
大规模工程电磁场的亿自由度可扩展并行计算方法
2022-02-21 07:48李育增杨庆新
电工技术学报 2022年3期
金 亮 李育增 杨庆新 张 闯 闫 帅
大规模工程电磁场的亿自由度可扩展并行计算方法
金 亮1,2李育增1,2杨庆新1,2张 闯1,2闫 帅3
(1. 省部共建电工装备可靠性与智能化国家重点实验室(河北工业大学) 天津 300130 2. 河北省电磁场与电器可靠性重点实验室(河北工业大学) 天津 300130 3. 中国科学院电工研究所 北京 100081)
精确和快速的电磁场计算,是电工装备精细模拟和优化设计的基础。该文在高性能云平台的高速互联弹性集群上开展可扩展并行计算研究,使用OpenMpi作为消息传递库,选取的区域分解算法为对偶原始有限元撕裂内联(FETI-DP)法,通过改进主从/对等的并行程序框架实现电导率不变时涡流场磁矢势的并行计算,在降低编程复杂度的同时提高了并行计算效率。使用C语言编写程序,用国际TEAMProblem7基准问题验证可扩展并行计算方法。该文将主从/对等并行程序框架和对偶原始有限元撕裂内联(FETI-DP)法引入电磁计算领域,提高了并行计算效率和可扩展性,为大规模工程电磁场计算提供了一种新的实践和理论方法。
并行计算 电磁场数值计算 有限元法 对偶原始有限元撕裂内联法
0 引言
现代电工装备是支撑智能电网和国家重点重大项目的关键装备。在向高技术参数的发展过程中,现代电工装备的设计需考虑性能优化、制造工艺约束、服役特性和极限工作条件,因而计算电磁学对于精细模拟的作用日益凸显[1-2]。
对于计算电磁学而言,有限元法(Finite Element Method, FEM)是一种强大的电磁场数值计算方法,它具有模拟复杂介质和精细几何的能力。由于普通计算机的计算能力无法满足电工装备精细模拟的计算需求,导致以下几个问题:一是常使用简化数值模型降低计算量,其计算结果的可信度降低。如大型电力变压器垂直漏磁场导致的涡流和磁滞损耗计算问题,一般采用将多层硅钢片进行整体等效的方法,导致局部热点计算难以反映实际情况[3]。二是对于含缝隙或小气隙的多尺度(空间)问题,网格精度满足不了实际要求。如存在mm级缝隙的m级装备——特大型电机、近零磁场环境装置等,由于尺寸差距过大导致设计指标与实际性能具有巨大差别[4]。三是受计算速度限制,一些精细模拟难以完成,产品级精细模型的计算面临计算时间过长的问题[5]。如特高压变压器的仿真计算需要多组工况的计算,而一次计算需要几天甚至几十天的时间。
面对大型而复杂的计算问题,并行计算是提高计算效率的有效方法之一。在电工领域中,并行计算方法已经被广泛应用以提高计算效率。如文献[6]提出了利用图数据库对电力系统进行建模、并在图内存数据库上进行图并行计算的方法,相比于传统串行计算的能量管理系统,在线潮流和静态安全分析的速度上有显著的提高。文献[7]提出了一种基于CPU-GPU异构的静态电压稳定域边界并行计算方法,避免了直接法计算量大、计算复杂度高的缺陷,提高了静态电压稳定域的搜索效率。文献[8]提出了一种基于多核并行计算的有限集模型预测算法(Finite Control Set Model Predictive Control, FCS-MPC),有效降低了传统FCS-MPC算法的执行时间。针对计算精度高的大规模工程有限元法在电磁场计算方面耗时长的问题,并行计算是有效的解决方法之一[9]。为了有效解决大规模计算问题,在高频大尺寸领域一般采用将整个计算域划分为更小子域的有限元区域分解法[10-12]。