
基于改进蚁群优化算法的云计算资源调度
2022-02-25 14:45肖耀涛
微型电脑应用 2022年2期
肖耀涛
(广东邮电职业技术学院, 软件学院, 广东, 广州 510630)
0 引言
随着网络技术的高速发展,云计算通过并行计算与分布式计算逐步发展而来[1]。传统的服务模式因云计算的应用发生变化。当前云计算主要是将数据中心的各种资源采用虚拟化技术形成虚拟资源池,并通过虚拟货源池将资源提供给用户[2]。现阶段云计算相关研究中,资源分配与任务调度十分热门,因为相较于传统并行计算及其他计算方法,云计算具有自治性以及动态性[3]。
为研究云计算资源调度问题,许多学者对此进行研究。如黄伟建等[4]研究了基于混沌猫群算法的云计算多目标任务调度,李卫星[5]研究基于改进共生优化算法的云计算资源调度优化,但当资源量增大时,依然存在难以调度等问题。
蚁群优化算法来源于自然界蚂蚁觅食时,找到食物源至蚁穴的最短路径[6]。每只蚂蚁在寻找食物时,为了防止迷路,在爬行过程中会将一种化学物质信息素(Pheromone)释放在路径上[7],使得其爬行范围可以被其他蚂蚁感知到。当同一路径上走过的蚂蚁逐渐增多,该路径上的信息素浓度也逐渐提高,因此蚂蚁选择路径觅食概率也随之增加,导致此路径信息素浓度持续加大。蚁群优化算法的求解过程中,并不需要人工干预,并且求解结果不依靠初始路线规划,同时此算法复杂度较低。但蚁群优化算法的计算规模较小[8],一旦应用场景规模较大时,该算法稳定性较低。因此,现有的蚁群优化算法并不适合大规模的云计算资源环境[9],由于其收敛性在资源数量增多时变得较差,极易陷入局部最优解[10]。因此,本文研究基于改进蚁群优化算法的云计算资源调度,设计云计算资源调度模型,应用改进蚁群优化算法实现云计算资源的最佳调度,便于资源规模达到用户需求。
1 基于改进蚁群优化算法的云计算资源调度研究
1.1 云计算资源调度模型
很多复杂的资源都存储在云计算模块内,为快速完成并解决用户资源调度问题,必须选择最佳的资源调度方案。采用Map/Reduce思想的编程模型规划云计算模型,设计资源调度模型如图1所示,该模型采用改进蚁群优化算法对大规模云计算资源数据集进行调度处理。对云计算资源进行调度,用户提交数据集后,调度过程进行切分数据集,即进行数据集分布式化,将用户提交的数据集切分为多个子数据集,并移交至调度中心,最终根据改进蚁群优化算法,向虚拟资源节点调度每个子数据集。
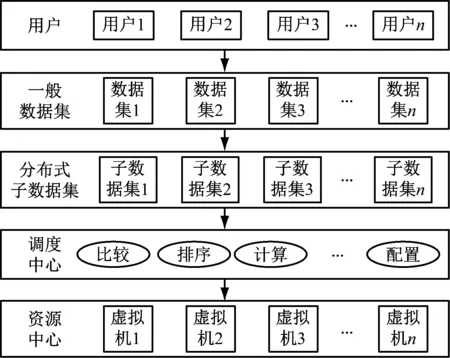
图1 资源调度模型
1.2 资源调度的相关定义
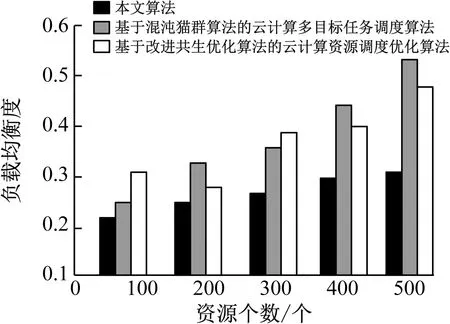
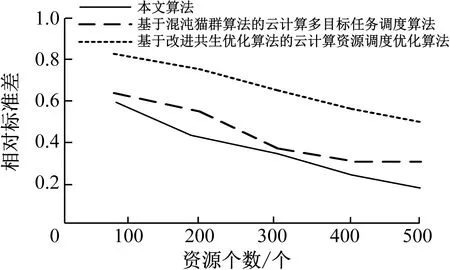
