
基于集成学习和代价敏感的类别不平衡数据分类算法
2022-03-11 08:40贺指陈
信息记录材料 2022年1期
贺指陈
(广东工业大学数学与统计学院 广东 广州 510520)
0 引言
现实生活中充斥着大量的类别不平衡的数据,类别不平衡的数据有着其某一类别样本数量远远多余其他类别的样本数量的数据特点。样本多的类别为多数类,反之样本少的类别叫作少数类,即多数类样本数量远远大于少数类样本数量的数据集称之为类别不平衡数据,如垃圾短信识别[1]、客户行为异常识别[2]、信用卡欺诈检测[3]、故障检测[4]等数据都是类别不平衡的数据。
传统的分类算法在处理类别不平衡数据时会倾向于把少数类和多数类分为一类,由于少数类样本量很少,这样处理整体的正确率尽管比较高,但是忽略掉了更应被重视的少数类,在实际应用中往往不能起到研究人员想要的效果[5]。为了较好地解决这个问题,研究人员提出了两个方向的解决方案。
一个方向是数据预处理方案,包括欠采样方法、过采样方法和混合采样方法。欠采样是指减少多数类样本的数量使之与少数类样本的数量达到平衡,随机欠采样算法的优点是简单快速,但是它可能会遗漏样本中的重要信息导致算法分类边界变得模糊。过采样方法是通过生成新的少数类的样本使之与多数类样本达到平衡。随机简单过采样因为其随机性容易使分类边界侵入多数类的区域导致效果不佳。Chawle,Bowyer & Hall等[6]的SMOTE算法是一种典型的过采样方法,它采用的采样策略是每次随机在两个近邻的少数类样本点之间随机生成新的样本点,通过迭代不断生成新少数类样本点来平衡数据集的不平衡性。Han,Wang & Mao等[7]认为更重要且难以区分的样本集中在分类边界上,对此提出了Borderline-SMOTE算法,该算法更加重视在分类边界附近的少数类样本,通过迭代,在分类边界附近生成新的样本点使分类边界变得清晰。混合采样是对多数类集合进行欠采样,少数类集合进行过采样组成新的训练集合再进行分类器的训练。冯宏伟等[8]的BMS方法引进“变异系数”识别出边界域和非边界域,进而过采样边界域中的少数类样本,欠采样非边界域中的多数类样本来解决问题。
另一个方向是从算法本身出发,其中常见的有代价敏感算法、集成学习。代价敏感算法[9]通过对样本赋予不同的权重更加重视少数类样本的分类来解决此问题。集成学习方法主要可以分为 bagging和 boosting两类,bagging是一种并行的算法,主要代表是随机森林[10](RandomForest),它利用bootstrap从原数据集中对属性随机采样出多个不同属性的子集作为训练集,对每个采样出来的子集进行训练,然后把训练出多棵决策树整合成森林。Boosting串行的算法,其主要代表是Adaboost[11]算法,通过训练弱分类器不断地更新训练数据集的样本权重和分类器的权重,正确划分的样本权重会被降低,错误划分的样本权重会被增大。最后将所有的弱分类器进行加权和运算组成一个强分类器集。Zhang[12]在Adaboost算法基础上提出了错分代价因子并将其加入到了样本权重的更新中,使得少数类错分时其对应的样本权重可以快速提高。Chawla,Lazarevic & Hall等[13]提出SMOTEBoost,将过采样思想与Adaboost结合以此解决少数类样本识别困难的问题。王和闫[14]提出USCboost算法,结合了Adacost算法和欠采样的思想,在每个基分类器训练完成之后,再根据多数类样本的样本权重,从大到小进行欠采样之后与少数类结合成临时训练集,以此训练下一个基分类器。Easyensemble是Liu,Wu & Zhou等[15]提出的一种集成学习的算法,该算法的结构与随机森林算法类似,先将多数类集合进行欠采样,采样出多个子集再分别与少数类集合结合成多个临时训练集,再以Adaboost算法对每个临时训练集进行训练,生成基分类器。
