
沼泽红假单胞菌相似菌株间差异功能模体的筛选和分析
2022-03-03 13:25杨艳北马荆鄂冯育林
江苏农业科学 2022年3期
杨艳北, 许 晶, 马荆鄂, 冯育林, 孙 勇
(1.江西中医药大学博士后流动站/正邦集团有限公司博士后工作站,江西南昌 330000;2.南昌师范学院生物技术研究院/江西省地方鸡种遗传改良重点实验室,江西南昌 330000; 3.南昌师范学院生命科学学院,江西南昌 330000)
沼泽红假单胞菌是光合细菌的代表菌株之一,属于益生菌的一种,广泛作为动物饲料添加剂和水质净化剂使用。在实际应用过程中,沼泽红假单胞菌菌株种类杂,效果不稳定,相似菌株间净水功能差异大。因此,从功能模体水平上,探索沼泽红假单胞菌相似菌株间功能差异的机理,对于沼泽红假单胞菌相似菌株的实际应用具有重要的参考价值。模体也译为基序,是DNA或蛋白质具有的局部保守序列区域,一般也被称为功能模体或结构模体,相当于超二级结构,它是蛋白质的基本结构单位和功能单位,决定着蛋白质的主要功能。蛋白质具有结构域和生物功能位点,功能相近的蛋白质或同类蛋白质家族成员表现出该功能所必需的模体,这个模体不仅反映蛋白质的功能位点,而且也作为蛋白质家族的识别信号。Prosite(https://prosite.expasy.org/)是蛋白质家族和结构域的数据库,在Prosite数据库中,一些有重要生物学意义的氨基酸序列可以被概括成规则的表达式,称作模式,被用于模体的识别,这些模式均具有实验上证实的结构或功能。
Python是一种功能强大的多用途编程语言,可用于生物信息学分析,尤其Biopython为各式各样的生物信息学问题提供Python库。Python有一套自身的语法,使它成为一套可以自行编译、开发的完美语言。Python是一种强大的编程语言,适合脚本编写。本研究以Prosite数据库中下载的用于识别蛋白质组序列模体的模式文件为基础,利用循环遍历算法和Python特有的字典数据格式,编写脚本test.py和difference analysis.py,筛选和分析沼泽红假单胞菌CGA009和YSC3差异功能模体,探索沼泽红假单胞菌相似菌株间功能差异的机理。
1 材料与方法
试验于2021年在南昌师范学院生物技术研究院实验室完成。
1.1 数据来源
试验中沼泽红假单胞菌CGA009和YSC3蛋白质组序列来自于美国国家生物信息中心(NCBI)中已登录的序列,下载文件分别为GCF_000195775.1_ASM19577v1_protein.faa、GCF_013415845.1_ASM1341584v1_protein.faa。试验中用于识别蛋白质组序列模体的模式文件来自于Prosite数据库(https://prosite.expasy.org/),下载文件为prosite. dat。
1.2 研究方法
第1步:在Windows操作系统下安装Python 3.7.0编程软件和geany-1.33文本编辑器。
第2步:打开蛋白质组序列文件GCF_000195775.1_ASM19577v1_protein.faa,内容复制到新的文本文件protein.txt,储存格式为fasta。打开模体文件prosite.dat,内容复制到新的文本文件prosite.txt。将上述3个文件置于同一个文件夹内。创建Python运行脚本,命名为test.py。
第3步:打开蛋白质组序列文件GCF_013415845.1_ASM1341584v1_protein.faa,内容复制到新的文本文件protein.txt,储存格式为fasta。打开模体文件prosite.dat,内容复制到新的文本文件prosite.txt。将上述3个文件置于同一个文件夹内。创建Python运行脚本,命名为test.py。
第4步:Python运行脚本test.py具体代码如下(注意代码缩进,“#”代表代码的注释)。
#导入re模块
import re
#读取功能模体,选取PATTERN模式,存储到新文件中
f = open("prosite_new.txt","a+")
prosite = open("prosite.txt").read()
separator_1 = re.compile(′∥′)
prosite_group = separator_1.split(prosite)
for group in prosite_group:
if "PATTERN" in group:
f.write(str(group))
#读取新文件中模体的登录(AC)号,蛋白名称和序列,存储到字典prosite_dict
prosite_seq = []
name_motif = []
AC = []
with open(′prosite_new.txt′) as file_object:
for line in file_object:
if line.startswith(′DE′):
name_motif.append(line[5:-2])
if line.startswith(′AC′):
AC.append(line[5:-2])
if line.startswith(′PA′):
prosite_seq.append(line[5:-1])
prosite_seq_str = "".join(prosite_seq)
prosite_seq_motif = prosite_seq_str.split(".")
