
基于区块链的水产品交易溯源系统研究与实现
2022-03-10 04:52冯国富胡俊辉
渔业现代化 2022年1期
冯国富,胡俊辉,陈 明
(1上海海洋大学信息学院,上海 201306;2 农业农村部渔业信息重点实验室,上海 201306)
水产养殖业在农业经济发展中占有重要地位,据统计,2020年中国水产品总产量为6 549万t,其中养殖产品占比达到了79.8%[1]。近年来,水产品质量安全事件频发,不仅危及人们的身体健康,对水产养殖业发展也有不利影响[2-3]。在水产品交易环节中,交易数据的安全至关重要,这些数据不只是消费者进行水产品质量追溯的依据,还能让养殖企业带来更高经济收益。在传统水产品交易模式下,数据多采用中心化的存储方式,数据的安全可靠性得不到保证[4-5]。当存储数据的中心服务器出现故障时,数据就会存在丢失的风险,并且中心化存储的数据有可能会被篡改,数据可靠性存疑。除此之外,数据不能共享且溯源困难,水产品的养殖厂家、经销商以及消费者之间的数据是不互通的,因此导致交易链的上下游不能有效协同,数据溯源的透明性较低,出现问题无法第一时间定位。
区块链具有去中心化、可追溯和不可篡改的特点[6-9],区块链的出现为解决水产品交易中存在的数据安全问题提供了新的解决思路。首先,区块链是由多方参与共同维护的分布式数据库,不存在中心化的管理机构,解决了中心化存储数据不可靠的问题[10]。其次,区块链运用密码学技术,每个区块包含前一个区块链的哈希(Hash)值,形成有序的链式结构,确保数据不易被篡改[11]。最后,区块链具有可追溯性,共识机制保证节点间的数据共享和监督,存储于区块链之上的每一条记录、每一笔交易都可以进行可信溯源[12]。但是将区块链技术直接应用于水产品交易数据存储会存在问题,一是水产品交易环节中节点众多,产生的数据量较大,如果这些数据直接存储到区块链网络上,会给区块链存储容量造成压力。二是要保证交易的隔离性,即当前交易参与主体间的操作对其他主体是不可见的,数据加密之后再进行传输。
本研究以Fabric区块链平台为基础,通过对水产品交易流程分析,梳理并提炼出交易环节中关键主体和数据,提出基于区块链的水产品交易数据溯源系统模型。在该模型中,数据不直接存储在区块链网络中,而是结合星际文件系统(IPFS)存储原始数据,区块链网络中只需要存储IPFS的文件Hash地址降低链上存储压力。在此基础上,提出了系统访问权限控制方案,不同主体间进行数据交易时运行在独立的通道内,每个通道有独立的账本和智能合约,不同通道间数据隔离,保证数据的隐私性和安全性。
1 相关背景
1.1 区块链
