
基于硬件多线程机制的网络处理器微引擎设计
2022-02-25 14:45刘思远任敏华谷航平
微型电脑应用 2022年2期
刘思远, 任敏华, 谷航平
(华东计算技术研究所,先进集成电路研究院, 上海 201808)
0 引言
提高网络处理器性能的方法有很多种,最直接高效的就是并行处理技术[1-2],利用多个结构相同的微引擎能够提高处理并行度,在一个微引擎中采用多个线程同样能够提高处理并行度[3]。路由器往往需要同时处理成百上千用户的信息接受和转发[4],微引擎在接收到数据包后,开始对其进行解析处理,而在程序指令访问外部存储器时,微引擎只能处于等待状态,造成性能资源的浪费[5]。由于网络交换中的各数据包相关性很低,因此可以将软件中常用的多线程调度机制引入微引擎的硬件设计中[6-7]。本文设计了一种8线程微引擎,相较于传统的4线程或单线程微引擎,它能够实现微引擎各线程的高速切换,大大提升微引擎的执行效率,并采用了专用的线程切换指令、信号机制和指令切换存储器,以此来实现一整套微引擎硬件体系结构,并在仿真平台上验证了该设计的高效性。
1 微引擎组介绍
该款网络处理器共有40个微引擎,分为5组,每组8个微引擎核,支持硬件8线程,工作频率500 MHz,可同时做320个数据处理,GPR(General Purpose Registers)为32 bit,其硬件结构示意图如图1所示。
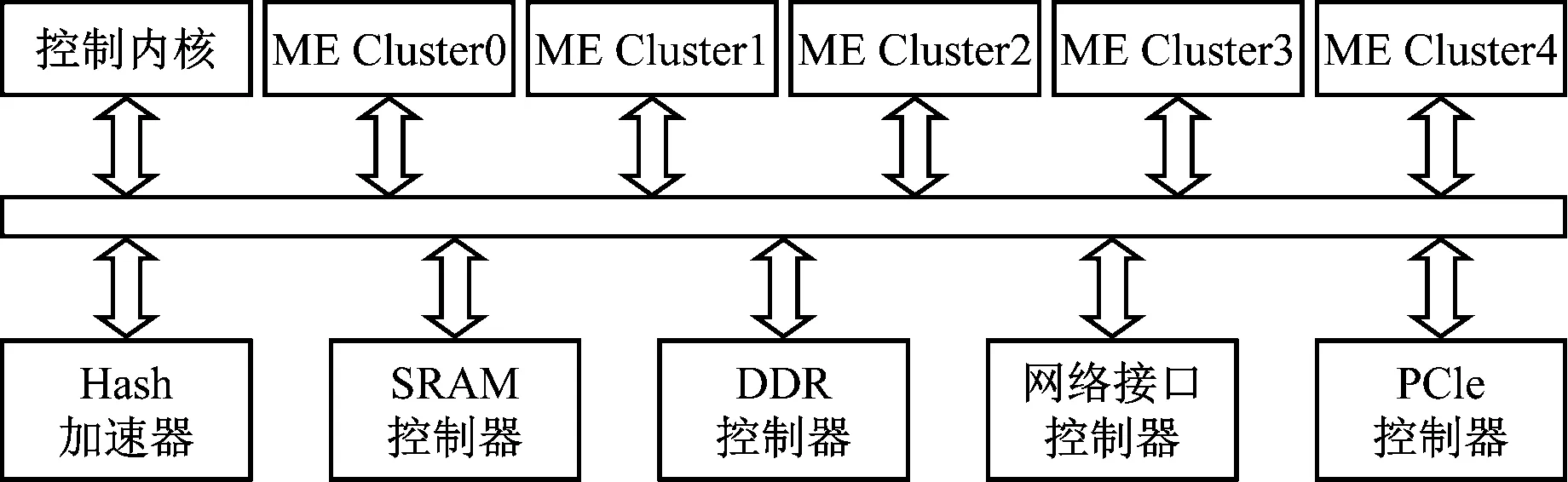
图1 网络处理器结构示意图
这些微引擎组分别执行数据包的主要处理任务,如接收、解析、分类、转发等任务,微引擎之间的通信参数由Scratchpad存储,支持原子操作和环操作,不会被线程调度所打断。以IPv4路由转发为例,该网络处理器各微引擎的工作流程如图2所示。
