
基于大数据驱动的低阻油层精准识别方法
2022-02-25 06:01张如玉孙玉强牛庆威徐思远
油气地质与采收率 2022年1期
刘 昕,张如玉,孙 琦,孙玉强,牛庆威,徐思远
(1.中国石油大学(华东)计算机科学与技术学院,山东 青岛266580;2.中国石油大港油田分公司第一采油厂,天津 300280)
20 世纪90 年代以来,伴随着已开发油藏高含 水、高采出与高分散的显著三高特性以及石油勘探开发工作难度加大,研究的重点逐渐转向低阻油层。低阻油层因其具有分布广、储量大、评价难、易遗漏等特点,一直倍受关注,成为老井复查、油田二次开发、成熟油田精细勘探阶段的主要研究内容和提高经济储量的重要对象,在石油开发生产中具有重要意义[1]。低阻油层由于受多种复杂因素影响,其电阻率明显低于常规油层,并且测井响应特征不明显,使得测井信息对该类储层识别的能力降低,往往被解释为水层甚至被漏掉[2]。
根据区块地质特征与测井资料研究,定义低阻油层,形成基于低阻油层成因机理研究的低阻油层识别方法[3-6],目前传统方法是根据勘探测量得到的测井资料(如浅、中、深电阻率及自然电位等不同物理参数),运用含油饱和度法、双孔隙度法、双电阻率法、交会图版法、重叠法、核磁测井等技术实现低阻油层识别[7-14],但低阻油层成因机理复杂,传统识别方法大多基于专家经验法、油藏工程法以及基本统计分析实现低阻油层识别,导致低阻油层挖潜准确率并不高。
应用大数据挖掘技术提高低阻油层识别准确率,相关学者进行了多项研究,包括分类归纳算法中的支持向量机分类模型与决策树等模型的应用[15-18],但监督分类方法往往需要大量带有标签的低阻层数据,而有标签低阻层数据的获取需要消耗大量人力、物力和财力,且标签小层因不同解释时间、不同井况信息存在一定解释误差,分类识别效果不佳。另有相关学者使用神经网络识别低阻油层[19-20],将小层数据放入大量神经元连接而成的网络中,使其自动提取特征、调整参数,建立分类模型实现低阻油层识别,但神经网络模型结构选择不一,结构过大易过拟合、过小导致模型不收敛,且泛化能力较弱、样本集依赖性强、可解释性差。为此,笔者提出以小层数据为切入点,融合测井与研究成果资料筛选并核实低阻层,基于已核实低阻层数据,应用并行关联规则深度挖潜影响小层的含油性参数关联关系,分析已核实低阻油层数据特征,通过自动小层聚类和包含典型低阻油层的相似度计算,实现低阻油层识别,通过数据智能算法降低开发成本,提高识别准确率。
1 相关概念
1.1 关联分析
