
多指标融合的引文网络仿真及领域知识扩散影响因素识别*
——以知识管理领域为例
2022-03-06 03:15汪舒韩毅,2
图书与情报 2022年5期
汪 舒 韩 毅,2
(1.西南大学计算机与信息科学学院 重庆 400715)
(2.西南大学商贸学院 重庆 402460)
随着社会经济的新发展及知识创新速度的快速增长,社会知识总量不断扩增。知识是信息与人进行交互后形成的一种认知元素[1],需要经过人的经验转化而成,具有共享和传递等特征,因而知识的价值不仅在于其内容意义,更应体现在交流过程中。科学研究过程中,知识单元通过引证方式得以传播与继承,通过科研成果共享,知识得以不断传递和扩散[2]。 知识扩散与流动实质上是主体基于相关性的不断选择过程,客观上表现为以引文网络为载体的知识单元聚集到领域知识扩散路径上,并基于选择机制形成领域的知识硬核[3]。知识扩散与流动包含知识主体、知识内容、流动方向三大要素[4],而引文网络作为科学文献交流和共享网络,它以文献作为知识载体,以文献内容为知识内容,基于引用关系实现知识内容的传递与扩散,其引用动机、引用特征与引用模式可高效衡量知识扩散和知识演化机制。
那么,引文关系网络形成受到哪些因素的影响?基于这些影响因素是否可有效预测引文关系网络的发展趋势?基于此,本文以知识管理领域引文网络为对象,聚焦样本领域的知识扩散特征与演化机制,尝试通过系统仿真方式,构建多角度细粒度的知识扩散模型,旨在为创建特定领域知识扩散的预测方法与工具研究提供参考。
1 相关研究
不同粒度层面下,知识扩散形式及其表征意义有一定差异,其基本单元可划分为:微观粒度的知识模因、关键词(或主题词)和作者,中观粒度的学术论文(包括专利文献),宏观粒度的学术期刊和学科领域。
1.1 微观粒度的知识扩散研究
情报学界在20 世纪80 年代提出“知识模因”概念。知识模因又称为知识基因,是知识遗传和变异的最小功能单元,典型方法是从摘要视角研究知识模因。作为单篇文献的价值表征,摘要是知识基因的静态表达,拥有文献的主要信息,因而只要将摘要细粒度化、结构化便能分析文献所包含的知识基因[5]。 梁镇涛等通过提取医学信息学领域文献题录信息来研究知识模因扩散特征,总结出四种典型的知识模因扩散模式[6]。
另外,关键词、主题词也能较好表征引文内容。毕崇武等基于知识主题、知识势差指标构建演化模型,揭示了引文内容视角下的知识流动特征[4];彭泽等利用主题词衡量引证过程中的知识流量,基于此构建网络模型并揭示知识流动主路径机制[7];许鑫等、岳增慧和许海云分别提取数字人文领域、社会网络领域的引文关键词构建知识图谱以研究知识内容扩散 的 演 化 过 程[8-9]。
作为知识创造者的论文著者也能在一定程度上反映领域知识的扩散趋势,因此,学者尝试从引文网络视角分析作者知识扩散特征[10-12],还有通过构建作者群体-关键词-引文[13-14]、作者-内容-方法[15]、词条-作者[16]等超模网络揭示领域中核心作者的知识交流现状。
1.2 中观粒度的知识扩散研究
