
多成本融合的立体匹配网络
2022-02-24 05:06张锡英王厚博边继龙
计算机工程 2022年2期
张锡英,王厚博,边继龙
(东北林业大学 信息与计算机工程学院,哈尔滨 150040)
0 概述
人们主要利用视觉系统获取信息,即通过双眼将获得的特征信息传入到大脑并进一步感知与理解。随着深度学习的发展,传统机器学习方法难以满足现在的应用对精准度和速度的要求,因此以神经网络为主的深度学习方法成为主要发展方向[1]。计算机开始被用于模拟人们的双眼和大脑以感知世界,计算机视觉成为目前人工智能领域的研究热点。立体匹配是计算机视觉领域中的关键技术,其主要解决在两幅图像中真实场景点与投影点的对应问题,即参考图像中每个待匹配点在其匹配图像中准确地找出对应点,并计算对应点之间的距离,即视差。高效且准确的立体匹配算法对于许多需要快速、可靠响应的应用场景至关重要,例如机器人导航、增强现实、自动驾驶[2-3]等。
双目立体视觉技术更加适用于实际生产生活中三维物体信息的采集,具有广阔的发展空间和应用前景[4]。传统的立体匹配方法分为成本计算、成本聚合、视差计算和视差优化4 个步骤[5]。文献[6-7]提出DispNet,利用端到端的方式训练网络,将立体匹配方法的4 个步骤整合到1 个网络中。文献[8]提出了GC-Net,使用3D 卷积的方法获得更多的特征信息。首先从左右图像对中提取特征图,将左右特征图连接起来以形成一个用深度特征表示的匹配代价卷;然后将3D 卷积神经网络应用于匹配代价卷,并使用回归的方式生成最终的视差图[9]。与2D 卷积神经网络相比,3D 卷积神经网络可以捕获更优的几何结构,并在3D 空间中进行光度匹配,以减少因透视变换和遮挡导致图像失真情况的发生[10]。文献[11]使用编码-解码结构解决网络运算量过大的问题。DispNet 通过一维相关性近似得到匹配代价,而GC-Net 是使用3D 卷积得到匹配代价,能够更充分地提取图像信息。文献[12]基于GC-Net 提出PSMNet,该网络解决了GC-Net 在特征提取上不足的问题,并将残差神经网络(ResNet)[13]作为特征提取部分的主要网络,进而利用SPP[14]模块提取多尺度信息,将不同分辨率的照片统一输出为同一尺寸的特征图,通过结合全局特征和局部特征来构建匹配代价卷。文献[15]在PSMNet 基础上改进了堆叠沙漏结构,提出GWCNet,以增加沙漏结构的输出和特征信息的丰富度。
随着立体匹配研究的不断深入,网络的特征提取方法也越来越多。PSMNet[12]采用空间金字塔池化[14](Spatial Pyrmaind Pooling,SPP)模块提取特征,采用不同尺度和次级区域信息的分层全局池化,但降低了分辨率和感受野。文献[16]在ASPP 模块的基础上结合稠密链接原理,提出了DenseASPP 模块,通过稠密链接方式将不同扩张率得到的特征图连接起来,使得前面层的扩张率低,后面层的扩张率逐层增大,最终得到更大的感受野和更高精准度的视差图。使用空洞卷积方法的立体匹配网络在特征提取部分普遍采用SPP 模块获得不同尺度的特征信息,但是该模块存在感受野不够大的问题,从而无法充分获取图像的特征信息。
