
一种轻量级多尺度融合的图像篡改检测算法
2022-02-24 05:06赵静文
计算机工程 2022年2期
吴 旭,刘 翔,赵静文
(上海工程技术大学电子电气工程学院,上海 201620)
0 概述
随着数字图像处理技术的快速发展,数字图像恶意篡改事件频繁发生,使得人们对于数字图像的真实性产生严重怀疑,这样的行为会对个人声誉、社会稳定乃至国家安全均造成巨大影响,因此数字图像篡改检测技术受到国内外研究人员的广泛关注。在数字图像被动取证领域,图像篡改主要分为内容篡改和操作篡改[1]。2017 年,BAPPY 等[2]提出基于像素级别的概率映射方法,建立CNN-LSTM 图像被动取证模型,但是掩码的定位不够精确。2018 年,LIU 等[3]利用多尺度方法进行篡改区域定位,设计不同尺度的图像滑动窗口,提取多尺度图像块特征,但该方法只能用于单一图像拼接篡改检测任务。图像篡改检测与传统语义分割任务[4]有较大区分:首先识别目标由广泛的语义内容转换为不规则的篡改区域,甚至是移除的区域;其次由于存在边缘的弱特征变化很难被学习到,对于一些逼真的篡改图泛化性能较差。目前,研究人员提出的一些基于图像分割的被动取证方法较少关注内容篡改引起的高低维特征间的差异性,因此本文旨在研究多尺度特征在篡改内容上的信息表达和篡改区域边缘上的像素差异问题。
1 本文算法
本文主要针对复制-粘贴和拼接这两种经典内容篡改的检测算法进行改进和研究,经典篡改方式如图1 所示,其中,第一行图片为拼接篡改,第二行图片为复制-粘贴篡改。
针对现有算法边缘特征提取不全、检测篡改方式单一、检测精确度较低、泛化能力低下、时间复杂度过高等问题,本文分析并改进MobileNetV3 网络[5],进而设计双流多尺度特征融合架构进行图像篡改区域检测。相比传统单分支分割网络,本文做出如下改进:
1)引入压缩注意力机制[6]替代原本MobileNetV3网络中的SE(Squeeze-and-Excitation)[7]模块增强全局特征。