基于文献整体的中观粒度知识扩散研究包括静态和动态两种形式。 静态知识网络结构通常以学术论文、专利文献[17]作为网络节点,通过构建主题演化网络[18]、共引网络[19]等模型,利用社会网络分析[20-22]、H 指数[23]等方法与指标来揭示领域知识扩散机制。为更好预测和探索演化机制,学者逐渐从动态视角构建网络演化模型。其中,Barabási Albert 模型作为科学网络演化的理论基础,揭示了引证关系中的马太效应现象。因此,刘向等在此基础上提出以核心知识与专业领域定位为主的知识网络模型[24],但其仅以节点度为核心,指标过于单一。 随后,有学者尝试在BA 模型基础上融合新机制以弥补单一指标的缺陷,如强调新文献被引概率更高的时间优先机制[25-26]等。在知识单元层面,仅少数学者引入知识内容相似性机制,赵伟艇和单冬红提出基于内容相似性的单一机制模型,认为相似文献间引证概率更高[27]。 关鹏等从知识溢出和知识势差角度构建多Agent 系统仿真模型,发现科研合作网络结构对知识扩散有重要影响[28]。 此外,也有学者从网络结构入手提出基于三角引证关系的拓扑模型[29]、基于随机游走算法的扩散模型[30]。 综上可知,为弥补静态研究的不足,学者们从不同维度构建动态仿真模型,但大部分仅包含单一机制,鲜有多维融合模型,同时,已有研究尚未揭示不同机制下知识网络扩散的演化特征以及模型对真实网络演化的解释程度,因此优化动态仿真模型为科学知识演化特征揭示与预测有重要意义。
1.3 宏观粒度的知识扩散研究
以期刊为单元的知识扩散研究不仅能分析期刊在学科范围内的地位与影响力[31],还能测度学科间的知识交流与学科交叉等特征[32]。 尹丽春和刘则渊以Scientometrics 刊载文献为研究单元,计算期刊节点度分布和平均度等指标并揭示领域引文网络特征[33];张慧等利用期刊与学科的对应关系,从学科引证视角分析我国人文社科领域的知识流动[34]。 此外,期刊的影响因子通常会影响文献的引证概率,研究表明核心期刊的文献更容易被引用[35],这也是引文网络呈现幂律分布的原因之一。
通过梳理不同层次的研究可知,在对象层面,多数以学术论文为主,常用社会网络分析来揭示知识网络密度、节点位势等特征,较少考虑微观层面的知识主体所包含的知识内容对知识扩散的影响;在方法层面,尽管社会网络分析等静态方法可以有效表征网络结构,但对于网络随时间变化形成的动态特征难以解释。同时,简单的回归分析无法检验非线性且复杂的知识网络演化进程中的影响因素,为弥补静态方法的缺陷,动态网络仿真为知识网络演化提供了较好的方法基础,随后有学者利用BA 模型,从系统仿真角度揭示知识网络演化机制。 但现有动态模型中,指标因素单一,连接机制尚未完善,缺少对微观层面的知识内容、作者及团队和宏观层面的期刊因素的融合分析,也未提出仿真模型对真实网络扩散的揭示程度,难以有效解释引文网络形成机制的具体细节与特征。 因此,把引文分析、复杂网络和社会网络三种理论与方法统一起来,多维度动态性地考察知识主体、知识内容对扩散的影响,才有可能将科学引文网络趋势预测提高到一个新的水平。
鉴于此,本文在BA 模型基础上优化连接机制,弥补单一机制模型的缺陷,融入多维指标,构建适于领域引文网络演化的仿真模型,并探索不同维度指标对引文网络知识扩散的贡献度,揭示不同指标贡献度下的知识扩散特征。
2 研究设计
