
应用量子粒子群算法优化神经网络的数据库重复记录检测
2022-02-21 23:58:56徐亮
微型电脑应用 2022年1期
徐亮
(解放军庐山康复疗养中心,信息科,江西,九江 332000)
0 引言
随着信息处理技术的不断发展,每天会产生大量的数据,为了对数据进行有效管理,各单位都建立了相应的数据库管理系统。随着数据管理系统使用时间不断的增加,数据库中存在大量的重复记录,这些重复记录不仅影响数据库运行效率,同时会占用太多的存储空间,使得数据库运行成本提高[1-3]。对数据库重复记录进行检测,适当删除一部分重复记录,不仅可以节约一定的存储空间,提高存储空间利用率,而且可以改善数据库数据检索速度,因此数据库重复记录检测研究具有一定的理论意义,同时具有一定的实际应用价值[4-6]。
近十多年来,一些学者对数据库重复记录检测问题进行了深入研究,提出了许多行之有效的数据库重复记录检测方法[7]。当前最常用的数据库重复记录检测方法为决策树算法和人工神经网络算法。决策树算法主要针对小规模数据库重复记录检测问题,无法适应数据库发展要求[8-9]。人工神经网络算法逼近问题解的精度高,不仅可以拟合数据库重复记录之间的关系,而且数据库重复记录检测速度要快于决策树算法,成为当前数据库重复记录检测的主要工具,其中BP神经网络的应用范围更加广泛[10-12]。在BP神经网络的数据库重复记录检测过程中,连接权值和阈值的初值对数据库重复记录检测效果具有重要影响,最初人们采用经验方法确定连接权值和阈值的初值,使得BP神经网络的迭代次数多,数据库重复记录检测时间长,对于大规模连数据库,无法在有效时间内得到数据库重复记录检结果,随后有学者引入遗传算法优化连接权值和阈值的初值,但是遗传算法自身存在收敛速度慢的缺限,到了进化后期,停滞不前,无法获得全局最优的连接权值和阈值的初值,影响了BP神经网络学习性能,使得数据库重复记录检测不理想。
为了提高数据库重复记录检测效果,针对当前BP神经网络的参数优化问题,提出了量子粒子群算法优化神经网络的数据库重复记录检测方法(QPSO-BPNN),采用量子粒子群算法对神经网络的连接权值和阈值的初值进行优化,建立全局最优的数据库重复记录检测模型,并提高数据库重复记录检测效率。
1 QPSO-BPNN的数据库重复记录检测方法
1.1 提取数据库重复记录检测特征向量机
在数据库存在大量的记录,每一个记录包括多个字段,当字段之间数据的相似度超过一定的值,那么认为这些记录是重复记录,不然就认为不是重复记录,因此首先提取数据库重复记录检测特征向量,本文采用数据库记录字段相似度量作为特征向量,设数据库记录2个字段分别为y1和y2,采用Jaro算法[13]计算2个字段的相似度值,具体为式(1),
(1)
式中,d表示字段匹配字符数,t表示字段不匹配字符数。
设2条记录共有Z个字段,fi表示2条记录的第i个字段相似度值,所有字段的相似度值组成特征量式(2),
F=(f1,f2,…,fi,…,fz}
(2)
1.2 BP神经网络
BP神经网络输入层第k个样本的输入以及其期望输出可以表示为式(3)、式(4)。
x(k)=(x(k)1,x2(k),…,xn(k))
(3)
do(k)=(d1(k),d2(k),…,dm(k))
(4)
根据输入层的输入,基于隐含层的神经元节点连接权值wih和映射函数f(·),可以得到隐含层神经元节点输入和输出计算式分别为式(5)和式(6),
(5)
hoh(k)=f(hik(k)),h=1,2,…,p
(6)
式中,p表示隐含层的神经元节点数,bh表示隐含层的神经元节点阈值。
