
基于CVGAE的无监督跨领域学习先决条件链挖掘
2022-03-02 06:15:54徐国兰
现代计算机 2022年23期
徐国兰
(山东理工大学图书馆,淄博 255049)
0 引言
随着通信技术的飞速发展,在线教育资源呈指数增长,人们需要一种快速有效的方式来掌握新知识。构建概念图可以帮助人们满足这种需要。在大多数学科中,概念是知识的基本单位,而概念与概念之间存在一种先决条件关系。比如,数学领域中的极限和导数,如果没有极限的知识,学生会难以理解导数的概念,极限就是导数的先决条件概念。所以获取概念之间的先决条件关系有助于规划学习路径,从而提高学习效率。有些领域的概念先决条件关系已由专家学者手工标注,但是还有更多的领域没有进行标注。对每个领域的概念先决条件关系进行手工标注费时费力,不切实际,因此需要我们使用深度学习方法,进行跨领域的先序关系挖掘,即将概念先决条件关系从熟悉的领域(源领域)迁移到要学习的领域(目标领域)。概念先决条件链挖掘对于智能辅导系统、课程规划、学习材料生成与书目推荐等基于人工智能的教育具有很高的应用价值。本文的贡献有:①自建了一个任务数据集ConceptsData;②构建了一个无监督跨领域变分图自编码器(CVGAE)。在CVGAE模型中引入了对抗训练机制,可以较好地实现概念先决条件关系的跨领域迁移。大量实验证明,本模型在跨领域概念先决条件链挖掘上取得了很好的效果,达到了当前最好结果。
1 相关研究综述
单领域的概念先决条件挖掘有很多研究,目前已经探索了不同类型的学习材料中概念之间的先决关系,包括维基百科、MOOC、教科书和科学语料库等。通常,从不同的学习资源中提取概念对的特征,然后将这些特征输入到机器学习模型中进行学习,从而确定概念对是否具有先决条件关系。例如,Pan等[1]定义了7个来自MOOC的概念对特征,并分别使用SVM、朴素贝叶斯、逻辑回归和随机森林四种分类器来预测概念对的先决条件关系。先决条件关系预测的质量高度依赖于使用的学习资源和人工标注的特征。
最近,表示学习模型和神经网络已应用于先决条件学习任务。例如,Roy等[2]提出了一种成对潜在狄利克雷卷积(Pairwise LDA)模型和孪生网络的方法PREREQ,它从MOOC播放列表中学习概念的潜在表示,然后将其用于先决条件预测。Li等[3]提出了一种用于无监督先决条件学习的R-VGAE模型。
相对于单领域,跨领域的先决条件链挖掘研究得较少。Li等[4]提出的跨领域变分图自编码器(CD-VGAE)应用于跨领域先决条件的迁移和推断,这项研究在开发教育资源、智能搜索引擎等方面具有很高的应用价值。但是,CDVGAE是在一个复杂的图上训练的,该图包含来自源领域和目标领域资源节点和概念节点,其可扩展性受到了很大的限制。在实践中,应用图神经网络难以将这些模型扩展到大图的场景。如果设计一个模型在只包含概念节点的图上进行训练,那么这个模型会比CD-VGAE小得多,并且能达到更实用的效果。
对抗学习方法[5]经常应用于涉及多语言或多领域场景的NLP任务。这种方法通常会向神经网络引入域损失,以便学习到领域无关的特征。但是,在图上训练对抗网络的研究较少,只有一个对抗正则化变分图自编码器(ARVGA)模型[6],它通过重构图结构来学习鲁棒的图嵌入表示。在本文中,我们设计了一个领域对抗变分图自编码器进行无监督的跨领域概念先决条件挖掘。
2 数据集和任务定义
本研究自建了一个数据集ConceptsData。ConceptsData由讲座幻灯片、概念与概念之间的先决条件关系构成。数据集主要包含两个领域:自然语言处理(NLP)和计算机视觉(CV)。对于每个领域,我们从MOOC和B站中找出高质量的讲座幻灯片,选出领域相关的关键概念,然后标注概念的先决条件关系,具体统计数据见表1。在NLP领域中共收集了1365张幻灯片和283个概念,手动标注先决条件关系1457个;以相同的数据格式得到193个CV概念,816个先决条件关系。实验时,我们将NLP作为源领域,CV作为目标领域。

表1 NLP和CV领域的统计数据单位:个