基于以上研究,本文将代价敏感思想引入Easyensemble算法,提出了USCensemble算法。该算法能有效减少噪声的影响,改进了欠采样的策略,将欠采样重心放在难以分类的多数类样本点上的同时,保留了临时训练集的随机性,提升了类别不平衡数据分类任务的分类性能。
1 相关工作
1.1 Adaboost算法
由多个分类器组合在一起共同完成任务的集成学习有着很好的泛化能力,集成学习不仅要求基分类器的效果好,还要求基分类器互不相同。Adaboost算法是一种典型的集成学习算法,每一轮通过弱分类器的预测结果来调整样本权重与分类器权重。分类正确的样本其样本权重降低,分类错误的权重升高,更加关注被错分的样本,使下一轮训练时着重改正之前的错误。最后通过加权平均法来整合所有的分类器以求理想的分类器有着不错的分类效果。通常将少数类记为1,多数类记为-1。
Adaboost算法执行步骤如下:
根据对Adaboost算法的研究,不难知道Adaboost算法虽然能关注到那些难被分类的样本,但是在处理类别不均衡的分类问题时,因为少数类集合样本数目的绝对稀少会让整个算法收敛的很慢以至于效果不佳。同时Adaboost算法有对噪声点很敏感这一缺点,所以噪声点对算法的分类边界也会有很大的影响。
1.2 EasyEnsemble算法
EasyEnsemble是一种带双层结构的集成算法,综合了Boosting、Bagging和欠采样技术,先从多数类中挑选出个样本数量等于少数类样本数量的子集,再将子集与少数类集合成个新的训练集,再将训练集用Adaboost算法进行训练生成弱分类器,最后将所有的弱分类器结合成强分类器。
EasyEnsemble算法执行步骤如下:
在EasyEnsemble算法中θi为调节参数,这一参数不仅需要自己调试,同时会根据临时数据集数量的不同而需要计算多个θi,这让EasyEnsemble算法的前期工作变得复杂。同时每一组训练集都是随机抽样,不能保证分类器的多样性,可能会丢失原数据集的某些特征,以至于在某些情况下效果不好。
2 基于集成学习和代价敏感的类别不平衡数据分类算法
通过对类别不平衡数据和现有针对此问题的分类算法所存在的不足进行研究,Adaboost算法虽然能在迭代过程中不停地提高错分样本的权重,但是由于此类数据多数类样本数量与少数类样本数量之比往往很大,以及数据本身类别之间的区分难度、特征维度等因素,容易导致Adaboost收敛过慢,效果不佳。于是本文算法将代价敏感思想引入Adaboost算法,赋予少数类样本更大的错分代价,使每一次迭代都能快速提高错误分类的少数类的样本权重,降低多数类的样本权重。
其中,n为少数类样本数量,m为多数类样本数量,k为数据样本数量。
考虑到EasyEnsemble算法结构能减少Adaboost算法中噪音的影响和分类边界附近有着更丰富的分类信息,本文提出了一类新的算法(USCensemble),该算法的关键是每个临时训练集是根据上一个分类器得到结果生成的,从多数类中选出权重重大的样本作为子集并与少数类样本结合作为临时训练集。本文新引入错分代价Ci和样本权重调节因子βi。具体计算公式如下:
USCensemble算法执行步骤如下:
3 实验结果与分析
3.1 评价标准
对于类别不平衡的分类算法,一般常用于评价分类算法的指标,如准确率和错误率已经不能很好地评价算法性能了。因为分类器会倾向于将少数类分到多数类去,由于少数类的样本数量绝对稀少,这样很轻松就能得到很高的准确率。然而这样并不能满足算法希望更关注于少数类的分类状况的需要。在二分类问题中,一般将数目少的类别(少数类)视为正例,数目多的类别(多数类)视为负例,混淆矩阵见表1。TP(TRUE POSITIVE)正类样本分为正类的频数,FP(FALSE POSITIVE)负类样本分为正类样本的频数,FN(FALSE NEGATIVE)正类样本分为负类的频数,TN(TRUE NEGATIVE)负类样本分为负类的频数,见表1。

表1 混淆矩阵