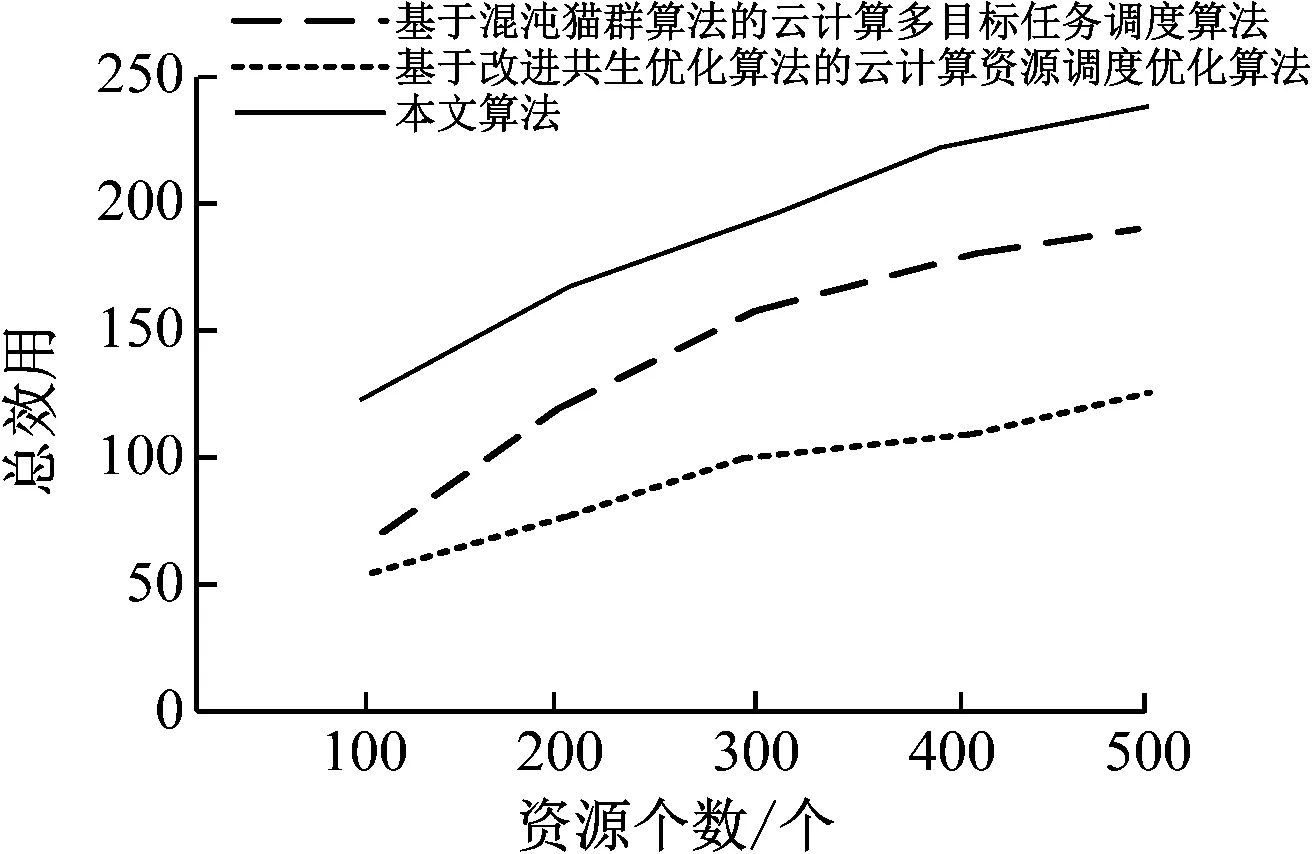
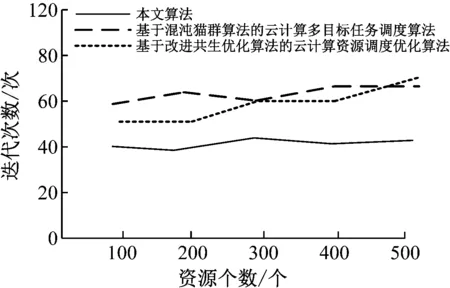
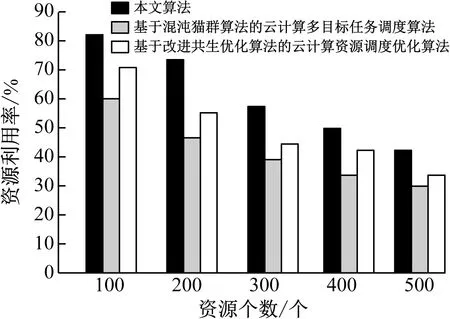
依据算法向m个虚拟机节点上(m (1)n个待执行独立资源的集合用T={T1,T2,…,Tj,…,Tn}描述; (2)m个虚拟机处理资源的节点用V={V1,V2,…,Vi,…,Vm}描述; (3) 虚拟机节点Vi单位时间内处理的指令数用MIPSi描述,以每秒百万计,m个虚拟机的计算能力用MIPS={MIPS1,MIPS2,…,MIPSm}描述,即计算速度; (4) 用矩阵M描述资源与虚拟机节点之间的映射关系,若资源Tj被分配至虚拟机节点Vi上进行调度,则Mij=1,否则Mij=0,其中Mij为矩阵中的元素,M的形式如式(1), (1) (5) 第i个虚拟机内第j个子数据集的执行时间,即资源的期望执行时间的表达式如式(2): (2) 可由上述矩阵计算,每个虚拟机Vi执行子数据集的时间,如式(3), (3) 式中,n表示虚拟机Vi执行的子数据集数量,Time(i,h)表示虚拟机Vi执行第j个子数据集的时间。 1.3.1 蚁群优化算法 若云计算环境内,有待处理资源n个,等待执行任务虚拟机m个,蚂蚁x只,当蚂蚁寻找食物时,信息素会残留在路径上,依据信息素浓度,下一只蚂蚁选择觅食路径,用式(4)表示路径选择的概率: (4) 随着蚂蚁最佳路径选择时,信息素浓度产生变化,用式(5)表示: (5) 1.3.2 蚁群算法的改进 (1) 改进选择下一节点概率计算公式 蚂蚁从当前节点i选择节点j,在改进算法中,用式(6)表示: (6) 式中,q为随机数。 当q (2) 改进启发因子β 在标准蚁群算法初始阶段中,信息素值是固定的,β值是固定的,由式(6)可知,解的搜索并未由此时的信息素指导,信息素值会随着算法运行,而依据不同路径持续更新,使全局最优解信息体现出来,提升了此时信息素的作用,所以将启发因子β设计为一个减函数,用式(7)表示,其具有迭代次数。 β(i)=b1/i (7) 式中,i表示当前迭代次数,b是常数。随着增加循环次数,β值逐渐变小。β值在初始阶段较大,是因为探索路径依赖于启发信息,使算法的收敛速度提升。后期搜索路径利用信息素和启发值,使信息素的指导作用充分发挥,在选择路径时依赖信息素强度。 (3) 改进信息素的更新 当蚂蚁选中边(i,j)时,更新边(i,j)上的信息素,利用式(8)进行: τij=(1-ρ)τij+ρΔτij Δτij=Q/lk (8) 式中,本次迭代时,lk表示第k只蚂蚁已走过路径的长度。 