
基于融合特征和迁移学习的艺术图像情感识别研究
2022-03-01 06:04:10刘佳欣潘建达
智能计算机与应用 2022年1期
杨 松,刘佳欣,潘建达
(1 大连外国语大学 软件学院,辽宁 大连 116044;2 大连外国语大学 语言智能中心,辽宁 大连 116044;3 网络空间多语言大数据智能分析研究中心,辽宁 大连 116044)
0 引言
随着图像情感计算的深入推进,研究方法从传统的手工提取特征过渡到表示学习阶段,深度学习模型的运用能够有效弥合图像底层视觉特征与深层语义特征之间的“语义鸿沟”。李志义等对比传统图像特征提取方法和深度学习方法后,利用改进的VGGNet模型,将增强颜色特征和增强纹理特征的图像分别作为模型输入,以提升图像情感识别的准确率;杨子文等提出一种基于两层迁移卷积神经网络模型的图像情感识别方法,采用ImageNet2012 数据集提取图像普适的底层视觉特征,将底层特征权重迁移至模型结构相同的网络中,利用“Painters by numbers”抽象风格分类数据集微调网络模型来提取图像深层语义特征;蓝亦伦等利用自动编码器构建视觉特征和语义特征联合嵌入网络,缩小两者之间的语义鸿沟,提取图像显著区域特征,引入注意力机制建立显著区域与视觉语义联合嵌入特征两者之间的关联,确定显著情感区域,并在此基础上构建图像情感分类器,实现图像情感分类。为解决缺失情感标签的图像,降低卷积神经网络模型训练性能问题,杨文武等构建大型数据集,并将图像主体与背景分离,在CNN 基础上利用关系学习网络模型提取图像层级特征信息及关系,以弥补图像特征与情感语义之间存在的鸿沟,进而精准实现图像情感分类任务。
目前人脸表情识别、风景及场景图像等成为图像情感识别领域的研究热点,而以颜色搭配、线条手法、纹理特征及抽象主体特写为主要特征的艺术图像相关情感研究不足。艺术图像作为艺术作品的重要表现形式,以显著抽象的视觉特征和显著主体向欣赏者传递情感语义信息,具有情景交融的特点。盛家川等将人类认知与CNN 结合,根据中国画显著性区域和笔道复杂度提取感兴趣区域,利用预训练的GoogLeNet模型提取中国画的深层特征,结合中国画情感表达手法知识,微调模型结构训练参数,提升中国画情感识别的准确率;王征等利用AlexNet模型提取中国画的深层特征并与颜色特征融合,利用SVM 分类器进行情感分类;张浩等以云南少数民族绘画作品为研究对象,分析了图像色相、亮度、饱和度和对比度对神经网络模型情感分类的影响,利用Twitter 数据集提升VGG16模型的学习能力,采用微调的迁移学习策略实现对民族绘画作品的情感分类。
