
基于TW-RN优化CNN的煤矸识别方法研究
2022-02-26 07:08郭永存刘普壮
煤炭科学技术 2022年1期
郭永存,王 希,何 磊,刘普壮
(1.安徽理工大学 深部煤矿采动响应与灾害防控国家重点实验室,安徽 淮南 232001;2.矿山智能技术与装备省部共建协同创新中心,安徽 淮南 232001;3.安徽理工大学 矿山智能装备与技术安徽省重点实验室,安徽 淮南 232001;4.安徽理工大学 电气与信息工程学院,安徽 淮南 232001)
0 引 言
机械化开采的普及使原煤中夹矸率不断增高,混杂的矸石一方面会降低煤炭的燃烧效率和能源利用率,另一方面会排放大量烟尘和有毒气体,危害人体健康,污染自然环境,这与我国倡导的绿色发展理念相违背[1],因此分选出原煤中混杂的矸石块是发展洁净煤技术的前提。目前基于X射线的煤矸识别方法成本高,具有辐射危险,且识别率受煤和矸石粒度大小限制[2-3]。在获取目标图像时,与射线法相比,高帧率的CCD、CMOS工业相机不仅对人体无危害、成本低,而且可以获取目标清晰的表面特征[4]。基于机器学习的煤矸识别算法,如:改进SVM算法[4-5],需人工利用图像处理、模式识别技术手动提取煤和矸石图像表面纹理、灰度值等浅层特征,过程繁琐,且提取到的若干个浅层特征无法完全反映煤和矸石区别所在,模型识别准确率低。自卷积神经网络(Convolutional Neural Network, CNN)获得2012年图像分类竞赛冠军(ILSVRC12)以来,深层卷积神经网络的研究很快引起广泛关注,并被成功应用到人脸识别[6]、文本分类[7]、农作物检测[8-9]等领域。在煤矸分选领域中, ALFARZAEAI等[10]基于CNN开发了CGR-CNN煤矸识别模型,并以煤和矸石热图像作为模型输入样本,借助2个试验硬件平台训练了170轮次后,最终的平均测试精度为98.75%。SU等[11]依据LeNet5网络设计适合于煤矸的分类模型,依托煤和矸石各10 000张的训练样本,在IBM Power8服务器上训练10 000轮次,识别率有较大提升。以上研究表明:重新设计并训练一个深度CNN模型需要众多带注释的样本,且模型训练参数较多,试验硬件性能需求较高。这限制了许多深度CNN被应用到小数据煤矸样本的分类问题。