为提升蚂蚁选择其他边的概率,要在蚂蚁选择一条边时,适量减少此边的信息素,全部蚂蚁走过一次循环后,为使搜索最佳路径的概率逐渐加大,需进行信息素的全局更新,通过式(9)执行, τij(t+1)=(1-ρ)τij(t)+ρΔτij(t) (9) 式中,Lgbest表示现阶段获得的最优路径长度。 1.3.3 改进蚁群算法的云计算资源调度步骤 (1) 对云计算虚拟机资源数、节点数、迭代次数以及信息素进行初始化,即初始化算法参数。 (2) 在虚拟机节点上,随机放置X只蚂蚁。 (3) 对蚂蚁个体移动至下一虚拟机节点的概率进行计算,然后将蚂蚁依照计算结果移动。 (4) 对蚂蚁走过路径的信息素进行局部更新,然后将对应的禁忌表进行修改。 (5) 对步骤(2)—(4)进行重复,直至某一条可行的路径被蚁群中的每个蚂蚁个体找到。 (6) 对所有路径的信息素进行全局更新。 (7) 将迭代次数增加,获取调度过程的最优解是指,其值已达到预设的最大迭代次数,最终停止搜索。 采用CloudSim仿真平台进行实验,其支持云计算的基础设施建设,利用datacenterbroker实现云任务到虚拟机的匹配。模拟采用500个虚拟计算资源进行调度,并选取文献[4]基于混沌猫群算法的云计算多目标任务调度算法、文献[5]基于改进共生优化算法的云计算资源调度优化算法与本文算法进行对比,分析不同算法下的负载均衡度,结果如图2所示。由图2可知,随着资源个数的增加,不同算法的负载均衡度也随之增加,基于混沌猫群算法的云计算多目标任务调度算法在资源个数为200、400、500时,负载均衡度要高于基于改进共生优化算法的云计算资源调度优化算法与本文算法,基于改进共生优化算法的云计算资源调度优化算法在资源个数为100、300时,负载均衡度高于基于混沌猫群算法的云计算多目标任务调度算法与本文算法,但本文算法的负载均衡度始终最低,因此本文算法在实现负载均衡方面具有较好效果。 图2 不同算法负载均衡度比较 3种算法在虚拟机上的负载均衡相对标准差统计结果如图3所示。由图3可知,基于改进共生优化算法的云计算资源调度优化算法的相对标准差较大,始终大于本文算法与基于混沌猫群算法的云计算多目标任务调度算法,说明资源分配并不均匀,而本文算法的相对标准差始终最低。这是由于本文方法利用蚁群算法的信息素的扩散和更新的特性,将云计算资源调度进行了全局搜索,使资源进行较为均匀的分配。 图3 资源分配相对标准差 对比不同算法的总效用值,分析结果如图4所示。 由图4可知,随着资源个数的增加,不同算法的调度总效用值也随之提升,但基于混沌猫群算法的云计算多目标任务调度算法与基于改进共生优化算法的云计算资源调度优化算法的调度总效用值始终低于本文算法,本文算法调度总效用始终都是最大的。