
精细油藏描述中的大数据技术及其应用
2022-02-25 06:01陈欢庆唐海洋刘天宇杜宜静
油气地质与采收率 2022年1期
陈欢庆,唐海洋,吴 桐,刘天宇,杜宜静
(1.中国石油勘探开发研究院,北京 100083;2.中国石油华北油田分公司勘探开发研究院,河北 任丘 062552)
精细油藏描述是指油田投入开发后,随着油藏开采程度的提高和动、静态资料的增加所进行的精细地质研究与剩余油描述,并不断完善已有地质模型和量化剩余油分布所进行的研究工作[1-4]。精细油藏描述研究内容丰富,主要包括地层精细划分与对比、构造精细解释、沉积微相和储层构型研究、储层综合定量评价、地质建模研究、剩余油表征等。这些研究内容几乎涵盖了油田开发地质研究的所有方面,涉及海量数据。要利用好这些海量数据,将研究者从繁杂的数据整理和分析中解脱出来,自然需要应用大数据技术。目前关于大数据技术的定义,不同的学者有不同的认识[5-9]。通常而言,大数据是指无法在一定时间范围内用常规软件工具捕捉、管理和处理的数据集合,是需要采用新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产[5]。在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》中,大数据指不用随机分析法(抽样调查)这样的捷径,而采用所有数据进行分析处理。麦肯锡全球研究所给出的定义是:一种在获取、存储、管理、分析方面的规模大到远远超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低等四大特征。大数据的出现,对于社会不同行业都具有十分重要的意义,主要体现在3方面:第一,大数据重新定义了数据的价值;第二,大数据为智能化社会奠定了基础;第三,大数据促进了社会资源的数据化进程。笔者对精细油藏描述中大数据的技术特征及大数据技术的应用进行详细阐述,并指出其存在的问题和发展方向,力图为大数据技术在精细油藏描述中发挥更大作用提供参考。
1 精细油藏描述中大数据特征
在油气行业,从数字油田数据的定义来看,油田大数据分为两类:一类是油田企业从勘探开发的生产源头上采集的原始数据体,也就是科学数据;另一类是专业人员对生产源头上的原始数据进行推断、解释后的成果数据,包括生产、经营过程中的各种数据,统称为计算机管理数据,也被称为知识数据[5]。具体到精细油藏描述中,对应两方面数据表:一是基础统计数据表,主要包括钻井数据表、钻井取心统计表、岩矿统计表、粒度统计表、裂缝统计表、单砂体数据表、储层四性关系分析表、油层厚度统计表、物性(孔隙度、渗透率、含油饱和度等)统计表、黏土矿物统计表、孔隙结构特征参数统计表、储层敏感性统计表、高压物性分析数据表、流体(包括油、气、水)性质分析数据表、岩石表面润湿性数据表、驱油实验数据表、射孔数据表、试油试采成果表等;另一类是综合研究成果表,主要包括分层数据表、构造要素表、油气层综合数据表、分单元储量数据表、沉积微相分类及命名表、各种沉积微相标志综合表、层内渗透率非均质参数表、层间渗透率非均质参数表、隔层数据表、夹层数据表、储层综合评价数据表、单层产量劈分数据表、生产井史数据表。除了上述两大类数据表之外,精细油藏描述中的数据还包括地震解释数据体、地质模型以及各种基础图件和成果图件。目前这些数据和其他研究数据一起,已成为各油气公司十分重要的资产。精细油藏描述各项研究任务的完成,需要各类数据的支撑。例如在研究断层封闭性时,可以对比断层上下两盘对应井的水分析资料[10-11],如果水分析资料成分差异很大,证明断层是封闭的,断层两盘流体之间不连通,如果水分析资料成分基本相同,则证明断层上下两盘之间不封闭,流体是连通的。无论是哪一类数据,都需要经过严格的质量控制、科学的管理和存储。