如,采用鲁棒的区域分解方法——对偶原始有限元撕裂内联法(Dual-PrimalFinite Element Tearing and Interconnecting, FETI-DP)解决多尺度有限元建模问题[13];使用区域分解法,在子域之间采用不连续的Galerkin方法提高不连续结构的电磁计算收敛性[14]。针对工频或低频电工装备,计算效率较高的单元接单元(Element by Element, EBE)并行有限元法在涡流场计算领域得到了初步应用和原理性验证[15]。大型电工装备的硅钢片,由于每片厚度仅为0.1~0.5mm,三维有限元建模和涡流计算困难,采用基于信息传递接口(Massage Passing Interface, MPI)和非结构化四面体网格的并行有限元程序可高效完成百万自由度的计算[16]。为了推广并行计算的使用范围和收敛性,LU重组方法可使近似奇异的有限元矩阵得到正则化,适用于大型涡流、开关磁阻电机和随钻测井问题[17]。目前,有限元并行计算方法在国内外工程领域的现实需求使其得到了快速的发展[18-20]。并行计算的应用从结构动力分析、地球物理发展到高频电磁场、工频和低频电磁场,甚至是电力系统以及静态电磁场等方面[21-28]。在电气领域,由于大型电机、变压器等电工设备或应用电磁原理大型装备的容量和规模越来越大,对于精细模拟的要求越来越高、计算规模的需求也日趋庞大。为满足电磁精细模拟对于计算规模、易用性的需求,高性能公有云、私有云和混合云成为高性能计算的一种有效解决方法[29-31]。
在岩土工程数值模拟领域,并行计算技术已经发展到百万、千万乃至亿自由度的计算规模[32-34]。目前,三维工程电磁场的有限元计算及其并行方法的计算规模多为数百万自由度的线性和非线性问题。计算规模、计算时间方面尚不能满足特大型电机、变压器等电工设备或应用电磁原理大型装备的工程和科学计算需求。
因而本文在百万自由度的电磁并行计算方法研究基础上[35-36],提出一种基于OpenMpi的亿自由度高效可扩展并行计算方法。首先搭建云计算弹性集群,改进主从/对等模型,并建立并行程序框架,推导电导率不变时的涡流场磁矢势法,推导并论述FETI-DP区域分解算法的收敛性和鲁棒性,最后使用国际TEAM Problem 7案例验证了亿自由度可扩展并行计算方法。
1 计算集群
云计算主要使用虚拟化、分布式存储技术将计算机集群的计算资源、存储资源、网络及相关服务组成资源池。对于用户,云计算即为三个层次服务:Infras-tructure as a Service(IaaS),Platform as a Service(PaaS)和Software as a Service(SaaS)。基于云计算的有限元仿真系统如图1所示。图中,SSL为安全套接字协议(Secure Sockets Layer),JSCH为安全外壳协议(Secure Shell, SSH)的纯Java实现,KVM为基于内核的虚拟机(Kernel-based Virtual Machine, KVM)。从IaaS 到SaaS(从硬件到软件或服务),用户可按照自己的计算需求从资源池中获得动态易扩展、可管理的资源及服务。
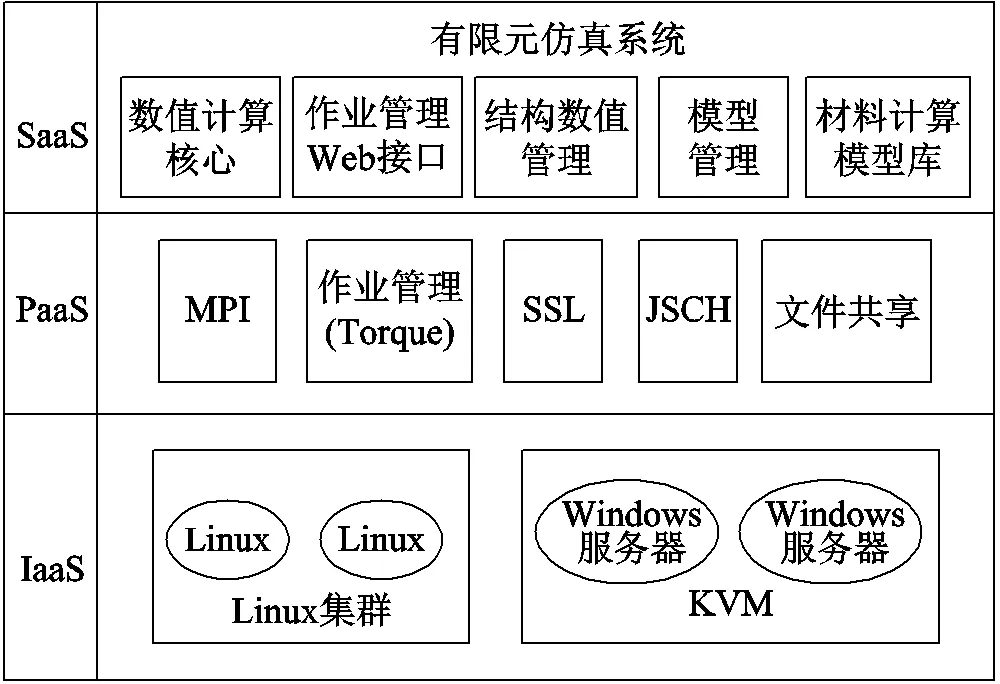
图1 基于云计算的有限元仿真系统