支持度 支持度(sup(a⇒b))是指小层数据中出现{a,b}的数据记录占所有数据记录的百分比,支持度计算式为:
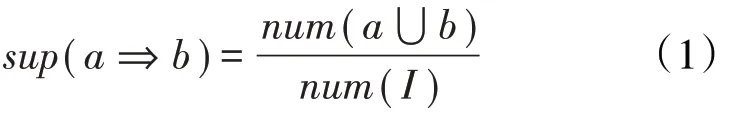
置信度 置信度(conf(a⇒b))是指小层数据中出现{a,b}的数据记录与出现{a}的数据记录之比,置信度计算式为:

关键参数集 由k个满足支持度阈值的关键参数组成的集合为k项频繁关键参数集,k项频繁关键参数集为:

1.2 t-SNE降维
t-分布随机邻域嵌入(t-SNE)[21]应用距离计算结果表征原始小层数据的相似关系特征,再将此相似关系转化成概率分布形式,作为低维空间转换的输入,得到P(mj|mi),其表达式为:
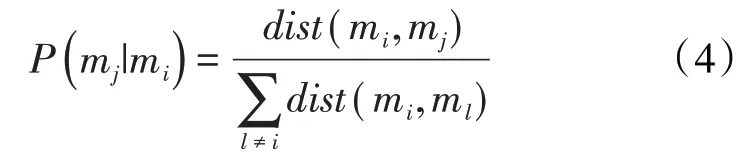
计算小层数据样本概率分布获得原始样本数据在低维数据空间中的输出表现形式,即Q(nj|ni),其表达式为:

t-SNE 算法的优化目标是保证P概率分布与Q概率分布之差等于0,即使得高维概率分布表示与低维空间概率分布表示间的Kullback-Leibler(KL)散度最小,KL[22]计算式为:
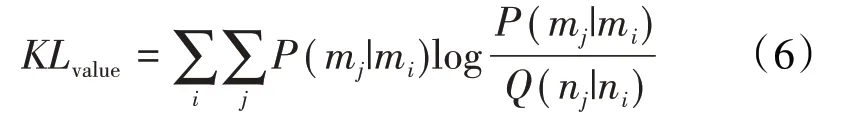
1.3 聚类分析
将物理或抽象对象集合分成相似对象类的过程称为聚类,在无监督情况下根据对象间相似程度自动地将其分割为一组有意义类的处理过程[23]。聚类分析三要素为相似性测度、聚类准则和聚类算法。按照不同试油结论进行聚类,可以间接获取不同参数组合对目标储层的敏感性。
采用基于局部密度的快速聚类算法[24]进行分析,选择的聚类中心应同时具有以下2个特性:本身局部密度大、与其他局部密度大的数据点间的相对距离更大。通过计算数据点的局部密度与相对距离,自动寻找聚类中心点,避免人为初始设置聚类中心步骤。
1.3.1 局部密度
局部密度是以i为中心点,计算与点i距离小于dc的点的个数,局部密度越大说明该节点数据分布越密集,反之越稀疏,局部密度的表达式为:
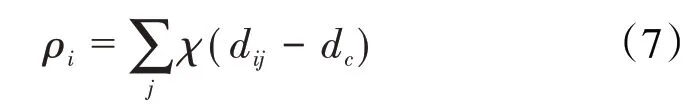
1.3.2 相对距离
相对距离是点i到其他较高密度点之间的最小距离,其表达式为:

局部密度大、相对距离小的节点具有聚类中心的特征,而局部密度小且相对距离大的节点则具有孤立点的特征。计算其他数据节点与聚类中心的距离,将与其距离最近且局部密度更大的节点聚为一类。
1.4 相似度计算
