
基于改进DDPG的空战行为决策方法
2022-02-25 05:09殷宇维胡剑秋
指挥控制与仿真 2022年1期
殷宇维,王 凡,吴 奎,胡剑秋
(江苏自动化研究所,江苏 连云港 222061)
空战行为决策是指我机根据战场实时态势采取行为策略以对敌方构成作战威胁、实施有效打击。在战机性能快速提升,空战对抗异常激烈的现代战场环境中,飞行员很难根据急剧变化和充满不确定性的战场态势进行快速有效的自主决策。因此,研究能根据战场实时态势进行智能决策的空战行为决策方法具有重大意义。
目前,空战决策方法主要分为数学推算、机器搜索和数据驱动三类。第一类基于数学推算的决策方法主要有微分对策法、最优控制等,虽然该方法具有可解释性强的优点,但其需要严谨的数学逻辑证明,且仅能对追逐、规避这类简单的空战形式进行有效建模,因此,在实际工程中实现困难,适用范围有限。第二类基于机器搜索的决策方法主要有影响图、蒙特卡洛搜索、决策树和近似动态规划等。这些方法主要逻辑为根据设计的态势评估函数对当前战场态势进行评估,然后,使用优化算法对最优策略进行搜索,但是这类方法存在的问题是:空战战场态势复杂,存在大量不确定性因素,态势评估函数设计困难,与此同时,空战节奏快,低效率的优化算法搜索难以满足根据实时态势进行快速决策的需求。第三类基于数据驱动的决策方法与机器搜索无本质上的区别,例如文献[12],虽然提到了强化学习的概念,但实质上仅利用神经网络的预测能力,为最优策略的搜索提供启发式经验。
与上述方法相比,深度强化学习方法能够基于深度神经网络实现从感知到决策控制的端到端自学习,在具有高度复杂性和不确定性的空战环境中能根据实时更新的战场态势进行行为决策。与上述方法相比,其不需要构建复杂的模型,且泛化能力更强。但采用深度强化学习的决策方法对奖励函数的设计十分敏感,而现有的奖励函数设计存在奖励信号过于稀疏,造成算法收敛缓慢甚至无法收敛,以及只适用于静态目标等问题。这种情况下也可采用专家系统来引导强化学习算法进行有效探索学习,但在充满随机性、对抗激烈的战场上,如何正确对战术动作进行抉择,是对专家系统的极大挑战;而且战场态势变化极其剧烈且复杂,没有重复的制胜法则,如果贸然引入专家干预,可能会导致算法越学越坏甚至无法收敛。
本文提出一种基于改进DDPG(Deep Deterministic Policy Gradient)的空战行为决策框架,在框架中设计一种针对动态目标的嵌入式人工经验奖励机制以解决上述奖励函数设置稀疏导致的收敛问题;同时针对现有的DDPG算法框架中Critic网络未得到充分训练,就急于更新Actor网络导致训练不稳定这一问题提出改进;并在框架中采用优先采样机制提高训练价值高的经验样本的利用率。最后通过实验验证了本文提出决策框架的有效性和优越性。
1 空战行为决策框架设计
1.1 总体框架设计
图1所示为基于改进DDPG的空战行为决策框架,整个框架包括态势信息处理模块、深度强化学习模块、经验存储模块、策略解码模块。

图1 基于改进DDPG算法的空战行为决策框架
决策框架流程如下:首先,框架中的态势信息处理模块将从战场环境中获取的态势信息数据进行归一化处理,将其作为智能体的状态送入深度强化学习模块;然后,深度强化学习模块中DDPG算法的策略网络根据状态输出策略;接着,策略解码模块根据其输出的策略添加噪声得到动作并执行;同时将状态、执行的动作、获得的奖励以及执行动作后的状态存入经验存储模块。框架训练时,依据优先采样机制从经验池中进行采样,将其送入DDPG算法框架对策略网络进行更新,同时采用软更新的方式对目标网络进行更新。
1.2 DDPG算法模型
DDPG算法是一种基于执行者-评论者(Actor-Critic,AC)框架的深度强化学习算法。AC框架的原理是利用Actor网络输出策略得到动作并执行,获得奖励计算回报得到状态的值,并以值得到目标函数用于Critic网络的训练,不断提高其对值评估的准确性,然后用Critic网络的输出代替总回报,计算策略梯度以更新Actor策略网络,由此不断改进策略。
本文采用的DDPG算法模型结构如图2所示,其采用策略-目标双网络结构以缓解自举和过估计的影响。模型中分别使用参数为和的Actor网络和Critic网络来输出确定性策略=π(|)和动作价值函数(,|)。其中,Actor网络根据当前状态,直接输出智能体采取的策略,而Critic网络用于对智能体当前策略进行评估,得到(,|)。