结合目前图像情感识别领域的发展及艺术图像情感识别的现状,本文提出一种基于融合特征和迁移学习的艺术图像情感识别模型HCFNet。首先,在HSV和YCrCb 颜色空间下,分别提取经CLAHE 处理后的H-S 二维特征和CrCb 二维特征,并分别输入对应模型HSNet和CrCbNet,进一步提取艺术图像的颜色特征;其次,基于FPN模型与ResNet101模型部分参数相同,为防止数据集规模较小出现过拟合现象,将ImageNet 中预训练好的ResNet101 部分参数迁移至FPN 中,并对FPN 进行改进,以提取艺术图像的深层情感语义特征;最后,将上述3 种特征利用像素间加法进行融合,输入BN 层和激活函数中,构成本文提出的HCFNet模型。同时考虑在特征融合之前对两种颜色特征给予不同权重,达到模型训练最优状态,提升艺术图像情感识别的准确性。
1 相关工作
1.1 迁移学习
目前,深度学习已经广泛应用在图像情感识别领域中,有效解决图像底层特征和深层特征之间存在的"语义鸿沟"问题,但深度学习同时也需要海量数据集支撑模型的训练,而目前带有情感标签的艺术图像数据集较少,训练卷积神经网络模型时易出现过拟合现象。迁移学习的基本思想是将源领域(大型数据集)中训练好的模型权重转移至目标领域(小样本实验数据集)中结构相同的模型,并利用目标领域微调模型结构,该方法可有效防止深度学习方法在小样本数据集中出现过拟合现象,同时也可以提升模型训练速度,缩短模型训练时间,减少模型参数。在目前计算机视觉领域中,迁移学习已被广泛应用在图像分类、物体识别、目标检测、人脸识别等研究中,随着图像情感语义特征逐渐被关注,越来越多学者证明了将图像对象分类任务迁移至图像情感分类任务中的可行性。
迁移学习方法主要有两种形式,即特征提取和微调。特征提取是指利用预训练模型中全连接层之前的所有参数,提取目标领域中图像特征,并添加新的全连接层或其他分类器,以适应目标任务。而微调方法可以弥补小数据集造成训练不足产生过拟合的现象,通过固定部分卷积层参数提取图像普适特征,微调其它层参数用于训练目标数据集,避免重新训练模型造成参数多训练时间过长的缺陷。Yosinski 等冻结在ImageNet 数据集中预训练的CNN模型部分网络层并进行迁移,该数据集约有120 万张图像,1 000种图像类别,主要分为物体和动物两大类,最后得出CNN模型提取的图像底层视觉特征具有普适性,而深层语义特征适用于与源领域类型相同或相近的小样本目标数据集中。源领域和目标领域样本类别相似度越高,迁移学习效果越好;反之,源领域和目标领域差别越大,迁移学习效果将负方向发展。因此,在使用迁移学习方法进行图像情感分类识别时,可根据实际情况迁移全部或部分预训练模型的参数,并利用实验数据集对模型进行微调,以提升模型分类准确率,防止出现过拟合现象。
1.2 CLAHE 处理
