
面向高校的智能问答系统设计
2022-02-22 01:07戚梦瑶
电脑知识与技术 2022年36期
戚梦瑶



关键词:问答系统;校园问答;数字化校园;文本分类;文本相似度
中图分类号:TP391.1 文献标识码:A
文章编号:1009-3044(2022)36-0033-03
1 概述
智能问答系统是一种能够理解用户提出的用自然语言表述的问题,并能够自动、准确地给出用户答案的软件系统[1]。现今互联网上的资源信息飞速增长,如何精确、快速地从海量信息中挖掘用户想要的信息成为亟待解决的问题。智能问答系统是进行该项工作的重要手段,很大程度上可以替代或辅助传统人工咨询的方式。
根据应用领域的不同,智能问答系统一般可分为面向开放域的问答系统和面向限定域的问答系统[2]。面向开放域的问答系统包含丰富的知识库,为回答多个领域的问题提供了一定的基础,但在回答专业领域的问题时难以精准定位答案、表现较差[3]。目前针对法律[4]、医疗[5]、金融[6]等限定领域的智能问答系统研究较为成熟,而针对高校领域的问答系统研究仍处于起步阶段。为了能够整合多方面资源,为高校学生提供快速、高效、准确的校园智能问答服务,同时建立起统一的信息获取平台,完善数字化校园建设,并进一步实现学生在校情况动态监测,本文旨在运用人工智能、自然语言处理等相关技术,研究和设计面向高校的智能问答系统。
2 高校应用智能问答系统的意义
高校是一个复杂的社会化服务系统,应向学生提供各类服务,如教育服务、生活服务等。学生在接受服务的过程中可能会遇到问题,需要进行咨询得到解答,例如食堂供应时间、图书馆开放时间、请假审批流程等;在招生季,学生会咨询大量有关报考方面的问题,例如招生计划、专业选择、学校制度等。学生在遇到问题时会咨询班主任、辅导员或者学校行政人员,但事实上,学生提出的大多数问题具有相似性,同时教师和行政人员难以对每个学生提出的问题都做出非常及时和详细的解答,而智能问答系统的研究和开发可以在以上校园问答场景中发挥重要作用,具体有以下三点意义:
1)建立统一信息获取平台、提高校园咨询效率。通过分析高校这一限定领域的特点,以校园为导向帮助院校建立起统一、可靠的信息获取平台,自动解答学生用自然语言提出的问题,为学校提供良好的信息化服务途径。相比传统的人工问答方式,使用智能问答系统可以为高校降低人力成本,解决大量重复、可自动化的工作内容,并能够24小时为学生提供高效、标准化的校园咨询服务。
2)完善数字化校园建设。数字化校园建设已成为教育信息化的重要部分,也是衡量教育现代化发展的主要标志。基于人工智能技术开发的智能问答系统辅助传统的人工咨询流程,可以提升高校管理效能和服务水平,实现校园服务工作信息化、自动化、便捷化,持续推动数字校园的建设和发展[7]。
3)实现学生在校情况动态监测。学生在平台咨询的问题能够体现学生在校期间的各方面情况,在智能问答系统的运行推广过程中,可以不断收集和整合学生咨询的问题,并基于问题数据做进一步的统计与分析,统计分析的结果可供高校有关部门进行参考,使得对学生在校生活、学习情况有大致的了解,真正落实“以学生为中心”的理念。
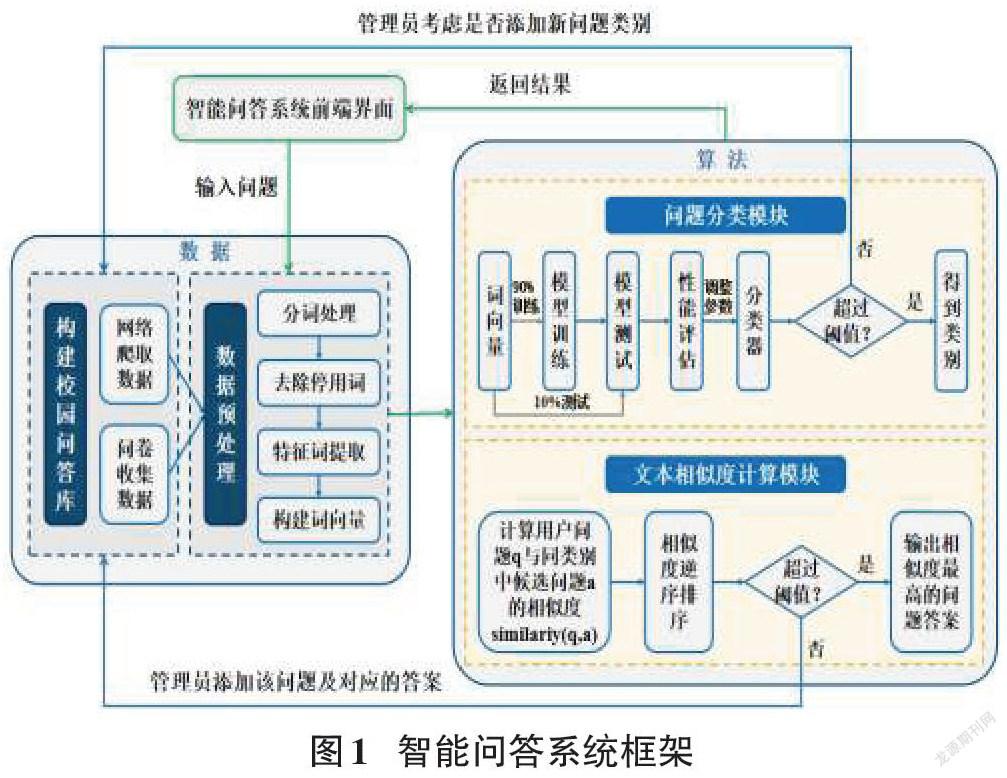
3 智能问答系统框架