对于高性能计算,云计算一般采用管理节点虚拟化和计算节点非虚拟化的混合架构。计算机集群由21台双路28核心、128GB内存的服务器组成。1台作为管理节点(Master),负责计算任务的分发和调度,其余20台作为计算节点(Slaver)实现计算与存储。集群之间通过Infiband协议实现30Gbit/s光纤互联。存储系统采用Hadoop 分布式文件系统(Hadoop Distributed File System, HDFS)。
2 有限元可扩展并行算法
可扩展并行计算是指并行算法能有效利用可扩展处理器核心数的能力。并行程序计算性能的下降主要是由于数值计算过程中迭代计算需要在不同处理器核心及不同节点之间将OpenMpi通信用于交换边界数据。在主从模式,由于所有的数据通信均需通过管理节点实现,因此通信时间随核心数和计算规模的增加急剧增加导致,其计算效能在大规模计算中下降严重。本文主要通过子进程间直接进行点对点的通信且子进程间完全对等的方法改进传统的主从模式,建立基于主从/对等模型的并行程序框架,在实现进程间的高效交换边界数据的同时,兼顾主从模式程序清晰易调试的优点。具体为:任务分配采用主从模式,分区取得子任务进入有限元计算后,子进程与子进程间直接进行点对点的通信,且子进程间完全对等。
2.1 并行程序框架
并行程序框架如图2所示。图中主程序、主进程、从进程、前处理数据读取模块为并行、串行相一致的程序或模块;剖分与数据分割模块、剖分模块、数据分发模块、数据接收模块、求解器同步模块为并行计算模块;求解器、结果输出模块、子程序通信模块为并行独有模块。首先采用前处理数据读取Gidpre模块读入有限元前处理数据,通过剖分与数据分割Mpartition模块对全局的有限元数据进行任务分割,并结合有限元剖分Mgetpart模块将对应各子分区的数据和细剖分指令发送到对应子进程。子进程的数据接收Spart、自由度处理和解初始化Spre、刚度矩阵Sgetpart等模块完成从主进程接收分配的区域任务数据,并进一步细化网格和组装刚度矩阵。然后各子进程使用求解器Starta、子进程通信testa、求解器Ssolv等模块完成有限元求解流程和数据通信。各子进程间的点对点通信完成数据交换是在求解器Ssolv模块求解过程中每一次迭代计算子程序完毕后进行,通过通信模块Scom完成。
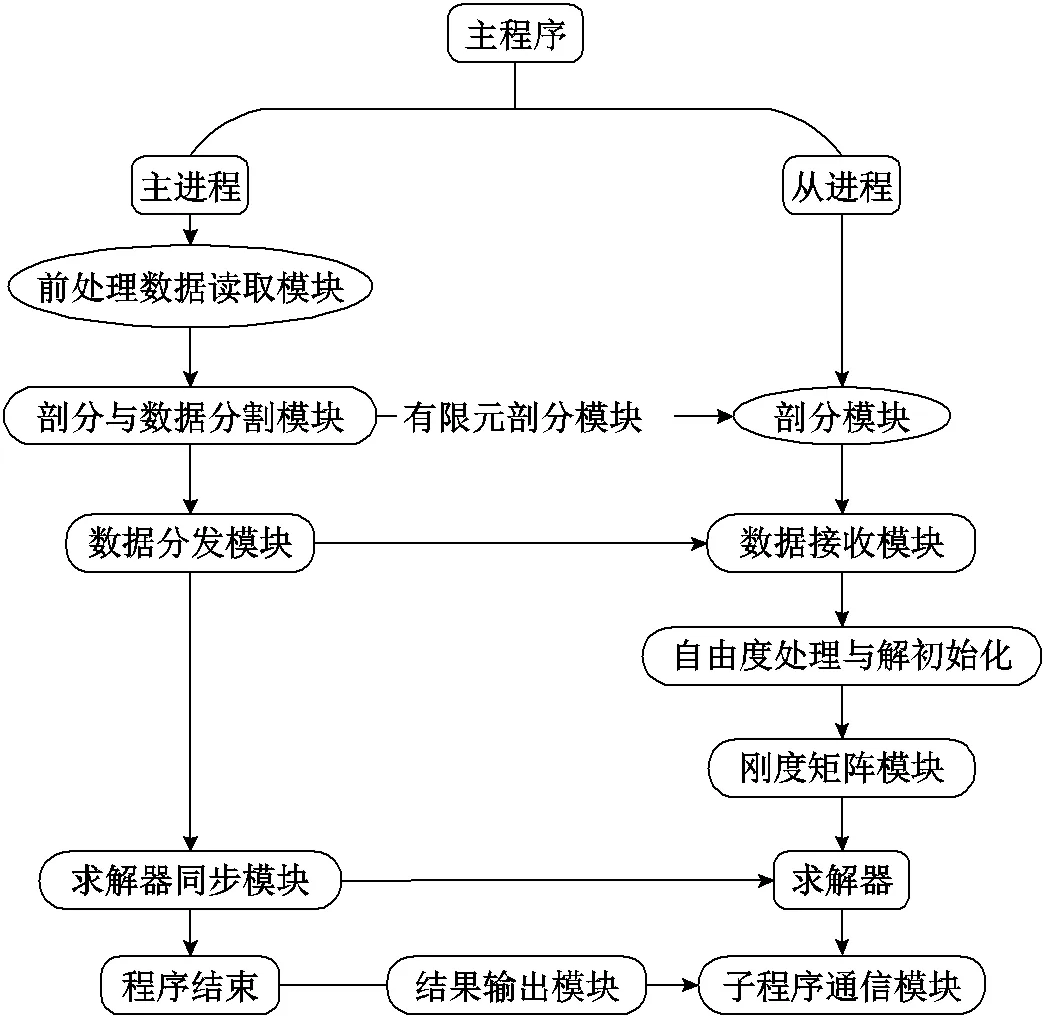
图2 并行程序框架
2.2 基于OpenMpi的并行程序通信
OpenMpi的工作机制如图3所示。MPI作为消息传递接口是一个并行计算的应用程序接口,能协调多台主机间的并行计算,且并行规模上的可伸缩性很强。基于组件架构MPI实现的OpenMpi,可通过组合不同组件来实现不同的功能,具有灵活、高效、适用性高等特点,适用于分布式内存之间的信息通信。主从/对等模型使得并行计算框架具有高度并行化的特点。为实现亿自由度的并行计算规模,并行计算框架运行在由多个计算节点组成的集群系统中,是典型的分布式内存系统,本文采用OpenMpi实现对本地指令和数据的直接访问以及管理节点和计算节点之间的消息传递。由MPI层、点对点传输层(PML)、字节传输层(BTL)、BTL管理层四部分组成的节点间通信架构,如图4所示。MPI层的作用是为MPI程序提供程序接口;在PML中,BTL组件管理所有的消息传递,实现了点对点通信原语,MPI层点对点语义通过PML运行,消息调度与进程策略嵌于协议中;由于多种功能组件需要BTL组件,BTL管理层(BML)给BTL的初始化与通过BTL进行资源恢复提供工具,在BTL初始化完成后,BML层对于BTL的内联功能被有效略过;BTL层架构包含了一组RDMA的通信单元,通过发送/接收端与基于RDMA端之间的内部数据连接实现数据转换的统一方法,以上四部分实现了节点间消息传递功能。