颜色特征是图像最基本的底层视觉特征,蕴含最关键与最敏感的视觉信息。在对图像底层颜色特征研究过程中,多数学者习惯采用颜色直方图表达颜色特征,可直观看出图像像素分布情况。在同一数据集中,图像像素分布参差不齐,针对像素分布不均匀的图像,部分区域较整体图像相比较为明亮或光线较暗,因此采用普通颜色直方图均衡进行全局图像增强时效果不太理想。自适应直方图均衡(AHE)与颜色直方图相比,优势在于该方法通过计算图像每一处显著区域的直方图,重新调节图像亮度值进行均匀分布,以改善图像每个区域的局部对比度,增强图像边缘的清晰度,但AHE 方法容易导致图像产生噪声,进而造成过度增强现象。而限制对比度自适应直方图均衡(CLAHE)与AHE 相比,通过对每一像素邻域的对比度限制,得到对应的变换函数,可有效抑制图像噪声的增强。其原理为在计算邻域的CDF 前,通过定义阈值对直方图进行裁剪,限制CDF 及变换函数的斜率,直方图切割部分使用的定义阈值称作修剪限幅(clip limit),产生的新直方图若仍然超过设定阈值,可适当增加阈值,重新调整,如图1 所示。与原图像相比,经CLAHE方法处理后的图像细节处更为突出,特征更加丰富,颜色直方图较原图像相比也更为平滑,如图2 所示。

图1 CLAHE 原理图Fig.1 The schematic chart of CLAHE
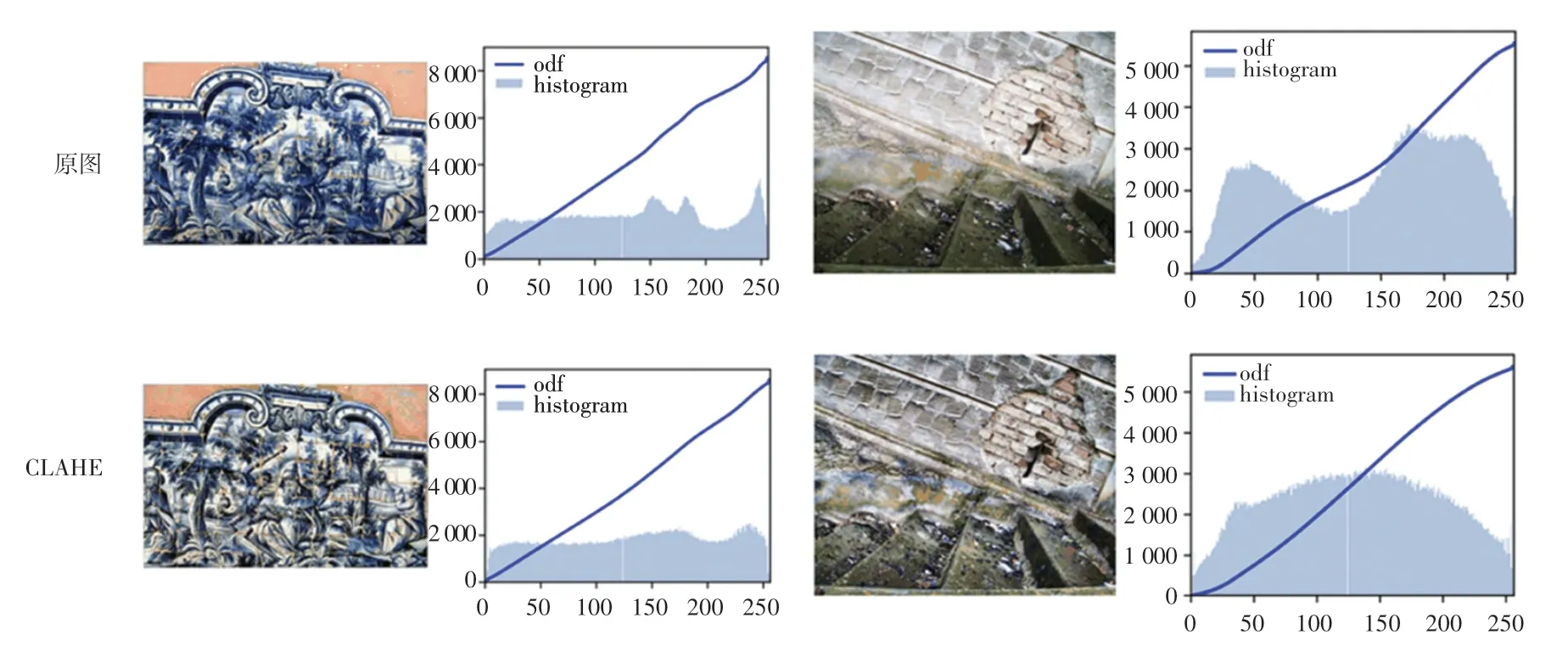
图2 CLAHE 颜色特征可视化示例图Fig.2 The example graph of CLAHE color feature visualization
2 艺术图像特征提取
2.1 H-S 颜色特征
实验证明,在图像底层特征中,颜色特征更能体现图像的情感语义特征。因此,本文实验将在CLAHE 处理后提取图像颜色特征的基础上进行图像颜色特征提取。图像颜色空间除RGB 空间外,还包括HSV、YCrCb 空间等。大量心理学研究表明,HSV 颜色空间更贴近人眼视觉特征,其中(Hue)指色调,即日常描述的红、绿、蓝,用角度度量,取值范围为0~360;(Saturation)指饱和度,即颜色接近光谱度的程度,颜色越接近光谱色,则饱和度越高,进而表明颜色越纯,其取值范围为0.0~1.0;(Value)指亮度,通常取值范围为0.0~1.0。
因此,鉴于图像HSV 空间具有更符合人类视觉对颜色感知的特点,首先将图像从RGB 格式转为HSV 格式,经CLAHE 处理后利用色调-饱和度二维直方图(H-S)方法,提取图像中起显著作用的H-S颜色特征,该二维直方图中色调值()介于0~180之间,饱和度()介于0~256 之间,输入图像对应的H-S 二维直方图可视化效果如图3 所示。
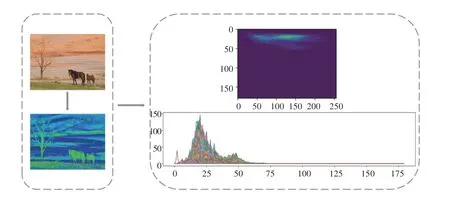
