
基于生成对抗网络的半监督遥感图像场景分类
2022-03-05 03:02郭东恩吴泽琛
南阳理工学院学报 2022年6期
郭东恩,吴泽琛
(南阳理工学院计算机与软件学院 河南 南阳 473004)
0 引言
遥感图像场景分类可以自动根据场景内容将其分类为指定的语义类别。基于深度神经网络方法在较大规模的有标签数据集上进行监督训练时,通常可以实现更高的分类精度[1]。此外,无监督分类可以从大量无标签样本中学习,但不能充分利用有标签样本,导致其分类精度很难满足实际需求。尽管最近已经发布了数以万计的遥感场景数据集,但由于标注遥感图像耗时耗力,在某些特定的遥感应用中仅包含部分有标签的样例,缺少大量有标签样本是遥感领域深度学习方法的关键挑战[2]。
半监督学习是一种解决有标签数据不足的有效方法。半监督遥感图像场景分类不仅可以从少量的有标签数据中学习,而且可以充分利用无标签的数据,可以减少对有标签样本的依赖,大大减轻了标注遥感图像的负担[3]。
近年来,生成对抗网络(generative adversarial networks,GAN)已用于半监督图像分类,这是因为GAN具有通过对抗训练从真实训练样本中学习基础数据分布的能力,可以与最先进的半监督图像分类方法竞争[4]。当前基于GAN的最新半监督方法使用标准DCGAN的变体进行图像分类[5-7]。Li等人提出了一种triple-GAN利用三者博弈实现出色的半监督分类性能[5]。Dai等人分析了GAN不能同时获得良好的半监督分类和良好的生成效果的原因,提出一种新的半监督分类模型,有效提高了多个基准数据集上的分类性能[6]。这些基于GAN的方法已经实现了更好的半监督分类性能,但是,由于标准DCGAN的判别网络无法充分提取图像特征,限制了分类性能的提高。尤其是面对更加复杂的遥感图像的半监督分类需要进一步研究更有判别性的特征提取方法,以提高基于GAN的半监督分类性能。
1 相关工作
半监督图像分类可以从有标签和无标签的数据中联合学习,以利用大量无标签的样本来提高分类性能。最近,GAN被引入半监督图像分类中,通过使用大量无标签的样本和有限的有标签样本来显著提高分类性能[5,6]。
标准GAN至少包含一个生成网络G和一个判别网络D,G通过随机噪声z生成假样本G(z),而D用于判断输入样本的真假,通过两者间的不断博弈实现相关任务。其博弈过程对应的值函数V(G,D)可表示为

EZ~pZ(Z)[log(1-D(G(z))]
(1)
其中,z表示遵循先验分布z~pz生成的随机噪声向量,pdata表示真实样本的概率,pz表示生成网络G生成的假样本的概率,D旨在使真实图像的概率最大化,而G旨在提高将生成图像分类为真实图像的可能性。
