
基于AlexNet网络的服装风格识别分析
2022-02-21 10:42:20李淑霞杨俊成
微型电脑应用 2022年1期
李淑霞, 杨俊成,2
(1.河南工业职业技术学院,电子信息工程学院,河南,南阳 473000;2.武汉大学,计算机学院,湖北,武汉 430072)
0 引言
随着电子商务的发展,通过网络购买服装的用户越来越多,如果能够根据服装图片对服装风格进行分类识别,不仅能给予消费者搭配选购的建议还能帮助商家促进销售。服饰行业作为网络营销中规模大、起步早的行业之一,网络购物占比超过了三成,至今依然在吸引消费者,其需求呈上升趋势。因此,基于已知服装图片进行服装风格识别具有一定的现实意义[1-2]。针对消费者,可以根据提供的单品图片对消费者推荐服装搭配,帮助消费者节省时间和精力;针对购物网站,可以根据提供的图片,找到相似的服装、搭配推荐给客户,从而扩大销售,达到共赢。
服装风格是指一个人的服装在形式和内容方面所展示出来的内在品格,价值取向和艺术特色,是除色彩及图案外描述服装的一种重要的中层特征属性[1]。服装风格十分繁杂,大致可分为嘻皮、韩版、简约、前卫、欧美、民族、嘻哈、田园、朋克、OL、Lolita、街头、华丽、淑女、松散、严谨等18类。由于服装风格的主观性、发展速度等特点,使得服装风格分类和识别变得非常复杂。
所以本文研究向用户提供目标输入,通过图像处理[3]和机器学习[4]技术,以期建立服装图像和服装风格之间的映射关系[5],使机器对其进行数字图像处理,通过构建深度卷积神经网络,对数据集进行图片增强,得到更高的分类精度目标图像风格分析结果。
1 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是深度学习中应用最广泛的网络之一,它最早由Yann LeCun[6]提出,并成功应用于手写数字的识别。卷积神经网络也是模仿人类大脑的特点,通过构造多层神经网络,每层神经元的输出作为下一层神经元的输入,学习最适合任务的特征组合,具有强鲁棒性。卷积神经网络主要有3个特性:权值共享、局部感受野和池化操作。这些特性有效地降低了网络的复杂度且减少了参数的数量。权值共享即卷积核上的参数对图像的任意区域保持不变,如果训练的一个卷积核在当前窗口提取图片的颜色特征,则该卷积核滑动到其他窗口时也是提取图片窗口的颜色特征。不同卷积核的参数不同,从而实现对原始图片的不同特征提取,获取的特征图作为下一层卷积的输入。局部感受野指卷积核只与图片局部卷积,因为图像上相连像素关系紧密,而距离较远的像素点之间相关性弱。池化操作增强了卷积神经网络对图像平移、翻转等位置变化的不变性,同时减少了模型的计算量。经过一次池化操作,特征图片的尺寸将缩小,提高了模型的计算效率。通常,一个完整的卷积神经网络模型包含卷积层、池化层、全连接层和分类器,适用于语音、特别是图像数据的处理。卷积神经网络模型可以直接输入图片,不再需要人为的定义特征作为输入,这相比传统的模式识别方法具有很大的优势。一方面传统的特征提取需要人为参与,具有较大主观性,一些利于图像识别任务的潜在的特征可能未被定义,精度难以提升。另一方面,由于数据量的急剧增加,传统的机器学习方法性能提升遇到瓶颈,而深度学习是数据驱动的方法,海量数据能够使深度学习模型充分地学习数据中的隐藏特征,并随着数据的更新而更新。