2 大数据技术在精细油藏描述中的应用
大数据技术在精细油藏描述中具有十分广阔的应用前景。一方面,精细油藏描述的研究内容众多,大数据技术可以应用的领域也很多;另一方面,精细油藏描述研究中收集的海量数据又为大数据技术的应用提供了丰富的数据基础和条件。笔者主要从地层自动精细划分与对比、储层沉积微相(或储层构型)自动批量判别、测井精细批量二次解释、聚类分析储层综合定量评价和多点地质统计学三维地质建模等5方面介绍大数据技术在精细油藏描述中的应用。
2.1 地层自动精细划分与对比
地层精细划分与对比一直是精细油藏描述最基础的工作之一。从最初的“分级控制、旋回对比”,到现在在高分辨率层序地层学指导下小层(或)单层级别的地层细分,地层精细划分与对比是精细油藏描述其他工作的重要基础,也占据了研究者大量的时间和精力。现在精细油藏描述正处于数字化向智能化发展转变,需要将研究者从繁杂的基础工作中解脱出来,因此地层的自动精细划分与对比就成为目前精细油藏描述十分重要的发展方向。笔者在进行准噶尔盆地西北缘某区克下组小层级别地层精细划分与对比时,主要依据自然伽马、自然电位和电阻率测井曲线,基于专业的软件工作平台,实现地层的精细划分与对比(图1),虽然该对比方法比人工在图纸上对比有了很大的进步,但是与地层自动精细划分与对比还有较大的差距。所谓地层的精细划分与对比,就是设计专业的软件,机器通过对典型井人工地层对比结果的学习和训练,实现整个研究区地层自动追踪对比。该方法充分体现了大数据技术思想,那就是机器学习的样本需要一定的数量基础,以充分体现学习样本的代表性。目前中国石油辽河油田等单位正在做相关的研发工作。有些专业软件上也有类似相关的功能,但自动对比的结果与地层的真实情况还有很大距离,还需要人工做大量的修改和完善工作。油田开发中,几平方公里的研究面积,少则数百口井,多则上千口井,如果都能实现地层的自动精细划分与对比,将极大地促进精细油藏描述由数字化向智能化方向发展和进步。
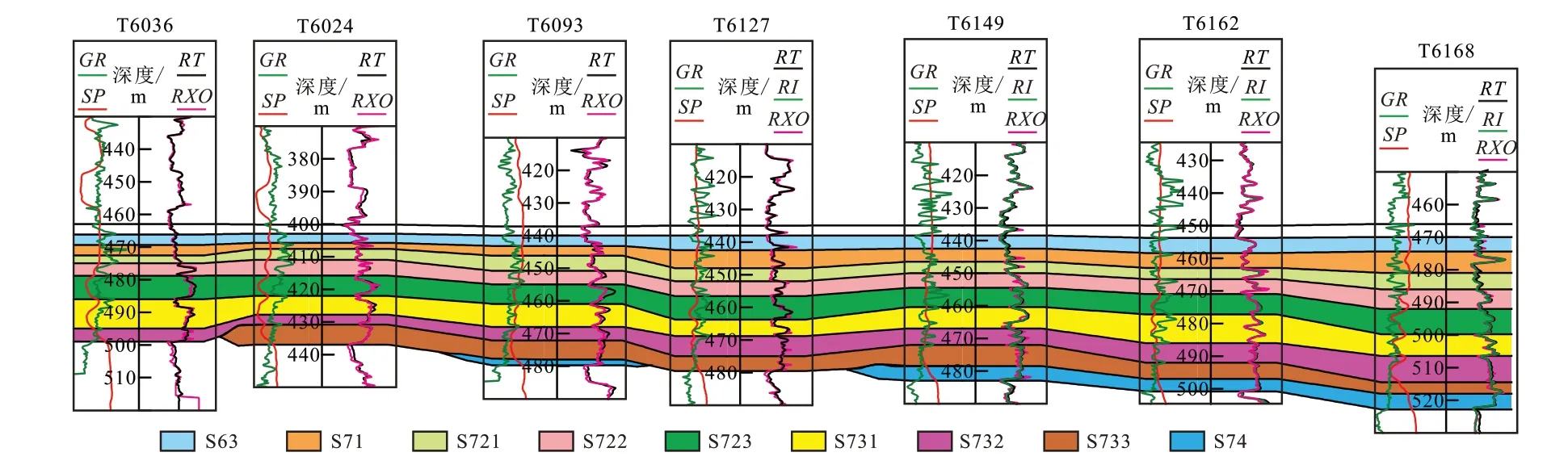
图1 准噶尔盆地西北缘某区克下组小层级别地层精细划分与对比Fig.1 Fine division and correlation of sublayers of Lower Karamay Formation in an area at northwestern margin of Junggar Basin
2.2 储层沉积微相(或储层构型)自动批量判别
