
基于分数阶网络和强化学习的图像实例分割模型
2022-03-01 12:34李学明吴国豪周尚波林晓然谢洪斌
计算机应用 2022年2期
李学明,吴国豪,周尚波,林晓然,谢洪斌
(1.重庆大学计算机学院,重庆 400044;2.河北经贸大学信息技术学院,石家庄 050061;3.外生成矿与矿山环境重庆市重点实验室(重庆地质矿产研究院),重庆 400042)
0 引言
近十余年,图像实例分割[1-2]问题一直是计算机视觉领域的研究重点和热点,目的是使用紧密边界框覆盖图像中目标物体所包含的像素点。国内外许多研究者针对这个领域进行了研究,提出了许多有效的实例分割方法,这些方法基本都是模拟人眼视觉神经系统对图像信息的处理过程,一种是基于“自上而下”的注意力机制[3-4],先定位目标物体的位置再对轮廓曲线进行精准分割;另一种是基于“自下而上”的注意力机制[5],将属于同一目标物体的像素点按照某种相似性逐渐聚合在一起。本文通过非线性理论和深度强化学习(Deep Reinforcement Learning,DRL)的起源[6]——人脑中海马体研究的启发,认为应当将这两种注意力方式结合在一起模拟视觉神经系统的信息获取和处理方式,首先人眼瞬间观测到的外界环境必定为非线性复杂区域而非像素点,即先看到目标物体的大致轮廓,这是一个“自下而上”的过程,本文称之为初始阶段;在看清轮廓后,仔细观察过程中,会边观察边根据以往的经验判断看到的某一部分是否属于该物体,即精细化细节部分,这是一个“自上而下”的过程,本文称之为第二阶段。因此,为了建立完整的图像信息接收和处理过程,以及针对以往非线性图像特征建模较少的问题,本文提出了一种联合分数阶非线性系统和强化学习(Reinforcement Learning,RL)的全新图像实例分割模型。
具体来说,在初始阶段,通过分数阶非线性系统中混沌同步和混沌吸引子的方法,对图像进行初步分割,完成视觉系统中接收图像特征并“看清轮廓”的过程。混沌同步[7-8]现象普遍存在于猴子、小鼠、猫和人类的大脑中,而且利用同步现象进行特征绑定和图像分割[9-10]可以有效降低模型复杂度。另外,混沌理论中认为,大多数系统在经历过一系列迭代过程后会达到某种稳定状态,即混沌吸引子[11],可以用来表征本文提出的图像初步分割结果。
在第二阶段,将第一阶段获取到的特征和混沌吸引子作为先验知识,为强化学习的DQN(Deep Q-learning Network)提供指导性策略:先将agent 的注意力聚集在混沌吸引子附近,之后使用agent 的探索策略模拟观察过程,一点点完善物体边界处的细节信息,达到精细化的效果。因为视觉神经系统对图像数据的处理是一个固定的顺序变化过程,人脑在视网膜细胞捕获到物体形状、颜色等整体信息后,会快速地根据大脑中存储的经验对物体进行判别,随后再注意到更加细节的地方,这是一个连续决策过程。为了最终建立一个健壮的决策过程,本文设计了符合本文提出的视觉神经系统机制的动作-状态表示、奖励函数和策略。
1 相关工作
1.1 分数阶导数及其应用
分数阶微积分算子是整数阶算子的扩展。在本文中,通过GL(Grunwald-Letnikov)定义[12]建立了分数阶弛豫系统。GL 的定义可以描述为:

式(1)可以改写为:

其中:q1 和h分别是系统的分数阶阶数和时间步长。
就其应用而言,当前图像处理技术中的图像增强[13]和图像降噪[14]已相对成熟,而图像分割技术仍处于发展阶段,几乎没有性能非常好的基准模型。其中,最初的图像分割模型是Wang 等[15]提出的LEGION(Locally Excitatory Globally Inhibitory Oscillator Network)模型,其中要分割的目标由与时间相关性和空间分布相关的振荡器表示(称为“振荡相关性”机制)。在此基础上,Zhao 等[9-10,16-17]提出了一系列场景分割模型。具体来说,文献[9-10,16]是基于分数阶网络和“振荡相关”机制的单层模型。文献[17]是一个双层模型,该模型结合了深度学习中的特征图以提取图像中像素的基本特征,并添加了基于分时同步的注意力机制,即第二层的中央控制单元在不同时间段内与具有不同特征的像素进行同步。在另外几项研究[18-19]中,模型是两层的,其中模型的第一层类似于文献[15]。然而,Qiao 等[18]提出的是基于共振频率的视觉选择注意力机制。在Lin 等[19]的模型中,模型的第二层是中央控制单元,通过分时相位同步来模拟大脑皮层神经元,以在第一层的不同目标间实现视觉注意力选择和转移。
1.2 强化学习
在强化学习中,使用agent 评估特定状态下某些动作对最终结果的影响,以此来对顺序决策问题进行优化。Mnih等[6]应用深度神经网络作为函数逼近器来估计强化学习的动作-值函数,从而得出深度强化学习方法。之后,提出了一系列方法[20]来辅助改进DRL,例如内存重播[6]和策略梯度[21]等。
最近,有一些成功将DRL 方法应用于计算机视觉任务的尝试。Caicedo 等[22]将整张图像视为一个环境,agent 根据学习的策略对边界框执行一系列变形操作,从而检测目标对象。Kong 等[23]针对图像中出现的不同目标,提出了一种基于协同深度强化学习的联合搜索算法,将每个检测器视为一个agent,然后利用多agent 深度强化学习算法来学习目标物定位的最优策略。Choi 等[24]提出了一种基于模板选择策略的深度强化学习跟踪算法。该跟踪算法构建了一个匹配网络和一个策略网络,其中,匹配网络用来生成当前视频帧中每个候选目标外观模板的预测热度图,策略网络根据强化学习的思想学习如何从预测热度图中决策出最佳目标外观模板,从而实现跟踪任务。这些模型都是与目前非常流行的深度学习相结合,而本文尝试将强化学习与分数阶网络结合来解决目标实例分割问题。
2 本文方法
2.1 整体架构
本文提出了一个针对某一特定类的自适应性模型来了解并分割图像中的目标实例。该模型遵循邻居搜索策略,该策略在选择初始像素点后,搜索初始像素点的相邻像素并比较彼此之间的相似性。详细流程如下:首先利用分数阶网络进行初步的图像分割,得到的图像分割结果,即混沌吸引子可以为后续的强化学习提供指导;然后使用强化学习对分数阶同步网络分割结果进行学习和分析,以了解像素之间的相似性和耦合力;然后根据搜索策略,agent 选择下一个像素和最佳动作;最后,agent 耦合属于同一目标实例的像素点。为了激发提出的agent 的注意力,本文设计了奖励函数来评估当前已耦合像素点与GT(Ground Truth)之间的相似度。为了提高模型的适应性,本文进一步设计了一种新颖的探索方法,以加快最佳状态-动作对的选择。
2.2 分数阶网络
本文的工作建立在采用混沌相同步方法进行图像分割的分数阶网络的基础上。详细过程如下:首先,给定输入图像,将图像转化为一个由混沌Rössler 振子耦合而成的二维网络,网络中每个振子代表图像的一个像素,并从其相应的像素接收输入。耦合系统如下:
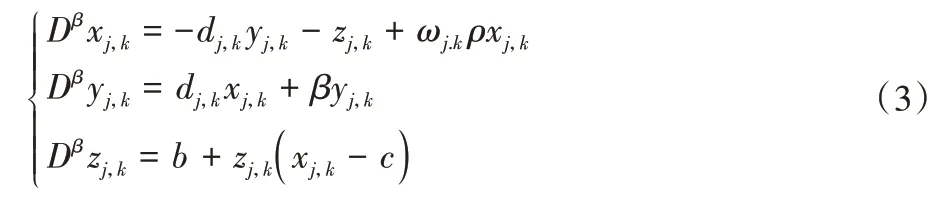
其中:ω和d分别是系统的耦合力和该振子对应的频率。本文中dj,k是在[0.98,0.99]区间的任意值。混沌系统的相位同步状态受耦合力的影响,不同耦合力随时间变化对相位方差S的影响如图1 所示。随着耦合力的增加,耦合振子的相位趋于一致,当耦合力ω=0.09 时相位方差最小。因此,之后的实验中,耦合力的取值都为0.09。在分数阶网络中,代表相同对象的振荡器之间的相位在一定的时间t范围内往往相同,而不同对象之间的振荡器则完全不同,这是分数阶网络进行图像分割的基础。
(j,k)表示振子所在的二维平面的j行和k列。ρxj,k指像素之间的耦合项,每个像素将选择其8 个相邻像素点进行耦合,如下所示:
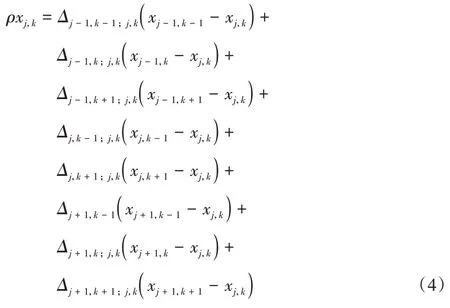
其中:如果振子(j,k)与振子(p,q)相耦合,则Δj,k;p,q=1;否则为0。
dj,k是像素(j,k)的对比度,它由∇d决定,而∇d取决于图像本身和Cj,k,如下所示:

其中:l为特征的总量;是像素点(j,k)特征值所选用特征l的平均值。本文在实验过程中使用了四个特征,Fg、FR、FG和FB,对应每个像素点的灰度(g)和RGB 值。四个特征的权重分别为1/2、1/6、1/6 和1/6。耦合力的计算方式如下:
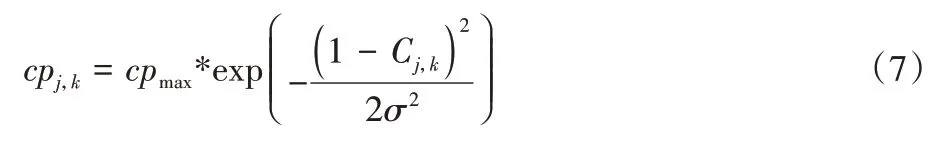
其中:cpmax即是前文提到的最大耦合力,图像中像素之间的相似度越高,振荡器之间的耦合力就越大,图1 中显示了不同耦合力导致的振荡器的相位方差不同;而只有耦合力超过研究中设置的耦合阈值,才认为这两个像素点属于同一个目标物体。σ对于不同类别的图像具有不同的值。
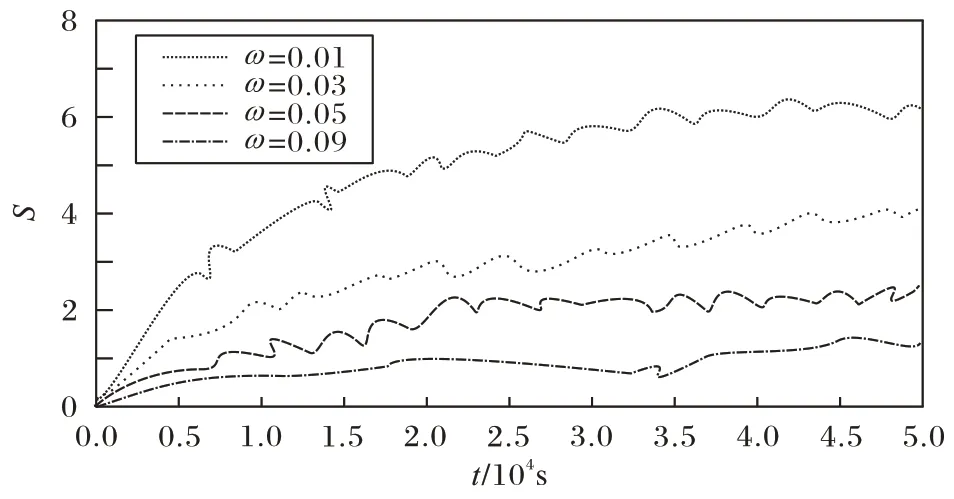
图1 不同耦合力的相位方差Fig.1 Phase variance of different coupling force
整个图像分割过程如下所示:

2.3 强化学习
本文考虑建立一个标准的马尔可夫决策过程[25],agent在连续的时间步t内与环境E进行交互,每个时间步t内都会获得对环境的观测xt,动作at并接受到一个奖励Rt。通常来说,agent 只能观测到环境的一部分,所以记录的状态-动作历史为st=(x1,a1,x2,a2,…,at-1,xt)来描述状态。本文假定环境都是可观测的,所以st=xt。策略π定义了agent 的动作集A,该策略计算状态-动作集π:S→P(A)上的概率分布。环境E也可能是随机的。本文将其建模为具有状态集合S,动作空间A=IRN,初始状态分布p(s1),动态的转换过程p(st+1|st,at)和奖励函数Rt(st,at)的马尔可夫决策过程(Markov Decision Process,MDP)。
2.3.1 Action
动作集A包含四个主要元素:
方向:agent 可以在四个方向上选择一个相邻像素,已选择过的像素点不会重复选择。
耦合力:agent 将所选相邻像素的特征与初始像素进行比较以计算相似度,然后根据相似度确定耦合力。
耦合状态:agent 将耦合力与给定阈值进行比较。如果耦合力大于阈值,则将相邻像素存储到耦合像素列表中;否则,不会。
终止动作:终止当前搜索序列,并在下一个初始像素处重新开始搜索新实例。
2.3.2 State
状态集合S可能会非常大,因为它包括来自大量图像的任意像素以及在这些像素采取的所有动作组合,因此,泛化对于设计有效的状态表示很重要,所以考虑将状态设计为元组(f,h,cl),其中:f代表观察到的像素的特征向量;h代表历史动作的二进制向量;cl代表已耦合像素列表。
特征向量f从之前的分数阶混沌同步网络中获取。h表示经常使用的动作,每个动作均由7 维二进制矢量表示,其中除与所采取的动作对应的值为1 外,所有值均为0。尽管h的维数很低,但它也足以说明过去发生的情况。将h和cl放在同一元组中的原因是,可以通过观察agent 和已耦合像素(即形成吸引子的过程)所形成的轨迹来获得图像的区域结构信息。
分数阶网络的输出与动作历史向量和耦合的像素列表连接在一起,以完成状态表示,并由DQN 中的Q-learning 网络处理来输出动作值。
2.3.3 Reward
为了解决稀疏奖励的问题[26],本文将奖励函数分为两类:即时奖励和最终奖励。即时奖励使用相似度sim来衡量从一个状态转换到另一个状态后对整体效果的改善。因为本文将视觉实例分割分为了两个阶段,所以不同的阶段会有不同的策略和奖励函数。在初始阶段,agent 每20 步得到一次奖励。在第二阶段,agent 的每一步都会获得即时奖励。实验过程中,只需在训练中评估奖励函数,因为图像需要手动标记为ground truth 情况。
假设p是当前耦合像素的列表,而g是目标实例的ground truth。将p和g之间的sim定义为:
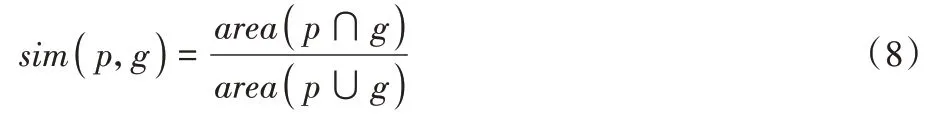
而即时奖励函数的设置如下:

式(9)表示如果sim在状态之间得到改善,则奖励为正,否则为负,并且本文采用“鼓励好结果”的奖励设定原则,即相似度越高,奖励越大。奖励功能适用于动作集A中的任何动作。这有效地提高了训练及测试数据集中的准确性。
当终止条件触发时,此时应该计算最终的奖励。最终奖励具有不同类型的方案,这取决于最终耦合像素列表与ground truth 之间的相似性。因此,最终奖励函数被设置为阈值函数,如下所示:

其中:T是终止点。使用相似度的平方可以扩大良好行为的奖励与不良行为的惩罚之间的差异,从而有助于提高强化学习agent 的训练速度。
2.4 训练分割agent
模型的体系结构如图2 所示。agent 的目标是通过选择动作来耦合像素,以最大限度地提高与环境交互过程中获得的奖励总和。核心问题是找到指导agent 的决策过程的策略。策略是函数π(s,a),用于选择当前状态为s时要选择的动作a。因为本文首先使用了分数阶网络来对图像进行了初步分割,在此基础上将整个强化学习过程分为两个阶段:初始阶段和第二阶段,由于本文方法采用的是像素级分割,因此在两个阶段中采用了不同的像素-动作策略。
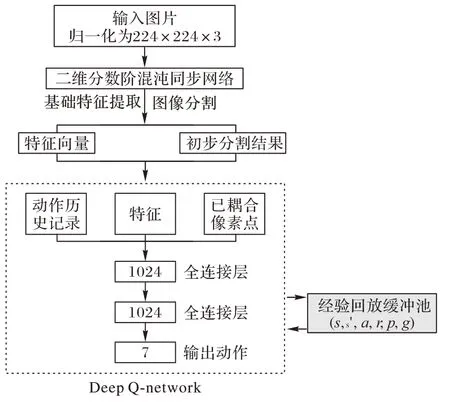
图2 模型体系架构Fig.2 Model architecture
2.4.1 初始阶段
在初始阶段,agent 的探索行动不是随机的。取而代之的是,根据强化学习中学徒式学习[27]的原则,使用具有指导性的探索策略对agent 的动作作出一定的引导,即在初始阶段使用分数阶混沌同步网络形成的混沌吸引子作为专家指导。这种方法与图像的注意力机制有一些相似之处,让agent 首先关注图像中的重要区域。但由于图像的尺寸相对较大,因此整个时间序列较长,并且整个决策过程中每一个步骤都需要消耗一定的成本,因此短序列可以有效降低累积效用。在经过实验后,本文决定让agent 每20 个时间步就获得一次即时奖励。由于该策略是确定性的,因此可以将其描述为一个函数,并避免内在期望:
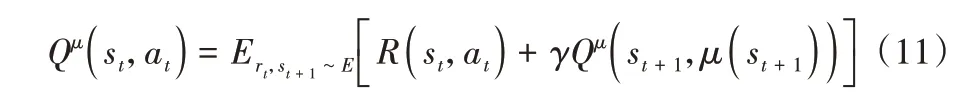
2.4.2 第二阶段
在第二阶段,分数阶同步网络的分割结果由于在局部以及边缘区域的精度不够,因此只能起到辅助作用,所以决定agent 每一个时间步就获得一次奖励,以此来更新策略。由于没有状态转移概率,并且奖励函数与数据相关,因此该问题被公式化为使用Q-learning 的强化学习问题。根据之前定义的动作集、状态集和奖励函数,agent 通过应用Q-learning算法学习最优策略,基于Q(s,a)选择具有最高期望奖励的行为,并用Bellman 方程更新Q(s,a),其公式如下:

其中:s表示当前状态;a表示当前选择的动作;r表示立即奖励;γ表示折扣系数;s′表示下一个状态;a′表示下一个动作。
在连续动作空间中学习的主要挑战是探索。非指导性策略算法的一个优点是agent 可以独立于学习算法来处理探索问题。通过将从噪声过程N采样的噪声添加到本文的策略中来构造探索策略。

其中:N是根据环境来选择的,参数更新方法使用与DQN 相同的梯度下降方法。
2.4.3 实例分割中的DQN
本文使用该DQN 将状态表示作为输入,并给出第七个动作的值作为输出。按照图2 所示的架构训练类别特定的Q-learning 网络。DQN 在训练过程中需要经验回放(Memory Replay)以存储大量经验样本。为了优化DQN,本文建立了改进的Memory Replay 来存储训练所需的经验数据。


3 实验与结果分析
3.1 实验设置
分数阶图像分割网络需要为不同类型的图像设置不同的参数。β是每个振荡器的分数阶,而a、b、c是系统参数。在2.2 节中,参数取值不同对分数阶混沌同步网络的耦合连接结果影响不同。本文中采用Pascal VOC 数据集中的单类——“飞机”图像对模型效果进行说明。为了增强模型的通用性,在实验过程中发现,设置β=0.9,a=0.5,b=0.65,c=6.2,∇d=1.01,分数阶网络的整体初步分割结果较好。
在强化学习agent 的学习过程中,设置合适的超参数很重要。当使用Bellman-equation 更新Q-function 时,如果系数γ较大,则生成的边界轮廓曲线很难覆盖目标;当该值较小时,分割目标实例过程中需要过多对图像环境的探索。在进行一定的实验后,本文设置γ=0.9。此外,Memory Replay 的大小设置为1 000,每个随机采样的最小batch 大小为128,训练次数为50。
3.2 数据集
本文的方法在Pascal VOC2007、Pascal VOC2012 以及这两个数据集的联合数据集上进行了评估。从Pascal VOC2007 和Pascal VOC2012 数据集中选择“飞机”图像,手动去除一些背景和干扰,并进行高斯模糊,来改善和简化数据集。其中,VOC2007 中共包含442 张此类图像,VOC2012 中共含有421 张图片。
本文提出了两种设置来评估模型的实验结果:1)使用标准的5 倍交叉验证(5-Fold Cross-Validation,5FCV),即80%的图像用于训练,其余图像用于测试;2)将训练数据集分为VOC2007 数据集和VOC2007+2012 数据集,并将测试数据集分为VOC2007 和VOC2007+2012。本文将在之后的3.7 节中详细说明该评估设置对实验精度的影响。
3.3 评价指标
本文遵循文献[28]来测量区域相似性J。具体地说,J被定义为“交集相交”,它仅考虑agent 在其中明确使用触发器来指示对象实例的存在的区域。对于每个图像的分割精度,区域相似度J表示如下:

其中:b是边界轮廓曲线;y是相应的ground truth。
而对于整个数据集的分割精度,本文采用平均精度AP(Average Precision)进行评估,如下所示:

其中:Ji是第i个图像的J值;N表示输入图像的数量,即两个训练数据集中图像的总和。
3.4 基准模型
将本文模型与以下基准模型进行比较:
1)LEGION[15]。这是最早使用“振荡相关”机制和分数阶混沌单层网络进行图像分割的网络。具体而言,该网络将具有相同特征的像素分组在一起,并区分具有不同特征的像素,此模型只能处理灰度图像。
2)SMCS(Scene segmentation Model based on Chaotic Synchronization)[10]和CPS(Chaotic Phase Synchronization and desynchronization)[16]。这些模型在文献[15]中模型的基础上,利用了更多的像素特征和新的特征编码方式,在实验精度上较LEGION 有明显提升。
3)FCPSM(Fractional-order Chaotic Phase Synchronization Model)[19]和NMVS(Neural network Model for Visual selection and Shifting)[18]。均为两层网络,它们引入了分时同步的注意力机制,即首先聚集吸引更多视觉注意力的像素,因此具有显著性标注能力,并提升了图像分割的效率。
4)OVSF(Object-based Visual Selection Framework)[17]。该模型将深度学习中的特征图与分数阶同步网络相结合,以提取图像的纹理,并引入了自上而下的注意力机制来标注目标显著性,整体效果较优。
3.5 分数阶网络图像分割过程
以自然图像“飞机”为例,如图3 所示。由于耦合力的存在和振子本身的振荡频率,代表相同目标的振子会实现相位同步。与图3 相对应的仿真结果在图4~6 中示出:图4 显示对应于不同目标的混沌吸引子不同;在图5 中,展示了从不同视角下不同坐标(i,j)目标振子的相位φ(i,j)图;在图6中,代表不同目标的振子之间相位变化较大。

图3 自然图像“飞机”Fig.3 Natural image“plane”

图4 图3中不同目标物体对应的吸引子Fig.4 Attractors corresponding to different target objects in Fig.3

图5 不同视角下不同坐标的振子相位图Fig.5 Phase diagrams of oscillators in different coordinates under different perspectives

图6 图3中代表不同目标物体的振子间相位方差随时间变化曲线Fig.6 Curves of phase standards between oscillators representing different objects in Fig.3 varying with time
3.6 对比实验
首先,在图7 中本文提出的模型与基准模型FCPSM 进行比较。图7 的结果强调了两个要点:首先,在大多数情况下,本文提出的模型使用具有类别特定知识,即agent 在单类图像探索过程中agent 可以从经验池中归纳总结出图像的类别信息,通过这种方式来查找目标实例的方法的性能要优于不具备此特性的FCPSM,但存在一个缺点,即在给定特征表示从未被识别的情况下,无法对目标实例进行分割。其次,本文模型的主要优点是在强化学习中使用动作,状态和奖励等元素来聚合相似像素形成局部区域,进而利用区域才具有的形状和轮廓等特征,而很少有分割模型试图做到这一点。这在图7 中也有所反映,即在通过强化学习处理初始分割结果之后,在处理诸如机尾、机翼等非平滑曲线的实验精度大大提高了。

图7 本文模型与基准模型FCPSM的实验效果对比Fig.7 Comparison of experimental results between the proposed model and baseline model FCPSM
本文模型与 OVSF、Mask-RCNN(Mask Region Convolutional Neural Networks)实例分割结果对比如图8 所示。从图8 可以看出:OVSF 因为结合了分数阶网络和深度学习中的feature map,所以取得的效果比之前的分数阶非线性模型效果都要好,但依然无法完全识别目标实例中应包含的像素,而本文提出的模型可以识别更多细节。因此,本文模型在目标实例像素覆盖率和边缘检测方面胜过OVSF。

图8 不同图像实例分割模型的实验效果对比Fig.8 Comparisons of result of different image instance segmentation models
目前,以Mask-RCN 为代表的图像实例分割中表现最佳。深度学习方法不仅可以更准确地标记目标的轮廓,而且,当场景中存在多种类型的目标实例时,深度学习方法仍然可以快速准确地分割实例。在算法复杂度方面,图1 中显示了分数阶网络在处理图像时达到同步所需的时间步骤,而且本文实验采用了联合分数阶同步和强化学习的双层模型,因此模型复杂度较高,在图像处理速度上与深度学习模型之间仍然存在一定的差距。这也是目前非线性模型的主要研究方向之一,仍需要一些更深入的探索。
表1 显示了各个非线性图像处理模型与本文模型在测试数据集上的AP 值,对每个图像仅进行一次实验。