近年来,注意力模型在卷积神经网络中得到广泛应用,文献[17]提出一个轻量的通用注意力模块CBAM,使用通道注意力模块和空间注意力模块优化特征,不仅保证了模块的独立性,而且将CBAM 集成到已有的网络架构中。
本文结合注意力模型,提出一个多成本融合的立体匹配网络DCNet,以充分地提取图像特征信息。在特征提取部分中引入密集空洞卷积和空间金字塔池化提取多尺度特征信息,并使用轻量化注意力模块对其进行优化。同时采用3D 卷积神经网络聚合特征信息,通过回归方式生成视差图。
1 DCNet 网络
DCNet 网络主要由多成本融合的特征提取模块和堆叠沙漏模块构成。DCNet 网络结构如图1 所示,将原始RGB 图片输入到特征提取网络,使用多成本融合特征提取模块来提取特征,通过扩大感受野形成更稠密的特征图,从而获得更多的特征信息,通过CBAM 注意力模块优化提取出的特征,采用特征融合方法来构建匹配代价卷。在3D 卷积神经网络中使用3 个沙漏结构的3D 卷积神经网络聚合特征信息,通过赋予权值的方法整合最终的特征点对应关系,最终使用回归的方法得出视差图。
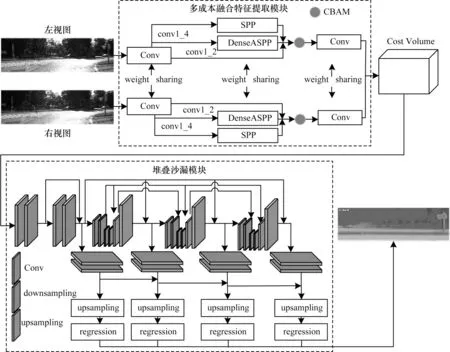
图1 DCNet 网络结构Fig.1 Structure of DCNet network
1.1 密集特征提取网络
1.1.1 ResNet 网络
ResNet[13]是一种深层残差卷积神经网络。随着网络深度的加深,特征信息的丰富程度增大,但是增加网络的层数存在梯度爆炸和梯度消失的问题,最终无法收敛,优化效果反而变差。为解决深层网络的退化问题,ResNet 通过残差网络将浅层网络的输出跳跃连接到深层网络的输入中,残差网络的表示如式(1)所示:

式(1)是在恒等映射Y=X的基础上改进得到的,当F(X)=0 时即为恒等映射。
残差块结构如图2 所示。残差块包括浅层网络ResNet18、ResNet34 和深层网络ResNet101、ResNet152等。
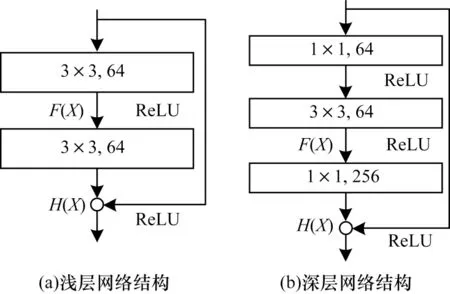
图2 残差块结构Fig.2 Structure of residual block
ResNet 通过学习残差F(X)的方式解决了传统深层卷积网络梯度消失的问题,利用跳跃连接减少了参数量。但是ResNet 仍存在一些不足,即当网络层数过多时会出现过拟合的情况,1 000 层以上的网络相对于浅层网络的优化效果更差。
1.1.2 DenseNet 网络
DenseNet[18]是一种深层的稠密卷积神经网络。受ResNet 中跳跃连接思想的影响,DenseNet 每一层都将前面所有层的输出作为其的输入。DenseNet 网络结构如图3 所示,通过连接模块DenseBlock 实现神经网络的密集连接,每个Block 包含一定数量的神经元。

图3 DenseNet 网络结构Fig.3 Structure of DenseNet network