储层沉积微相(或储层构型)研究是认识储层砂体发育规律最主要的途径。可以通过细分不同成因的沉积微相(或储层构型),刻画其在空间上的发育规律,在此基础上描述单砂体分布特征,指导方案的设计和调整措施的实施。储层沉积微相(或储层构型)自动批量判别和地层自动划分与对比类似,都是基于专业的软件平台,利用大数据技术,通过样本的机器学习来实现研究结果的批量实现。与地层精细划分与对比不同的是,储层沉积微相(或储层构型)需要用瓦尔特相律等地质规律对机器判别的结果进行约束,以保证研究结果符合地下地质实际,不能出现窜相的错误。总体上,储层沉积微相(或储层构型)对于地质规律的要求要远大于地层自动划分与对比。需要特别注意的是,无论是储层沉积微相还是储层构型的分类,都需要以人工划分的结果作为样本,通过机器学习来实现。在该过程中,需要优选特征的测井曲线和岩性来建立岩-电关系,即测井相。同时在这个过程中样本的数量要丰富到一定程度,以确保机器学习结果的准确性。笔者在进行准噶尔盆地西北缘某区克下组沉积微相和储层构型表征时,首先在典型井(取心井)上划分储层构型类型,利用专业软件平台建立模板,再利用软件平台特有的功能,初步实现了整个研究区储层构型单元的自动批量判别(图2)。但是受样本数量的限制及其他因素的影响,自动判别的储层构型划分结果还需要人工进行检查和修改完善,工作量减少的程度比较有限。未来可以逐渐积累,建立整个盆地不同层位不同沉积类型构型单元划分大数据库,在新区块构型表征时可以通过机器学习实现构型划分模板向整个研究区目的层的推广和自动划分。目前中国石油新疆油田和辽河油田正在开展相关的探索,虽然完全实现难度很大,但已经取得了一定的效果。

图2 准噶尔盆地西北缘某区克下组J6井储层构型划分结果Fig.2 Reservoir architecture classification results of Well J6 of Lower Karamay Formation in an area at northwestern margin of Junggar Basin
2.3 测井精细批量二次解释
测井精细解释是精细油藏描述中储层评价研究重要的组成部分。测井精细解释的成果可以为储层非均质性研究、储层定量分类评价、地质建模等提供数据基础,因此其研究成果的准确性对精细油藏描述至关重要。在测井精细二次解释中,首先是优选符合研究区目的层地质实际的测井曲线,或者测井曲线组合,结合分析测试获取的储层物性资料,建立测井解释图版,在测井解释图版的指导下,完成测井精细二次解释。在这个过程中,也一定程度上体现出大数据技术的特征。笔者在进行辽河盆地西部凹陷某区于楼油层测井精细二次解释时,就利用该思路来完成工作(图3)。目前有众多的专业软件可以辅助完成测井精细批量二次解释。该项工作中最重要的是解释图版的建立,现在常用的是分区分层位来建立测井解释图版,以提高解释图版的精度。中国石油新疆油田在基于大数据技术进行砂砾岩沉积储层测井精细批量二次解释方面做了有益的尝试,初见成效。

图3 辽河盆地西部凹陷某区于楼油层测井精细二次解释Fig.3 Fine logging reinterpretation of Yulou oil-bearing beds in one area of West Sag in Liaohe Basin
2.4 聚类分析储层综合定量评价
聚类分析是按一批研究对象在性质上的亲疏关系进行分类的一种多元统计分析方法。聚类分析可以分为对个案聚类(R 型聚类)和对变量聚类(Q 型聚类)。它能根据样品的许多观测指标(自变量参数)和具体计算样品之间的相似程度,把相似的样品归为一类,同时把关系密切的归为一个小分类单位,关系不密切的归到一个大分类单位,把所有样品归类完毕后,形成一个由大到小的分类系统[12-13]。
