
中文文本中的个人信息自动化检测框架研究
2022-02-19 10:24贾昊阳盛毅敏阮雯强韩伟力
计算机应用与软件 2022年2期
贾昊阳 盛毅敏 阮雯强 韩伟力
(复旦大学软件学院 上海 201203)
0 引 言
大数据技术的发展伴随着隐私问题的产生。随着数据存储和数据处理技术的不断发展,越来越多互联网用户的隐私信息被收集并用于商业服务或者科学研究[1-2]。由于隐私信息的泄露可能会造成诈骗、人身攻击、歧视等多种危害[3],因此对此类数据的处理过程受到了严格的法律法规约束。近几年,不同国家和组织相继出台了一系列大数据环境下隐私数据保护的法律法规,如欧盟在2018年5月实施的《通用数据保护条例》(General Data Protection Regulation, GDPR)[4]。中国自2016年起相继颁布和实施了《网络安全法》和《信息安全技术:个人信息安全规范》,并在2019年公布了《个人信息保护法》的专家建议稿。这些法律法规通过严格规范数据持有者收集、应用、存储和转移数据的过程来保障个人信息主体的权益以及隐私信息的安全。
隐私保护法律的实施为数据持有者带来了法律风险。例如,2019年美国监管机构因Facebook涉嫌与第三方组织共享用户数据而对其罚款50亿美元;英国航空公司因为被黑客组织攻击泄露客户数据而受到约2.3亿美元的罚款。为了规避或减少此类风险的产生,数据持有者有必要确定他们的数据集中是否存在个人信息,存在何种类别与量级的个人信息,从而制定有效的数据保护措施。
然而,当前尚缺有效工具支持检测中文数据集中的个人信息。特别是对于文本数据而言,由于其内容复杂,信息量大,具有很高的不确定性。同时由于个人信息的种类繁多,格式各不相同,因此虽然针对某一类个人信息的识别算法易于实现,但缺少一个统一的框架以支持从文本中检测多种类别的个人信息。
为了解决上述问题,本文设计并实现了一个个人信息的自动化检测框架。首先,本文参考国内外法律关于个人信息的定义,明确了13种个人信息的具体类别,即框架需要在文本中检测的目标数据。然后,本文结合模式匹配与自然语言处理技术设计并实现了一个高效的个人信息自动化检测框架。除此之外,为了解决家庭住址格式复杂、识别困难的问题,本文提出一种新的家庭住址检测方法。
1 相关工作
在工业界领域,Google提供了一种名为Cloud Data Loss Prevention (Cloud DLP)的隐私信息检测工具[5]。该工具支持从数据中检测117种个人信息及敏感信息,其中包含31个国家的公民身份识别信息。然而,对于识别中文数据里的个人信息,Cloud DLP存在以下两个问题:(1) 不支持检测中国公民的电话号码、生日、家庭住址等常见类别的个人信息;(2) 只支持访问服务端API,对每分钟请求数的上限(600次)和单次请求规模上限(0.5 MB)存在严格约束,这导致在检测大规模数据集时性能受到影响。