2)在MobileNetV3 网络输出区块中加入空洞卷积层来增大感受野,并减少网络层数来降低时间复杂度。
3)加入基于LSTM 网络[8]的副分支帮助识别频域边缘特征,将多尺度特征与边缘特征融合,从而更好地识别出类间差异特征(原始类和篡改类)。
最终对掩膜解码器输出的图像进行二值化和传统去噪得到篡改图预测掩膜,并与真值掩膜进行比对。本文算法整体流程如图2 所示。
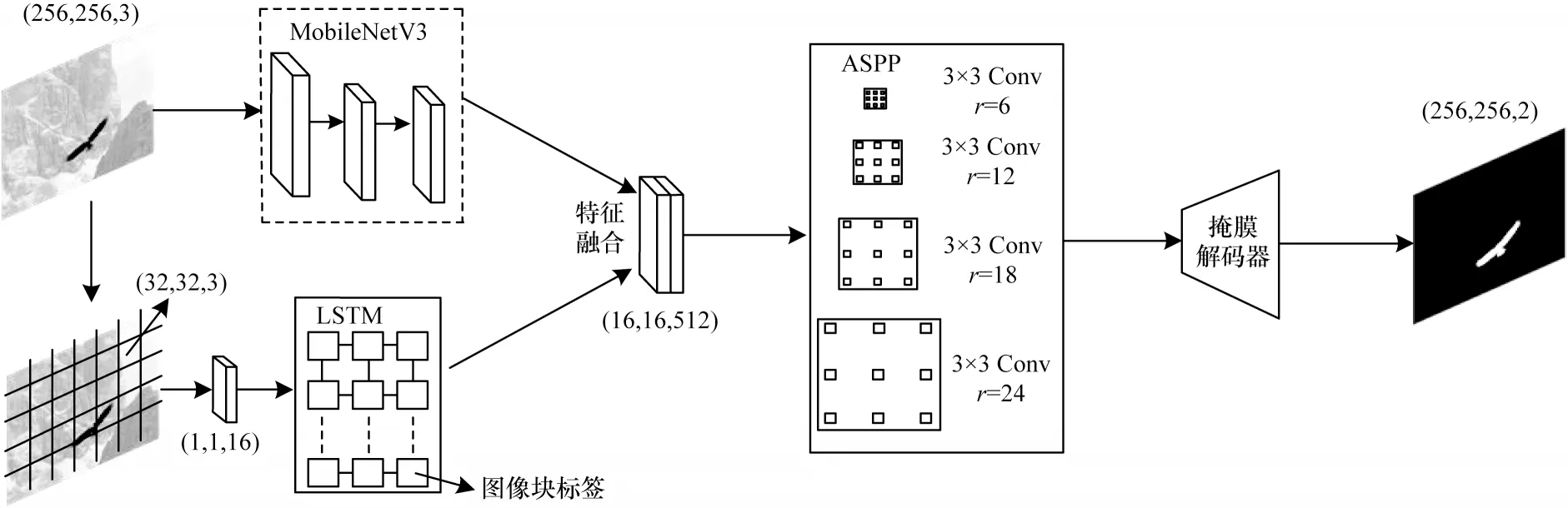
图2 轻量级多尺度融合的图像篡改检测算法流程Fig.2 Procedure of lightweight multiscale fusion algorithm for image tampering detection
1.1 主网络结构
MobileNetV3 网络采用的深度可分离卷积和线性瓶颈逆残差结构可以大大减少参数量和运算成本。本文在此基础上做出改进,将最后区块的平均池化层移除,并引入3 个连续的空洞卷积层来增大感受野。原始的MobileNetV3 和改进的MobileNetV3结构分别如表1 与表2 所示,其中:OC 为输出通道数;NL 为激活函数,HS 表示h-swish 激活函数,RE 表示Relu 激活函数;SE 和SA 为不同的注意力机制;AC 表示空洞卷积;采样率均为2。
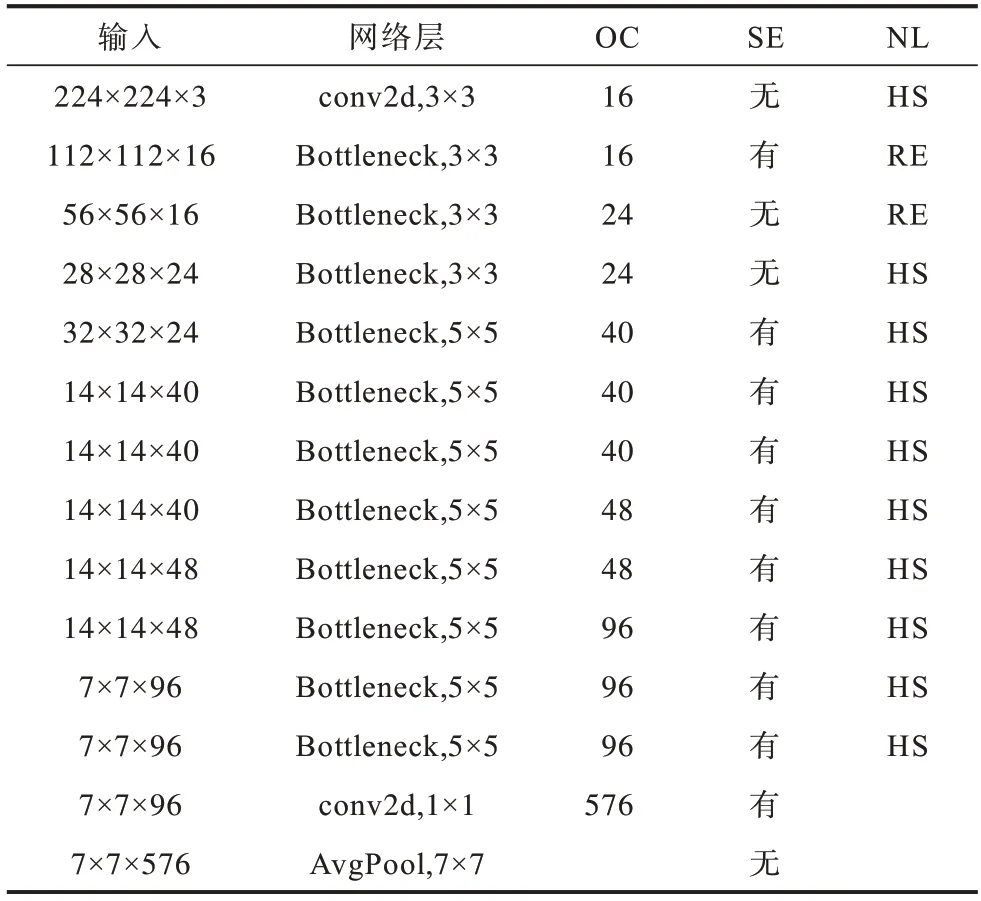
表1 原始的MobileNetV3 结构Table 1 Structure of original MobileNetV3
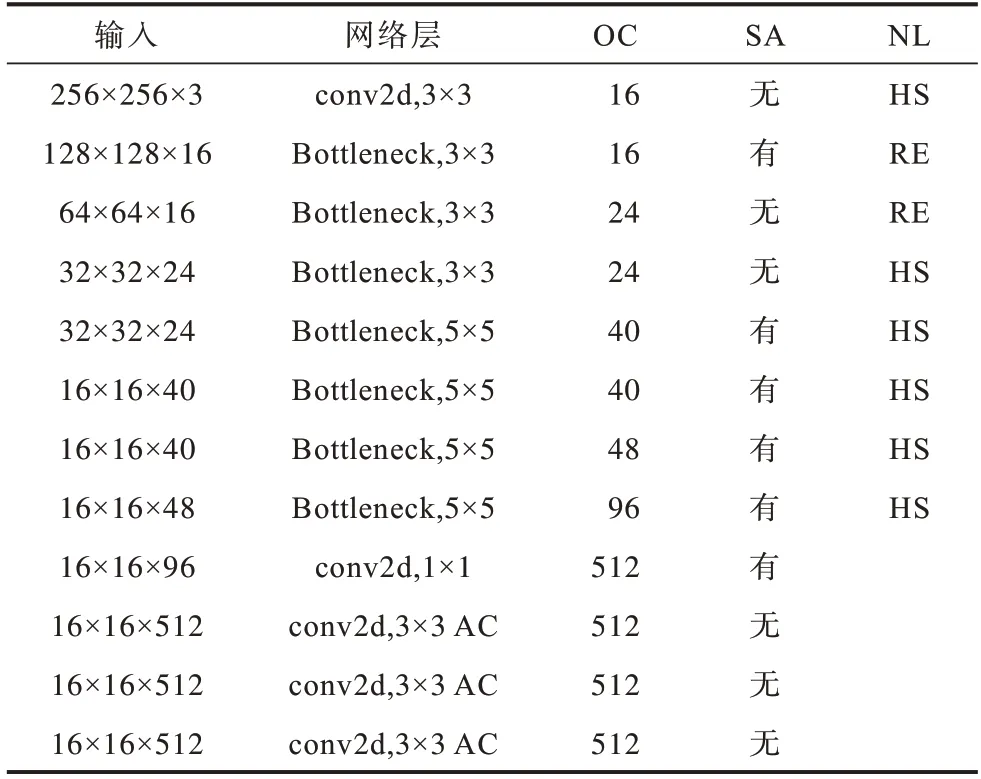
表2 改进的MobileNetV3 结构Table 2 Structure of improved MobileNetV3