在DenseBlock 中,每个神经元由BN(Batch Normalization)层、ReLU层和Conv(Convolution)层3个部分组成。由于每个神经元都与之前的神经元相连接,因此最终输出特征图的数量增多。在每两个Block 之间添加一个卷积层和一个池化层,增加卷积层的作用是使用1×1 的卷积来降低特征图数量,从而减少网络开销。池化层能够减少输入到下一个Block 中的特征图数量,达到改善网络参数量的效果。相比ResNet,DenseNet 解决了梯度消失的问题并减少了参数量。
1.1.3 CBAM 模块
CBAM 是一种通用的轻量化注意力模块,其分为通道注意力模块和空间注意力模块2 个部分[17]。CBAM 模块结构如图4 所示。
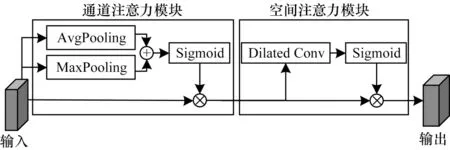
图4 CBAM 模块结构Fig.4 Structure of CBAM module
在通道注意力模块中,将最大池化和平均池化并行链接相比于单一池化的方法可以有效减少信息的丢失。CBAM 结合通道注意力模块和空间注意力模块,在两个子模块中通过与输入的特征相乘可以自适应地对特征进行优化。因此CBAM 注意力模块可以直接集成到CNN 中,与原网络一起进行端到端的训练。
1.1.4 多成本融合的特征提取模块
将SPP 和基于ASPP 改进的DenseASPP 相连,利用CBAM 注意力机制中的通道注意力模块和空间注意力模块对提取到的特征进行优化。多成本融合的特征提取模块结构如图5 所示,其中,C0是普通卷积,C1是使用残差块的卷积。将原始RGB 图像输入到卷积模块中,其由3 个卷积核为3×3 的卷积层组成,第1 层C0_1步长为2,将图像尺寸缩小1/2,第2 层C0_2和第3 层C0_3步长均为1,第3 层得到尺寸为H/2×W/2×32 的输出,这样可以保留更多的信息并输入到残差模块中。残差模块利用基本的残差块来提取一元特征,其由4 个残差块组成:前2 个模块C1_1和C1_2分别为3 个两层的残差块和16 个两层的残差块,将特征图尺寸缩小到H/4×W/4×64;后2 个模块C1_3和C1_4为使用空洞卷积的残差块,分别是扩张率为2 的3 个两层的残差块和扩张率为4 的3 个两层的残差块,在保持尺寸不变的前提下将通道数提高到128,得到H/4×W/4×128 的输出。
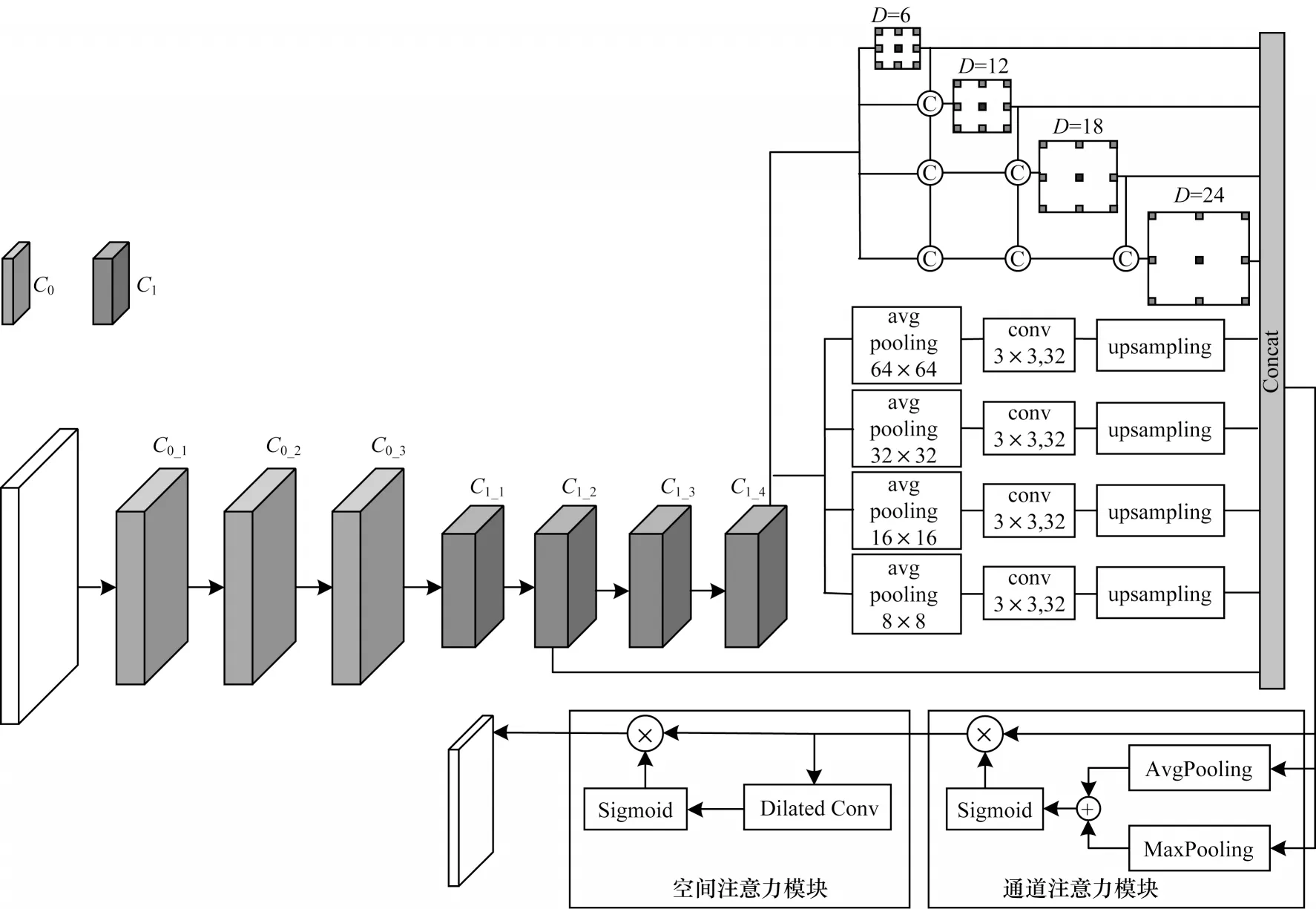
图5 多成本融合的特征提取模块结构Fig.5 Structure of feature extraction module with multi-cost fusion
卷积块的扩张率越大,获得的感受野也就越大,扩张卷积模块的计算如式(2)所示:
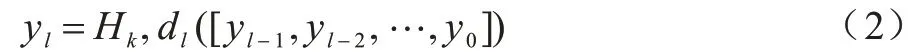
其中:dl为第l层的扩张率;[…]为级联操作;[yl-1,yl-2,…,y0]为连接之前卷积层的输出。