2.1 研究思路与方法
蒙特卡洛模拟也称随机模拟、统计试验,其实质是利用服从某种分布的随机数来模拟现实系统中可能出现的随机现象,通过大量的模拟试验后,根据概率论中心极限定理和大数定理,得出有价值的统计结论[36],是解决复杂问题的有效方法,常用于计量经济学、风险决策分析等领域。本文遵循蒙特卡洛模拟的思想,在先验理论的基础上,分析领域引文网络的知识主体、知识内容维度的数据分布特征,以BA 模型为基准,构建融合多维度细粒度的知识扩散模型,通过建立模型误差函数判别真实网络与仿真网络的结构特征差异,以此衡量仿真模型对真实领域网络的揭示程度与效度,并模拟不同指标贡献度下网络的扩散特征,探寻模型误差最小区间内的各维度指标最优贡献度分布,为知识扩散在各因素影响下所展示的特征及演化机制提供分析依据。 以上实验主要借助Python、Pajek、Origin 及相关开源软件,并以模拟仿真与统计分析方法为主。
2.2 领域引文网络构建
本文以知识管理领域的样本数据进行引文网络的构建,选择中国引文数据库为数据来源。为筛选文献间的引证关系,按照被引文献检索中的主题检索途径,以“知识管理”为主题词,被引文献来源期刊选择核心期刊与CSSCI 收录期刊,时间范围为2010-2020 年,共检索到3327 篇文献,其中每篇文献的题目、关键词、摘要至少一项字段包含“知识管理”主题词,检索时间为2020 年12 月28 日。 将文献的题名、作者、第一责任人、关键词、摘要、来源、年份、被引频次、参考文献、引证文献等字段导入Excel 中存储。
为确保主题领域的相关性、期刊来源的统一性、时间范围的一致性,本文以3327 篇文献为网络节点,提取“引证文献”字段数据,构建上述文献间的引证网络模型。 由于原始网络中存在孤立节点和小型子网络(节点数≤10),这类网络由于样本量过小,无法有效探索知识网络扩散特征。同时,知识扩散模型以连通子图构建而来,随着时间的增长网络规模不断扩大,符合真实网络演化的特征,因此,从原始网络特征和网络模型构建的角度来看,本文结合已有研究[24],选择最大连通子图为主要分析对象具有一定合理性,该子图共1036 个节点(占比31.14%),1239条引证边(占比80.04%),随后本文将基于此网络分析知识主体、知识内容对扩散的影响。
2.3 指标遴选
为揭示真实领域引文网络扩散的影响因素,本文在已有研究基础上,筛选适用于“知识管理”引文网络的指标,采用统计分析与数据可视化方法呈现真实领域网络的数据分布特点,为后续模拟仿真奠定数据基础。
(1)内容相似性:表示文献间文本内容的相似程度。科学交流过程中,学者引用文献时往往参考的是文献内容,内容的贴合度与相似性至关重要。Menczer 和Amancio 等均认为引文网络演化过程中,作者引用方式与文献内容相似性显著相关[37-38];赵伟艇和单冬红建立基于相似度特性的复杂网络演化算法验证了相似度大的节点间更容易产生连接[27]。
本文采用余弦相似性(见式1)计算领域网络各节点间内容相似性,提取文献标题、摘要、关键词,以搜狗细胞词库作为分词词典,融合百度停用词表等经典停用词库作为停用词词典,剔除高低频词汇,记录文献词频并向量化,计算余弦相似性,得到紧邻文献间内容相似性分布、任意文献间内容相似性分布以及各文献与其紧邻文献间平均相似性分布(见图1)。