1.1 卷积层
卷积层是卷积神经网络最重要的结构,具有局部感受野特性,可以减少大量的权值计算。假设输入图像为5×5大小,使用的卷积核大小为3×3,滑动步长为1,则通过卷积之后输出图像的大小为3×3,该图像也称为特征图(图1)。
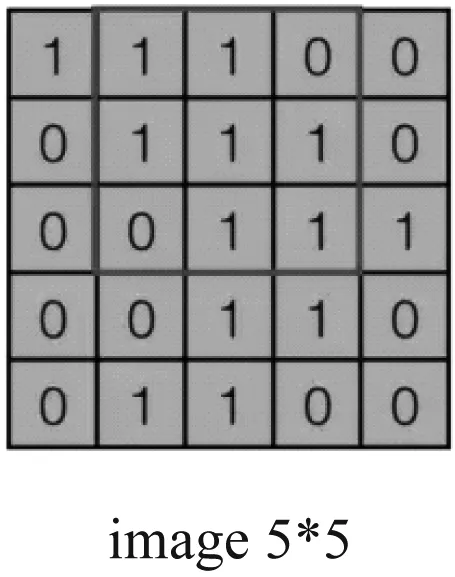
这样会造成输入与输出的尺寸不一致,为了实现更深层的复杂卷积神经网络模型构建,需要保证特征图尺寸缩小不能过快,这就是使用填充值(padding)的原因。Valid卷积和Same卷积是常用的两种卷积类型,Valid卷积指不使用填充,而Same指使用填充来保证输出特征图尺寸与输入特征图尺寸相同。步长(stride)也是卷积操作需要设置的一个参数,表示卷积核在特征图上每次卷积移动的像素个数。卷积层的输入与输出尺寸可通过式(1)计算,
(1)
其中,w与h指特征图的宽和高,k为卷积核尺寸,p为填充的像素个数,s为卷积核滑动步长。以图1为例,卷积层的具体计算式为:
(2)
式中,ai,j为输出特征图中第i行第j列的特征值,wm,n为卷积核第m行第n列的权值,b为偏置值,f为激活函数。
一个卷积核对图像卷积后得到一张新的特征图,若有多个卷积核,则在卷积后会得到多张特征图。
1.2 池化层
池化层在卷积神经网络结构中的主要作用是对特征图的降采样。在图像分类任务中,模型无需学习目标对象的位置,但是必须保证物体所处的位置对模型最终的识别结果没有影响。池化层的特点就是能保证平移和旋转等变换的不变性,增强模型的鲁棒性。同时,池化的降采样过程使特征图尺寸缩小,减少了模型的计算量,但却能较好保持高分辨率特征。通常,卷积神经网络模型中的池化层级联在卷积层后,常用的池化类型有均值池化(Average pooling)和最大池化(Max pooling)。均值池化指对池化所在窗口上特征图的所有值取平均,最大池化即取池化窗口所在区域特征值的最大值作为下一层特征图特征值。
1.3 全连接层
全连接层在模型的最后部分充当分类器的作用,将卷积层与池化层学习的特征拉伸为一列特征向量,经过多层全连接层后使用激活函数输出得到每个类别的概率。Softmax[7]是多分类任务中常用的激活函数,假设有m个训练集样本{((x(1),y(1)),…,(x(m),y(m)))},标签y(i)∈{1,2,3,…,k}共k类,输入样本x对应输出类别为j的概率为式(3)。
(3)
可见在输入样本x条件下预测x的类别为1至k的概率之和为1。