prosite_seq_motif.pop()
prosite_key_list = [(i, j) for i, j in zip(AC, name_motif)]
prosite_dict = {i : j for i, j in zip(prosite_key_list, prosite_seq_motif)}
#读取蛋白质序列,储存到字典protein_dict
protein = open("protein.txt").read()
separator = re.compile(′>′)
protein_group = separator.split(protein)
protein_seq = []
name_protein = []
for group in protein_group:
group_new = group.split(" ")
name_protein.append(group_new[0])
protein_seq.append(group_new[1:])
for i in name_protein:
if i == "":
name_protein.remove(i)
protein_seq_new = []
for i in protein_seq:
j = "".join(i)
protein_seq_new.append(j)
protein_seq_new.pop(0)
protein_dict = {i : j for i, j in zip(name_protein, protein_seq_new)}
f1 = open("检测结果.txt", "a+")
for prosite_dict_key, pattern in prosite_dict.items():
#将Prosite正则表达式转换为Python正则表达式
pattern = pattern.replace(′{′, ′[^′)
pattern = pattern.replace(′}′, ′]′)
pattern = pattern.replace(′(′, ′{′)
pattern = pattern.replace(′)′, ′}′)
pattern = pattern.replace(′-′, '')
pattern = pattern.replace(′x′, ′.′)
pattern = pattern.replace(′>′, ′$′)
pattern = pattern.replace(′<′, ′^′)
pattern_motif = re.compile(pattern)
for protein_dict_key, protein_seq_group in protein_dict.items():
match_all = pattern_motif.findall(str(protein_seq_group))
match_iter = pattern_motif.finditer(str(protein_seq_group))
if match_all:
f1.write(" " + "**************************" + " " )
f1.write("Prosite的AC号和功能模体名称: " +
str(prosite_dict_key) + " ")
f1.write("匹配模式: " + str(pattern) + " ")
f1.write("蛋白质ID号和名称: " + str(protein_dict_key) + " ")
f1.write("蛋白质序列: " + str(protein_seq_group) + " ")
f1.write(" ")
for t in match_iter:
f1.write("蛋白质中的匹配序列:" + str(t.group()) + " ")
f1.write("蛋白质中的起始位置: " + str(t.start()) + " ")
f1.write("蛋白质中的终止位置: " + str(t.end())+ " ")
f1.write(" " + "**************************" + " ")
第5步:将上述软件运行后,获得的2个"检查结果.txt"文件,分别命名为analysis _1.txt、analysis _2.txt。将上述2个文件置于同一个文件夹内。创建Python运行脚本,命名为difference analysis.py。
第6步:Python运行脚本difference analysis.py具体代码如下(注意代码缩进,"#"代表代码的注释)。
#创建文件
f_0_1 = open("1相同2结果.txt","a+")
f_0_2 = open("2相同1结果.txt","a+")
f_1_1 = open("1差异2结果.txt","a+")
f_1_2 = open("2差异1结果.txt","a+")
#读取文件内容
f_2 = open("analysis_1.txt").readlines()
f_3 = open("analysis_2.txt").readlines()
#筛选差异功能模体并储存在新文件中
for line in f_2:
if "Prosite的AC号和功能模体名称:" in line:
if line in f_3:
f_0_1.write(line)
else:
f_1_1.write(line)
for line in f_3:
if "Prosite的AC号和功能模体名称:" in line:
if line in f_2:
f_0_2.write(line)
else:
f_1_2.write(line)
2 结果与分析
2.1 Python脚本运行结果
Python运行脚本test.py后,在2个不同的文件夹内分别自动创建“检测结果.txt”文本文件,运行结果见图1(文件过大,只显示部分运行结果)。输出结果包括:(1)Prosite的AC号和模体名称;(2)匹配模式(Python正则表达式);(3)蛋白质ID号(NCBI)和名称;(4)蛋白质序列;(5)蛋白质中的匹配序列;(6)蛋白质中的起始位置;(7)蛋白质中的终止位置。Python运行脚本difference analysis.py后,自动创建含有分析结果的新文件(1相同2结果.txt、2相同1结果.txt、1差异2结果.txt、2差异1结果.txt),见图2。输出结果包括 Prosite的AC号和模体名称。


2.2 沼泽红假单胞菌CGA009和YSC3差异功能模体分析
沼泽红假单胞菌CGA009与YSC3比较,独有14种功能模体。沼泽红假单胞菌YSC3与CGA009比较,独有5种功能模体见表1。
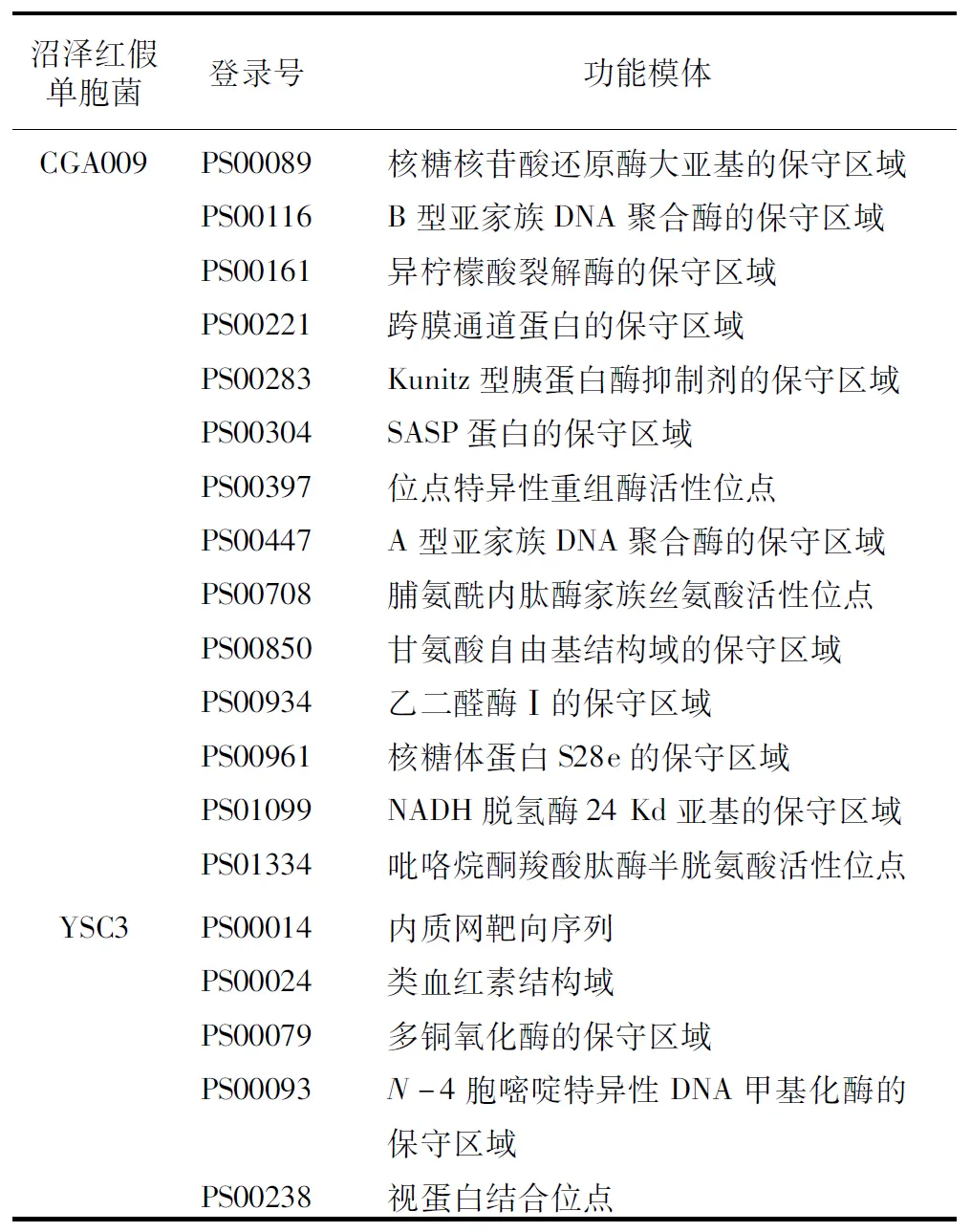
表1 沼泽红假单胞菌CGA009和YSC3差异功能模体
3 讨论与结论
本研究编写的Python脚本不仅适用于沼泽红假单胞菌的研究,也广泛适用于细菌、真菌、动物、植物等所有物种,用于筛选相似物种间的差异功能模体,探索相似物种间功能差异的机理。
