
基于卷积神经网络的多媒体视频压缩研究
2022-02-25 14:45唐琳孙叶周鹏张玉豹
微型电脑应用 2022年2期
唐琳, 孙叶, 周鹏, 张玉豹
(国网德州供电公司, 山东,德州 253000)
0 引言
随着数字技术、流媒体技术、无线通信和视频监控的应用范围扩大,出现了海量的多媒体视频[1-2]。存储和传输海量媒体视频会占用大量的存储空间,传输耗时长,给多媒体视频后续处理带来了巨大压力。对多媒体视频进行压缩,可以减少多媒体视频的存储空间,节约存储成本,在相同信道条件下,多媒体视频传输错误率大幅度降低,因此对多媒体视频压缩进行研究,构建理想的多媒体视频压缩方法具有十分重要的意义[3]。
多媒体视频压缩技术是根据人类视觉原理,结合多媒体视频信息冗余量大特点,采用一定的方法消除多媒体视频信息之间的空间、时间冗余,大幅减少多媒体视频存储空间。几十年来,国内外许多专家对多媒体视频压缩进行了深入研究。当前多媒体视频压缩方法可以划分为2类:一类是基于硬件技术的多媒体视频压缩方法,另一类是基于软件技术的多媒体视频压缩方法[4-6]。基于硬件技术的多媒体视压缩率高,压缩速度快,但是存在压缩成本高,对操作人员的专业知识要求高,无法大范围进行推广。基于软件技术的多媒体视频压缩成本低、而且易实现,因此成为当前多媒体视频压缩的主要研究方向[7-9]。基于软件技术的多媒体视频压缩方法又划分为2类:有损压缩方法和无损压缩方法,其中有损压压缩方法主要包括霍夫曼编码的多媒体视频压缩方法、游程编码的多媒体视频压缩方法;无损压缩方法主要包括离散余弦变换的多媒体视频压缩方法、小波变换的多媒体视频压缩方法、基于预测编码的多媒体视频压缩方法。这些方法均存在各自的实际应用范围,同时存在一定的不足,如无法有效去除多媒体视频冗余信息,多媒体视频压缩率小等[10]。