ρab表明文献A 与文献B 之间的内容相似性,Ai与Bi代表文献A 与文献B 的词频向量各分量。
由图1 可知,知识管理领域引文网络中非紧邻文献、紧邻文献间的内容相似性指标满足正态分布,但与后者相比,前者峰值左偏且有长尾现象,指标均值仅为0.26,显著低于后者(0.48),表明内容相似性对引用关系具有影响,高相似度的文献间引证概率越大。 为方便仿真实验,计算最大连通图中1036 篇文献间平均内容相似性分布,得到均值为0.48、标准差为0.16 的特征值。
(2)时间新颖性:表示被引文献相对于引证文献具有的新颖性程度,在仿真模型中表现为时间优先机制[26],即新颖文献被引概率越高。 具有引证关系的文献,其引文时滞可表示知识扩散速度,同时能反映领 域 科 研 进 程[39];Kamalika 和Sen 验 证 发 现 引 文 时滞超过一定阈值时,与被引频率满足指数约为-2 的幂律分布[40]。
本文采用引文时滞指标计算领域引文网络的新颖性程度(见式2),并进行曲线拟合,得出结果(见图2)。
△t 为引文时滞,由引证文献B 的发表时间Tb减去被引文献A 的发表时间Ta,Nab表示被引文献A 相对于引证文献B 的新颖性,指数-2 选择Kamalika 等的结论。
由图2 可知,引文时滞与频率近似满足-2 的幂律分布(γt=-1.74,p=0.046<0.05),表明领域引文网络中,相对新颖的文献越容易被引证。
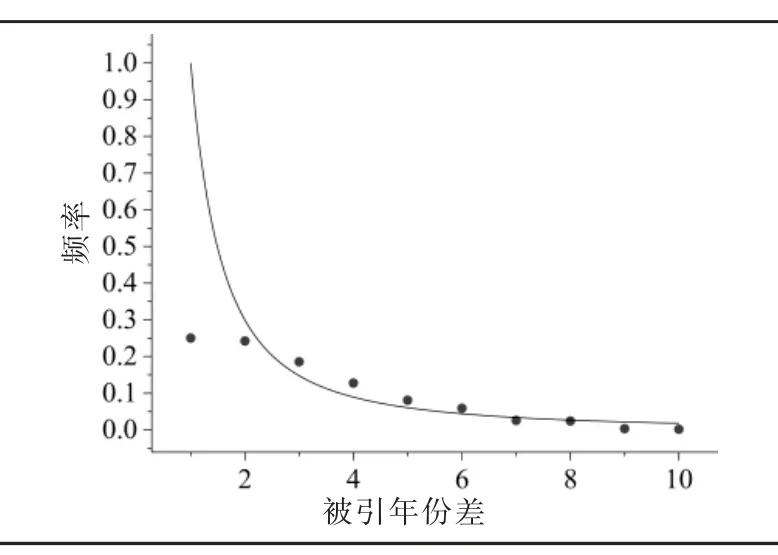
图2 引文时滞分布
(3)位置核心性:表示文献在领域引文网络中核心性程度。 Price 发现引文网络的连接度满足指数绝对值为2.5-3.0 的幂律分布[41],该现象由节点的“累积优势”演变而来。 随后,以度优先为核心的BA 模型正式提出,其基本假设为网络节点度越大,其被再次连接的概率则越大[42]。
本文利用绝对点度中心性衡量文献的核心性,由于节点度存在量纲差异,为消除指标间的异方差性,对其进行对数运算和极大值归一化处理(见式3),节点度与频率的对数曲线拟合结果(见图3)。
Ci表示节点的位置核心性,Di代表文献i 的度值,Dmax代表当前网络中的最大度值。
由图3 可知,度和入度核心性与频率分别满足-2.27 与-2.68 的幂律分布, 说明领域中文献引证关系存在明显的累积优势,趋近网络中心的文献被再次引证的概率相对于边缘文献来说更大。
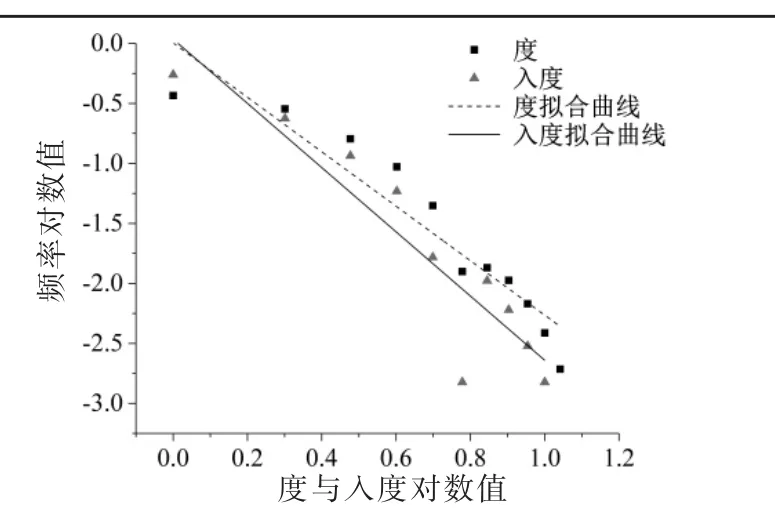
图3 位置核心性分布
(4)作者及团队声誉:表示文献的作者团队在领域中具备的声誉度。 Bornmann 等通过文献梳理发现高被引作者会吸引更多的引文[43],经分析得到作者团队在ISIHighlyCited.com 网站中出现比例与文献被引量显著正相关。
本文结合现有引文数据,提取每篇文献的作者集合,统计每位作者以第一作者身份在领域中发布论文的总篇数与总被引量,并计算作者集合平均被引量,该指标用于表征文献作者团队在领域中的平均扩散广度。由于作者同名因素影响,本文对数据进行了简单的标识,发现同名作者文献仅占2.34%,对指标整体影响可忽略不计,同时,由于数据具有量纲差异容易产生指标间的异方差性,因此参考位置核心性的处理方式(见式4),得出结果(见图4)。
