
多源道路智能选取的本体知识推理方法
2022-03-07 10:45钱海忠刘俊楠赵钰哲陈国庆
测绘学报 2022年2期
郭 漩,钱海忠,王 骁,刘俊楠,任 琰,赵钰哲,陈国庆
1. 信息工程大学地理空间信息学院,河南 郑州 450000; 2. 信息工程大学数据目标与工程学院,河南 郑州 450000
制图综合是解决多尺度表达的关键技术之一,且已经从算法综合、协同综合、过程控制综合发展到了知识推理综合的新阶段[1]。道路选取作为制图综合的重要内容,一直受到广泛关注[2]。然而,大数据时代多源数据存在语义差异,导致跨数据源的道路选取高度依赖专家知识[3],因此建立多源数据选取规则并进行知识推理是促进计算机实现智能综合的必然途径。本文基于本体表示道路选取知识,通过相似性度量消除多源数据差异,利用语义网规则语言进行知识推理,实现跨数据源的道路智能选取。
道路选取指通过评价道路重要性,保留主要道路、删除次要道路,达到选取目的[4]。早期基于传统模型的评价方法主要包括基于语义等级[5]、网眼密度[6]、stroke[7]及图论[8]等方法,其中基于stroke的选取方法效果较好[9-11],可有效保持道路的几何连续性。随后部分学者借助智能模型,提出了基于遗传算法[12]、决策树[13]和神经网络[14]的选取方法,在一定程度上提高了道路选取的自动化水平,但制图综合问题并非都能模型化,建立其知识法则成为必然[1]。近年来,国内学者将案例推理方法(case-based reasoning,CBR)应用于道路选取[15],以实现智能化制图综合。该方法可简化知识获取过程,降低知识表示难度,但传统案例的适用性较差,难以实现面向其他数据源的知识推理。为实现知识表示与共享,部分学者利用本体表达领域知识[16],并结合相似性度量方法解决多源数据的语义不一致问题[17-19],同时文献[20—21]利用本体描述专家案例,提高了系统的决策能力。虽然本体的知识表达能力较强,但知识推理能力不足,难以实现跨数据源道路选取的过程性知识推理,智能化程度有待提高。
针对以上问题,本文将1∶5万基本比例尺地形图道路数据作为基础案例,将四维图新导航电子地图和开放街道地图(OpenStreetMap,OSM)中的道路数据作为试验数据,提出一种利用本体知识推理的道路选取方法,以解决跨数据源的智能综合问题。首先,基于道路stroke分别构建基础案例与试验数据的道路对偶图,计算道路等级、长度、连通度、接近度、中介度等特征项,提取特征项概念和关系并构建本体。然后,分别计算语义特征项和数值特征项的概念相似性,消除基础案例与实验数据的语义差异,为道路选取提供知识共享基础。最后,利用本体和语义网规则语言定义本体通用规则、语义特征规则、数值特征规则等选取规则,面向多源数据进行知识推理,实现试验数据到1∶5万基本比例尺数据的自动综合。
