
基于多模态语义识别的语音识别报警系统
2022-02-21 01:45陈立鹏陈小龙宋诗凡陈桢衍
科学技术创新 2022年2期
陈立鹏 陈小龙 宋诗凡 陈桢衍
(天津工业大学 软件学院,天津 300387)
人类的感知过程是多模态的[1],样本可以通过不同通道的信息加以描述,每一通道的信息定义为一种特定的模态[2]。相比于单一模态,多模态能更准确地描述出样本的特征。
早在公元前4 世纪,多模态的相关概念和理论即被用以定义融合不同内容的表达形式与修辞方法[3-4]。多模态学习从1970 年起步,经历了几个发展阶段后,在2010 年之后全面步入深度学习阶段。多模态学习可以划分为以下五个研究方向:多模态表示学习、模态转化、对齐、多模态融合、协同学习[5]。
多模态技术常被应用到语义识别中,通常结合图片、文本、语音等,判断说话人的语义,语音识别技术最早可以追溯到1952 年,当时Davis[6]等人研究出了可以识别10 个英文数字发音的实验系统。从那时起到现在,语音识别给我们带来了很多方便[7]。现阶段家教平台众多,大学生家教由于价格便宜,性价比高受到了一些家长的青睐,但是大学生家教还未形成规范的体系,在上课期间可能发生意外情况却无法报警或及时告知能帮助他们的人,针对这一现象,本文提出一种基于多模态语义分析的语音识别报警系统。
1 系统简介
本系统基于Python Tensorflow环境实现了语音识别报警功能,部署本系统的应用在工作场景进行实时录音,当检测到一方对另一方发出具有威胁性或者求救性的语音时实施报警,为避免当事人因无意识地触发词库关键词而导致系统错误地报警,因此需要实时监测被监听者的语音情绪,当被监听者用恐惧或是伤心的语气触发求救关键词立刻触发报警系统,所以实现本系统的关键在于两大模块,分别是:情感分析模块以及语音关键词唤醒模块。
2 情感分析模块
2.1 情感描述方式
情感描述方式主要有两种类型:一种是维度描述方法例如Schlosberg[9]等提出的三维情感,该种描述可以从三个维度描述情感,同时可以体会出情感的微妙变化;而另外一种则是对情感实施离散分类,就像Chen[8]等提出的MFCCG-PCA 情感识别模型,该模型实现了害怕、高兴、惊讶、中性、悲伤、生气这六种情感的离散化分类,该种描述无法体会到情感的微妙变化。
作者在构建该语音识别警报系统时选择离散式的情感描述方式,因为该系统只需要检测被监听者发出求救信号时的情感状态,不需要体会被监听者的情感变化。
2.2 语音情感识别模型
在早期Wang[10]等利用支持向量机来预测语音情感,Zhao[11]等分析了不同情感的时间构造、振幅构造、基频构造和共振峰构造等语音特征。
近年来由于深度学习的发展人民普遍应用深度学习的方法来对语音情感进行预测,Geng[15]等提出了卷积神经网络CNN 来预测语音情感,Li[12]等提出了改进MFCC 融合特征的愤怒情绪判断方法,Zhu[13]等利用了AlexNet 预训练的网络结合FNC 全卷积神经网络实现了对不同情绪的预测,Xue[14]等结合了卷积神经网络CNN 以及双向循环神经网络BiGRU 提出了TSTNet 语音情感识别模型。
由于作者需要实现实时分析语音情感的系统,并且训练好的模型为了保证运算速度会部署在性能足够强大的服务器上,考虑到数据在网络上的传播时延会显著的影响模型的响应速度,因此训练模型时必须选取计算时间足够短的网络结构。在保证至少85%的正确率的前提下,作者选择了Geng[15]等提出的CNN 卷积网络结构作为用来实现本系统的语音情感分类器,尽管有比该类模型更加优秀的选择,但考虑到计算时间的要求CNN 卷积网络结构是最好的选则,因为其它网络的网络结构过于复杂,计算量要比CNN 模型大得多,经作者测试在同一硬件条件下CNN 网络的计算速度要比TSTNet 快2s。因此作者最终选择了CNN 卷积神经网络作为语音情感分类器。