本文设计的面向高校的智能问答系统框架如图1所示,分为数据、算法、应用三个部分。用户通过前端界面输入用自然语言表述的问题,首先系统会对问题进行分词、去除停用词等预处理操作,并使用词向量模型表示文本,接着通过问题分类模块以及文本相似度计算模块,向用户返回结果。在上述过程中,若无法成功在系统中匹配到用户的问题,则管理员需要及时在校园问答库中进行补充,从而使得问答库能够不断更新和完善。
数据:包括构建校园问答库以及数据预处理。构建校园问答库是智能问答库的基础,通过网络爬取数据以及问卷收集数据两种方式构建问答对。为了后续算法的实现,还需进行数据预处理步骤,构建词向量表示文本。
算法:包括问题分类模块以及文本相似度計算模块。问题分类模块使用训练得到的分类器对已经预处理的用户问题进行分类,得到问题所属的类别。文本相似度计算模块将用户问题和问答库中的问题进行文本相似度计算,获取用户需要的答案。
应用:向用户提供方便操作的可视化前端界面,用户可通过前端界面发送问题并接收结果。为方便用户的使用,接入微信公众号,可采取基于MVC(Mod⁃el View Controller模型-视图-控制器)设计模式,采用Vue.js框架实现微信客户端的开发。
4 构建校园问答库(FAQ)
构建校园问答库是实现自动问答系统的基础,其优劣对于智能问答系统的适用性以及可靠性起着至关重要的作用。校园问答库中的问题要能够基本覆盖高校学生会遇到的常见问题,答案需要根据不同高校的实际情况对问题进行有针对性地解答。本文收集问题数据的方式有两种,一种是使用爬虫技术,爬取各高等院校贴吧中的问题数据;另外一种是通过问卷调查的方式,收集学生在平常学习、生活过程中容易碰到的问题。
在收集完问题之后,需要给问题标注准确的答案,形成问答对。同时为实现后续自动问答模块的问题分类功能,还需手工给问题标注分类标签,本文针对校园场景将问题分为3种类别,最终得到的校园问答库示例数据如表1所示。
5 自动问答模块设计
5.1 自动问答模块处理流程
自动问答模块是本系统的核心,其处理流程如图2所示。首先对用户提出的问题进行分类,若问题属于某个类别的可能性最大且超过阈值,则将问题标记为该类别,否则提示用户该问题类型不在问答库中,同时系统记录该问题并通知管理员是否考虑添加新问题类别。在得到问题所属类别后,将其与校园问答库(FAQ)中同类别下的问题进行相似度计算,找到问答库中与用户提出的问题相似度最高的问题,并判断相似度是否超过阈值,若超过阈值则将对应的答案返回给用户,否则提示用户该问题不在问答库中,同时系统记录该问题并通知管理员在问答库中添加该问题以及对应的答案。
5.2 自动问答模块实现流程
自动问答模块通过获取词向量、问题分类、问句相似度计算三个步骤,基于Word2vec词向量模型和TextCNN模型实现自动问答模块关键算法。
5.2.1 文本向量表示
首先,需要将用自然语言表述的问题转换为计算机可以识别的格式,使用Word2vec模型进行文本向量表示。在构建词向量前,需要对校园问答库(FAQ)中问题进行数据预处理,主要包括对问句的分词处理、去除停用词、特征词提取等操作。
1)分词处理:词是汉语中最基本的语义单位,分词主要是将原先没有分割符的中文语句(例如“我想咨询食堂开放时间”)按照规定的划分原则拆分其中的字或词(“我/想/咨询/食堂/开放/时间”)的过程。