为更充分地提取特征信息,在本文提出的特征提取模块中将改进的DenseASPP 模块和SPP 模块并连,同时对C1_4模块得到的特征图进行特征提取,并与C1_2得到的特征图相连。由于DenseASPP 采用的空洞卷积会对小物体的分割产生影响,因此将C1_2引入到匹配成本中可以减少小物体特征的损失,通过CBAM 注意力模块对得到的特征图进行优化,并将优化过的特征图连接以组成匹配代价卷。
本文采用融合特征图的方法构造匹配代价卷,通过将左右图片生成的特征图相连接以得到一个4 维的匹配代价卷(高度、宽度、视差、特征数量),并将其作为匹配代价聚合网络的输入,从而在匹配代价卷中保留更多的特征维度。
1.2 堆叠沙漏模块
在匹配代价聚合网络部分,本文在高度、宽度以及视差3 个维度上利用3D CNN 方法对匹配代价卷中的特征信息进行规则化。为解决3D CNN 参数量过大的问题,GC-Net 使用编码-解码的结构以减少参数量。
文献[11]提出了堆叠沙漏网络,通过下采样和上采样操作可以更好地混合全局和局部信息,将原始特征加入到上采样过程中,进而减少因上采样导致的特征损失。堆叠沙漏模块结构如图6 所示,c3通过下采样操作得到c4,c6通过上采样操作扩大尺寸后与b3相连接组成c7,b3作为c3的副本,使得c7的特征图保留了中间层的所有信息,且与c3具有相同尺寸。
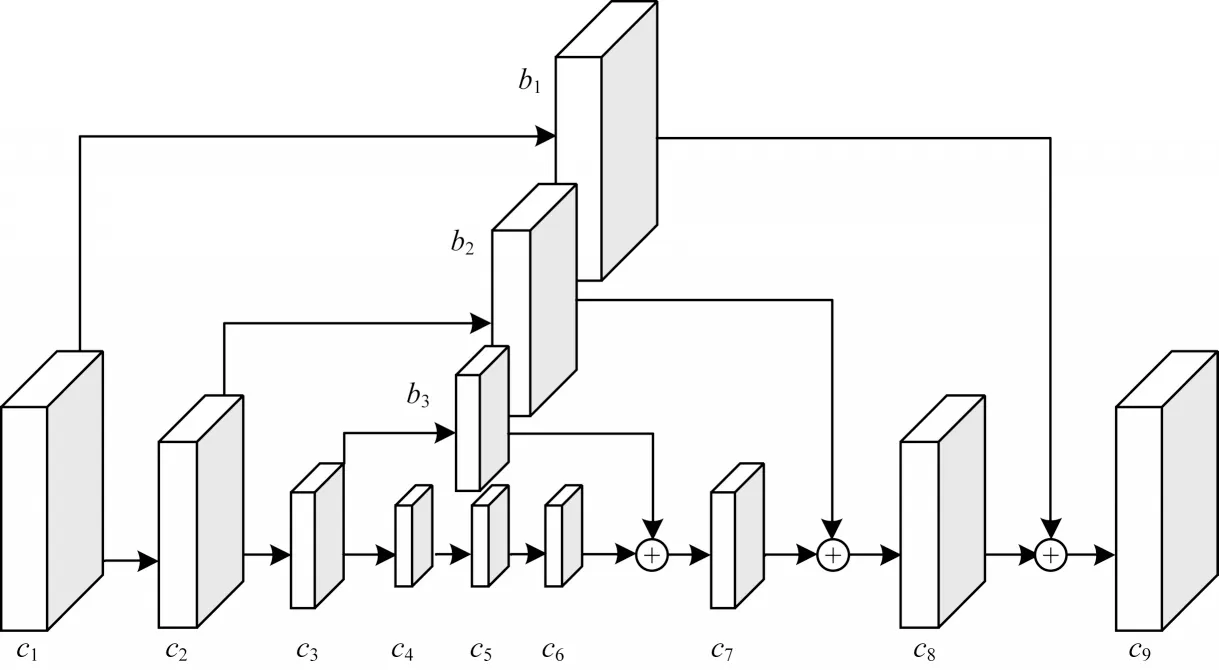
图6 堆叠沙漏模块结构Fig.6 Structure of stacked hourglass module
本文在图1 中用方框标记堆叠沙漏模块。堆叠的沙漏网络由3 个主要的沙漏网络构成,每个沙漏网络生成的损失分别为L1、L2和L3。沙漏网络的输入经过上采样和回归得到的损失为L0,结合密集连接的思想将每个模块和之前模块的输出L0、L1、L2和L3相连接,赋予4 个不同的权值0.1、0.3、0.7、1,得到最终的损失是4 个值的加权和。沙漏网络首先用两个模块进行下采样,每个模块包含一个步长为2 的3D 卷积层和一个步长为1 的3D 卷积层,然后使用两个步长为2 的反卷积将特征卷恢复到原始尺寸D/4×H/4×W/4×32。沙漏网络通过反卷积方法进行上采样,使每个像素学习固定的上采样参数[19]。
1.3 视差回归
本文利用回归方法建立视差图,预测视差d是由成本cd通过Softmax 方法计算得到:

1.4 损失函数
SmoothL1损失函数相比于L2损失函数具有对离群点和异常值不敏感的特点[20],且梯度变化相对较小,能够解决函数不光滑的问题,被广泛应用于目标检测领域。SmoothL1损失函数如式(4)、式(5)所示:

其中:N为标记像素的总数;di为真实的视差值为预测的视差值。
2 实验与结果分析
2.1 数据集
实验在SceneFlow、KITTI2015 和KITTI2012 这3 个公开数据集上进行训练和测试。
SceneFlow数据集包含分辨率为960像素×540像素的35 454 对训练图像和4 370 对测试图像,包括FlyingThings、Monkaa、Driving3 个部分。