传统下采样层在增大感受野的同时使特征图的分辨率降低,从而丢失空间信息,空洞卷积层[9]能在增大感受野的同时,输出高分辨率的特征图。改进的MobileNetV3 网络最终输出的特征图分辨率为1/16,为原始的2 倍,且没有增加额外的参数量和运算成本,这样有利于检测大篡改目标又能精确定位篡改区域。另外,引入h-swish 激活函数并减少层数,可在降低计算量的同时提高检测精度。

其中:Relu6=min(max(0,x),6),x为输入特征向量。
空洞卷积的内核限制了在分割网络中学习到的空间特征的形状,而多尺度特征聚合策略增强了逐像素的预测结果,但图像的全局信息仍未得到充分利用。因此,本文采用压缩注意力(SA)机制[6]进行像素级的密集预测。压缩注意力机制采用的注意力卷积(ACONV)通道并没有像SE 模块一样全部压缩成1×1 卷积,而是使用平均池化替代原来的全连接层来缩小样本特征图,经过上采样后生成具有特定像素类别的注意力掩膜(Xatt),从而完成篡改与非篡改两类像素分组,并保留非局部空间信息。SE 和SA两种注意力机制对比如图3 所示。
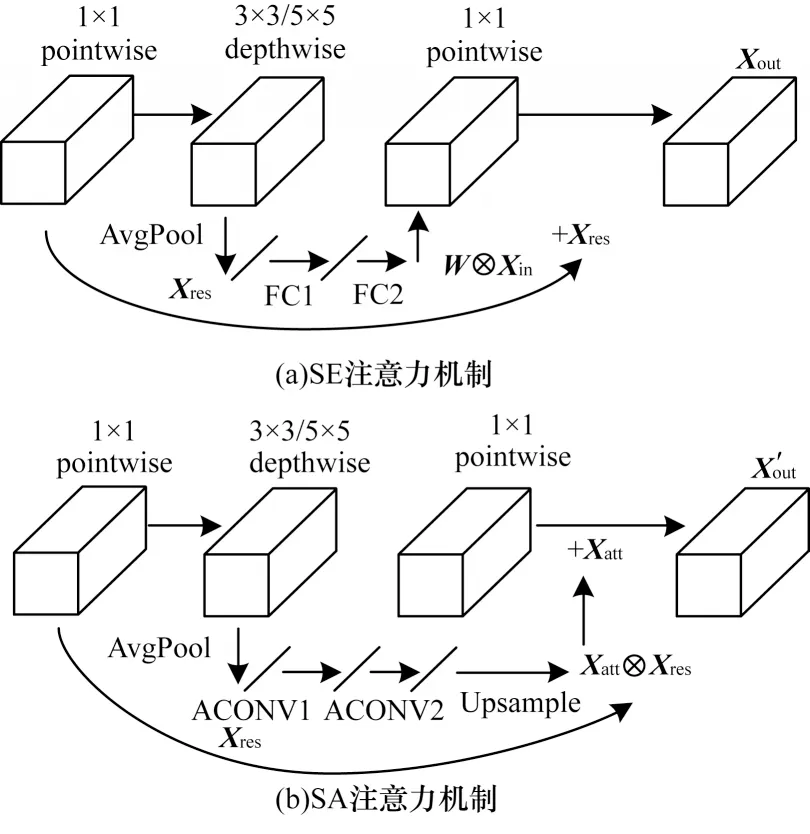
图3 两种注意力机制对比Fig.3 Comparison of two attention mechanisms
SA 模块引入像素组的注意力机制,即在不同空间尺度下属于同一类像素组的注意力,使网络可以学习到原图区域与篡改区域的隐蔽特征。另外,针对类间像素分组去除了空间的限制,将不同尺度下的同类特征分为一组,使得多尺度空间特征和非局部特征经学习后能够被密集预测。设,Xres为残差卷积块,则SE和SA 分别输出如下特征图:

其中:Xatt=Upsample(Ft(AvgPool(Xin))),Ft为包含注意力卷积的特征图函数映射。
1.2 边缘相关性检测
