
基于EOBL-AO的牛奶脂肪含量预测模型
2022-03-04 14:31刘江平李欣陈晨
山西农业大学学报(自然科学版) 2022年6期
刘江平,李欣,陈晨*
(1.内蒙古农业大学 计算机与信息工程学院,内蒙古 呼和浩特 010018;2.内蒙古自治区农牧业大数据研究与应用重点实验室,内蒙古 呼和浩特 010030)
牛奶作为常见的乳制品,其中含有大量的营养物质,以满足人们的日常需求。传统的牛奶中营养物质的检测方法多为化学方法,检测成本较高。随着高光谱技术的逐渐成熟,由于其自身所特有的优点,被广泛应用于食品检测方面[1]。
目前,国内外很多学者应用高光谱成像技术对牛奶中所含有的物质进行定量分析。刘美辰等[2]利用高光谱成像技术结合麻雀搜索算法(Sparrow Search Algorithm,SSA)对牛奶中蛋白质的含量进行预测,结果表明,高光谱成像技术能很好地预测出牛奶中蛋白质的含量,预测的准确率较高;Wang Yan等[3]利用高光谱成像技术对牛奶中的山梨酸钾含量进行分析,结果证明,高光谱成像技术检测山梨酸钾的含量是可行的;赵紫竹等[4]利用高光谱成像技术结合多维偏最小二乘(Multidimensional Partial Least Squares,N-PLS)对牛奶中的脂肪含量进行预测,预测集的相关系数值为0.997 6,预测效果好;Liu等[5]利用高光谱成像技术结合多层前馈神经网络(Back Propaga⁃tion,BP)对牛奶中的蛋白质含量进行预测,应用此方法进行检测是可行且高效。综上可知,应用高光谱成像技术对牛奶中的脂肪含量进行检测可行,但由于牛奶中的物质成分较为复杂,试验所获得的光谱数据间共线性较高,传统的机器模型的预测效果达不到人们的期望值,故本文利用高光谱成像技术结合改进的天鹰优化器算法建立牛奶脂肪含量的预测模型。本研究通过将优化后的模型与其它算法优化后的模型作比较,旨在为改进的天鹰优化器算法优化SVR模型是可行的提供理论依据。
1 材料与方法
1.1 试验材料
试验所用牛奶均来源于超市购买的5种牛奶,分别为蒙牛高钙牛奶、伊利QQ星、特仑苏牛奶、伊利脱脂牛奶和伊利纯甄牛奶,其中每100 mL中蒙牛高钙牛奶脂肪含量为3.7 g,伊利QQ星为3.7 g,特仑苏牛奶为4.4 g,伊利脱脂牛奶为0 g,伊利纯甄牛奶为4.6 g。
1.2 样品制备及数据采集