本研究的目标是将图像输入网络模型中,模型就可以对图像进行一系列操作,将图像特征提取出来,这样就可以提取得到图像的特征,抽象出每种服装风格对应的属性,这样就可以将服装风格和属性特征一一对应,将每种风格进行了分类。
1.4 激活函数
针对复杂图像特征线性不可分的问题,需要在卷积神经网络结构中加入非线性因素。引入激活函数,可以增加网络非线性表征能力,更好地解决复杂问题。激活函数一般连接在卷积层后对特征值进行非线性映射,常见的激活函数有Sigmoid[8]、Relu[9]、tanh[10]和PRelu[11]函数。
Sigmoid函数值域范围为(0,1),tanh值域范围为(-1,1),其表达式分别为式(4)、式(5)。
(4)
(5)
由于函数Sigmoid和tanh的饱和性,使得在输入绝对值较大时,容易发生梯度消失现象,导致网络训练困难。Relu激活函数的提出,有效地解决了上述两种激活函数的问题,其定义为式(6)。

(6)
Relu激活函数在输入为负值时的激活值为0,这在一定程度上增加了网络的稀疏性,从而加速了训练。PRelu激活函数是对Relu激活函数的改进版本,区别在于当输入值为负值时,激活值不再是0,其表达式如式(7):
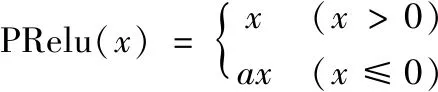
(7)
其中,a初始值一般设置为0.25,可通过训练学习调整。近年来,卷积神经网络中使用Relu激活函数较多,也有研究考虑使用PRelu激活函数,而使用Sigmoid和tanh激活函数较少。
2 数据收集与处理
2.1 数据收集
使神经网络学习获得高准确率的一个重要措施就是增加数据集的容量,给网络输入足够大的数据量,网络才可以获得更高的学习率。因此,本研究采用2种方式来增加文中数据集,利用爬虫从网络爬取了20 000+的图片作为文中所需数据集。
2.2 数据处理
(1)对数据集进行人工标注
从网络上面爬取的图片存在很大的误差,需要人工去除其中错误的分类。因此,根据每种服装风格的特点,对爬取的数据集进行人工筛选,得到正确的分类。正确分类前后效果如图2所示。
图2 分类前后对比图
(2)完善及扩充数据集
本研究的研究对象是服装,具有高可变性,从不同的角度也会得到不同的属性特点,因此,为了减少模型学习过程中的错误,对同一张图片进行了多种处理,用Photoshop对图片进行反转,改变像素大小等方式,一张图片就可以得到多个数据集。最终得到了100 000+图片,形成输入数据集。
3 服装风格识别
3.1 AlexNet方法
2012年举办的ImagNet图像识别竞赛上,Alex Krizhevsky设计的AlexNet卷积网络模型实现了57.1%的top-1准确率和80.2%的top-5准确率。相比于当时的传统机器学习算法,其性能具有极大的提升。