根据隐含层的神经元节点输出,以及输出层的神经元节点的连接权值who和映射函数g(·),输出层的神经元节点的输入和输出计算式具体为式(7)和式(8),
(7)
yoo(k)=g(yio(k)),o=1,2,…,m
(8)
式中,m表示输出层的神经元节点数,bo表示隐含层的神经元节点阈值。
计算输出层的神经元节点的输出和期望输出之间的误差具体为式(9),
(9)
式中,q表示训练数量。
计算输出层和隐含层的偏导数,它们分别为δo(k)和δh(k),根据δo(k)和δh(k)计算wih和who的增量,计算式为式(10)和式(11),
(10)
(11)
根据Δwho(k)和Δwih(k)对连接权值who和wih进行更新操作,即式(12)和式(13)。
wih(k)=wih(k)+Δwih(k)
(12)
who(k)=who(k)+Δwho(k)
(13)
不断重复上述过程,当输出层误差小于预设值,那么BP神经网络学习过程终止。
由于bh、wih和bo、who的初值直接影响BP神经网络学习性能,为此本文采用量子粒子群算法优化bh、wih和bo、who的初值。
1.3 量子粒子群算法
量子粒子群算法是一种基于量子力学理论的人工智能算法,具有较快的收敛能力,可以大概率找到全局最优解,粒子最优位置为mbest,具体为式(14),
(14)
式中,d表示粒子的维数。
第i个粒子的当前位置为式(15),
(15)
式中,rid表示量子系统的第i个基态,uid表示一个随机数,Kid的计算式为式(16),
Kid(t}=2β(t}|mbestid(t}-xid(t}|
(16)
式中,β表示收缩-扩张系数。
粒子位置更新方式用式(17),
(17)
1.4 QPSO-BPNN的数据库重复记录检测步骤
Step1:收集数据库记录,并提取数据库重复记录检测特征向量,并对数据库重复记录进行相应的标记。
Step2:建立数据库重复记录检测样本集合,其中选择50%样本组成数据库重复记录检测训练样本集合,其他50%样本组成数据库重复记录检测的测试样本集合。
Step3:初始化量子粒子群,每一个粒子位置向量与一组连接权值和阈值的初始值相对应。
Step4:BP神经网络根据连接权值和阈值的初始值对数据库重复记录检测训练样本集合进行训练,并计算每一个粒子的适应度函数值,本文选择数据库重复记录检测准确度作为适应度函数。
Step5:确定每一个粒子的当前最优位置和量子粒子群的最优位置。
Step6:对粒子位置进行更新。
Step7:量子粒子群的迭代次数增加,如果迭代次数达到最大迭代次数或者BP神经网络输出误差小于预设值,那么此时得到了BP神经网络最优的连接权值和阈值的初始值。
Step8:BP神经网络采用最优的连接权值和阈值初始值对数据库重复记录检测的训练样本进行重新学习,建立最优的对数据库重复记录检测模型。
Step9:采用训练样本集合对数据库重复记录检测模型的性能进行验证测试,并输出数据库重复记录检测结果。
2 仿真实验
2.1 实验平台
为了测试量子粒子群算法优化神经网络的数据库重复记录检测方法(QPSO-BPNN)的有效性和优越性,选择当前经典数据库重复记录检测方法进行对比实验,具体为遗传算法优化神经网络的数据库重复记录检测方法(GA-BPNN)、经验法确定神经网络参数的数据库重复记录检测方法(BPNN),选择数据库重复记录检测准确率、召回率以及平均检测时间对结果进行衡量,其中准确率、召回率定义分别为式(18)和式(19),
(18)
(19)
式中,A表示检测重复记录正确的数量,B表示检测到的重复记录数;Total表示重复记录总数。
