
结合双语义数据增强与目标定位的细粒度图像分类
2022-02-24 05:06叶武剑刘怡俊
计算机工程 2022年2期
谭 润,叶武剑,刘怡俊
(广东工业大学信息工程学院,广州 514000)
0 概述
细粒度图像分类是计算机视觉领域一项极具挑战和应用价值的研究课题,其在传统图像分类基础上进行更精细的图像类别子类划分,如区分鸟的种类等。区别于传统图像,细粒度图像均来自同一基本类别,不同子类图像间的差异较小,只通过目标整体轮廓往往无法取得良好的分类效果;而同一子类不同图像中又存在姿态、光照、背景遮挡等诸多影响因素,类内差异较大,因此,细粒度图像分类往往只能借助于极其细微的局部差异才能较好地完成分类。同时,细粒度图像数据库的获取和标注依赖于专家级别的知识,制作成本和时间成本昂贵。上述这些问题都给细粒度图像分类造成了极大的困难,使现有算法难以很好地完成分类任务。
细粒度图像分类的研究工作主要分为基于强监督信息和基于弱监督信息2 个方向[1-2]。两者区别在于,基于强监督信息的算法需要引入额外的人工标注信息,如局部区域位置、标注框等,用于定位图像局部关键区域,而基于弱监督信息的算法仅依靠图像标签完成图像局部关键部位的定位和特征提取。目前研究思路主要分为2 种:一是通过构建更具判决力的特征表征,适配于复杂的细粒度图像分类任务;二是在算法中引入注意力机制,通过注意力机制弱监督式地聚焦于部分局部区域,进一步提取特征,但仍存在定位不准确的问题。同时,细粒度图像中存在较多的遮挡,只通过提取少部分的局部关键特征,往往无法在所有同一类别图像上得到对应,不能达到良好的分类效果。
本文提出一种基于双语义增强和目标定位的细粒度图像分类算法。以双线性注意力池化(Bilinear Attention Pooling,BAP)方式构建注意力学习模块和信息增益模块提取双语义数据,并结合原图通过双语义数据增强的方式提高模型分类准确率。该算法一方面通过模块相互增益可控地学习图像中多个局部关键特征,另一方面分别获取2 种语义层次数据,用于丰富模型训练数据,以双语义数据增强的方式辅助模型训练,同时在测试阶段构建目标定位模块,实现目标整体定位。
1 相关工作
目前,单独使用传统的卷积神经网络(如VGG[3]、ResNet[4]和Inception[5-6])无法很好 地完成细粒度 图像分类任务,因此,研究者通常在传统卷积神经网络的基础上进行基于强监督信息或基于弱监督信息方向的算法研究。