篡改区域的定位任务与图像空间信息密切相关,LSTM 网络[10]能学习图像块之间的相关度,并依赖对数似然距离,学习篡改边界上的空间差异信息。然而,这些信息在经过平滑、模糊等后处理操作后很难被识别。为了使提取特征包含明显的异常边界信息,本文将输入的原图分块后经过一个1×1 卷积层升维,以此增加非线性特性和实现跨通道信息交互,将输出的16 维特征图划分为8×8 的小块,按照一定序列输入LSTM 单元来学习特征图像块之间的相关性,从而在频域中捕捉到篡改区域和真实区域之间边界上的差异特征。
与传统CNN-LSTM 序列模型不同,此并联结构分别提取图像的块级和像素级特征进行融合训练,使得通道间的时空信息交互更密切,特征层次更丰富。本文使用3 个堆叠层,每层有64 个神经元,每个神经元产生256 维的特征向量,将其重塑成16×16 的子块并串联成二维特征图,尺寸为16×16×512,最终由LSTM 输出的特征图包含了异常边界信息与篡改像素块之间的映射关系。
1.3 多尺度特征提取
篡改的不规则区域可能存在不同尺度,为了捕获篡改图像的全局多尺度信息,本文构建多尺度特征提取模块。CHEN 等[11]提出在级联模块和空间金字塔池化(Spatial Pyramid Pooling,SPP)[12]的框架下,使用空洞卷积来增大滤波器的感受野以融合多尺度的语境信息的方法,即空洞空间卷积池化金字塔(Atrous Spatial Pyramid Pooling,ASPP)模块。该模块包含不同采样率的并行空洞卷积层,针对不同尺度图像区域进行不同特征映射,从而密集预测多尺度篡改区域。每个单独的并行层与图像级特征融合后有效去除了冗余信息,经过解码器最终输出预测掩膜图。空洞卷积的采样率(r)是在普通卷积的基础上做的改进,相邻权重之间的间隔为r-1,普通卷积的r默认为1,因此空洞卷积的实际大小如下:

其中:k为原始卷积核大小;ks为等效卷积核尺寸,s为步长。假设输入特征向量为(Hin,Win,Cin,N),输出向量为(Hout,Wout,Cout,N),则:
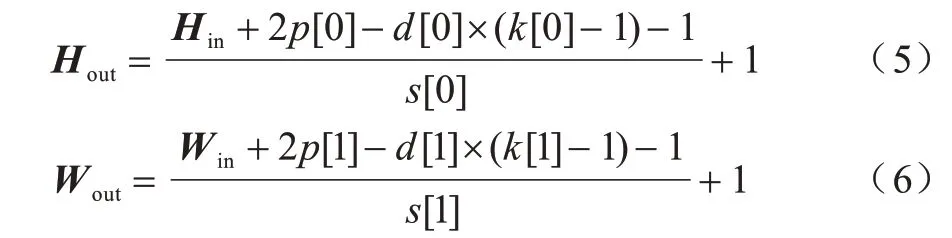