区块链是一种分布式去中心化账本[13-14],随着区块链在不同领域研究的深入,区块链的应用也越来越多样化,学者们提出了许多数据存储和溯源方案[15-17]。Xie等[18]基于区块链提出了一种双链存储结构进行农产品数据的存储,利用链式数据结构存储交易的哈希值,然后将其与区块链链接在一起形成链式结构,保证数据不会被篡改。Hao等[19]提出了一种基于IPFS和区块链的农产品数据存储模型,将传感器数据存入IPFS文件系统,然后利用区块链存储分布式文件系统IPFS的哈希值,确保数据安全。葛艳等[20]将区块链技术与危害分析及关键控制点(HACCP)结合,提出了生食牡蛎的质量溯源模型,通过设计智能合约,对链上和链下数据进行监控并进行质量判断。李梦琪等[21]通过分析水产品供应链的关键信息,提出了一种主从多链存储模型对供应链溯源信息进行管理,保证了溯源数据的真实性和追溯过程的透明化。赵磊等[22]从信息生态视角分析用户需求,提出追溯参与主体的风险补偿方案,并进行信息链流程再造,给出了一种基于区块链的生鲜食品追溯模型。以上基于区块链的数据溯源模型都有各自的优点,但是水产品交易数据溯源场景下数据量较大,直接存储在区块链之上会给链上造成很大压力,并且交易数据的隐私性应该进行控制。因此,本研究结合区块链技术的优势以及现有溯源系统的不足,提出区块链在水产品交易数据上的溯源模型。
1.2 星际文件系统
IPFS是一个由所有参与的节点共同构成的分布式文件系统[23-24]。IPFS在进行数据存储时不会受到文件大小的限制,因为它会将文件分为大小相等的数据块,每一块数据都有一个对应的Hash值,根据这些Hash值可以构建出一张文件检索表,从而可以实现将这些数据块分散存放在不同的服务器上[25]。
在进行数据查询时,只需要输入要查询的文件Hash值,IPFS就会根据文件检索表去对应的文件服务器上查询数据并返回。IPFS分布式的特点使其可以天然地与区块链结合,区块链网络中不再存放完整的数据,只需要存放对应数据文件的IPFS散列地址,从而节省区块链的网络带宽,降低链上存储压力。
2 系统模型
2.1 水产交易流程分析
在整个水产品交易流程中,首先要保证源头数据的真实可靠,即保证消费者购买到的水产品的养殖信息是真实可追溯的。水产品交易溯源流程如图1所示。

图1 系统流程图
