
分布式资源描述框架数据管理系统查询性能评价
2022-03-01 12:34王秉发陆佳民
计算机应用 2022年2期
冯 钧,王秉发,陆佳民
(河海大学计算机与信息学院,南京 211100)
0 引言
资源描述框架(Resource Description Framework,RDF)作为万维网联盟(World Wide Web consortium,W3C)定义的一种展示、共享和连接语义网络数据的标准数据模型,已经被广泛用于各种数据科学应用中。随着RDF 数据规模的日益增长,集中式存储已经难以满足存储和查询处理需求,需要高性能的分布式RDF 数据管理系统对大规模的RDF 数据进行管理和重用。
现有的分布式RDF 系统通过一个无共享的集群实现对大规模RDF 数据的存储和管理[1],采用基于连接的方法(Join-based)和基于图匹配(Graph-matching Based)的方法[2]进行SPARQL(Simple Protocol and RDF Query Language)[3]查询计算。得益于关系数据库技术的成熟性、健壮性和可扩展性,大量基于关系存储模式的分布式RDF 系统应运而生。按照系统的执行模型不同,本文中将这些系统分为:基于主存(Random Access Memory,RAM)的系统和基于Spark 的系统。
现有的基于RAM 的系统和基于Spark 的系统仅针对高选择性的小直径查询进行了优化,可以高效地响应小直径查询;但是SPARQL 查询是一个连接密集型查询,据研究显示,用户倾向请求越来越复杂的交互式查询,交互式DBpedia 的SPARQL 查询日志中,最高可达10 个连接,而生物医学领域的分析查询甚至包括50 个以上的连接[4]。因此,有必要针对交互式查询中涉及的多连接复杂型查询进行优化。为了有效提高分布式RDF 系统的查询性能,现有的研究主要从以下两个方面进行优化[5]:1)优化关系存储模式;2)优化SPARQL 到SQL(Structured Query Language)的查询转化。通过减少查询处理期间连接操作数量、输入数据大小和中间结果大小[6],提升分布式SPARQL 查询性能。
本文的主要工作包括:1)详细调研了现有的基于RAM和基于Spark 的系统在分布式SPARQL 查询上的相关工作;2)将查询准确性作为分布式SPARQL 查询的评价指标,支持SPARQL 查询结果的持久化,实现了查询结果的校验;3)结合查询准确性、查询响应时间这两个评价指标,对8 个代表系统的查询性能进行了广泛的实验评估;4)讨论分析当前分布式SPARQL 查询的局限性,展望了未来可能的研究方向。
1 相关理论
1.1 SPARQL查询
SPARQL[3]是W3C 提出的一种标准查询语言,以实现对大规模RDF 数据的查询与检索。SPARQL 查询的基本组成单元是三元组模式,一组三元组模式构成了基本图模式(Basic Graph Pattern,BGP),其形式化定义如定义1 所示。
定义1三元组模式和基本图模式。tpi={t|t∈(I∪V∪B)×(I∪V)×(I∪L∪V∪B)},其中:I表示国际化资源标识符集,B表示空白节点集,L表示字面量集,V表示变量集,并且这四个集合互不相交。如果一个三元组是该集合中的元素,则该三元组称为一个三元组模式tpi。,基本图模式由一组三元组模式进行合取运算组成,因此也称为合取查询(Conjunctive Query)。
合取查询本质上是在数据集上对一组经三元组模式选择后的三元组进行连接运算,三元组模式选择性[7]的形式化定义如定义2 所示。
定义2三元组模式选择性。Sel(tpi,D)=,其中:tpi表示SPARQL 查询Q 的三元组模式;D表示一个数据集;N为数据集D中三元组的总个数;Card(tpi,D)表示D中匹配三元组模式tpi的三元组个数。
SPARQL 查询由基本图模式组成,根据查询图的结构可将SPARQL 查询分为三种基本形态:链型查询、星型查询和雪花型查询以及由这三种基本查询组合而成的复杂查询[8]。SPARQL BGP 的直径定义为最长路径,即不考虑边的方向,最长的三元组模式连通序列[9]。
1)链型查询:对三元组模式间的主语(宾语)−宾语(主语)进行连接,其查询图结构如图1 所示,连接变量在一个三元组中位于主语位置,在另一个三元组中位于宾语位置,链型查询模式的直径对应查询模式中三元组模式的个数。
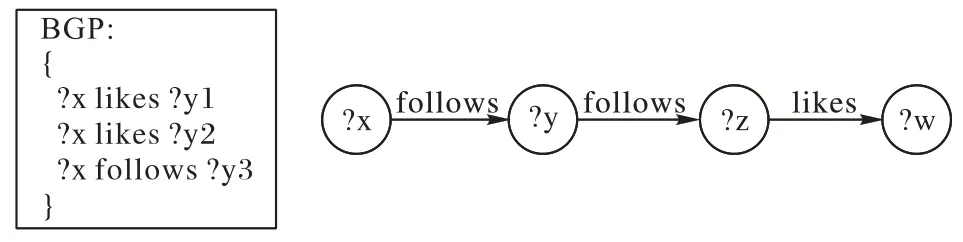
