块致密油藏仍处于开发初期,水平井体积压裂数量有限,适合小样本高维度的支持向量机方法预测效果较好。其中,支持向量机留P法在该阶段能更加充分地利用样本信息,非常适合初期压裂水平井的产量预测。不足之处是随着开发的继续进行,井数增加,留P法会产生巨大的计算量,运算速度开始下降。因此,随着开发井数的增加可选择运算速度更快的支持向量机10折法,数据量的增加可以提高模型的预测能力。 为了更好验证模型预测效果,基于本文的数据库并结合长庆油田X井区长7致密油水平井体积压裂的8组数据,构建产能预测模型,数据来自于文献[28]。预测效果如图4所示,其中,长庆油田X井区长7的6口训练集水平井的预测产量平均相对误差为2%,测试集两口水平井的预测产量平均相对误差为11%;说明构建的模型可以有效地应用于其他区块的产能预测工作中。 图4 长庆油田油井产量预测效果 1) 基于大庆油田M2区块20口典型致密油体积压裂水平井的油藏条件、储层性质和压裂参数,综合采用皮尔森系数、斯皮尔曼系数和肯德尔系数进行主控因素筛选和评价。钻遇油层和产量相关性最强,总砂量和压裂簇数次之,之后是油层厚度和压裂段数,总液量和缝间距与产量的关联度最小。 2) 在数据标准化和主成分分析的预处理工作基础上,采用支持向量机方法建立了目标油藏水平井体积压裂产能预测模型。对比发现,支持向量机10折交叉验证的精度较好,平均误差为8.4%,支持向量机留P交叉验证预测效果更好,平均相对误差仅为5.4%。 3) 由于不同方法各有优势,在致密油产能预测等相关领域的应用中,应该结合实际情况,进行不同开发阶段的机器学习方法优选。其中,支持向量机方法适合小样本高维度情况下的精准预测。建议在开发初期,井数较少时选用留P法;随着开发的推进,井数增加,建议优选精度较好、运算速度更快的10折法;当数据量更为充足时,可以考虑神经网络方法。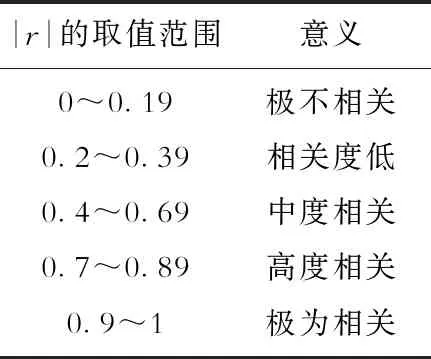

2 支持向量机方法的原理

3 数据预处理
3.1 数据的标准化
3.2 主成分分析(PCA)数据降维
4 模型建立
4.1 模型训练及测试
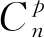
4.2 超参数寻优

5 模型验证与应用
5.1 模型验证
5.2 模型应用
6 结论
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
云南化工(2020年11期)2021-01-14 00:51:02
云南化工(2020年11期)2021-01-14 00:50:42
西南石油大学学报(自然科学版)(2019年2期)2019-04-25 13:07:26
西南石油大学学报(自然科学版)(2016年6期)2017-01-15 14:14:10
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
天然气勘探与开发(2015年3期)2015-12-08 08:28:37
西南石油大学学报(自然科学版)(2015年4期)2015-08-20 09:05:24