整个流程主要包括3个主体,分别为养殖厂、消费者和监管部门。在水产品流入市场进行交易前,养殖厂首先要将水产品的养殖信息,如池塘编号、水产品种类、入塘时间和捕捞时间等信息通过智能合约协调IPFS和区块链的工作,将原始数据存入IPFS中,再将返回的IPFS地址Hash值上传至区块链网络。消费者和养殖厂进行交易时,也需要将这些水产品的订单交易记录,包括买卖双方姓名、水产品名称、重量、单价和订单金额等信息结合IPFS进行存储。在交易完成之后,如果消费者发现购买的水产品出现食品质量安全问题,也可以将投诉信息上传至IPFS中进行存储。监管部门根据投诉信息在IPFS中找到对应交易订单信息和问题水产品的养殖信息,若该批次水产品存在质量问题,可以及时进行处理。
2.2 系统结构
联盟链Hyperledger Fabric平台具有去中心化、部署成本低、可扩展性高和数据安全可追溯等特点[26]。因此,通过对水产品交易流程分析,结合Hyperledger Fabric平台提出了系统整体架构。系统整体架构设计如图2所示,自上而下可分为应用层、数据库层、网络层和数据层。其中区块链技术主要用于数据库层和网络层。

图2 系统整体架构
应用层是在区块链网络的基础上,通过在区块链中编写智能合约对外提供API接口,设计一个水产品交易溯源平台,利用可视化的界面提供信息交互服务,面向的对象为水产品养殖厂、消费者和监管部门。
数据库层包括区块链网络中的分布式账本和IPFS文件系统。系统中所有的原始数据在IPFS中进行存储,数据存储完成后IPFS会返回对应文件的地址Hash值。区块链网络中的分布式账本存储的不再是原始数据,而是地址Hash值。为了实现数据隐私保护,文件地址Hash值在提交上链之前先通过对称加密的方式进行加密,然后再做上链处理。通过这种方式可以实现上传地址Hash值不会被通道内的其他用户看到,并且只有获得访问权限的用户才可以查看区块链网络中的地址Hash值,最终实现根据地址Hash值从IPFS文件系统中获取原始数据。
网络层采用共识算法解决用户之间的信任问题,通过共识机制选取背书节点进行数据验证。基于工作量证明的PoW共识算法会消耗很大的算力资源,不适合在商业领域应用[27]。因此,本研究使用了更加高效的Kafka共识算法,采用一组排序节点对消息进行处理,根据排序之后的结果进行上链处理[28]。网络层还要进行节点的访问权限控制,通过多通道机制实现通道间的数据隔离,通过证书颁发机构(Certification Authority,CA)签发证书控制节点对数据的访问,实现数据的隐私保护。
数据层作为最底层主要进行3部分数据信息的收集。一是水产品养殖过程中的数据,如池塘编号、水产品种类、入塘时间和捕捞时间等。二是交易过程中的订单数据,如买卖双方姓名、水产品名称、重量、单价和订单金额等。三是交易完成之后消费者给出的反馈数据,如质量问题的类型和描述、水产品名称和对应订单号等。