为解决以上问题,国内外学者提出基于迁移学习算法构建深度CNN识别模型,利用较少的样本集就可训练模型参数,且迁移后的模型性能较好[12-14]。同样,也有一些学者引进迁移学习思想构建煤矸识别模型, PU等[15]基于迁移学习技术改进VGG16网络识别煤矸,最终的测试识别率达82.5%。但所用训练样本过少仅200张,且训练时仅优化了全连接层参数,模型学习效果不佳,出现了欠拟合的情况。孙立新[16]使用960张煤和矸石图片训练迁移后的VGG16网络,较原模型的识别率提高了3.25个百分点,但其煤和矸石图片来源于网络或者实验室环境下拍摄,与真实生产环境下的煤和矸石状态有较大差异,识别结果不可靠。徐志强等[17]采集实际生产环境中的煤和矸石图片作为输入,在基于经典CNN网络与轻量级网络构建多种煤矸识别模型时,测试效果不理想,识别精度最高的模型为VGG16,其F1分数值仅为0.921。
针对现有技术问题,笔者通过搭建的机器视觉平台获取了667张多尺度形态、颜色的煤和矸石图像,并采用图像增强技术扩充数据集,增添样本集的多样性。对于小样本煤和矸石数据,设计了一种新的模型优化方法,并构建了4种煤矸识别模型。分析每种模型取不同超参数时的训练结果,进而确定每种网络的最优超参数。采用评估参数对比每种模型改进前后的性能,最终确定了一种可以快速精准分选煤矸石的最优模型。
1 理论基础
1.1 卷积神经网络
CNN基本结构形式如图1所示,是由卷积层、池化层交替组合,外加全连接层和分类器组成的深层网络。CNN的成功应用归因于其出色的多尺度高级特征表示,而不是手工设计低级特征[10]。
交替组合的卷积、池化层构成特征提取器,用于学习煤、矸石表面显而易见的灰度、纹理等特征,以及内部深层语义特征。
全连接层包括扁平化层和隐含层,用于把图像识别任务转化为分类任务。扁平化层把浅层网络提取到的高维特征矩阵转化为一维特征向量。隐含层中每层之间的神经元互相连接,采用Dropout技术随机置零部分神经元权重,弱化无关信息,缓解模型过拟合问题[18]。全连接层综合浅层网络提取到的图像信息输入到softmax分类器,以概率的方式输出图像识别结果。
1.2 深度迁移学习