1.1 基于强监督信息的细粒度图像分类
基于强监督信息的细粒度图像分类算法需要利用训练数据集中已有的人工标注信息定位局部关键部位,再进一步提取特征。ZHANG 等提出Part R-CNN算法[7],利用选择性搜索形成关键部位的候选框,通过目标检测R-CNN[8]算法对候选区域进行检测,挑选出评分值高的区域提取卷积特征用于训练SVM分类器。BRANSON 等从分类目标姿态入手,提出姿态归一化CNN[9]。LIN 等提出Deep LAC[10],在同一个网络中进行部件定位、对齐及分类,设计VLF 函数用于Deep LAC 中的反向传播。但基于强监督信息的算法所依赖的人工标注信息获取耗时且代价昂贵,导致该类算法实用性较差。
1.2 基于弱监督信息的细粒度图像分类
仅依靠图像标签信息完成细粒度图像分类任务成为近年来主要的研究方向。JADERBERG 等提出时空卷积神经网络(ST-CNN)[11],在目标合适的区域进行适当的几何变换校正图像姿态。FU 等提出循环注意力神经网络(RA-CNN)[12],在多尺度下递归式地预测注意区域的位置并提取相应的特征,由粗到细迭代地得到最终的预测结果。但该模型在同一时间只能关注于一个注意力区域,存在时间效率问题。ZHENG 等提出多注意力卷积神经网络(MA-CNN)[13],通过构建一个部位分类子网络学习多个特征部位。但该模型在同一时间只能定位2~4 个关键局部区域,这对于复杂的细粒度图像仍是不够的。
1.3 双线性网络
双线性网络也是弱监督算法的一种,与同类算法不同,其从高阶特征表达的角度出发,以外积汇合的方式聚合2个特征块。这种高阶特征间的交互作用适配于细粒度图像分类任务,如LIN 等提出双线性CNN[14]和 改进的 双线性CNN[15]用 于细粒度图像分类,LI 等利用矩阵平方进一步改进双线性CNN[16]。但该类算法往往受限于较高的计算复杂度。HU 等在双线性CNN 的基础上提出双线性注意力池化方法[17],同时对原图采取注意力式剪切、注意力式丢弃,得到可以随着模型迭代更新变动的增强数据,这些数据和原图一起以数据增强的方式提高模型分类准确率。但该算法只利用了单一语义的数据增强方式,对于更复杂的细粒度图像任务仍存在缺少有效分类信息的问题。