图1 链型查询图结构示意图Fig.1 Schematic diagram of chain query graph structure
2)星型查询:对三元组模式间的主语−主语进行连接,其查询图结构如图2 所示,连接变量位于主语位置,查询直径为1。星型查询模式在SPARQL 查询中经常出现,许多查询处理器都针对这种工作负载进行了优化。
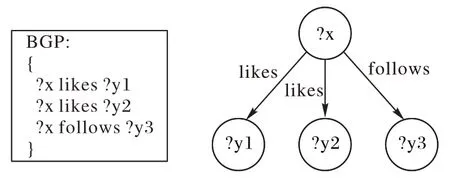
图2 星型查询图结构示意图示意图Fig.2 Schematic diagram of star query graph structure
3)雪花型查询:由短路径连接的若干个星型查询组合而成,其查询图结构如图3 所示,该查询图由两个星型查询图组合而成,其查询直径为3。

图3 雪花型查询图结构示意图Fig.3 Schematic diagram of snowflake query graph structure
4)复杂型查询:由三种基本查询模式组合而成的复杂查询,其查询图结构如图4 所示,该查询图由两个星型查询子图和一个链型查询子图组合而成,其查询直径为4。
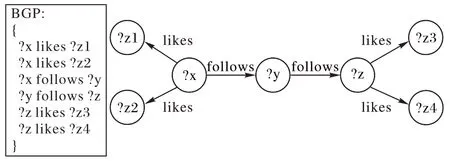
图4 复杂型查询图结构示意图Fig.4 Schematic diagram of complex query graph structure
1.2 关系存储模式
现有的基于关系的分布式RDF 系统中,涉及的关系存储模式包括:
1)垂直划分(Vertical Partitoning,VP)[10]:按照谓语创建关系模式为(subject,object)的表,将相同谓语的三元组的主语、宾语存入同一张表中,表的总数量为谓语的数量。
2)扩展垂直划分(Extended VP,ExtVP)[8]:预先对具有连接相关性的两个垂直划分表进行半连接计算,当相应的扩展垂直划分表对原始的垂直划分表缩减量达到了设定的阈值时才物化这些表。
3)宽属性表(Wide Property Table,WPT)[11]:按照主语创建关系模式为(subject,property1,…,propertyn)的表,即将同类主语存入一张表中。由于不同主语的谓语集合也存在差异,容易存在空值问题。此外,宽属性表还存在多值属性存储问题。
4)逆宽属性表(inverse Wide Property Table,iWPT)[12]:按照宾语创建关系模式为(,object)的表,即为数据集中的每个属性包含一个不同的列,将一个宾语的所有信息存入同一行。因此,基于宾语−宾语的连接计算可以通过对iWPT 进行一次扫描操作获取。
5)宽属性表−逆宽属性表内连接(inner join between WPT and iWPT,jWPT-inner):预先将宽属性表和逆宽属性表进行内连接运算,jWPT-inner 表每一行包含一个资源一跳上的所有信息。
6)六重索引(Sextuple Indexing)[11]:以三元组〈主语,谓语,宾语〉的全排列方式对应地创建主语−谓语−宾语(spo)、主语−宾语−谓语(sop)、谓语−主语−宾语(pso)、谓语−宾语−主语(pos)、宾语−主语−谓语(osp)、宾语−谓语−主语(ops)六张表。六重索引主要分为两组:一组是主语索引集,包括spo表、sop 表和pso 表;另一组是宾语索引集,包括osp 表、ops 表和pos 表。
关系模式设计[13]对分布式SPARQL 查询效率起着至关重要的作用,不同的关系模式设计不仅产生不同的物理数据分区,还意味着相同SPARQL 查询的不同SQL 转换。因此,通过优化关系存储模式,可以有效地减少连接操作数量、输入数据大小和中间结果大小,从而提高SPARQL 查询处理的效率。
1.3 SPARQL到SQL的查询转化
基于连接的SPARQL 查询计算将每个图模式转化为等效的SQL 表达式,并在单张表或多张表上使用连接操作组合每次迭代的结果。在现有的分布式RDF 系统中,SPARQL 查询是通过三元组模式进行计算,一个查询执行规划可以看作三元组模式在变量上的连接。但是由于SPARQL 查询是连接密集型查询,并且SPARQL 连接计划的状态空间的大小又与连接数量呈指数相关,在这样的空间下,搜索最优的查询规划是一个NP(Non-deterministic Polynomial)困难问题[14]。