近年来,随着人工神经网络的发展和研究深入,出现了深度学习网络,其中卷积神经网络是一种性能优异的深度学习网络,相对于传统人工神经网络,卷积神经网络的学习能力更优,具有更高精度的拟合效果[11]。为了提高多媒体视频压缩率,去除信息之间的冗余,本文设计了基于卷积神经网络的多媒体视频压缩方法,并且通过了具体媒体视频压缩测试,实验分析这种方法的性能。
1 卷积神经网络的多媒体视频压缩方法
1.1 卷积神经网络的概述
20世纪中期,有学者对猫的神经系统进行研究,并且发现神经元具有单向传输特性,同时具有局部敏感特征,因此模拟神经元该特点在传统人工神经网络的基础上,提出了卷积神经网络。相对传统人工神经网络,卷积神经网络降低了权重数目,采用端对端的训练方式,将特征获取嵌入到卷积结构中,使得同一层可以进行大量卷积操作,具有并行学习能力,这样卷积神经网络的学习速度更快[14-15]。卷积神经网络的结构如图1所示。从图1可以看出,卷积神经网络主要包括卷积层、激活层、池化层。
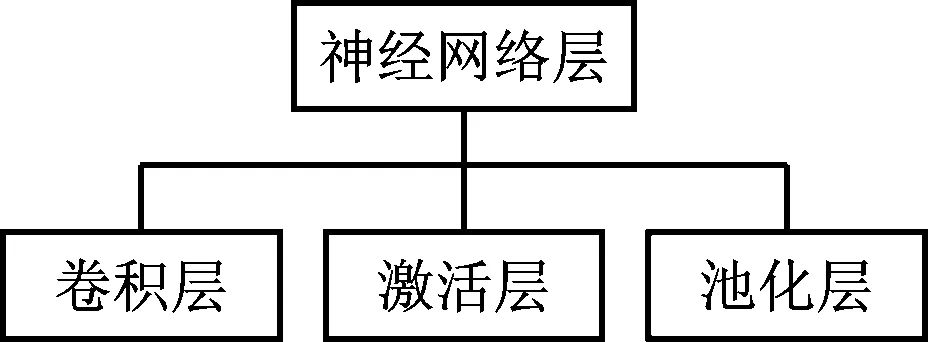
图1 卷积神经网络的结构
1.2 卷积神经网络的多媒体视频压缩原理
由于多媒体视频的关键帧图像具有局部不变性,再结合卷积神经网络的局部敏感特征,设计了基于卷积神经网络的多媒体视频压缩方法,具体工作原理如图2所示。
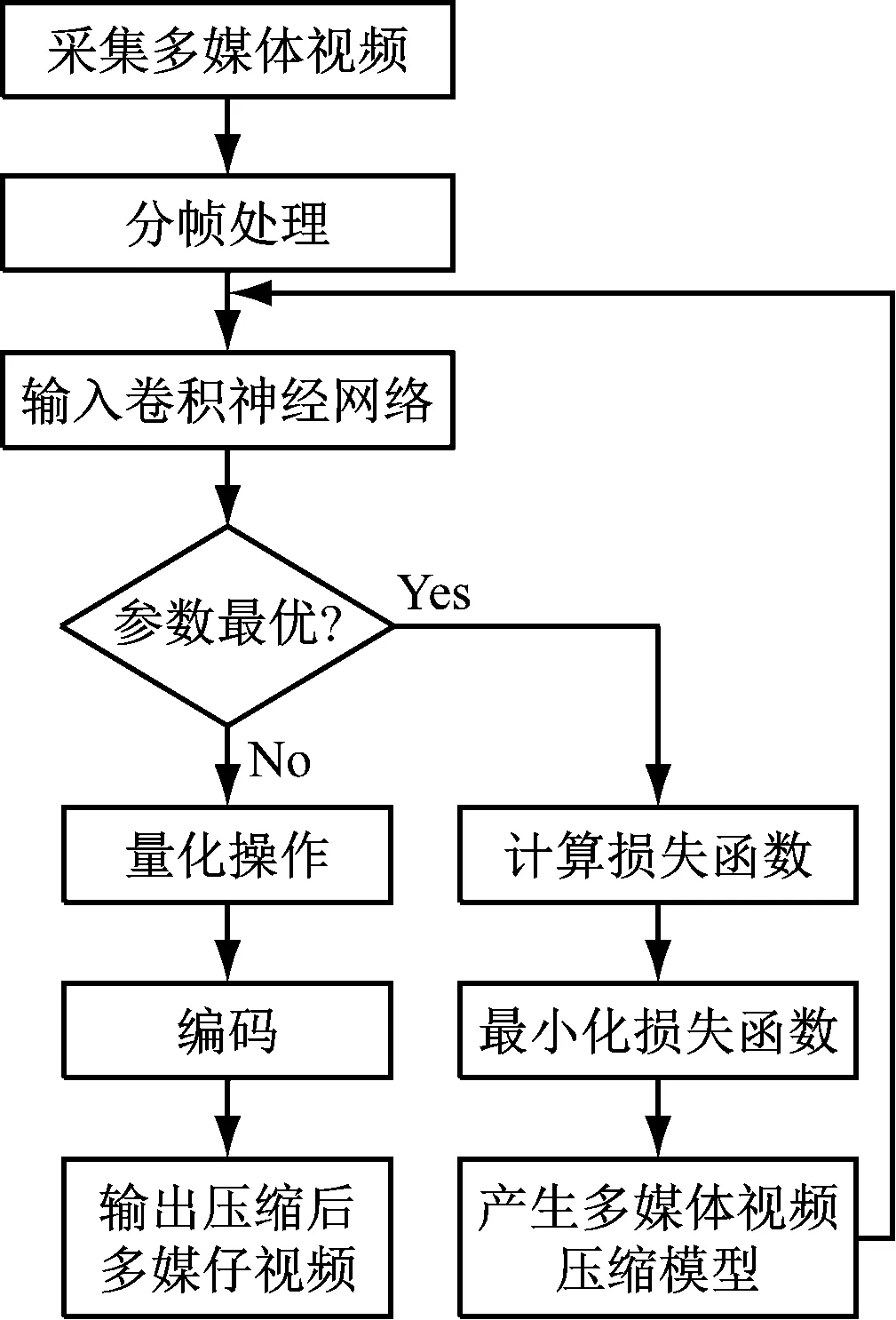
图2 卷积神经网络的多媒体视频压缩原理
基于卷积神经网络的多媒体视频压缩原理具体描述如下。首先对多媒体视频进行分帧预处理,提取关键帧图像,并将关键帧图像输入到卷积神经网络进行学习,然后通过卷积神经网络降低多媒体视频关键帧图像的空间尺度和特征数目,并且为显著性高的点分配相对多的码字,最后对关键帧图像特征进行量化处理,去降对关键帧图像影响微弱的信息,并对关键帧图像的统计冗余进行去除,从而实现关键帧图像的信息进行有效压缩,并通过卷积神经网络恢复图像的尺度,得到压缩后的关键帧图像,重组得到压缩后的多媒体视频。