图3 H-S 二维直方图可视化示例图Fig.3 The example graph of H-S two-dimensional histogram visualization
将H-S 二维直方图提取到的颜色特征输入含有两个卷积层、两个最大池化层、一个全连接层、3个BN 层和3个激活层的网络中,其中卷积核大小为3 中卷,64,2,1;最大池化层大小均为2 最大,2;全连接层神经元个数为1 000;3个激活层均使用激活函数;卷积层和全连接层后均连接BN 层,防止模型的过拟合。将该网络模型命名为HSNet,输出结果即为图像的H-S 颜色特征,记为。H-S 颜色特征提取过程如图4 所示。
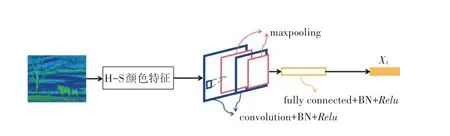
图4 H-S 颜色特征提取Fig.4 H-S color feature extraction map
2.2 CrCb 颜色特征
图像颜色空间除常见的HSV、RGB 外,还存在一种符合人类视觉特征的颜色空间,即YCrCb,又称YUV 颜色空间。YCrCb 主要用于优化彩色视频信号的传输,其中表示颜色的明亮度;表示色调,是颜色中红色部分的分量值;表示饱和度,是颜色中蓝色部分的分量值。基于在YCrCb 颜色空间中,对于图像的"色度"起决定性作用的是、两通道,因此该处在提取颜色特征时,只考虑CrCb二维空间特征。具体方法同上,将图像从RGB 格式转为YCrCb 格式,经CLAHE 处理后利用色调-饱和度二维直方图方法,提取图像中起显著作用的CrCb颜色特征,在该二维空间特征中,色调值()介于16~224 之间,饱和度()介于16~224 之间。针对输入图像,对应CrCb 二维直方图可视化效果如图5 所示。
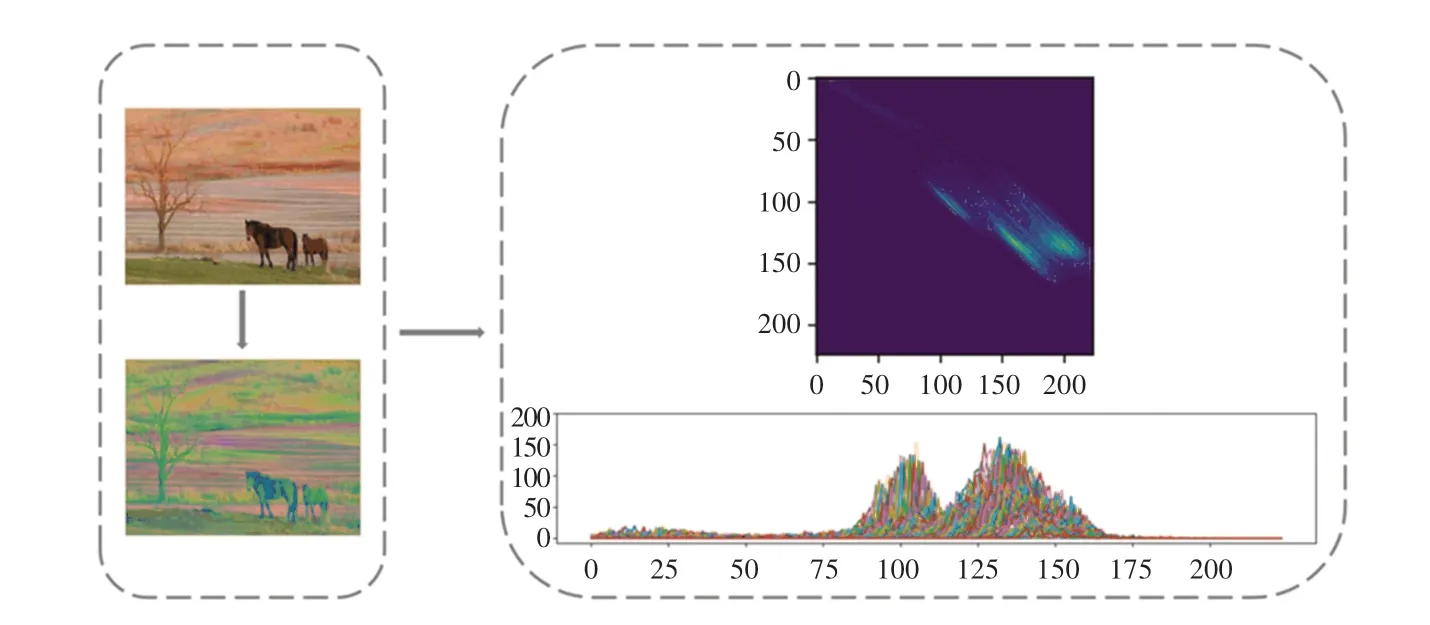
图5 CrCb 二维直方图可视化示例图Fig.5 The example graph of CrCb two-dimensional histogram visualization
将提取到的CrCb 二维直方图特征输入含有两个卷积层、两个最大池化层、一个全连接层、3个BN层和3个激活层的网络中,其中卷积核大小为3 中卷,64,2,1;最大池化层均为2 为大,2;全连接层神经元个数为1 000;3个激活层使用函数;卷积层和全连接层后均连接BN 层防止过拟合。将该网络模型命名为CrCbNet,输出结果即为图像的CrCb 颜色特征,记为。CrCb 颜色特征提取过程如图6 所示。
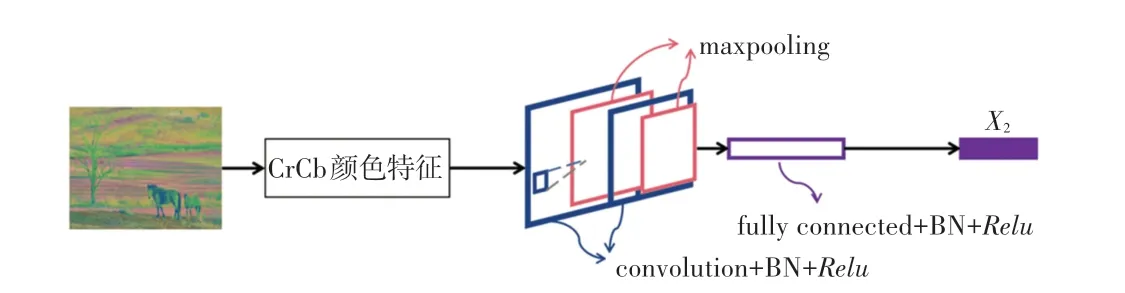
图6 CrCb 颜色特征提取Fig.6 CrCb color feature extraction map
2.3 改进的FPN 特征