其中:H、W、C分别为特征向量的高度、宽度、通道数;N为batch size;p为padding 参数;d为空洞卷积率。由于复杂的空洞卷积层需要大量的推断时间,为了达到性能与耗时的平衡,本文通过选择不同的采样率r组合进行优化,经过多次实验对比,最终采用4 层并行空洞卷积层,空洞采样率组合为6+12+18+24,如表3 所示,其中通道数为1 024。
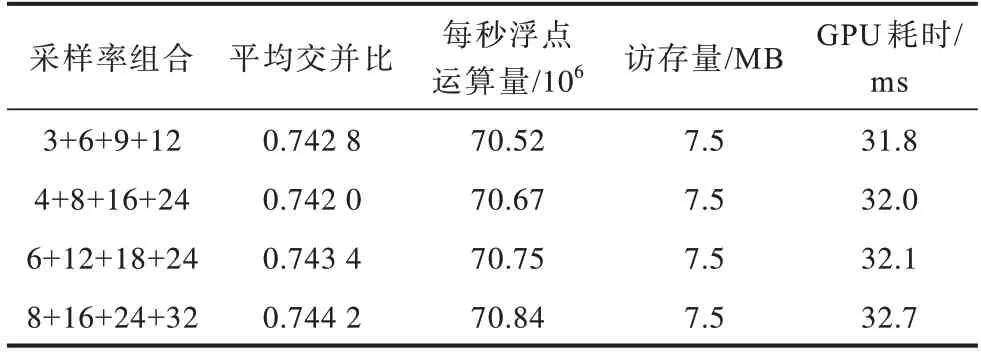
表3 不同采样率组合下的性能与时间复杂度Table 3 Performance and time complexity under different sampling rate combinations
经过空洞卷积层提取的特征与全局平均池化后的特征相融合输入到掩膜解码器中,最终的预测篡改结果是通过合并来自ASPP 模块的4 个层次结构的输出,通过集成多尺度上下文信息从而获得增强的逐像素预测。
2 实验
采用Microsoft COCO 与Dresden[13]复制-粘贴和拼接篡改混合数据集作为训练集,将20 000 张图像按7∶2∶1 随机分成训练集、测试集和验证集,分类后的图像同样按照比例划分并标注图像块的真值掩膜图,成对输入网络进行端到端的双分支网络同步训练。
2.1 实验参数与评价指标
在训练过程中,设定初始学习率为0.001,ASPP池化后输出掩膜尺寸为16×16×1 024,采用Adam 优化器降低网络损失,并加入学习率衰减使后期迭代不再需要手动调整,每次迭代进行一个小批量(minibatch)梯度下降来更新网络参数,从而加快网络收敛且大幅减少运算成本,batch-size 设置为32,迭代轮数在160 次之后网络完全收敛。实验平台在Tensorflow 框架中搭建,实验对比算法调至最优参数。为提高计算效率,使用4 块NVIDIA GeForce GTX 1080Ti GPU 进行训练。为评估本文提出模型的性能,采用精确率(P)、召回率(R)和F1 分数(F)作为评估指标,计算公式如下:

其中:TTP表示检测结果中正确检测为篡改区域的像素个数;FFN表示检测结果中错误检测为非篡改区域的像素个数;FFP表示检测结果中错误检测为篡改区域的像素个数。复杂度分析主要分为空间占用-参数量、内存占用-访存量、运行速度-耗时、推理速度-计算量4 个部分,其中计算量采用乘加操作(Madds)次数[14]作为评估指标,对于普通卷积和深度可分离卷积分别计算如下:
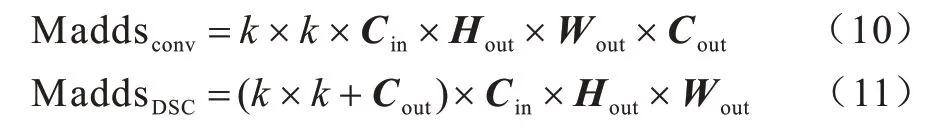
其中:k为卷积核大小;Hout×Wout为输出特征图 分辨率。
2.2 实验对比分析
由于本文设计的网络相对复杂,为了证明每个设计模块对像素级预测分类结果的重要性,设计消融实验对比评估指标,在测试集上的实验结果如表4所示。在表4 中,S 表示单分支,D 表示双分支,S-MobV3-SE 表示带SE 模块的MobileNetV3 原始网络模型,S-MobV3-SA 表示用SA 模块替代SE 后的网络模型,S-MobV3-LSTM 表示用LSTM 与原始网络模型串联,D-MobV3-LSTM 表示用LSTM 与原始网络模型并联,D-MobV3-SA-ASPP-LSTM 表示本文改进的网络模型。可以看出,尽管SA 模块对整体网络性能的提升并不大,但是ASPP 和LSTM 却是十分必要的,即多尺度模块和频域相关性检测模块对篡改区域检测任务的精确率提升影响较大,且双流特征融合模型比单分支序列模型性能更佳。
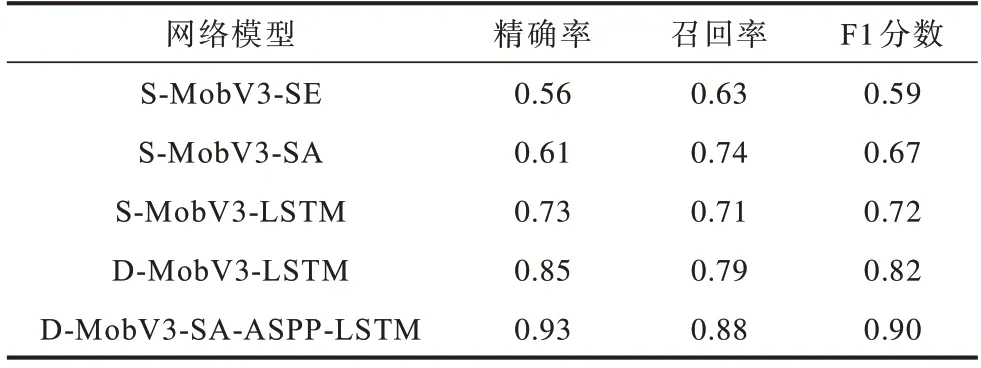
表4 消融实验结果Table 4 Results of ablation experiment