基于进程调度的OpenMpi,并行扩展能力强,可满足成千上万计算节点的并行需求,且计算效率最高,但将串行程序并行化需要大量修改原有的串行代码和架构,导致编程工作量大、调试难度很大。本文的程序采用C语言编写,并在架构上考虑了并行的需要,因而采用OpenMpi实现并行指令和数据的通信和管理,达到提高并行计算效率的目的。同时采用了检查点设置/回卷恢复功能,建立进程、节点失效恢复的容错系统。
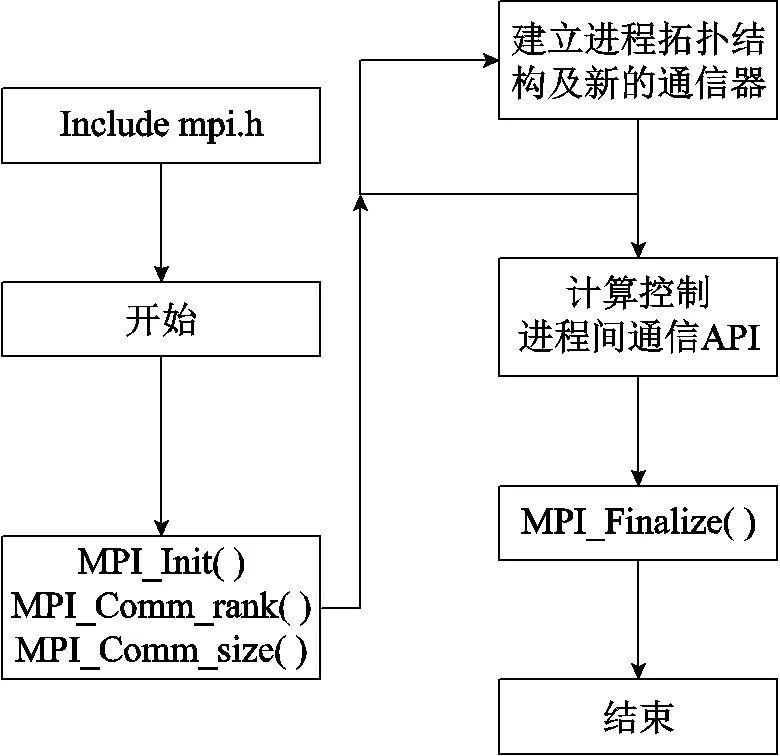
图3 OpenMpi工作机制
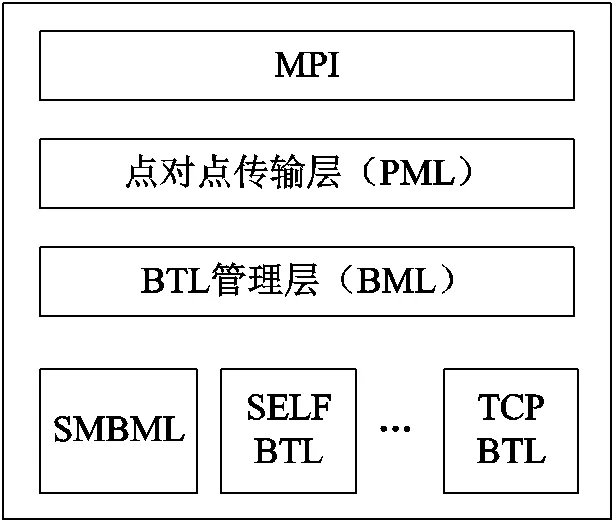
图4 节点间通信架构
2.3 电导率不变时的涡流场磁矢势A法
在涡流区内,在忽略位移电流的情况下,Maxwell方程可写作[37]
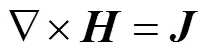
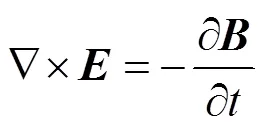
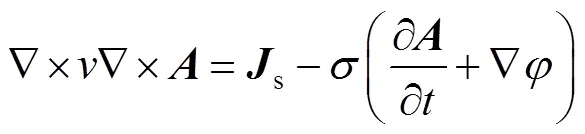
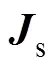
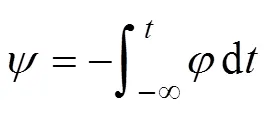
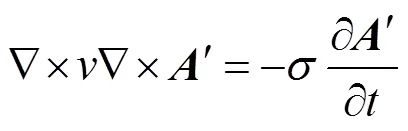
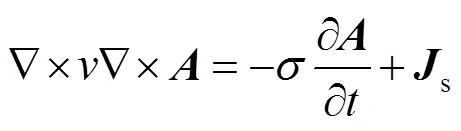
当源电流随时间按正弦变化,矢量可用复数计算。于是式(6)成为复矢量方程的三维涡流场矢量磁位微分方程及其边值问题,即
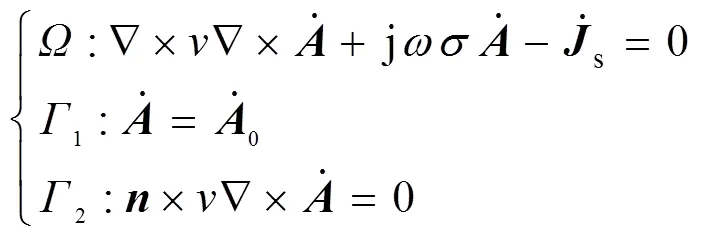
式(7)可通过伽辽金方法,可以得到一个线性方程的有限元系统
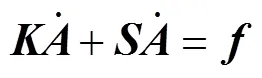
式中
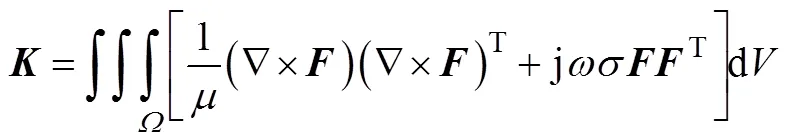
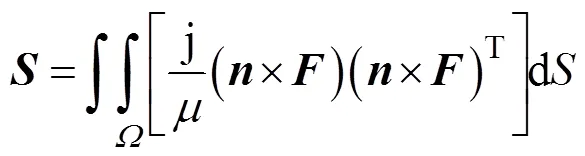
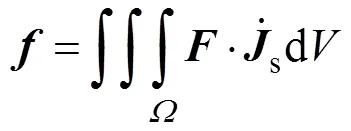
最后,电场强度表达式为
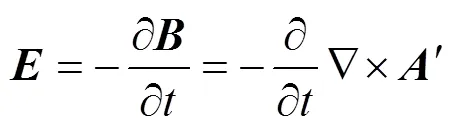
2.4 区域分解和并行算法
为了处理规模较大的模型,本文采用多层划分框架Metis。Metis是一组串行程序,用于对图进行分区、对有限元网格进行分区以及为稀疏矩阵生成填充顺序。Metis中的算法是基于多级递归对分、多级路和多约束分区方案。
区域分解方法(Domain Decomposition Method, DDM)将原来的大规模问题分解成更小的子域问题,并使用并行计算方法对其进行独立处理,从而使总计算时间显著缩短。并行算法采用一种鲁棒的区域分解方法——对偶原始有限元撕裂内联法(FETI-DP)提高有限元计算效率和扩展能力[22]。

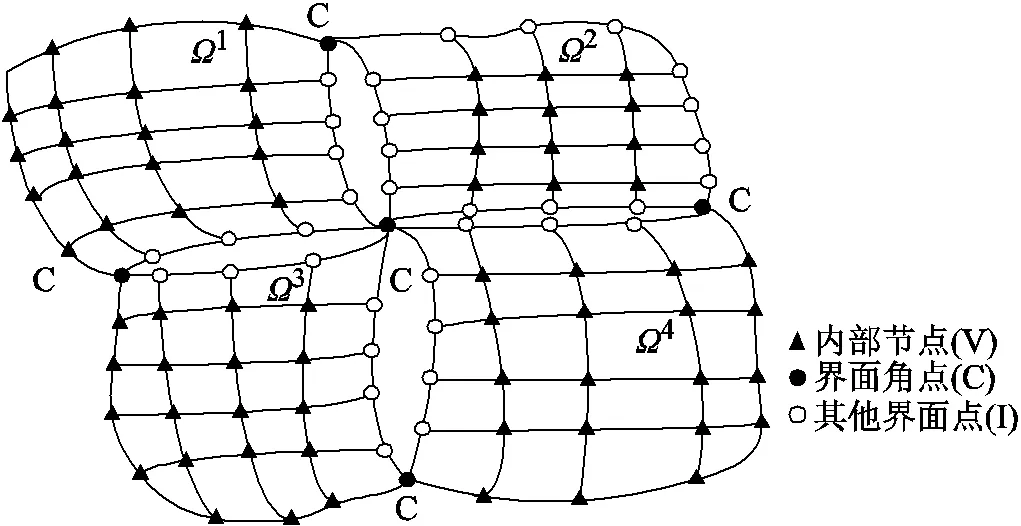
图5 FETI-DP 算法网格剖分及节点分类
在每个子域界面上,应满足场量的连续性,即
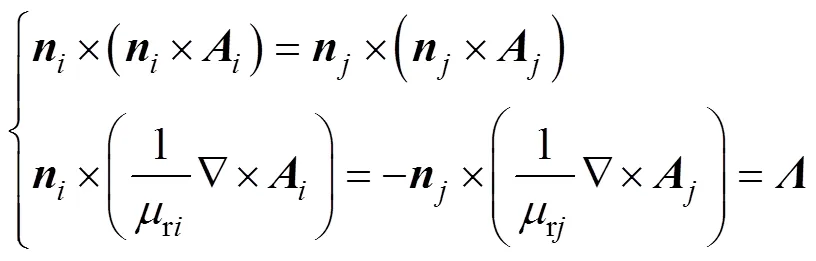
式中,、为两个相邻子域的编号。
