
基于Attention的AIS数据段相似性搜索模型
2022-02-25 05:22赖俊星
指挥控制与仿真 2022年1期
李 丽,赖俊星
(1.中国人民解放军91001部队通频室,北京 100072;2.中国船舶工业综合技术经济研究院,北京 100072)
当前,自动识别系统(Automatic Identification System,AIS)在船运领域中广泛应用,以提高船舶航行的安全性与效率。AIS数据内部蕴含着大量的海上交通时序信息,包括航速、航向、经纬度等船舶的动态信息和船名、呼号等船舶静态信息。船载AIS数据是记录船舶航行与作业信息的大规模数据,包含船舶行为特征与航行规律,AIS数据挖掘,是研究船舶行为特点的重要方法。在众多AIS数据挖掘方法中,相似性搜索可以帮助人们进行相似航线识别以及异常船只的检测,在提升船舶航行安全以及船舶目标信息识别等方面具有重要的实际应用与研究意义。
AIS数据属于时间序列数据,在时间序列数据挖掘领域中,给定待查询数据段在数据库中搜索到与其相似的数据是较为基本的要求。然而,对于AIS数据进行相似性搜索是一种具有挑战性的工作,主要由于:1)相比于单变量时间序列数据,AIS数据这种多变量时间序列数据具有海量、高维的特点,使得捕获其数据特征更加困难;2)由于AIS数据中时序特征以及属性变量潜在关联关系的存在,为相似性表示增加困难。
在众多时间序列相似性搜索方法中,基于二进制编码的模型被广泛使用,例如:局部敏感哈希(LSH)通过计算产生编码的汉明距离来得到最相似的数据段,这种方法相比于传统相似性方法可以降低计算过程中的时间复杂度。另外一种广泛使用的方法是使用滑动窗口切割原始时间序列数据,然后通过最小距离方差法生成搜索索引并计算索引结构来搜索时间序列数据段。近年来,深度学习成为最广泛应用的数据挖掘技术之一,其可以自动地对原始数据进行特征的抽取。在这种情境下,基于深度学习的二进制编码生成模型便有潜力进行AIS数据的相似性搜索。注意力机制在深度学习领域被广泛应用,通过利用注意力机制可以帮助深度学习模型对输入的部分赋予不同的权重,从而提升模型的判断能力。基于此,本文提出基于Attention机制的Seq2Seq模型来完成AIS数据相似性搜索任务。其中,基于GRU的Seq2Seq网络可以学习AIS原始数据中的时序特征,Attention机制可以捕获AIS数据中各参数变量之间的依赖关系。
1 研究背景和相关工作
时间序列相似性搜索是一个热点问题,在工业界、金融界等多个行业展开了广泛的研究。对时间序列数据进行相似性搜索有助于促进其他时间序列数据挖掘领域的分析工作,例如:异常数据检测、序列数据标注、数据状态识别以及基于相似性搜索结果进行时间序列预测等。同样地,在AIS数据挖掘领域,相似性搜索可以进一步辅助行业工作人员进行航迹分析、相同航迹匹配以及异常船只识别等,具有较为重要的研究意义。对于时间序列相似性搜索,前人的工作主要可分为:传统时间序列数据表示以及基于深度学习的时间序列数据表示方法。本部分主要介绍传统时间序列表示方法以及Seq2Seq模型和Attention机制。
1.1 传统时间序列表示方法
传统的时间序列数据表示方法主要通过对原始数据进行降维,并使用降维后的数据空间进行时序数据的相似性搜索。近二十年来,多种基于降维的时间序列相似性搜索方法被提出,例如:离散傅里叶变换(Discrete Fourier Transform,DFT)、离散小波变换(Discrete Wavelet Transform,DWT)、符号近似聚合(Piecewise Aggregate Approximation,PAA)、主成分分析(Principle Component Analysis,PCA)、基于动态时间弯曲(Dynamic Time Warping,DTW)等。然而,通过这些方法得到的向量表示通常需要相应领域的先验知识,也存在查询结果有效性和查询效率偏低、算法复杂度较高等问题。