对比分析各类图像篡改检测算法并在不同公开数据集上测试像素级分类的准确度,以证明MobileNetV3-LSTM 混合模型的优异性能,选取的对比算法具体为通过隐写分析中的空域富模型(Spatial Rich Model,SRM)捕捉篡改伪影并与CNN 相结合的特征提取算法Xavier-CNN[15]、传统离散小波变换与CNN 结合的算法DWT-CNN[16]、ManTra-Net[17]、多尺度分析算法ELA[18],对比结果如表5 所示。由表5 可知,传统算法与CNN结合的检测准确度较低,ELA 忽视了边缘信息的获取,而ManTra-Net准确度较高,且仍有上升空间,原因是虽然加入了时间维度但却忽略了多尺度特征的获取。其中,COVERAGE 数据集[19]主要用于检测复制-粘贴,将相似目标通过粘贴覆盖类似对象来隐藏篡改图像,COLUMBIA 数据集[20]侧重未压缩的图像拼接篡改检测,CASIA2 数据集[21]为混合数据集,检测难度较大。
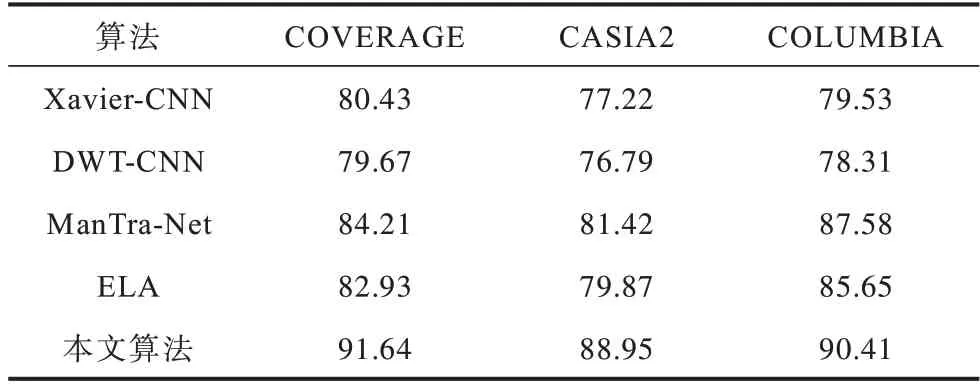
表5 不同数据集下的像素级分类准确度Table 5 Accuracy of pixel-level classification of different datasets %
图4为本文算法的部分可视化篡改检测定位结果,可以看出本文算法对于篡改边缘痕迹明显的区域,篡改检测定位的准确度较高。测试一张256像素×256像素图像的算法复杂度如表6所示。

图4 可视化篡改检测定位结果Fig.4 Visualized results of tampering detection and positioning
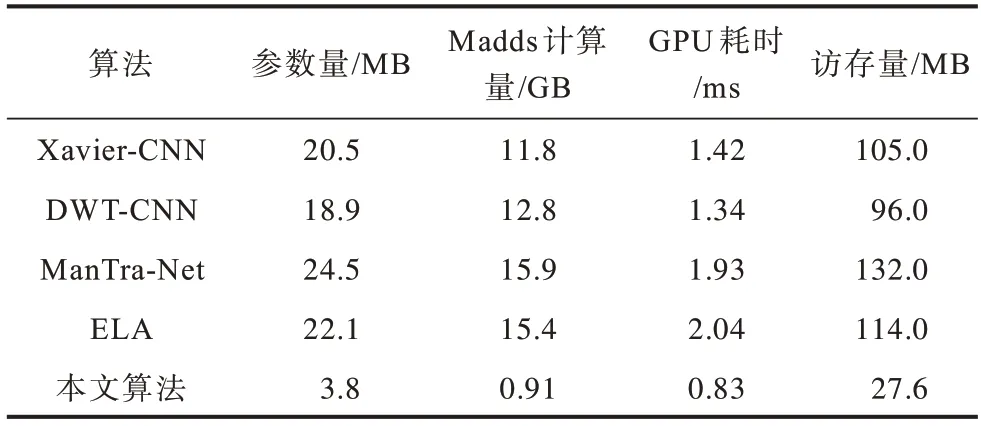
表6 算法复杂度对比Table 6 Comparison of algorithm complexity