聚类分析是大数据技术数据信息挖掘中十分重要的方法之一,在精细油藏描述中的储层综合定量评价和流动单元研究等内容中都有比较广泛的应用,目前已成为储层定量分类评价的主流研究方法。笔者在进行鄂尔多斯盆地某区长2油层组低渗透砂岩储层综合定量评价时,就利用聚类分析的方法开展工作:将地质思维与数学统计分析相结合,既实现了地质思维在实际储层评价工作中的运用和体现,又克服了纯粹人工储层分类数据量过大、易出错且很难将多参数有机结合的缺点,实现了定性和定量相结合的储层综合分类评价(表1)。
在聚类分析过程中,当确定了有效厚度、孔隙度、渗透率、含油饱和度、夹层频率、层内渗透率突进系数等特征参数后,选用聚类分析方法中的KMeans 方法。该方法执行快速聚类的命令,使用K均质分类法对观测量进行聚类,适用于对大样本进行快速聚类,尤其是对形成的类的特征(各变量值范围)有了一定的认识时,此聚类方法使用起来更加得心应手。进行快速样本聚类首先要选择用于聚类分析的变量和类数。参与聚类分析的变量必须是数值型变量,且至少要有一个。为了清楚地表明各观测量最后聚到哪一类,还应该指定一个表明观测量特征的变量作为标识变量。
快速聚类方法的过程如下:如果选择了n个数值型变量参与聚类分析,最后要求聚类数为k。那么可以由系统首先选择k个观测量(也可以由用户指定)作为聚类的种子,n个变量组成n维空间。每个观测量在n维空间中是一个点。k个实现选定的观测量就是k个聚类中心点,也成为初始类中心。按照距这个类中心的距离最小原则把观测量分派到各类中心所在的类中去,形成第一次迭代形成的k类。根据组成每一类的观测量计算各变量均值,每一类中的n个均值在n维空间中又形成k个点,这就是第二次迭代的类中心,按照这种方法依次迭代下去,直到达到指定的迭代次数或达到中止迭代的判据要求时,迭代停止,聚类过程结束,最终得到储层分类评价的结果。
目前在一般精细油藏描述研究中,利用大数据技术中聚类分析方法进行储层综合分类评价没有遇到太大的问题和困难。但如果聚类分析的对象达到盆地级别,数据量极大丰富,这时聚类分析方法将遇到分类结果收敛性的问题,需要特别注意。
2.5 多点地质统计学三维地质建模
油藏描述的最终成果是建立定量的油藏地质模型,作为油藏模拟和油藏工程、采油工艺等研究工作的基础[14]。地质建模的方法有很多种,目前前沿的建模方法是多点地质统计学地质建模。多点地质统计学以训练图像为基本工具,着重表达空间中多点之间的相关性,能有效克服传统地质统计学在描述空间几何形态复杂的地质体方面的不足[15]。训练图像最大的优势是充分体现了不同沉积微相类型在空间上的定量分布模式,包括不同微相在空间上的叠置样式、规模、不同位置的变化等信息,使得研究者从基于两点的沉积微相平面分布特征把握变为对沉积微相发育特征的三维分布规律认识,认识的程度更加深刻准确。传统地质建模方法中的变差函数的最大特点是忠于井点等数据,而多点地质统计学建模中训练图像并不完全忠于井点数据,它只是井点数据统计规律的体现。训练图像建立过程中可以充分加入研究者的地质思维,而这在变差函数分析过程中基本是无法实现的[16],因此多点地质统计学建模方法具有一般建模方法所不具备的巨大优势。