3 系统实现
3.1 Fabric网络环境模块
图3所示为根据系统流程图设计的Fabric网络结构模型,Fabric网络采用单机多节点的部署方式。在Fabric网络中,每1个参与主体对应1个组织节点,使用配置文件的方式创建系统所需要的养殖厂、消费者和监管机构3个组织节点,并通过Fabric模块生成对应的数字证书、数据文件和通道创始区块。每个组织下面包含2个Peer节点,用于实现各组织的背书、记账等功能。除此之外,需要配置CA证书节点和排序节点,CA证书节点用于给用户分发并且验证证书,排序节点用于对传递的消息进行排序以便后续生成相应的区块。在Fabric网络中,每一个组织都有相应的CA证书机构给用户颁布证书进行身份验证,采用支持富查询的CouchDB数据库作为Fabric的状态数据库,每个组织配有相应的数据库进行数据存储。共识模块是由多个Order排序节点组成的Kafka集群来实现的,它具有高扩展性的特点,并且由于多个排序节点的存在,具有很高的容错能力。
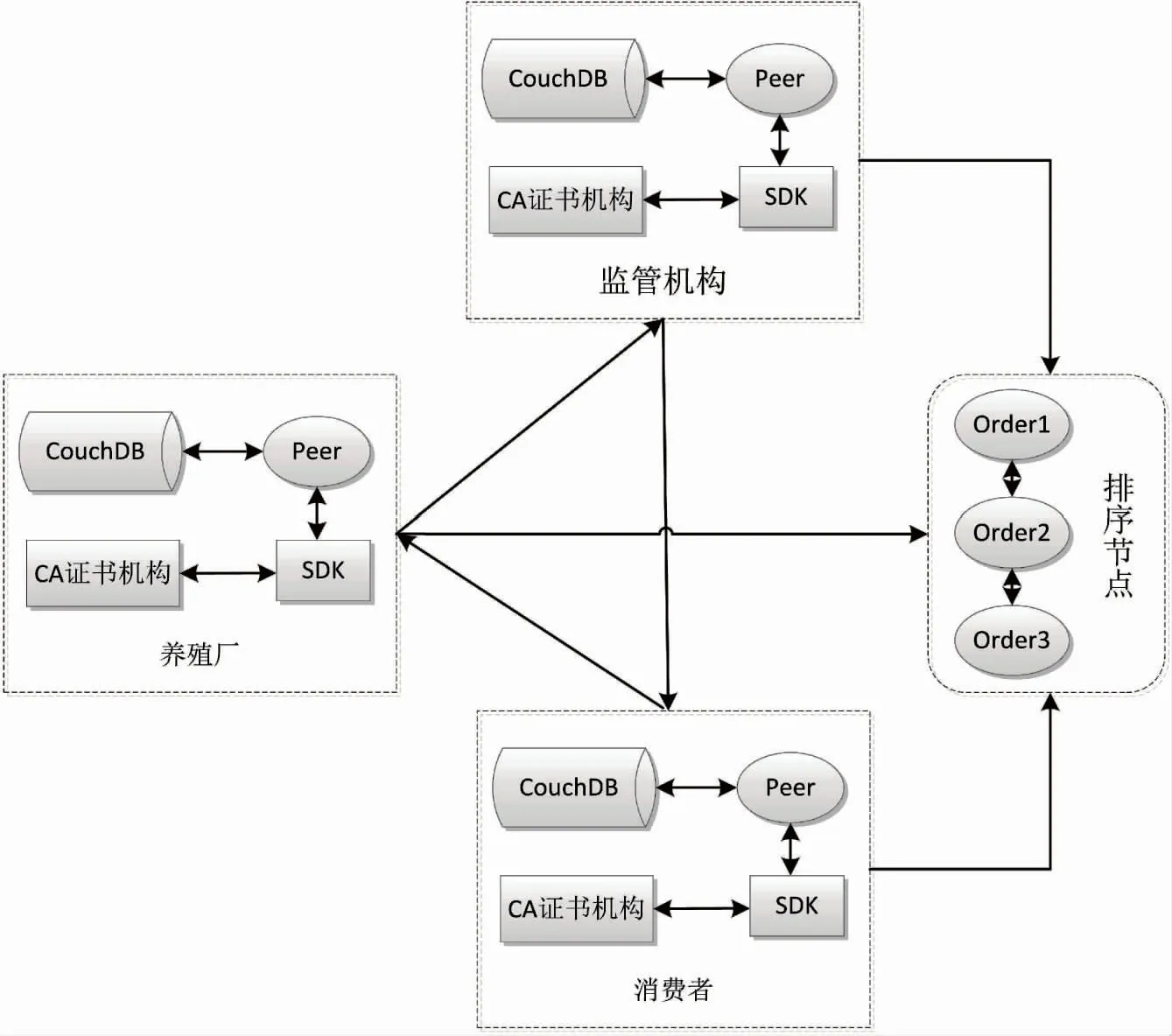
图3 Fabric网络结构模型
系统中存在养殖厂、消费者和监管机构3个组织,其中,组织标志符、组织ID和各个组织安装的智能合约信息如表1所示。

表1 系统组织表
3.2 系统访问权限控制模块
在系统模型中,养殖厂、消费者和监管机构3个组织下存在不同的用户,用户之间应当是相互独立的,当消费者A进行数据查询时,对其他消费者来说应该是不可见的。因此,本研究在系统模型中配置了多条通道,每条通道拥有自己独立的账本和智能合约。从系统上看,通道仍然是由Order节点进行管理,划分目的只是为了将不同的通道信息进行隔离,保证数据交易信息的安全性和隐私性。
如图4所示为系统的通道设计模型,在该系统模型中,所有的节点会共同加入一个公共通道之中,他们共同维护一个账本并将自己的数据写入其中进行交易。channel1和channel2是按照业务需求划分的私有通道,私有通道之间以及私有通道和主通道之间都是隔离的,可以保证数据的隐私性。在该模型中,养殖厂不希望养殖数据直接被其他养殖企业看到,消费者也不希望将自己的消费信息暴露出去。因此,养殖企业BP1和BP2分别订阅channel1和channel2通道,购买了相应企业水产品的消费者C1和C2也会订阅对应的通道,监管机构根据业务需求订阅需要监管的通道。在图4中,BP1和C1在channel1通道中进行交易,BP2和C2在channel2通道中进行交易,通道外组织节点无法查看交易数据。