从表6 可以看出,本文算法的参数量平均缩减了82.3%,Madds 计算量远小于其他算法,推理速度平均加快了2 倍。为验证本文算法的泛化性,在realistictampering-dataset[18]等真实篡改数据集上进行测试,并给出部分可视化结果,如图5 所示。从图5 可以看出,尽管在真实篡改数据集上本文算法存在漏检和误检的情况,但是边缘轮廓信息以及多尺度信息基本能被检测,并且完成了初步的篡改定位,这表明本文算法具有一定的泛化性能。

图5 真实篡改数据集的可视化结果Fig.5 Visualized results of real tampering dataset
3 结束语
本文设计一种轻量级多尺度融合的图像篡改检测算法,利用深度学习方法端到端学习篡改图像的差异性特征并将其分类为多尺度特征和边缘特征,同时采用双分支特征融合架构进行学习输出预测掩膜,完成图像篡改定位任务。实验结果表明,本文算法的精确率、召回率以及F1 分数均取得较好结果,相比ManTra-Net、Xavier-CNN 等算法检测准确度平均提高9.2 个百分点、参数量缩减82.3%、推理速度加快2 倍,并通过消融实验证明了每个设计模块的必要性和贡献度。由于MobileNetV3-LSTM 混合模型设计较为复杂,后续将在轻量级网络架构的基础上,采用裁剪稀疏化等模型压缩方法,进一步降低图像篡改检测算法的时间复杂度及计算成本。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
今日农业(2021年11期)2021-11-27
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
学生天地(2020年18期)2020-08-25
红领巾·萌芽(2019年8期)2019-08-27
故事作文·高年级(2017年2期)2017-03-01
太空探索(2016年5期)2016-07-12
CHIP新电脑(2016年3期)2016-03-10
时代英语·高三(2014年5期)2014-08-26
漫画月刊·哈版(2009年10期)2009-03-26