为提取足够多的有区分度的局部关键特征,本文在训练阶段以双线性注意力池化的方式在网络不同深度构建注意力学习模块和信息增益模块,同时为提高模型中期特征表达能力,并行地在注意力学习模块和信息增益模块中分别引入卷积块注意模块(Convolutional Block Attention Mmodule,CBAM)。而在测试阶段,通过注意力学习模块和信息增益模块分别得到特征图,并以此构建目标定位模块用于聚焦图像中的目标整体,从而进一步提高分类准确率。
2 本文分类算法
本文算法的训练流程及网络模型如图1 和图2所示,测试流程如图3 所示。训练流程模块分别提取两种语义层次的数据,以2 种语义数据增强的方式辅助模型训练。
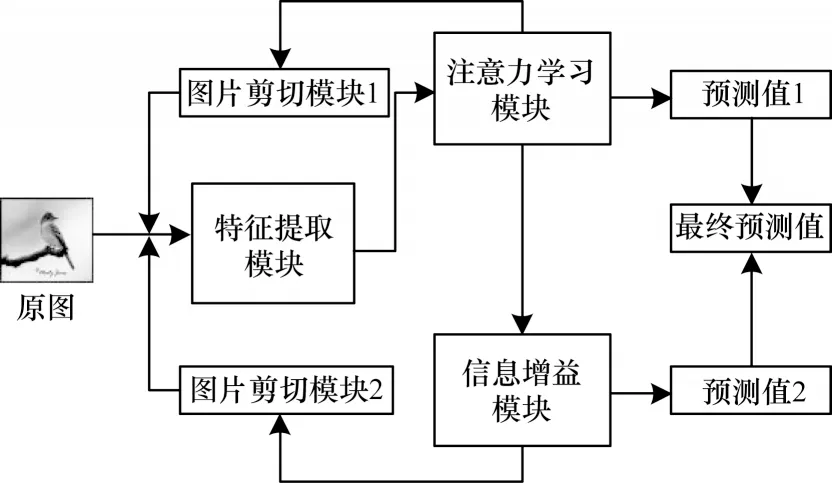
图1 训练流程Fig.1 Training procedure
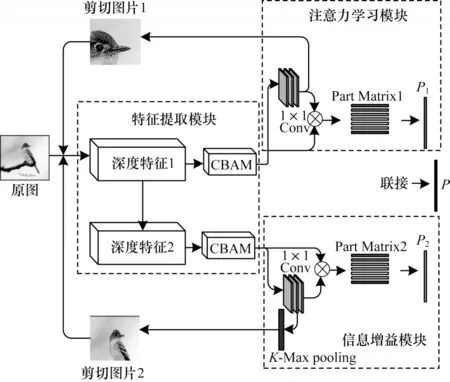
图2 网络模型框架Fig.2 Framework of network model
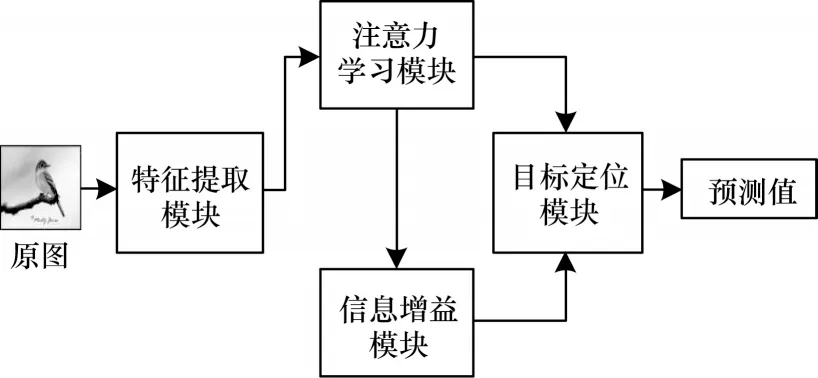
图3 测试流程Fig.3 Testing procedure
2.1 第1 类语义数据增强
图1 中的注意力学习模块和图片剪切模块1 用于第1 类语义数据增强,其中注意力学习模块负责分类特征的学习,图片剪切模块1 从分类特征中得到第1 种语义类型的剪切图片辅助模型训练,该语义类型图片更关注于分类目标的局部细节信息。
1)注意力学习模块
如图1 所示,模型首先从特征提取模块得到深度特征f1∈RC×H×W。对于细粒度图像分类任务,为使特征图有足够的特征表达能力同时增强特定区域的表征,从特征图本身出发,模型加入卷积块注意力模块(CBAM)[18],从通道维度和空间维度引入关注权重,提升特征图对关键局部区域的关注度。(1)从通道维度引入关注权重。
对得到的初始深度特征f1分别进行全局平均池化和全局最大池化,得到2 个C维的池化特征,这2 个池化特征均经过一个共享参数的多层感知器(Multi-Layer Perceptron,MLP),分别得到2个1×1×C维的通道关注权重,最后将其分别对应元素相加,经sigmoid 激活函数激活得到最终的通道关注权重Mc(f1),如式(1)所示:

将该权重与初始特征f1相乘,得到通道关注特征f1c∈RC×H×W,如式(2)所示:

(2)从空间维度引入关注权重。
对上一步得到的通道关注特征f1c∈RC×H×W,沿着通道方向进行取平均(mean)和最大(max),得到2 个维度为1×H×W的特征图,将这2 个特征图进行维度拼接得到维度为2×H×W的特征图,最后本模型选择用一个卷积核大小为7×7 的卷积层对其进行卷积操作,经sigmoid 激活函数激活得到最终的空间关注权重Ms(f1c),如式(3)所示:
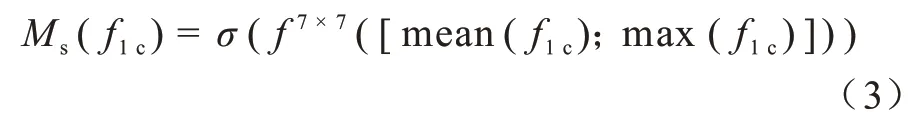
将该权重与特征f2相乘,得到最终的聚焦特征F1∈RC×H×W,如式(4)所示:

通过上述过程,得到经过CBAM 模块的聚焦特征F1,之后模型采用双线性注意力汇合的思想,将聚焦特征F1与其经过k个1×1 卷积核后得到的注意力图A1k以外积即点乘的形式汇合,从注意力图出发,使得到的分类特征的每一维代表分类目标中的一部分关键部位,最终得到注意力学习模块的分类特征P1,如式(5)所示:
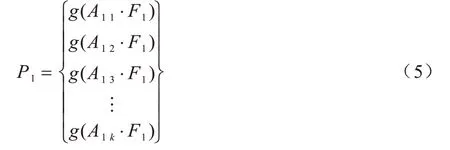
其中:g为特征聚合函数。本文在该模块中采用全局平均池化方式为特征聚合函数聚合特征。
2)图片剪切模块1
从注意力学习模块得到注意力图A1k∈RK×H×W,其中每一通道的注意力图代表分类目标的一关键部位。模型在每个迭代过程中随机挑选一个通道的注意力图,这样随着网络训练,每个通道的注意力图都有可能被挑选到。然后由挑选到的注意力图A1k1∈R1×H×W按是否大于阈值θ可以生成剪切的掩模图,如式(6)所示:


其中:I为原图;S为采样函数。
2.2 第2 类语义数据增强
图1 中的信息增益模块和图片剪切模块2 用于第2 类语义增强,其中信息增益模块负责更深层次分类特征的学习,图片剪切模块2 从深度分类特征得到第2 种语义类型的剪切图片辅助模型训练,该语义类型图片更关注于分类目标的重要轮廓。
1)信息增益模块