这是由于本文算法利用蚁群优化算法将选择节点的范围扩大,避免陷入局部最优解,进而可最大程度满足用户资源调度需求。 图4 不同算法的总效用值对比 对不同资源个数下3种算法调度所需的迭代次数进行计算,分析不同算法的收敛特性,分析结果如图5所示。由图5可知,3种算法随着资源个数的增加产生迭代,但基于混沌猫群算法的云计算多目标任务调度算法与基于改进共生优化算法的云计算资源调度优化算法的迭代次数始终大于本文算法,且随着资源个数增加,迭代次数变化波动较大,说明本文算法有较好的收敛特性,仅需较少的迭代次数便可达到较好的资源调度效果。 图5 不同算法收敛特性对比 在不同资源个数下,对不同算法调度后的资源利用率进行比较,分析资源库应用不同算法的资源调度情况,分析结果如图6所示。 图6 不同算法资源利用率对比 对图6进行分析,随着资源个数的上升,不同算法调度后的资源利用率也逐渐下降,基于改进共生优化算法的云计算资源调度优化算法应用后的资源利用率始终高于基于混沌猫群算法的云计算多目标任务调度算法,但本文算法应用后的资源利用率同时高于2种用来比较的算法。表明本文算法应用后可提升资源库中资源利用率,优势显著。这是由于本文算法应用信息素及时更新资源调度节点,避免了计算的冗余,使资源调度的计算量减少,且单位时间内能够处理更多的资源量。 本文研究基于改进蚁群优化算法的云计算资源调度,对云计算资源调度问题进行深入分析。采用云计算模型并通过对蚁群优化算法进行改进,以达到最佳的云计算资源调度。在未来阶段,可在此基础上进行加深研究,提升算法的运行时间,使用户可以更高效地进行资源调度。1.3 基于改进蚁群算法的优化调度
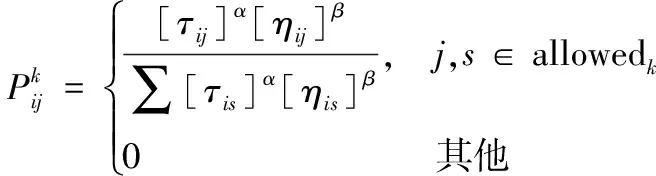
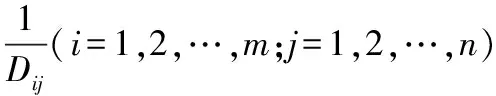
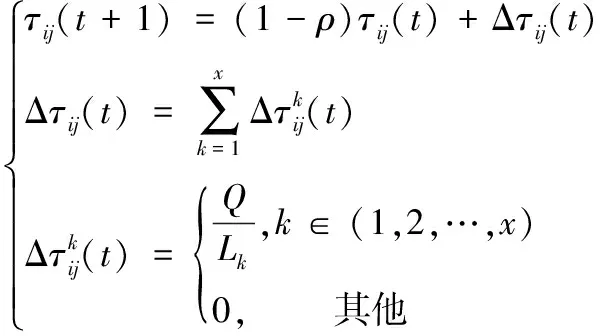
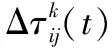
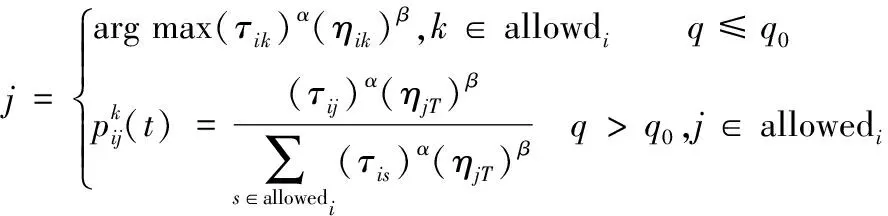

2 实验结果与分析
3 总结
猜你喜欢
吉林大学学报(信息科学版)(2022年2期)2022-08-15
计算机测量与控制(2022年2期)2022-03-30
科学与财富(2020年6期)2020-05-19
铁道通信信号(2020年10期)2020-02-07
电子制作(2019年20期)2019-12-04
北京航空航天大学学报(2019年9期)2019-10-26
微型电脑应用(2019年10期)2019-10-23
计算机测量与控制(2019年6期)2019-06-27
科技与创新(2017年11期)2017-07-01
软件(2016年5期)2016-08-30