1.2 Seq2Seq模型和Attention机制
Seq2Seq模型通常与自动编码器相关联,其中包括编码器以及解码器,并且编码器或解码器也通常使用训练神经网络进行模型学习。编码器读取输入序列=(,,…,)并将其转换为固定长度的向量表示或内容向量。接下来,解码器将向量表示进一步转换为与输入数据长度相同的输出序列=(,,…,)。
Seq2Seq模型在处理时间序列数据时存在着相应弱点,主要是因为模型中的向量表示无法对输入时序数据的特征进行完全的捕获。对此,研究者们提出Attention机制来使解码器对编码器相应的隐藏层进行选择。近年来,研究者们提出了几种Attention模型。通常地,Attention模型的操作如下:在时刻的解码过程中,Attention模型通过对编码器中所有隐藏层进行加权求和计算得到相应的内容向量。通过打分函数计算得到求和过程的权重,从而对解码器中各隐藏层的相似性进行测量。最后,相应的分数通过softmax函数进行归一化。
2 基于Seq2Seq的AIS数据段相似性搜索模型
本部分提出基于Attention机制的Seq2Seq模型来进行AIS数据段的相似性搜索。在详细介绍该模型之前,先对本文研究的基本问题进行初步介绍。该相似性搜索模型包含:GRU编码器、时序Attention机制以及GRU解码器三部分。
2.1 问题描述
AIS数据是记录船舶航行与作业信息的大规模数据,包含船舶行为特征与航行规律。主要包括船舶静态数据、船舶动态数据和船舶航程数据。船舶静态数据包括船名、呼号、MMSI、IMO、船舶类型、船长和船宽等; 船舶动态数据包括经度、纬度、船首向、航迹向和航速等; 船舶航程数据包括船舶状态、吃水和目的地等。其中,船舶动态数据是船舶位置经纬数据的主要来源。
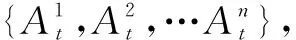
给定待查询AIS数据段,通过构建基于Attention机制的Seq2Seq模型,在AIS时间序列数据库中搜索到与之相似的数据段具有重要的实际应用意义。
2.2 模型定义
基于Attention机制的Seq2Seq相似性搜索模型结合了时间序列数据与Seq2Seq模型的特点,使用Seq2Seq模型中GRU编码器产生的二进制编码进行AIS时间序列数据的相似性搜索。如图1所示,预处理后的AIS数据段作为GRU编码器的输入,通过编码过程来进一步获取输入AIS数据的时序信息,并通过GRU解码器来重构AIS输入数据。此外,用于衡量AIS数据段之间相似性的二进制编码在GRU编码器与解码器之间生成。整个模型通过计算输入数据与GRU解码器生成的重构数据之间的均方误差损失来进行训练。
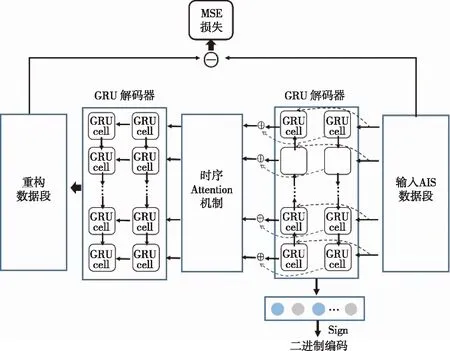
图1 基于Attention的AIS数据段相似性搜索模型
由于船舶的速度和航向经常发生变化,经纬度值具有较大的波动性,使用原始的AIS数据进行建模预测容易造成较大的误差。因此,本文采用中值滤波的方法对AIS数据预处理,分析该时刻邻域内的多个数据来计算在该时刻的信息。使其更接近于真实值。
设AIS在时段的数据为(),由其周围2个数据点组成的数据集合为
[(-),…,(),…,(+)]
则进行中值滤波后该点的值为
()=Med[(-),…,(),…,(+)]
中值滤波的优点在于对如AIS数据这种单位时间内的位移波动较大的数据,起到较好的消噪效果,使其更接近于真实值。

GRU网络是用来学习原始时间序列数据时序依赖特征的常用模型。典型的GRU单元包含2个门,分别是更新门(update gate)和重置门(reset gate),其分别具有不同的作用:1)更新门:控制前一步隐藏层保留至当前状态下的信息量; 2)重置门:控制当前输入信息与之前记忆信息的结合,GRU内部原理如图2所示。