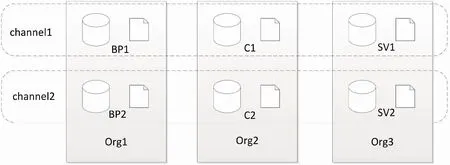
图4 多通道设计模型
除了对区块链网络进行多通道划分,数据在网络中应该以密文的方式进行传输,确保数据的隐私性。当用户不希望IPFS文件数据的地址Hash值直接被通道内其他用户看到时,可以对其加密后再进行上链操作。如当通道内用户A上传地址Hash值并且只希望同一通道内的用户B查看时,可以采用对称加密算法对地址Hash值进行加密,上链过程可以描述为:用户A首先获取用户B通过AES(Advanced Encryption Standard)生成的密钥K,对地址Hash值进行对称加密。加密函数定义为encrypt(K,Hash),加密后的地址Hash值为E_Hash,加密完成之后再将密文E_Hash上传至区块链网络。当用户B要查询原始数据时,首先会从区块链中获取加密之后的地址Hash值E_Hash,然后使用密钥K对E_Hash进行解密获取地址Hash值,解密函数定义为decrypt(K,E_Hash),最后再根据IPFS文件的地址Hash值执行查询操作获取原始数据。
3.3 智能合约模块
在Fabric平台中,智能合约又被称为链码,链码是连接客户端与Fabric网络的桥梁[29]。链码就是一段程序代码,用来表示系统流程的业务逻辑,也需要通过编译之后才能够运行,链码在经过编译和部署之后,一般运行于Docker容器之中。在Docker容器中,客户端可以通过调用链码,完成数据的发布和查询操作。链码可以由多种语言进行实现,本研究选用Go语言编写,系统编写的部分智能合约接口如表2所示。

表2 智能合约接口说明
链码的主要功能包括发布和查询水产品养殖信息、水产品交易数据信息和问题投诉信息。根据组织的不同安装对应的链码,链码部署成功后首先会调用Init方法进行系统的实例化,然后执行Invoke方法发起交易执行定义的业务功能。以水产品养殖信息发布为例,当用户在客户端执行养殖信息发布操作时,数据存储的业务逻辑如图5所示。
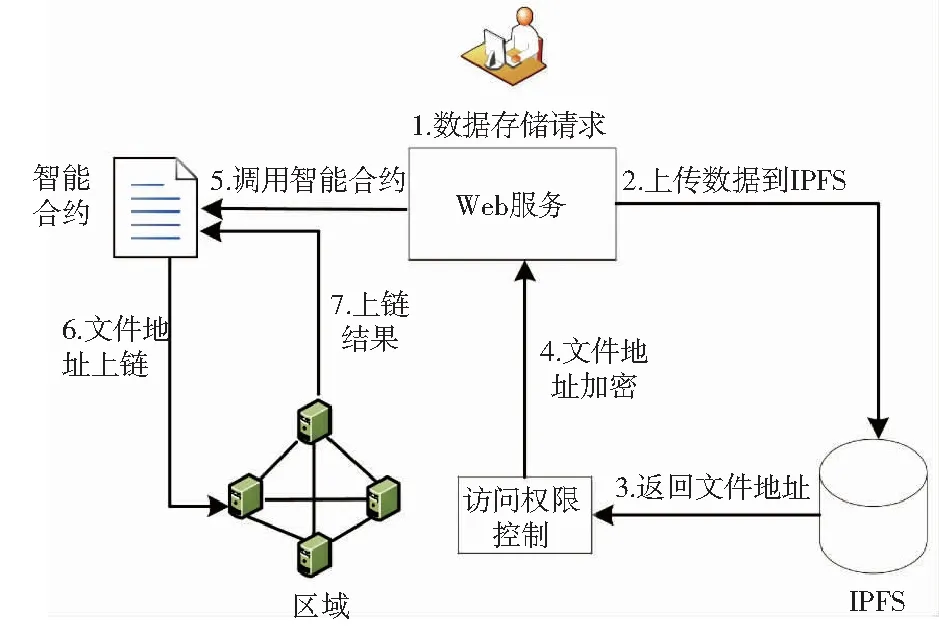
图5 养殖信息上传流程图
用户登录成功后会发起数据发布请求,首先会进行权限认证验证节点身份信息,然后执行文件上传操作将数据提交到IPFS中并返回存储该文件的地址Hash值,再将返回的地址Hash值进行加密,最终通过调用智能合约将加密后的地址Hash值通过底层共识机制完成上链。
当用户需要查询水产品养殖信息时,数据查询的业务逻辑如图6所示,用户在前端界面发起查询请求后,节点首先进行身份验证获取访问权限,然后调用智能合约执行查询操作,从区块链上获取IPFS地址Hash值密文,再将地址Hash值进行解密,最终根据地址Hash值从IPFS中获取原始数据返回给前端用户。