2.3 中文情感数据库
由于本系统被研发出来是希望应用于中文环境中的,因此作者进行模型训练时只选取了CASⅠA 中文语音情感数据库,该数据库中共收录了总共1200 条分别由四位播音员录制的害怕、高兴、惊讶、中性、悲伤、生气这六种情感的语音数据,每条语音数据长度在[1s, 2s]这个区间。
2.4 数据处理
每一条数据首先被统一成音长2s,采样率16000Hz 的数据,之后作者对原始数据进行了随机语音增强以及混入自然噪音,并将数据增强后的语音数据集喂入Pascual[16]等提出的语音增强对抗神经网络中再做进一步的数据增强。作者最终通过随机语音增强以及混入自然噪音加上对抗神经网络数据增强的方式得到了12000 余条语音数据。之后将所有数据样本进行预加重、数据分割、加汉明窗、提取MFCC 后就可以将数据送入神经网络中进行模型训练。
2.5 CNN 情感识别模型的设计
作者建立该模型使用了五个卷积模块(如图1 所示),第一个卷积模块只有一个卷积层和一个Relu 层,第二个卷积模块拥有一个卷积层、一个正则化层、一个Relu 层、一个Dropout 和一个最大池化层,第三个和第五个卷积模块和第一个相同,第四个卷积模块和第二个一样,作者试验过多种卷积网络结构经过验证发现该种结构的效果最好。
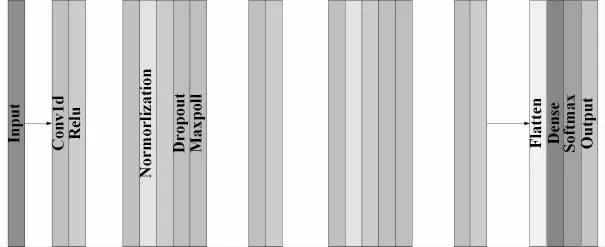
图1 CNN 网络结构图
在神经网络中第一个卷积模块被用来提取音频数据的二维特征频域×时序,再将该二维特征作为输入数据喂入其余四个卷积模块中,在本系统中作者输入大小设置为63×1,内核设置为2×2,卷积核的跨度为1×2,其余所有卷积核均为1×1。同时为了提高深度网络的运算速度并且保证训练时数据分布一致,作者还在网络中使用了批归一化[17]。
气象站位于甘肃酒泉市金塔县境内,地处东经98°30'00",北纬 40°19'58.8",北靠黑山,地处戈壁,地势平坦,场地开阔。金塔县位于甘肃省河西走廊中段北部边缘,东、北与内蒙古额济纳旗毗连,西面与甘肃嘉峪关、玉门、肃北接壤,南与酒泉市和张掖地区的高台县为邻。
经过批归一化处理过后神经网络最终输出结果为:
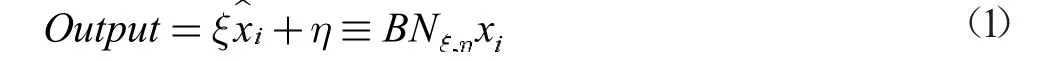
经过作者验证,该模型可在1s 左右的时间计算结果准确率可以达到87.43%。
3 语音关键词唤醒模块
语音关键词检测是指从连续语音流中识别或检测出一个特定关键词[18]。在检测到词库关键词后唤醒后续的程序,这就是本模块的基本工作内容。
语音关键词识别的方法:
作者在构建语音关键词唤醒模块时分为以下两个步骤:
a.基于模板匹配的关键词识别[21]
基本算法框架包括语音信号预处理,端点检测,特征参数提取,模板库参考模板建立,模板匹配识别等基本单元[19-20]。
首先将一段用人声说出的词汇录音下来,通过算法制作成可识别的词汇模板。设计出算法对语音进行预滤波、ADC、分帧、端点检测、预加重、加窗、特征提取、特征匹配。算法模块加载了词汇模板后,检测出有效语音,根据人耳听觉感知特性,计算每帧语音的MFCC。然后采用DTW 算法与特征模板相匹配,最终输出识别结果。
本文将“模板”替换为RNN 循环神经网络,这样做可以提高2%的识别精度。
b. RNN 循环神经网络
人工神经网络的基本结构与训练方法:在人工神经网络中,神经元结点的输入首先经过加权线性组合,然后通过激活函数(Activation function)激活[24]。