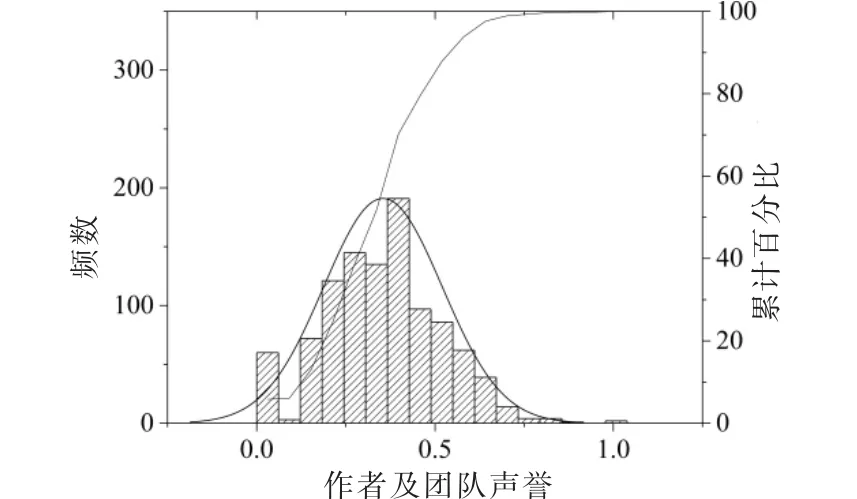
图4 作者及团队声誉分布
其中,Gi表示文献i 的作者及团队声誉,Gmax代表网络中作者及团队声誉指标的最大值,Ak代表节点文献中第k 作者以第一作者身份发文的总被引量,Nk表示第k 作者以第一作者身份的总发文量,n代表文献i 的作者总数。
由图4 可知,作者及团队声誉近似服从均值为0.35、标准差为0.17 的正态分布,且与文献被引量的斯皮尔曼相关性达到0.79(p=0.00<0.01)。
(5)期刊影响因子:常用于衡量期刊的声誉与影响力。 Yao 等利用期刊影响因子构建引文连接机制,所得仿真网络节点度仍然满足幂律分布[35];刘璇等研究发现期刊影响力对文献的知识扩散发挥正向影响[20]。
本文提取各文献期刊2010-2018 年的综合影响因子(检索时数据库期刊影响因子年份范围仅至2018 年),为去除期刊老化、被引量爆发等因素,以2010 年至2018 年的平均影响因子作为测度指标,经极大值归一化处理后,该指标近似满足均值为0.25、标准差为0.14 的正态分布(见图5),且与文献被引量的斯皮尔曼相关性为0.37(p=0.00<0.01)。
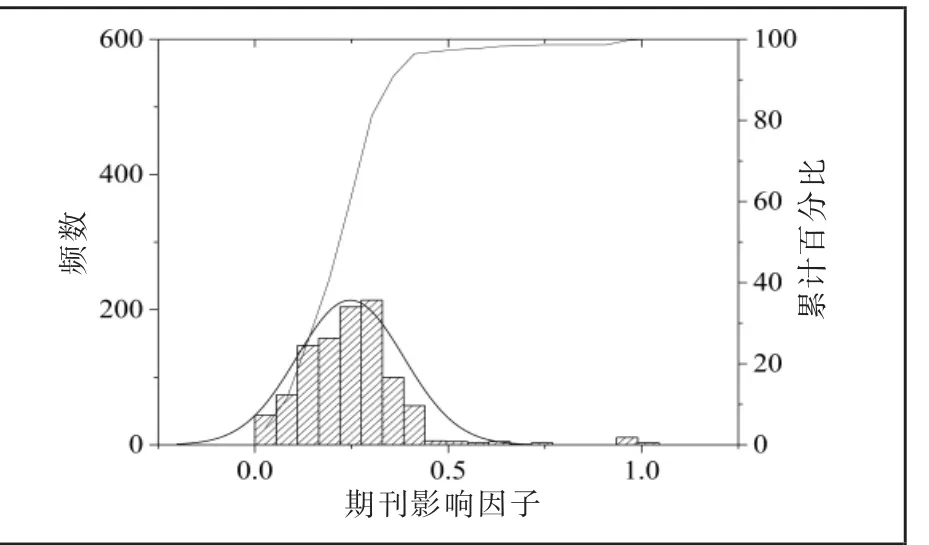
图5 期刊影响因子分布
经总结发现上述五个指标均对知识管理领域引文连接产生影响,为后续融合模型的建立,对上述五个指标进行统计分析(见表1),以检验各指标是否存在多重共线性与量纲差异。

表1 描述性统计及多重共线性分析
统计可知,各指标相关性系数均小于0.4,同时,指标容差趋近于1 且VIF 小于10,表明通过多重共线性检验,最后,由均值分布(0.2-0.4)可知,指标量纲差异较小。
综上所述,多种因素会导致文献引证关系的形成,但关于这些因素如何影响领域知识扩散的研究还并未完善。 鉴于此,本文选择从内容相似性、时间新颖性、位置核心性、作者及团队声誉、期刊影响因子五个特征指标构建引文视角下领域知识扩散演化模型(见图6)。 其中“文献被引势”表示领域引文网络中文献被新文献引用的相对能力,同时表征文献的知识扩散能力,如果文献的被引势较高,则被新节点连接的概率就越高。
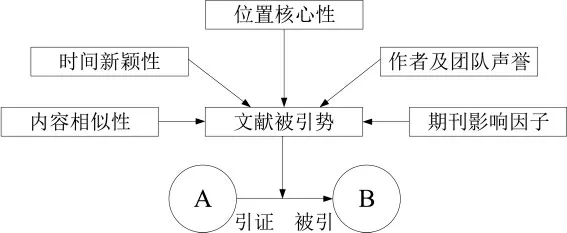
图6 引文视角下领域知识扩散演化模型
3 仿真实验及结果分析
3.1 模型变量及公式定义
根据各指标的数值分布特征,以引文视角下领域知识扩散演化模型为基础构建仿真公式(模型变量见表2)。
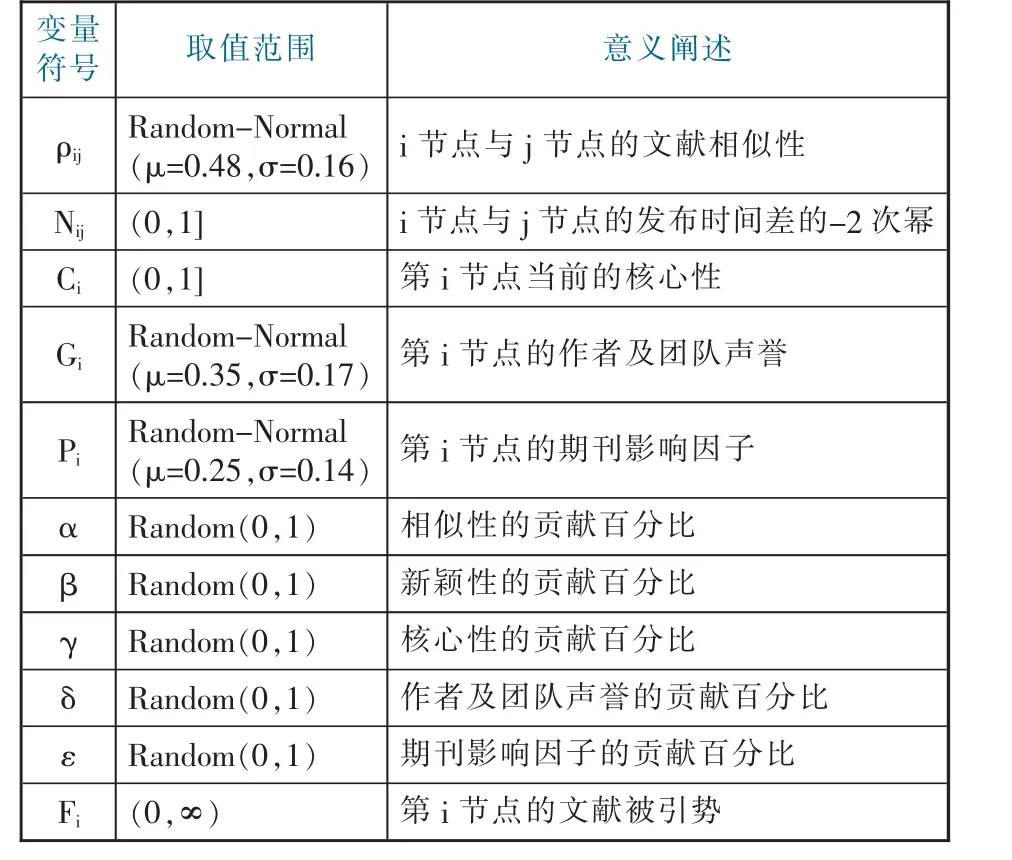
表2 模型变量与定义
按照蒙特卡洛模拟的思想,各节点的内容相似性、作者及团队声誉、期刊影响因子在网络初始化阶段与节点进入阶段由系统模拟生成,为更贴近真实网络,3 项指标均选取真实网络的数据分布。设内容相似性、时间新颖性、位置核心性、作者及团队声誉、期刊影响因子5 个指标的贡献度分别为α、β、γ、δ、ε,可得到文献被引势计算公式(见式5):