图6 养殖信息查询流程图
4 系统测试与分析
4.1 功能测试
在虚拟机VMware中完成水产品交易溯源系统环境的搭建,操作系统为Ubuntu16.4。虚拟机的配置为内存2 GB,硬盘为40 GB,Hyperledger Fabric版本为1.2,采用JavaScript进行Web服务开发。
在Fabric网络环境中,系统采用单机多节点部署的方式,通过在Cryptogen模块中配置3个节点来模拟系统中的Org1、Org2和Org3共3个组织,每个组织下分别有peer0和peer1共2个节点。系统首先生成每个节点的证书文件并存放在本地,然后执行创建通道的命令,根据业务规则创建2个私有通道channel1和channel2,同时执行命令将对应节点加入通道内,最后在每一个组织节点中安装链码完成网络启动。用户在登录时会对节点身份证书进行认证,只有在证书认证通过以后才可以进行操作。
水产品交易溯源系统提供的功能包括水产品养殖数据、订单数据和问题反馈信息的发布和查询。当用户登录系统后,系统访问权限控制模块会根据当前用户所在组织的权限,控制用户可以执行哪些业务功能。如当登录养殖厂用户peer0org1,用户所在组织为Org1MSP,节点发起交易订单数据发布请求后,首先需要在前端用户界面输入订单交易数据的相关信息,然后节点会调用安装在Org1组织内的智能合约执行上链操作。操作是在一个单独的通道内完成,对于未订阅该通道的组织和用户,所有的数据都是不可见的。订单数据发布成功之后,拥有权限的组织内的节点可以根据订单编号查询该订单的详细信息进行验证。如图7和图8分别为根据交易订单编号查询订单详细信息和根据水产品编号查询水产品养殖信息,系统首先验证当前peer节点的证书keyStore是否正确,验证成功后调用智能合约执行相应的业务逻辑返回结果。
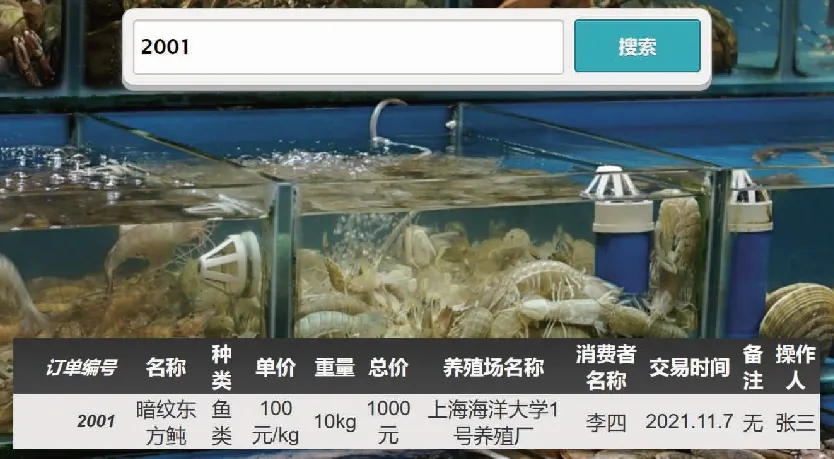
图7 交易订单数据查询界面

图8 水产品养殖信息查询界面
4.2 性能测试
对于系统整体性能,主要关注系统的吞吐量(Transaction Per Second ,TPS)。采用HyperLeager项目中的Caliper性能测试框架,测试在系统交易量为100~700笔/s时,吞吐量的变化情况。如图9所示,横坐标表示交易的并发数,纵坐标表示系统吞吐量,当发送请求数量在0~200次/s之间时,系统吞吐量呈稳步上升趋势。当发送请求数超过200次/s时,系统吞吐量在220笔/s左右波动,此时已经为系统最大吞吐量。