2017 年,Lin 等提出了FPN(feature pyramid networks)特征金字塔结构,该网络模型同时兼顾图像的底层特征和深层特征,将低分辨率、高级语义信息的深层特征和高分辨率、低级语义信息的底层特征进行自上而下的侧边连接逐层融合,构成图像多尺度的融合特征,FPN 结构如图7 所示。FPN模型结构大致分为自底而上、自顶而下和横向连接(lateral connection)3 部分。在自底向上阶段,采用卷积神经网络中ResNet模型作为网络主干结构,将conv2_x、conv3_x、conv4_x、conv5_x 各部分最后一个残差结构输出记为{2、3、4、5};而在自顶向下阶段,采用上采样内插值方法,在原有图像像素点之间选取合适的插值算法,插入新的元素,进而扩大原图像的大小,通过对特征图上采样,使特征图具有和下一层的特征图相同的大小,充分利用图像各层的细节信息。
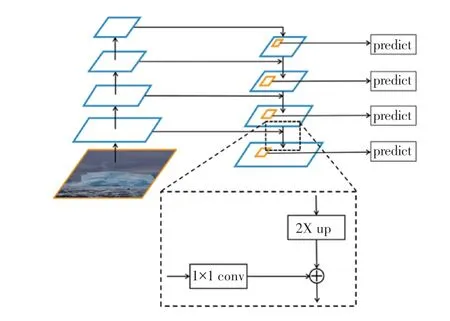
图7 FPN 特征金字塔结构示意图Fig.7 FPN(feature pyramid networks)structure diagram
如图8 所示,自底向上的特征图5 经过11 卷积核卷积得到5,之后通过上采样得到与4 大小一样的特征图,再利用像素间加法将4 通过1×过卷积核卷积后的特征映射与5 上采样特征图相加。为了消除上采样产生的混叠效应,利用3 采样卷积核卷积得到4,重复迭代上述过程,最终得到多尺度特征映射{2、3、4、5}。
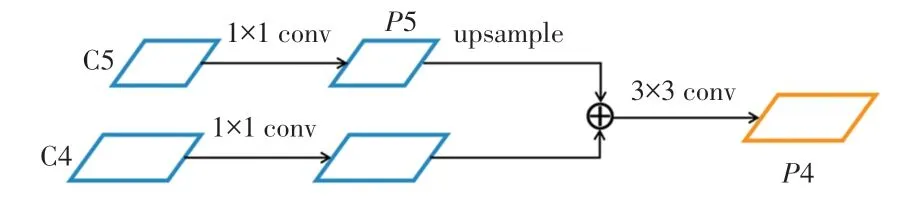
图8 图像特征融合示意图Fig.8 Schematic diagram of Image features fusion
FPN模型是在ResNet模型的基础上构建的,两个模型部分结构参数相同,为防止因数据集较小而出现过拟合的现象,本实验将迁移学习思想与FPN模型结合,截取部分ResNet101模型的预训练参数,并将其应用于训练后续改进的FPN模型。
为充分利用FPN 特征金字塔模型各层特征信息,对FPN模型进行改进,如图9 所示。将{2、3、4、5} 逐一输入到大小为1∗1的自适应的平均池化层中,利用像素间加法原则将输出特征进行融合,得到由改进FPN 特征金字塔模型提取的整体特征,并将该特征先后输入全连接层、BN 层、激活层中,输出结果记为特征。
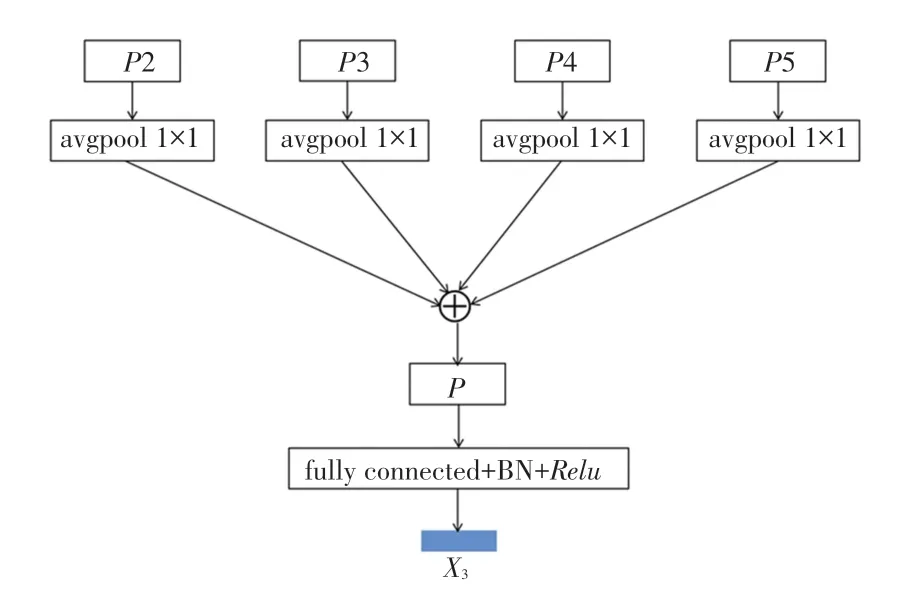
图9 改进FPN 特征提取模型Fig.9 Improved FPN feature extraction map