1 道路选取本体构建
道路选取需要明确的制图规则和专家知识,通过1∶5万基本比例尺数据提取道路选取案例,可有效降低知识的形式化表达难度。但基础案例与试验数据间存在语义差异,还需借助本体模型定义数据概念结构,提供领域知识共享基础。
1.1 道路选取案例描述
道路选取案例主要由案例对象和特征项组成,以道路stroke作为案例对象,基于stroke构建道路对偶图,进而计算特征项。其中stroke指自然延伸未断裂的道路[22],通常基于几何与专题规则进行构建,前者指两条路段转折角小于阈值60°[23],后者指两条路段具有相同的等级和名称。道路对偶图通过将stroke表示为节点(V={v1,v2,…,vn}),将节点间关系表示为边(E={vivj|vi,vj∈V}),进而深入分析路网结构[24],具体如图1所示。
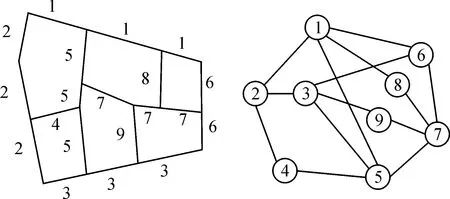
图1 道路stroke对偶图Fig.1 Road stroke dual graph
特征项方面,选择等级(grade,G)作为语义特征项,选择长度(length,L)、连通度(degree,D)、接近度(closeness,C)、中介度(betweenness,B)作为数值特征项,综合评价stroke的重要性。其中等级反映道路的属性信息,长度反映道路的几何信息,连通度、接近度、中介度反映道路的拓扑信息,可以保证重要道路优先选取等基本原则[2]。同时,通过对10篇以stroke为对象的道路选取文献进行统计分析(图2)[4,9-11,22-27],表明本文的特征项选择合理,各特征项的计算方法及具体含义见表1。

表1 特征项计算方法及含义Tab.1 Calculation and description of features
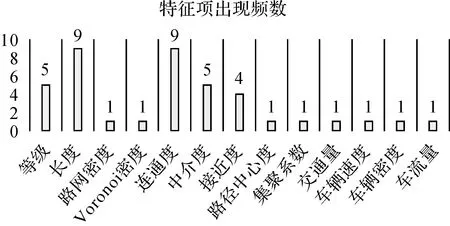
图2 特征项出现频数统计Fig.2 Frequency statistics of features
1.2 本体构建方法
道路选取专家知识一般是开放性的,而基于数据库的本体构建方法可根据数据的语义信息确定领域范围[28],因此本文基于基础案例和试验数据构建本体模型(图3)。具体流程包括:①根据基础案例与试验数据确定本体范围,结合专家知识提取领域概念;②提取领域概念的层次关系和属性关系,构建概念模型;③根据概念模型编辑本体,并添加实体进行形式化表达;④重复上述步骤完善本体,更新领域知识库。由此通过数据库内容作为约束条件,能快速确定本体领域界限,还可整合空间数据、属性数据及其映射关系,有效保证多源道路选取本体涵盖制图综合知识的完整性。