现有的分布式SPARQL 查询优化使用确定的估计器作为查询规划的评估指标[15],对SPARQL 连接状态空间中所有可能的查询规划进行探索,通过代价评估确定最优的查询规划。现有的两种主流的搜索策略为:基于动态规划的查询规划和基于启发式的查询规划[16]。
基于动态规划的查询规划的核心思想是在搜索连接计划时,根据预先计算的统计信息选择代价估计最小的作为最优查询计划,并通过合并冗余状态,减小搜索空间。
基于启发式的查询规划的核心思想是通过一定的搜索策略对部分状态空间进行启发式搜索,与动态规划方法相比,它能节约大量的搜索时间,但是确定的查询规划不一定是最优的。
2 基于Spark的系统
S2RDF(SPARQL on Spark for RDF)[8]使用垂直划分和基于半连接预处理的扩展垂直划分相结合的混合关系存储模式进行存储。在数据加载阶段,S2RDF 通过选择性阈值物化部分垂直划分数据表之间的左半连接结果并存储在关系数据表中,减小了连接操作时输入数据的大小。在查询处理阶段,S2RDF 首先根据统计信息为基本图模式中的每一个三元组模式选择查询候选表,接着通过Jena ARQ(a SPARQL Processor for Jena)将SPARQL 查询解析到相应的代数树上,应用基本的代数优化后生成等效的Spark SQL 表达式,然后通过经验知识进行连接顺序优化,避免连接悬挂三元组模式,从而避免了笛卡儿积,减小了中间连接结果大小,有效地提高了查询效率。S2RDF 通过预先计算三元组模式中变量的半连接结果,有效地提高了查询性能,但导致磁盘占用空间大、数据加载时间长等问题。此外,优化查询连接时,S2RDF 假设较小的连接输入通常导致较小的连接输出,但这个假设并不是完全正确的。
SPARQLGX[17]使用垂直划分模式进行RDF 数据存储,基于连接选择性进行连接顺序优化。在查询处理阶段,SPARQLGX 对基本图模式的每个查询模式分别进行处理,从磁盘中读取相关数据并使用常量进行过滤;然后寻找具有相同变量的三元组模式进行连接,通过中间结果的统计信息,优化连接顺序;最终将SPARQL 查询片段中的每个操作符转化为符合Spark 的Scala 命令序列,通过Spark API(Application Programming Interface)直接执行查询。Li 等[18]在SPARQLGX 的基础上进行改进,提出了一种基于语义连接信息链的查询优化方法SparkIlink。SparkIlink 在查询处理阶段,首先根据变量对三元组模式进行映射,然后通过循环遍历映射图搜索具有值交集的映射并将其加入语义信息链,最后根据语义信息链的顺序和连接三元组信息确定查询连接顺序,通过Spark API 直接执行查询。SparkIlink 通过语义连接信息链优化连接顺序,减小了中间连接结果大小,在SPARQLGX 的基础上有效提高了链型、星型和雪花型这三种基本查询类型的查询性能。
PRoST(Partitioned RDF on Spark Tables)[19]采用垂直划分和宽属性表进行混合存储。查询处理阶段,PRoST 将SPARQL 查询转化为连接树,根据连接树节点的优先级,自底向上进行计算。其核心思想是将主语相同的三元组模式归为一组,存入根节点,使用属性表进行查询;将其余的节点存入叶子节点,使用垂直划分表处理。PRoST 通过宽属性表减少了连接操作的数量,通过数据加载阶段的统计信息优化查询连接顺序,有效地减小了中间结果的大小,从而提高了查询效率。
Hassan 等[20]在2018 年提出了两种新的关系存储模式VPExp 和3CStore。VPExp 模式根据宾语的显式类型信息拆分垂直划分表,从而最小化查询计算时输入数据的大小;但是它的适用范围仅针对谓词为“rdf_type”且宾语为字面量的三元组模式。3CStore 模式存储三元组模式间相关性(除宾语−宾语相关)的预连接计算结果,从而减少了查询处理时的输入数据大小和连接操作数量。在查询处理阶段,根据查询编译器将SPARQL 查询解析到相应的代数树中,并将相应的关系存储模式转化为等效的SQL 表达式进行查询计算。2019 年Hassan 等[21]又在PRoST 的基础上,提出了一种名为“子集宽属性表”(Subset Property Table,SPT)的关系存储模式,它通过显式地避免存储空值和采用嵌套数据结构存储多值属性的方式,有效地解决了传统属性表中所存在的空值和多值问题;通过拆分宽属性表,最小化查询连接时输入数据的大小,降低了连接的复杂度。SPT+VP 中采用子集宽属性表和垂直划分相结合的混合存储模式存储数据,在查询处理阶段,与PRoST 的思想一致,使用子集宽属性表处理星型查询,使用垂直划分表处理其他查询;通过自定义的查询编译器将SPARQL 转化为Spark SQL,根据三元组模式中常量的数量和数据集统计信息设定查询连接的优先级,从而优化查询。