Salimans等人提出FMGAN通过加入生成网络生成的假图像扩展标准分类器实现半监督的图像分类[4]。
基于GAN的半监督图像分类网络框架如图1所示。判别网络D的输入由3部分构成:真实有标签图像、真实无标签图像和生成网络G生成的假图像,无标签图像需要进行无监督训练,有标签图像需要进行有监督训练。因此,判别网络D的损失函数LD可以表示为
LD=Ls+Lun
=-Ex,y~pdata(x,y)[log(pmodel(y|x))]-
{Ex~pdata(x)logD(x)+Ez~pzlog(1-D(G(z)))}
其中,Ls表示有标签图像训练的有监督损失,Lun表示无标签真实图像和生成网络生成的假图像对应的无监督损失。
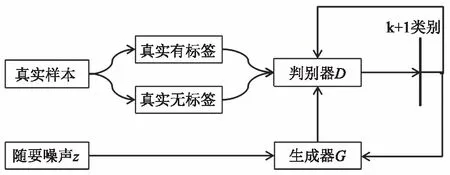
图1 基于GAN的半监督图像分类网络框架
Roy等人提出一种用于半监督卫星图像分类的语义融合GAN(SFGAN),通过引入一个语义分支增强判别网络的特征提取能力获得更好的分类性能[8]。最近,Guo等人提出了SAGGAN,利用门控自注意及预训练语义分支实现遥感图像的半监督分类,取得了良好的效果[3]。但是SAGGAN采用标准的DCGAN结构,适合处理场景相对简单,空间分辨率较低的图像,对于复杂场景的高分辨率遥感图像,特征捕获能力受到较大的限制。
Duta等人提出了金字塔卷积(PyConv)利用不同大小和深度的不同类型的滤波器捕获场景中不同层次的细节。Miyato等人引入谱归一化(spectral normalization,SN)到GAN中稳定训练过程提高GAN的性能。夏英等人提出了深层和浅层特征融合的基于GAN的半监督遥感图像场景分类方法,取得了较好的分类效果[9]。Ledig等人提出了SRGAN,利用深度残差结构的GAN进行自然图像的超分辨率重建,实现了更真实的图像纹理的恢复重建[10]。
受上述文献的启发,本文提出一种新的基于GAN的半监督遥感督场景分类模型(SSGAN),该模型引入密集残差块代替SAGGAN中的卷积,使用金字塔卷积、预训练分支、谱归一化及特征融合对判别网络特征提取能力进行增强。通过引入密集残差块到生成网络增强生成图像的质量,通过引入密集残差块到判别网络增强判别网络特征判别能力。通过引入预训练的ResNet50 v1网络分支有效提取图像的语义特征并和原始判别网络的特征进行融合,提高特征判别能力。通过将判别网络中标准卷积块替换为金字塔卷积块有效获取场景图像中不同层次的细节特征。利用谱归一化稳定GAN网络的训练,有效提高半监督遥感场景分类的精度。
通过在公开的遥感数据集EuroSAT[11]和UCM Merced[12]上的对比实验验证了提出的SSGAN方法的性能,提出的SSGAN和基于GAN的其他半监督方法相比获得了更高的分类精度。