Sigmoid 函数:
激活函数有很多种本文作者使用Sigmoid 函数,因为该模块可以看作二分类系统模块,即符合关键词与不符合关键词。
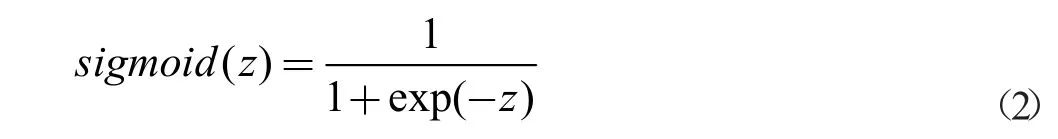
由于语音是与时序有关的信号,语音中过去和将来的状态信息都会影响到此时的状态,为了解决这种时序问题Grave在文献[25]中设计了如图2 所示的双向循环神经网络。
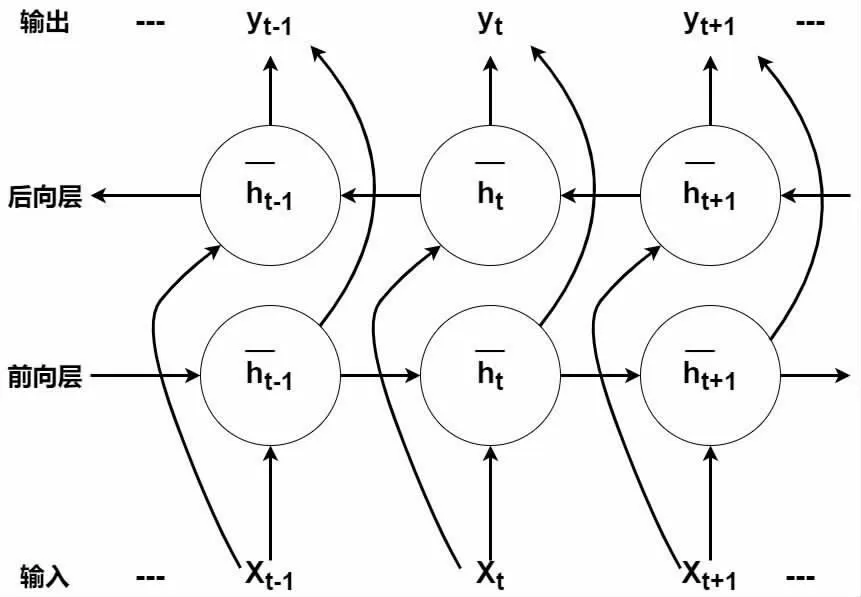
图2 双向循环神经网络[26]

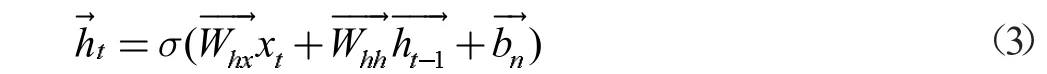
当前层通过t=1 到T 的迭代,根据式(4)计算隐藏层的后向序列,
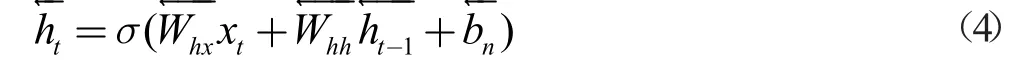
建立好网络之后就可以进行迭代训练了,最后语音识别唤醒模块的准确率为91%。
4 双模态融合
作者使用两种模型后端融合的方式来实现该语音识别报警系统的模态融合,具体操作(如图3 所示)为将语音关键词唤醒模块作为语音情感分析的启动模块,语音关键词唤醒模块(以下简称S)将被安装到客户端上,一旦被监听者触发关键词库中的关键词,S 就会通过网络将监听到的关键词语音片数据段送到位于服务端的情感分析模块上(以下简称E),之后E 会针对这一段语音进行情感分析,一旦S 传递的语音片段属于悲伤、恐惧这一类的负面情感,E 会通过网络向位于客户端的S 发出报警信号,同时E 也会向后台管理人员发出报警,S 在接到E 的报警信号后会大声地发出警报声音恫吓施暴者,并且还会通过网络向E 发送被监听者所处的位置,以便于在确认被监听者真正遭受人身威胁时向警方提供关键信息。
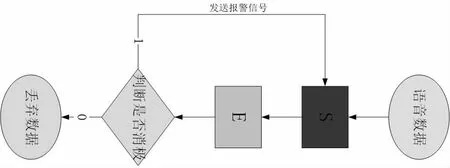
图3 双模态融合图
结果分析:
情感识别模块的准确率为87.43%,关键词识别模块的准确率为91%,在建立好图4 的系统结构之后,通过在分别为安静无声的环境中进行播放带有恐惧情感的“救命”录音的方式进行测试以及在有不规则背景噪音的环境中进行播放带有恐惧情感的“救命”录音的方式进行测试,两个场景分别执行50次测试,最终测得安静无声的环境中该系统识别的正确率为88%,而在有不规则噪音的环境中测试的成功率为80%。
5 结论
本文从系统功能出发,首先介绍了该语音识别报警系统的系统结构,包括语音情感分析模块和语音关键词唤醒模块,随后又分别针对两大模块介绍了其实现原理,包括基于对抗神经网络的数据增强,基于CNN 模型、RNN 模型的Tensorflow预测模型的搭建与训练,同时还简要介绍了加速训练的批归一化算法。
经过实景测试表明该系统可快速判断求救语义并做出及时的反应,经过多次人工实验表明,在安静无声的环境中该系统识别的正确率为88%,而在有不规则噪音的环境中识别的成功率为80%,因此对实际应用具有一定的指导意义。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
北京航空航天大学学报(2021年9期)2021-11-02
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
电子制作(2019年13期)2020-01-14
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年11期)2019-07-04
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