Chawla 等[5]提出了HyPSo,它采用垂直划分和哈希划分相结合的混合关系存储模式进行数据存储。HyPSo 首先对初始RDF 数据集进行垂直划分,然后对垂直划分后的结果集进行基于主语的哈希划分,这种混合划分方式有效地减少了处理星型查询时所需的通信开销,同时又减少了连接操作的数量和数据搜索空间,从而优化了星型查询。
Schievelbein 等[12]提出了一种名为“逆属性增强的宽属性表”(iWPT)的关系存储模式,并利用相同RDF 数据图的多个宽属性表扩展表来进行混合存储。其核心思想是根据不同关系模式构造中间抽象树来表示SPARQL 查询,以最小化查询计算所需要的连接操作数量。实验结果表明,采用宽属性表、逆宽属性表和宽属性表−逆宽属性内连接(WPT+iWPT+jWPT-inner)的混合存储模式,优化了除链型查询外的所有查询类型的查询性能;但是,使用混合存储进行存储时,需要权衡查询计算中连接操作的数量与所有查询候选表的行数。
3 基于RAM的系统
Gurajada 等[22]提出了内存型分布式RDF 系统TriAD(Triple Asynchronous Distributed),它是一种基于内存的分布式RDF 系统,使用六重索引模式进行RDF 数据存储,通过MPI(Message Passing Interface)协议进行SPARQL 查询处理。在数据预处理阶段,TriAD 在主节点上建立一个全局概述图,并将其水平划分为若干块分发到从节点上。在查询处理阶段,首先在主节点上对概述图进行图匹配获取查询图中每个三元组模式的候选三元组,然后在从节点上对数据图上的候选三元组进行连接操作获得最终解。采用自底向上的动态规划算法确定概要图的最优探索顺序和针对六重索引的最优三元组模式连接顺序,使用灌木丛计划来限制动态规划搜索树的形状,从而减少搜索空间。TriAD 的查询性能始终比集中式RDF 引擎性能好两个数量级;但是,TriAD 中大量的索引导致数据冗余、存储空间消耗大、数据更新的一致性维护代价大等问题。
Harbi 等[23]提出了内存型分布式RDF 系统AdPart,它通过基于主语的哈希划分方式实现RDF 数据的初始划分,通过分层热图监控查询工作负载,设定频繁阈值标识频繁模式,使用频繁模式指导RDF 数据进行增量重划分。在查询处理阶段,采用动态规划算法设计查询连接顺序,使用右深度树约束搜索树形状,基于局部性哈希和自适应划分加速SPARQL 查询。AdPart 通过扫描索引获得子查询的局部匹配结果,利用分布式半连接(Distributed Semi-Join,DSJ)算法获得整个子查询的计算结果。由于数据驻留在内存中并且是哈希索引的,可以利用局部性哈希来并行处理星型查询,最小化了查询计算期间的通信代价。此外,使用频繁模式驱动数据进行增量重划分,实现了对系统对查询工作负载的自适应性,有效地提高了分布式SPARQL 的查询性能;但是,AdPart 存在查询准确性较低,查询计算过程中发生内存溢出等问题。
Potter 等[24]提出了内存型分布式RDF 系统RDFox,它使用图划分的方式进行数据存储,使用哈希索引在内存中索引数据。在查询处理阶段,使用索引嵌套循环连接作为分布式连接算法,让集群节点在数据分区上并行计算查询。RDFox在查询处理期间动态交换数据,使用流量控制机制限制分布式连接计算中连接中间结果的物化,从而大大限制查询计算期间的内存占用。RDFox 通过动态数据交换和流量控制机制,使得RDFox 在查询响应时间、网络通信和内存使用方面优于其他方法。此外,通过在分布式连接算法中限制内存使用,成功响应了复杂链型查询。但是,RDFox 在低选择性的复杂型查询上的性能仍然较差。
4 实验设置
4.1 对比系统
Abdelaziz 等[25]对12 个具有代表性的分布式RDF 系统在不同数据集和查询负载上进行了实验评估,实验结果表明AdPart 和TriAD 的查询性能持续优于其他系统。因此,本文使用AdPart 和TriAD 作为基于RAM 的分布式RDF 对比系统。此外,由于AdPart 和TriAD 不能响应低选择性的大直径查询,Potter 等[24]提出的RDFox 通过动态数据交换和流量控制机制成功响应了复杂型查询,因此,将RDFox 也作为基于RAM 的对比系统。由于RDFox 未公开源代码,所以本文中与RDFox 相关的实验均采用了文献中公布的结果。