类别不平衡分类算法需要新的评价指标,因为任务是对类别不平衡的样本进行分类,更关注少数类的分类情况,所以本文选取Recall、f1-measure值和g-mean值来对算法效果进行评价。
3.2 实验方法
本文选择Adaboost、Adacost、USCboost、EasyEnsemble 4种算法作为对比算法,都采用深度为5的算法作为基分类器。在10个uci数据集上进行性能评测,数据集信息见表2;本文将数据集的目标类别设置为正类,其他类别设置为负类。因为EasyEnsemble和本文的USCboost算法都有多层结构,此时需要事先设定基分类器。表2第4列给出了基分类器设置,例如3*9表示在abalone数据集上采样出9组子集,每组子集数据训练3次,其他类同。为保证公平性,Adaboost、Adacost、USCboost算法都训练27个基训练器,采用了10倍交叉验证,以考察算法的泛化性,见表2。

表2 实验数据集
3.3 结果与分析
实验分析了5种算法在10个uci数据集下各自的Recall值、f1-measure值和g-mean值,并加粗了每组数据下数值最高的评价指标,见表3。
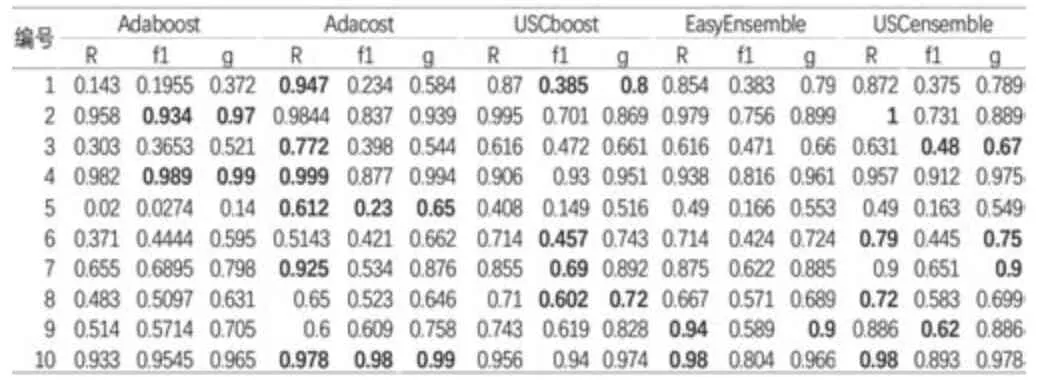
表3 不同算法R、f1、G值对比
f1-measure值和g-mean是能体现类别不平衡分类算法性能的有效指标,从表3来看Adaboost算法在uci数据集上的Recall值、f1-measure值和g-mean值都不太理想,综合表现较差,不能很好地完成类别不平衡的分类任务。尽管Adacost算法在一些数据集的表现非常不错,但在大部分数据集上都没有较高的f1-measure值和g-mean值。从f1-measure值和g-mean值上来看USCboost、EasyEnsemble、USCensemble算法对类别不平衡数据的分类任务有着较好的效果。这3种算法在处理类别不平衡数据分类任务时是有效的。
为了更直观地对比3种算法的性能,图1、图2和图3展示了USCboost算法、EasyEnsemble算法和USCensemble算法在10个数据集上的实验结果柱状图。其中,横坐标表示数据集,纵坐标表示实验评价指标数值取值范围。可以发现USCensemble在分类任务中往往有较高的Recall值,能有效将正类样本识别出来,这是因为USCensemble任务,采取了多层结构能有效地避免噪声的影响,同时在采样分组时能关注那些在分类边界附近分错了的样本点,实现了有着较高Recall值的同时,保持不错的f1-measure值和g-mean值的目的,证实了该方法的有效性。
4 结语
本文通过对现有的Adaboost类算法在类别不平衡的分类任务上存在的问题进行研究。结合各类算法的优点,采取多层迭代的方式和代价敏感的思想,避免了噪声的巨大影响,同时关注于分类边界上的信息,使算法更在意少数类的分类情况而又不过度拟合。本文发现类别不平衡度对算法性能影响有限,而各类别之间的差异程度会对算法性能产生一定的影响。因此对数据集采取一定的预处理,深度挖掘原始数据的特征信息是否能提高算法的性能将是今后研究的重点。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
中学生数理化(高中版.高一使用)(2021年9期)2021-12-02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
陶瓷学报(2021年4期)2021-10-14
计算机系统应用(2021年2期)2021-02-23
少儿画王(3-6岁)(2020年4期)2020-09-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
计算机应用与软件(2020年1期)2020-01-14
计算机测量与控制(2019年4期)2019-05-08
都市丽人(2015年4期)2015-03-20