对比注意力学习模块,模型从特征提取模块更深层次的卷积层中得到深度特征f2∈RC×H×W,一方面,更深网络层次的卷积特征可以更关注于分类目标整体的重要信息;另一方面,随着训练迭代,模型分类逐渐满足于注意力学习模块的分类特征映射,通过构建一个结构相似但关注点区别于注意力学习模块的新的信息学习模块,可以形成相对的信息差,共同作用于最后的模型分类。因此,区别于以往的CBAM 模块以单个或残差的形式出现,模型并行地引入一个额外的CBAM 模块得到特征F2∈RC×H×W,同理,最后运用双线性注意力汇合的思想,将特征F2与生成的注意力图A2k汇合得到最后的分类特征P2。
2)图片剪切模块2
与图片剪切模块1 同理,模型从信息增益模块生成的注意力图A2k∈RK×H×W中得到剪切图片2,但为了增强其与注意力学习模块的区分度,对注意力图A2k采用K-Max pooling 处理,即保留前K个响应最大的注意力图。由经过K-Max pooling 层的注意力图去生成剪切图片。
2.3 目标定位模块
在测试阶段,为了降低模型对分类图片的误判,模型通过构建一个目标定位模块,定位原图中的分类目标,并将其放大至原图得到目标定位图片。具体步骤:首先可以从注意力学习模块和信息增益模块分别得到经过CBAM 模块的聚焦特征F1和F2。对于特征F1∈RC×H×W,沿着通道方向对特征F1进行深度求和,得到一个二维的深度描述子S(i,j)∈RH×W,由S(i,j)可以得到其均值a-,对于S(i,j)中大于均值aˉ的值设定为1,其他则设定为0。由此,最终可以从注意力学习模块得到掩模图M1(i,j)。同理,可以从信息增益模块中的特征F2中得到掩模图M2(i,j)。将这2 个掩模图分别对应原图,取其重叠的部分,最终将重叠部分放大至原图大小得到目标定位图片,如式(8)所示:

其中:S为采样函数;I为原图。
2.4 损失函数
由以上提出模型,可以分别得到分类特征P1和P2,对其采用交叉熵损失函数指导模型训练,与此同时,模型另外沿通道联接特征P1和P2,得到特征P,同样采用交叉熵损失函数。对于注意力学习模块和信息增益模块,模型采用双线性注意力汇合的思想,引入中心损失函数Center Loss,迫使最终特征P1和P2的每一维能对应分类目标的一关键部位。在测试阶段,模型实验只取联接特征P用于得到预测值。本模型实验损失函数最终如式(9)所示:
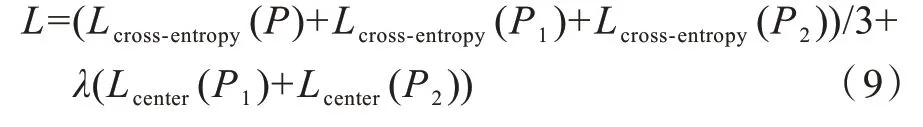
3 实验分析与结果