从大数据技术角度考虑,多点地质统计学最关键是训练图像的代表性问题。笔者在进行辽河盆地西部凹陷某区于楼油层多点地质统计学建模时,通过对数十个随机建模模型中水下分流河道、河口砂坝、水下分流河道间砂、水下分流河道间泥和前缘席状砂等不同沉积微相在空间发育定量规模特征进行统计,结合人工绘制的沉积微相平面图来分层位、分区块建立研究区目的层的训练图像,最终建立研究区三维地质模型。在地质建模过程中,训练图像的代表性特征得到了充分体现(图4)。
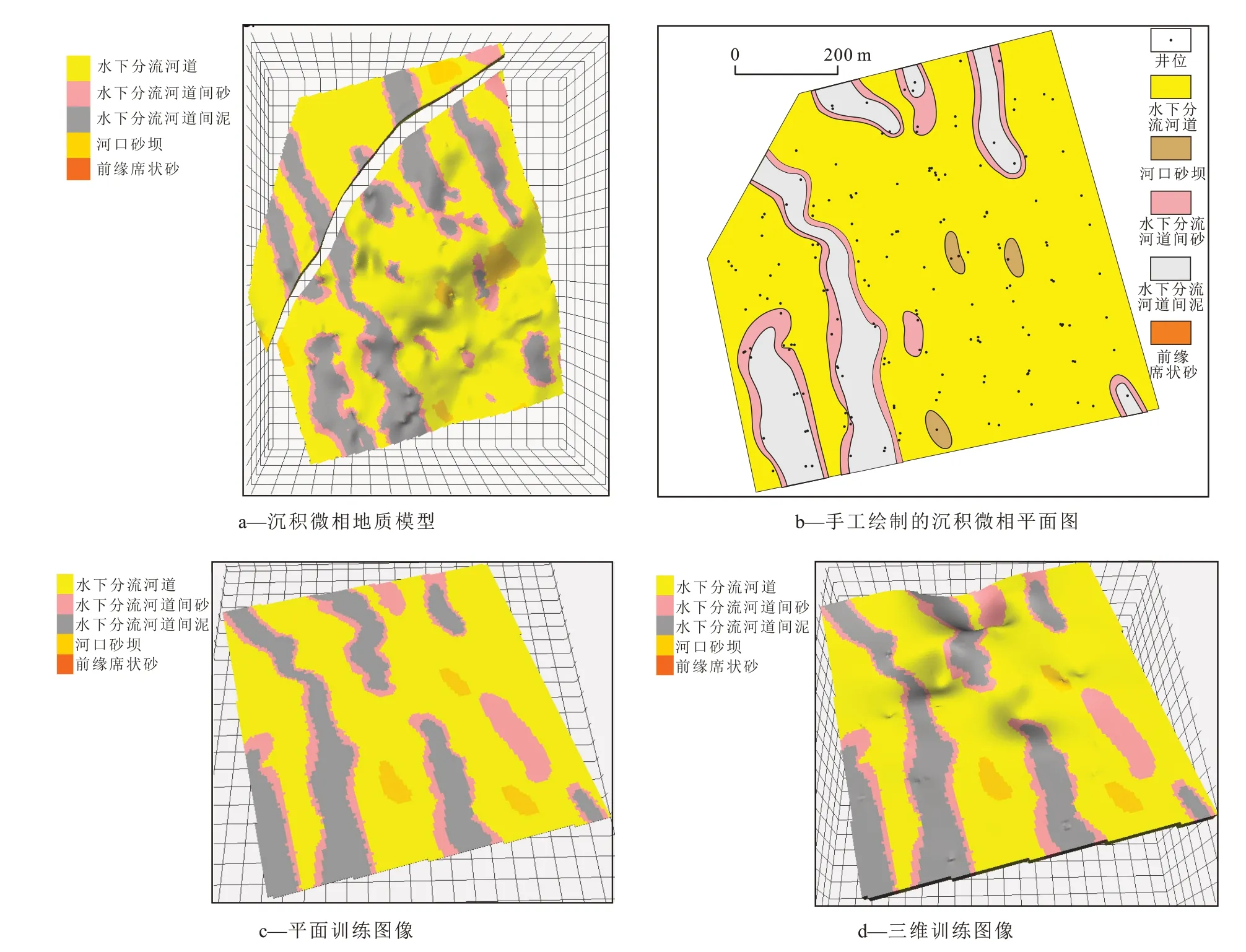
图4 辽河盆地西部凹陷某区于楼油层多点地质统计学建模中训练图像建立Fig.4 Training image construction in multipoint geostatistical modeling of Yulou oil-bearing beds in one area of West Sag in Liaohe Basin
3 存在的问题和发展方向
3.1 存在的问题
根据文献调研的成果,结合自身科研实践,笔者认为精细油藏描述中大数据技术应用存在以下主要问题。
大数据技术数据库的建设困难重重 目前精细油藏描述研究中,大数据技术应用刚刚起步,地质、地球物理和开发等不同类型的数据分散存储,还没有完善的针对性数据库为研究提供基础数据支撑。这样导致在项目研究中,研究者需要花费大量的时间用于基础资料的整理和收集,对人力物力资源是极大的浪费。
大数据技术信息挖掘需要加强 在精细油藏描述中,研究内容包括地层精细划分与对比、构造精细解释、沉积微相(或储层构型)研究、储层综合定量评价、地质建模和剩余油表征等,但目前大数据技术应用仅限于地层对比、沉积微相或储层构型表征、储层定量评价和地质建模等方面,而且应用程度很低。在多信息综合储层裂缝表征、动静态数据结合砂体连通性判别等领域还有很多难题需要攻关解决。
大数据的代表性问题十分突出 大数据是一定条件下的数据体,利用大数据可以有针对性地去获取一定条件下全体数据的信息,但样本数据并不是总体,只是无限接近总体。以上文多点地质统计学建模为例,建立的训练图像只是无限接近真实的地质模式,还存在一定的差异。而且因为陆相沉积地层特征的非均质性很强,因此选择分区分层位建立多个训练图像来约束三维地质模型的建立,取得了较好的效果。在精细油藏描述中,一定要在充分认识到大数据局限性的基础上,充分挖掘各方面信息,优选能够充分体现地质现象的数据体属性开展分析研究,凸显大数据技术的优势。
大数据多种类型数据之间的融合难度很大大数据的难点不是数据量大,而是数据类型多样。现有数据库软件解决不了非结构化数据的问题,因此要重视数据融合、数据格式的标准化和数据的互操作[8]。针对大数据信息挖掘中不同信息融合的问题,梁吉业提出可以探索基于多粒结构的多模态变量的关联关系挖掘,为复杂数据关联关系分析提供有效途径[17]。在精细油藏描述中,研究一个问题需要用到多种大数据信息,数据的融合至关重要。以地层精细划分与对比为例,研究中需要将地震资料和井资料紧密结合建立大尺度等时地层格架,在地层细分时,如果地震资料和井资料产生矛盾不一致时,应该以地震资料为准[18]。精细油藏描述其他内容研究中,也会遇到类似不同数据信息融合的问题,需要谨慎对待。信息融合不但有某项研究内容中的不同类型资料的融合,也有不同研究内容取得成果之间的融合。