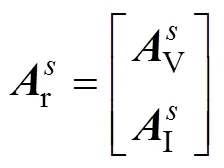
则有限元的子域刚度方程可定义为
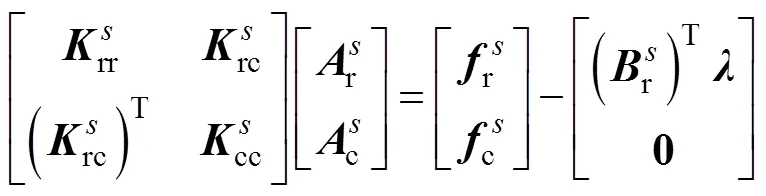
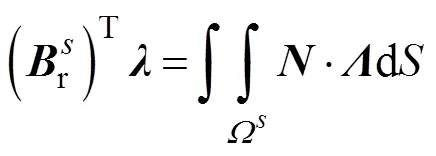
子域分界面上的连续性方程可表示为
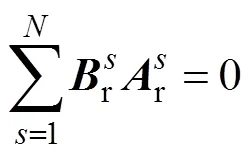
通过矩阵运算,由式(15)、式(16)与式(17)消去分界面的自由度,可以将原问题转变为求解关于界面拉格朗日乘子的一个对称正定对偶问题,即
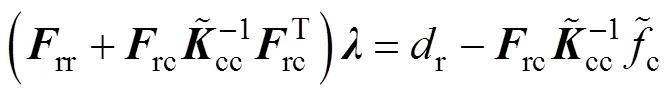
其中
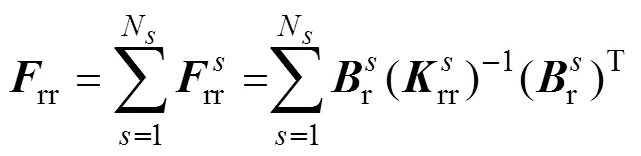
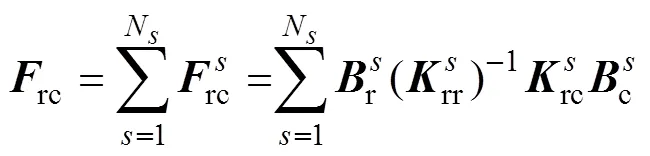
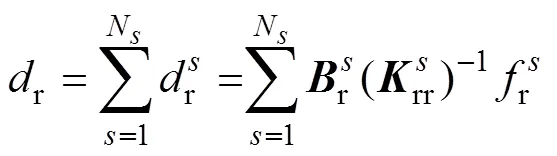
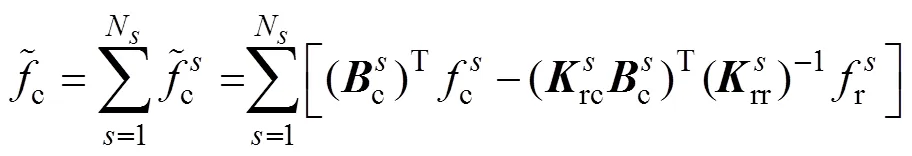
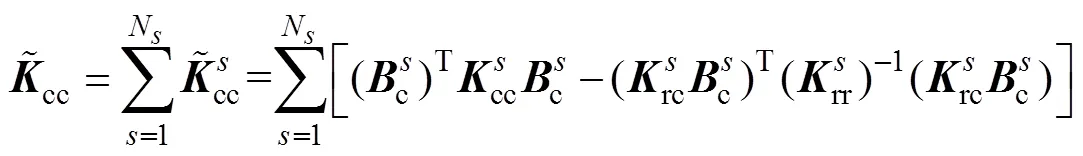
通过求解式(18)得到,然后将代入式(15)求得子域的,进而得到全局。由于原问题转变为求解关于界面拉格朗日乘子的一个对称正定对偶问题,FETI-DP方法具有良好的扩展性和收敛性。
3 计算案例
并行算法的实现是基于FELAC计算平台,具体实现过程,如图2所示。OpenMpi采用基于intel 14.0.2编译器编译的mpi。操作系统为Red Hat 6.5,内核版本为2.6.32-431.TH.x86_64。单机串行程序在Felac开发平台上开发完成,并行程序在上述的软硬件环境下开发、运行和测试。
π的并行计算程序在计算集群多节点上的并行程序测试,如图6所示。

图6 多节点并行程序测试
国际TEAM(Testing Electormagnetic Analysis Methods)基准问题是为了测试和验证电磁工程问题的电磁场数值计算方法正确性而建立的一系列标准模型和案例。TEAM Problem 7是检验三维涡流场数值计算精度的标准模型,由矩形载流线圈和导体板组成,线圈通以正弦电流,如图7a所示。矩形载流线圈一般由绝缘漆包铜线绕制,导体板一般为铝板。可用于模拟电工设备中金属构件的交变漏磁场引起的损耗。
可由式(12)计算电场强度,铝板中感应涡流密度e的求解公式为
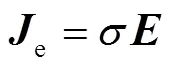
磁通密度计算公式为
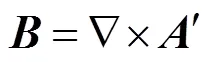
采用多层划分框架Metis对含空气域的整体进行分区后的情况,如图7b所示。由于矩形载流线圈和导体板均为非导磁性材料,磁场和电场分布在一个比较大的空间内并考虑到几何结构为方形,因此包含矩形载流线圈和导体板的空气域为方形结构。采用多层划分框架Metis对线圈和导体板进行分区后的情况,如图7a所示。从图7a和图7b可知多层划分框架Metis可对求解域进行区域分解,且分区较为规则和均匀。
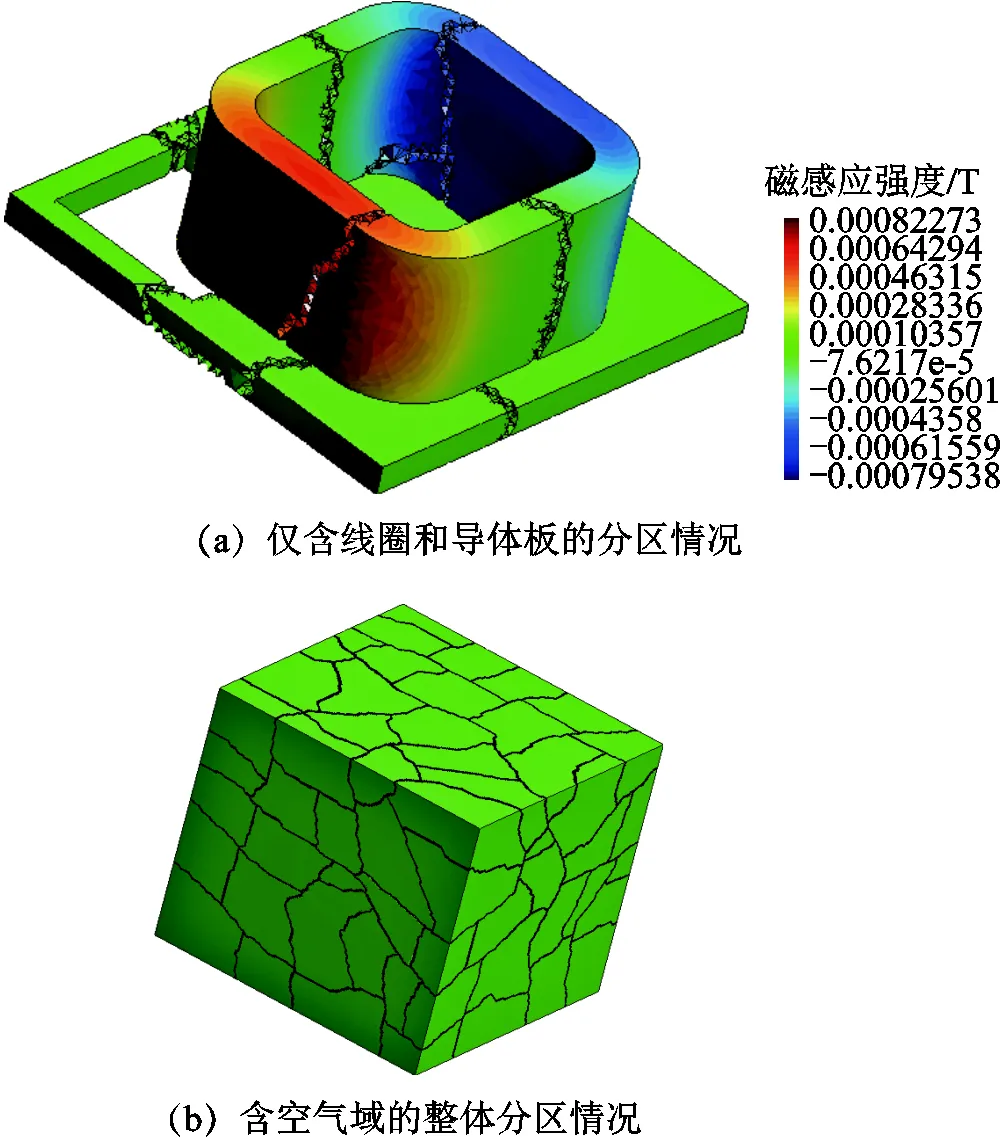
图7 TEAM Problem 7基准问题计算案例
200Hz时导体板上表面电流分量分布如图8所示。电流虚部和实部的分布情况和电磁感应定律是一致的,电流在矩形载流线圈正下方的导体板开孔边界处最大、在远离矩形载流线圈的导体板外边缘处最小。