深度迁移学习(Deep Transfer Learning)将迁移学习算法引用到深度模型的构建过程中,其目标是将在源任务上训练好的网络模型通过简单的参数调整,适用到目标任务[8]。深度迁移学习为基于小数据样本构建模型提供了一种全新的方法。
构建深度迁移学习模型,即将在相似数据集上训练好的网络特征提取层,有效地转移到目标模型中,并根据实际应用重新设计全连接层。与设计并训练一个全新的网络模型相比,参数迁移方法大大减少了参数训练时长,且能够在普通计算机上操作。
2 基于TW-RN的煤矸识别
2.1 TW-RN模型优化方法
CNN网络虽在各领域得到了较好的应用,但网络参数多、计算量大是其一直存在的问题,且参数计算量主要集中在全连接层[19]。原AlexNet、VggNet、ResNet网络中浅层网络提取到的特征图大小分别为6×6×256、7×7×512、7×7×2 048。在把高纬度特征矩阵扁平化为一维向量时, AlexNet和VGGNet采用和特征图同样大小的卷积核进行卷积操作,分别得到9 216、25 088个神经元连接到含有4 096个神经元的隐含层[20-21],这极大增加了全连接层的计算量。ResNet则是采用全局平均池化(Global Average Pooling, GAP)[19]思想,以每张特征图的全部像素值为对象作均值池化,得到2 048个特征点连接到隐含层,从而减少了全连接层的参数[22]。
ResNet虽然发现并改善了全连接层计算量大的问题,但对于煤矸石二分类问题,2 048个神经元仍显得有些冗余,容易导致模型过拟合。即使采用了Dropout、L2正则化等技术,但仍没有解决以上问题。
为节省构建煤矸识别模型的训练成本,降低模型参数量,提出一种新的模型优化方法——迁移权重&简化神经元(Transfer Weight-Reduce Neurons, TW-RN)。TW-RN模型优化方法的目标是直接迁移预训练模型的浅层权重参数,同时在CNN扁平化层中采用GAP技术降低神经元个数, TW-RN模型优化方法的思路如图2所示。
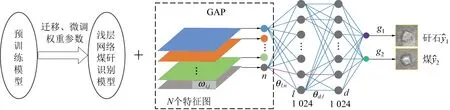
图2 TW-RN模型优化方法
假设浅层网络提取到的特征图个数为N,大小为M×M,则第n个(n=1,2,…,N)个特征图经GAP降维后的输出cn为:
(1)
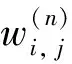