图3 基于基础案例与试验数据的本体构建方法Fig.3 Ontology construction method based on cases and data
道路选取本体模型包括概念层和实体层,其中概念层涉及案例对象、特征项等概念,实体层表示概念的具体实例。本文以等级语义特征项和长度数值特征项为例,具体说明本体构建过程,其他特征项与此类似。首先,根据基础案例数据的语义特征项,构建国道、县道等概念。其次,分析基础案例数据的长度数值分布情况,利用二分k-means算法[29]对数值进行聚类,提取均匀分布且可表示数值区间的实体,利用“hasMax”与“hasMin”数据属性描述取值范围,同时为统一表示方式,定义实体的区间为左开右闭,如实体“La-1”的取值区间(0.35,0.69],实体“Lb-1”的取值区间(0.69,1.92]。然后增加“is-a”父子关系和“hasProperty”属性关系,其中父子关系描述概念的上下位关系及实体与概念的所属关系[30],属性关系描述案例、案例对象与特征项间关系。如图4所示,案例对象stroke 1表示长度为0.69 km的国道,案例对象stroke 2表示长度为1.47 km的县道。最后基于导航、OSM等多源试验数据增加其他相关概念和实体,如概念行人道路和实体“Lb-1”,其中“Lb-1”的取值区间为(0.50,0.72],可完善道路选取本体,为多源数据的相似性度量提供知识共享基础。

图4 道路选取本体示例Fig.4 Example of road selection ontology
2 概念相似性度量
相似性度量是描述概念相似程度的重要方法,可避免多源数据的语义差异,提高道路选取案例的适用性[31],主要包括语义和数值相似性度量两个方面。其中语义相似性通过概念间关系进行度量,数值相似性通过计算实体的相似性进而实现概念相似性度量。
2.1 语义相似性度量
道路选取要求优先选择重要道路,其中等级特征项最为关键[2]。本文以导航数据为例,基于基础案例数据和导航试验数据构建的概念层次树如图5所示,利用余弦相似性模型计算多源数据等级特征项的语义相似性。
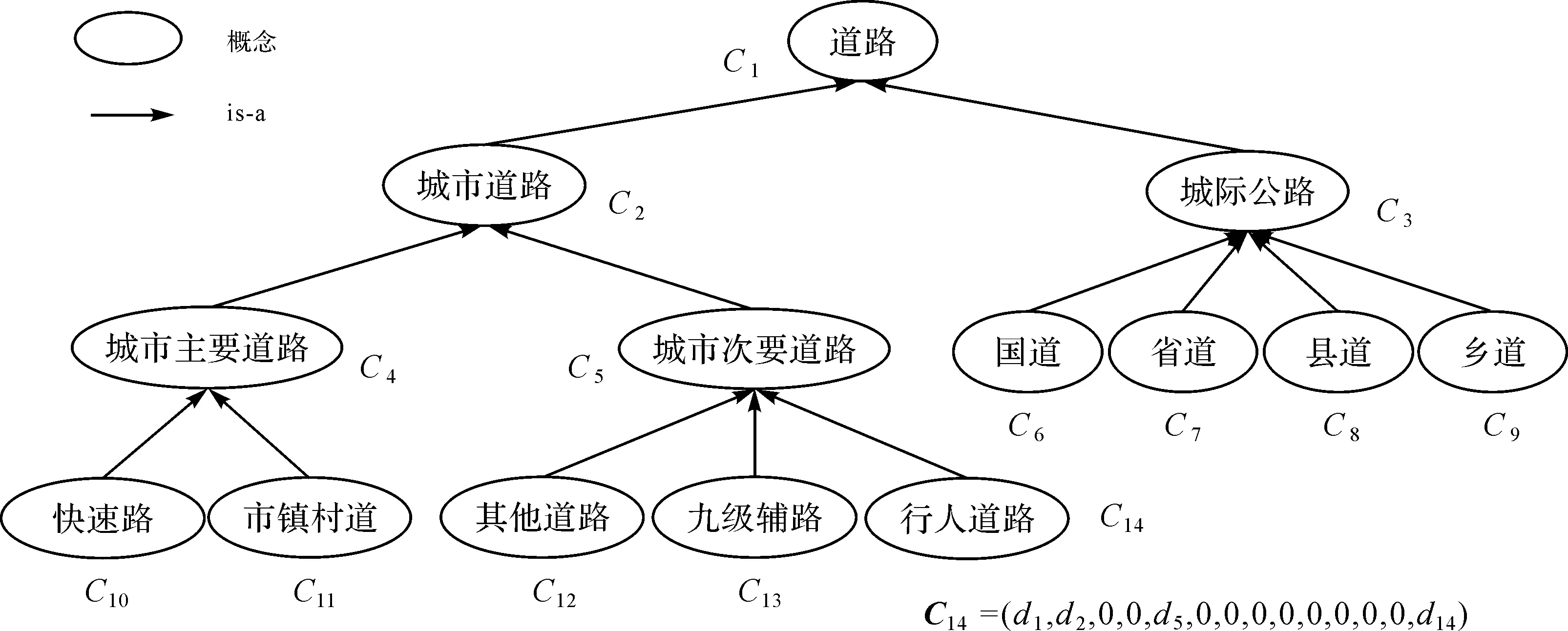