2 提出的模型
本节详细介绍提出的SSGAN模型。具体SSGAN的框架结构如图2所示。
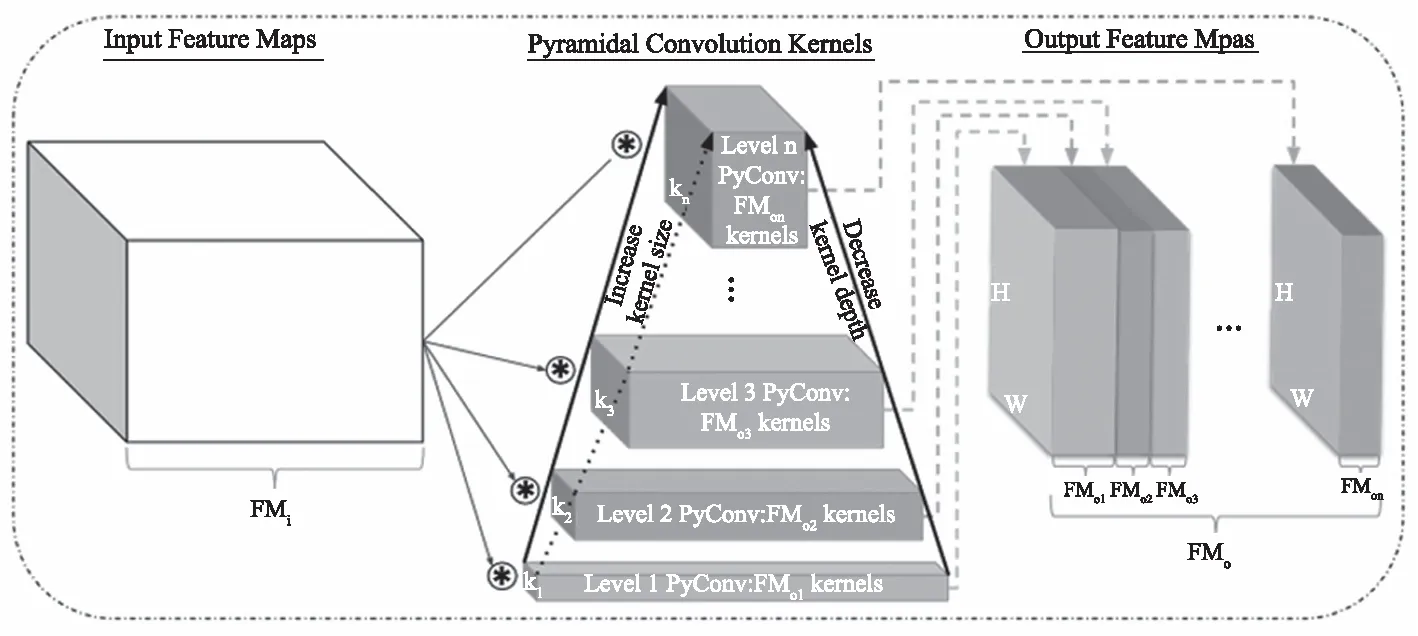
图2 PyConv的结构
2.1 SSGAN模型结构
按照SAGGAN[3]中的结构,使用SRGAN[12]中的残差块来代替SAGGAN中的普通卷积构建SSGAN的生成网络和判别网络结构,具体结构如图2所示。生成网络由4个残差块构成,每个残差块结构如图中G_Block块所示,包含一个上采样层,然后紧跟一个批正则化(batch normalization,BN)和一个参数化激活函数(Paramitric ReLU,PReLU),然后是两个卷积层,中间有一个BN层。
为了进一步增强判别网络的特征表示能力以促进半监督遥感场景分类性能,受SF-GAN的启发[8],本文扩展了判别网络以进一步增强特征描述能力。首先引入一个在ImageNet数据集上预训练的ResNet50 v1作为网络分支扩展判别网络,当图像x输入到D时,通过微调ResNet50 v1分支提取最后一个卷积层的激活值,然后对提取的特征图进行全局平均池化操作(global average pooling,GAP)。其次,为了捕获更广泛的上下文信息,将判别网络残差块中第二个卷积层替换成金字塔卷积(PyConv)。此外,在生成网络和判别网络的每个残差块中加入了SN层以稳定GAN的训练过程,提高分类精度。最后,将从原始判别网络分支和ResNet50 v1分支中提取的两个特征进行融合,输入到softmax分类器中进行半监督场景分类。
2.2 金字塔卷积
由于遥感场景图像的复杂性,不同对象在不同场景中可能呈现不同大小,相同对象在同一场景中也可能呈现不同的大小,使用传统的3×3卷积很难有效学习这种多样性。Duta等人提出了金字塔卷积[9],该卷积包含金字塔状的核,每一层包含不同大小和深度的过滤器,能够捕获不同层级的细节信息,具有n组不同核的PyConv如图2所示。按照PyConv[9]的思想,本文构建了判别网络的残差块D_Block,其中第二个卷积替换为PyConv,本文参考PyConvHGResNet的结构,使用4组不同核大小的PyConv捕获不同层次的信息。
这里FMi表示中间层的特征图作为PyConv的输入,FMo表示PyConv的输出,PyConv由4组不同大小和深度的过滤器组成,通过PyConv构成的残差块可以捕获到不同层次的特征信息,增强判别网络中特征的判别能力。
2.3 特征融合和谱归一化