大数据应用的安全性问题形势严峻 大数据应用的安全问题需要引起足够的重视。目前关于数据安全还主要是通过权限的设置等实现,但数据存储和提取过程中存在的网络安全等因素还需要建立相应的保障机制来将风险降低到最低程度。
大数据应用探索和领域需要不断拓展 从大数据技术在精细油藏描述中应用的范围而言,目前只是在地层对比、沉积微相(或储层构型)研究、储层综合定量评价和地质建模等工作中尝试使用大数据技术,对其使用的广度和深度还需要加强。从应用的领域来看,对非常规油藏等精细油藏描述新对象研究才刚刚起步,还有很多问题需要攻关解决。
3.2 未来发展方向
笔者总结精细油藏描述中大数据技术未来有如下几方面发展方向。
大数据应用平台建设 目前在数字油田建设等项目的支持下,不少油气田企业都建立了自己的数据平台,但是专门针对精细油藏描述研究的平台建设还处于起步和探索阶段,还有很多问题需要创新和攻关。宋洪庆等指出,油气资源大数据智能平台的总体框架应以数据资源为基础、大数据平台算力为支撑、人工智能算法为核心,面向油气行业生产需求,构建集勘探、开发、生产数据于一体的油气数据资源池,通过数据清洗与融合提升数据质量,整合物理模拟与数据挖掘等手段,实现服务功能模块化,并在PC端、管控大屏、手机移动APP等多维平台实现智能监测、预警与展示[19]。以中国石油为例,精细油藏描述大数据应用平台正在探索建设之中,目前在大庆、辽河、大港、长庆和新疆等油田已经初见成效,其他油田也在积极跟进。未来精细油藏描述大数据应用平台建设需要重点关注项目研究基础数据整理和收集、工作过程不同专业协同研究、成果安全标准存储和快速输出生产应用等3 方面内容。
大数据技术信息挖掘方法优化 目前在大数据技术信息挖掘方面,应用的主要方法包括聚类分析法、关联分析法、决策树、神经网络方法、遗传算法和特征分析法等[20-21]。还需要探索更新更有效的信息挖掘方法,提高大数据技术在精细油藏描述中应用的水平和质量。主要是探索创新各种数理统计计算方法,提高大数据技术数据信息挖掘的精确度、准确度。
大数据质量控制 大数据的质量控制存在于精细油藏描述研究的各项内容之中,比如测井精细解释中对于不同测井仪器、不同测试年代获得的测井曲线,在应用之前的归一化。再比如储层综合定量评价中对于取心井分析测试资料进行质量控制,剔除由于裂缝存在导致的渗透率异常的测试数据等。李金昌将大数据质量定义为基于大数据来源与构成的不确定性和极端复杂性、数据的可得性和可分析性等要素,而衡量的数据满足使用者需求的程度,它贯穿于从数据产生、数据选择到数据分析的全过程[22]。其中,准确性是最关键的要素。在精细油藏描述中,研究过程每一步都需要在关键节点设置大数据质量控制的内容,确保研究质量和最终成果的精确度和准确度。影响大数据质量的因素主要包括大数据来源多元化、数据总体多变且覆盖不全、数据表现非标准且含义非单一、数据真伪难分辨,需要全面慎重分析。
大数据中的可视化技术创新 可视化作为一种知识表达、知识展示和知识传递手段,通过交互可视界面进行分析、推理和决策,将复杂、抽象、枯燥、难于理解的数据转化为直观图形[23]。精细油藏描述中大数据技术可视化包括各种图件、地质模型等展示方式(图5)。精细油藏描述中大数据可视化技术为数据质量控制和成果应用等提供了有效工具,未来将成为研究者关注的焦点之一。

图5 辽河盆地西部凹陷某区于楼油层孔隙度地质模型Fig.5 Geological porosity model of Yulou oil-bearing beds in an area of West Sag in Liaohe Basin