表1 各个模型的AP值 单位:%Tab.1 AP of each model unit:%
LEGION、SMCS 和CPS 依次使用更多的像素基本特征,因此数据集上的最终结果越来越好。FCPSM 和NMVS 明显优于LEGION、SMCS 和CPS,达到约54%,因为它们首先对图像的显著性进行标注。OVSF 利用深度学习中的feature map处理像素的基本特征,因此其结果超过60%。然而以上模型的结果未达到65%。最后,本文模型表现最好,证明了将RL构造的区域特征与像素的基本特征相结合是有效的。有趣的是,在扩展数据集后,本文模型对测试集的实验精度有了很大的改进,提升了至少15 个百分点,这是其他模型均不具有的特性,其原因将在3.6 节中说明。
3.7 最终实验结果与分析
图9 显示了本文模型在“飞机”类别测试集的分割结果。大多数图像的背景信息仅在RGB 颜色、对比度等方面有所区别,但是对于某些具有附加干扰信息的图像,本文提出的模型仍然可以清晰地分割目标实例,而传统的混沌同步方法不仅容易受到背景干扰,而且难以准确地分割目标实例。

图9 本文模型部分实验效果Fig.9 Some experimental results for the proposed model
对数据集进行预处理的优点:如前所述,本文实验中简单预处理了数据集,然后将Pascal VOC2007 训练数据集与Pascal VOC2012 训练数据集混合在了一起,使图像数量比单个数据集多了大约1 倍,用以评估模型。实验结果的对比如图10 所示,可以看出在目标实例的像素覆盖率和边缘检测精度方面图(b)明显高于图(a)。图片的Ji值从单个数据集的43.6%和57.2%提高到了76.8%和81.1%,这与强化学习本身的性质有关:训练集的数量越多,agent 可以探索的上下文信息和先验知识越详细,可以借鉴的经验越多,实验的最终结果越精确。

图10 不同数据集上的实验结果对比Fig.10 Comparison of experiment results on different datasets
由于RL 模型在训练过程中采用了累积式奖励,因此不仅考虑当前效果,而且考虑未来的潜在优势。换句话说,以监督学习方式训练的模型较为短视,而以RL 方式训练的模型则更加关注全局利益和整体性能,所以更适合于图像相关的任务。此外,RL 还可以重用数据集进行训练。而与深度学习方法的对比中可以发现,基于深度学习的模型具有较好的性能,因为它们可以从神经网络中的多层功能模块中学习更多的抽象图像特征。受此启发,本文模型按照一定的相似性对像素进行汇总,以此来按照另一种方式抽象化图像的局部区域特征。这是本文模型在局部区域的分割精度几乎可以达到Mask R-CNN 水平的原因,同时也是下一步的重点工作,即将非线性图像基础特征提取模型按照深度学习的思想进行改进。
4 结语
在图像实例分割方面,本文提出了一种基于分数阶混沌同步网络和强化学习的模型。该模型与大多数实例分割方法具有本质上的不同,是分数阶网络和强化学习结合在一起进行像素级别的目标实例分割。本文模型的实验结果比目前基于分数阶模型的现有方法更好,而且可以与某些深度学习基准模型竞争,在局部区域的细粒度信息获取能力甚至超过了某些深度学习模型。但在获取目标实例类别信息的能力仍有所欠缺,因此未来的工作旨在构建更强大的分数阶网络以表征和提取图像基础特征。
猜你喜欢
农业工程学报(2022年4期)2022-04-24
智能制造(2021年4期)2021-11-04
红领巾·萌芽(2019年8期)2019-08-27
智富时代(2019年3期)2019-04-30
智富时代(2019年3期)2019-04-30
计算机辅助工程(2018年3期)2018-09-17
CHIP新电脑(2016年3期)2016-03-10
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
意林(2013年16期)2013-05-14