在科研领域,对个人信息的检测研究集中在医疗数据安全。医疗数据如病历中包含大量病人的基本信息和健康信息,这些数据虽然存在很大的研究价值,却因为涉及十分敏感的个人隐私而被约束使用。为了促进医疗研究进步,保障医疗数据的安全共享,美国的HIPAA法案组织定义了“受保护健康信息”(Protected Health Information,PHI)[6],并规定在对这类数据进行收集和处理时需要严格遵守法案规定。为了在格式多样化的医疗数据集中进行PHI的检测,研究者们主要应用了以下几种方法:
(1) 模式匹配。利用正则表达式、词典匹配、句法结构等来提取信息[7-8]。这种方法易于实现,可以得到比较高的准确率和召回率,但是它需要随着时间不断更新规则和词典的内容来满足新的数据格式要求。除此之外,模式匹配会忽略上下文的作用,因此可能存在误报(满足格式但不满足语义)和漏报(匹配规则不够完备)的情况。
(2) 机器学习。传统机器学习方法,如支持向量机(SVM)[9]、条件随机场(CRF)[10]等模型通过从数据中提取特征进行训练来决定一个字段是否是PHI。这些特征包含字段的大小写,是否出现在预定义的词典中,在文本中的位置等。这种方法的效果受到特征完备性的影响,因此需要大量工作来确定使用的特征类别。深度学习,如循环神经网络(RNN)则从标注的数据集中自动提取特征[11-12]。这些方法利用“词向量”的概念,将数据中的单词映射成空间中的向量,从而提取一些人工不一定能识别的特征。以上提到的机器学习算法存在一个共有的问题是,它们的训练基于小规模的医疗标记数据完成,用于完成指定格式的医疗数据检测任务,因此不适用于在格式复杂、内容多样的自然文本中识别个人信息。
2 个人信息类别
本节通过比较国内外法律法规中对于个人信息的定义,确定待检测的个人信息具体类别。在本节参考的法律法规有中国的《网络安全法》《信息安全技术:个人信息安全规范》,欧盟的《GDPR》,以及美国国家标准与技术研究所NIST提供的指导标准《SP 800-122》[13]和上文提到的HIPAA法案。
国内外的法律法规在定义个人信息时存在两种不同方式:一种用抽象的描述,将任何用来识别个人身份的信息都定义为个人信息(如《GDPR》);另一种则是用精确的枚举,将可能是个人信息的类别用列表展示 (如《SP 800-122》)。前者更为严苛,因为它们的范围十分广泛,任何与人相关的数据,包括兴趣爱好等都可能被视为个人信息。而后者更方便数据持有者们通过某些措施以达到遵守法律规定的目的,只需要将法律中明确枚举的个人信息类别加以保护,就能减少违反法律的风险。
本文主要参考第二种形式的法律规定确定个人信息类别。这些法律法规提供了个人信息的详细列表,包括《信息安全技术:个人信息安全规范》中的“个人信息示例”,《SP 800-122》定义的 “个人可识别信息”和HIPAA法案定义的“受保护健康信息”。以上三个列表在枚举个人信息时都存在特有类别,例如“个人信息示例”中的性别、民族、国籍等;“受保护健康信息”中的医疗记录编号、健康保险受益人编号,以及统一资源定位符;“个人可识别信息”中的出生地、昵称。本文取这三个列表的交集,将其视为最基本的个人信息类别。除掉不存在于文本中的基于图像或基因序列的生物识别信息,最终得到以下13类个人信息作为检测目标:姓名、生日、家庭住址、电话号码(包括手机和固定电话)、电子邮箱、身份证号码、驾驶证号码(等同于身份证号码)、护照号码、IP地址、银行卡号(包括信用卡和借记卡)、车牌号。这些信息能够直接或间接识别到个体,并且在国内外的法律中均被强调。对于像性别、民族、国籍这类的个人信息,由于其具有相同属性的群体数量较为庞大,可识别性低,因此不将其纳入检测范围。