第1个隐含层中第l(l=1,2,…,1 024)个神经元的输出yl为:
(2)
式中:f为ReLU激活函数;θl, n为第1个隐含层与扁平化层之间的连接权值;bl为对应的偏置项。
同理,第2个隐含层中第d个(d=1,2,…,1 024)个神经元的输出zd为:
(3)
式中:θd, l为第2个隐含层与第1个隐含层神经元之间的连接权值;bd为对应的偏置项。

(4)
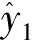
2.2 煤矸识别模型的构建
为验证TW-RN模型优化方法的有效性,基于TW-RN法,分别对AlexNet、VGG16、VGG19、ResNet50四种网络进行改进,构建Im_AlexNet、Im_VGG16、Im_VGG19、Im_ResNet50煤矸石识别模型。模型改进思路如图3所示。
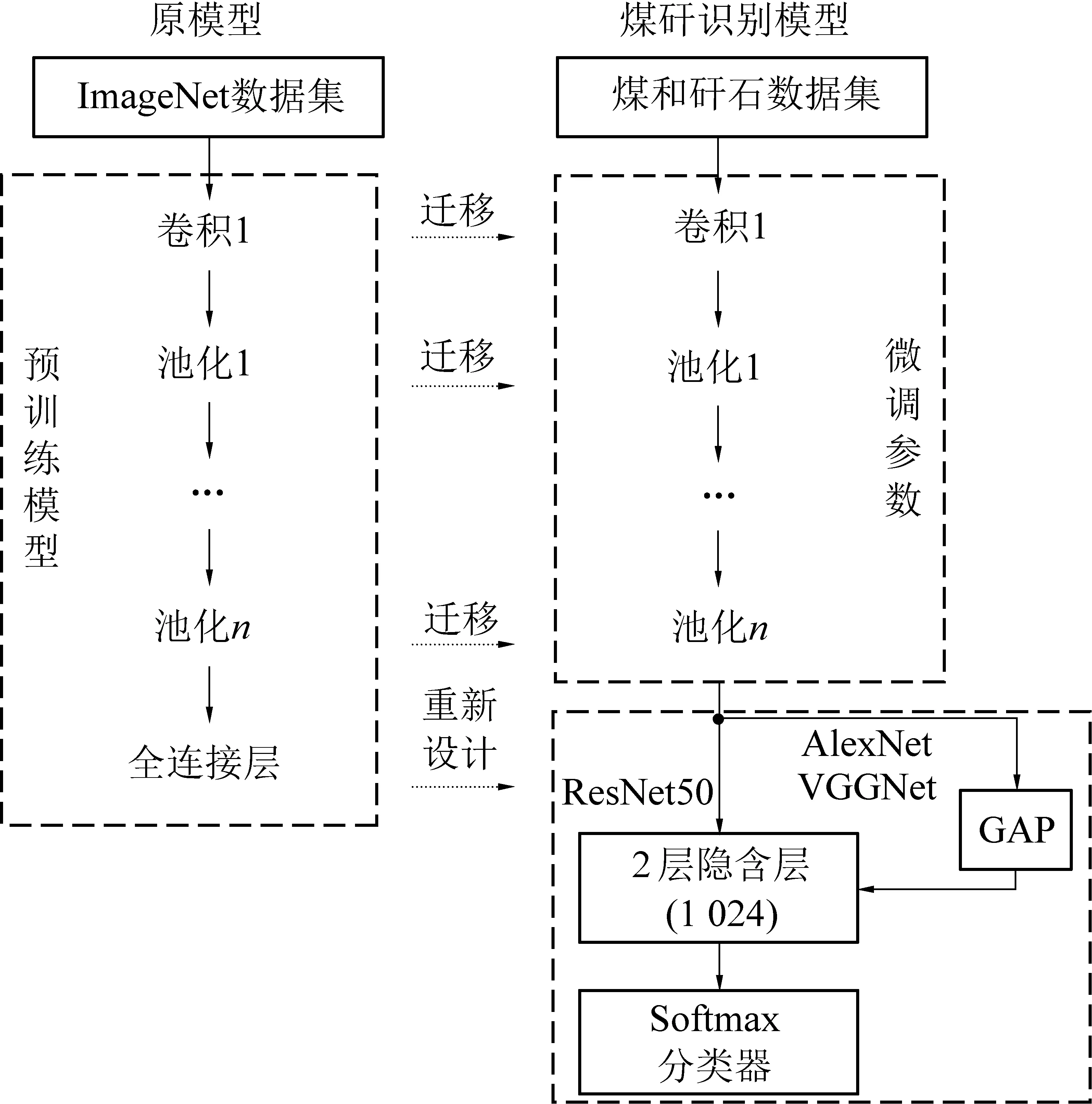
图3 模型改进思路
首先采用迁移思想,把在ImageNet数据子集上训练好的浅层网络权重迁移到煤矸识别模型中。其次,根据图4所示方法优化模型全连接层, Im_AlexNet在卷积、池化层后添加GAP,直接把256维6×6大小的特征矩阵转为256×1的列向量。由此,连接到隐含层神经元的个数由9 216降为256个;同样, Im_VGG16、Im_VGG19网络采用GAP技术,把原输入到隐含层的25 088个神经元降为512个,同时2个隐含层的神经元数降为1 024个,实现全连接层的参数降维。因原ResNet50网络已采用GAP正则化技术,所以只把隐含层神经元个数降为1 024个。在训练模型时,对于网络全连接层参数,全部重新设置更新。
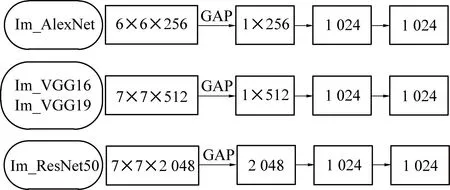
图4 模型全连接层改进方法
2.3 煤矸识别仿真试验设计
首先依据扩充后形态各异的煤矸训练样本,对每种模型的优化器类型、学习率进行了寻优仿真试验,确定基于TW-RN法设计的几种模型的最优超参数。然后再基于划分好的煤矸测试集,试验对比改进前后的每种模型的效果,确定一种煤矸识别最佳模型,仿真试验过程如图5所示。
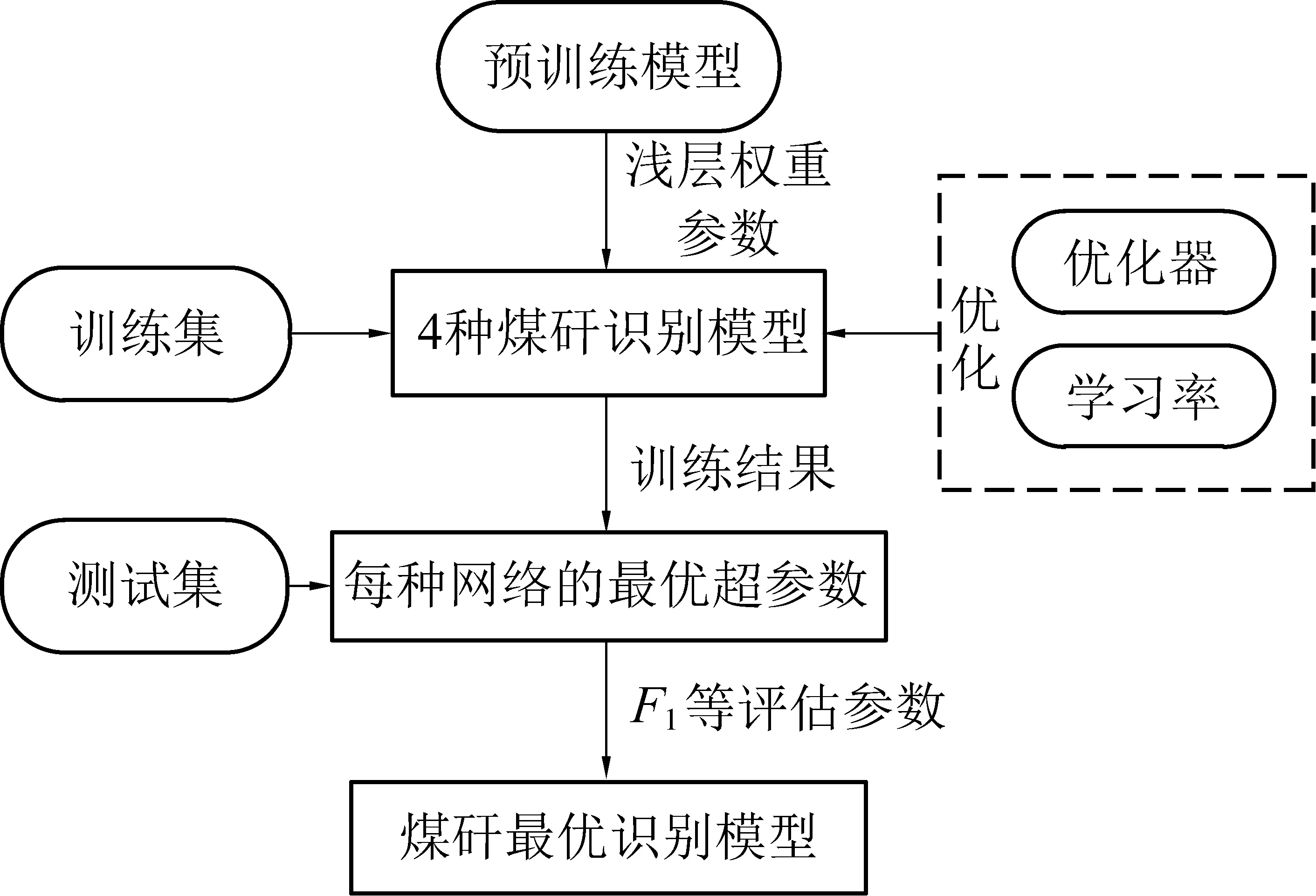