本节通过实验证明各模块分别及其组合对模型分类准确率的贡献,同时在3 个通用实验数据集上对比其他主流算法,最后通过可视化实验给出注意力学习模块和信息增益模块得到的不同语义层次的剪切图片,及其测试时经过目标定位后得到的剪切图片。本文模型由pytorch 深度学习框架所搭建,训练环境为英伟达P40 GPU。
3.1 实验数据集
本次实验采用细粒度图像识别领域3 个通用实验数据集:CUB-200-2011鸟类数据集[19],FGVC Aircraft飞机数据集[20],Stanford Cars 车类数据集[21]。这3 个数据集的详细信息如表1 所示。

表1 细粒度图像分类数据集Table 1 Fine-grained image classification datasets
3.2 实验细节
实验参数设置:本次实验模型采用通用网络模型Inception V3 作为特征提取器,取Mix6d 层特征映射作为注意力学习模块的特征图,取Mix6e 层特征映射作为信息增益模块的特征图。注意力图由特征图经若干个1×1 卷积核得到,其中注意力学习模块和信息增益模块本实验均设置为64 个1×1 卷积核,即生成64 张注意力图。剪切图片模块θ阈值设为:random(0.4,0.6)。中心损失函数参数λ设为1。
训练参数设置:批量样本数设为16,学习率设为0.01。实验采用随机梯度下降法(SGD)来训练模型,动量设为0.9,权重衰减设为0.000 01。最大迭代次数设为180。在训练阶段,剪切模块剪切图片大小均为256像素×256像素。
测试参数设置:批量样本数设为12,目标定位模块图片大小设为448像素×448像素。
实验数据集预处理:实验训练过程将所有图片调整尺寸为448像素×448像素,统一将图片进行随机翻转、随机调整亮度、标准化。测试过程将调整尺寸为448像素×448像素,统一将图片标准化。
3.3 模块及其组合准确率贡献
表2 给出在数据集CUB-200-2011 上模块及其组合对模型分类准确率的贡献,可以看出,各模块能有效地提高模型分类准确率。本文构建的注意力模块和信息增益模块所提取的分类特征较好地表征了细粒度图像。表3 给出2 种语义数据增强下上模块及其组合对模型分类准确率的贡献,可以看出,结合语义数据训练能大幅提高模型分类准确率,且组合2 种语义数据辅助模型训练达到了模型最高的准确率。数据增强可以提高细粒度图像分类模型的准确率,并且双语义数据增强的设置下可以使模型性能达到最优。