深层神经网络中不同层次的特征包含不同的细节,特别是高层特征往往包含高层语义信息,因此,多层特征融合可以增强特征表示能力。那么,对多个网络分支获取的特征进行融合也能增强特征表示能力,主要受SFGAN的启发,将原始判别网络分支和微调预训练ResNet v1分支的特征进行融合,进一步增强特征判别能力。特征融合的结构如图3所示。
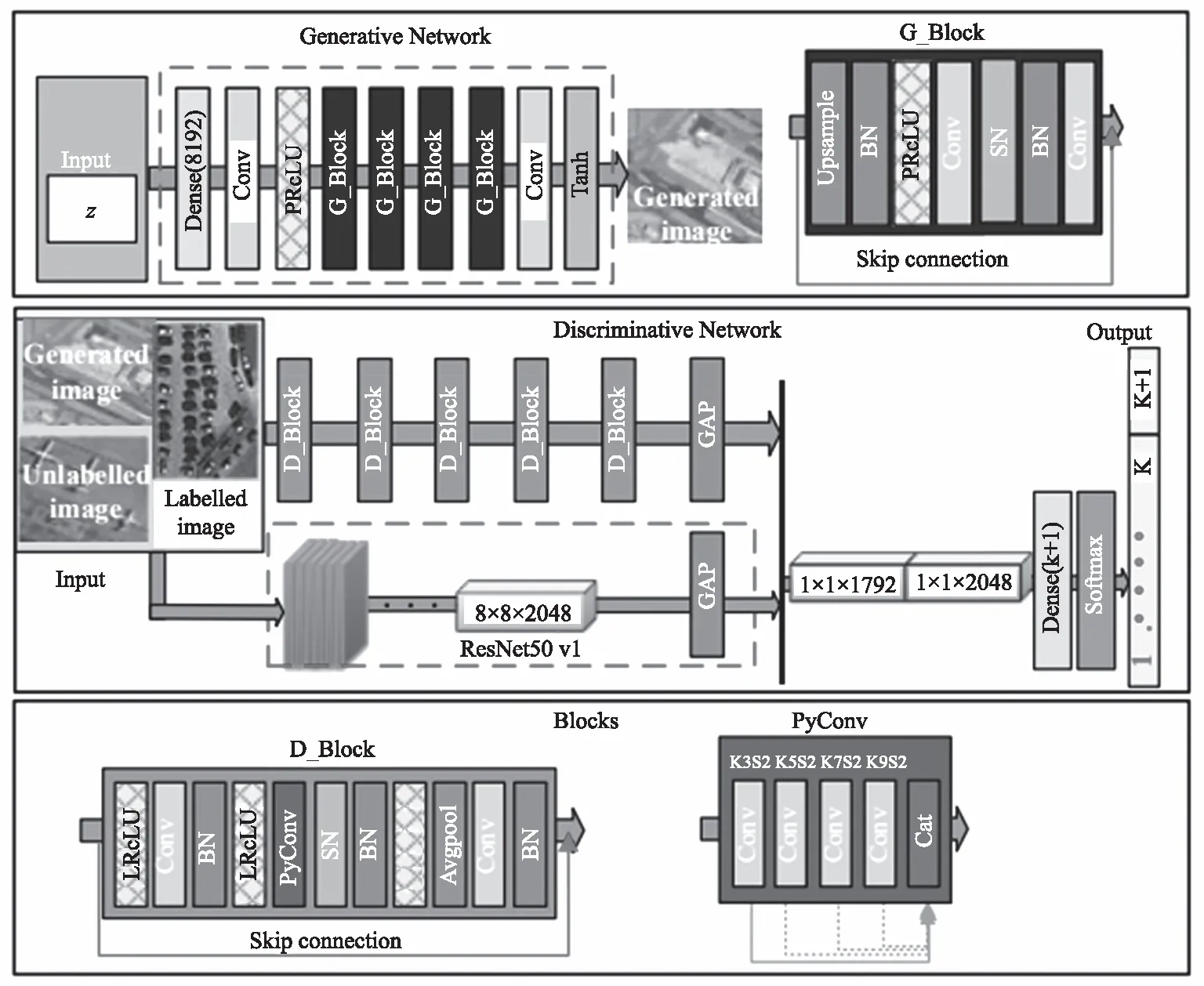
图3 SSGAN模型的网络架构
GAN训练的不稳定性一直是基于GAN任务中的一大挑战。Miyato等人提出了谱归一化[10]思想,用以约束判别网络1-Lipschitz连续,从而有效提高模型性能。而在SAGAN[13]中,谱归一化被同时用于GAN的生成和判别网络的每个卷积中,来稳定训练梯度,提高GAN的性能。受SAGAN启发,本文在生成网络和判别网络中均加入谱归一化来稳定GAN训练,以增强判别网络的特征表示能力。
3 实验结果及分析
本节在遥感图像基准数据集EuroSAT和UCM Merced上进行广泛的实验,以验证提出的SSGAN方法的有效性。
3.1 数据集描述和实验设置
EuroSAT 数据集[11]是基于Sentinel-2卫星获取的中分辨率遥感图像数据集,含有10种不同的土地规划类别,共27,000张空间分辨率为64×64的图像。UC Merced数据集[12]是遥感图像场景分类最常用的基准数据集,共包括21种土地覆盖类别。每类包含100张大小为256*256的图像。
为了验证提出的SSGAN的半监督分类性能,本文按照SAGGAN[3]中的设置,将两个数据集拆分为3部分:训练集80%,验证集2%和测试集18%。另外,确定了有标签训练样本的数量M。EuroSAT数据集上M分别设置为100、1000、2000和21600,而UC Merced数据集上M设置为100、200、400、1680,其余的作为无标签样本。
所有实验在64位Ubuntu 16.04服务器上PyTorch框架中进行,该服务器采用8核Intel®Xeon®Gold 6048 CPU @ 2.36 GHz处理器,配有4个TITAN V GPU。在训练过程中,根据SAGGAN[3]设置最小批大小为128,训练轮次为200,初始学习率0.0003,学习率衰减为0.9。所有对比方法都遵循原始设置,以确保公正性和客观性。
此外,为了确保实验的可靠性,所有实验结果均是对随机选择的样本进行的5次重复实验取平均值。
3.2 实验分析
本部分在两个数据集上对提出的SSGAN进行实验,并和微调的Inception V3预训练网络及几种代表性的基于GAN的图像分类方法进行比较。基于GAN的半监督分类方法包括SAGGAN[3]、FM-GAN[4]、Triple-GAN[5]、bad-GAN[6]、REG-GAN[7]、SF-GAN[8]。表1列出了几种方法的整体精度,从这些数据中我们可以得到以下结论:
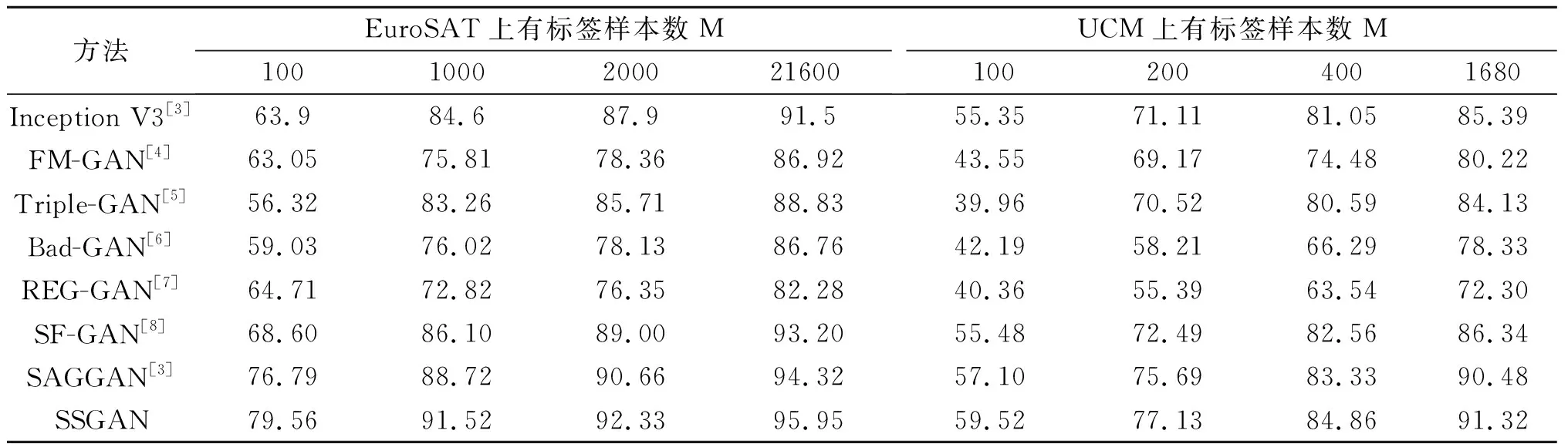
表1 不同方法的整体精度
(1)本文提出的SSGAN在两个数据集上实现了最佳分类精度,这是因为引入了预训练分支、PyConv和SN,并且使用了特征融合以进一步增强特征表示能力。SAGGAN方法的性能排第二,因为引入了自注意门控模块和门控单元增强了判别网络的判别能力。 SF-GAN方法的性能排第三,可能是因为在SF-GAN中引入了预训练的Inception V3网络来增强了判别网络的特征表示能力。Inception V3方法的性能超过了除SAGGAN、SF-GAN和本文提出的SSGAN之外的其他方法,这是因为Inception V3在大规模ImageNet数据集上进行了预训练,能够通过微调提取遥感图像中更有判别性的特征。
(2)随着有标签样本数量M的增加,每种方法的精度呈线性增加。有趣的是,当M=21600时,提出的SSGAN比预训练的Inception V3方法具有更高的精度。这可能是因为本文提出的SSGAN可以使用生成网络生成的图像进行额外训练,而这些生成的样本对预训练的Inception V3网络是不可用的。在UCM Merced数据集上的结果存在相同的趋势。
(3)在EuroSAT数据集上当M=100时SSGAN的精度比SF-GAN和SAGGAN分别高10.96%和2.77%,达到79.56%,这表明SSGAN可以用较少的有标签样本获得更高的精度。在UC Merced数据集上可以看到类似的结果。
(4)在UC Merced数据集上,M=100、200、400和1680时,SSGAN的精度仅为59.52%,76.13%,83.86%和91.02%,这是因为总的训练样本数量不足,这限制了基于GAN网络的半监督分类性能。但是,与其他方法相比,SSGAN的分类精度仍最高。
为了进一步分析所提出的SSGAN的性能,在EuroSAT数据集上分别在M=100、1000、2000和21600生成了混淆矩阵。从图4混淆矩阵的结果中,可以得出如下结论:
(1)随着有标签样本数量M的增加,每个类别的精度单调增大,而混淆误差相应减小。当M=100时,10个类别中有6个类别精度超过76%,说明在具有更少有标签数据情况下,提出的方法获得了更好的分类精度。
(2)通过对M=100和M=2000的结果进行比较,类别1、2、6、7、8的准确性分别提高了21%,29%,28%,21%和22%。表明随着有标签样本数的增加,各类别分类精度明显增高。