图5 仿真试验过程
参数寻优仿真试验时,网络反向传播中参数优化方法分别选择自适应动量估计方法Adam(Adaptive moment estimation)、带动量因子的随机梯度下降方法SGD(Stochastic Gradient Descent)。将浅层网络的学习率统一设置为0.000 1,微调网络权重;全连接层的学习率分为固定0.001不变和自适应调节(简称Self-A)2种情况,自适应调节方式即为每隔20个轮次,学习率自动下降为原来的10%[23]。每种模型在4组不同超参数下进行仿真试验,4种模型共进行16组试验。
模型中其他部分超参数统一设置:输入图片大小为224×224×3,图片3个通道的特征标准化均值为[0.485,0.456,0.406]、方差为[0.229,0.224,0.225],全连接层中神经元随机置零概率为0.5,自适应学习率初始值为0.01, SGD优化器中的动量因子为0.9,总训练轮数epoch为100,参数更新迭代次数interation为3 200,每次迭代的训练图片数batch_size为64。并采用交叉熵损失函数计算每张图片的训练损失值以及每轮次的测试损失值。
3 试验平台设计
3.1 数据集采集
为增强分类模型的鲁棒性和泛化能力,在实验室搭建试验样本采集装置如图6所示。模仿实际生产环境中原煤表面附着有煤灰、输送带表面颜色为灰色时的工作状态,采集运送状态下的样本图像。

图6 试验样本采集装置
输送机的速度设为0.3 m/s;2根条形LED白光灯作为辅助光源,通过调节光源控制器将摄像区域光强稳定在(2 400±20)Lux;彩色CMOS工业面阵相机帧率为35 fps、分辨率为2 448×2 048。工况机与工业相机之间使用USB3.0接口通信,显示采集画面并保存图像。
煤和矸石部分样本图像如图7所示,包含3种不同质地的煤块和2种不同颜色的矸石,具体表现为表面光亮常具裂缝的黑色亮煤、表面半亮呈极薄层状的黑色镜煤、表面暗淡粗糙的灰黑色暗煤,以及黑矸、灰矸,煤和矸石的粒径均分布在40~120 mm。试验共采集煤图片322张,矸石图片345张。

图7 煤和矸石部分样本图像
