
一种基于Corr-LDA-ITD模型利用类标促进标注的方法研究
2022-03-08 01:21罗菊香
江苏科技信息 2022年2期
罗菊香
(江西服装学院 大数据学院,江西 南昌 330000)
0 引言
图像自动标注是指针对图像的视觉内容,通过机器学习的方法自动给图像添加反映其内容的文本特征信息的过程。基本思想是:利用已标注图像集或其他可获得的信息,自动学习语义概念空间与视觉特征空间的潜在关联或映射关系,给未知图像添加文本关键词。经过图像自动标注技术的处理,图像信息问题可以转化为技术已经相对较成熟的文本信息处理问题。传统的图像标注是通过人工方式完成的,随着图像数据的爆发式增长,人工方式成本高而效率低,同时也存在一定的主观性,使得效果不理想。为了能够高效地从大量图像数据中寻找到自己需要的图像,对图像自动标注研究就变得非常重要。
目前,各种标注模型及方法层出不穷,其中,很多图像标注概率主题模型是基于Corr-LDA 模型的[1]。而 Corr-LDA-ITD 模型[2]是对 Corr-LDA 改进之后的图像标注模型,具有更好的标注效果。文献[3]提出了基于Corr-LDA 模型,利用类别信息来促进图像标注的方法。基于此,本文利用Corr-LDA-ITD 模型对不同类别的图像进行学习,选取log 似然值最大的模型来对2 个数据集(Labelme 和Uiuc-sport)中的测试集图像进行标注实验。
1 Corr-LDA与Corr-LDA-ITD模型
LDA 模型是单模态的主题模型,对LDA 模型进行扩展,形成文本和图像的多模态概率主题模型Corr-LDA 模型,而 Corr-LDA-ITD 将 Corr-LDA 的文本主题的均匀分布抽取修改为在已抽取的图像主题中按图像主题分布抽取,这种生成方式更加符合真实图像,均匀分布只是认为的理想情况,从已抽取的图像主题中按图像主题分布抽取更能体现真实图片的图片主题情况。因此相较于Corr-LDA 模型,Corr-LDA-ITD 模型中文本和图像的关系更紧密,文献[2]中的实验验证了Corr-LDA-ITD模型的标注性能要优于Corr-LDA 模型。文献[3]是基于Corr-LDA模型利用类别信息促进标注,因此,本文在Corr-LDA-ITD模型的基础上进行改进,利用类别信息来促进图像标注,提出了一种基于Corr-LDA-ITD 模型利用类标促进标注的方法,利用该模型可以对未标注图像集进行自动标注。概率图模型如图1所示。