试验包含5种牛奶,每种牛奶配置5个平行样本,故5种牛奶共包含25个样本。以蒙牛高钙牛奶为例,取适量的牛奶放置于直径长度为85 mm的培养皿中,使得液面高度为8 mm,等待备用。
首先将样品放置于采集台上,利用高光谱图像采集软件进行图像采集(图1)。
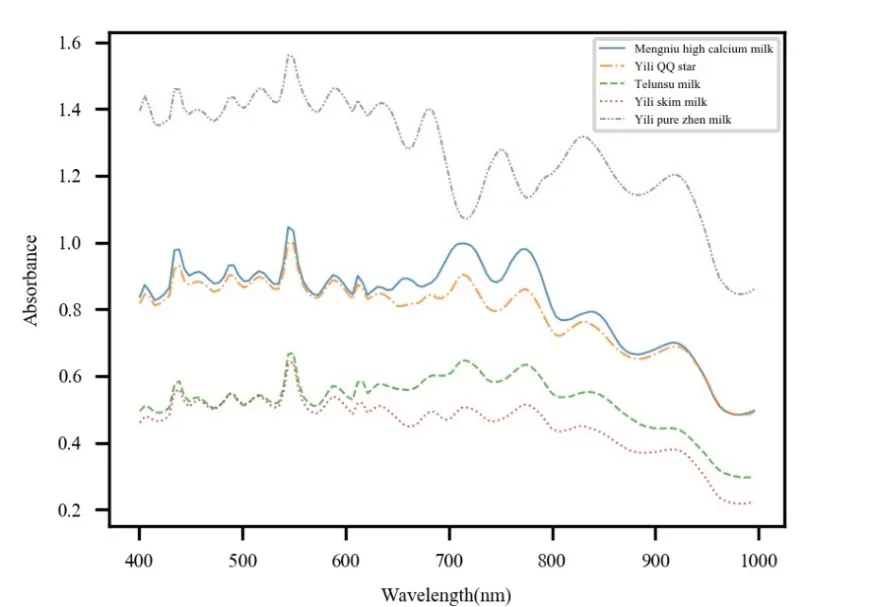
图1 原始的平均光谱图像Fig.1 The original mean spectral image
其次,利用ENVI软件进行感兴趣区域(Re⁃gion of interest,ROI)提取,最终得到250条数据,每条数据均含有125个波长,波长的范围为400~1000 nm。有关数据集的信息如表1所示。

表1 数据集的相关信息Table 1 Information about the data set单位:(g·100 mL-1)
1.3 数据处理方法
在数据的获取过程中,由于受到噪声、光散射等因素的影响,会直接导致获取的数据不够准确。为了消除这些因素对试验数据影响,故试验开始对原始数据进行预处理操作。常用的预处理方法[6]包括多元散射校正(multiplicative scatter cor⁃rection ,MSC),变 量 标 准 化(standard Normal Variate transform ,SNV),移动平均法(Moving Average,MA),平 滑 滤 波 法(Savitzky-Golay,SG)。将经过不同预处理方法所建立的PLSR模型进行比较,通过比较模型的评价参数,选取最好的预处理方法。
1.4 特征选择方法
由于试验所获得的光谱数据中含有大量的冗余信息,会使得模型训练时间长,从而导致效率低下,训练结果不准确。为了消除冗余信息对实验产生影响,需通过特征选择来消除数据中的冗余信息,提高光谱信息与标签值之间的相关性。常见的特征选择方法有连续投影算法[7](successive projections algorithm,SPA)、竞争性自适应重加权算 法[8](competitive adapative reweighted sam⁃pling, CARS)和 主 成 分 分 析 方 法[9](Principal Component Analysis,PCA)。将3种不同的特征选择方法进行比较,选取最好的特征选择方法进行建立模型操作。
1.5 建立模型方法
1.5.1 基于GA的SVR参数优化