仿真试验环境为:Windows10系统, AMD Ryzen7 4800H处理器、16 GB内存, NVIDIA RTX2060型号显卡、6 GB独显。基于Pytorch框架搭建煤矸识别深度网络,通过CUDA(Compute Unified Device Architecture)加速训练过程。
3.2 数据集预处理
煤和矸石数据集预处理过程如图8所示。深度学习训练模型参数时,训练样本越多,学习模型的泛化能力越高,误差率越低[24]。由于试验材料、时间成本问题,试验采集的煤和矸石的图像数量有限,故需扩充样本图像,增添输入样本的多样性。

图8 煤和矸石数据集预处理过程
数据集扩充方法如图9所示,可描述为:首先分别将煤和矸图片绕x、y轴翻转以及向右旋转180°,然后,选取部分样本图像添加高斯噪声和椒盐噪声,用于模仿实际生产环境中的运动模糊图像。考虑到煤和矸石的光泽差异是分类的重要参照,因此不对图片进行亮度和对比度处理。
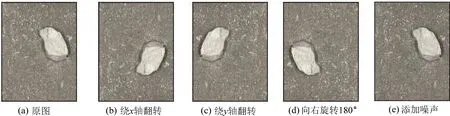
图9 数据集扩充方法
对原数据集进行扩充后共获得煤和矸石图像2 905张,其中矸石图像1 519张,煤图像1 386张。为避免样本不平衡问题的干扰[25],同时剔除冗余样本图像,选取了煤、矸石图像各1 280张。然后按照80%、20%的划分方法,分别把煤和矸石数据集划分为训练集、测试集,并且2个数据集之间无交叉。
4 试验结果与分析
4.1 评估参数
F1分数(F1Score)是用来衡量二分类模型精确度的一种指标,可以看作是模型查准率(P)和召回率(R)的一种加权平均,值域在[0,1],值越大代表模型识别精度越高。
在图像预处理过程中煤标签设置为0,矸石的标签为1。作以下定义,见表1。
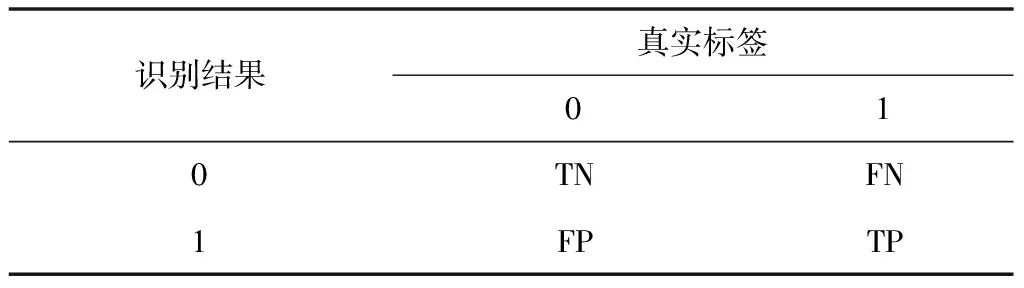
表1 实际值与预测值关系
F1分数计算公式如下
F1=2PR/(P+R)
(5)
其中,准确率P为
P=TP/(TP+FP)
(6)
召回率R为
R=TP/(TP+FN)
(7)
4.2 模型超参数确定
对于改进后的Im_AlexNet等4种煤矸识别模型,分别对其设置表2中4组不同超参数。经训练后,每种模型得到4组不同的训练结果, 如图10所示。图10a—图10d分别为Im_AlexNet、Im_VGG16、Im_VGG19、Im_ResNet50的训练结果。