3 个人信息检测框架
本节将介绍个人信息的检测框架。框架包括数据预处理、个人信息识别、以及数据可视化三个模块,同时框架提供知识库和算法库,用于支持个人信息识别模块的执行。并且,本节将对个人信息识别流程进行详细介绍,展开说明家庭住址的识别算法。
3.1 整体框架
个人信息的检测框架如图1所示。该框架的输入是包含文本数据的文件,输出是经过可视化的检测报告文件,报告中包含:个人信息所在文本、定位、各类型个人信息数量等。框架共分为以下三个模块:
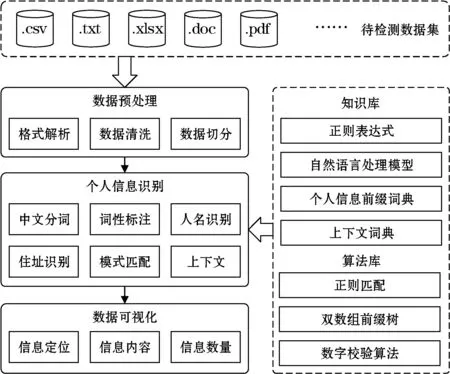
图1 个人信息检测框架介绍
(1) 数据预处理。预处理用于统一输入数据的格式,对于pdf、xlsx等文件类型,应用特殊的格式解析工具提取文本。解析得到的文本数据将通过数据清洗步骤过滤非法表情字符、替换繁体字为简体字,全角字符为半角字符,提高格式统一性,降低脏数据对检测的影响。数据切分则将文本划成独立分区,以便应用于多线程检测。
(2) 个人信息识别。该模块应用自然语言处理模型检测人名与住址,应用模式匹配算法识别由数字、字母和符号构成的其他个人信息。该模块同时提供个人信息的上下文词典对识别结果进行筛选,从而提高检测精确性。自然语言处理模型包括中文分词、词性标注和命名实体识别,三者依照其顺序,下一阶段的输入依赖于上一阶段的输出;模式匹配算法包括正则匹配、词典匹配、数字校验。
(3) 数据可视化。可视化将格式化的检测结果以图文形式写入检测报告中。图片用于展示个人信息类别及其对应数量、隐私信息所占比例等统计数据。对于检测到个人信息的文本,可视化模块将会以形如“的电话是
在该框架中,知识库用于存储格式有限的个人信息的通用正则表达式、特定前缀词典(如身份证号的前缀表示行政区划代码)、上下文词典,以及自然语言处理模型。这些知识来源于预先制定的数据格式规则、收集的词典列表、以及训练的模型。算法库则基于知识库提供高效的算法来执行匹配流程,例如应用双数组前缀树完成前缀和上下文的词典匹配。
3.2 个人信息识别流程
检测首先执行模式匹配,在此基础上再执行中文分词、词性标注和命名实体识别。对于一段文本而言,首先应用模式匹配检测除人名和住址之外的11类个人信息,当且仅当检测结果不为空,或者文本中出现预定义的家庭住址上下文时,才会对当前文本执行中文分词、词性标注和命名实体识别这一系列流程。之所以判断检测结果是否为空,是考虑到一段文本中如果只出现人名这一种个人信息,其敏感性远低于人名和其他类型的个人信息一同出现,因此当文本只包含人名时,不将其涵盖在检测范围中;而优先进行住址上下文匹配,是因为上下文检测是住址识别的必要过程。应用上述检测流程的主要目的是减少需要执行人名和住址识别任务的文本数量,提升检测性能。
