
融合目标端句法的AMR-to-Text生成
2022-03-09 11:52李军辉
中文信息学报 2022年1期
朱 杰,李军辉
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
抽象语义表示(Abstract Meaning Representation,AMR)[1]是一种新型的语义表示方法,其是从文本中抽象出来捕捉核心的“谁对谁做了什么”的语义结构,形式上是一种单根有向无环图的结构。图 1 给出了一个AMR图示例,它是由句子 “It begins and ends with Romneycare.” 抽象而成的。文本中的实词被抽象成AMR图中的概念节点(concept),如图中“begin-01”和“thing”等节点称为概念。概念之间的相互关系则被抽象为边(edge),表示两个概念之间存在的语义关系,例如,“: ARG0”和“: op1”等。AMR图在语义表示中已经得到了广泛应用,且在机器翻译[2]、问答系统[3]、事件抽取[4]等自然语言处理相关任务中也得到了实践。与此同时,AMR-to-Text生成在近年来也受到了越来越多的关注。

图1 "It begins and ends with Romneycare. "抽象成AMR图的一个例子
AMR-to-Text生成是在给定AMR图的条件下,自动生成相同语义的文本。该任务现存的一些方法都着重考虑如何对图关系进行建模,从而忽略了生成时存在的句法约束。
最初的工作是采用基于统计的方法[5-7],随后Konstas等人[8]将该任务引入到了序列到序列(sequence-to-sequence,S2S)模型上,使用双向长短时记忆网络(Bi-LSTM)进行编码。但是S2S模型需要将AMR图进行序列化去适应模型的输入,这样会损失大量的图结构信息。因此,为了更好地对图关系进行建模,Beck等人[9]、Song等人[10],Damonte等人[11]、Guo等人[12]、Zhu等人[13]提出了图到序列(graph-to-seq,G2S)的框架,使用图模型来对AMR图进行建模。
然而,他们的工作都将句子表示为单词序列,并没有考虑到句子中潜在的句法信息。最近的一些研究也表明,即使百万级的平行语料,模型仍然无法从中捕获深层的句法信息[14]。
针对上述问题,本文提出一种显式的方法来融入句法信息,从而给定生成时的一些句法约束,并且不需要对模型本身进行任何修改。为了更好地验证本文方法的有效性,作者选取了S2S中最优的Transformer模型和G2S中现存最优的模型[13]进行了实验。最终,在两份标准的英文数据集LDC2015E86和LDC2017T10上均取得了显著的性能提升。
1 相关工作
目前AMR-to-Text生成的任务大致可以分为两类: 基于统计的方法和基于神经网络的方法。而基于神经网络的方法,现在又可以分为seq2seq和graph2seq两类。
1.1 基于规则的方法
早期神经网络未普及时,在AMR-to-Text生成上的工作大都使用基于统计的方法。Flanigan等人[7]将AMR图转换为合适的生成树,并应用树-串(tree-to-string)转换器生成文本。Song等人[15]将一个AMR图拆分成许多小的片段,并生成所有片段的翻译,最终通过采用非对称广义旅行商问题解法来确定片段顺序。Song等人[6]使用同步节点替换语法来对AMR图进行解析,并生成相应的句子。Pourdamghani等人[5]采用基于短语的机器翻译模型来对线性化AMR图进行建模。
1.2 基于神经网络的方法