KITTI2015 数据集包含分辨率为1 241像素×375 像素的200 对训练图像和200 对测试图像,其中训练图像包含视差信息,将测试图像上传到KITTI网站进行评测。在200 对图像中,其中160 对作为训练集,40 对作为测试集。数据是在街道场景中使用汽车上的双目摄像头拍摄得到的图像,包括车辆、数目、车道、路标等公路场景。
KITTI2012 数据集包含分辨率为1 226像素×370 像素的194 对训练图像和195 对测试图像,其中训练图像包含视差的信息,将测试图像上传到KITTI 网站进行评测。在训练图像中,160 对作为训练集,34 对作为测试集。
2.2 实验环境
实验环境为Linux 系统,使用PyTorch 深度学习框架。硬件配置为:内存128 GB,CPU 为Inter®Xeon®Silver 4116 CPU @ 2.10 GHz,GPU 为NVIDIA Tesla V100(16 GB)x2。
2.3 训练
网络模型使用Adam 优化器,其参数为β1=0.9,β2=0.999。在预训练SceneFlow 数据集上,训练图像被裁剪成512 像素×256 像素,迭代周期设置为10,学习率设置为0.001,最大视差设置为192,批量(batch_size)设置为8。
KITTI2015 数据集在SceneFlow 数据集训练结果的基础上进行优化训练,首先在SceneFlow 数据集上进行预训练,然后在KITTI2015 数据集上进一步优化,当图像裁剪成d像素后,将其输入到网络,迭代周期(epoch)设置为1 000,其中前200 个周期学习率为0.001,剩余周期学习率为0.000 1,批量(batch_size)设置为8。在KITTI2012 在KITTI2015 结果上进行优化训练,参数设置与KITTI2015 相同。KITTI2015 和KITTI2012 的测试集分别在对应的模型上计算得到对应的视差图,并上传到KITTI 网站进行评测。
2.4 实验对比
SceneFlow 数据集的评价采用终点误差(End-Point Error,EPE)的方式衡量匹配的精准程度,误差越大则准确率越低。KITTI2015 数据集的评价采用3 像素误差(3px-Error)的方式表示匹配的精准程度,3 像素误差是指视差的绝对值超过3 像素的像素点占总像素点的比率,其值越高表示匹配效果越差,准确率越低。KITTI2015 数据集测试结果由D1-bg、D1-fg 和D1-ALL 3 个部分组成,其值越低效果越好。KITTI2012数据集采用>2px、>3px、>5px以及Mean Error 这4 个指标评价匹配的精度程度。
2.4.1 特征提取模块对比
不同的特征提取方式不仅影响生成特征图的质量,而且影响最终生成视差图的准确性。实验以本文提出的网络为主干,在特征提取部分选用不同的特征提取模块进行对比,数据集采用KITTI 2015 和SceneFlow,其中KITTI 2015 是在SceneFlow 的结果上进行训练得到的,目的是选取最优的特征提取模块。不同特征提取模块的误差对比如表1 所示。