遗传算法[10](Genetic Algorithm,GA)常被用于问题的优化,选择任意的初始种群并计算其适应度函数值,经过选择、交叉和变异3种算子的操作,得到一群适应度函数值更高的个体,从而求得问题的最优解。试验中初始种群的规模设置为50,迭代次数设置为50,将初始种群的值带入到相应的参数中,对特征筛选后的数据进行训练并建立预测模型,计算该模型的适应度函数值,逐次进行迭代,若达到最大的迭代次数,则输出此时参数对应的值即最优解,实现GA对SVR参数的优化。
1.5.2 基于HHO的SVR参数优化
哈 里斯鹰优 化 算 法[11](Harris Hawks Optimi⁃zation, HHO)是模仿哈里斯鹰捕猎行为,用数学公式来描述哈里斯鹰在不同情况下捕食猎物的策略。在HHO算法中,哈里斯鹰的位置是当前的候选解,猎物即兔子的位置是当前迭代次数中的最优解。HHO算法包括全局探索和局部开发两个阶段。试验中初始种群的规模设置为50,迭代次数设置为50,将初始种群的值带入到相应的参数中并计算适应度函数值,依次进行迭代,迭代的同时,要注意更新种群的位置及适应度函数的值。若达到最大的迭代次数,则输出此时参数对应的值即最优解,从而实现HHO对SVR参数的优化。
1.5.3 基于AO的SVR参数优化
天鹰座优化器[12](Aquila Optimizer,AO)是模仿天鹰座捕食猎物的行为,常被用来寻找最优解。AO算法共包括扩大搜索、缩小搜索、扩大开发、缩小开发4个阶段。根据当前的迭代次数来决定具体的操作。若迭代次数t的值小于等于三分之二倍的最大迭代次数的值,则执行搜索操作;反之,则执行开发操作。若达到最大的迭代次数,则输出此时参数对应的值即最优解,从而实现AO对SVR参数的优化。
1.5.4 基于EOBL⁃AO的SVR参数优化
精 英 反 向 学 习[13](Elite Opposition-Based Learning,EOBL)用来增加种群的多样性,使得初始种群更接近于最优解。AO采用随机的方式生成初始种群,使得可行解的范围增大,寻找最优解所花费的时间增加。精英反向学习策略根据公式(1)另外产生一个反向种群,分别计算2个种群的适应度函数值,选取适应度函数值最好的个体进行迭代运算。
式中,k是[0,1]中的随机数,L是位置信息范围的上限,U是位置信息范围的下限,Xi是初始种群的位置信息。利用试验所要求位置信息的范围对反向种群中的位置信息进行筛选,对于不满足条件的位置信息采用以下公式进行随机生成。