此外,为了验证不同关系存储模式对查询性能的影响,本文还将S2RDF、PRoST、WiW(WPT+iWPT)、C3W(WPT+iWPT+jWPT-inner)和C2WVP(WPT+iWPT+VP)作为对比系统。其中S2RDF 的选择性阈值设定为0.25,WiW 采用属性表和逆属性表进行混合存储,C3W 使用属性表、逆属性表和属性表−逆属性表的内连接表进行混合存储,C2WVP 采用属性表、逆属性表和垂直划分表进行混合存储,这些系统都沿用PRoST 中的查询执行器执行SPARQL 查询计算。以上实验对比系统的相关特征如表1 所示。

表1 实验对比系统的相关特征Tab.1 Related characteristics of experimental systems for comparison
4.2 基准数据集和查询集
基准数据集可以分为合成数据集和真实数据集[7]。真实数据集可以使用真实数据和用户查询日志对系统进行基准测试,但是真实数据集无法测试不同数据集大小和查询工作负载下RDF 系统的可伸缩性。合成数据集利用生成数据,有助于测试不同数据集大小下系统的可伸缩性。本文中同时在合成数据集WatDiv(Waterloo SPARQL Diversity Test Suite)和真实数据集YAGO2(Yet Another Great Ontology version 2.0)上进行实验。表2 中展示了十亿规模下的WatDiv 数据集(WatDiv-1B)和YAGO2 数据集统计信息。

表2 实验所使用数据集的统计信息Tab.2 Statistics of datasets used in experiments
WatDiv 基准[26]:加拿大滑铁卢大学于2014 年提出的用于描述用户实体相关信息的数据集,包括数据生成器和查询生成器。WatDiv 查询集由查询器根据预定义的查询模板生成。本文中的查询集由基础测试用例和增量链型测试用例组成。其中,基础测试用例由20 个预定义的基础类型查询模板生成,根据查询形状可分为:链型(Ln)、星型(Sn)、雪花型(Fn)和复杂型(Cn)四类;增量链型测试用例由18 个增量链型(Incremental Linear,IL)查询模板生成,根据三元组模式中主语类别分为:IL-1、IL-2 和IL-3 三类查询,IL-1、IL-2 和IL-3 查询分别由绑定的用户、绑定的零售商以及未绑定的主语组成,每个查询类型的直径由5 增大为10。
YAGO2[27]:来源于多种语言的维基百科,包含WordNet、GeoNames 和其他数据源,其中包含1.5 亿个三元组。据YAGO2 查询日志显示,有77%的三元组模式都涉及星型连接,平均每个查询有1.8 个基于主语的连接。由于YAGO2是真实数据,没有提供查询基准,所以本文中仍然遵循文献[23]中提出的四种代表性查询类型。
4.3 评价指标
查询响应时间:在各类查询类型上的执行查询处理的总时间,包括查询编译时间和查询执行时间。
查询准确率:在各类查询类型上查询结果正确查询的个数与查询总个数的比值。本文中支持将SPARQL 查询结果持久化到Hadoop 分布式文件系统(Hadoop Distributed File System,HDFS)文件中,通过将查询结果与基准结果进行校验,从而客观准确地对系统的查询准确率进行定量评估。
4.4 实验环境
搭建一个由10 个节点组成的无共享服务器集群,通过专用带宽为1 Gb/s 的网络进行连接。每个服务器运行Ubuntu 16.04 系统,有8 个vCPU、32 GB RAM 和512 GB 磁盘存储空间,安装Hadoop 2.7.1 和Spark 2.0.2,每个Spark 执行器都设置为20 GB 内存。
对每个查询进行10 次评估,记录每个系统报告的查询计算时间,并计算每种查询类型的查询时间的几何平均值(Geometric Mean,GM)。
5 实验与结果分析
为了全面评估上述8 个分布式RDF 系统的查询性能,本文中选择了影响SPARQL 查询性能的三个特征:查询类型、查询直径以及数据集类型,对相关系统进行了实验,并结合查询响应时间和查询准确性两个指标对实验结果进行分析。
5.1 查询响应时间分析
5.1.1 不同查询类型下的查询效率