随着神经网络的兴起,最近的研究都是使用神经网络来生成。在Sutskever等人[16]证明了深度神经网络的优越性之后,Konstas等人[8]提出使用序列到序列(S2S)模型来生成文本,利用双向LSTM来对线性化的AMR图进行编码。为了限制生成的文本具有更合理的句法,Cao等人[17]将AMR-to-Text生成的任务拆分成两个步骤,先使用句法模型去预测最优的目标端句法结构,再利用预测的句法信息去辅助生成模型更好的生成句子。但是这些方法也相应地损失了深度神经网络端到端的特性,并且和本文方法相比更加复杂,增加了网络的复杂度和参数。
随后,为了解决seq2seq模型将AMR图线性化之后信息损失的问题,大家的研究热点主要集中在图神经网络上。图到序列(Graph-to-Sequence)模型常优于序列到序列(S2S)模型,包括图状态LSTM[10]、GGNN[9]等。图状态LSTM通过每步迭代交换相邻节点的信息来更新节点。同时也对每个节点增加一个向量单元保存历史信息。GGNN是一个基于门控的图神经网络,将AMR图结构完整地融入模型中,并且将边信息也转化为节点,解决了参数爆炸问题,也给了解码器更丰富的信息。为了解决AMR图中重入节点的问题,Damonte等人[11]提出了一种堆栈式的编码器,由图卷积神经网络和双向LSTM堆栈组成。Guo等人[12]提出了一种深度连接图卷积网络(GCN),可以更好地获取局部与非局部信息。Zhu等人[13]在Transformer的基础上,受到Shaw等人[18]对相对位置建模的启发,提出了一种Structure-Aware Self-Attention的编码方法,可以对图结构中任意两两节点进行完整的建模(不论节点之间是否直接相连),在该任务上取得了最优结果。
2 方法
本文采用了两种方法作为基准模型(Baseline)。
(1)Transformer模型: 最先进的seq2seq模型,最初使用于神经机器翻译和句法分析任务[19]。
(2)Structure-Aware Self-Attention模型: 目前在AMR-to-Text生成的任务上取得了最高的性能。
2.1 基础模型1(Baseline1)——Transformer模型
2.1.1 Transformer
Baseline1使用Transformer模型,它采用编码器-解码器(Encoder-Decoder)的架构,由许多编码器和解码器堆栈组成。每一个编码器都存在两个子层: 自注意力机制层(self-attention)后面紧接着前馈神经网络层(position-wise feed forward)。自注意力层使用了多个注意力头(attention head),将每个注意力头的结果进行连接和转换之后,形成自注意机制层的输出。每个注意力头使用点乘注意力机制(scaled dot-product)来计算,输入一个序列x=(x1,…,xn),得到一个同样长度的新的序列z=(z1,…,zn),如式(1)所示。
z=Attention(x)
(1)
其中,xi∈Rdx,z∈Rn×dz。 每一个输出元素 zi是输入元素的线性变换的加权和,如式(2)所示。

(2)
其中,WV∈Rdx×dz是一个可学习的参数矩阵。式(2)中的向量αi=(αi1,…,αin)是通过自注意力机制得到的,该机制捕获了xi和其他元素之间的对应关系。 具体来说, 每个元素xj的自注意力权重αij是通过一个softmax函数计算得到,如式(3)所示。
(3)
其中,
(4)
是一个对齐函数,它用来度量输入元素xi和xj的匹配程度。WQ,WK∈Rdx×dz是可学习的参数矩阵。
2.1.2 线性化预处理