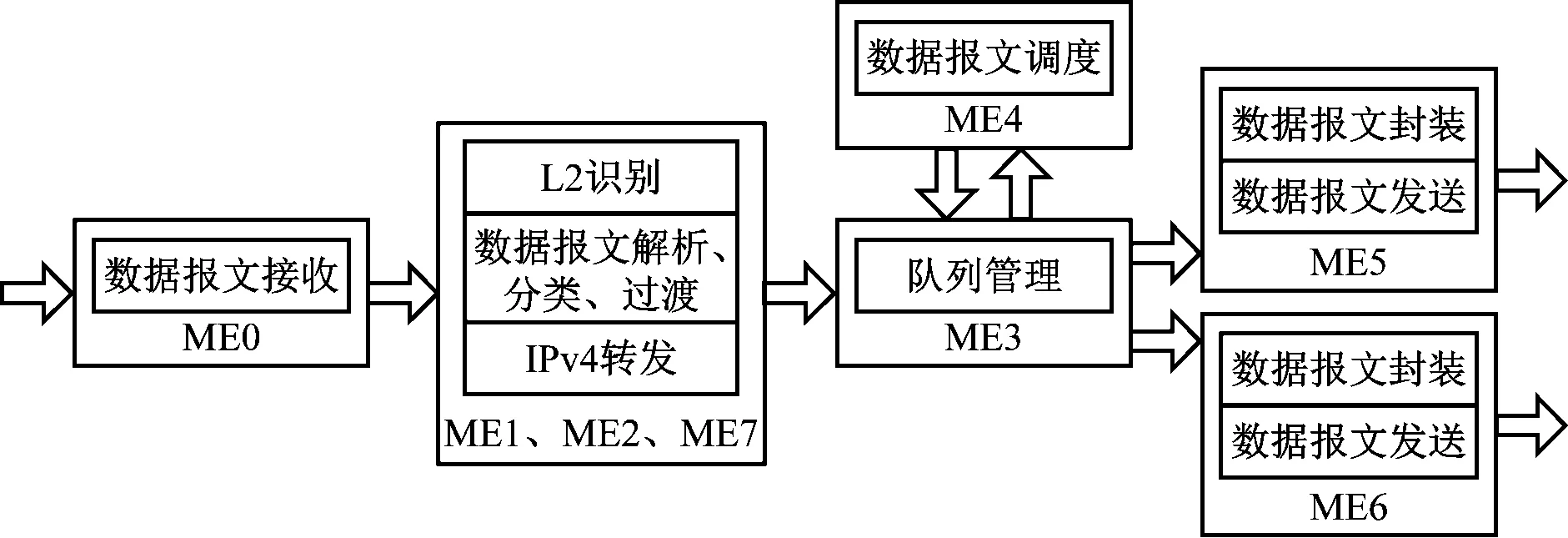
图2 IPv4路由转发中微引擎之间的数据通路
本设计中的微引擎内核为五级单发射的流水MIPS架构,从二级译码级收到切换指令到线程完成切换需要4个时钟周期。微引擎在处理报文中的数据时,会通过外设命令调用协处理器如Hash加速器或外部存储器如DDR控制器来处理数据[8-9]。
2 多线程微引擎设计
2.1 多线程寄存器模块
对于每个微引擎的单个线程,一共有4种状态,分别为未激活态、运行态、就绪态和睡眠态,本设计为其配置了专用的硬件系统模块来存放处理切换状态,其中包括:信号事件寄存器SIG_EVT_REG、程序指针寄存器PGM_PTR_REG、状态控制寄存器STA_CTL_REG,其结构如图3所示。
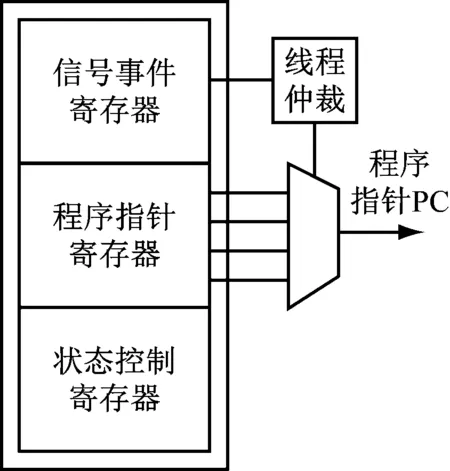
图3 多线程模块结构示意图
2.2 多线程仲裁机制
本设计通过Round-Robin算法来调度8个线程,与硬件中断机制不同,这是一种非抢占式机制。在微引擎收到线程切换指令Context_ARB时,信号事件寄存器和程序指针寄存器会记录所有睡眠线程,而状态控制寄存器则根据即时的各线程状态来维护线程切换状态机,线程仲裁器则从就绪线程中,以和睡眠线程等待信号量匹配为原则,选出就绪状态线程,准备激活运行,同时将此线程的程序指针寄存器中的值作为微引擎的程序指针,等收到切换线程指令后立即执行指令存储器中的指令,从而实现流水线指令的快速对接,且不因线程切换导致微引擎指令的停止[10]。图4为多线程状态机示意图。