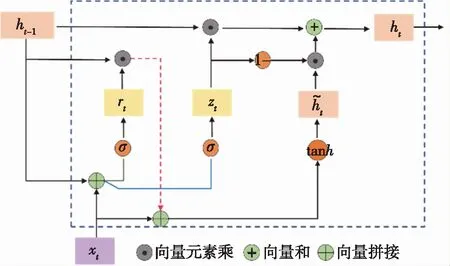
图2 GRU网络内部结构
其中,更新门和重置门所对应的公式如下:
=(+-1+)
=(+-1+)
此外,内部状态的计算公式如下:
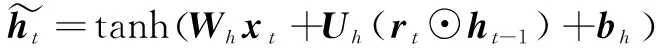
最终传递给外界的外部状态为:
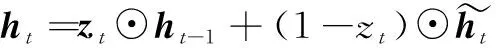
然而,传统的GRU在挖掘时间序列数据中有着相应弱点,其只能学习到先前的时间序列数据特征,对于后续时间序列的时序关系特征无法进行捕获。因此,本文使用双向GRU网络(Bi-GRU)作为编码器,通过两个相互关联的隐藏层单元在不同的方向同时进行输入时间序列数据的处理。
选用两层单向的GRU网络作为解码器,对输入AIS数据进行重构。解码器中隐藏层可通过公式进行更新。对于解码器得到的重构数据,通过两层的全连接网络以得到与输入数据相同的尺寸,便于进行均方误差的计算。此外,为防止过拟合,在解码器中的GRU层以及全连接层也加入Dropout层以及正则化层。

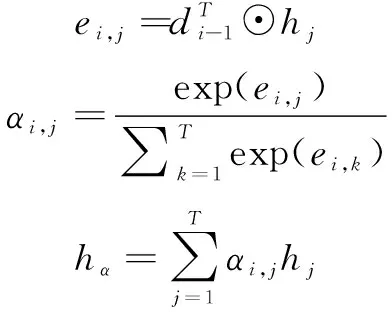
其中,-1为解码器的隐藏层,,为编码器的输出与-1的点积操作结果。计算出的作为编码器所有隐藏层输出的加权和。
对于GRU编码器的输出数据,本文使用一层全连接神经网络来产生特征向量[,,…,]。并使用二进制嵌入映射方程将该特征向量压缩为二进制编码,其中映射方程具体可表示为
=sgn(),=1,2,…,
其中sgn(·)为信号方程,当输入值大于0时该方程的输出为1,小于0时输出结果为-1。对于生成的二进制编码,我们通过计算其汉明距离来进行AIS数据的相似性搜索。
对于基于Attention机制的Seq2Seq的相似性搜索模型,损失函数定义为输入与输出时序数据之间的重构误差。重构误差的计算过程如下:

其中,、为数据段的长度与属性参数数量,与′分别表示模型输入与输出数据。本文使用Adam优化器来训练模型并且最小化损失函数。在训练合适的回合数后,相应的模型参数将用于测试数据集进行相似性搜索。
3 实验验证与结果分析
3.1 实验数据
本文实验选用的自有北斗定位的AIS数据集,数据集包括了3502条船体的定位信息,共232.5万条数据信息,AIS数据是一种时间序列数据,本文所用的每一个时间点的数据所包含的信息主要包含船体ID信息、经度、维度、速度、方向、时间及工作类型,单个船体具体数据示例如表1所示。
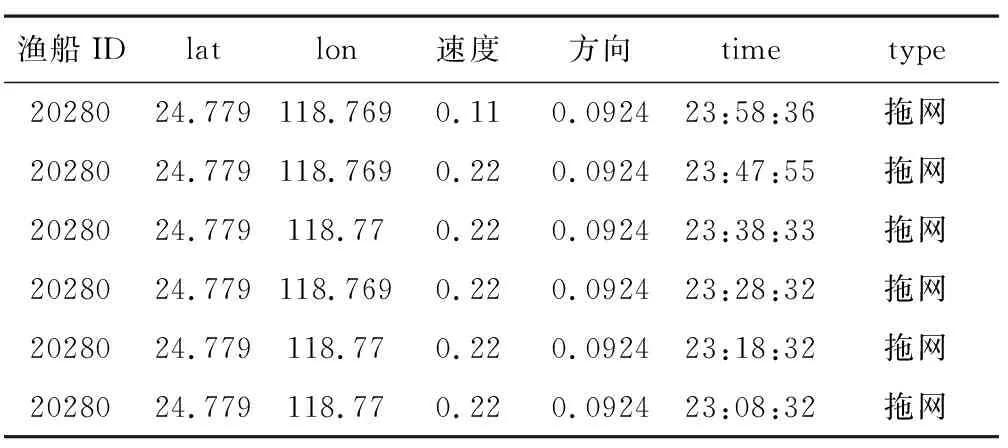
表1 AIS数据实例
实验中将已知的航道作为“标签变量”使用,计算实际的轨迹数据与这些已知航道之间的距离。在进行相似性查询之前,还需要在这些距离结果的基础上做一些初步的处理:
1)将轨迹数据归类到某个航道。对于这一功能的实现,会设置一个阈值,当一条轨迹数据到某个航道的距离小于这个阈值时,就将相应的轨迹归类到这个航道。
2)轨迹数据偏离航道检测。当轨迹数据到所有已知航道的距离都大于阈值时,就可以将这条轨迹数据归类为异常数据。
3)未知新航道检测。对于异常数据,可以使用非监督的聚类算法,再次重复上面的算法得到相应的航道发现结果。
经过数据预处理后得到的航道发现结果如图3。其中,坐标分别对应经纬度值,举例了两个航道的轨迹数据,偏离航道的异常数据用黑色点表示。
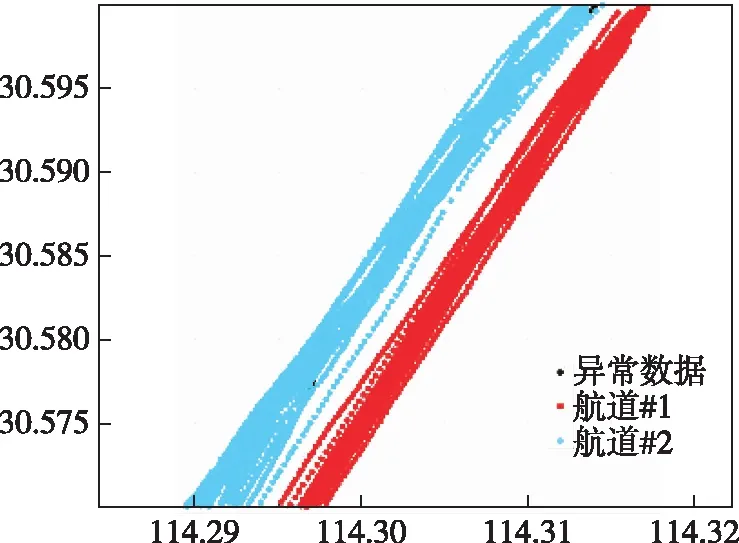
图3 AIS数据预处理后的航道轨迹图
3.2 模型参数设定与评估方式