将跨领域概念先决条件挖掘定义为二元分类问题。给定一个源领域和一个目标领域,每个领域中有许多概念对(m,n)。如果概念m是概念n的先决条件,则概念对标签为1,否则为0。在模型训练过程中,源领域的标签是已知的,目标领域的标签是未知的。
3 构建CVGAE模型
3.1 构建跨领域概念图
首先构建一个跨领域概念图G=(X,A),作为模型的输入。其中,X是节点特征集,A是邻接矩阵,表示概念对之间是否存在先决条件关系。如果概念m是概念n的先决条件概念,那么定义Am,n=1。为了获得X,我们将数据集ConceptsData中每个幻灯片文件按页拆分成若干文档,并对每个概念的所有出现位置进行标记。在文档集合上训练BERT模型[7],对文本进行编码。对于每一个概念,找到其所有标记,将这些标记的嵌入表示平均,得到概念的特征表示。
对每个领域分别建立概念图,即:Gs(源领域图)和Gt(目标领域图)。每个图中只包含属于该领域的概念。在Gs中,邻接矩阵包含两种类型的边:人工标注的先决条件关系和使用余弦相似度计算概念之间嵌入表示得到的边。而在Gt中,邻接矩阵只包含使用余弦相似度计算得到的边。在无监督的先决条件学习中,我们的任务是补全Gt的邻接矩阵。
3.2 引入并优化VGAE模型
用于无监督跨领域学习先决条件链挖掘的对抗变分图自编码器(CVGAE),模型架构如图1所示。

图1 CVGAE模型
跨领域编码器VGAE模型[8]包含一个图神经网络(GCN)编码器[9]和一个内积解码器。在GCN中,下一层节点的潜在表示只使用直接邻居和节点本身的信息来计算。
VGAE的损失定义为其中第一项表示重构损失,第二项表示VGAE学习出的潜在表示H与正态分布之间的KL散度。图神经网络GCN编码器可以用图注意力网络(GAT)[10]替换。
领域对抗训练是一种领域适应学习表示的方法,之前很少应用于图。为了强制VGAE编码器学习概念节点的域不变特征,可以添加领域判别器模块来预测潜在表示H中的每个节点属于源领域还是目标领域。使用两层神经网络来预测领域标签:如果节点来自源领域,则为1,否则为0。因此,领域判别器损失Ld被定义为领域预测的交叉熵损失。模型的总损失为
在图的层面上训练模型。每一轮训练,随机选取一个领域的图作为输入。
3.3 先决条件预测
一般情况下,先决条件是不对称的,所以不适合使用内积解码器。我们可以使用图解码器DistMult[11]来预测概念对(m,n)之间是否存在链接。具体来说,通过学习一个可训练的权重矩阵W来重构邻接矩阵̂,使得̂=HrWH。最后,用Sigmoid函数来确定补全后的邻接矩阵m,n。
4 实验
为了有效地评估模型CVGAE,与两类基准模型进行对比:无监督基准模型和具有额外资源节点的基准模型。在自建的语料库Concepts-Data上进行评估,NLP为有标注数据的源领域,而CV为没有标注数据的目标领域。对数据进行拆分,将数据集中人工标注的先决条件关系随机分为训练、验证和测试三个集合,其比例为7∶2∶1。为了解决数据不平衡的问题,随机抽取不具有先决条件关系的概念对作为负例使得训练集中的正负关系数量相同。
4.1 无监督基准模型
用机器学习分类器(CLS)和图嵌入(Graph-SAGE)方法建立无监督基准模型。首先在我们的语料库上预训练BERT,得到每个概念的嵌入表示。然后采用三种方法预测先决条件关系:①机器学习分类器法,把概念对的嵌入表示拼接起来,并输入到机器学习分类器中进行训练。在源领域上训练分类器,在目标域上进行预测。②图嵌入法,训练GraphSAGE[12]生成节点嵌入,并使用DistMult解码。模型输入包括源领域和目标领域概念的BERT嵌入,以及由源领域人工标注的先决条件关系和所有领域概念嵌入的余弦相似度值构建的邻接矩阵。③变分图自编码器(VGAE),使用VGAE模型预测概念对关系。所有基准模型都是在NLP领域上进行训练并直接应用于目标领域,因此称它们为无监督基准模型。
4.2 具有附加资源节点的基准模型