通过计算小层特征之间距离进行相似度评定,分别定义2个小层(已核实低阻油层与低阻层)X,Y,X={x1,x2,...,x5},Y={y1,y2,...,y5},包含五维特征(含油饱和度、泥质含量、孔隙度、渗透率、砂层厚度)。基于余弦相似度理论计算小层相似性,余弦相似度取值为-1~1,其值越趋于1,表示两向量相似度越高,其值越趋于-1,表示两向量变化方向完全相反,相似度越低。余弦相似度表达式为:
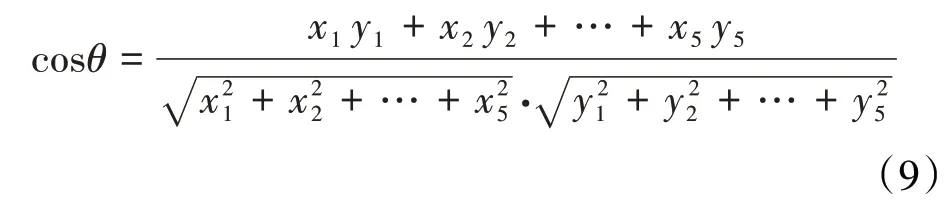
2 大数据驱动的低阻油层精准识别
2.1 识别流程
基于大数据驱动的低阻油层精准识别整体框架流程如图1所示。
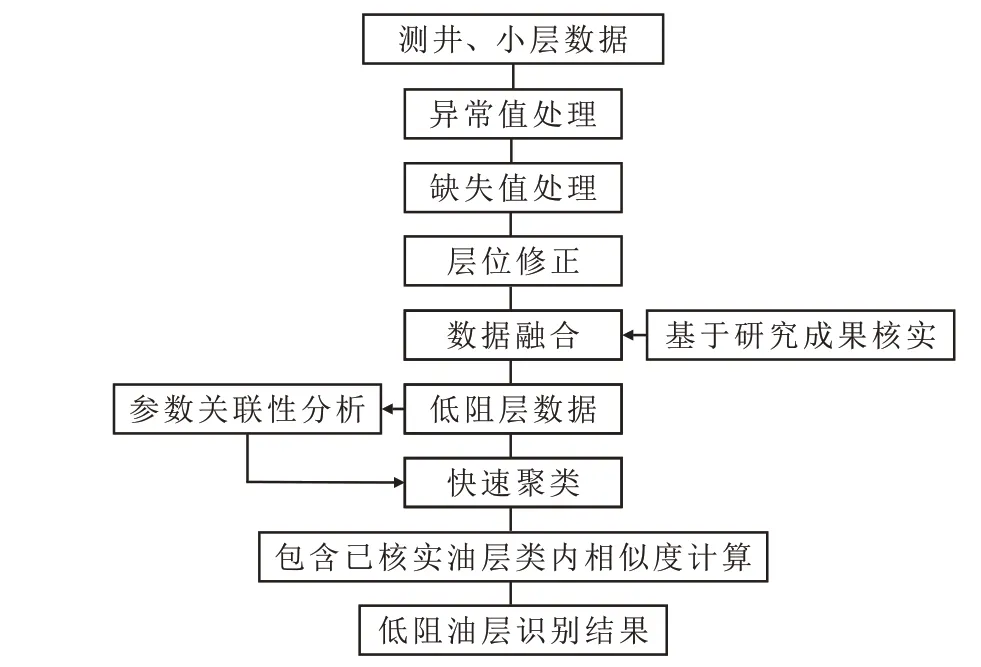
图1 低阻油层精准识别整体框架流程Fig.1 Flowchart of identification of low-resistance oil layers
2.2 低阻层数据融合
在完成数据异常值处理、缺失值处理以及层位修正等基础上,将井号为同一名称且深度在低阻层井段埋深之间的测井数据与低阻层数据进行融合,形成以深度为主键的小层测井数据(表1)。

表1 部分小层测井数据Table1 Part of sub-layer logging data
综合研究成果资料与油田专家经验筛选的低阻层数据并进行油、水层标记。低阻层定义为2.5 m电阻率为2~5 Ω·m 的小层。共筛选出3 866 个低阻层,其中已核实低阻层(标记油、水层标签)共160个,未标记低阻层共3 706个。
2.3 参数关联性分析
选取已核实低阻层的孔隙度、渗透率、含油饱和度、泥质含量、砂层厚度以及油、水层标签等小层参数进行关联分析。因选取数据为连续性参数,需对其分区间离散化处理,结合专家经验与参数实际分布对小层进行分区间处理;基于(1)式计算小层参数支持度,设置支持度阈值,选取大于等于支持度阈值参数构成1 项频繁关键参数集;组合1 项频繁关键参数集通过支持度阈值筛选获取2项频繁关键参数集,直到获取k项频繁关键参数集;基于(2)式计算所有k项频繁关键参数集生成的关联规则置信度,设置置信度阈值,输出大于等于置信度阈值的关键参数组合规则,深度挖掘各小层参数与含油性间潜在关联关系及参数分布区间。
2.4 小层数据分析
2.4.1 小层快速聚类分析
选取同区块下低阻层数据(已核实低阻层与预测层)中孔隙度、渗透率、含油饱和度、泥质含量、砂层厚度等5 列小层数据应用t-SNE 将小层数据融合降到二维输入到快速聚类模型中,用低维数据融合表征原始特征,提高计算效率;计算小层数据局部密度与相对距离,选取局部密度大且相对距离远的小层为聚类中心,计算聚类中心与其他低阻层相对距离与局部密度进行分类。