对于应用模式匹配的个人信息,其检测流程如算法1所示。算法首先基于预先定义的格式要求和数字校验对文本进行匹配,再结合前缀词典对可能是个人信息的对象做内容匹配。除此之外,算法1在模式匹配的基础上充分应用了上下文匹配。考虑到部分个人信息的格式容易误匹配其他类型的数据,因此利用上下文来过滤满足格式但不满足语义的匹配结果,减少误报。同时算法1将满足上下文但不匹配词典的个人信息前缀在词典中更新,以自动地对前缀词典进行维护,降低漏报的可能性。
算法1个人信息检测流程
输入:一段文本e;某类个人信息Pi包含的正则表达式ri,校验算法fi,词典di以及上下文词典ci;上下文取词窗口,默认为左右各取8。
输出:个人信息列表W。列表中的每一个元素包括个人信息的类别、内容、在文本中的位置。
1:W=∅
2: ifri.matches(e) then
3: for eachsi∈ri.find(e) do
4: iffi≠null andfi(si)=false then
5: continue
6: end if
7: ifdi,ci≠null andprefix(si)∉dithen
8:si.label=suspect
9: end if
10:W.add(si)
11: end for
12: end if
13: forwi∈Wdo
14:CW=context(wi,e,SIZE)
15: ifci≠null andCW∩ci=∅ then
16:W.remove(wi)
17: else ifCW∩ci≠∅ and
wi.label=suspectthen
18:di.record(wi)
19: end if
20: end for
21: returnW
不同的个人信息由于其格式特点,在检测过程中应用的匹配方法也不尽相同。例如,对邮箱的识别只需要正则匹配,而对银行卡号的识别则需要进行正则匹配、前缀匹配、Luhn校验和上下文匹配四个步骤。表1展示了11类个人信息的格式特点。所有的正则表达式均基于格式特征进行设计。表2中展示了需要应用前缀词典和上下文匹配的个人信息,并列举前缀词典的来源,上下文内容。在表2中,部分个人信息只需要在正则匹配的基础上,依赖词典或上下文匹配中的一种方法即可完成检测,例如护照识别不存在可以应用的有效词典,因此仅使用上下文完成匹配。
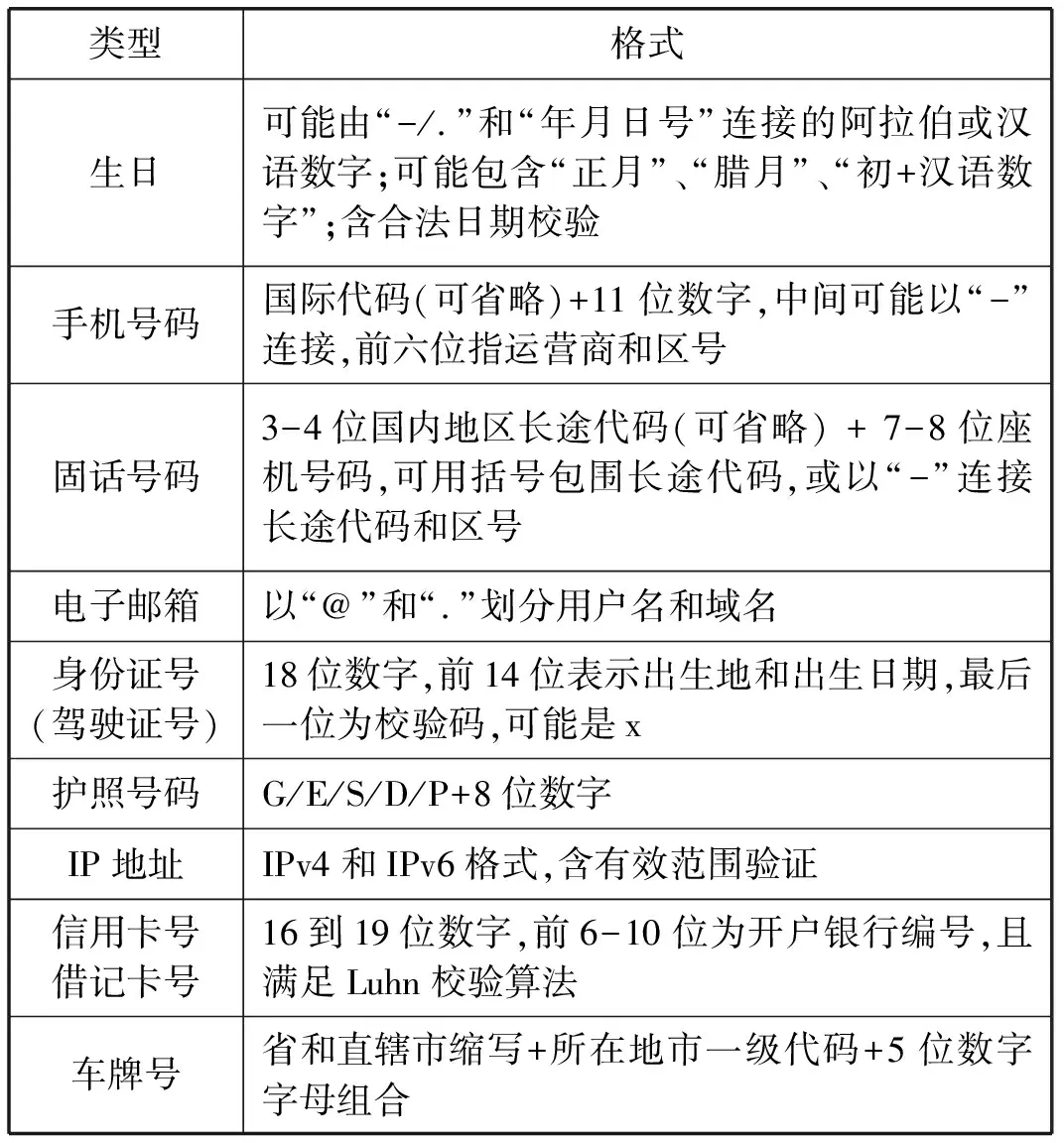
表1 个人信息格式特征
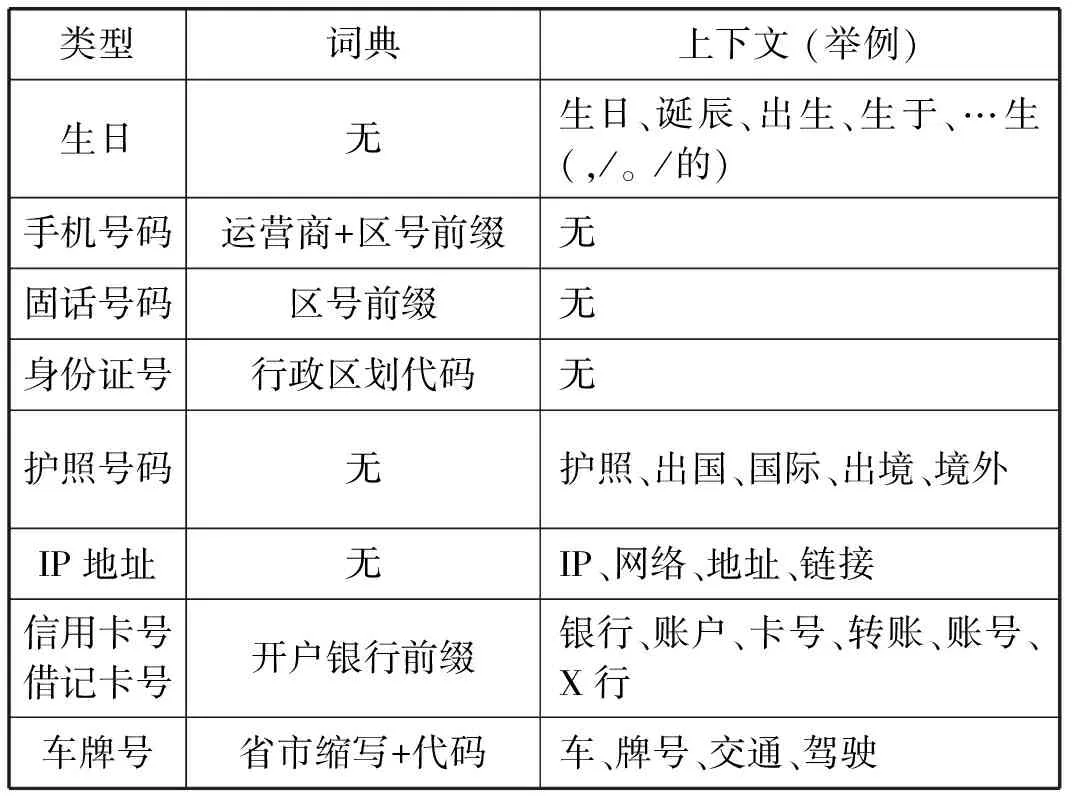
表2 个人信息检测的前缀词典及上下文
3.3 家庭住址识别算法
家庭住址不同于人名,后者可以通过现有的命名实体识别模型完成检测,而家庭住址存在格式多样、与语义关联性强的问题。本文针对家庭住址的格式特征训练了一个支持检测复杂地址的命名实体识别模型。对于家庭住址与语义关联性强的问题,则通过枚举上下文词典与规则对模型识别出的复杂地址进行过滤。