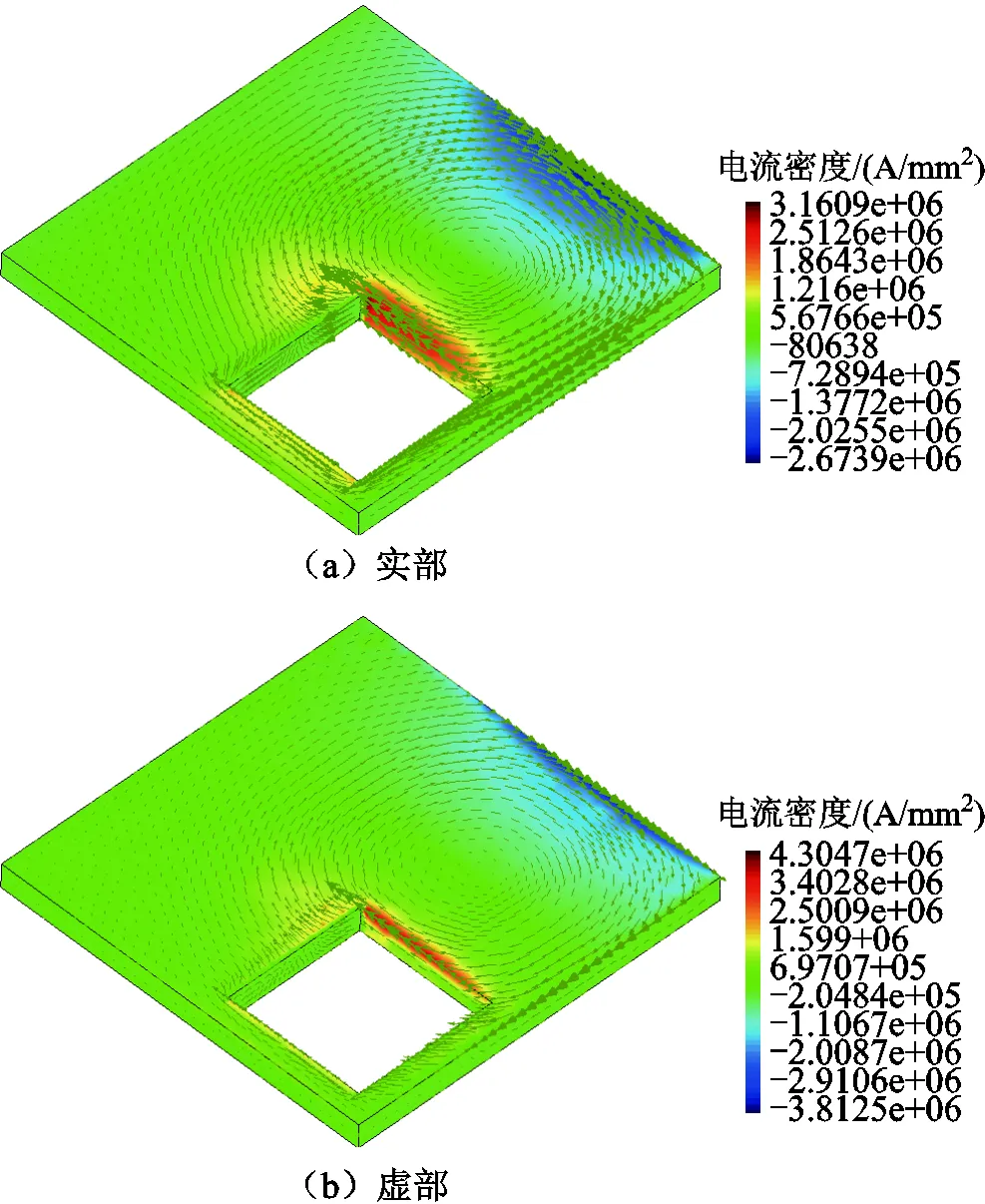
图8 200Hz时导体板上表面电流Y分量分布
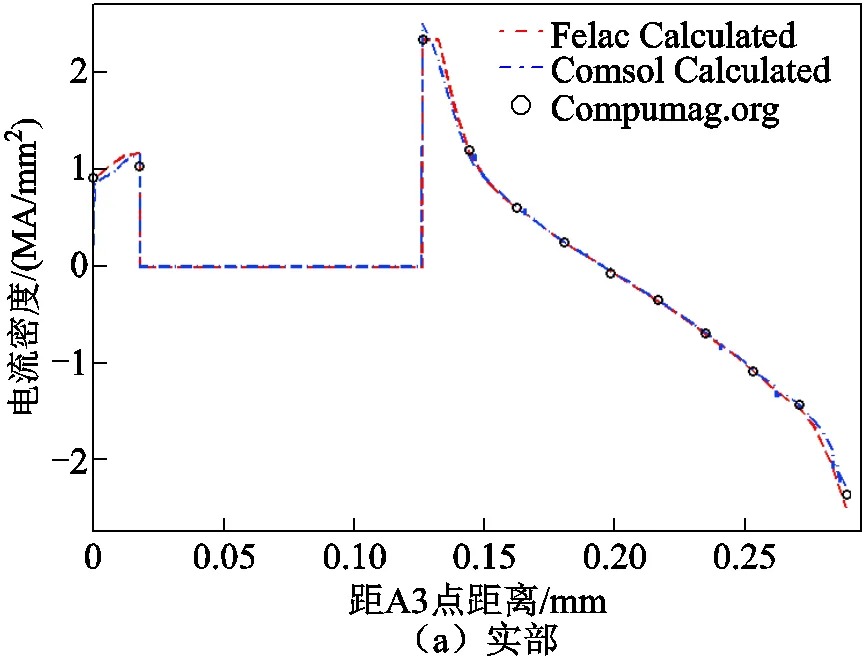
200Hz时空气中A3-B3直线上磁场分量的计算值和测量值,如图9所示。其中,直线A3-B3是指Team Problem7文献中给出的测量线[39]。A3-B3是紧邻导体板上表面的一条位于空中的直线,A3坐标值为(0mm, 72mm, 34mm),B3坐标值为(288mm, 72mm, 34mm)。图9中的Felac Calculated是指可扩展并行计算方法得到的计算值;Comsol Calculated是指电磁场数值计算软件Comsol计算得到的计算值;Compumag. org是指Team Problem7文献中给出的测量值[39],结果证明本文并行计算方法的计算结果是正确的。
1)小规模测试
有限元的测试规模为节点330万、自由度2 643万、单元数2 091万,为评价并行计算的效率,分别采用100核、200核、300核和400核进行测试。加速比为单个CPU计算运行时间s与个CPU计算运行时间p()之间的比值p()=s/p()。个CPU的并行计算效率为p()=p()/,并行效率可以理解为每个CPU的平均利用率。以100核作为基准的并行性能见表1。
表1 小规模测试的并行性能

Tab.1 Performance for small-scale testing
2)大规模测试
有限元的测试规模为节点数1 256万、自由度数10 049万、单元数7 436万。为评价并行计算的效率,分别采用100核、200核、300核、400核进行测试,以100核作为基准的并行性能见表2。
节点数、自由度数、单元数的数量将会影响计算规模的大小。随着计算规模的增加将会使并行计算过程的迭代计算时间和并行计算总时间明显增加。对比两个测试结果,采用100核、200核、300核、400核时,大规模测试的计算效率相比小规模测试变化不大。实验结果证明本文提出的大规模工程电磁场亿自由度可扩展并行计算方法具有很好的并行计算效率和鲁棒性。
表2 大规模测试的并行性能

Tab.2 Performance for big-scale testing
4 结论
本文研究并改进传统的主从并行程序框架,建立了主从/对等并行程序框架,基于电导率不变时涡流场磁矢势法和对偶原始有限元撕裂内联(FETI-DP)法建立了可扩展并行计算方法,调用400个计算核心实现了涡流场的高效并行计算,成功地将数值计算规模提高到1亿自由度。数值计算的加速比结果表明可扩展并行计算方法具有很好的可扩展性能和很高的并行计算效能,同时点对点的对等模型为更大规模的并行数值计算奠定了基础。研究成果为大型复杂电工装备产品级模型的高效和高精度数值模拟提供了有效的理论和实践方法。
在后续研究中,将进一步提高并行计算规模和加速比,基于A-phi方法实现TEAM Problem21案例的实现亿节点并行计算。
[1] Cheng Zhiguang, Norio Takahashi, Yang Sumei, et al. Loss spectrum and electromagnetic behavior of Problem 21 family[J]. IEEE Transactions on Magnetics, 2006, 42(4): 1467-1470.