2.4.2 小层相似度计算
分析已核实低阻层特征,选取包含已核实低阻层类内的低阻层数据进行相似度计算。选取孔隙度、渗透率、泥质含量、含油饱和度及砂层厚度等5列参数作为特征输入,以已核实低阻层数据为标签数据,分别计算其他低阻层与已核实低阻层间余弦相似度,选取相似度最大的低阻层为潜力油层并进行标记,直到所有已核实低阻层数据计算完毕结束。
3 应用实例
东部地区某油田受断层和岩石性质双重控制,构造形态被多条断层切割,属于复杂断块构造油气藏。沉积类型多以曲流河、辫状河为主。储层以中-细砂岩为主,胶结类型为孔隙式和接触式,胶结成份以泥质为主,属高孔隙度、高渗透率的疏松砂岩储层。针对东部地区某油田641 口井小层数据,应用笔者提出的大数据驱动的低阻油层精准识别方法进行油层挖潜。基于并行关联规则算法对已核实低阻层的含油性进行分析;利用聚类分析算法对低阻层数据分类,对包含已核实油层类小层进行相似度计算,自动识别与已核实低阻油层相似小层。
3.1 参数关联性分析
选取油田160 个已核实低阻层数据中的孔隙度、泥质含量、渗透率、含油饱和度、砂层厚度等小层参数进行数值分布统计,参数数值分布情况如图2所示。

图2 小层参数分布情况Fig.2 Distribution of sub-layer parameters
由图2 可知,横坐标表示160 个小层的层号,纵坐标分别表示孔隙度(图2a)、泥质含量(图2b)、渗透率(图2c)以及砂层厚度(图2d)的数值大小。依据油田专家经验与参数实际分布情况(表2)将孔隙度、泥质含量、渗透率、砂层厚度和含油饱和度进行划分。将划分好的参数区间输入到并行关联规则模型中进行分析,设置支持度阈值参数为8%,置信度阈值参数为10%,关联分析结果如表2所示。
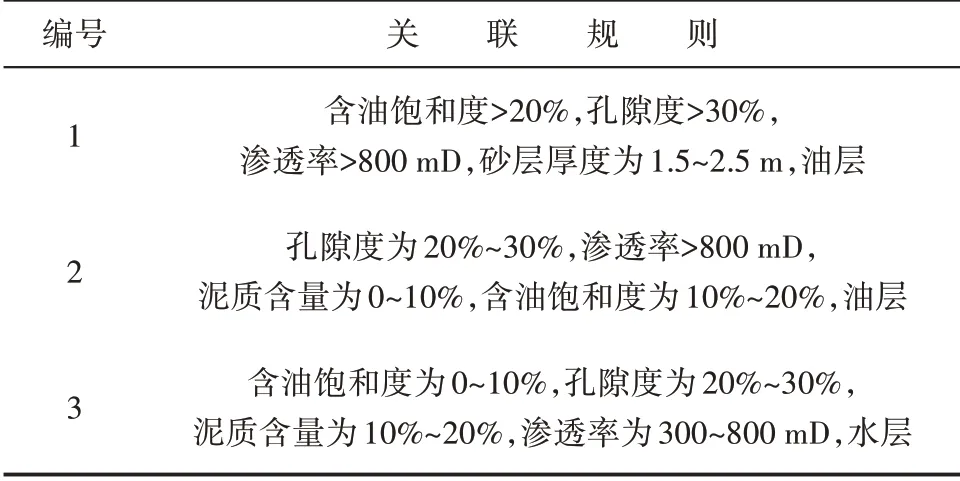
表2 参数关联分析结果Table2 Results of parameter association analysis
分析已核实低阻小层数据关联关系可知,当小层的含油饱和度大于20%、孔隙度大于30%、渗透率大于800 mD、泥质含量为0~10%、砂层厚度为1.5~2.5 m 时,该层为油层的可能性较大;当含油饱和度为0~10%、孔隙度为20%~30%、泥质含量为10%~20%、渗透率为300~800 mD 时,该层为水层的可能性较大,同时基于上述模型分析结果也验证了含油饱和度、孔隙度、渗透率、泥质含量等小层解释参数对含油性具有重要影响作用。