根据公式5 即可计算第i 节点的文献被引势,则第i 文献被引概率满足(见式6):
其中,Fi越大则表明第i 节点的文献被引势越高,对于新节点来说,在目前已有的n 个节点中,其被引证的概率则相对越高。
3.2 仿真模型算法
(1)建立初始网络:构建有m0个节点的初始连通网络,以正态分布随机初始化每个节点的作者及团队声誉指标、期刊影响因子指标,各项数值参考表2。据已有研究发现不同初始网络对最终结果没有太大的影响[24],且由于学术网络本身符合无标度网络特征,故选用BA 模型建立初始网络。

(3)节点连接:以正态分布随机初始化新增节点与网络现有节点的内容相似性;以公式2 计算新增节点与网络现有节点的时间新颖性;以公式3 计算现有网络中各节点的核心性;以均匀分布随机化5 个指标的贡献度;以公式5 计算新加入节点与现有节点间的文献被引势Fi,最后依据公式6 随机择优连接。
3.3 模型误差公式建立
为检验仿真网络与真实网络的差异,采用网络密度、点度中心势、节点入度分布系数、平均最短路径长度4 项网络基本特征作为测度指标,并构建模型误差计算公式(见式7)。 据此得到知识管理领域引文网络特征指标计算结果(见表3)。

表3 知识管理领域引文网络基本特征
3.4 仿真结果与分析
为探索指标对引文网络的扩散影响,寻求适合真实领域网络的最优指标贡献度,本文采用蒙特卡洛模拟思想,以模型误差为筛选机制,提取误差值最小区间范围和指标贡献度,具体步骤如下:
(1)基本参数设置:依据领域引文网络规模,设置初始节点数据m0=5,总迭代时间tz=1031,以(0,1)均匀分布随机生成指标贡献度,得到不同指标贡献度下的仿真网络特征值,以求和归一化方式计算指标间相对贡献度,并记录1000 次实验结果。
(2)最优解组遴选:1000 次实验中,异常值仅占0.2%,其余所有实验误差均小于0.2,均值为0.0483。将异常值划为第20 组,其余实验按照模型误差递增排序,以0.01 区间单位划分误差范围(0.009,0.20)为19 组并统计各组平均模型误差和各指标平均贡献度(见图7)。其中,第1 组实验的模型误差最小,范围为0.009-0.02,均值为0.0157,因此本文将第一组视为最优解组(占比为13.2%),并以该组为基准对比分析其他各组的指标均值,以探索不同贡献度分布下的网络扩散特征。
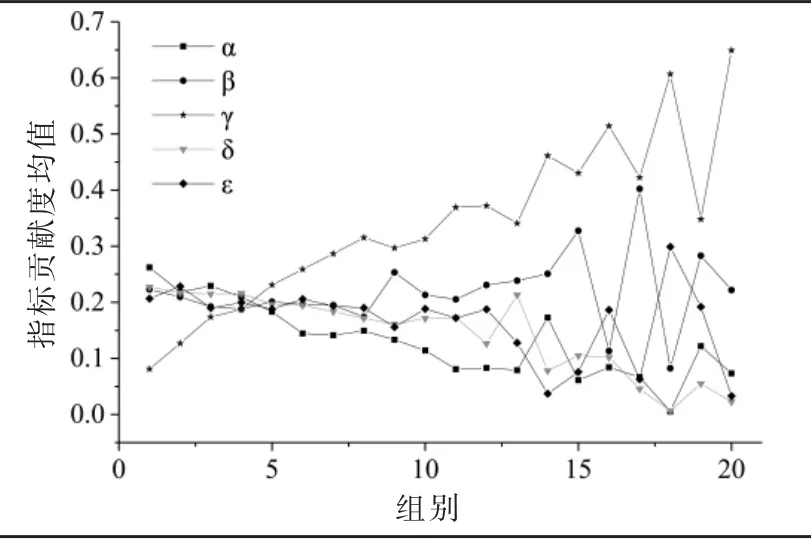
图7 各组指标贡献度分布
(3)各组指标贡献度对比:据图7 可知,最优解组的内容相似性贡献度均值与其他组相比最高;时间新颖性中,前8 组实验贡献度均值较为平缓,达到稳定状态;位置核心性贡献度均值呈现递增趋势,最优解组为最低;作者及团队声誉贡献度均值呈现递减趋势,最优解组为最高;期刊影响因子前8 组分布均衡,整体呈现下降趋势。最后,13-20 组在5 个指标贡献度分布上与最优解组相比波动较大,模型误差不理想,因而选择第1 组为最优解组具有可靠性。