本组实验使用WatDiv-1B 作为数据集,WatDiv 基础测试用例作为查询集,对各个系统在不同查询类型下的查询性能进行评估。表3 展示了各个系统在不同查询类型的查询响应时间。
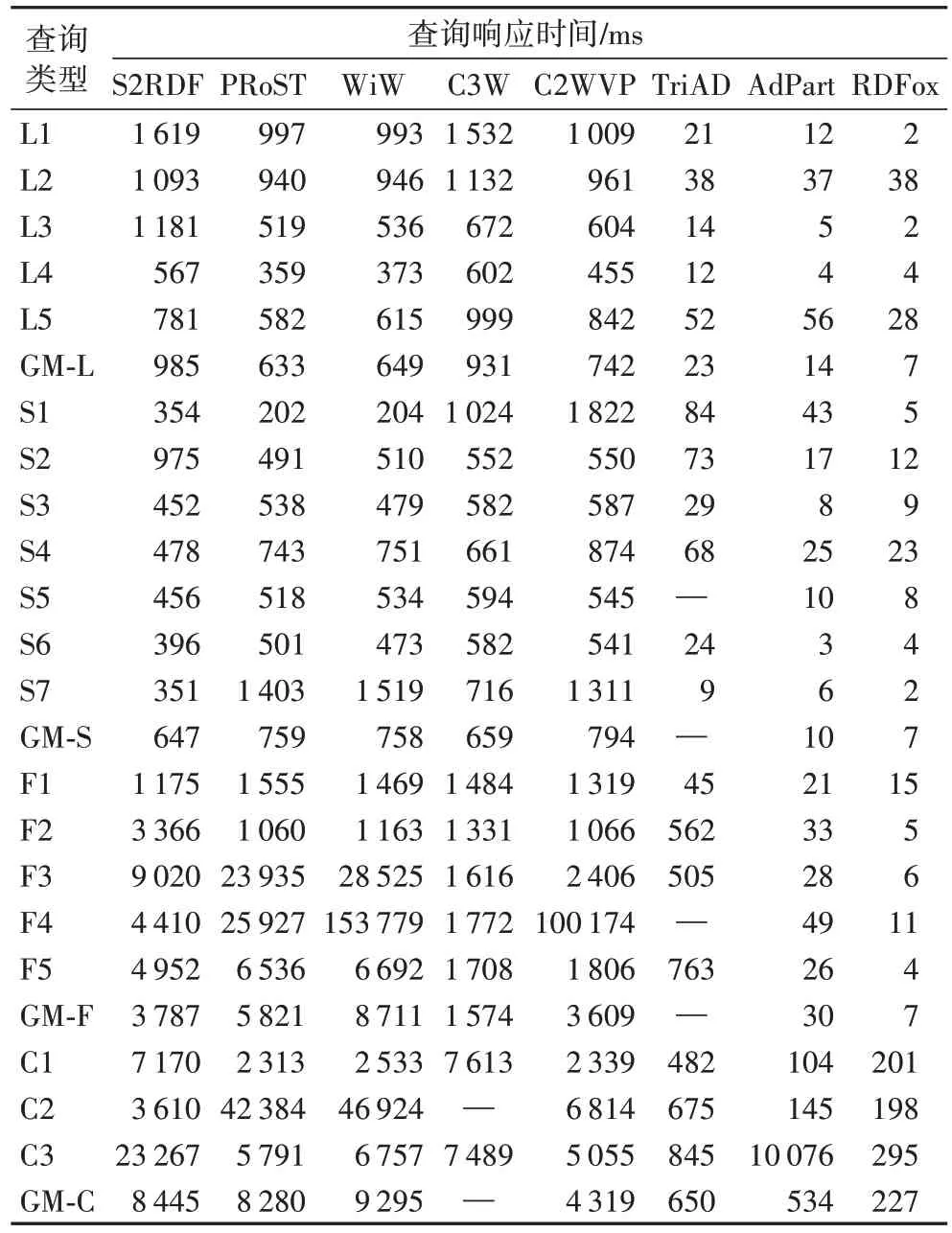
表3 WatDiv基本查询集上各系统的查询响应时间对比Tab.3 Comparison of query time of different systems on WatDiv basic query set
实验结果表明:1)不同查询类型下的查询时间差异明显,基于RAM 和基于Spark 的系统在链型查询、星型查询上的查询效率都优于雪花型查询和复杂型查询;2)基于RAM的系统在基础测试用例下的查询效率优于基于Spark 的系统三个数量级,在不到1 s 的时间内就可以响应10 亿三元组的RDF 图上的基准测试查询;3)对于基于Spark 的系统而言,不同的关系存储模式对于查询效率也有显著的影响。
下面结合实验结果对各个系统在不同查询类型下的查询响应时间进行具体分析。基于RAM 的系统在基础测试用例下表现出了优越的查询性能,主要原因是基础查询用例都是小直径的高选择性查询,查询连接过程中的中间结果较小,而基于RAM 的系统在查询过程中将数据驻留在内存中,并且通过异步执行的方式进行并行计算,有效提高了查询效率,而基于Spark 的系统受限于Spark 同步执行查询计划的限制,减少了查询计算的并行性,极大影响了查询性能。
对于雪花型查询(Fn),其涉及的基本查询图模式中只包含主语−宾语连接、主语−主语连接。C3W 在该类查询上的性能优于其他基于Spark 的系统,主要是该系统中预先对属性表和逆属性表进行了内连接计算,通过一次表扫描就可以获得一个资源一跳上的所有信息,从而最大限度地减少了连接操作数量,缩短了查询时间。WiW 在查询F4 中的性能显著低于其他基于Spark 的系统,主要由于在该类查询中涉及属性表和逆属性表的连接操作,从而导致查询效率的降低。
对于复杂型查询(Cn),查询C1 和C2 包含四种不同的连接模式,查询C3 只包含低选择性的主语−主语连接。基于RAM 的系统在该类查询上的性能比基于Spark 的系统高出两个数量级,对于C3 查询RDFox 和TriAD 可以快速响应,但AdPart 要比它们慢两个数量级。PRoST、WiW 以及C2WVP在C1 和C3 查询上的性能大致相当。S2RDF 在C3 查询上由于涉及大量的连接操作,查询性能显著降低。而C3W 由于jWPT-inner 表中存在较多的行数,查询的性能受限于输入数据大小,因此无法响应C2 查询。
5.1.2 不同查询直径下的查询效率
WatDiv 基础测试用例可以有效地评估系统对于不同复杂度的查询工作负载的效率,但是基础测试用例中绝大多数查询的查询直径都很小,因此为了测试实验系统在不同查询直径下的查询性能,本组实验中使用了由Schätzle 等[8]提出的增量链型查询集进行实验,实验结果如表4 所示。

表4 WatDiv增量链型查询集上各系统的查询响应时间对比Tab.4 Comparison of query response time of different systems on WatDiv incremental linear query set
实验结果表明:1)基于RAM 的系统在低选择性的增量链型查询IL-1 和IL-2 的效率高出基于Spark 的系统四个数量级;2)各个系统的查询时间与查询直径大小未呈明显关系;3)RDFox 和AdPart 在IL-1 和IL-2 上的查询效率比TriAD 高出三个数量级;4)不同的关系存储模式在不同查询直径下的查询效率也存在较大影响;5)基于RAM 对于低选择性查询IL-3 的伸缩性差,AdPart 和TriAD 不能响应IL-3 查询,而RDFox 在此类查询上的效率也低于基于Spark 相关系统一个数量级。
下面结合查询特征进行具体分析,由于IL-1 和IL-2 都是主语绑定的高选择性链型查询,查询结果数量较小,因此与基础测试用例下的结果基本类似,基于RAM 的系统查询性能仍优于基于Spark 的系统。此外,各个系统的查询时间与查询直径大小也未呈现明显关系。例如,在S2RDF 中IL-2-5虽然是IL-2 中其他查询类型的子类型,但是其查询效率却是最低的,这表明增大查询直径甚至可以提高查询效率。