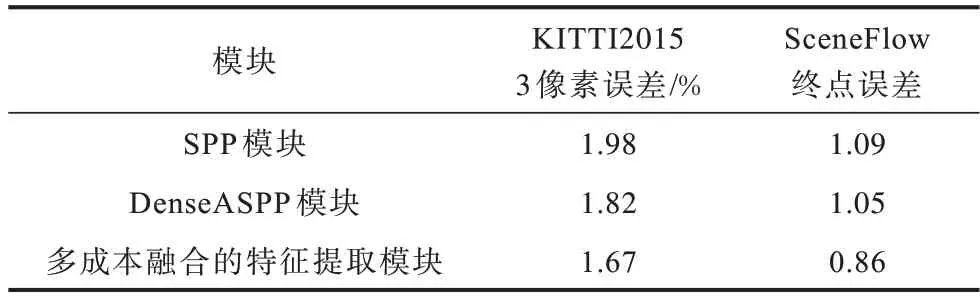
表1 不同特征提取模块的误差对比Table 1 Errors comparison among different feature extraction modules
从表1可以看出,实验采用SPP模块、Dense ASPP模块和本文提出的多成本融合的特征提取模块3 个模块进行对比,可以发现,通过扩大网络的感受野可以得到更充分的特征信息,进而降低误差。将DenseASPP 和SPP 相融合得到的多成本融合的特征提取模块提取图像特征,虽然增加了网络参数的数量,但能够降低网络误差。相比SPP 和Dense ASPP模块,采用多成本融合的特征提取模块的网络误差较低,因此,在本网络的特征提取部分验证了多成本融合的特征提取模块的有效性。
2.4.2 堆叠沙漏模块输出权值对比
堆叠沙漏 模块具有L0、L1、L2和L34 个输出,这4 个输出的权值对深度图产生很大影响。为选择最优的权值,本文实验在SceneFlow 数据集上对这4 个输出的不同权重进行对比,如表2 所示。

表2 堆叠沙漏模块输出权值对比Table 2 Output weights comparison of stacked hourglass modules
由于每个沙漏模块都包含上一个模块的特征信息,因此第3 个沙漏模块中的信息含量达到最大。从表2 可以看出,随着L0、L1和L2权值的增加,终点误差逐渐减小,说明L0、L1和L2中的信息能够有效提高预测深度图的准确度。当L0、L1、L2和L3权值为0.1、0.3、0.7、1.0 时终点误差为0.89;当L0、L1和L2继续增大时,终点误差反而逐渐增大,这说明深层沙漏模块的输出包含更多有效信息,需要较大比重的权值。
2.4.3 消融实验
为选择最优的网络整体结构,本文对网络中的各个模块进行消融实验。本节将多成本融合模块简写为MIM,具有权值的堆叠沙漏模块简写为SH_W,没有权值的堆叠沙漏模块简写为SH。
从特征提取模块实验中可以得出,本文提出的MIM具有较优的特征提取性能,因此,将MIM 作为基础特征提取方法。训练集采用KITTI2015 数据集,不同模块的3 像素误差对比如表3 所示。

表3 不同模块的3 像素误差对比Table 3 3-px error comparison among different modules %
从表3 可以看出,使用MIM、CBAM 和SH_W 模块的3 像素误差较低,其具有最优的网络结构。相比仅使用MIM 和SH_W 的网络,3 像素误差降低了0.14 个百分点。使用SH_W、CBAM 和MIM 模块的误差为2.02,相比仅MIM 和CBAM、SH 网络的误差降低了0.02 个百分点,说明CBAM 和带有权值的堆叠沙漏模块可以有效提高网络的视差预测精度。
2.4.4 其他网络对比