(4)最优解组内部分析:对最优解组中132 个子实验的各项指标最优解贡献度分布进行分析(见图8),其中内容相似性贡献度均值和箱体整体较高(均值为26.22%),其次是作者及团队声誉(均值为22.72%)、时间新颖性(均值为22.29%)与期刊影响因子(均值为20.66%),最后是位置核心性(均值为8.11%),即使最优解组误差均值优化达到0.0157,各项指标仍然存在误差波动,因此可以推断出最优解具有多种模式。
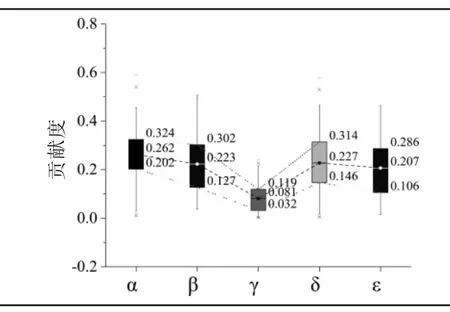
图8 最优解组指标贡献度分布
(5)最优解组指标聚类分析:为深入研究最优解模式,本文利用K-Means 聚类方法对最优解组中贡献度进行聚类,以k=3 进行聚类分析,得到个案数分别为43、42、47 的3 个类别,各类别个案分布均匀且模型误差无明显差异,证明聚类结果合适,继而提取3 个类别的指标贡献度与网络指标均值(具体见表4中6-8 项)。
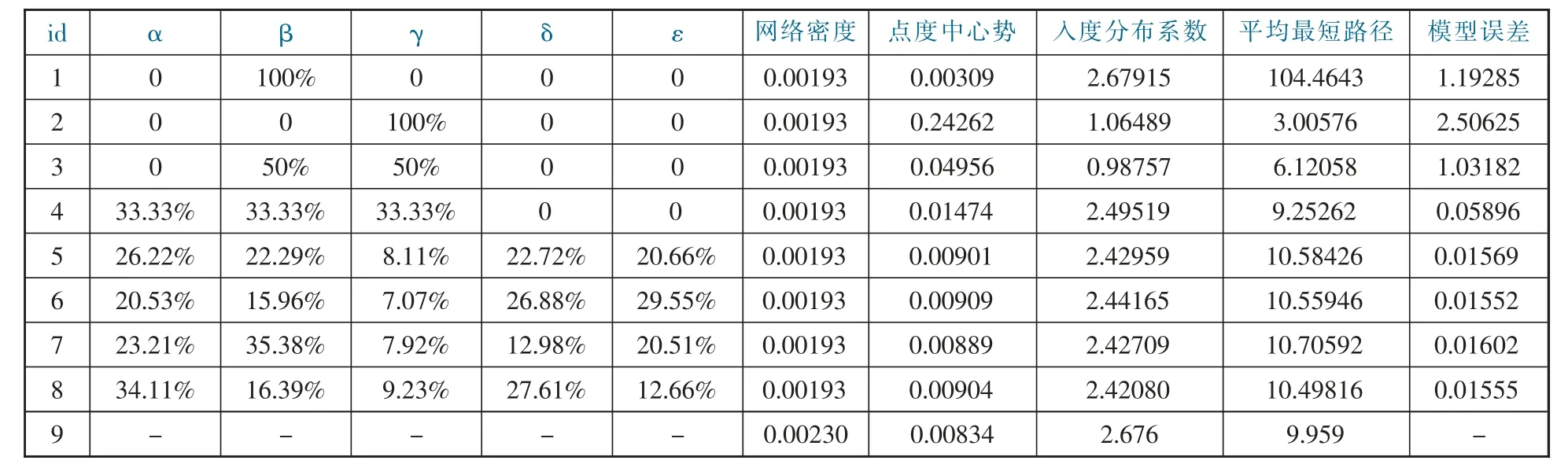
表4 仿真结果
(6)最优解组与现有模型对比分析:为验证融合多角度细粒度的模型能更好揭示真实网络扩散特征,本文分别对“时间优先机制”(id1)、“度优先机制”(id2)、融合“度优先机制”与“时间优先机制”(id3)、融合前两者机制与“内容相似性”(id4)的模型进行30 次实验,计算其平均误差值与网络基本特征,并与最优解组(id5)、最优解组聚类结果(id6-8)、真实网络(id9)对比,研究发现前4 组实验的模型误差均大于后4 组。
由贡献度可知,最优解组(id5)中内容相似性具有最高贡献度,其次是作者及团队声誉、时间新颖性、期刊影响因子;聚类结果1(id6)中期刊影响因子、作者及团队声誉与内容相似性三者贡献度相对较高;聚类结果2(id7)以时间新颖性、内容相似性和期刊影响因子为重;聚类结果3(id8)则以内容相似性与作者及团队声誉为重。四组实验中内容相似性和作者及团队声誉贡献度均较高,而位置核心性均较低。
综上,内容相似性连接机制在真实领域网络中发挥了较大的作用,贡献度为20%-35%,表明学者在科研活动中,往往会选择与自己研究主题和内容相近的文献。其次,作者及团队声誉、时间新颖性、期刊影响因子,三者贡献度相近,约为15%-30%,这表明学者会主动选择引证时间新颖的文献,对领域中重要期刊和核心作者团队的文献有更多的引用偏好。此外,研究发现,位置核心性贡献度仅占7%-9%,表明学者更倾向于引证新颖的文献,而较少选择发布时间较早的核心文献,同时也说明文献在引文网络中的位置核心性并非被引的决定性因素,这与传统BA 模型的基本假设有较大差异。
实验组间的网络特征具有明显差异,这是由不同连接机制所致。其中,id1 仅考虑时间新颖性,即时滞越短的文献,被引证的概率越大,而id2 只考虑文献位置核心性,即节点度值越高,被再次引证的概率越大,是典型的BA 模型。两组实验的连接机制分别表征的是对新文献的偏好和对传统核心文献的偏好,但前者显示连接路径较长、网络较稀疏的特征,与后者相反。id3 中时间新颖性与位置核心性贡献度均占50%,其点度中心势、最短路径长度均处于id1 和id2的值之间且模型误差小于前2 组实验,说明融合时间新颖性与位置核心性具有更好的可解释性,二者不可或缺,都在领域知识扩散过程中发挥重要作用。id4 在id3 的基础上融入内容相似性,模型误差大幅降低,可知内容相似性指标具有更大贡献,但其模型误差仍高于最优解组,说明还存在其他影响因素。