3.2 小层数据分析
选取东部地区某油田小层的泥质含量、孔隙度、渗透率、含油饱和度、砂层厚度等5 项参数共3 866 个小层数据应用t-SNE 将小层数据融合降到二维;计算各小层的局部密度与相对距离,将具有不同参数特征的小层数据聚类分析划分为10类,设置相对距离参数值为6.8,局部密度参数值为3,聚类分析结果如图3所示。

图3 小层聚类分析结果Fig.3 Results of sub-layer clustering analysis
将泥质含量、孔隙度、渗透率、含油饱和度和砂层厚度降为二维后,用参数1 和参数2 分别表示小层不同维度,不同颜色代表不同类别,分析已核实低阻油层数据特征,以第6 类小层数据分析为例进行已核实油层相似度计算,选取低阻小层泥质含量、孔隙度、渗透率、含油饱和度以及砂层厚度作为X和Y的输入特征,应用(9)式计算该类小层内已核实低阻油层与其他低阻小层的余弦相似度。在第6类小层数据中将9个已核实低阻油层数据分别与67个低阻小层数据进行相似度计算,选取与已核实低阻油层数据相似度最大的小层作为最终的低阻潜力预测油层。应用大数据驱动的低阻油层精准识别方法识别的低阻油层结果如表3所示。
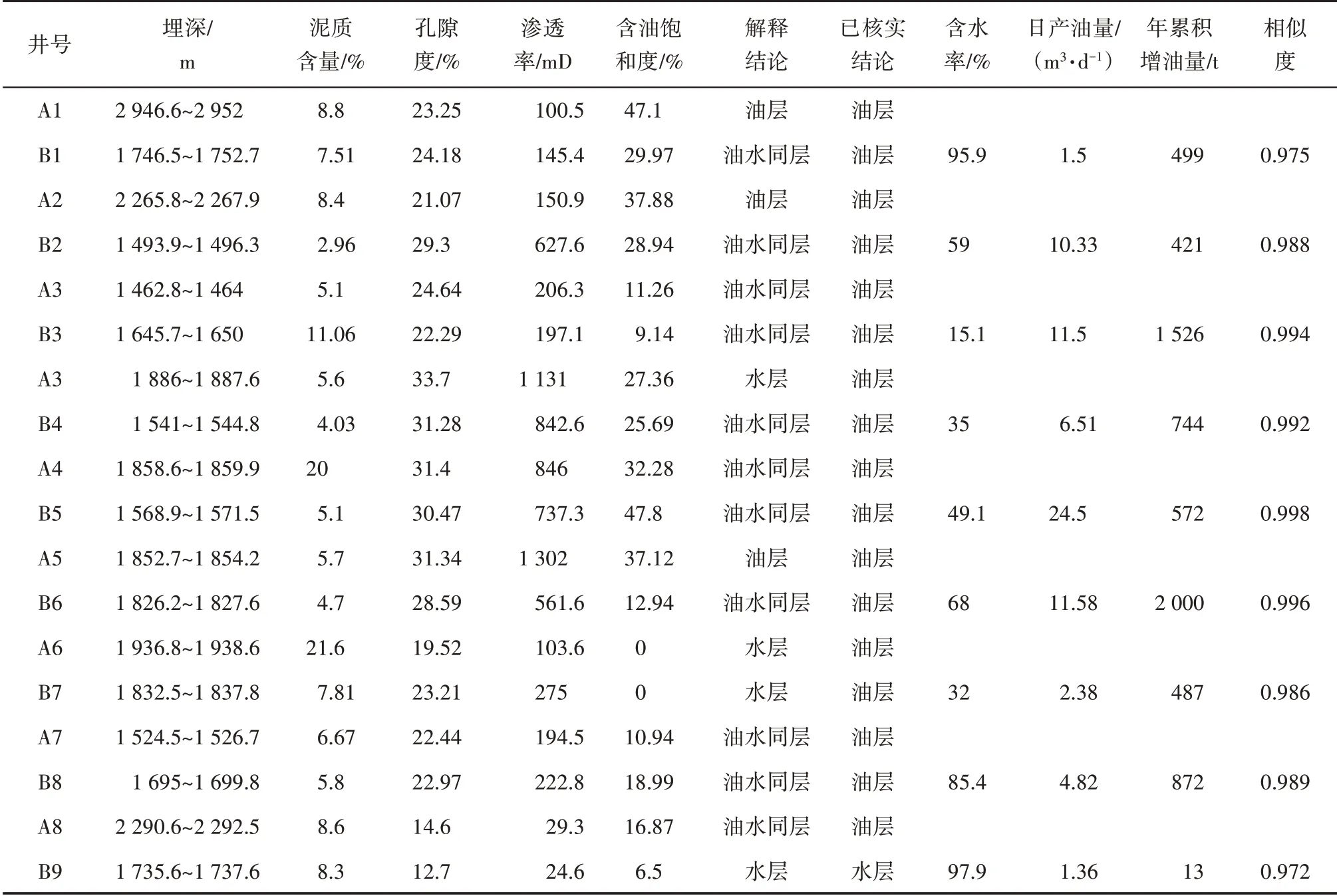
表3 应用本文模型识别的低阻油层结果Table3 Low-resistance oil layers identified by model
3.3 应用效果分析
由表3 可见,基于大数据驱动的低阻油层精准识别方法共识别出9 个低阻油层,结合油田现场补开生产情况进行分析验证,其中8 个小层补开出油且年累积增油量均在400 t 以上,识别准确率达90%。其中B6 井埋深1 826.2~1 827.6 m 井段增油效果最佳,该层录井曲线显示测井解释为油水同层,录井解释为差油层,有荧光显示;补开后初期日产液量为36 m3/d,日产油量为11.58 t/d,含水率为68%,稳定生产516 d,年累积增油量为2 000 t。
4 结论
基于小层数据、研究成果资料以及测井数据分析提出了一种大数据驱动的低阻油层精准识别方法。该方法首先基于并行关联规则挖掘各小层参数与含油性之间潜在关联关系,描述小层各参数指标同时出现的规律和模式;随后建立了小层数据聚类模型,自动将具有相似油层、低阻层特征的小层识别为一类,克服了解释数据中各小层的解释结论描述不准确问题;在同类数据中建立了小层相似度计算模型,深度挖潜与已核实低阻油层相似小层,更好地提高采收率。