对于IL-1-n和IL-2-n查询,RDFox 和AdPart 的查询性能比TriAD 高出三个数量级,主要原因是RDFox 和AdPart 使用哈希索引在内存中索引数据,使用异步的方式沿着查询计划并行运行多个连接操作,并且在进行连接时只交换投影连接列的唯一值,通过提高查询的并行性大大提高了查询性能。而TriAD 通过六重索引数据,使用摘要图对查询搜索空间进行剪枝,但当执行分布式合并连接(merge join)和哈希连接(hash join)时,TriAD 需要在集群节点上对连接关系进分片,因此在并发执行连接时产生较大且不必要的中间结果,从而影响了查询效率。PRoST、WiW 以及C2WVP 在IL-1-n和IL-2-n查询上的性能大致相当,而C3W 由于jWPT-inner 表中存在较多的行数,查询的效率受限于数据大小,查询效率显著降低。S2RDF 在选择性阈值设定为0.25 的情况下,查询效率低于除C3W 外的其他混合存储模式。
对于IL-3-n型查询,由于它是非选择性的链型查询,查询连接的中间结果很大,返回的查询结果数量也比其他查询多出几个数量级。AdPart 和TriAD 未能响应此类查询,主要原因是这两个系统中哈希连接的内存使用由中间结果大小决定,极大限制了系统的伸缩性,因此对于高选择性的查询这两个系统都发生了内存溢出。而RDFox 通过使用索引嵌套循环连接并通过流量控制机制限制内存的使用,从而成功响应IL-3-n查询。对于基于Spark 的系统而言,通过内置的调度策略对集群资源进行调度,有效避免了内存溢出的发生,因此S2RDF、PRoST、WiW、C3W 以及C2WVP 在IL-3-n型查询上的效率更高。
5.1.3 不同数据集下的查询效率
除了使用合成数据集WatDiv-1B 外,本组实验还使用了真实数据集YAGO2 和用户查询日志进行对比实验。由于未能在TriAD 和AdPart 上完成数据集加载,因此这两个系统采用文献[23]中发布的实验结果作为参照结果,而RDFox 因为无法复现,未对其进行相关实验,详细实验结果如表5 所示。

表5 YAGO2查询集上各系统的查询响应时间对比Tab.5 Comparison of query response time of different systems on YAGO2 query set
实验结果表明:1)YAGO2 上的查询结果总体与WatDiv数据集上的结果一致,对于YAGO2 上的四种基准查询,AdPart 的效率比基于Spark 的系统高出两个数量级,比TriAD高出一个数量级;2)对于基于Spark 的系统而言,不同存储模式在YAGO2 上的查询效率也存在明显差别,C2WVP 除了在Y2 查询上都取得了最佳性能。
下面针对YAGO2 数据集下各系统在各类查询上的查询响应时间进行具体分析。对于Y1 和Y2 查询主要涉及主语−宾语连接,AdPart 在不需要通信的情况下就可以处理Y1 和Y2 中的大多数连接,因此AdPart 比TriAD 性能更优越。而Y3 和Y4 查询中包含宾语−宾语连接,因此包含逆属性表模式的WiW 和C2WVP 系统在这两类查询上的效率明显高于其他几种混合关系存储模式。C3W 虽然也采用了逆属性表模式,但是在查询时由于jWPT-inner 表中存在较多的行数,查询的效率受限于输入数据大小。
5.2 查询准确性分析
本组实验对比分析不同系统(不含RDFox)的SPARQL查询准确性,各个系统在不同查询维度上的查询准确率如表6 所示。实验结果表明,S2RDF、AdPart 在SPARQL 查询上存在着较大的查询误差。从表6 可知,在WatDiv 基础测试用例上,S2RDF 的平均准确率为82%、AdPart 仅为70%,主要原因是这两个系统在查询计算过程中出现了大量重复答案,而其余系统在基本查询类型上未出现错误。对于WatdDiv 增量链型查询而言,S2RDF 在增量链型查询IL-1、IL-2、IL3 上出现了查询错误,AdPart 在IL-2 上出现错误答案,而TriAD 和AdPart 由于内存溢出未能响应IL-3 查询,因此在IL-3 上的准确率为0。对于YAGO2 基础测试用例上而言,由于YAGO2上的查询都为高选择性的查询,因此上述7 个系统都未出现查询错误。

表6 不同SPARQL查询下各系统的查询准确率 单位:%Tab.6 Accuracy of different SPARQL queries in different systems unit:%
综合不同维度上的实验结果可以得出以下结论,现有系统仅在高选择性的小直径查询上具有较高的查询准确性,对于低选择性的大直径查询存在较大的查询误差。