图2 深度确定性策略梯度算法模型示意图
在得到AC网络的输入输出后,需依据损失函数对这两个网络的权值进行更新,DDPG的损失函数与DQN类似,其输入来源于Critic网络输出的值,其损失函数为
=(-(,|))
(1)
而为
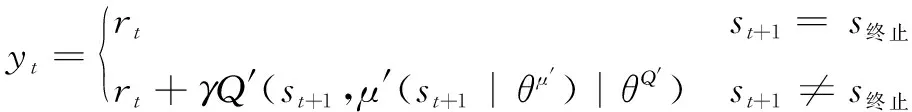
(2)
式(2)中,′是目标网络中的Critic网络的参数,′是目标网络中的Actor网络参数,而′表示目标网络中的Actor网络对状态+1下对动作的预测。
策略网络中Critic网络和Actor网络的更新则依据于损失函数的梯度,公式如(3)所示:

(3)
目标网络的更新则采用软更新方式,如公式(4)所示,即每隔一段时间保留一部分微小量的同时叠加复制策略网络的参数。

(4)
1.3 Actor-Critic框架中网络结构
本文AC框架中Actor网络和Critic网络的结构如图3所示,其中,上半部分为Actor网络,下半部分为Critic网络。

图3 AC框架中Actor和Critic网络结构
Actor网络的输入状态为1和2,分别包含全局位置态势信息和战机自身状态信息。全局位置态势信息为前五个采样时刻雷达观测到的敌我双方智能体的位置场景;局部状态信息则主要为当前采样时刻战机朝向、航速、远近程导弹的剩余量、敌方战机经纬度等具体的战机自身状态信息。通过卷积神经网络可对获取的位置场景进行特征提取,再与通过全连接层的战机自身状态信息进行拼接,作为送入Actor网络的状态。Actor网络的输出为该网络根据当前状态得到的确定性策略。
Critic网络的输入与Actor网络相比,增加了Actor网络输出的策略,输出则为Critic网络对该策略的评估,即值。
1.4 Actor网络延迟更新机制
根据DDPG算法模型可知,模型中 Actor网络的更新依据是Critic网络输出的值;但如果Critic网络未得到一定的训练,评估效果差时,其输出的值具有很大的不可靠性,此时更新Actor网络,非但不能对其改进,反而会造成输出策略不稳定,影响到 Critic网络的训练。
因此,可延迟Actor网络的更新,即每次训练时都对Critic网络进行更新,但每隔轮才会对Actor网络更新一次,此处的为超参数,在实验中进行调整。
1.5 基于动态目标的人工经验奖励机制
强化学习算法的训练对奖励函数的设置极其敏感,在本文的空战环境中,如果基于传统的奖励函数,智能体只有达到特定的状态(例如战机击毁敌方和被敌方击毁)才能得到奖励,这种状态空间巨大、奖励过于稀疏的情况会导致算法收敛缓慢甚至完全无法收敛的情况。
为解决这一问题,可引进人工经验对奖励函数进行改进,即当智能体向目标靠近时,会收到除传统奖励之外的额外奖励项。
=-
(5)
其中,表示前一时刻智能体与目标的距离,则表示当前时刻智能体与目标的距离。
但本文实验通过实验发现上述奖励函数的设置并不适合动态目标,已知额外奖励项与智能体和目标间的距离变化有关,当目标为动态时,两者间的距离变化不仅与智能体采取的动作相关,动态目标的位置变化也会对其产生影响;这种情况下,即使智能体采取了远离目标的动作,其仍有可能获得正的额外奖励项,这显然与奖励函数的设置应引导智能体选择恰当的动作这一原则相悖。


图4 基于动态目标的人工经验引导奖励设置

(6)