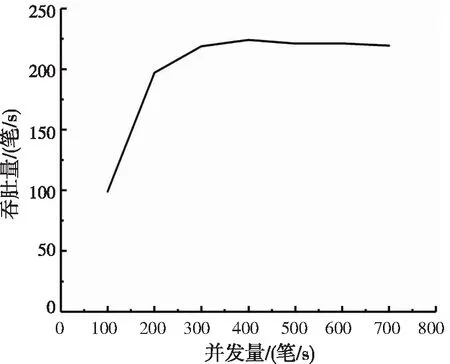
图9 系统吞吐量测试结果
通过对系统的功能和性能进行测试和分析可知,系统功能的有效性得到了验证,性能上220笔/s交易的吞吐量可以应用于生产实践[30],完成了预期的设计目标。将本研究提出的模型与其他几篇文献模型对比如表3所示。
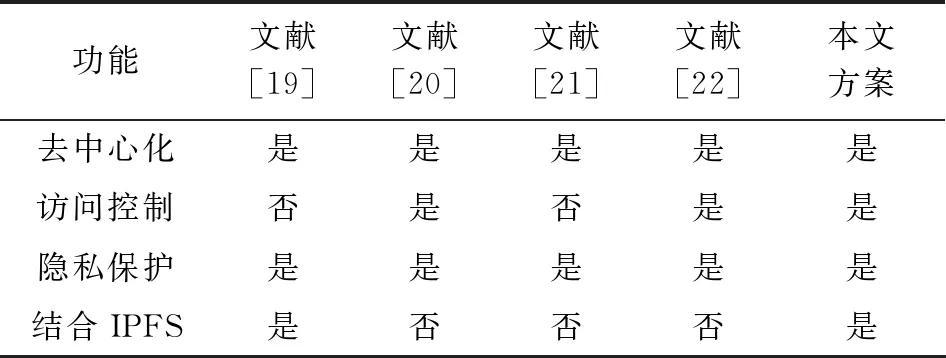
表3 方案性能对比
可以发现,5篇文章的模型都是基于区块链去中心化的特点实现了数据的发布和追溯功能。文献[19]和文献[21]均没有访问控制机制,本模型进行了完善的通道设计,并且通过智能合约来进行访问控制,数据的隐私性较好。除此之外,文献[20-22]均未将区块链与分布式文件系统相结合,数据直接存储在区块链网络上,本模型结合IPFS的存储方案使得该模型在进行大文件存储时有更好的适用性。但是,本研究模型未采用物联网、传感器设备实时采集数据,下一步可将区块链技术与物联网技术相结合,进一步提升数据的可信性。
5 结论
本研究从水产品交易流程出发,提出了一种基于区块链的水产品交易溯源模型,基于Fabric技术框架和分布式数据存储方案IPFS实现了该系统。通过区块链去中心化的特点和共识机制解决了水产品交易数据在中心化存储模式下面临的安全问题,同时利用分布式文件系统IPFS降低了链上的数据存储压力。在此基础上,进行了多通道设计和访问权限控制,用户只能访问所在通道内的数据,提高了数据的隐私性。从性能上看吞吐量为220笔/s左右,方案的可行性和有效性得到了验证。在水产品供应链交易中引入区块链技术,保证供应链中数据的完整性和安全性,防止信息孤岛和篡改。这些数据对于水产品的质量安全监控,以及提升养殖厂的经济效益具有很大的作用,为整个水产品供应链良性运转提供了保障。
□
猜你喜欢
当代水产(2022年4期)2022-06-05
现代电子技术(2022年4期)2022-02-21
卫星电视与宽带多媒体(2020年7期)2020-06-19
红楼梦学刊(2020年3期)2020-02-06
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
中国计算机报(2019年8期)2019-03-27
当代贵州(2018年21期)2018-08-29
南都周刊(2018年6期)2018-06-23
农家顾问(2016年11期)2017-01-06
农家顾问(2016年6期)2016-05-14