图5 基础案例与导航数据的道路等级概念层次树Fig.5 Concept hierarchy tree of road grade for basic case and navigation data
余弦相似性模型可利用空间向量夹角的余弦值衡量概念差异,符合道路等级概念层次树特征[32,33],因此本文以概念层次树的局部密度为基础构建概念向量,基于余弦相似性模型[18]计算等级的语义相似性。具体计算公式为
(1)
式中,概念Ca的概念向量为Ca=(va,1,va,2,…,va,b),va,b表示概念Ca与Cb的相关性,计算公式为
(2)
式中,da指概念Ca父概念的所有子概念数量,即局部密度,关联概念指与概念Ca直接或间接关联的所有父概念和子概念。如图5所示,父概念城市次要道路具有3个子概念:其他道路、九级辅路和行人道路,因此每个子概念的局部密度均为3。概念行人道路的关联概念包括道路、城市道路、城市次要道路和行人道路,局部密度分别为1、2、2和3,因此概念向量C14=(1,2,0,0,2,0,0,0,0,0,0,0,0,3)。基础案例的道路等级包括国道、县道、城市主要道路、城市次要道路,导航数据包括国道、县道、市镇村道、其他道路、九级辅路、行人道路,概念相似性度量结果见表2,由此可建立跨数据源的等级概念语义关联。其中导航数据的国道、县道分别与基础案例的国道、县道为相同概念,市镇村道与城市主要道路属于相似概念,其他道路、九级辅路、行人道路与城市次要道路为相似概念。

表2 基础案例与导航数据道路等级语义特征项相似性度量结果Tab.2 Road grade semantic similarity measurement results for basic case and navigation data
2.2 数值相似性度量
除语义特征外,道路选取本体模型还涉及众多数值特征项概念,根据数值类型可分为离散特征项和连续特征项,其中离散特征项指取值为整数的连通度,连续特征项指取值被聚类为若干连续区间的特征项,具体包括长度、接近度、中介度。离散特征项方面,由于连通度取值通常为整数,且整数间距离越大则表示的语义差异越大[17],因此本文利用连通度值的相对距离评价其相似性,计算公式为
(3)
式中,Ca、Cb分别表示基础案例与导航数据连通度值。
连续特征项方面,本体将道路长度、接近度、中介度聚类为区间实体,不同区间的重叠范围越大则语义差异越小,同时区间值的重叠部分越大,则实体对应概念表达的语义越接近[17]。因此本文参考Jaccard系数[34],利用区间实体交集与并集的比值评价概念的相似性,计算公式为
(4)