1.6 模型的评价指标
模型的评价指标包括均方根误差(Root Mean Square Error,RMSE)、决定系数(R-Square,R2)、运行时间(Time)。其中RMSE值越小,R2值越接近于1,运行时间越短,表明模型的预测能力越好,收敛速度越快。各个评价指标的计算公式如下:
均方根误差(RMSE)计算公式如下:
决定系数(R2)计算公式如下:
运行时间计算公式如下:
式中,yi表示真实的观测值,ŷ表示预测值,yˉ表示真实观测值的平均值,end表示结束时间,start表示开始时间。
2 结果与分析
2.1 预处理方法选择
本文主要研究EOBL-AO-SVR预测模型的性能。首先利用不同的预处理方法对光谱数据进行预处理操作,其次对处理后数据采用train_test_split()函数进行训练集及测试集的划分,参数test_size的值设置成0.3,故训练集含175条数据,测试集含有75条数据,最后建立PLSR模型,通过比较模型的评价参数值,得出最佳的预处理方法。4种预处理方法的比较如表2所示。
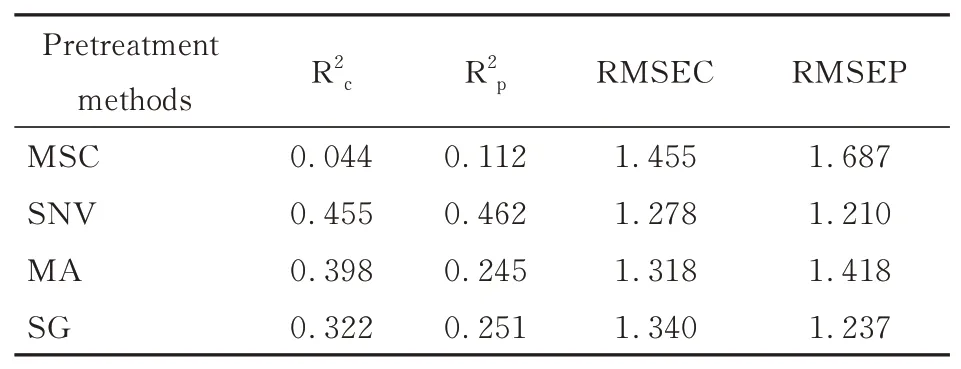
表2 预处理方法的比较Table 2 Comparison of four pretreatment methods
由图2可知,预处理方法SNV消除了由乳液不均匀及乳液多少所引起的散射影响。故采用SNV方法对数据进行预处理操作。
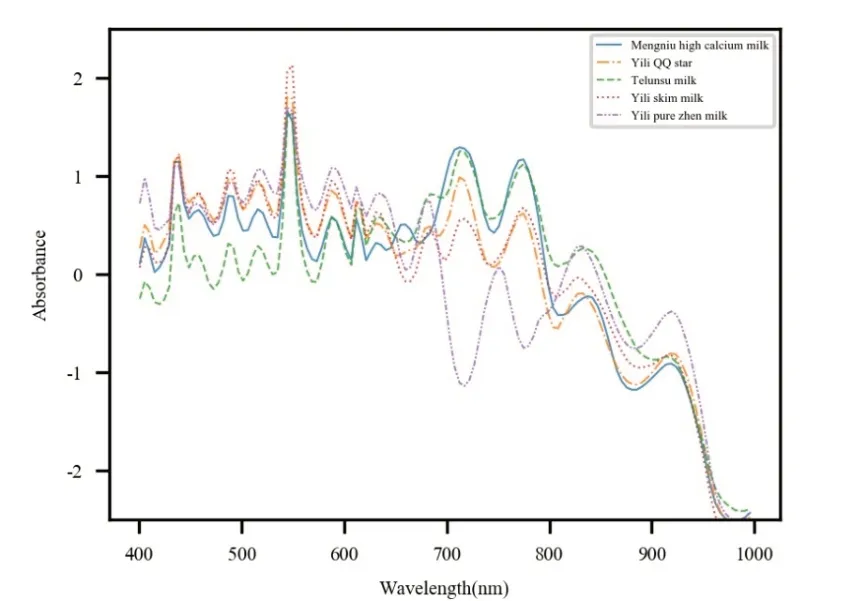
图2 经SNV预处理后的平均光谱图像Fig.2 Average spectral image after SNV preprocessing
2.2 特征选择方法
光谱数据含有大量的冗余信息,需要进行特征选择操作消除冗余信息对试验结果的影响,提高模型的预测精测及效率。SPA常被用于特征波长的选取,其最大的优点是能够消除数据中的冗余信息,使得数据的空间共线性最小化。如图3所示,将经SNV处理后的数据所为输入变量,经过反复迭代投影,最终得到的特征波段有23个。
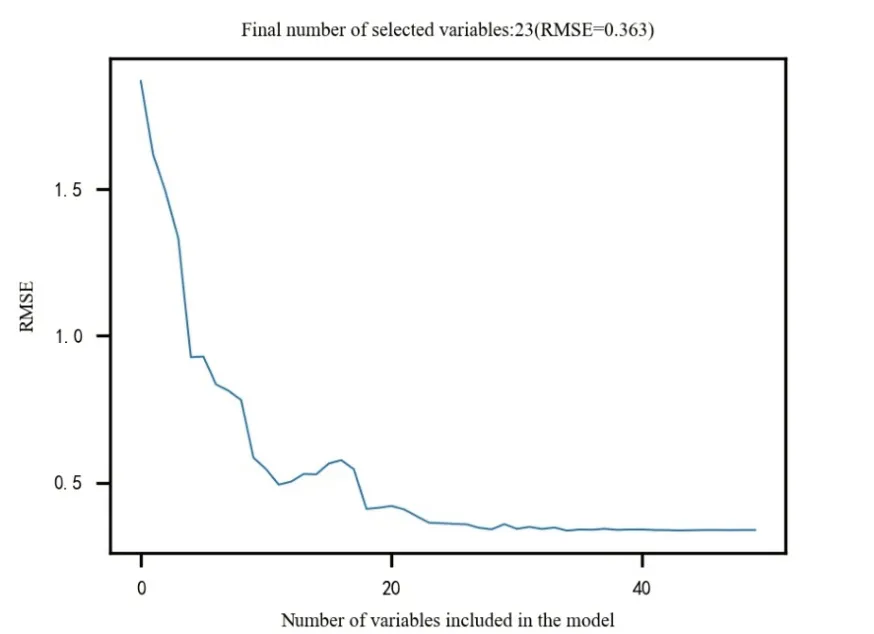
图3 SPA特征选择方法Fig.3 SPA feature selection method