本文的命名实体识别模型利用开源自然语言处理工具集HanLP提供的感知机训练框架完成。该工具集基于结构化感知机[14]实现了一个同时完成中文分词、词性标注和命名实体识别三项任务的完整自然语言处理框架,并支持在线学习,增量更新模型参数。对于命名实体识别而言,中文分词与词性标注是前提。由于HanLP提供的感知机算法框架对于三项任务分别提供了模型训练、加载与存储的接口,因此本文仅对支持检测复杂格式地址的命名实体识别模型进行训练,而对于中文分词和词性标注任务则直接应用了HanLP在大规模中文语料库下预先训练好的模型。
对家庭住址上下文中可能出现的关键词语进行统计,并根据这些关键词与地址之间的关系对地址位置进行约束,得到表3。窗口大小用于约束目标地址在上下文中取字符的数量。在不限上下文的情况下,窗口大小为左右各取8。在这些关键词中,“+”用于表示关键词必须按顺序以组合形式出现,但不一定相连。“…”用于约束地址位置,不需要考虑上下文窗口大小。

表3 家庭住址上下文关键词列表
基于训练的感知机模型和预定义的上下文,对一段文本进行家庭住址识别的流程如算法2所示。算法2对命名实体识别模型的检测结果进行了过滤。首先筛选标记为“ns”即地址的实体;当且仅当其识别到的地址是组合词组(isCompound方法判断当前识别出的词是否为由多个字词组合而成的词组,例如“[上海市 人民大道 200 号]”是由四个字词组成的词组),且组合词组的元素组成数量大于等于3时,该地址为复杂地址。上下文取词方法会依据窗口大小将上下文按顺序排列,通过匹配上下文与词典,即可确定识别的复杂地址是否为家庭住址。对人名的识别则直接利用了命名实体识别模型的结果,当识别到标签为“nr”的item时,即识别到人名。
算法2家庭住址识别算法
输入:一段文本e;训练的感知机模型recognizer;家庭住址上文词典cpre及窗口大小PRE_SIZE,下文词典csuf及窗口大小SUF_SIZE,不限位置的词典c与窗口大小SIZE;上下文匹配规则r。
输出:文本中识别到的家庭住址列表W。
1:W=∅
2:ArrayitemList=recognizer.recognize(e)
3: for eachitemi∈itemListdo
4: ifitemi.label="ns"anditemi.isCompound(e)
anditemi.list.size≥3 then
5: ifr.matches(itemi,e) then
6:W.add(itemi)
7: continue
8: end if
9:PRECW=pre_context(itemi,e,PRE_SIZE)
10:SUFCW=suf_context(itemi,e,SUF_SIZE)
11:CW=context(itemi,e,SIZE)
12: ifPRE_CW∩cpre≠∅ orSUF_CW∩csuf≠∅
orCW∩c≠∅ then
13:W.add(itemi)
14: end if
15: end if
16: end for
17: returnW
4 检测效能分析