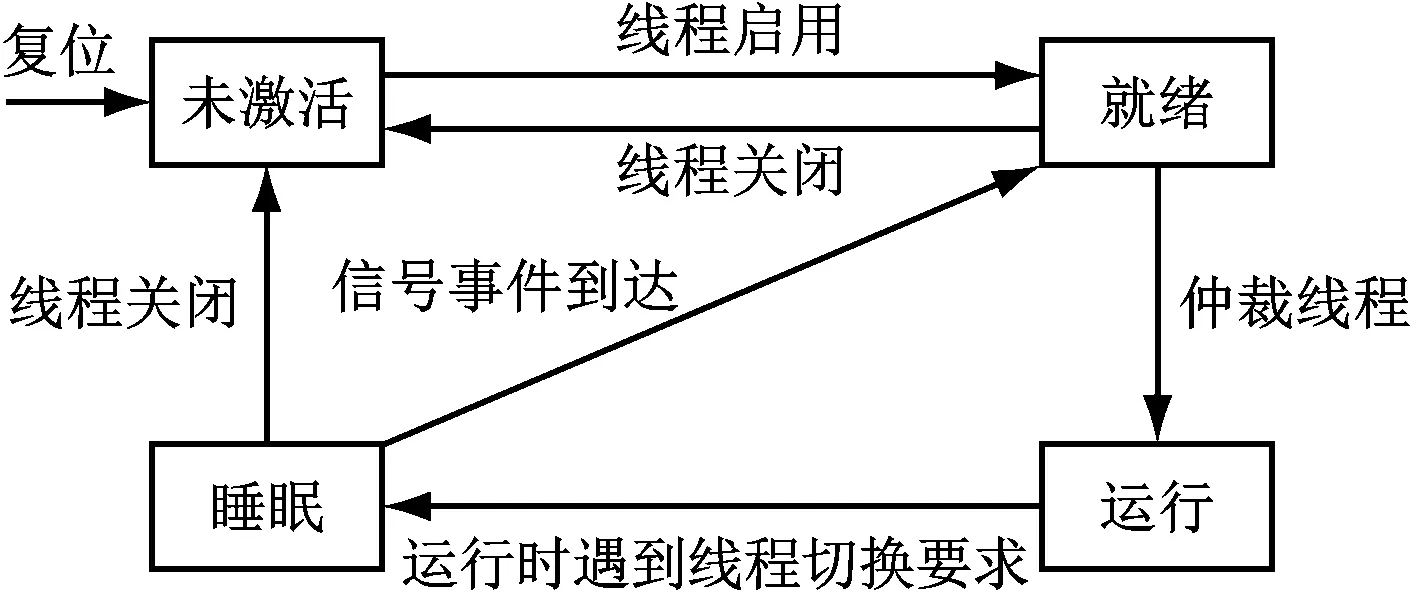
图4 多线程状态机示意图
本设计中的8线程微引擎,相较于单线程,理论上能够提升8倍的微引擎处理速度,在实际的应用中也能获得非常可观的效率提升[11]。图5为8线程切换示意图。

图5 8线程切换示意图
2.3 微引擎的执行权
微引擎在运行态拥有微引擎的执行权,线程在执行完切换指令后随即进入睡眠态,被仲裁出来的就绪线程则获得执行权,激活态线程的状态寄存器则会记录下目前处于运行态的线程,保证同一时刻只有一个线程在运行。
2.4 微引擎指令存储器
本设计中的每个微引擎的硬件线程都有自己的L1数据缓存,每个微引擎中的8个线程共享一个L1指令缓存,40个微引擎共享一个L2指令缓存,因为所有线程都拥有单独的硬件资源,所以状态切换不需要用更多的时间去保存当前的线程状态,仲裁模块提前选出就绪进程,在微引擎执行完外设命令之后随即执行线程切换指令,在执行此线程命令的时间里,对应的其他某一线程会被唤醒并执行相应的指令,这样可有效节约存储空间和处理时间。
3 仿真与验证
本设计通过Mentor ModelSim软件进行了功能验证和时序验证,Microengine_top为一个微引擎组,采用测试激励testbench作为输入,仿真的部分用例如图6所示。
图6 仿真部分用例文件
如图7所示,跳转汇编指令转换为32位机器码,指令寄存器在一个时钟周期后准确收到输入指令,仿真结果符合设计预期与实验预期。
经过一系列的模块验证之后,搭建了FPGA以太网测试平台(图8),并在测试平台上完成了性能测试,测试时间约为800万个时钟周期。

图7 功能验证截图

图8 FPGA以太网测试平台