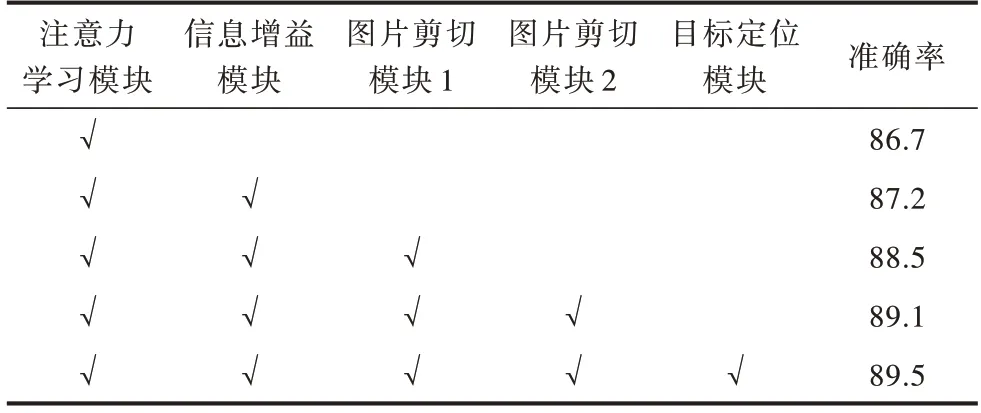
表2 模块及其组合贡献程度Table 2 Contribution of module and their combinations %
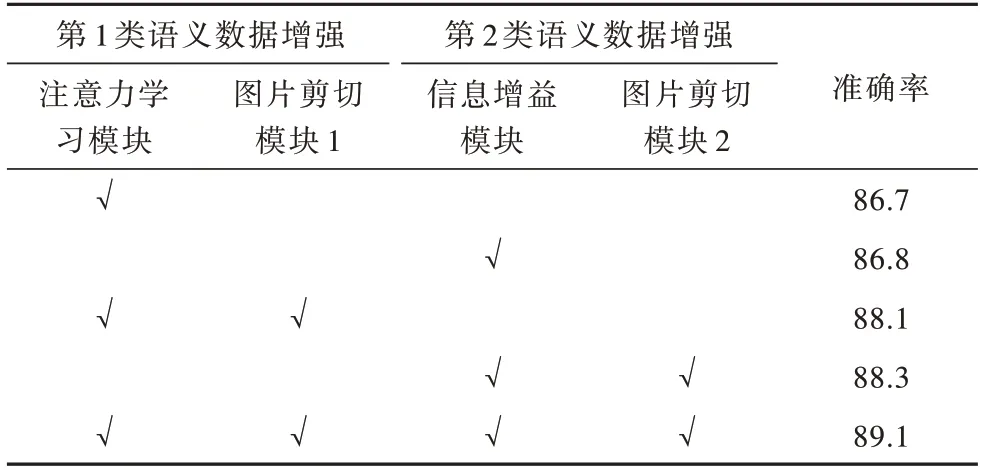
表3 2 种语义数据及其组合贡献程度Table 3 Contribution of two kinds of semantic data and their combinations %
3.4 与其他先进算法的对比
本文设置实验在数据集CUB-200-2011、FGVC Aircraft和Stanford Cars上对比其他同期先进算法,实验结果分别如表4~表6 所示。可以看出,对比本实验的基准网络Inception-V3,本文算法在CUB-200-2011鸟类数据集上准确率提高了5.8%,对比本文采用的双线性注意力池化特征聚合方式,本文算法在CUB-200-2011 鸟类数据集上准确率提高了3.1%。对比其他同期先进细粒度图像分类算法,本文模型在数据集CUB-200-2011、FGVC Aircraft 和Stanford Cars 上均表现出了更优越的性能。此外,本文模型在实验细节参数设置下,模型复杂度为185.71 MB。
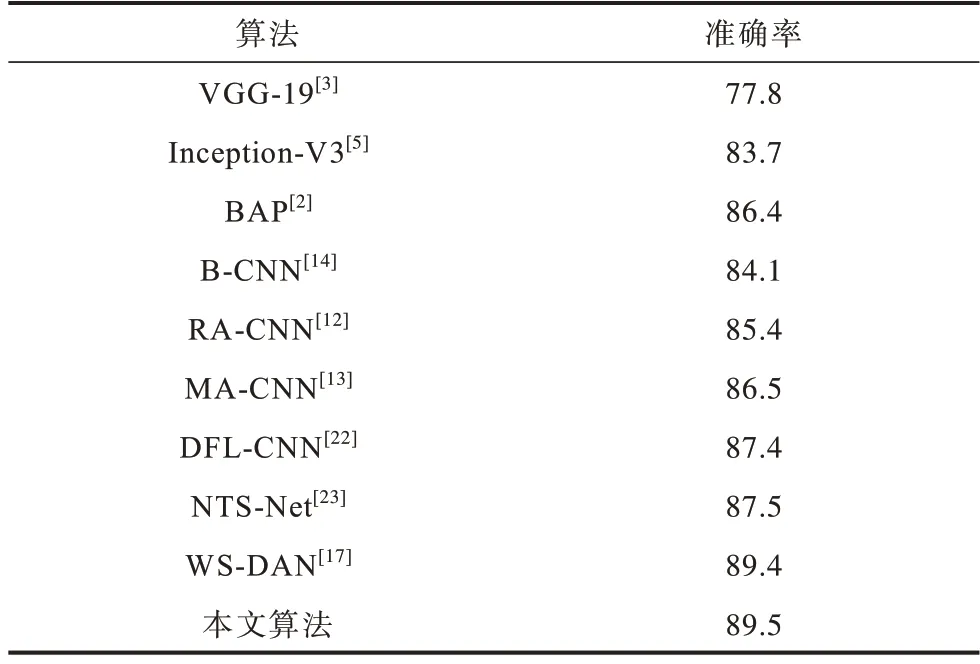
表4 在CUB-200-2011 数据集上的分类性能对比Table 4 Comparison of classification performance on CUB-200-2011 dataset %
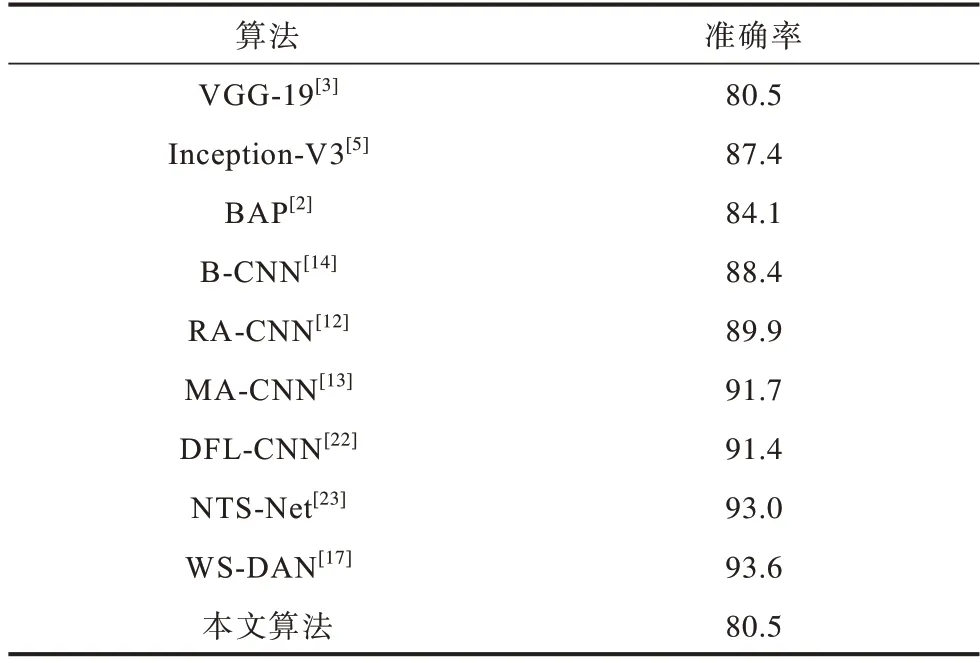
表5 在FGVC Aircraft 数据集上的分类性能对比Table 5 Comparison of classification performance on FGVC Aircraft dataset %
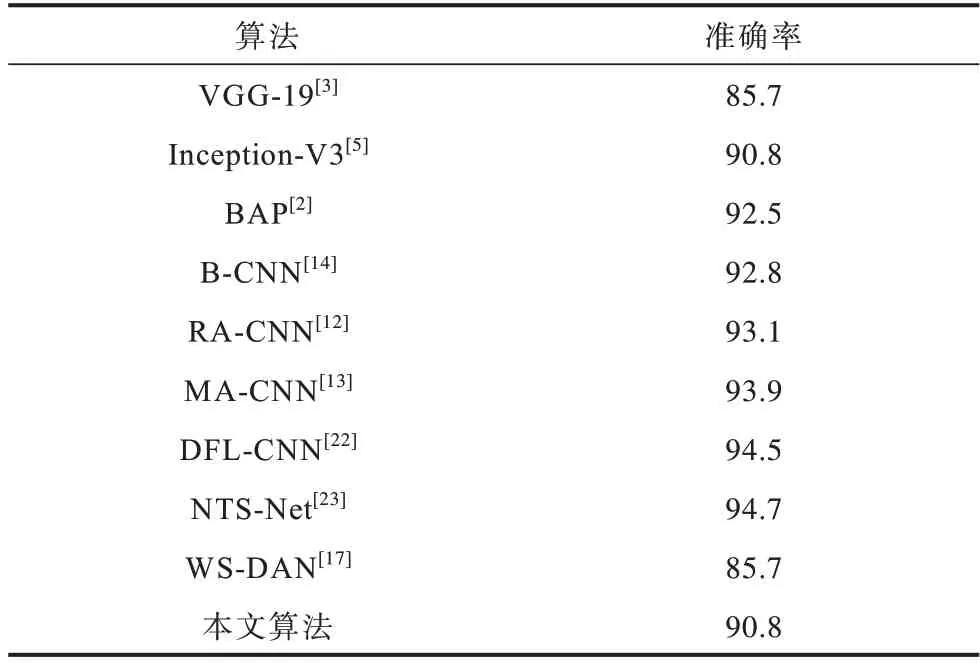
表6 在Stanford Cars 数据集上的分类性能对比Table 6 Comparison of classification performance on Stanford Cars dataset %