本节对个人信息检测框架的效能进行实验分析。首先介绍用于训练复杂地址识别模型的语料库的准备流程;接着基于用户发布的在线社交平台数据分析复杂地址检测的精确性;然后利用大规模的公开文本数据分析检测方法的时间开销;最后基于对实际数据的检测结果,对框架生成的报告进行展示说明。
4.1 训练数据准备
为生成包含复杂地址的语料库,具体流程如下:
(1) 收集新闻数据并自动标注。新闻抓取自新浪门户网站下的地方新闻,这些新闻记载国内不同地区的事件,地址信息丰富。新闻发表日期在2014年至2018年间,共收集2 198万字。利用上文提到的HanLP分词与词性标注模型对该数据集进行标注,标注格式满足2014年人民日报语料标注格式要求。
(2) 收集复杂地址并统计其格式。在由政府机构发布的开放数据集中收集具有复杂格式的公司或服务机构地址,这些地址包含市区、道路名、门牌号信息,部分包含更细粒度的楼层、室号。筛选具有明确位置信息的地址列表并对其进行分词和词性标注,统计地址格式。例如,“上海市黄浦区人民大道200号”在HanLP的词性标注模型下得到的结果为“上海市/ns黄浦区/ns 人民大道/ns 200/m 号/q”,其中“ns”为地名,“n”为名词,“m”为数量,“q”为量词;因此该地址的格式为“ns,ns,ns,m,q”。在已有的格式集中,将前缀重复的地名(“ns”)或机构名(“nt”)标签合并为一个,作为复杂地址开始标志。本文在上海市公共数据开放平台上获取有效地址35 387条,有效格式3 233条。
(3) 利用统计得到的格式集合对新闻数据集中的复杂地址进行自动化标注。对于一段已经完成词性标注的新闻,首先匹配地址的起始位置(即“ns”或“nt”),然后将与其连接的重复标签合并,再基于地址格式集进行最长模式匹配,将匹配到的字符串用“[]”包围,并在末尾添加“/ns”以表示这是一个复合地址。循环该操作直到文本的末尾。
(4) 人工修正误报数据。对标记过的复杂地址词组利用人工检验的方式对其中的误报地址进行修正,主要包括删除不是地址的词组;修改地址终止字符位置,以过滤将地址和下文信息一同标记为复杂地址的情况。
除了上述自定义语料库之外,同时用于训练的还有人民日报1998年1月份的开源语料库与微软命名实体识别语料库。后两者基于2014年人民日报语料格式进行了转换。新闻数据集的作用是辅助模型提取复杂地址的上下文特征,同时复杂地址的复合格式辅助统计复杂地址内部特征。而微软语料库和人民日报语料库则用于平衡语料中不同类型实体的数量。
4.2 复杂地址识别精确性
用于验证复杂地址识别精确性的数据来自头条新闻提供的在线寻人启事,这些寻人启事中包含大量走失者的籍贯和走失地信息。利用网络爬虫随机抓取2 000条寻人启事,并人工对其中的复杂地址进行了标注。标记复杂地址的依据是判断地址详情是否小于“村”或“区”的范围。将该数据作为验证集,并与检测框架得到的结果进行对比。利用准确率 (Precision)、召回率 (Recall)、F1值 (F1-score)三个指标对结果进行评估,得到表4。表4显示复杂地址的识别达到了较高的准确率。在该实验中,任何与标注数据不匹配的检测结果均被标记为误报和漏报,在这种要求下,即使命名实体识别模型检测到了标记地址的子串,也被归纳到识别错误的集合中。