式中,RCa、RCb分别表示基础案例与试验数据的连续特征项数值区间,RCa∩RCb表示Ca与Cb数值的交集,RCa∪RCb表示数值的并集。本文将计算结果最大的两个实体的概念作为相似概念,如图4所示试验数据长度区间(0.50,0.72]与基础案例长度区间(0.35,0.69]、(0.69,1.92]的相似性分别为0.514、0.021,与其他基础案例长度区间的相似性为0,因此概念Lb-1与La-1为相似概念。通过语义和数值相似性度量,可建立试验数据与基础案例的概念关联关系,为道路选取提供更加完善的知识基础。
3 道路选取知识推理
本体为道路选取提供了领域知识共享基础,但难以表示选取过程的动态知识[35]。而语义网规则语言(semantic web rule language,SWRL)可基于自定义的专家规则实现知识推理,进一步增强本体的逻辑性。
3.1 SWRL规则
SWRL由实现(Imp)、原子(Atom)、变量(Variable)和内置组件(Built-In)组成(图6),可根据简单概念定义复杂关系,扩展知识表达能力[34]。其中Imp是规则的基本单元,Atom是规则的最小元素单位,Variable记录Atom使用的变量,Built-In封装Atom的逻辑关系。本文根据式(5)[35]设计SWRL规则,具体解释为:若前件(Body)的原子全为真,则后件(Head)的推理结果也为真。
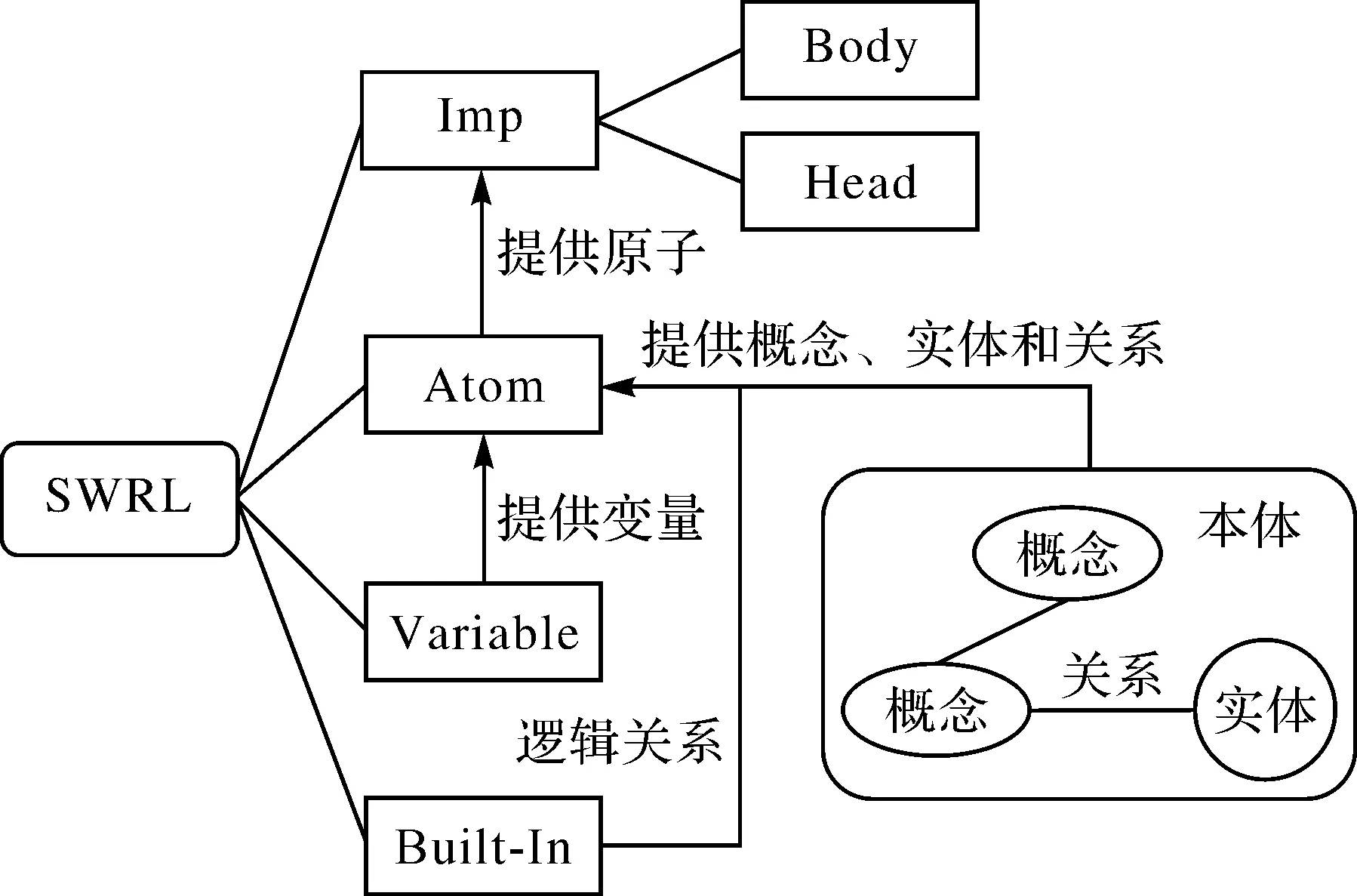
图6 SWRL组织结构及其与本体间关系Fig.6 Structure and relationship of SWRL and ontology
Body(Atoma1∧Atoma2…)→Head(Atomb)
(5)
本体模型可为Atom提供概念、实体和关系[35](图6),本文定义的SWRL规则示例见表3。其中,Road(x)表示道路x为概念Road的实体,Grade(g)表示等级g为语义特征项概念Grade的实体,Length(l)表示长度l为数值特征项概念Length的实体,[“国道”](g)表示g为国道,isSelected(x,true)表示道路x被选取,hasLength(x,l)表示道路x长度为l,swrlb:lessThan(l,0.69)表示道路x的长度小于0.69 km。

表3 SWRL规则示例Tab.3 Examples of SWRL rules
3.2 SWRL规则推理
道路选取知识推理主要通过Java expert systems shell(Jess)推理引擎实现(图7),其中推理引擎将本体模型和SWRL规则分别转换为事实库和规则库,利用推理机对基础规则进行组合与筛选,更新领域知识。