图像输入改进FPN模型后,模型不同层所提取到的特征可视化效果如图10 所示。随着模型层数的加深,特征图效果越模糊,但从模型第十二层开始,随着层数加深,提取到的图像特征开始逐层融合,特征图变得更为直观具体,情感语义特征更加丰富。
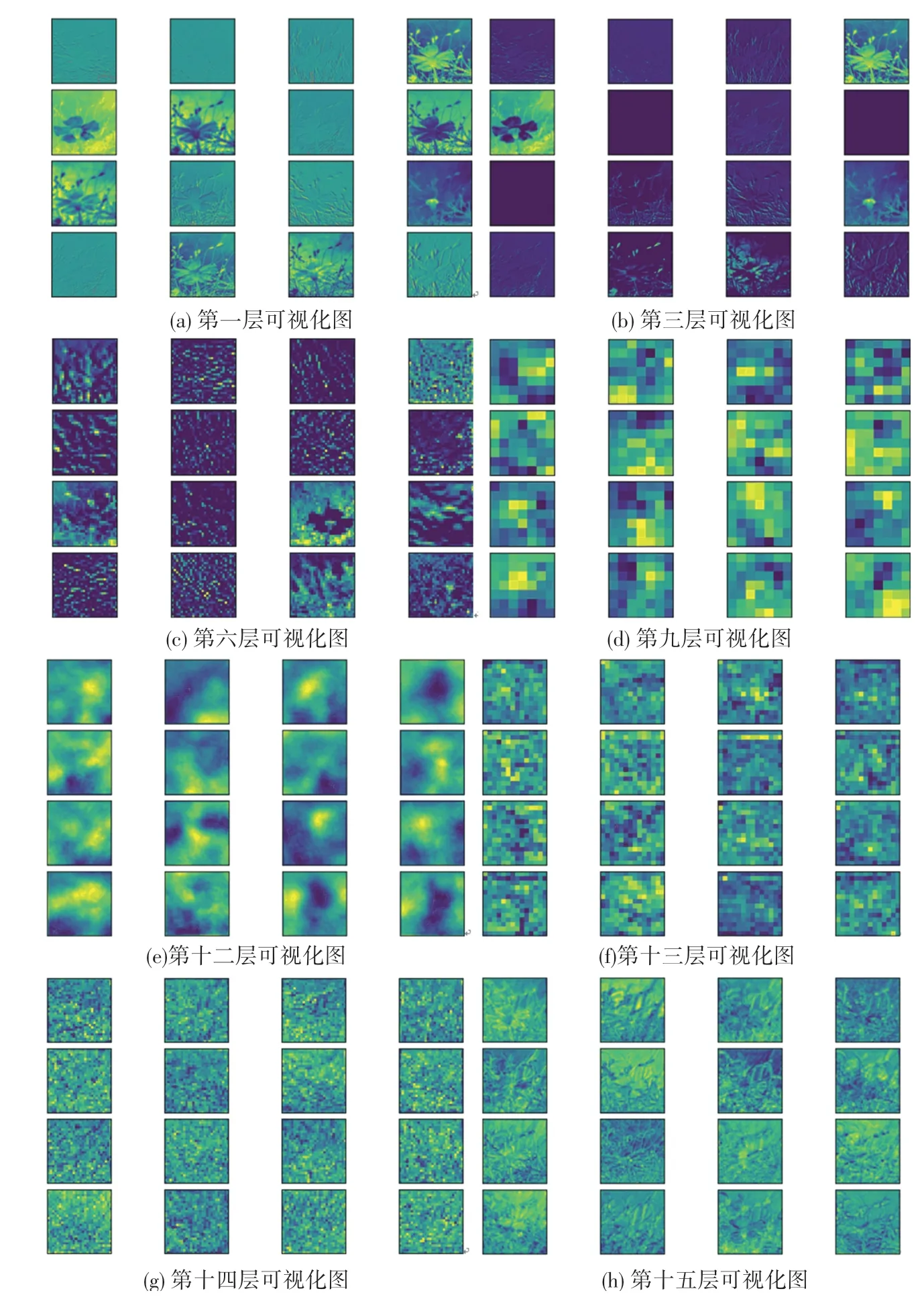
图10 不同层深层特征可视化图Fig.10 Visualization of deep features in different layers
2.4 图像特征融合
将上述提取到的H-S 颜色特征,CrCb 颜色特征及FPN 多尺度融合特征利用像素间加法进行融合,相比于concat 融合方式,该融合方法计算时间短并且参数较少,并将融合后的特征输入BN层和激活函数中。
3 算法主要流程
将本文实验的整体网络模型命名为HCFNet,其网络模型结构如图11 所示。输入的图像大小为224× 24,由于艺术图像的颜色特征处理需在OpenCV 库中进行,因此在提取H-S 颜色特征和CrCb 颜色特征之前需将向量转换为numpy数组形式,再各自进行颜色特征处理;将提取到的二维H-S 颜色特征和CrCb 颜色特征转回张量形式,并分别输入HSNet和CrCbNet 网络中,进一步提取图像颜色特征,HSNet 输出的特征记为,CrCbNet 输出的特征记为,图像输入到改进FPN 网络模型中得到深层语义特征记为;最后,将得到的图像底层特征和深层情感语义特征融合,输入到BN 层和激活函数中,对艺术图像进行情感语义识别。
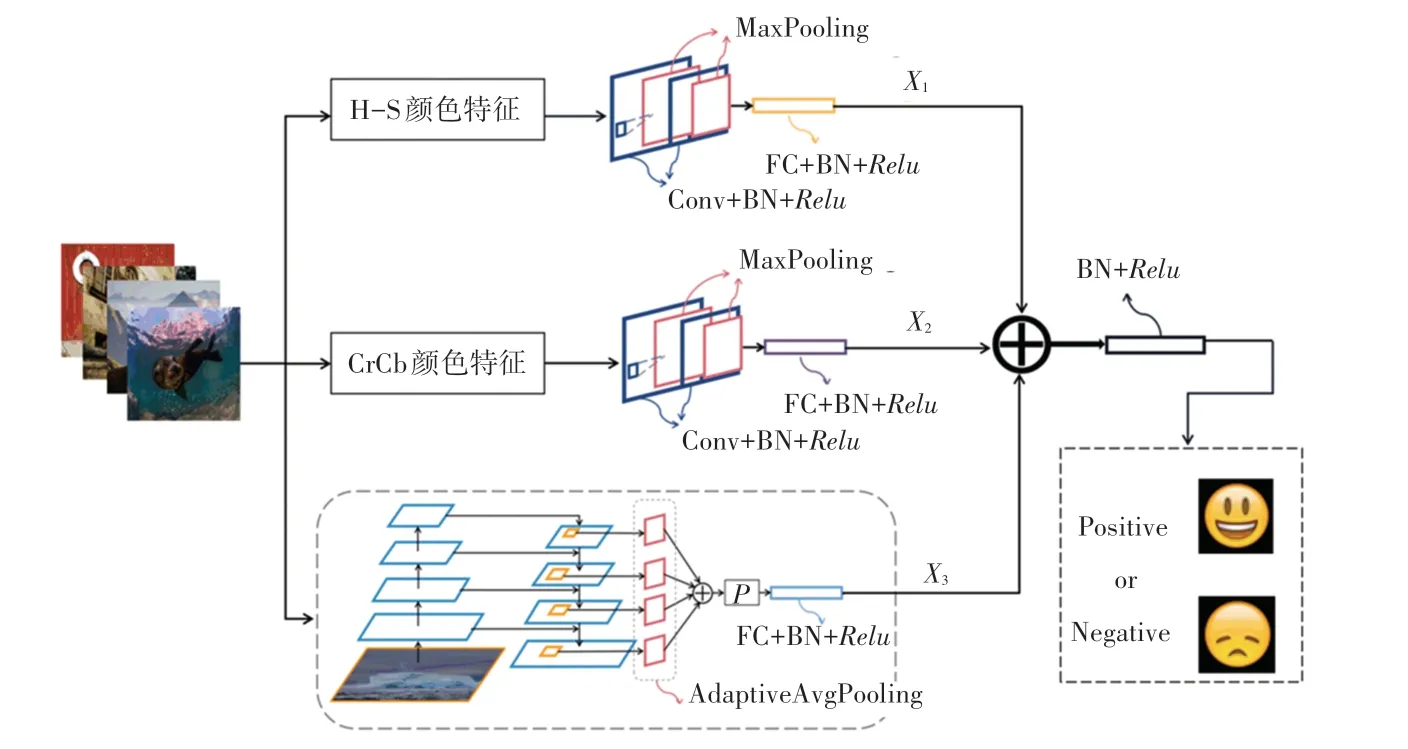
图11 HCFNet 网络模型结构图Fig.11 HCFNet network model structure diagram
4 实验结果与分析
4.1 实验环境
本文实验环境:处理器为Intel i5-8279U,主频2.40 GHZ,实验基于Python 3.7的深度学习框架Pytorch 运行,开发工具为PyCharm,使用Linux 操作系统,GPU 进行训练,GPU 为NVIDIA Tesla V100-SXM2-16GB,显存总量为16 160 MiB。
4.2 实验数据集
4.2.1 数据集介绍
本文实验使用Flickr 公开数据集,图像情感标签共分3 类,分别为Positive、Negative和Neutral。基于Flickr 数据集中Neutral 标签下图像数量较少,因此只保留Positive和Negative 两类情感特征,并人工筛选Positive和Negative 标签下的图像各1 920张,作为本文实验数据集。人工筛选原则为选取具有显著视觉特征、真实情感标签符合原本标定的艺术类情感图像,以保证各类标签下样本图像数量相等,确保情感识别结果均衡。本文数据集各标签的示例图像如图12 所示。