经过改进后的奖励函数为:
=(1-)*+*
(7)
=*0995
(8)
将奖励函数改进后,训练初期获得的奖励主要为额外奖励,即引导战机主动追寻敌机,而随着训练迭代次数的叠加,传统奖励开始占据主导,此时主要探索战机的空战行为策略。这种嵌入人工经验引导的额外奖励机制可使原本稀疏的奖励变得稠密,以达到加快算法收敛的目的。
1.6 优先采样机制
强化学习算法一般通过设置经验池,随机均匀采样的方法消除样本的数据关联性。但是训练过程中存入经验池中的绝大多数都是训练价值很低的经验样本,而价值高的经验样本却占比很小;这种情况下,采用随机均匀采样会使得价值高的经验样本没有被高效利用。因此,应设置一种优先采样的机制,确保价值高的经验样本会被优先采样。
本文中首先定义经验样本价值高低的衡量标准,已知强化学习算法中网络训练的目标为降低损失函数的值,因此,损失函数的值越大,对网络的训练所起作用就越大。而损失函数一般是Td-error的均方。因此可依据经验样本的Td-error绝对值大小进行排序,并据此采样。公式如下:

(9)
其中,表示样本总个数,表示第个经验样本在所有样本中排序的位数,则该经验样本被采样到的概率为其倒数除以所有样本位数倒数之和,即Td-error绝对值越大,其在所有经验样本中排序就越靠前,被采样的概率越大。
1.7 算法决策框架流程

参数输入:状态空间S,动作空间A,折扣率γ,学习率α,目标网络更新软参数τ初始化经验池和经验池大小初始化策略Critic网络参数θQ和策略Actor网络参数θμ初始化目标Critic网络参数θQ→θQ'和目标Actor网络参数θμ→θμ'

repeat:起始状态S0repeat: 处于状态St时,依据策略Actor网络输出选择动作at=π(st| θμ)+Nt(添加噪声,鼓励探索)战机执行动作at,与环境交互,得到奖励Rt+1以及新的状态St+1计算St,at,Rt+1,St+1的TD误差大小,按大小排序存入经验池D中依据经验排序从经验池中进行优先抽样得到S,a,R,S'依据目标Q网络得到更新目标:yt=rt st+1=s终止rt+γQ'(st+1,μ'(st+1| θμ')|θQ') st+1≠s终止 损失函数为L=1N∑i(yt-Q(st,at| θQ))2以损失函数对策略Q网络进行更新策略Q网络每更新k次,策略Actor网络更新一次状态转移St+1→St对目标AC网络的参数进行软更新:θQ'=τθQ+(1-τ)θQ'θμ'=τθμ+(1-τ)θμ' 当St+1为终止状态时,跳出循环训练结束,退出循环
2 仿真实验结果
2.1 实验仿真环境
本文的实验环境基于中电集团开发的MaCA平台,实验想定如图5所示,红蓝双方各一架配置相同的战机,想定范围为1000 km*1 000 km的区域。
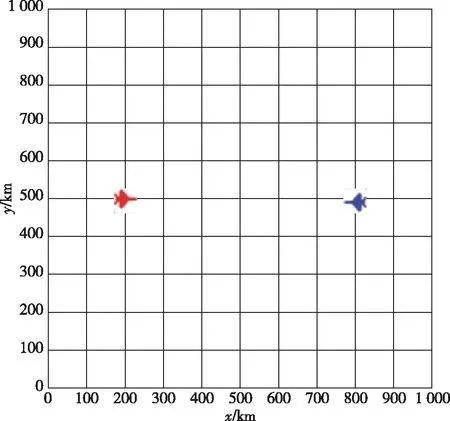
图5 实验仿真场景设定示意图
2.2 模型构建
根据前文所述的改进DDPG算法构建强化学习智能体,并对智能体的状态、动作和奖励函数进行设计,同时在实验中调整超参数。
战机状态信息主要为根据雷达观测构建的全局位置态势以及朝向、航速、远近程导弹的剩余量等这类战机自身状态信息。
战机动作信息则主要为战机航向、雷达开关及频点、干扰设备及频点、远近程导弹发射。
奖励函数则按照上节中所述方法进行设计。 而实验中超参数的设置见表1。