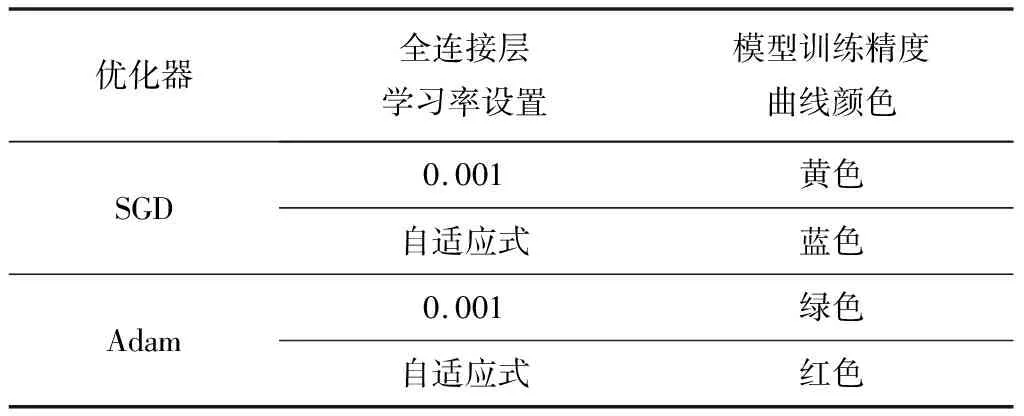
表2 网络超参数设置
由图10知, Im_AlexNet模型的优化器类型设为SGD时,比设为Adam的准确率要高且更快趋于平稳;并且在学习率设置为自适应时,参数曲线收敛速度进一步提高。Im_VGG16模型在选择Adam优化类型时,其损失值能够快速收敛在一定范围内,同时准确率快速达到100%并趋于平稳;而且学习率选择自适应调节类型,曲线收敛更快。Im_VGG19和Im_VGG16模型有类似的性能曲线:选择Adam优化器搭配自适应学习率的参数更新方式,能够使模型训练曲线最佳。由于ResNet50本身的结构较复杂,改进后的Im_ResNet50分类模型在训练集上的表现相对不佳。对比4组超参数下的训练结果可知,采用SGD优化器搭配自适应学习率的训练方法相对较好,参数曲线最终在较小范围内收敛。

图10 优化模型的训练结果
综上所述,基于TW-RN优化方法构建的4种模型,都有适应于自身网络结构特点的最佳参数更新方法和学习率设置方式,各模型的最优超参数设置见表3。
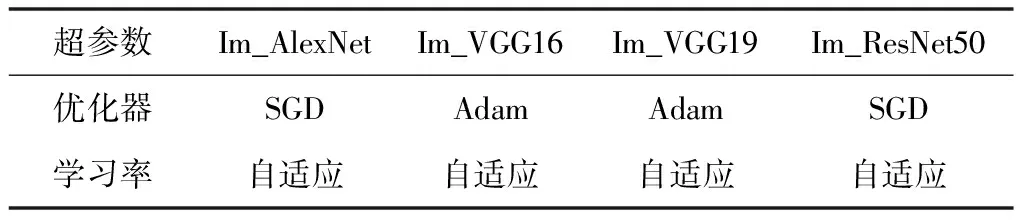
表3 优化模型的最优超参数
4.3 模型效果分析
为验证基于TW-RN法构建模型的有效性,并确定煤矸最优识别模型。在试验样本集、试验环境以及超参数设置相同的情况下,对比各模型改进前后的性能,各模型的测试准确率如图11所示。
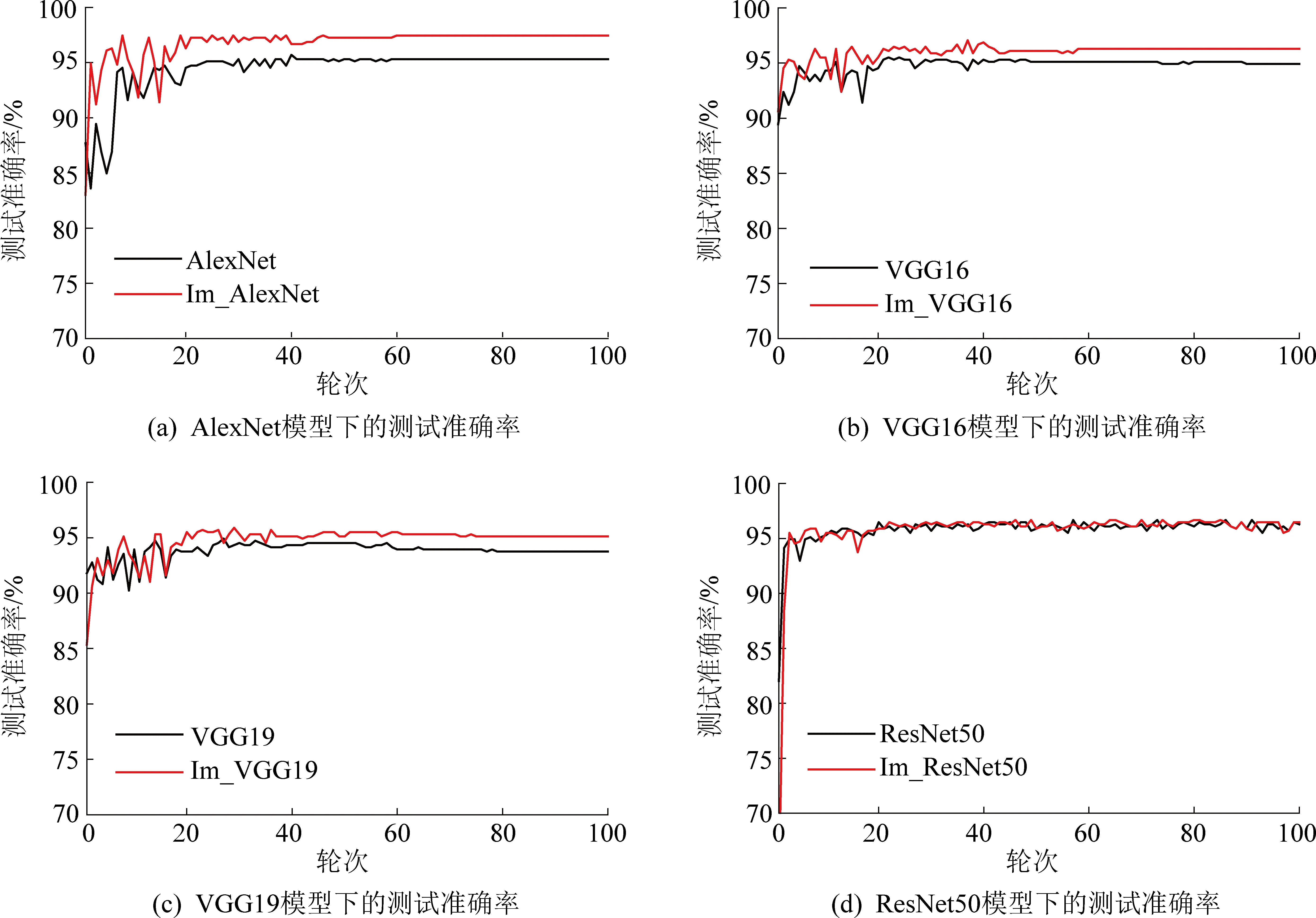
图11 4种最优网络模型的测试精度
为更好地对比模型改进前后的性能,采用测试准确率、F1分数、模型内存大小、训练时间4个评估参数,对改进前后的每种模型进行定量分析,分析结果见表4。
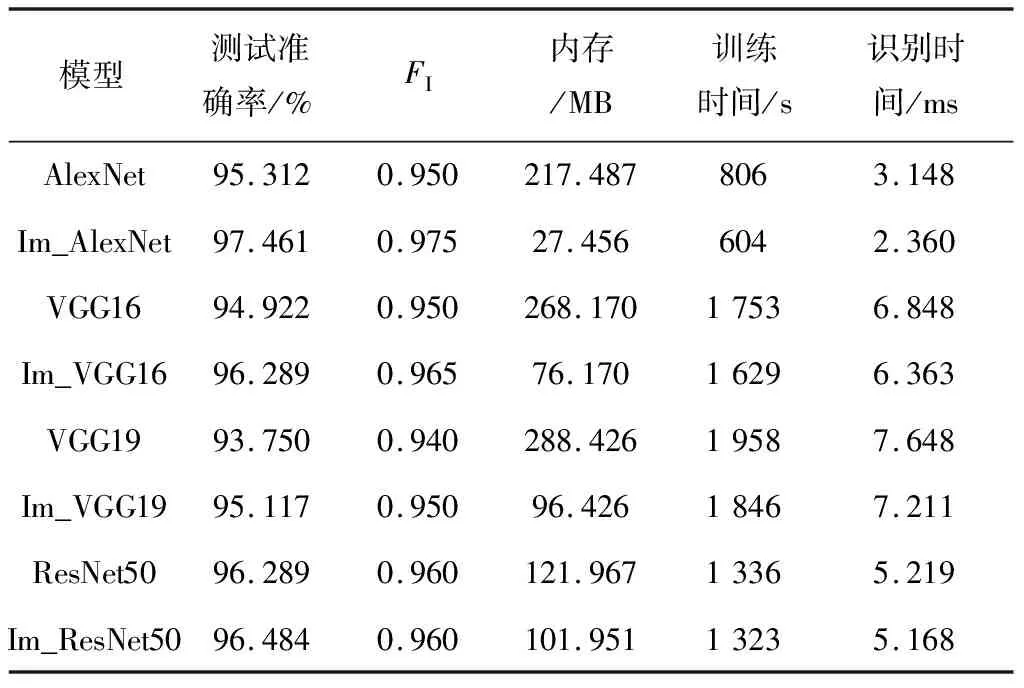
表4 模型评估结果
Im_ResNet50相比原模型,在测试准确率未降低的基础上,减少了占用内存,节省了训练时间。由此可见,对于煤矸二分类任务,降低复杂网络中的神经元个数,并不会影响煤和矸石的有效特征提取。改进后的Im_AlexNet、Im_VGG16、Im_VGG19三种模型均增加了GAP技术,提高了模型对煤和矸石图片特征空间位移的泛化能力,进而提升了识别精度,降低了模型占用内存。