3.5 双语义增强数据及目标定位剪切图片可视化
由图片剪切模块1 和图片剪切模块2 得到的剪切图片如图4 所示。可以看出,在双语义数据增强模型的设置下,模型可以由此得到2 种不同语义层次的剪切图片。其中剪切图片1 更关注于分类目标局部细节信息例如鸟的眼睛等,剪切图片2 更关注目标重要的有区分度的轮廓,结合这2 种语义层次的剪切图片可以有效提高模型分类准确率。
本文给出经过目标定位模块的图片,如图5 所示。可以看出,经过目标定位模块模型可以准确地定位于分类目标整体,从而忽视图片背景等无关信息的干扰。
4 结束语
针对细粒度图像分类类内差异大、类间差异小的特点,本文基于双线性注意力融合提出注意力学习模块和信息增益模块,分别关注目标局部细节信息和目标整体重要轮廓,由此得到2 种语义层次的增强数据辅助模型训练,并在测试阶段提出目标定位模块用于定位目标整体,进一步提高分类准确率。实验结果表明,本文算法在CUB-200-2011、FGVC Aircraft 和Stanford Cars 数据集上分别达到89.5%、93.6%和94.7%的分类准确率,性能优于对比算法。本文设计的2 种语义特征学习模块可以得到2 种语义层次的增强数据,但得到的2 种语义层次的剪切图片区分度不够明显,有可能成为冗余数据,无法为模型带来增益。下一步将增加模块间的区分度,减少冗余信息。此外,本文算法包含了特征间的外积运算,对比基准网络Inception-V3 复杂度较高,这局限了模型在移动端的应用范围,后续将考虑降低模型复杂度,构建轻量型细粒度图像分类网络。
猜你喜欢
红外技术(2022年11期)2022-11-25
北京航空航天大学学报(2022年8期)2022-08-31
矿产勘查(2020年11期)2020-12-25
航空发动机(2020年3期)2020-07-24
安阳工学院学报(2020年2期)2020-06-05
开放教育研究(2020年2期)2020-03-31
模具制造(2019年10期)2020-01-06
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
长江学术(2016年4期)2016-03-11