AlexNet结构图如图3所示,其输入原始图片的大小为256×256的彩色三通道图像,输入层通过随机裁剪获取大小为227×227的增广数据集。模型由8个卷积层、3个池化层以及3层全连接层构成,随着层次的增加,特征图尺寸逐渐缩小,但特征图数目逐渐增加。全连接层的神经元个数为4 096,对应的值是原始图片通过卷积和池化得到的特征向量,最后送至Softmax分类器中实现对18类服装风格的识别。该结构采用Relu激活函数,避免了梯度消失的问题从而使网络收敛更快。针对网络可能出现过拟合的问题,本研究提出使用数据增广、权值衰减以及dropout[6]的正则化方法,来增加模型的泛化能力。
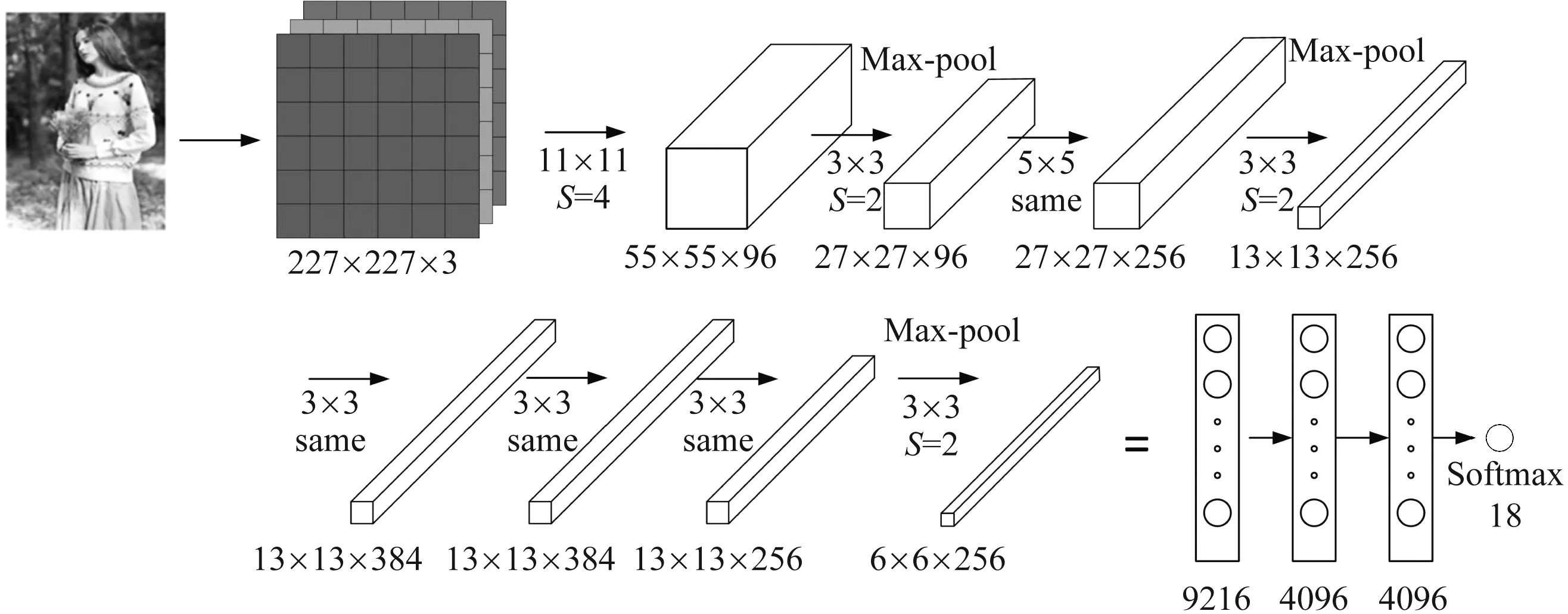
图3 AlexNet结构图
3.2 改进方法及实验结果
本研究将AlexNet的各模块进行耦合,形成一个完整的网络。该方法可以对输入图片进行像素格式化,按照227×227的格式输入到模型,然后对每一幅图像进行卷积池化等一系列操作,通过损失函数,优化算法,定义网络模型精度,用测试集对参数进行修改等操作,提高训练参数的准确度。
为了简化测试环节,本研究前期用两类数据集进行训练,用了25 000训练集,5 000测试集,在电脑上面迭代5次,运行了5个小时,准确率可以达到40%,如图4所示。
图4 AlexNet运行
将本研究中的方法用于服装风格中的百搭和淑女两个类别进行测试,针对25 000训练集,5 000测试集,迭代10次,运行了18个小时,准确率可以达到75%,图5为采用本研究方法处理结果的一组效果图。
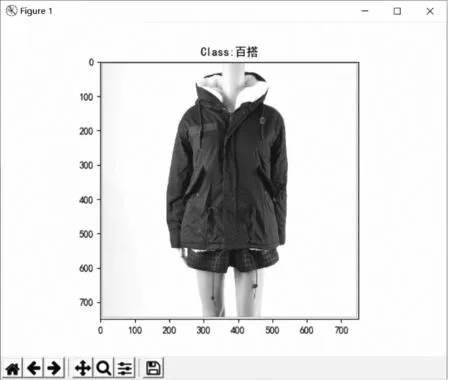
图5 训练模型对输入图像的预测
输入未加标签时图6给出的图像,让模型对图像进行分析,并将它转化为数据化表示,然后根据训练学习的数据和它进行比对,最后将它放入一个归类。这些图片是已经打上标签的,对于预测结果和标签结果相同的标签正常显示,预测结果和标签结果不一致的标签用红色显示,结果如图6所示。

图6 训练模型对测试集的预测
4 总结
本研究针对服装风格识别这一重要领域,用图像增广技术对图像进行扩展来增加训练集的数据量,采用AlexNet卷积神经网络进行建模,采用分类精度更高的深度学习网络,具有较高的可用性,但是服装风格复杂多样,对于实际生活中的服装风格精确识别还需更进一步的深入研究。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
趣味(作文与阅读)(2021年9期)2022-01-19 01:25:56
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
计算机技术与发展(2019年1期)2019-01-21 00:56:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
米娜·女性大世界(2016年9期)2016-12-02 19:05:42
股市动态分析(2015年20期)2015-09-10 20:40:44