2)去除停用词:为提升文本特征的质量,降低文本特征的维度,进行去除停用词操作。“停用词”为经常出现在文本中但对信息检索没有帮助的、应该提前消除的词语,例如中文语句中的语气词、助词、虚词等,目前常见的去除停用词的方法是通过构建停用词表,主流的通用中文停用词表有百度停用词表、哈工大停用词表等。
3)特征词提取:特征词是指能表示文本意向的关键词,能否正确地找出问题中的特征词,影响着后续文本分类及相似度计算的准确性和效率[8]。
接着基于Word2vec模型对知识库中的问题数据构建词向量集。Word2vec有两种词向量训练模式,包括CBOW和Skip-gram[9]。对于用户输入的问题,也需要利用Word2vec模型获取其词向量,从而方便进行下一步的问题分类和相似度计算。
5.2.2 问题分类
对用户输入的问题进行分类,从而缩小问题集比对范围,提高问答的准确性。文本分类过程包括两个步骤:模型训练和测试。在得到词向量后,基于Ten⁃sorflow机器学习框架构建Text-CNN[10]模型,该模型首先通过卷积层、池化层提取特征,其流程框架如图3所示,然后对提取到的特征进行分析就可以实现文本分类。
利用训练数据集训练分类模型,在模型训练过程中,性能评价指标可以使用损失(loss)和准确率(Ac⁃curacy)。然后,对训练好的分类模型进行测试,在模型测试过程中,性能评价指标可以使用损失(loss)、准确率(Accuracy)、查准率(precision)、召回率(recall)、F1 Score以及混淆矩阵。如果训练结果不理想,调整参数进行训练,再次对模型进行测试,直到找到最优的文本分类模型。
5.2.3 计算相似度
最后,计算用户提出的问题与校园问答库(FAQ)中的问题集的相似度,根据相似度逆序排序得到答案,并将答案返回用户可视化前端界面。采用Word2vec结合余弦相似度公式计算问句词向量间的距离。对于每个文本组合(q,a),其中q 为用户提出的问题,a 为问题库中的候选问题,词向量余弦相似度计算公式如式(1)所示。
6 结束语
本文设计了一个适用于高校的智能问答系统,并基于Word2vec词向量模型、TextCNN模型设计自动问答算法,能基本实现校园场景下的自动问答应用,为学生提供更高效的问答服務,为高校有关部门提升工作效率提供参考。但系统仍有不完善之处需要在未来进行进一步优化,主要有以下两个方面。
1)添加用户评价及反馈功能。在用户通过智能问答系统提问并得到答案之后,邀请用户对答案的满意度进行评分,从而能够在问答库构建以及算法模型训练过程不断改进,形成良性循环,使得系统能够更符合用户的使用需求。
2)与可视化大屏系统相结合。在问答系统的运行过程中可以积累大量的问答数据,结合大数据技术分析问答数据,开发可视化大屏,使用图表的形式进行统计展示,与问答系统相结合,开放接口,构建全方面、闭环、可拓展的智能校园问答体系,推动校园数字化建设。
猜你喜欢
计算机应用(2016年12期)2017-01-13
中国教育技术装备(2016年20期)2016-12-12
中国教育信息化·基础教育(2016年9期)2016-10-18