表4 复杂地址在检测框架下的结果
为了证明家庭住址识别的有效性,本文在一个大规模的开源数据集THUCNews上进行了验证。THUCNews为清华大学提供的开源语料库,其中包含从新浪新闻上抓取的14个主题下的新闻报道。这份数据未经过人工标注,因此属于从互联网上公开的原数据。通过使用家庭住址识别检测算法,在该份语料库中识别出家庭住址共22条。人工对这22条信息进行验证,证明这些信息均为家庭住址,且源自新闻中对通缉或已抓捕的犯罪嫌疑人的信息曝光。对真实数据的检测结果验证了家庭住址识别方法的有效性。
4.3 检测效率
本节首先对检测方法的性能瓶颈进行分析,以说明人名和住址识别任务在检测框架中对性能的影响。针对正则匹配、字典匹配、中文分词、词性标注、命名实体识别任务分别进行压力测试。压力测试通过不断重复对同一个字符串的检测以保证对应任务一直处于执行状态。测试环境的软硬件信息如表5所示。

表5 性能测试环境软硬件信息
表6展示了这些任务在单线程下每秒钟处理的字符数量以及用于测试的字符串详情。其中,对词性标注、命名实体识别的速度计算不包含前驱任务的时间开销;输出字典匹配应用了双数组前缀树。表6显示,对于检测框架而言,对人名和家庭住址的识别成为了性能瓶颈。这是因为两者均需要完成中文分词、词性标注和命名实体识别三项任务。考虑到命名实体识别的完整流程应用到了前两者,因此对于人名和家庭住址而言,最优识别效率仅能达到8.2万字每秒。这解释了算法1中先完成模式匹配,后执行人名和住址识别的流程。
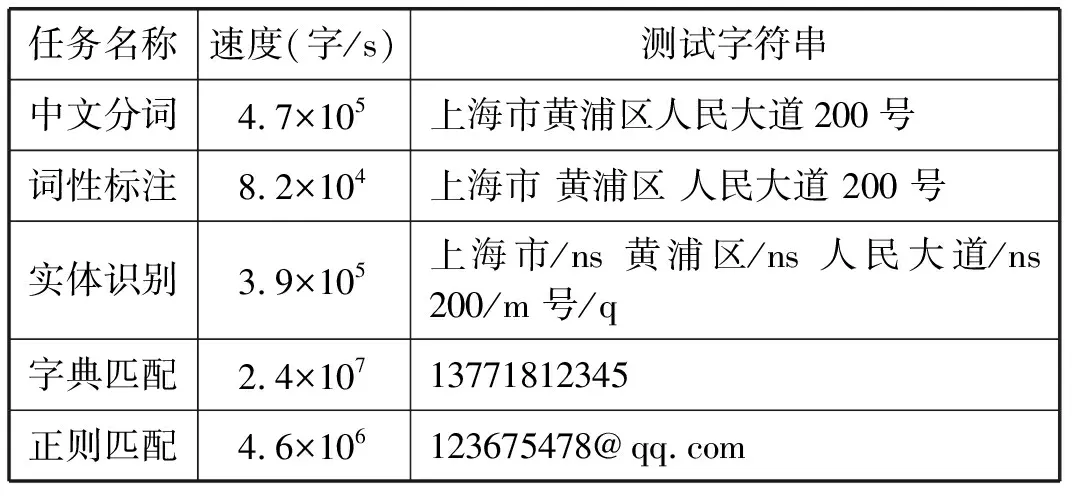
表6 不同任务压力测试结果及测试字符串详情
为了对检测框架的性能做完整分析,本文应用了上文提到的THUCNews数据集。该数据集中共分为14个主题,各主题下新闻数据集大小范围是8 MB到380 MB之间,且文本内容复杂多样。表7展示了其中5个不同大小数据集的平均检测流程耗时情况。该检测任务运行在多线程环境下,线程数量与内核的数量保持一致。表7中的运行时间不包含感知机模型初始化、生成可视化报告的时间,由于这部分任务在整个检测流程中只执行一次,因此不进行专门的性能评估。
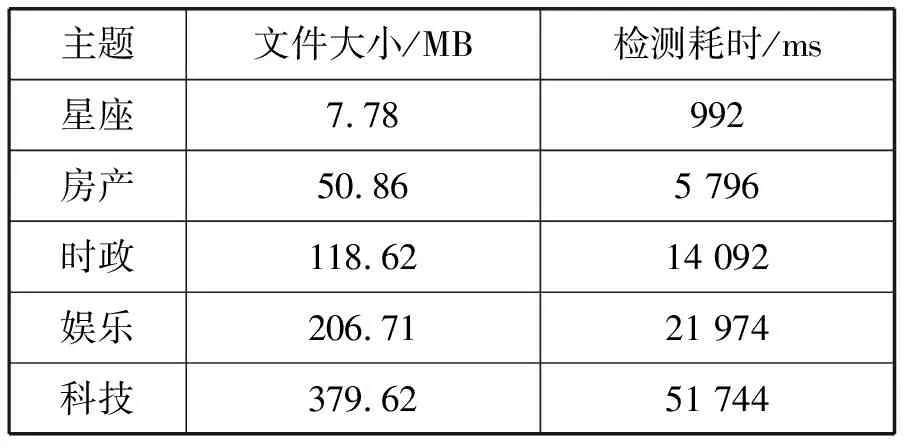
表7 THUCNews部分数据集详情及平均检测耗时
实验结果展示,个人信息检测框架在新闻数据集中达到较高的检测性能。与在文本中进行人名、地名和机构名标记的命名实体识别任务相比,个人信息识别的效率显著增高。
为说明算法1的优化效果,本文基于这14个数据集进行了一组对比实验。对照组为不经过检测结果过滤,直接对全文执行命名实体识别的检测流程。两组实验皆在多线程模式下完成,检测耗时随文件大小的变化如图2所示。图中的Alg1为算法1,NER为对照组方法。图2显示算法1的检测耗时随文件大小的变化趋势接近于线性增长。随着文件大小的变化,算法1的性能优化效果更为明显。利用计算提升倍数依据的公式:
可以得到对比在全文中执行命名实体识别任务,检测框架的平均性能提升11.18倍。对这14个文件进行多组实验下得到的平均检测耗时进行统计,得到检测框架在多线程环境下的平均处理效率为每秒8.26 MB。
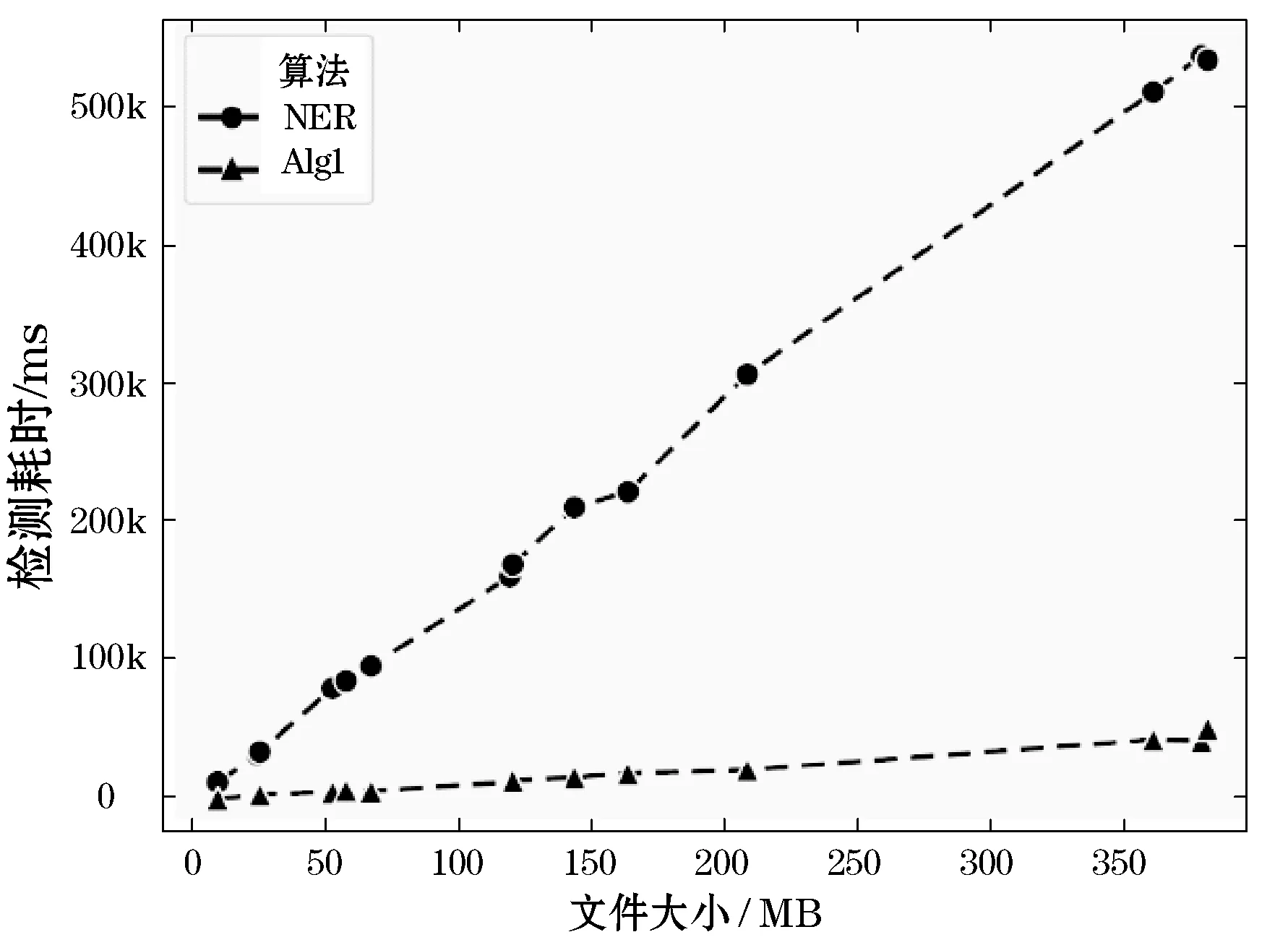
图2 算法1与对照组检测耗时随文件大小的变化
4.4 案例分析
本文从在线社交平台天涯论坛上抓取了约5 000条用户发布的帖子,涉及版面为“百姓声音”(日期范围20191016-20191205)和“公益同行”(日期范围20190625-20191203),大小为10 MB。利用本文设计并实现的框架对数据集进行检测,生成的检测报告可视化示例如图3、图4所示。为保护信息主体的隐私,在截图中不对具体的文本数据进行展示。
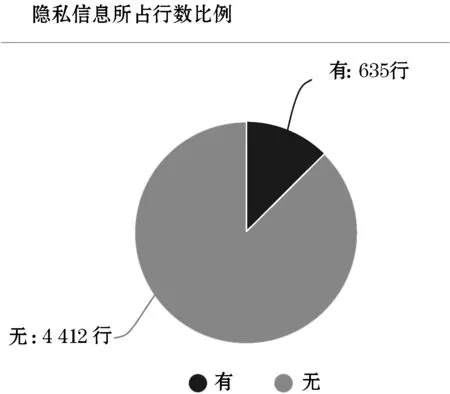
图3 报告示例:隐私信息所占行数比例
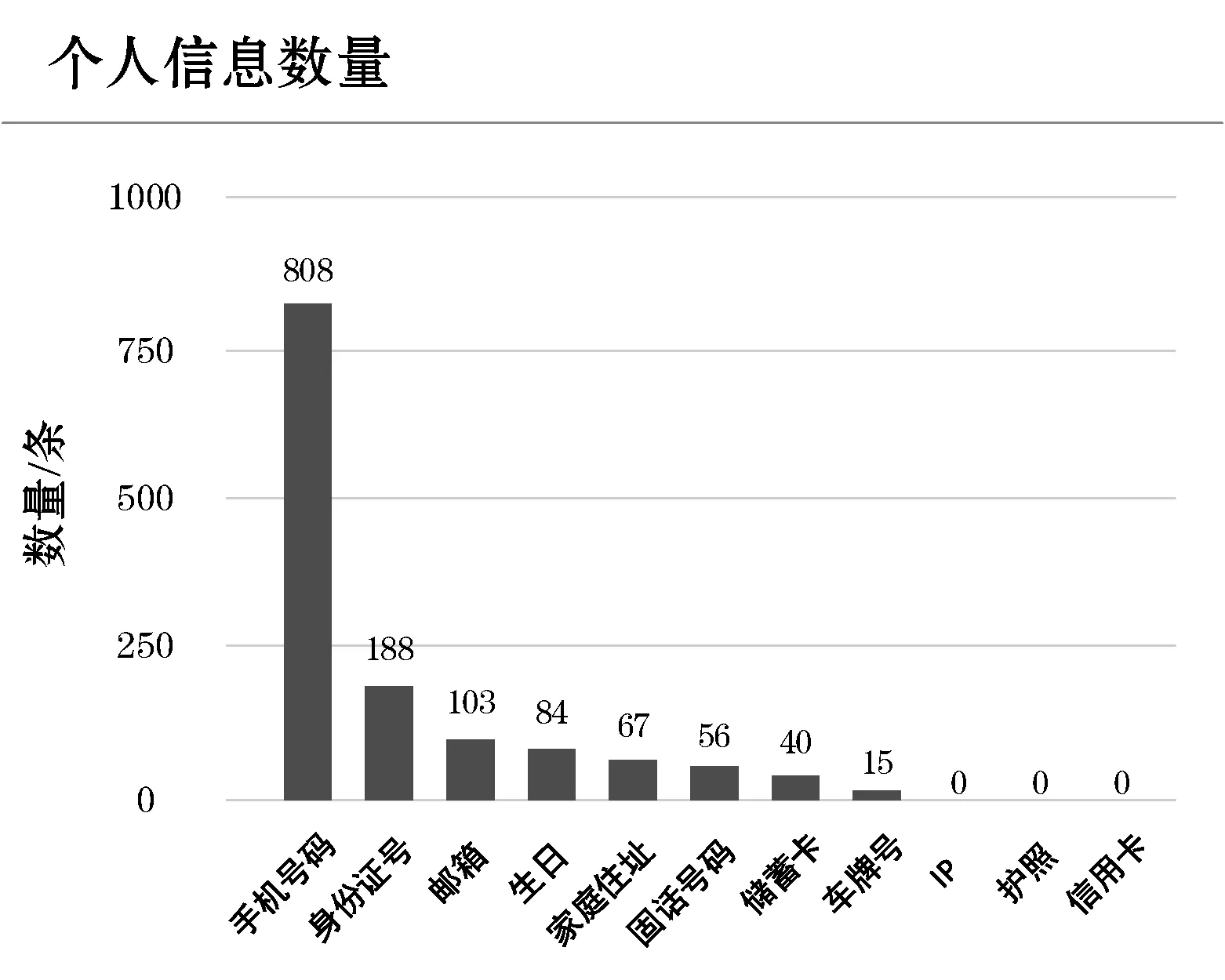
图4 报告示例:个人信息数量
在人工收集的这份天涯论坛数据中,有635条数据检测到了个人信息,其中不乏一些敏感信息如身份证号码、家庭住址、银行卡号。这些信息由于公开存在于互联网环境中,一旦被第三方收集并进行二次传播,将有可能对个人信息主体带来一定的安全威胁,并给第三方数据持有者带来法律风险。互联网上真实数据的检测结果可以证明,本框架能有效从自然文本中识别多种类型的个人信息;对于数据持有者而言,有必要利用本文提出的个人信息检测框架对他们收集的数据进行扫描。
5 结 语
近几年国内外颁布的隐私保护相关的法律法规明确规范了个人信息在收集、应用、存储、转移等多个阶段应当满足的要求。为了保证数据的安全性和合规性,本文基于这些法律法规确定个人信息的具体类别,并提出一种个人信息检测框架,用于在中文文本中进行隐私信息的自动化识别。本文介绍了一种识别家庭住址的方法,有效解决地址格式复杂多样的问题。在寻人启事数据集、THUCNews,以及天涯论坛数据集上证明了检测框架的可行性。除此之外,本文提出的检测工具能高效地对数据集进行检测,在THUCNews的新闻数据集中进行检测的平均速度达到每秒8.26 MB。在后续的研究中,本文将扩展个人信息涵盖的范围,将一些依赖语义的信息如薪资、学历等信息添加进来,以丰富个人信息检测框架的功能。
猜你喜欢
今日农业(2022年1期)2022-06-01
诗选刊(2021年8期)2021-08-23
中国军转民·下半月(2021年12期)2021-02-15
星星·散文诗(2020年7期)2020-09-16
疯狂英语·爱英语(2020年9期)2020-01-07
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
民主与法制(2019年45期)2019-11-17
意林(2019年1期)2019-01-16
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