图7 基于规则的Jess引擎推理Fig.7 Jess engine reasoning based on rules
为实现道路选取知识推理,本文结合本体模型和道路数据特征项设计选取规则,包括本体通用规则、语义特征规则、数值特征规则,表4为部分SWRL规则描述示例。其中,Rule 1和Rule 2是适用于所有领域的通用规则,可根据本体概念与实体间父子关系的传递性进行推理,Rule 3—9为用户自定义规则,可根据通用规则推理结果实现深层次推理。Rule1说明子概念的实体同样为父概念的实体,Rule 2表示若两个概念为相似概念,则其对应的两个实体为相似实体。语义特征规则Rule 3表示基础案例选取规则,即选取道路stroke等级为国道的道路;Rule 4表示导航数据选取规则,即选取导航数据中与基础案例城市主要道路为相似实体的市镇村道;Rule 5表示OSM数据选取规则,即选取OSM数据中与基础案例国道为相似实体的motorway。数值特征规则Rule 6表示基础案例选取规则,即选取道路stroke长度区间范围为(0.35,0.69]的道路;Rule 7表示导航数据选取规则,若基础案例长度区间为(0.35,0.69]的道路stroke被选取,则导航数据相似长度区间为(0.50,0.72]的道路stroke被选取;Rule 8表示基础案例选取规则,即选取道路stroke连通度为6的道路;Rule 9表示OSM数据选取规则,若基础案例连通度为6的道路stroke被选取,则OSM数据中的相似连通度道路stroke也应被选取。由此通过语义特征和数值特征规则,可推理更多制图综合动态知识,实现多源数据道路的自动选取。

表4 SWRL规则描述示例Tab.4 Examples of SWRL rules
4 试验与分析
4.1 试验数据与流程
为验证本文方法的有效性,选择国家1∶5万比例尺地形图中某地区的道路数据作为基础案例,相应区域的四维图新导航电子地图和开放街道地图中的道路数据作为试验数据展开验证,具体试验流程如图8所示。

图8 试验流程Fig.8 Experimental procedure
(1) 数据处理。对案例数据、导航数据、OSM数据进行断链并构建道路stroke,提取等级、长度特征项,根据道路对偶图计算连通度、接近度、中介度特征项。
(2) 本体构建。以处理后的多源数据为基础,提取道路选取本体领域概念、实体及其关系,构建本体模型。