为验证网络的整体性能,本文使用经典网络PSMNet、AANet 和ResNet-101[21]进行对比实验,在KITTI 2015 和SceneFlow 数据集上分析4 个网络评价指标的差异,其中KITTI 2015 是在SceneFlow 的结果上进行优化训练。不同网络的评价指标对比如表4 所示,加粗表示最优数据。

表4 不同网络的评价指标对比Table 4 Evaluation indexs comparison among different networks
从表4 可以看出,本文所提DCNet 网络的准确度最高,其相较于PSMNet 在KITTI2015 数据集3 像素误差减小了0.31 个百分点,SceneFlow 终点误差下降了0.13 个百分点。本文使用多成本融合的特征提取模块,增加了特征图包含的特征信息,能够有效提高网络的精确度,且其在3 像素误差和终点误差中的结果优于仅使用SPP 模块。
在KITTI2015 数据集上不同网络的背景区域内的异常值百分比D1-bg、前景区域内的异常值百分比D1-fg 和D1-all 对比如表5 所示,相比主流网络,DCNet 的D1-bg 和D1-fg 均减少,其中在D1-fg相较于PSMNet 降低了10.17%。
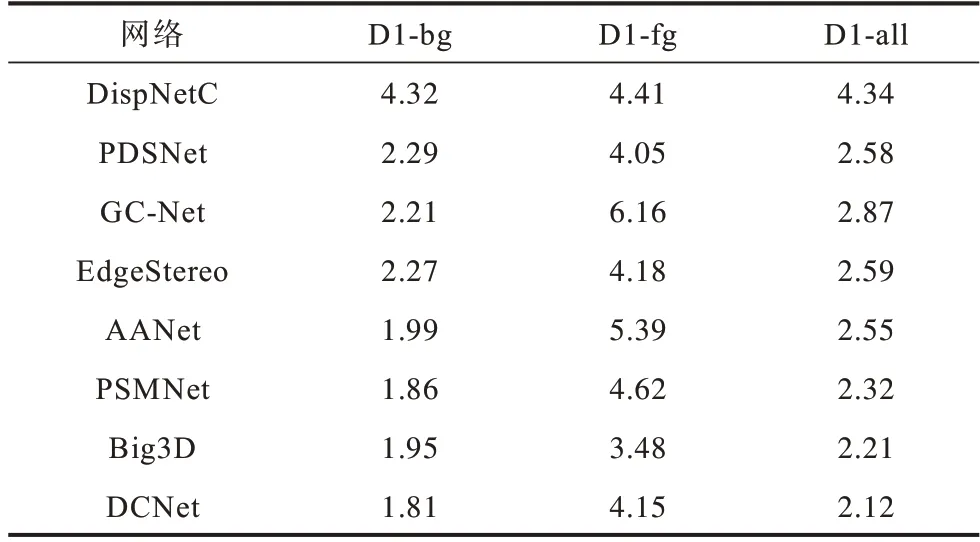
表5 在KITTI2015 数据集上不同网络的实验结果对比Table 5 Experimental results comparison among different networks on the KITTI2015 data set %
在KITTI2012 数据集上不同网络的实验结果对比如表6 所示,Noc 是指非遮挡区域,即匹配的区域对应关系在图片域内,All 是指所有区域。DCNet 网络在>2px、>3px、>5px 以及Mean Error 4 个指标中均优于GCNet、PSMNet、AANet 等先进匹配网络。与在特征提取和3D 卷积均使用注意力机制的MGNet[22]相比,DCNet在>3px、>5px 的误匹配率中的指标较高,这说明在特征提取过程中,本文使用的多成本融合模块能够提取更丰富的特征信息。
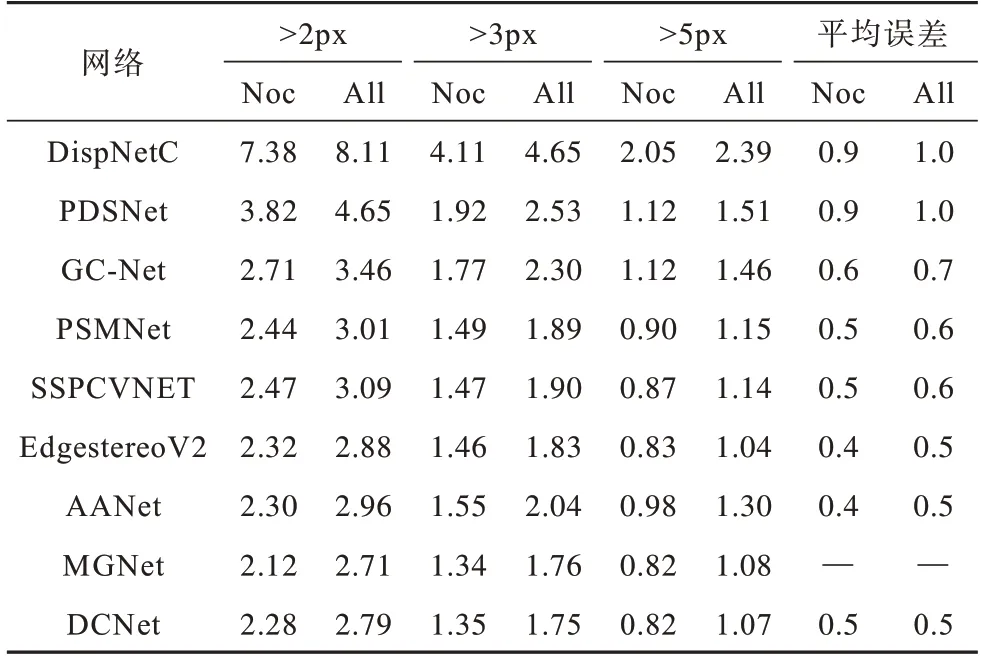
表6 在KITTI 2012 数据集上不同网络的实验结果对比Table 6 Experimental results comparison among different networks on the KITTI2012 data set %
图7为PSMNet、GC-Net和DCNet网络在KITTI2015测试集上的部分视差图、原图和误差图,所有图片均取自于KITTI 测试服务器反馈的结果。图中视差预测效果较差的部分用黑色框标记,其通常出现在栅栏、标识等包含较小结构的图像部分。DCNet使用了多成本融合的提取模块,结合SPP 和DenseASPP 的优点提取图像的特征信息,利用注意力模块进一步优化得到的特征信息。相比使用SPP 模块的PSMNet,DCNet可以得到包含更多特征信息的特征图,进而提升网络预测的视差图精准度。从图7 可以看出,DCNet能够提高在电线杆、阴影部分等区域的匹配精准度,尤其是在小物体的边缘区域。