Im_VGG16和Im_VGG19两种模型由于其本身的深层串联式结构特点,导致训练时间较长。虽在训练集上性能表现较好,但总参数计算量依然较大,在测试集上出现了过拟合的情况。ResNet50模型由于自身结构较复杂,即使降低了神经元个数, Im_ResNet50的参数计算量仍很大,导致测试准确率曲线难以快速收敛。
改进后的4个模型中,基于TW-RN优化方法构建的Im_AlexNet煤矸识别模型较原模型在各方面的提升最大。模型训练100轮次的时长仅需10 min 4 s,占用内存仅28 115 kB,单张图片的识别时间为2.360 ms,识别率达97.461%。
综上所述, Im_AlexNet煤矸识别模型可精准识别出多种形态、粒径的煤矸石,且模型泛化能力高,鲁棒性强。
5 结 论
1)TW-RN模型优化方法中的权值迁移能够节省模型训练时间, GAP则能够大大降低神经元个数和计算量,同时保护煤和矸石特征的空间信息。TW-RN法不但能够成功解决煤矸小样本数据集难以构建深度模型的问题,而且也能够缓解模型中全连接参数多、计算量大的问题,提升模型识别率。
2)对于煤、矸石二分类任务,基于TW-RN法优化的Im_AlexNet网络模型识别率最高,达97.461%,较改进之前提高了2.149个百分点;占用内存仅为27.456 MB,较原模型减少了87%;训练100个轮次的时间为604 s,识别单张图片的时间为2.360 ms,提升了0.788 ms。
3)8层的Im_AlexNet模型就可以快速精准识别出煤矸石。结构复杂度较高的模型反而因特征提取能力太强,导致提取到的煤、矸石的相似信息过多,出现过识别的情况。
猜你喜欢
煤炭科学技术(2022年3期)2022-04-29
煤炭学报(2022年3期)2022-04-01
科学与财富(2021年35期)2021-05-10
电子产品世界(2021年8期)2021-01-16
智富时代(2019年7期)2019-08-16
智富时代(2019年7期)2019-08-16
中国计算机报(2019年49期)2019-02-07
中国新闻周刊(2017年36期)2017-10-21
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