(3) 相似性度量。利用相似性模型计算本体概念相似度,消除基础案例与试验数据的语义差异。具体包括:基于道路等级概念层次树,计算语义特征项概念的相似性;利用相对距离及Jaccard系数,计算数值特征项概念的相似性。
(4) 知识推理。面向本体模型构建SWRL规则,分别转换为Jess事实库与规则库,并利用Jess推理引擎实现制图综合知识推理,指导计算机自动获得实验数据道路选取方案。
4.2 试验结果分析
4.2.1 道路密集地区导航数据选取结果
为验证本文方法的科学性,试验选择传统的stroke选取方法与本文方法进行对比。其中1∶5万比例尺基础案例道路数据如图9(a)所示,相应地区导航数据及其选取结果分别如图9(b)、9(c)所示,其中共选取195条导航数据道路stroke。在传统的stroke选取方法中,本文利用文献[20]熵权法计算stroke各特征项权重,并根据导航数据重要性评价排序,判断路网选取情况。为保证选取比例一致,选择重要性评价排序前195的导航数据stroke作为选取结果(图9(d))。

图9 导航数据及选取结果Fig.9 Navigation data and selection result
本文方法选取结果与1∶5万比例尺基础案例数据的同名实体匹配个数为135,而传统stroke选取方法的同名实体匹配个数为119,说明本文方法选取结果与基础案例更相似,更能反映专家知识。对不同方法选取结果进行分级显示如图10所示,各等级stroke选取情况见表5。通过对比发现:①本文方法选取的国道、县道等高等级道路较多,而传统方法选取的市镇村道和九级辅路等中低等级stroke较多。②两种方法保留的其他道路stroke个数相同,但本文方法选取的该等级道路大部分均能形成完整网眼,而传统方法选取的多为悬挂道路(图10(b)虚线标出)。③本文方法选取的完整网眼数为225,悬挂道路为5条,选取结果道路的总连通度为488;而传统方法选取结果的完整网眼数为209,网眼内悬挂路段较多(18条),同时道路的总连通度仅为474。因此在将导航数据综合为基本比例尺数据过程中,本文方法选取的完整网眼数更多,产生的悬挂道路更少,道路stroke连通性更好,更能保持道路的整体结构和局部关键结构。

表5 道路选取结果统计Tab.5 Statistics of road selection results
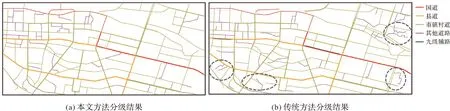
图10 道路选取结果对比Fig.10 Comparison of road selection results
4.2.2 道路稀疏地区OSM数据选取结果