CARS是将蒙特卡洛采样与PLS模型回归系数的特征变量选择方法结合起来。由图4可知,在CARS特征波长选择过程中,随着迭代次数的增加,选择的波段数量在变少。当迭代次数最优时,即交互验证均方根误差(RMSECV)越小迭代次数越好。当 RMSECV值最小时,对应的迭代次数为12。因此,以SNV方法预处理后的数据作为输入,最终选取的特征波长有45个。
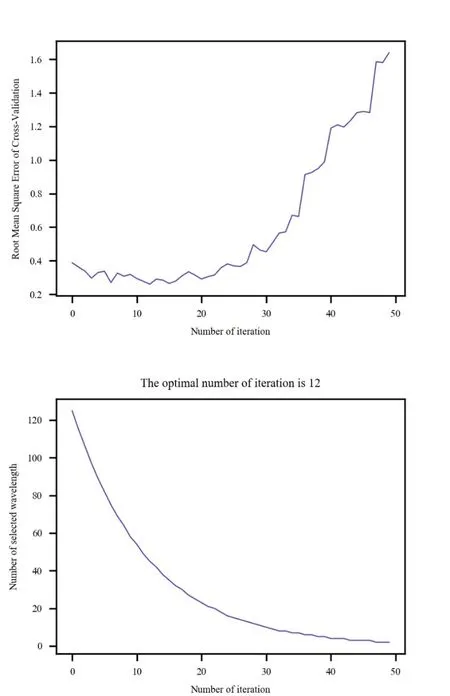
图4 CARS特征选择方法Fig.4 CARS feature selection method
PCA方法是将波段信息进行重组,重组后的波段信息与标签值的联系更紧密。PCA方法筛选出的特征波长与标签值的相关性与最终形成的特征波长个数有很大的联系。通过比较不同的特征波长个数所对应的RMSE值,选取最佳的特征波长数。由图5可见,最佳的特征波长个数为6。
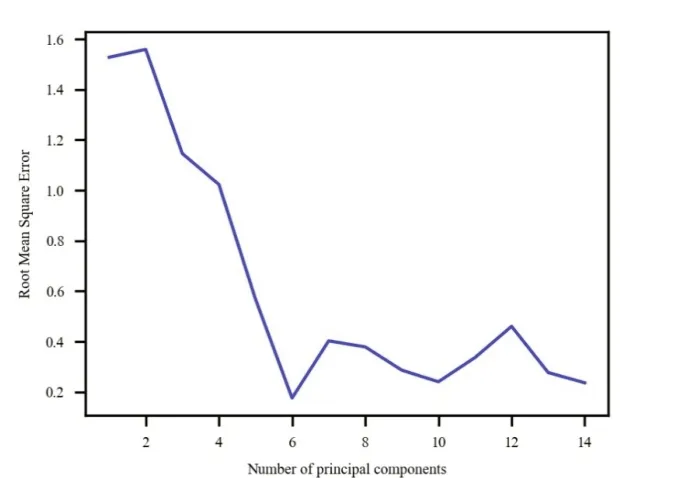
图5 PCA特征选择方法Fig.5 PCA feature selection method
采用3种不同的特征选择方法对数据进行处理,建立支持向量回归机(Support Vector Regres⁃sion ,SVR)模型,通过比较模型的预测精度及运行效率,将3种特征选择方法进行比较(表3)。
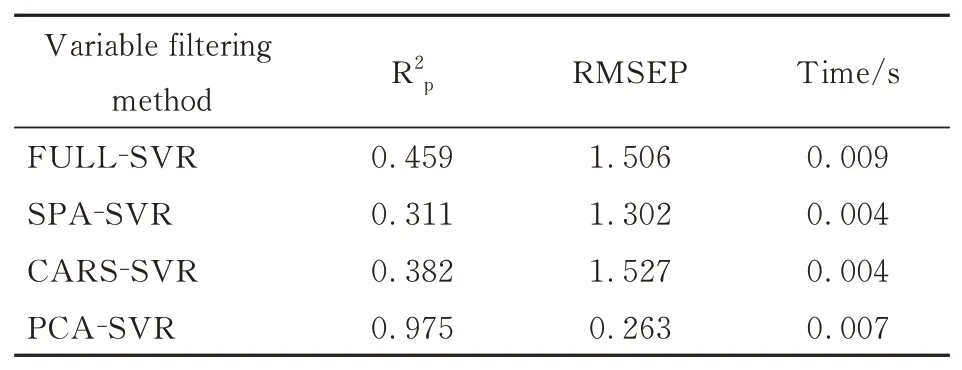
表3 特征选择方法比较Table 3 Comparison of feature selection methods
由表3可见,PCA算法能够有效地消除数据中的冗余信息,减少数据的计算量,从而提高模型的预测精度及效率,其中R2p的值为0.975,RM⁃SEP的值为0.263。故在接下来的建模操作中,采用PCA方法对波段信息进行特征选择。
2.3 建立模型方法
SVR是一种有监督的机器学习方法,包含2个重要的参数—惩罚因子c和核系数g,因此,SVR模型优化的实质是选取合适的参数。为了检验EOBL-AO-SVR模型的预测效果,将其与SVR,GA-SVR、HHO-SVR、AO-SVR模型进行比较,比较结果如表4所示(记录反复试验的最优结果)。

表4 建立模型方法比较Table 4 Comparison of modeling methods