因为Transformer是seq2seq模型,只支持序列化的输入,所以需要对AMR图进行线性化的预处理。本文采用Konstas等人[8]提出的深度优先遍历的线性化方法来对AMR图进行预处理,从而得到简化版的AMR图。在线性化之前,首先移除了图中的变量、wiki链接和语义标签。图2展示了一个AMR图线性化示例。

图2 一个AMR图线性化实例
2.2 基准模型2(Baseline2)——Structure-Aware Self-Attention
2.2.1 Structure-Aware Self-Attention
Zhu等人[13]扩展了传统的自注意力机制框架,提出了一种新颖的结构化的注意力机制,在对齐函数中显式地对元素对(xi,xj)之间的关系进行编码,用式(5)替换式(4)。
(5)
其中,WR∈Rdz×dz是一个参数矩阵。然后, 再相应地更新式(2), 将结构信息传播到子层的输出。
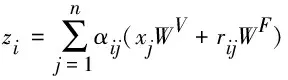
(6)
其中, WF∈Rdz×dz是一个参数矩阵。rij∈Rdz代表了元素对(xi,xj)之间的关系,它是通过2.2.2节学习到的一个向量表示。
2.2.2 学习图概念(concept)对之间的向量表示
上述的Structure-Aware Self-Attention机制可以用来获取图中任意两两概念对(concept pairs)之间的图结构关系。定义使用沿着概念xi到xj之间边标签(edge label)组成的一条路径当作概念对之间的图结构关系l。同时,为了区分方向,也给每条边标签相应地增加了方向符号。表 1 展示了图1中的几个概念对之间的结构标签序列。

表1 图1中一些概念对之间结构路径示例
现在已经给定了一个结构标签路径 s=s1,…,sk,然后获取到它的向量表示l=l1,…,lk, 最后本文使用基于卷积神经网络[20](CNN-based)(1)Zhu等人[13]使用了多种方法来学习图结构表示方法,本文选择了CNN-based这一方法作为基线模型。的方法来获得式(5)和式(6)中的向量表示 rij。
CNN-based
使用CNN来卷积标签序列l获得一个向量r,如式(7)、式(8)所示。
实验中m的大小常设置为4。
2.3 数据稀疏性
在训练AMR-to-Text模型的时候,因为语料数量的限制,常常会受到数据稀疏性的影响。为了解决这个问题,前人的工作或者采用匿名化的方法来删除命名实体和罕见词[8],或者使用复制机制[21]来学习,使模型可以学会从源端输入复制未登录词到目标端。在本文中,我们提出使用字节对编码(BPE)[22]将未登录词拆分成更细粒度、更高频的单词。再根据该任务的特性,共享了源端和目标端的词表。Zhu等[13]也在实验中验证了本方法的有效性。
2.4 融合句法信息
前人的工作都是使用平行语料来进行训练,输入源端AMR图去生成对应的句子。他们大都是将句子视为单词序列,但却忽略了句子本身的一些外部知识,没有考虑到句子中潜藏的句法信息。为了使模型能够学习到目标端句子的句法信息和内部结构,本文提出一种显式的方法来融入目标端的句法信息。
融合目标端句法信息的基本思想是将目标端句子经过解析得到句法树,之后再通过深度优先遍历得到最终的句法标签序列。句法的标注形式大致有两种,短语结构句法树和依存句法树。本文在训练时选择使用线性化的短语结构句法树[23]来替换目标端的句子,图3给出了一个目标端句子解析的短语结构句法树和其线性化结果。之所以选择短语结构句法树,是因为与依存树相比,它具有良好的线性化顺序的优点。此外,短语结构句法树也更容易实现,因为它们有效地对应了句子中单词的顺序。在解码阶段,只需要将句法标签去除之后,就是最终预测生成的句子。