沼泽红假单胞菌CGA009与YSC3比较,独有14种功能模体。核糖核苷酸还原酶是DNA 合成和修复的关键酶和限速酶,对细胞的增殖和分化起着调控作用,在几乎所有生物生长和繁殖的生命活动中起着非常重要的作用。DNA聚合酶是催化DNA精确复制的关键酶。异柠檬酸裂解酶是乙醛酸支路代谢中的关键酶,催化异柠檬酸转化为琥珀酸和乙醛酸,乙醛酸支路是三羧酸循环的替代支路。跨膜通道蛋白是横跨质膜的亲水性通道,允许适当大小的离子顺浓度梯度通过,包括离子通道、孔蛋白、水孔蛋白等。胰蛋白酶抑制剂是对胰蛋白酶具有抑制作用的一类物质,在动物、植物和微生物中都有发现,在微生物中,胰蛋白酶抑制剂主要来源于酵母菌、链霉菌属等。胰蛋白酶抑制剂属于丝氨酸蛋白酶抑制剂家族,其分子的活性部位是赖氨酸,主要与胰蛋白酶等酶的丝氨酸结合,使其失活,起到抑制作用。SASP蛋白与双链DNA结合后,导致DNA构象变化,保护DNA骨架结构免受化学试剂或酶的裂解,使DNA对紫外线具有高抗性。位点特异性重组在原核生物DNA重排中起着重要作用。位点特异性重组中,DNA节段的相对位置发生移动,从而使DNA序列发生重排。脯氨酰内肽酶广泛存在于动物、植物和微生物体内。脯氨酸内肽酶是一类能够特异性水解多肽链中脯氨酸残基羧基端的内切酶,是丝氨酸蛋白酶家族成员之一,其能有效降解小于30个含有脯氨酸残基的多肽链,脯氨酸内肽酶能特异性地水解许多含脯氨酸的多肽类神经递质和激素。甘氨酰自由基酶共享以甘氨酸为中心的保守区域,参与多种功能,例如核苷酸、丙酮酸和甲苯的代谢等。乙二醛酶Ⅰ(又称乳酰谷胱甘肽裂解酶)催化乙二醛途径的第一步,即催化甲基乙二醛和谷胱甘肽转化为- 乳酰谷胱甘肽,然后再由乙二醛酶Ⅱ将底物- 乳酰谷胱甘肽转化为乳酸。乙二醛酶Ⅰ是普遍存在的一种酶,序列很保守。甲基乙二醛破坏细胞平衡,具有毒性,乙二醛酶系统能够清除过量的甲基乙二醛,维持细胞内的动态平衡。核糖体蛋白参与细胞内蛋白质合成。NADH脱氢酶参与呼吸链反应。吡咯烷酮羧酸肽酶(又称焦谷氨酰胺基肽酶)是从蛋白质的-末端去除焦谷胺酸的酶,存在于细菌和古细菌中。沼泽红假单胞菌CGA009独有的14种功能模体,功能主要集中在:(1)DNA 复制、合成、修复、重排和保护;(2)蛋白质合成;(3)呼吸链的电子转移;(4)细胞的增殖和分化;(5)生长和繁殖;(6)代谢途径的补充;(7)离子运输;(8)清除毒性物质甲基乙二醛。
沼泽红假单胞菌YSC3与CGA009比较,独有5种功能模体。内质网靶向序列是存在于内质网蛋白上的非常保守的靶向序列。类血红素结构域能与多种分子和蛋白质结合。多铜氧化酶含有多个铜结合中心,催化有机底物使其氧化,参与微生物对重金属铜的抗性,降解多种生物胺的活性。DNA甲基化酶识别DNA的特定序列,并使该序列中的胞嘧啶甲基化,保护细胞自身的DNA不被限制性内切酶破坏。视蛋白是一种膜蛋白,有7个跨膜区,属于G蛋白偶联受体超家族。视蛋白广泛分布于动物和微生物中,是一种重要的感光物质,具有调节生物节律和光周期等多种功能。沼泽红假单胞菌YSC3独有的5种功能模体,功能主要集中在:(1)对重金属铜的抗性;(2)降解生物胺;(3)调节生物节律和光周期。
沼泽红假单胞菌CGA009对紫外线和化学试剂具有抵抗能力,DNA骨架结构更稳定,生长和繁殖性能更强。沼泽红假单胞菌YSC3,对光照反应更加敏感,对重金属铜具有抵抗能力,能够降解生物胺,生存能力更强。本研究编写的Python脚本,用于筛选相似物种间差异功能模体,探索相似物种间功能差异的机理,该脚本适用于所有物种。
猜你喜欢
中国环境科学(2023年10期)2023-10-26
林产工业(2022年10期)2022-10-30
云南化工(2021年8期)2021-12-21
计算机与现代化(2021年5期)2021-05-27
闽南师范大学学报(自然科学版)(2020年2期)2020-07-06
智能计算机与应用(2019年1期)2019-01-11
下一代英才(酷炫少年)(2017年9期)2017-11-27
复杂系统与复杂性科学(2017年4期)2017-07-07
剑南文学(2016年11期)2016-08-22
自动化学报(2016年5期)2016-04-16