图7 在KITTI2015 测试集上不同网络的视差图与误差图对比Fig.7 Disparity images and error image comparison among different networks on the KITTI2015 test data
图8 为PSMNet、GC-Net和DCNet在KITTI2012 测试集上的部分视差图、原图和误差图,使用黑色方框标记了视差预测效果较差的部分,所有图片取自于KITTI测试服务器反馈的结果。从图8可以看出,在KITTI2012测试集中,DCNet网络在栏杆、路灯等物体中具有较优的匹配精准度,说明使用注意力模块和多成本融合的特征提取方法能够完整地提取细小物体的特征信息。

图8 在KITTI2012 测试集上不同网络的视差图对比Fig.8 Disparity images and error image comparison among different networks on the KITTI2012 test data
图9 为DCNet在ScnenFlow 测试集上的部分原图、真实视差图以及DCNet预测视差图。从图9可以看出,DCNet预测视差图与真实视差图在复杂纹理部分均有较优的匹配效果,这说明DCNet 网络的性能较优。
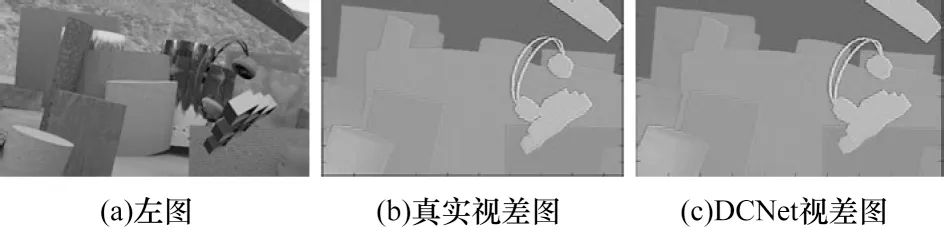
图9 DCNet 的视差图Fig.9 Disparity image of DCNet
3 结束语
本文构建一个多成本融合的立体匹配网络DCNet,利用基于DenseASPP 和SPP 的特征提取网络提取较多的特征信息,通过引入轻量化注意力模块对提取的特征进行优化,并融合左右特征图形成匹配代价卷,通过3D 卷积神经网络聚合特征信息,以回归的方式生成视差图。实验结果表明,与PSMNet、GC-Net、AANet 等网络相比,DCNet网络具有较高的精确度,能够改进对于格栅、电线杆等区域的匹配效果。DCNet 网络在纹理重复密集区域的匹配效果较差,因为使用3D 卷积神经网络导致网络参数较多,且训练时间较长。后续将在保证精确度不变的前提下减少网络参数量,提高网络的匹配效率,构造一个轻量化的立体匹配网络。
猜你喜欢
发明与创新(2022年24期)2022-11-22
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
小型微型计算机系统(2022年1期)2022-01-21
计算机与数字工程(2020年11期)2020-12-23
北京航空航天大学学报(2020年10期)2020-11-14
疯狂英语·新悦读(2020年6期)2020-06-28
北京航空航天大学学报(2019年9期)2019-10-26
数学大王·低年级(2018年3期)2018-03-27
儿童故事画报·自然探秘(2017年2期)2017-09-26