不幸的是,AMR标注数据并没有发放句法标注数据。因此,本文使用斯坦福解析器(Stanford Parser)[24]解析训练集和验证集语料,从而获得对应结构语法树的银语料(Silver-Standard)。
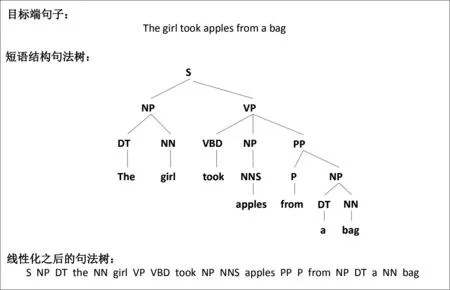
图3 一个目标端句子解析的短语结构句法树及其线性化示例
3 实验
3.1 数据集
为了评估方法的有效性,本文使用LDC发行的现存的两份标准英文语料集进行实验,分别是LDC2015E86和LDC2017T10。两份语料集分别包含了16 833和36 521条训练数据,并且共享了1 368条验证集和1 371条测试集。训练集和验证集使用斯坦福解析器(2)https://nlp.stanford.edu/software/lex-parser.html获取到目标端句子所对应的 Penn treebank-style 风格的结构句法树。
3.2 实验设置
本文分别通过使用10K和20K的操作数来对LDC2015E86和LDC2017T10两份语料进行BPE操作。从BPE处理之后的训练集中根据词频建立词汇表,参考Ge等[25]的工作,共享了源端和目标端的词汇表。为了公平地对比,模型中的词向量使用随机初始化的方式。
本文使用OpenNMT[26]框架作为Transformer的基准模型(3)https://github.com/OpenNMT/OpenNMT-py。在超参数的设置上,模型的编码器和解码器为6层。在优化器方面,本文使用beta1=0.1[27]的Adam优化算法。自注意头的数量设置为 8。此外,模型中向量和隐藏状态的维度位置为 512 ,批处理大小(batch size)设置为 4 096。为了模型计算速度考虑,限定路径标签的最大长度为4。解码时,默认的额外长度从50增加至150,该值表示模型解码时允许生成句子长度是源端最大长度加150。在所有实验中,以学习率0.5在Tesla P40 GPU上训练300K步停止。本文实验代码已开源公布(4)https://github.com/Amazing-J/structural-transformer。
为了更好地体现本文方法的有效性,采用了BLEU[28],Meteor[29],chrF++[30]三种评测指标。BLEU是基于语料级的评估指标,后两者是基于句子级的评估指标。相对来说,后两者的分数更接近于人工评测。
3.3 实验结果
表2给出了本文两个基准模型在融合了目标端句法信息前后AMR-to-Text生成的性能对比。
从表2可以看出,融合目标端句法信息之后,AMR-to-Text生成的性能有着显著的提升。针对两个基准模型,在数据库LDC2015EB6上的BLEU值分别提高了1.26和1.07(LDC2015E86),而在数据集LDC2017T10上的BLEU值分别提高了1.15和1.18(LDC2017T10)。这也有力地表明,在目标端融入句法信息,可以帮助模型学习到句子中潜藏的一些知识,从而在生成时考虑到句法信息的约束。该方法与融合源端句法和语义角色信息的机器翻译方法类似[14],进一步验证了在生成任务中目标端融入句法信息同样可以有显著提升。
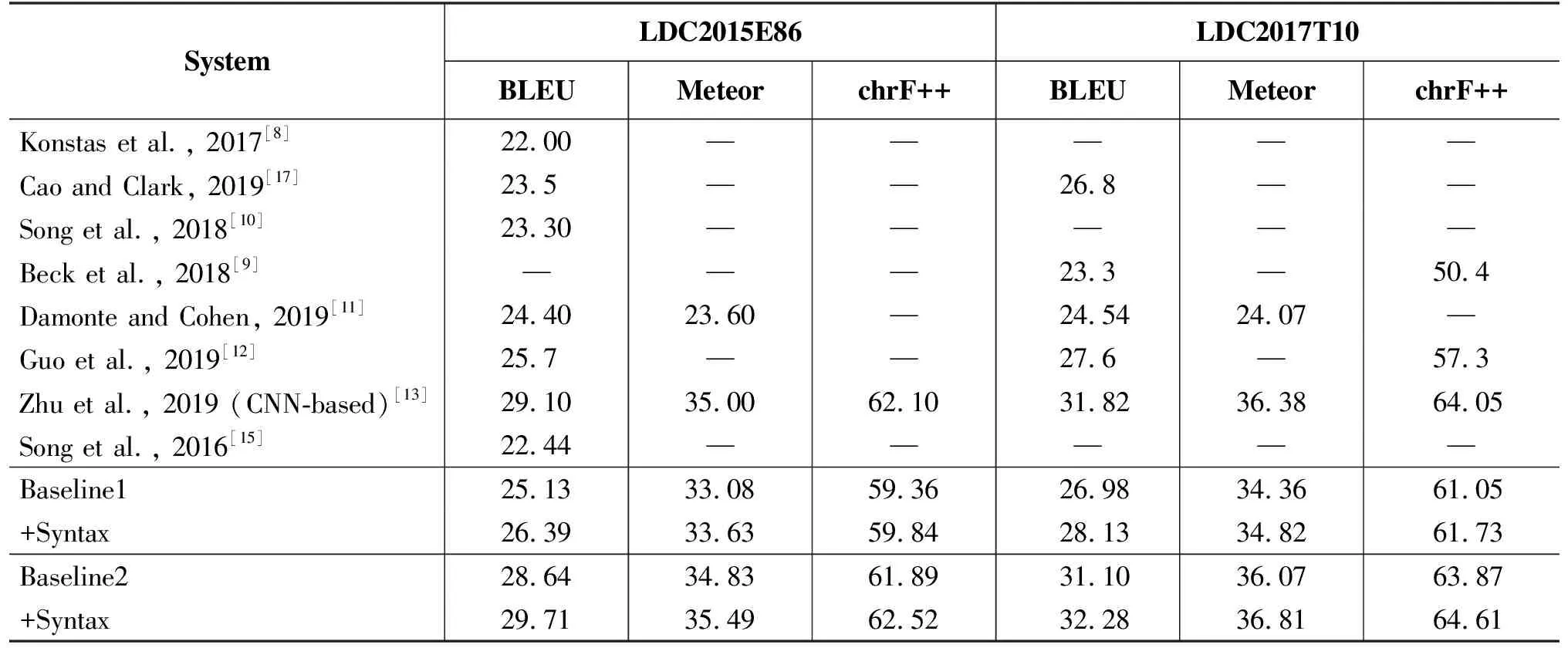
表2 本文方法在LDC2017T10和LDC2015E86测试集上的实验结果及与其他现存模型的对比