采用Li等[4]提出的跨领域变分图自编码器CD-VGAE模型,通过优化的VGAE预测目标领域先决条件关系。因为CD-VGAE模型是在附加了资源节点的跨领域概念图上进行训练的,所以要在构建的概念图G=(X,A)上附加资源节点,构建一个跨领域资源-概念图G'=(X,A)。在节点特征集X中加入资源节点,在邻接矩阵A中增加两条边Arc(所有资源节点和概念节点之间的边)和Ar(仅资源节点之间的边)。
4.3 跨领域概念图
分别使用GCN和GAT作为VGAE的编码器进行实验。此外,为了验证对抗学习机制的有效性,还进行了去除对抗学习的实验。
4.4 评估结果说明
随机选取五个随机种子对数据集进行分割,然后将每次实验的结果平均。实验结果见表2。实验结果表明跨领域概念图模型的F1值高于无监督基准模型的最好结果。并且,在跨领域概念图模型中,使用GCN作为编码器的CVGAE模型取得了最好的结果。
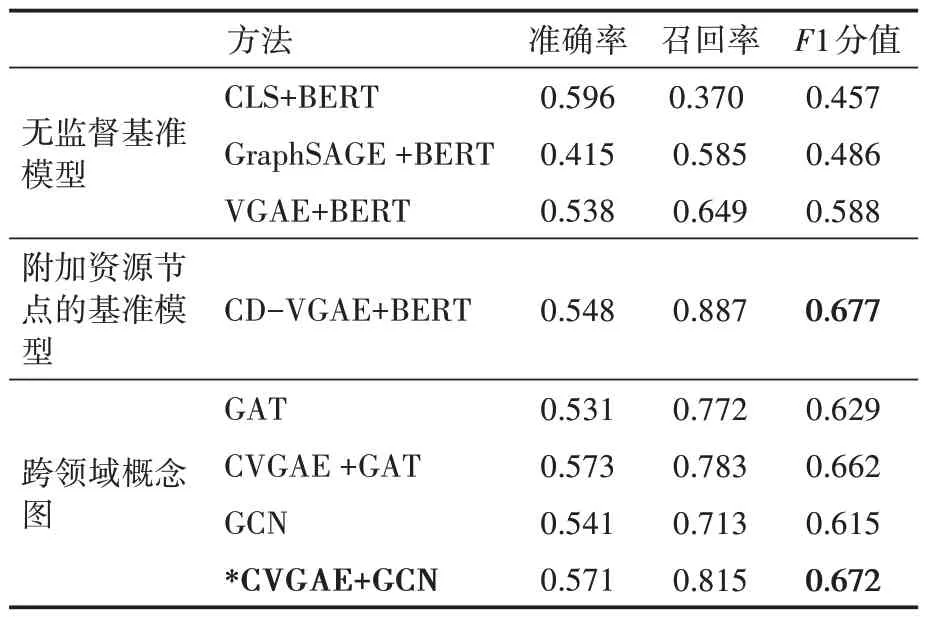
表2 在目标领域CV上的评估结果
虽然附加了资源节点的基准模型的F1值稍高一些,但也正因为附加了资源节点,导致训练的图规模非常大,而且训练时间比较长,其可扩展性较差。图规模和计算时间数据见表3。本实验中,CVGAE模型是在一个有283个节点的图上训练的,而CD-VGAE构建一个有1421个节点的大图。在最好的情况下,CVGAE只需要CD-VGAE 20%的图规模和35%的训练时间。
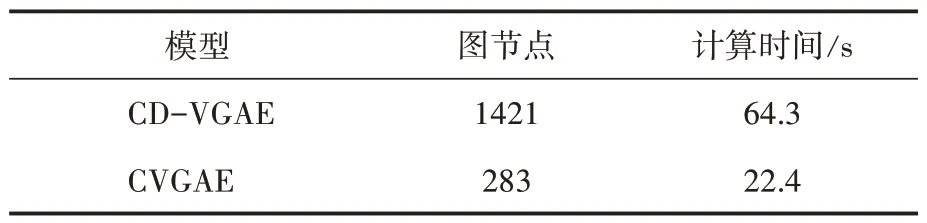
表3 图规模和计算时间的比较
5 分析
本节在选定的领域对模型进行定量分析和案例分析,验证模型预测出的先决条件。
5.1 定量分析
将CVGAE的预测结果与另一个基准模型(CLS+BERT)的预测结果及真实数据进行比较。CVGAE预测了893个先决条件,而基准模型预测了475个,真实数据中有719个。一般来说,CVGAE比选定的基准模型具有更高的召回率。虽然高召回率会让人们多学习一些额外的概念,但至少不会漏掉那些满足先决条件的概念。
5.2 案例分析
在经过CVGAE补全后的概念图中,我们观察到有几个概念对被多条路径覆盖,真实数据图中也存在这种现象。当图中存在循环时,就很难找到所有可能的先决条件路径,因此,随机选取几条路径进行案例分析。
CV领域中,在真实数据图中随机选取的每一条路径通常都含有5~10个概念。我们的模型预测出了更多的先决条件,因此补全的概念图往往有更多或更长的路径。对真实数据概念图和通过模型补全的图中的路径进行比较。例如:概念object recognition→autonomous driving的先决条件链,在真实数据中有一条很长的路径,但CVGAE预测了一条较短的路径,这说明还可能存在另外一条更简洁的学习路径。而在R-CNN→Faster R-CNN的路径中,真实数据图中有5条路径,路径的平均长度为6,而在CVGAE预测图中找到了7条路径,平均长度为9.21,这次CVGAE预测了比真实数据图更多的概念。
6 结语
本文提出的CVGAE模型可以有效地解决跨领域学习中概念先决条件链挖掘问题,相较于在概念图上训练的无监督基准模型和在概念-资源图上训练的基准模型,该模型无论在精度还是时空复杂度上都具有非常明显的优势。
猜你喜欢
作文成功之路·小学版(2020年5期)2020-06-11 12:48:42
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
生态文明新时代(2018年1期)2018-03-21 05:17:00
电子设计工程(2017年20期)2017-02-10 03:39:29
戏剧之家(2016年6期)2016-04-16 12:42:25
新课程研究(2016年21期)2016-02-28 19:28:28
电子器件(2015年5期)2015-12-29 08:42:24
海南热带海洋学院学报(2014年2期)2014-08-08 12:49:48
电测与仪表(2014年13期)2014-04-04 12:04:18
中学生物学(2008年6期)2008-08-29 09:23:38