表1 超参数设置
2.3 实验结果分析
为检验本文提出的基于改进DDPG的空战行为决策框架(Air Combat Behavior Decision-making Framework on Improve DDPG,ACBDF_DDPG)的有效性和优越性,同时为分别研究算法框架中优先采样、Actor网络延迟更新和基于动态目标的嵌入式人工经验奖励这些改进机制对算法实验效果的影响,在ACBDF_DDPG框架基础上减去这些改进机制进行消融对比实验。消融实验的设置如表2所示。

表2 消融对比实验设置
消融对比实验的结果和性能对比图分别如表3和图6所示,可以看出,随着训练次数的增加,ACBDF_DDPG模型的胜率逐渐上升,大约在6500轮开始收敛,收敛后胜率稳定在83.1%左右。
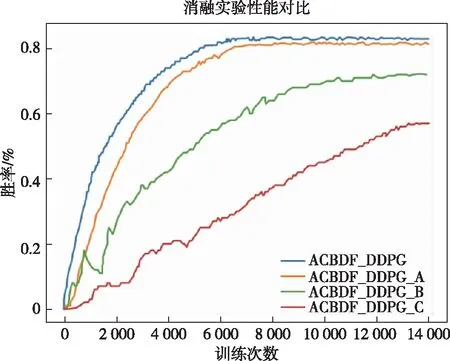
图6 消融实验性能对比图

表3 消融对比实验结果数据
同时,从结果可以看出框架中的三种改进机制对于模型的实验性能均有一定的提升,但由于作用机制存在差异,提升程度并不相同。例如,优先采样机制对于模型的收敛速度和收敛后的性能提升就比较小,剔除优先采样机制的ACBDF_DDPG _A模型大约在7000轮开始收敛,稳定后胜率保持在81.3%左右,其与ACBDF_DDPG模型相比差距并不大。而Actor延迟更新机制和嵌入式人工经验奖励机制的采用均很大程度上提升了算法框架收敛稳定性和实验性能。其中,嵌入式人工经验奖励机制的提升效果最为明显,其作用在于初期能对框架模型进行一定的引导,减少由于传统奖励稀疏造成的盲目性,如此不仅大大提升了算法框架的收敛速度,也给收敛后算法框架性能带来显著提升——由实验结果可知当剔除该机制时,ACBDF_DDPG _C模型直到13 600轮才开始收敛,而且收敛后的胜率仅维持在57.0%左右。Actor延迟更新机制的改进主要在于多次更新Critic网络,使其评估效果较好后再更新Actor网络;通过实验结果对比可知,未采用该机制的ACBDF_DDPG_B模型在训练中尤其是训练初期,稳定性较差,性能曲线出现了大幅震荡,而且收敛速度变慢,大约在11 300轮才开始收敛,收敛后的胜率稳定在72.1%,与ACBDF_DDPG模型的结果83.1%相比也存在一定的差距。
3 结束语
针对空战行为决策这一背景,本文主要提出了一种基于改进DDPG算法的空战行为决策框架。在框架设计的过程中分析了现有奖励函数设置稀疏会导致算法收敛慢甚至不收敛,针对这一问题在框架中增加了嵌入式人工经验奖励机制,同时对其只适用于静态目标这一缺点进行改进;另外,在框架中采用Actor网络延迟更新机制以缓解现有DDPG算法模型中AC网络更新方式导致的训练不稳定和算法模型性能较差等问题;最后,在框架中采用优先采样机制确保训练过程中训练价值高的经验样本得到充分利用。最后,在仿真实验平台上开展仿真实验对比,验证了本文提出算法框架的有效性和优越性。
猜你喜欢
文史春秋(2022年4期)2022-06-16
小资CHIC!ELEGANCE(2022年1期)2022-01-11
军事文摘(2020年3期)2020-04-02
青少年科技博览(中学版)(2019年2期)2019-06-20
现代职业教育·职业培训(2019年12期)2019-02-03
决策(2018年8期)2018-12-10
小天使·四年级语数英综合(2018年1期)2018-07-04
电子技术与软件工程(2018年11期)2018-02-25
连环画报(2015年12期)2016-01-14
中国报道(2015年6期)2015-06-19