图12 Flickr 数据集示例图像Fig.12 The schematic images of Flickr Dataset
4.2.2 数据集预处理
由于原数据集大多数图像格式是通道数为3的RGB 图像,其中也存在少数灰度图像,其通道数为1,为方便后续实验的展开,在数据预处理阶段统一将图像转为RGB 图像。
4.3 实验评价指标
实验评价指标为图像情感分类准确率(,),表示如式(1):

其中,为测试集样本总数,为测试集中标签预测正确的样本数。
实验采用折交叉验证方法,因此准确率最终为经折交叉验证后准确率的平均值。
4.4 实验结果分析
为证明本文实验方法对艺术图像的情感识别任务有效,在训练过程中,采用五折交叉验证方法,默认迭代轮次为20 轮,学习率设为0.005,批大小设为64,使用交叉熵损失函数,选择SGD 优化器,动量梯度下降参数设置为0.9。
在本文实验中,选择经典卷积神经网络模型VGG16的迁移学习模型、VGG16_BN的迁移学习模型以及未融合迁移学习ResNet101的改进FPN和本文提出的模型算法进行比较,五折交叉验证后测试集的平均准确率见表1。在各模型的五折交叉验证中,选取训练集预测结果最好的一折,并绘制该折训练全过程的准确率及损失值变化情况,各模型的准确率随着迭代次数变化的折线对比图如图13 所示,各模型随迭代次数变化的损失变化折线对比情况如图14 所示。

表1 与经典卷积神经网络模型准确率对比Tab.1 Accuracy comparison with classic CNN models

图13 各模型的准确率变化折线图Fig.13 Line chart of accuracy changes of each model

图14 各模型的损失值变化折线图Fig.14 Line chart of loss value changes of each model
由表1 可知,以改进的FPN模型特征作为主干特征,分别用、和3 组特征组合,逐一对数据集进行训练,所得到的准确率较VGG16的迁移学习模型、VGG16_BN的迁移学习模型以及未融合迁移学习ResNet101的改进FPN模型算法均有所提升。将H-S和CrCb 两个二维颜色特征和,分别与特征融合,所得准确率有所降低;但是横向比较,H-S 二维颜色特征较CrCb 二维颜色特征相比更能反应图像的情感语义信息,由此可说明HSV 颜色空间更能直接影响图像情感特征。而本文所提出的将、和3个特征融合的HCFNet模型准确率高达90.31%,比未融合迁移学习ResNet101的改进FPN模型提升12.55%,比本文改进的FPN模型特征提升0.15%。