(3)在M=21600的情况下,所有10类样本中有9个类别的分类精度超过95%。简而言之,提出的SSGAN可以实现良好的半监督分类性能。

图4 EuroSAT数据集上M=100、1000、2000和21600产生的混淆矩阵
3.3 消融实验
与其他半监督图像分类方法相比,提出的SSGAN由于对判别网络的增强而达到了最佳性能。本节对预训练的ResNet50 v1分支及特征融合、PyConv和SN的有效性进行验证。分别研究了所提出方法的3个变体:(1)SSGAN-R是没有预训练的ResNet50 v1分支及特征融合的变体;(2)SSGAN-P是不使用PyConv的变体;(3)SSGAN-SN是不含SN的变体。
为了公平比较,本文在相同的实验设置和数据集上进行了广泛的实验。从表2中两个数据集上的实验结果可以看出,ResNet50 v1分支和特征融合、SN和PyConv都有助于改善SSGAN性能。其中,SSGAN-R在两个数据集中的精度最低,这表明ResNet50 v1分支和特征融合是最有效的,因为ResNet50 v1可以从场景图像中提取高级语义信息,然后将提取的语义特征图和原始判别网络特征进行融合以进一步增强特征判别能力。第二有效的是PyConv,因为通过多组不同核大小的金字塔卷积操作,可以获取不同层次的细节信息,增强特征判别能力。第三有效的是SN,在两个数据集上精度也有较大的提高。有趣的是,SSGAN-SN在标签数量M更大时其精度明显比SSGAN更低,这表明SN在有更多有标签训练样例下性能更好。

表2 消融实验结果
4 结论
论文提出了一种新的基于GAN的半监督场景分类方法,该方法引入密集残差块、预训练的ResNet50 v1网络及特征融合的思想和金字塔卷积来增强特征表示能力,同时在生成网络和判别网络引入谱归一化增加GAN训练的稳定性,该方法可以充分利用少量有标签和大量无标签样本进行半监督遥感场景分类。广泛的实验结果表明,与其他对比方法相比,本文提出的方法可实现更高的整体精度,尤其是在仅有少量有标签样本时能获得明显更高的精度。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学年刊A辑(中文版)(2020年2期)2020-07-25
电子制作(2019年13期)2020-01-14
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
电子制作(2019年11期)2019-07-04
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
Coco薇(2015年11期)2015-11-09