[2] 谢德馨, 程志光, 杨仕友, 等. 对当前计算电磁学发展的观察与思考——参加COMPUMAG2011会议有感[J]. 电工技术学报, 2013, 28(1): 136-141.
Xie Dexin, Cheng Zhiguang, Yang Shiyou, et al. Observation and consideration on the current development of computational electromagnetics—in perspective of COMPUMAG2011[J]. Transactions of China Electrotechnical Society, 2013, 28(1): 136-141.
[3] Hihat Nabil, Napieralska-Juszczak Ewa, Lecointe Jean-Philippe, et al. Equivalent permeability of step-lap joints of transformer cores: computational and experimental considerations[J]. IEEE Transactions on Magnetics, 2011, 47(1): 244-251.
[4] 李立毅, 孙芝茵, 潘东华, 等. 近零磁环境装置现状综述[J]. 电工技术学报, 2015, 30(15): 136-140.
Li Liyi, Sun Zhiyin, Pan Donghua, et al. Status reviews for nearly zero magnetic field environment facility[J]. Transactions of China Electrotechnical Society, 2015, 30(15): 136-140.
[5] 程志光, 刘涛, 范亚娜, 等. 基于TEAM P21三维杂散场问题建模仿真与验证[J]. 电工技术学报, 2014, 29(9): 194-203.
Cheng Zhiguang, Liu Tao, Fan Yana, et al. TEAM P21-based validation of 3-D stray-field modeling and simulation[J]. Transactions of China Electrotechnical Society, 2014, 29(9): 194-203.
[6] 刘广一, 戴仁昶, 路轶, 等. 基于图计算的能量管理系统实时网络分析应用研发[J]. 电工技术学报, 2020, 35(11): 2339-2348.
Liu Guangyi, Dai Renchang, Lu Yi, et al. Graph computing based power network analysis applications[J]. Transactions of China Electrotechnical Society, 2020, 35(11): 2339-2348.
[7] 李雪, 张琳玮, 姜涛, 等. 基于CPU-GPU异构的电力系统静态电压稳定域边界并行计算方法[J]. 电工技术学报, 2021, 36(19): 4070-4084.
Li Xue, Zhang Linwei, Jiang Tao, et al. CPU-GPU heterogeneous computing for static voltage stability region boundary in bulk power systems[J]. Transactions of China Electrotechnical Society, 2021, 36(19): 4070-4084.
[8] 刘涛, 习金玉, 宋战锋, 等. 基于多核并行计算的永磁同步电机有限集模型预测控制策略[J]. 电工技术学报, 2021, 36(1): 107-119.
Liu Tao, Xi Jinyu, Song Zhanfeng, et al. Finite control set model predictive control of permanent magnet synchronous motor based on multi-core parallel computing[J]. Transactions of China Electrotechnical Society, 2021, 36(1): 107-119.
[9] 管建和. 电磁场有限元法解释分布式并行计算的研究[D]. 北京: 中国地质大学(北京), 2006.
[10] Li Yujia, Jin Jianming. A new dual-primal domain decomposition approach for finite element simulation of 3-D large-scale electromagnetic problems[J]. IEEE Transactions on Antennas and Propagation, 2007, 55(10): 2803-2810.
[11] Zhen Peng, Lee JinFa. Non-conformal domain decomposition method with mixed true second order transmission condition for solving large finite antenna arrays[J]. IEEE Transactions on Antennas and Propagation, 2011, 59(5): 1638-1651.
[12] Xue Mingfeng, Jin Jianming. A hybrid conformal/ nonconformal domain decomposition method for multi-region electromagnetic modeling[J]. IEEE Transactions on Antennas and Propagation, 2014, 62(4): 2009-2021.
[13] Xue Mingfeng, Jin Jianming. Nonconformal FETI-DP methods for large-scale electromagnetic simulation[J]. IEEE Transactions on Antennas and Propagation, 2012, 60(9): 4291-4305.
[14] Mario A Echeverri Bautista, Francesca Vipiana, Matteo Alessandro Francavilla, et al. A nonconformal domain decomposition scheme for the analysis of multiscale structures[J]. IEEE Transactions on Antennas and Propagation, 2015, 63(8): 3548-3560.
[15] 唐任远, 吴东阳, 谢德馨. 单元级别并行有限元法求解工程涡流场的关键问题研究[J]. 电工技术学报, 2014, 29(5): 1-8.
Tang Renyuan, Wu Dongyang, Xie Dexin. Research on the key problem of element by element parallel FEM applied to engineering eddy current analysis[J]. Transactions of China Electrotechnical Society, 2014, 29(5): 1-8.
[16] Zheng Weiying, Cheng Zhiguang. An inner-constrained separation technique for 3D finite element modeling of GO silicon steel laminations[J]. IEEE Transactions on Magnetics, 2012, 48(8): 2277-2283.
[17] Wang Yao, Jin Jianming, Philip TKrein. Application of the LU recombination method to the FETI-DP method for solving low-frequency multiscale electromagnetic problems[J]. IEEE Transactions on Magnetics, 2013, 49(10): 5346-5355.
[18] Van Emden Henson, Ulrike Meier Yang. BoomerAMG: a parallel algebraic multigrid solver and preconditioner[J]. Applied Numerical Mathematics, 2002, 41(1): 155-177.
[19] Ralf Hiptmair, Xu Jinchao. Auxiliary space preconditioning for edge elements[J]. IEEE Transactions on Magnetics, 2008, 44(6): 938-941.
[20] Zhang Linbo. A parallel algorithm for adaptive local refinement of tetrahedral meshes using bisection[J]. Numerical Mathematics a Journal of Chinese Universities English Series, 2009, 2(1): 65-89.
[21] George Karypis, Vipin Kumar. Multilevel k-way partitioning scheme for irregular graphs[J]. Journal of Parallel and Distributed Computing, 1998, 48(1): 96-129.
[22] Charbel Farhat, Michel Lesoinne, Patrick LeTallec, et al. FETI-DP: a dual–primal unified FETI method—Part I: a faster alternative to the two-level FETI method[J]. International Journal for Numerical Methods in Engineering, 2001, 50(7):1523-1544.
[23] Xue Mingfeng, Jin Jianming. A preconditioned dual-primal finite element tearing and interconnecting method for solving three-dimensional time-harmonic Maxwell's equations[J]. Journal of Computational Physics, 2014, 274: 920-935.