海量油田开发大数据的标准化管理 油田开发,特别是精细油藏描述,需要用到大量的基础统计数据和综合研究成果数据,这些数据涉及地质、地球物理、油藏工程等诸多方面,如何将这些数据统一标准,规范管理,并准确便捷地应用至实际工作中,是精细油藏描述中大数据技术应用未来需要充分考虑的重点和难点。
大数据技术在非常规油气精细油藏描述中的应用探索 非常规油气目前已成为精细油藏描述新的研究领域,中国石油大庆油田的古龙页岩油、长庆油田庆城页岩油等都表现出良好的开发前景。未来将会有更多的非常规资源被发现并投入开发,这些非常规资源也将成为精细油藏描述十分重要的研究对象,大数据技术大有可为。
大数据技术目前作为一项新兴技术,在很多行业都在探索应用并初见成效。但是在精细油藏描述研究中,虽然之前的研究中也部分体现了大数据技术的特征,但大数据技术的深度应用才刚刚起步,还有许多难题需要探索攻关。大数据技术为精细油藏描述带来了机遇,同时也带来了挑战。可以通过建立大数据技术平台,利用大数据和人工智能等统计分析和自动学习的优势,充分挖掘地质、地球物理和动态监测以及生产动态资料之间的关系和规律,为低级序断裂体系空间分布规律刻画、井间砂体预测、井间砂体连通性分析、剩余油表征等精细油藏描述关键核心问题提供有效工具。
4 结论
精细油藏描述研究内容丰富,涉及海量数据。大数据技术可以为精细油藏描述研究提供坚实支撑。精细油藏描述中数据类型主要包括基础统计数据和综合研究成果数据,同时还包括地震解释数据体、地质模型等各类数据体以及各种成果图件。目前大数据在精细油藏描述中的应用主要体现在地层自动精细划分与对比、储层沉积微相(或储层构型)自动批量判别、测井精细批量二次解释、聚类分析储层综合定量评价和多点地质统计学三维地质建模等5方面。
精细油藏描述中大数据技术应用存在的问题主要包括:大数据数据库的建设困难重重、大数据技术信息挖掘需要加强、大数据的代表性问题十分突出、大数据多种类型数据之间的融合难度很大、大数据应用的安全性问题形势严峻、大数据应用探索和领域需要不断拓展。
精细油藏描述中大数据技术应用未来发展方向主要包括:大数据应用平台建设、大数据技术信息挖掘方法优化、大数据质量控制、大数据中的可视化技术创新、海量油田开发大数据的标准化管理、大数据技术在非常规油气精细油藏描述中的应用探索。可以通过建立大数据技术平台,利用大数据和人工智能等统计分析和自动学习的优势,充分挖掘地质、地球物理和动态监测以及生产动态资料之间的关系和规律,为低级序断裂体系空间分布规律刻画、井间砂体预测、井间砂体连通性分析、剩余油表征等精细油藏描述关键核心问题提供有效工具。
猜你喜欢
测井技术(2022年3期)2022-11-25
科海故事博览·上旬刊(2022年5期)2022-05-17
长江大学学报(自科版)(2022年2期)2022-03-21
科技创新导报(2020年19期)2020-09-26
石油研究(2020年3期)2020-07-10
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
科技创新与应用(2016年5期)2016-10-21
建筑工程技术与设计(2015年22期)2015-10-21