与前四组相比,五维指标融合模型的误差降低至0.015 左右,说明仿真网络不能仅依据单一指标,内容、时间、作者团队、期刊、核心性等都会影响文献的引证关系。从最优解组聚类结果可知,指标最优解存在一定模式,但内容相似性的贡献度仍较高而位置核心性的贡献度最低,其余三个指标在15%-30%波动。 即便是最优解组,其结果仍然具有一定误差,说明还有其余因素影响引证关系,如文献语言、作者数目、期刊语言、学科领域等[43]。
4 结论与讨论
本文从多粒度视角构建引文网络仿真模型,融合内容相似性、时间新颖性、位置核心性、作者及团队声誉、期刊影响因子5 个维度,建立“文献被引势”仿真机制,利用模型误差公式计算仿真模型对真实网络的拟合程度,基于蒙特卡洛模拟思想,实现不同贡献度条件下各维指标对引文网络知识扩散的影响分析,同时应用K-Means 聚类寻找指标贡献度最优解模式。在指标上,弥补了传统BA 模型在引文知识内容、新颖性、作者团队与期刊声誉维度的缺陷问题,实现多指标融合仿真;在分析上,探索了不同影响因素对引文网络扩散的影响程度。
从最优解组指标贡献度分析可知内容相似性、时间新颖性、位置核心性、作者及团队、期刊因素均会影响引文网络的形成:(1)内容相似机制最大程度影响知识节点的连接,相似节点间的连接概率更高;(2)时间优先机制使得引文网络的平均最短连接路径增加、点度中心势降低,表现为对新知识的偏好;(3)度优先机制与时间优先机制的作用方式与效果不同,其更强调领域核心知识的继承,有利于保持学科领域内核知识的稳定性;(4)作者及团队与期刊择优机制则体现在高指标值节点的可见度与连接概率的提升;(5)模拟发现近11 年“知识管理”领域引文网络中,内容相似性指标的贡献度最高,位置核心性指标的贡献度最低。
不同学科领域中各影响因素的贡献度可能会有所不同。本文仅搜集中文“知识管理”领域11 年内核心期刊的引文数据,由于该领域具备较强的交叉学科属性,所得贡献度并不能完全适用于其他学科。其次,模型也仅参考题录、作者等显性特征,缺乏更深层的指标,在作者及团队声誉计算过程也存在同名作者的影响。未来研究中,将不断优化现有模型并分析更多领域的引文网络,一方面检验现在模型的普适性,另一方面通过指标的贡献度排序可为学科差异发展态势识别提供精确的衡量指标。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
河北画报(2020年8期)2020-10-27
计算机世界(2020年50期)2020-01-15
青年生活(2019年23期)2019-09-10
石河子大学学报(哲学社会科学版)(2019年3期)2019-07-27
中国生物医学工程学报(2019年4期)2019-07-16
浙江大学学报(工学版)(2016年2期)2016-06-05
电力自动化设备(2015年4期)2015-09-28
中共南宁市委党校学报(2015年4期)2015-02-28
西华大学学报(哲学社会科学版)(2014年2期)2014-02-27