[24] James Ahrens, Kristi Brislawn, Ken Martin, et al. Large-scale data visualization using parallel data streaming[J]. IEEE Computer Graphics and Applications, 2001, 21: 34-41.
[25] 史燕琨, 熊华强. 基于伪并行遗传算法的配电网电容器优化配置[J]. 电力系统保护与控制, 2009, 37(20): 57-60.
Shi Yankun, Xiong Huaqiang. Optimal capacitor arrangement based on pseudo parallel genetic algorithm[J]. Power System Protection and Control, 2009, 37(20): 57-60.
[26] 黄靖, 张晓锋, 叶志浩. 大型船舶电力系统分布式并行潮流计算方法[J]. 电力系统保护与控制, 2011, 39(7): 50-55.
Huang Jing, Zhang Xiaofeng, Ye Zhihao. A distributed parallel load flow calculation method for large ship power system[J]. Power System Protection and Control, 2011, 39(7): 50-55.
[27] 简金宝, 杨林峰, 全然. 基于改进多中心校正解耦内点法的动态最优潮流并行算法[J]. 电工技术学报, 2012, 27(6): 232-241.
Jian Jinbao, Yang Linfeng, Quan Ran. Parallel algorithm of dynamic optimal power flow based on improved multiple centrality corrections decoupling interior point method[J]. Transactions of China Electrotechnical Society, 2012, 27(6): 232-241.
[28] David MFernández, Maryam Mehri Dehnavi, Warren JGross, et al. Alternate parallel processing approach for FEM[J]. IEEE Transactions on Magnetics, 2012, 48(2): 399-402.
[29] Gabriel Mateescu, Wolfgang Gentzsch, Calvin JRibbens. Hybrid computing—where HPC meets grid and cloud computing[J]. Future Generation Computer Systems, 2011, 27(5): 440-453.
[30] Ismail Ari, Nitel Muhtaroglu. Design and implementation of a cloud computing service for finite element analysis[J]. Advances in Engineering Software, 2013, 60-61: 122-135.
[31] 符伟. 云计算环境下的线性有限元方法研究[D]. 武汉: 华中科技大学, 2013.
[32] Zhang Y, Gallipoli D, Augarde C E. Simulation- based calibration of geotechnical parameters using parallel hybrid moving boundary particle swarm optimization[J]. Computers and Geotechnics, 2009, 36(4): 604-615.
[33] 张友良, 冯夏庭, 茹忠亮. 基于区域分解算法的岩土大规模高性能并行有限元系统研究[J]. 岩石力学与工程学报, 2004, 23 (21): 3636-3641.
Zhang Youliang,Feng Xiating, Ru Zhongliang. Large-scale high performance parallel finite element system based on domain decompositioin method in geomechanics[J]. Chinese Journal of Rock Mechanics and Engineering , 2004, 23(21): 3636-3641.
[34] Zhang Youliang, Domenico Gallipoli. Development of an object-oriented parallel finite element code for unsaturated soils[M]. Berlin Heidelberg: Springer, 2007.
[35] 金亮, 汪东梅, 邱运涛, 等. 基于弹性云计算集群的国际TEAM Problem 7基准问题计算方法[J]. 电工技术学报, 2017, 32(8): 144-150.
Jin Liang, Wang Dongmei, Qiu Yuntao, et al. A calculation method for the international benchmark Problem of TEAM 7 based on elastic cluster in cloud computing[J]. Transactions of China Electrotechnical Society, 2017, 32(8): 144-150.
[36] 金亮, 邱运涛, 杨庆新, 等. 基于云计算的电磁问题并行计算方法[J]. 电工技术学报, 2016, 31(22): 5-11.
Jin Liang, Qiu Yuntao,Yang Qingxin, et al. A parallel computing method to electromagnetic problems based on cloud computing[J]. Transactions of China Electrotechnical Society, 2016, 31(22): 5-11.
[37] 颜威利, 杨庆新, 汪友华, 等. 电气工程电磁场数值分析[M]. 北京:机械工业出版社, 2006.
[38] 张友良, 谭飞, 张礼仁, 等. 岩土工程亿级单元有限元模型可扩展并行计算[J]. 岩土力学, 2016, 37(11): 3309-3316.
Zhang Youliang, Tan Fei, Zhang Liren, et al. Scalable parallel computation for finite element model with hundreds of millions of elements in geotechnical engineering[J]. Rock and Soil Mechanics, 2016, 37(11): 3309-3316.
[39] Problem 7 asymmetrical conductor with a hole[DB/OL].https://www.compumag.org/wp/wp-content/uploads/2018/ 06/problem7.pdf.
Extensible Parallel Computing Method with Hundreds of Millions of Freedoms for Large-Scale Engineering Electromagnetic Field
Jin Liang1,2Li Yuzeng1,2YangQingxin1,2Zhang Chuang1,2Yan Shuai3
(1. State Key Laboratory of Reliability and Intelligence of Electrical Equipment Hebei University of Technology Tianjin 300130 China 2. Key Hebei Key Laboratory of Electromagnetic Field and Electrical Apparatus Reliability Hebei University of Technology Tianjin 300130 China 3. Institute of Electrical Engineering Chinese Academy of Sciences Beijing 100081 China)
Accurate and rapid electromagnetic field calculation is the basis of fine simulation and optimization design of electrical equipment. In this paper, the scalable parallel computing research is carried out on the elastic cluster of high-speed interconnected high-performance cloud platform. OpenMpi is used as the message passing library, and the dual-primal finite element tearing and interconnecting (FETI-DP) method is selected as the domain decomposition algorithm. The parallel computing of eddy current magnetic vector potentialwith constant conductivity is achieved by improving the master-slave/peer parallel program framework, which can reduce the complexity of programming and improve the efficiency of parallel computing. The program is written in C language and the scalable parallel computing method is verified by the benchmark problem of international TEAM Problem 7. In this paper, the master-slave/peer-to-peer parallel program framework and the dual-primal finite element tearing and interconnecting FETI-DP method are introduced into the field of electromagnetic computing, which improves the efficiency and scalability of parallel computing, and provides a new practical and theoretical method for large-scale engineering electromagnetic field calculation.
Parallel computing, numerical calculation of electromagnetic fields, finite element method, dual-primal finite element tearing and interconnecting(FETI-DP)
10.19595/j.cnki.1000-6753.tces.211050
TM153
国家自然科学基金面上项目(51977148)和国家自然科学基金重大研究计划项目(92066206)资助。
2021-07-09
2021-11-01
金 亮 男,1982年生,博士,教授,研究方向为工程电磁场与磁技术、电磁场云计算和电磁无损检测等。E-mail:jinliang@tju.edu.cn(通信作者)
李育增 男,1996年生,硕士研究生,研究方向为工程电磁场。E-mail:lyz18330774321@163.com
(编辑 郭丽军)
猜你喜欢
核安全(2022年3期)2022-06-29
军民两用技术与产品(2021年4期)2021-07-28
空间科学学报(2021年6期)2021-03-09
河北省科学院学报(2020年4期)2020-03-19
能源(2019年9期)2019-12-06
能源(2019年5期)2019-06-19
能源(2019年12期)2019-02-11
数学大王·趣味逻辑(2019年2期)2019-01-23
考试周刊(2017年3期)2017-02-13
中国舰船研究(2015年2期)2015-02-10