5.3 实验总结
本文通过四组对比实验对8 个典型的分布式RDF 系统的查询性能进行了系统的评估。实验结果显示,上述实验系统针对链型查询和星型查询进行了优化,但是对于分布式SPARQL 查询的伸缩性差,不能动态适应查询工作负载的变化,部分系统甚至还存在查询准确性的问题。基于RAM 的系统可以高效地响应高选择性的小直径查询,但是对于低选择性的大直径查询性能低甚至无法响应。基于Spark 的系统则在低选择性的大直径查询上具有较高的查询性能,但是对于高选择性的小直径查询的性能差。但总的来说,现有的系统难以满足真实应用中对低选择性大直径复杂查询的需求。
此外,经实验论证上述系统还存在以下问题:
1)在现有的关系存储模式中存在着数据倾斜、表扫描时间过长的问题,例如在WatDiv-1B 数据集对应的VP 表中,最大的VP 表中含有4.5 亿个三元组,而最小的VP 表仅含有240 个三元组。严重的数据倾斜导致了SPARQL 查询计算的连接复杂度过高,对大表的扫描时间过长,同时还导致了集群节点之间的通信代价增大,制约了分布式SPARQL 查询的性能。
2)上述的基于Spark 的系统依赖RDF 特定的概要统计信息或特征集的方式进行基数评估,采用贪婪搜索的方式规划查询计划;基于RAM 的系统依赖基于摘要图进行基数评估,采用动态规划的方式搜索查询计划。但是这些系统中的基数评估方法依赖条件独立性假设、函数依赖性假设或者一致性假设,但是这些假设并非总是成立,限制了基数评估的准确性,导致了查询优化器生成次优的查询连接计划,从而限制了分布式SPARQL 的查询性能。
3)上述系统在SPARQL 查询规划阶段,采用贪婪搜索或者动态规划的方式规划查询计划,选择代价估计最小的作为最优查询计划,但是对于大直径的复杂型查询,搜索SPARQL 查询连接状态空间的时空复杂性过高,导致查询编译时间极大。在查询规划过程中,除了TriAD 外,均将查询计划构造为左深度树或右深度树,极大限制了SPARQL 查询计算的并行度,从而影响了分布式SPARQL 查询效率。
6 结语
本文系统地阐述了现有的基于RAM 和基于Spark 的分布式RDF 系统的查询优化方法,使用了大规模的合成数据集和真实数据集对具有代表性的8 个系统进行了广泛的实验评估,并对实验结果进行了全面的总结分析。
通过本文的实验分析与比较,可以看出目前分布式SPARQL 查询优化上已经取得了一定的成果;但是仍然存在着查询效率低、查询准确性差和伸缩性差等局限性,在垂直领域的应用上仍面临着许多问题和挑战。因此,未来的研究方向包括:
1)探索面向垂直领域应用的关系存储模式,针对垂直领域查询需求对RDF 数据进行高效、平衡划分,实现数据的负载均衡,有效解决现有系统中由于存在数据倾斜而导致的连接复杂性过高的问题。
2)设计基于混合存储模式的数据索引与过滤机制,对表中不包含目标值的数据进行快速过滤,减少不必要的磁盘I/O 操作,从而提高SPARQL 查询计算过程中目标RDF 数据的查找速度,有效解决实验中出现的查询性能受限于表扫描时间的问题。
3)设计一种高准确性的SPARQL 基数估计器,例如使用基于学习的方法训练基数评估器,通过神经网络模型学习RDF 数据特征以及三元组模式间的相关性,提高对查询连接中间连接结果大小的预测准确度,实现对三元组模式间连接顺序、连接方式的优化,有效防止实验中出现的由于中间结果过大而导致内存溢出、查询复杂度过高的问题。
4)设计一种基于代价评估的启发式查询规划算法,利用代价评估模型生成最优查询计划,并将最优查询计划构造为并行性更高的查询树,有效解决现有系统中查询并行度低、查询编译时间和执行时间长的问题,从而有效提高分布式SPARQL 查询的性能。
猜你喜欢
科学与财富(2021年35期)2021-05-10
考试与评价·高一版(2020年2期)2020-10-29
初中生学习指导·中考版(2020年8期)2020-09-10
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
疯狂英语·新阅版(2019年11期)2019-09-10
疯狂英语·初中版(2019年12期)2019-01-02
新高考·英语进阶(高二高三)(2016年11期)2017-07-07
中学生英语高中综合天地(2008年10期)2008-12-22
中学英语园地·教学指导版(2008年10期)2008-11-25