表2也给出了与其他现存模型在该任务上的性能比较。值得注意的是,LDC2015E86和LDC2017T10的验证集和测试集是相同的,区别只是训练集的数量相差了一倍左右。从表 2 可以看到,与seq2seq模型相比,本文的baseline1就已经显著地超越了它们,并且在融入句法信息(+Syntax)之后,性能依然有明显提升。目前最高的性能是Zhu等人[13]提出的Structure-Aware Self-Attention模型,本文在它们的基础之上也同样有着有效的性能提高,创造了新的最高的性能(SOTA)。这表明本文的方法无论用在seq2seq模型上还是在graph2seq模型上都有效。
3.4 参数数量和训练时间
本文融合目标端句法信息的方法是将目标端句子替换为线性化结构句法树,不会对模型进行任何修改,也就意味着并不会给模型增加参数,这也是本文方法的一大优点。但是,目标端句子替换成线性化结构句法树之后,它的序列长度会相应地变长,这就会导致训练的时间略微增加。据统计,本文baseline1基准模型在LDC2015E86上进行训练,完成一轮训练的时间大概需要288s(约4.80min),而融合目标端句法信息之后,大概花费345s(约5.75min)。
3.5 融合不同形式句法信息的影响
从实验结果可以得到: 融合目标端句子的句法信息可以显著提升AMR-to-Text生成的性能,但是为了探究哪种形式的句法信息对生成性能最为有效,本文做了进一步的实验分析。
如表3所示,本文探索了三种线性化短语结构句法树对生成性能的影响。第一种形式包括了一个完整的句法树,不仅保留了句法树的所有节点,还给相应节点增加了结束标签,例如,“)NN”“)NP”“)S”等。第二种形式没有增加节点的结束标签,并且为了缩减句子的长度,把句法树中的词性标签删除,仅保留句法树的主干成分,剔除如DT、NN、VBD等词性标签。第三种形式在第二种形式的基础上保留了单词的词性标签。

表3 三种线性化结构句法树的示例
本文在LDC2015E86的测试集上对上述三种句法树的形式做了实验。从表 4 可以看出,当使用第一种形式时候性能最差,因为它会使目标端的句子的长度成倍地增长,极大地增加了模型的学习难度。从第二种和第三种形式得到的性能可以看出,保留短语结构句法树中的词性标签信息对生成性能有着明显的贡献,有着 0.5 BLEU值的提升。本文使用的则是第三种短语结构句法树的形式。

表4 三种线性化结构句法树在LDC2015E86 测试集的性能对比
4 结论
本文提出了一种直接而有效的方法融合目标端句子的句法信息,并且在最优的seq2seq模型Transformer上以及AMR-to-Text生成任务中最优的模型上都进行了实验。实验结果表明,使用该方法可以有效地对目标端句子的句法信息进行学习,从而提高AMR-to-Text生成的性能。在该任务最优模型的基础上同样也有着1.07和1.18 BLEU值的提升,创立了新的最高性能纪录。未来的工作中,由于句法分析和生成任务有着比较高的关联性,所以将会探索句法分析与AMR-to-Text生成任务之间的联合学习方向。
猜你喜欢
大连民族大学学报(2021年2期)2021-07-16
中等数学(2020年2期)2020-08-24
车迷(2018年11期)2018-08-30
中华诗词(2018年3期)2018-08-01
海峡姐妹(2018年3期)2018-05-09
中华诗词(2018年11期)2018-03-26
北京航空航天大学学报(2016年7期)2016-11-16
兵器装备工程学报(2015年1期)2015-12-23
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