上文提到在模型训练过程中,使用Adam优化器,学习率设定为0.0002。模型实验使用的batch-size为128。AIS相似性搜索模型中GRU编码器与解码器的hidden-size设定为100。此外,GRU网络以及全连接层中Dropout的值设定为0.3。
为评估相似性搜索模型的性能,对于给定的查询数据段,在数据集中基于欧氏距离计算待查询数据段的近邻数据段作为基准结果。对于搜索模型产生的二进制编码,使用汉明距离来找出带查询数据的相似数据段。相似性搜索模型的有效性将通过三种指标进行评估,分别为平均精度均值(Mean Average Precision, MAP)、Top-k准确率(precision at top-K position, Precision@K)以及Top-k召回率(recall at top-K position, Recall K)。
3.3 实验结果与分析
将基于Attention机制的Seq2Seq的相似性搜索模型与不包含Attention机制的Seq2Seq模型以及传统的时间序列相似性搜索方法LSH进行实验对比以验证本文所提模型的有效性。
为评估基于Attention机制的Seq2Seq的相似性搜索及其对比模型的有效性,表2给出了不同二进制编码维度下(=64,128,256),三种模型的平均精度均值。从表2中可以看出:相比于传统的时间序列相似性搜索方法LSH,基于Seq2Seq的相似性搜索模型展现出更好的搜索结果,这主要归因于LSH无法捕获AIS时间序列数据中的时序依赖关系,进而导致在相似性搜索过程中无法形成适合的时间序列向量表示。此外,相比于不包含Attention机制的Seq2Seq模型,基于Attention机制的Seq2Seq模型展现出更为优异的AIS时序数据相似性搜索性能,这主要是由于Attention机制可以进一步学习AIS时序数据中各参数变量之间的依赖关系,从而提升整个模型的相似性搜索性能。

表2 三种方法在AIS数据集上的MAP值
为了进一步验证本文所提出模型的有效性,图4以及图5分别给出了基于Attention机制的Seq2Seq模型与其他模型的Top-k准确率以及Top-k召回率的对比结果。如图5所示,基于Attention机制的Seq2Seq模型相比于对比模型展现出更高的Top-k准确率。同样地,通过图5可以看出:在Top-k召回率上,本文所提出的模型也均优于对比模型。以上结果表明,本文所提模型在基于汉明距离的搜索Top-k列表中展现出较高的准确率及召回率,这意味着这种基于Attention机制的Seq2Seq模型,不仅可以捕获AIS数据中的时序信息,而且由于Attention机制的存在也可对AIS数据中各参数变量之间的依赖关系进行学习,从而进一步提升模型的相似性搜索性能。

图4 三种方法在AIS数据上的Top-k准确率曲线(v=256)

图5 三种方法在AIS数据上的Top-k召回率曲线(v=256)
4 结束语
本文提出了一种基于Attention机制的Seq2Seq模型用于AIS时序数据的相似性搜索任务。通过实验对比了LSH,不包含Attention机制的Seq2Seq模型以及本文所提出模型在AIS数据集上的相似性搜索效果,验证了所提模型的有效性。在AIS数据集上,本文提出的基于Attention机制的Seq2Seq模型展现出优异的时间序列数据相似性搜索性能,可以为AIS数据挖掘的相关应用提供便利。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
现代信息科技(2019年18期)2019-09-10
科技创新与应用(2017年26期)2017-09-12
科技与创新(2017年5期)2017-03-28
中国信息技术教育(2016年13期)2016-09-10
电脑爱好者(2015年24期)2015-09-10