3种方法仿真测试平台是一致的,具体如表1所示。

表1 数据库重复记录检测的仿真测试平台
2.2 数据库重复记录检测的样本数据
选择不同规模的数据库重复记录检测的样本数据作为实验对象,具体如表2所示。
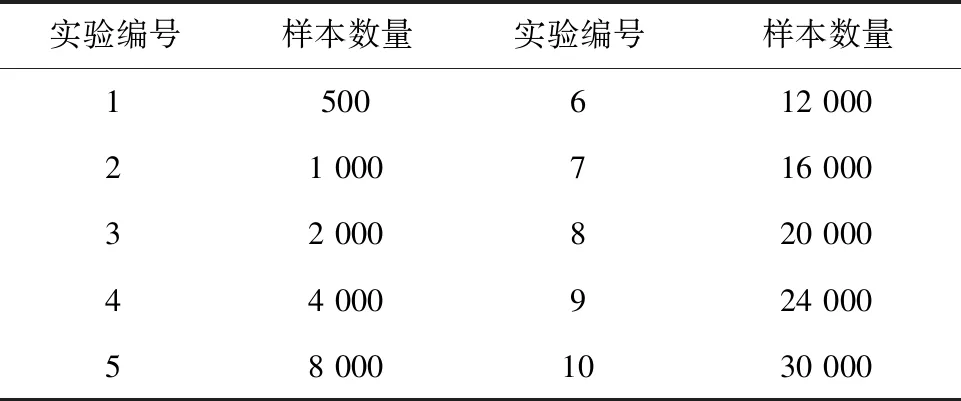
表2 数据库重复记录检测的实验数据
2.3 数据库重复记录检测结果分析
统计3种方法的数据库重复记录检测准确率和召回率,结果如图1和图2所示。从图1和图2的数据库重复记录检测准确率和召回率进行对比和分析可以发现,QPSO-BPNN的数据库重复记录检测准确率和召回率平均值分别为91.06%和94.23%,GA-BPNN的数据库重复记录检测准确率和召回率均值分别为88.14%和89.73%,BPNN的数据库重复记录检测准确率和召回率均值分别为86.15%和84.47%。相对于对比方法,QPSO-BPNN的数据库重复记录检测效果得到了明显的提升,减少了数据库重复记录检测错误率,数据库重复记录拒检测率也得到了下降,获得了更加理想的数据库重复记录检测结果。
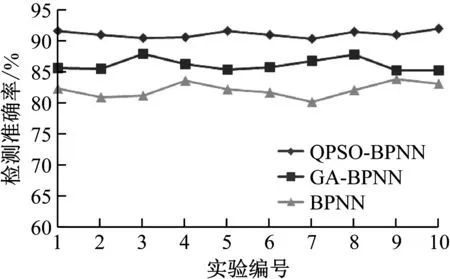
图1 不同方法的数据库重复记录检测准确率
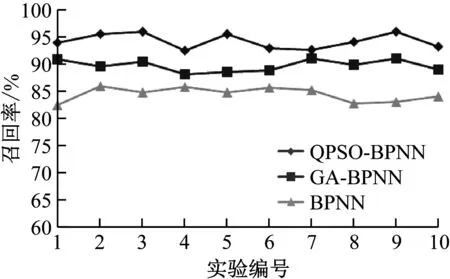
图2 不同方法的数据库重复记录检测召回率
2.4 数据库重复记录检测效率分析
统计不同方法的数据库重复记录检测时间,具体结果如表3所示。对表3的数据库重复记录检测时间进行分析可以发现,QPSO-BPNN的数据库重复记录检测时间最少,GA-BPNN的数据库重复记录检测时间次之,BPNN的数据库重复记录检测时间最长。这表明连接权值和阈值的初值能够对BP神经网络的学习过程产生直接影响,BPNN采用经验方法确定连接权值和阈值的初值,使得BP神经网络的学习过程迭代次数增多,而QPSO算法对权值和阈值的初值进行优化后,可以减少BP神经网络的学习过程迭代次数,提升了数据库重复记录检测效率,能够满足数据库重复记录向大规模方向发展的要求。
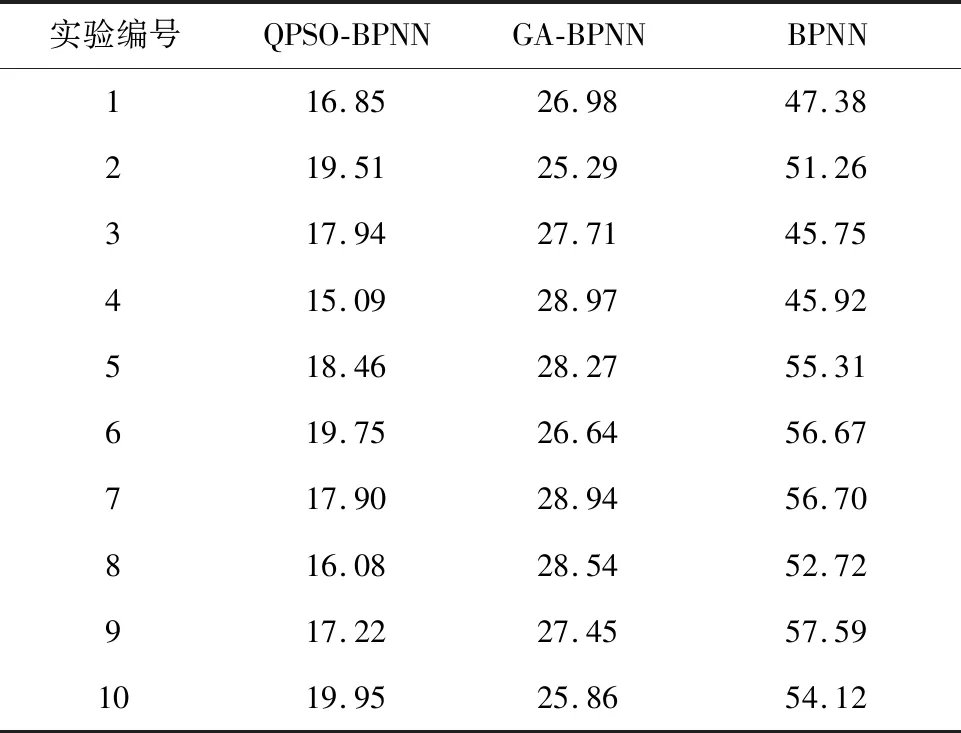
表3 不同方法的数据库重复记录检测时间
3 总结
重复记录直接影响数据库检索效率,同时浪费了存储空间,为了节约数据库的存储空间,加快数据库检索速度,满足数据库向大规模发展方向的要求,针对当前BP神经网络在数据库重复记录检测过程中存在的问题,提高了量子粒子群算法优化神经网络的数据库重复记录检测方法,仿真测试结果表明,本文设计方法可以改善数据库重复记录检测效果,克服了当前数据库重复记录检测方法存在的局限性,提升了数据库重复记录检测效率,为大规模数据库重复记录检测提供了一种新的研究方向。
猜你喜欢
青少年科技博览(中学版)(2023年3期)2023-05-11 07:36:58
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
小学科学(学生版)(2020年1期)2020-01-19 06:02:08
制造技术与机床(2019年9期)2019-09-10 07:36:54
科学大众(中学)(2019年2期)2019-04-08 02:26:40
西南交通大学学报(2018年6期)2018-12-18 02:22:28
河北遥感(2017年2期)2017-08-07 14:49:00
自动化学报(2017年7期)2017-04-18 13:41:02
西安工程大学学报(2016年6期)2017-01-15 14:08:28