1.3 卷积神经网络的多媒体视频压缩关键技术
(1) 多媒体视频关键帧图像的显著性。显著性是多媒体视频关键帧图像的重要特征,对不同的用户,对关键帧图像感觉兴趣区域不同,这样对不同的对象,只提取关键帧图像感觉兴趣区域,实现可以基于显著性的关键帧图像压缩。本文采用基于高级特征的关键帧图像显著性检测方法。对于一幅关键帧图像,具体如图3(a)所示。提取的显著性图如图3(b)所示。从图3可以看出,显著性较高的区域包含更多的信息,显著性较低的区域包含更少的信息。

(a) 关键帧图像

(b) 显著性图
(2) 损失函数设计。基于显著性图的损失函数具体由式(1)给出,
(1)
式中,γ表示权重系数,ld和ld分别表示失真损失和损失率,它们具体由式(2)、式(3)算出,
(2)
(3)
式中,E(x)表示特征图,S(x)表示显著性图,D(E(x))表示解压缩图,sij表示像素(i,j)的显著性,xij表示像素(i,j)的值,r表示某一压缩率的显著度和。
2 多媒体视频压缩的仿真测试
2.1 多媒体视频压缩对象
为了测试基于卷积神经网络的多媒体视频压缩方法性能,采用4类多媒体视频作为测试目标,它们的关键帧如图4所示,采用Java编程实现多媒体视频压缩程序,选择霍夫曼编码的多媒体视频压缩方法、离散余弦变换的多媒体视频压缩方法、小波变换的多媒体视频压缩方法进行对照测试。

(a) 蝴蝶

(c) 交通
2.2 结果与分析
多媒体视频压缩效果通常采用关键帧图像压缩前后的相似度进行衡量,本文选择峰值信噪比、结构相似度和压缩率作为评价标准,峰值信噪比、结构相似度分别定义式(4)、式(5):
(4)
(5)
式中,MSE表示均方误差,具体为式(6):
(6)
式中,M和N分别表示关键帖图像的长与宽。