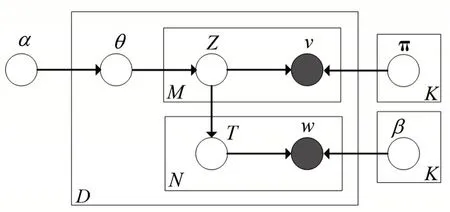
图1 Corr-LDA-ITD的概率图模型
模型的具体生成过程为:假设图像集由D张照片经过图像处理之后构成M个图像词汇和N个文本词汇,首先按照狄利克雷分布抽取主题比例θ;对每一个图像词汇vm先按照多项式分布抽取图像主题Zm|θ,再按照多项式分布抽取图像词vm|Zm;对每一个文本词wn,先按照多项式分布抽取主题比例Tn|Z,再按照多项式分布抽取文本词wn|Tn。模型的潜变量和观测变量的联合分布为:

2 基于Corr-LDA-ITD模型标注图像的方法
本文基于文献[2]和文献[3],利用类标信息结合Corr-LDA-ITD 模型进行模型构建,因为不同类别的图像之间,图像呈现的事物差距较大,相同类别的图像之间,图像呈现的事物相近。标注方法的构建过程如图2所示。
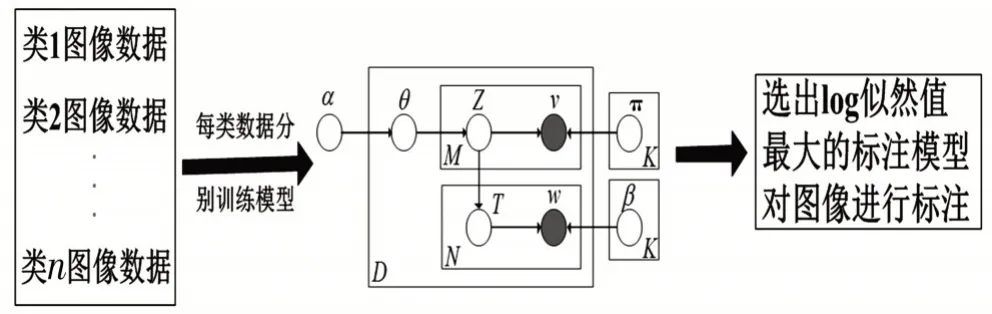
图2 模型选择
模型构建首先利用Corr-LDA-ITD对各个类的图像进行学习,然后用各个类图像集学习出的模型对测试图像集进行测试,选出所有模型中log 似然值最大的标注模型来对图像进行标注,模型通过公式(2)确定log似然值。
模型具体标注过程是首先使用训练好的模型参数计算图像主题分布;再依据该分布选择文本主题;最后按照这个选中的主题生成标注词,确定概率较大的前4个标注词作为图像的标注模型:
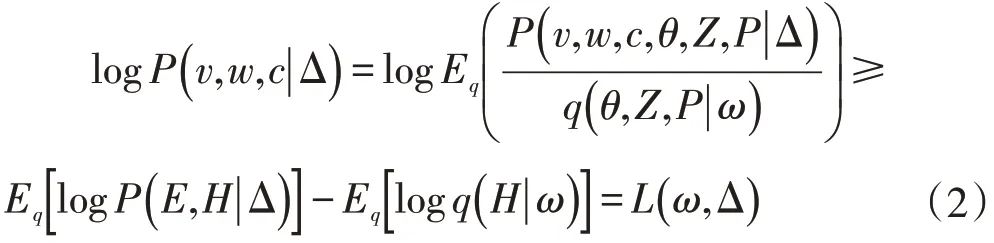
3 实验结果与分析
为比较本文方法的标注效果,实验在2个真实图像集(Labelme和Uiuc-sport)上进行,模型选取6组主题(K=20,40,60,80,100,120)进行标注实验,实验将本文方法与Corr-LDA模型、Corr-LDA-ITD 模型以及Mca-SLDA[4]模型进行标注比较,在 2 个真实图像集(Labelme 和Uiuc-sport)的实验效果分别如图3—4 所示。