为进一步验证多源道路选取方法的可靠性,选择道路稀疏地区的OSM数据进行试验。其中1∶5万比例尺基础案例道路数据如图11(a)所示,相应地区OSM数据、本文方法选取结果以及传统方法选取结果分别如图11(b)、图11(c)、图11(d)所示。为保证选取结果比例一致,两种方法均选取98条OSM数据道路stroke,其中本文方法选取结果与1∶5万比例尺基础案例数据的同名实体匹配个数为76,而传统stroke选取方法的同名实体匹配个数仅为64。同时本文方法选取的完整网眼数为61,悬挂道路为5条,选取结果道路的总连通度为111;而传统方法选取结果的完整网眼数为56,悬挂道路为8条,同时道路的总连通度仅为97。因此本文方法可保持选取结果的路网平面图形特征,能够实现密集型和稀疏型等区域的多源道路自动选取,具有较强的适用性。
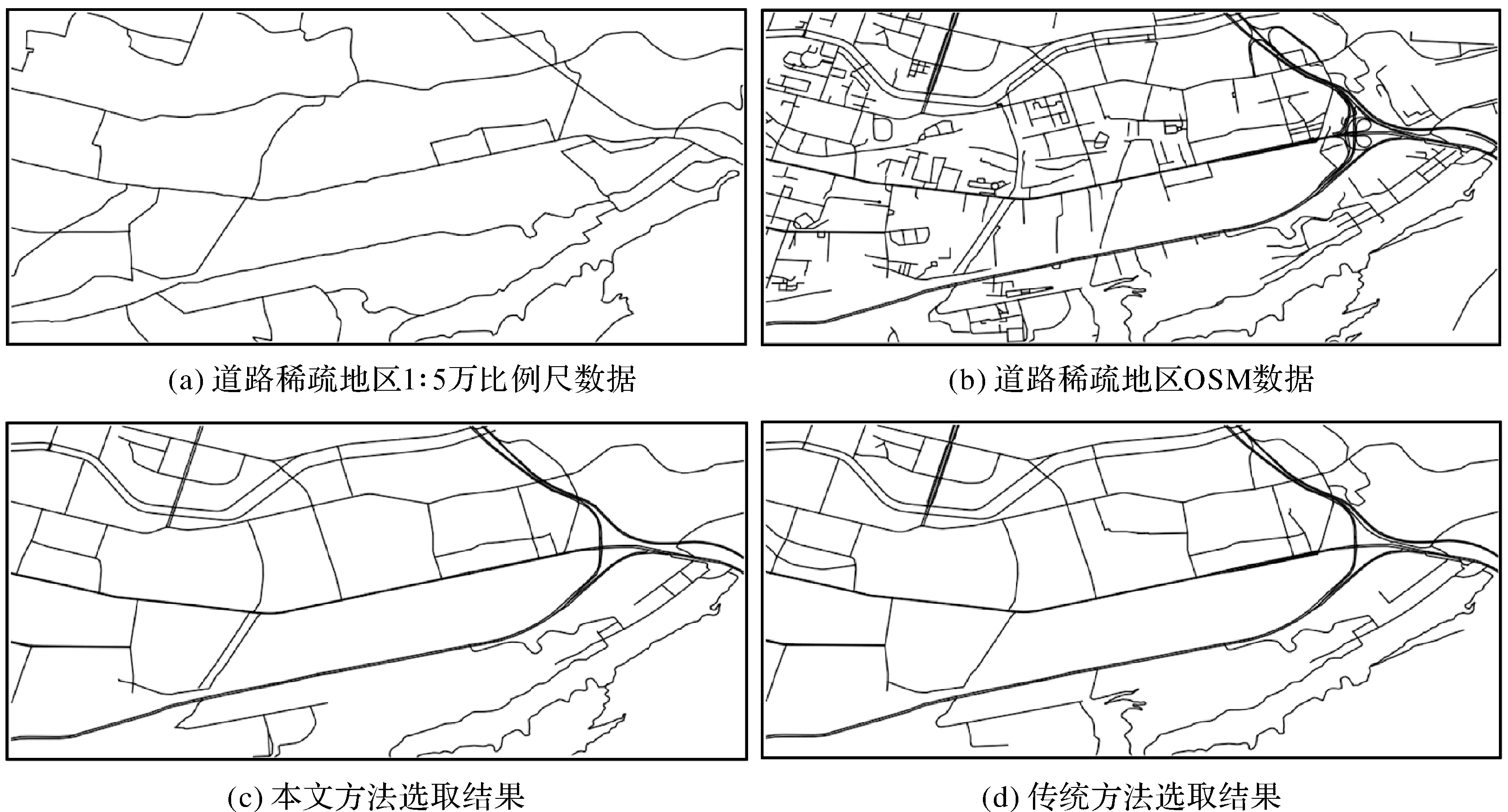
图11 OSM数据及选取结果Fig.11 OSM data and selection result
5 结 论
大数据时代积累的多源数据成为制图综合新的机遇与挑战,本文提出了一种基于本体知识推理的多源道路智能选取方法。首先,将基本比例尺数据作为基础案例,将导航数据和OSM数据作为试验数据,提取特征项概念和关系,并构建了道路选取本体模型;然后,分别针对语义和数值特征项,计算概念相似性,建立了基础案例与试验数据间的关联关系;最后,利用SWRL规则表示并推理道路选取动态过程知识,实现了试验数据向基本比例尺的自动选取。试验表明,本文方法能够消除基础案例与试验数据的语义差异,指导相似地区其他数据的自动选取,为面向多源数据的智能化制图综合提供了新思路。然而,道路选取还受居民地等其他因素约束,因此本体的构建工作并未结束,还需利用数据驱动的本体评估方法,评价道路选取本体的合理性与科学性。同时本文仅实现了1∶5万比例尺的道路选取,未来还需研究其他比例尺下的选取情况,进一步完善本体知识推理规则,提高本文方法的可行性。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
哈哈画报(2021年10期)2021-02-28
河北画报(2020年8期)2020-10-27
开放教育研究(2020年2期)2020-03-31
制造业自动化(2017年2期)2017-03-20
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
浙江大学学报(工学版)(2016年2期)2016-06-05
长江学术(2016年4期)2016-03-11
图书与情报(2013年1期)2013-11-16