4种方法对4类多媒体视频的峰值信噪比、结构相似度和压缩率分别如表1—表3所示。对表1—表3的峰值信噪比、结构相似度和压缩率进行分析可以发现,相对于对照方法,卷积神经网络的峰值信噪比、结构相似度和压缩率均得到了明显的改善,在不破坏多媒体视频信息的条件下可以更大幅度的对多媒体视频进行了压缩,可以节约多媒体视频存储空间,提高多媒体视频传输速度。
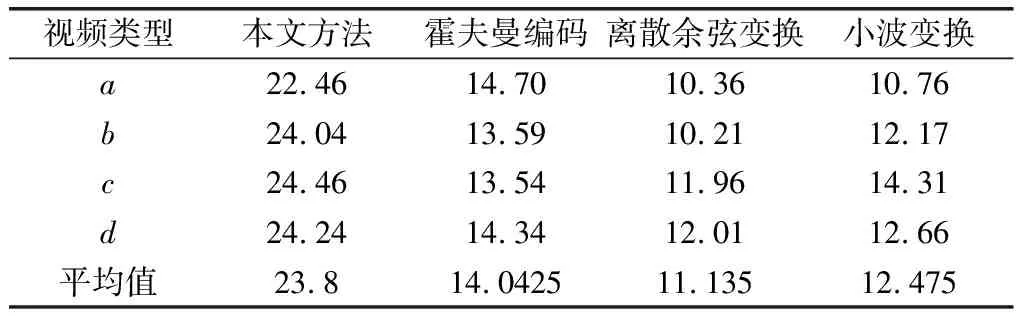
表1 4种方法的多媒体视频压缩率比较 单位:%
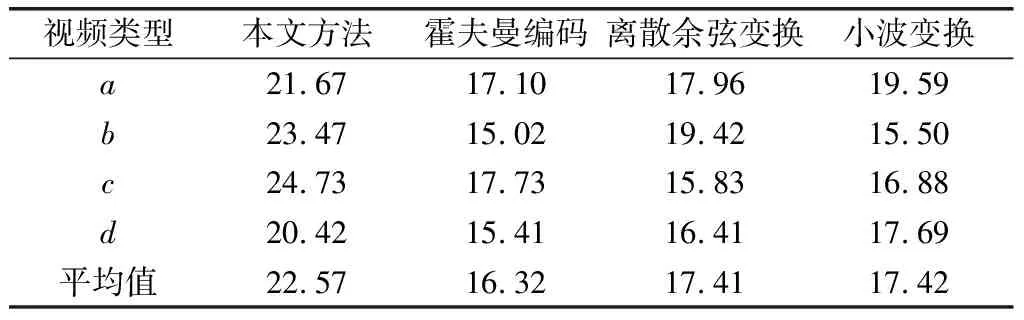
表2 4种方法的多媒体视频峰值信噪比
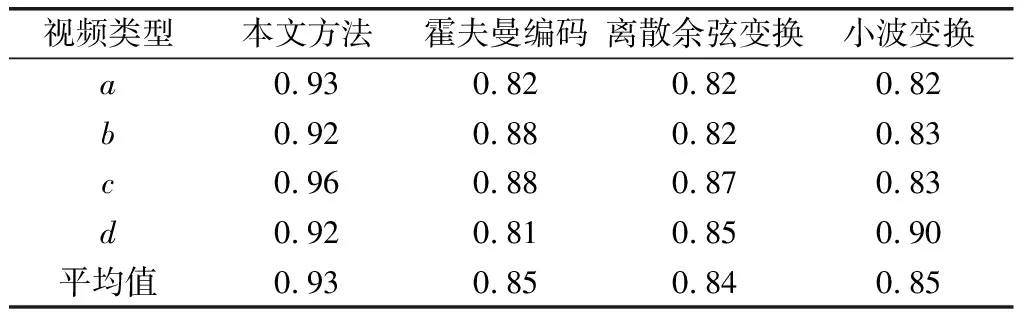
表3 4种方法的多媒体视频结构相似度
3 总结
多媒体视频信息量大,相对图像、文字能更好表达目标的内容,针对当前多媒体视频压缩存在的不足,以提升多媒体视频压缩率,设计了提出基于卷积神经网络的多媒体视频压缩方法,并与其它多媒体视频压缩方法进行对比测试,结果表明,卷积神经网络可以高精度描述多媒体视频关键帧之间的关系,获得较高的多媒体视频压缩率,为多媒体视频后续提供了基础,具有十分广泛的应用前景。
猜你喜欢
现代计算机(2022年4期)2022-04-24
现代仪器与医疗(2022年1期)2022-04-19
北京理工大学学报(2021年12期)2022-01-13
舰船电子对抗(2020年1期)2020-04-27
北京航空航天大学学报(2019年9期)2019-10-26
扬州大学学报(自然科学版)(2019年2期)2019-08-12
导航定位与授时(2019年3期)2019-05-16
科学与财富(2018年26期)2018-10-24
科技信息·中旬刊(2018年4期)2018-10-21
航空维修与工程(2018年8期)2018-09-10