首先,对单线程处理器进行了各存储器的延迟测试,测试结果如表1所示,除了Local Memory之外,微引擎和存储器之间的访存时间开销是非常大的,有很大的效率提升空间。

表1 存储器访问延迟测试结果 单位:CLK周期
随后,又对单线程、4线程以及本设计中的8线程处理器进行了IPv4路由转发测试,测试结果如表2所示,可以看出,8线程网络处理器的效率有了很大的提升且非常可观,完全能够满足高速网络场景中的使用需求。
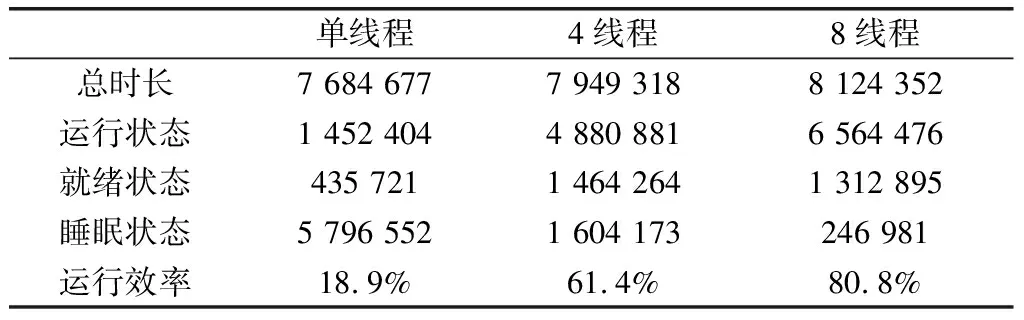
表2 IPv4路由转发测试结果 单位:CLK周期
4 结论
本文提出了一种8线程网络处理器微引擎的设计方案,通过实验仿真验证可以得知,本设计中的微引擎执行效率相较于单线程和4线程网络处理器有了很大的提升。目前,本设计已经完成了全芯片代码的集成、软仿以及FPGA板级验证,未来还将进行协同验证,在流片封装并进行硬件测试之后会应用在工业以太网等对即时性要求很高的使用场景中。随着网络速率和带宽需求的不断提升,网络处理器在架构方面以及分组处理优化方面还有很大的发展潜力,这将是日后研究的重要方向。
猜你喜欢
现代电子技术(2022年8期)2022-04-13
体育科技文献通报(2022年1期)2022-01-15
北京航空航天大学学报(2021年6期)2021-07-20
计算机应用(2020年5期)2020-06-07
计算机研究与发展(2019年4期)2019-04-18
电子技术与软件工程(2018年1期)2018-03-22
环球时报(2014-06-18)2014-06-18
科技传播(2013年22期)2013-08-15
计算机世界(2009年27期)2009-07-30
计算机教育(2006年4期)2006-04-19