通过大数据驱动的低阻油层精准识别方法深度挖掘出各小层参数之间潜在关系,智能化识别低阻油层与油田实际生产进行对比评测发现,基于大数据驱动的低阻油层精准识别方法可以高效准确地识别出潜在的低阻油层,识别准确率达90%。应用该方法对东部地区某油田641口井的小层数据进行低阻油层智能识别,优选潜力层,通过油田现场实施验证,获得了良好增油效果。该方法降低了对专家经验的依赖性,减少了主观性影响,节省了大量人力,且提高了油田采收率。
符号解释
a,b——小层的解释参数集合;
dc——超参数截断距离;
dij——点i与点j的距离;
dist(mi,mj)——高维空间中mi与mj两点之间的距离;
dist(mi,ml)——高维空间中mi与ml两点之间的距离;
dist(ni,nj)——低维空间中ni与nj两点之间的距离;
dist(ni,nl)——低维空间中ni与nl两点之间的距离;
i——第i个小层数据;
j——第j个小层数据,j≠i;
k——频繁关键参数集中包含的频繁关键参数数量,个;
I——低阻小层数据集;
KLvalue——数据集中所有数据点在高维空间的概率分布表示与低维空间的概率分布表示之间的KL散度;
Lk——k项频繁关键参数集;
mi,mj——高维数据点坐标;
ni,nj——低维数据点坐标;
num(a)——关键参数集{a}在数据集中出现的次数;
num(a∪b)——关键参数集{a,b}在数据集中出现的次数;
num(I)——低阻小层数据集中数据记录的总条数;
P(mj|mi)——高维数据空间中选择数据点mj作为数据点mi近邻点的条件概率;
Q(nj|ni)——低维数据空间中选择数据点nj作为数据点
ni近邻点的条件概率;
x1,2,3,4,5,y1,2,3,4,5——小层的X,Y特征分量;
wi——第i个支持度满足支持度阈值的频繁关键参数;
ρi——点i处的局部密度;
ρj——点j处的局部密度;
δi——点i到其他较高密度点之间的最小距离;
χ——分段函数。
猜你喜欢
中国化工贸易·上旬刊(2020年1期)2020-09-10
当代化工(2019年2期)2019-12-10
中国化工贸易·上旬刊(2018年4期)2018-09-10
文艺生活·下旬刊(2018年3期)2018-05-04
科学与财富(2017年25期)2017-09-17
科技资讯(2017年19期)2017-08-08
当代化工(2015年7期)2015-10-21
中国高新技术企业(2015年26期)2015-08-14
中国高新技术企业(2015年29期)2015-08-11