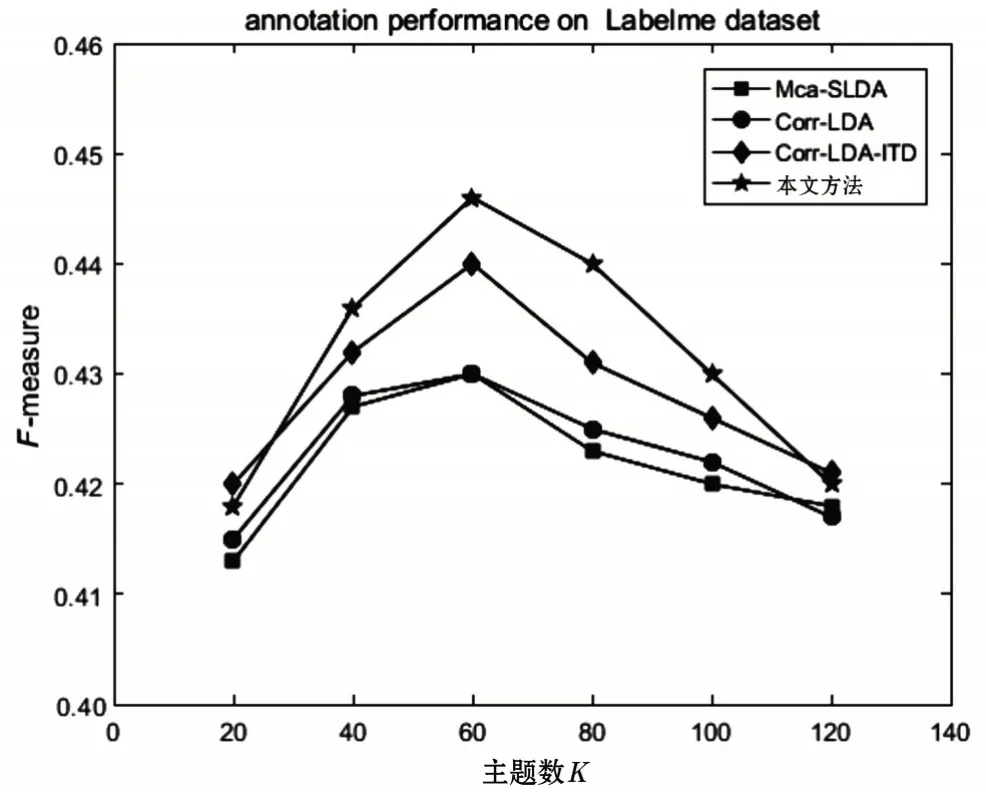
图3 Labelme数据集上F-mesaure值性能比较
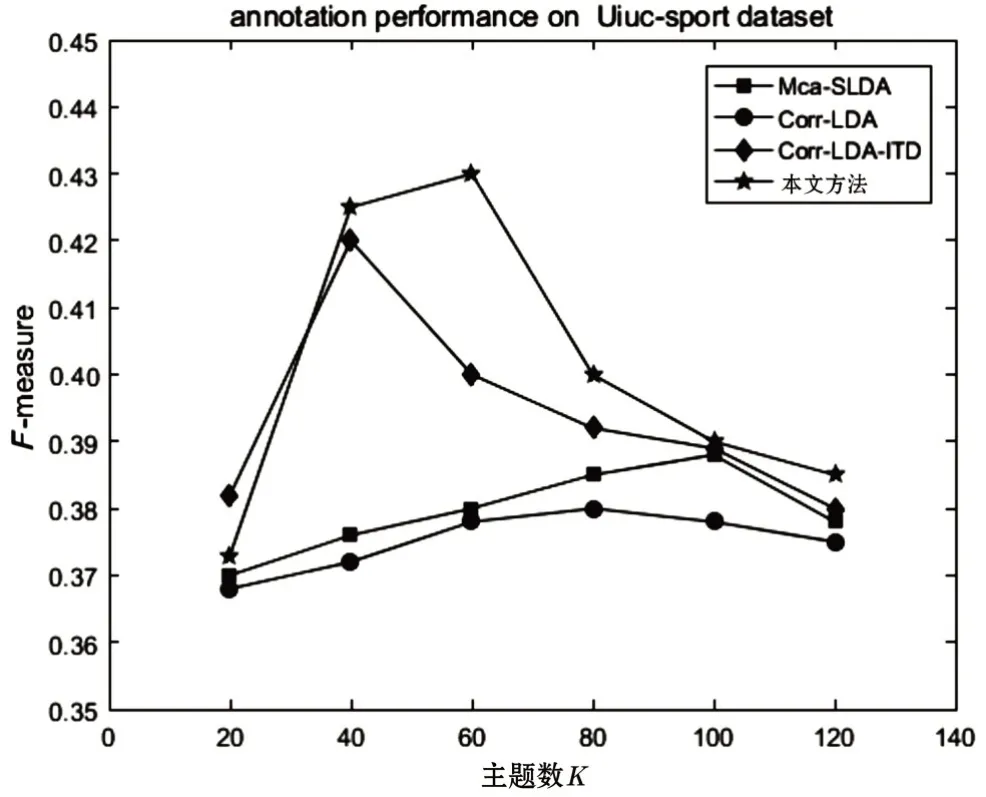
图4 Uiuc-sport数据集上F-mesaure值性能比较
从实验结果可知,本文方法在2 个真实图像集(Labelme 和Uiuc-sport)上表现出了图像标注效果总体要高于相比较的3 个模型。Labelme 和Uiuc-sport数集都是在主题数为60 时表现出最好的标注效果,在实验的几组主题上标注效果都优于相比较的其他3个模型。
4 结语
本文利用类标信息结合Corr-LDA-ITD模型进行模型构建,通过在各个类图像集中进行模型学习,利用所有模型中log似然值最大的标注模型来对图像进行标注。实验验证了本文方法相较于其他模型标注效果有所优化。
目前,自动图像标注是计算机视觉和自然语言处理交叉研究领域的研究热点,近年来学术界和工业界都对其进行了大量的研究。其中有一部分学者致力于卷积神经网络在图像标注中的应用研究。卷积神经网络融合了人工神经网络及深度学习的理论基础,可以大幅度减少参数估计的数量。因此相比于其他网络结构,卷积神经网络会更容易得到训练,也可以有效避免传统人为干预选择特征提取方式时的预处理过程,笔者后续也将着力于这方面的研究。
猜你喜欢
中等数学(2022年2期)2022-06-05
云南教育·小学教师(2022年4期)2022-05-17
小学生学习指导(低年级)(2020年6期)2020-07-25
艺术评论(2020年3期)2020-02-06
制造技术与机床(2019年10期)2019-10-26
电子制作(2018年18期)2018-11-14
小学生学习指导(低年级)(2018年9期)2018-09-26
疯狂英语·新读写(2018年2期)2018-09-07
民族古籍研究(2018年1期)2018-05-21
西夏学(2016年2期)2016-10-26