结合图13和图14 各模型在训练集的表现情况上看,在训练过程中,基于迁移学习的VGG16和VGG16_BN模型准确率均保持在85%左右,未融合迁移学习ResNet101的改进FPN模型,其准确率从60%上升至80%左右;而、、和(HCFNet)各模型在8 时,准确率已经达到100%。在损失值变化情况方面,基于迁移学习的VGG16、VGG16_BN和未融合迁移学习ResNet101的改进FPN模型的值损失波动幅度较大;相反,、、和(HCFNet)模型的收敛速度非常快,当epoch=13 时,损失值趋近平缓。
基于H-S 特征和CrCb 特征均属于颜色特征范畴,在特征融合前尝试对和给予权重,将给予权重的两个特征与再进行融合,形成加权融合特征,式(2):

其中,权重系数和为1。
给予不同权重后HCFNet模型的测试结果见表2。由表2 可知,对特征和特征给予权重后,随着特征权重系数的增加,HCFNet模型的准确率逐渐提升,当权重系数09,01 时,HCFNet模型准确率最高,能达到90.63%,较未加权的HCFNet模型结果提升0.32%。

表2 加权HCFNet 准确率对比Tab.2 Weighted HCFNet accuracy comparison
综上所述,本文提出的基于融合特征和迁移学习的艺术图像情感识别方法能有效地识别艺术图像情感语义特征,在改进FPN模型中引入迁移学习思想,提取艺术图像的多尺度深层语义特征,在此基础上融合图像的颜色特征,并对不同颜色特征加权,可更好地弥合艺术图像底层特征和深层特征之间的“语义鸿沟”。
5 结束语
本文提出一种基于融合特征和迁移学习的艺术图像情感识别模型HCFNet,充分利用艺术图像的不同颜色空间下的二维颜色特征,即提取H-S 颜色特征和CrCb 颜色特征;将迁移学习思想引入FPN 特征金字塔网络中并进行改进,以多角度提取图像深层语义特征;将3 种特征融合构成本文模型HCFNet。考虑在特征融合之前对两种颜色特征加权,该模型情感识别准确率可达到90.63%,证明本文方法可有效实现艺术图像情感识别任务。
猜你喜欢
高中数理化(2024年1期)2024-03-02 17:52:40
湘潭大学自然科学学报(2022年2期)2022-07-28 05:26:40
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
开放教育研究(2020年2期)2020-03-31 01:54:14
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:02
中国交通信息化(2018年5期)2018-08-21 03:37:40
现代语文(2016年21期)2016-05-25 13:13:44
计算机工程(2015年8期)2015-07-03 12:20:21