由上表可知,经算法改进后的SVR模型与传统的SVR预测模型相比较,预测精度有了很大的提升,但训练模型所需要的时间有所增加。经AO优化后的SVR模型的预测精度较HHO、GA有所提高,其中模型的评价参数R2p的值为0.983,RM⁃SEP的值为0.058,运行时间4.625 s;经EOBLAO优化的SVR模型较AO优化的SVR模型的预测精度及运行时间都有变好的趋势,其中R2p的值提高了0.002,运行时间降低了0.437 s。
综上所述,利用EOBL改进AO是可行性的,改进后的AO算法具有更好的优化效果。
3 讨论与结论
试验在python环境中开发运行,以牛奶脂肪含量作为分析对象,建立SVR、GA-SVR、HHOSVR,AO-SVR,EOBL-AO-SVR五种不同的模型,分析比较5种模型对牛奶中脂肪含量的预测效果,结论如下:
(1)使用MSC、SNV、MA、SG四种算法对原始光谱数据进行预处理操作,其中SNV预处理后的光谱数据,消除了由乳液不均匀及乳液多少所引起的散射影响,较大的提高了模型的预测精度;
(2)使用 SPA、CARS、PCA 三种算法对牛奶数据进行特征选择操作,其中PCA算法能够有效地消除数据中的冗余信息,减少数据的计算量,从而提高模型的预测精度及效率;
(3)使 用SVR、 GA-SVR、HHO-SVR、AOSVR、EOBL-AO-SVR五种方法对特征选择后的数据进行建模操作。其中利用 EOBL-AO算法优化的SVR模型具有较高的预测精度。当PCA选择的特征波长作为输入变量时,预测集R2的值为0.985,RMSE的值为0.058,相较于其它4个模型,模型的准确率及效率有所提高。
本文为高光谱成像技术快速、无损的检测牛奶脂肪含量提供的一个可行的方法。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
小天使·一年级语数英综合(2021年4期)2021-05-08
小天使·一年级语数英综合(2020年11期)2020-12-16
制导与引信(2017年3期)2017-11-02
电子制作(2017年23期)2017-02-02
作文周刊·小学一年级版(2016年1期)2016-08-12
工业设计(2016年11期)2016-04-16
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
环境科技(2015年6期)2015-11-08
