
分解机深度网络推荐算法
2022-02-19 02:27严武尉
小型微型计算机系统 2022年2期
李 超,付 伟,马 宁,严武尉
(哈尔滨师范大学 计算机科学与信息工程学院,哈尔滨 150500)
1 引 言
近些年来,随着人工智能、深度学习的发展,推荐系统在解决“信息过载”问题方面达到了新的领域.Top-N推荐是推荐系统的一个主要方向,例如当一个用户浏览电影网站或者在手机进行美食点餐时,会出现一个推荐的列表供用户选择,如何让用户对列表里的推荐项目感兴趣或者使列表里的前几个项目吸引用户的目光成为了Top-N推荐的主要任务.用户通过购买、评论、点赞、收藏等行为与项目进行交互,这些交互关系隐藏着用户的偏好喜爱.有时候用户的额外信息比如年龄、性别也很重要.
推荐系统主要有协同过滤和基于内容的推荐方法,矩阵分解技术是协同过滤的具体应用,矩阵分解通过对用户和项目的隐向量做内积来预测评分.因式分解机是基于矩阵分解思想的学习算法,可以求解大规模稀疏向量特征之间的组合问题,降低了特征学习不充分的影响.然而矩阵分解只是通过简单的内积将特征组合,因式分解机只是组合了特征之间的低阶线性组合.目前提出了许多基于协同过滤算法的改进模型.文献[1]提出了一种融合信任度与半监督密度峰值聚类的改进协同过滤推荐算法,该方法通过峰值聚类将用户分类,基于兴趣度和信任度形成的邻居用户集合来为用户推荐,降低了寻找目标用户的时间消耗,提高了推荐效率.文献[2]提出了融合热门因子的协同过滤改进算法,考虑到物品热门程度对用户相似度的贡献,在准确率和召回率指标上比传统算法表现得更好.文献[3]提出基于改进用户相似度和评分预测的协同过滤推荐算法,改进了相似度的计算方法,使数据稀疏对相似度的影响变小,提高了推荐的准确性.上述方法是在协同过滤的框架中改进,并没有利用到深度网络的结构.
基于深度学习的推荐模型具有学习高阶非线性特征的能力.文献[4]提出神经协同过滤模(Neural Collaborative Filtering,NCF),将用户和项目的嵌入向量连接起来输入到多层感知机中来学习非线性的交互函数,此模型只是简单的将嵌入向量连接起来并没有充分利用输入向量.文献[5]提出深度矩阵分解(Deep Matrix Factorization,DMF)模型,分别把用户和项目的嵌入向量输入到多层感知机中,再把输出结果做内积,此模型把矩阵分解和深度网络结合起来,然而没有考虑特征之间的组合情况.文献[6]提出深度分解机(Deep Factorization Machine,DeepFM)模型,通过多层感知机和因式分解机的并行网络结构,对输入特征向量进行两种处理,最后在输出层将两者融合起来,然而此模型的因式分解机部分没有输入到多层感知机中,无法进行高阶非线性学习.
本文提出分解机深度网络模型,模型考虑到特征之间的组合情况,将二阶的组合特征融入到模型中.FMN模型不仅可以学习到线性特征和低阶的组合特征,而且还可以学习到高阶的非线性特征.本文的主要贡献有以下几点:
1)提出了基于分解机的深度网络结构,在深度神经网络的嵌入层中增加了因式分解机向量.嵌入向量通过分解机操作,学习到不同特征组合的向量.此模型可以把特征之间的二阶组合输入到深度网络中,充分挖掘数据的隐藏信息.
2)将因式分解机的思想融入到深度网络中,相比传统的因式分解机,分解机向量通过深度网络可以学习到高阶的非线性特征.
3)将嵌入向量与分解机向量连接组成新的向量,解决了传统嵌入向量没有考虑特征之间交互的问题,增加了模型的可表示性.
2 相关工作
2.1 深度学习推荐系统
与传统的推荐算法相比,基于深度学习的推荐算法能够更有效地反映用户的不同偏好以及提高推荐的准确性[7].如何更好的提取输入数据的特征以及设计更高效的深度网络成为了基于深度学习的深度系统的主要课题.
He[4]等人提出神经协同过滤模型,用户和项目的信息分别通过广义矩阵分解和多层感知机得到向量,在多层感知机部分,率先将用户向量和项目向量连接起来,输入到深度网络中.然而NCF在深度网络的输入部分,简单的将向量连接起来,降低了深度网络的学习能力.文献[8]提出了用于文本上下文感知的卷积矩阵分解模型(Convolutional Matrix Factorization,ConvMF),解决了基于传统词袋(Bag-of-words)模型的局限性,将卷积层运用到描述文本信息向量上.然而ConvMF在对用户的向量特征方面并没有进行什么处理.文献[9]提出了耦合协同过滤(Coupled Collaborative Filtering,CoupledCF),使用卷积神经网络(Convolutional Neural Network,CNN)学习全局和局部的用户-项目关系,使用深度协同过滤(Deep Collaborative Filtering,DeepCF) 模型学习隐性用户-项目关系.CoupledCF模型的CNN部分可以学习用户-项目的全局和局部信息,然而在DeepCF部分只是将嵌入层向量做内积后输入到多层感知机中,并没有充分挖掘出向量内部的可能组合.
Xue[5]等人提出深度矩阵分解模型,通过深度网络将用户和项目信息分别映射到非线性投影的低维空间,分别输入到多层感知机中学习非线性特征.文献[10]在DMF的基础上融入了隐性反馈,提出了隐反馈嵌入层,使模型更擅长融入额外信息.然而DMF模型并没有对输入向量特征进行交互处理.文献[11]提出了极度深度分解机(eXtreme Deep Factorization Machine,xDeepFM)模型,在压缩交互网络(Compressed Interaction Network,CIN)部分,用显性的方式在向量层面生成特征交互.模型学习了显性和隐性的高次特征交互,同时不需要手动的特征工程.文献[12]提出了分解机深度网络(Factorization Machine supported Neural Networks,FNN),将因式分解机作为深度网络的嵌入层.然而此模型只考虑到了高阶组合特征,没有考虑到低阶特征的组合.文献[13]提出序列感知机深度网络(Sequence-aware Deep Network,SeqaDN),将注意力机制和深度双向循环神经网络结合到模型中,可以区别学习每个项目对预测项目的权重,进而学习到用户的历史偏好向量.
2.2 因式分解机
因式分解机模型的输入可以是用户评分数据,也可以是用户项目的额外信息,提升了模型的可学习数据量.
文献[14]提出因式分解机(Factorization Machines,FM),在推荐系统中有着广泛的应用,是许多模型的基础与来源.FM的表达式由线性回归部分和交叉项部分组成:
(1)

(2)
公式(1)中的交叉项部分经过变换可以降低时间复杂度:
(3)
vfm是一个长度为d的向量.文献[15]提出领域感知分解机(Field-aware Factorization Machine,FFM),FFM是基于FM的模型,对特征向量进行分类,这样嵌入向量不仅与特征有关系,还与所属的类有关系.然而FM和FFM模型没有使用深度网络,不具有高阶非线性特征学习能力.文献[16]提出了神经因式分解机( Neural Factorization Machines,NFM),把可以学习二次交互线性特征的分解机和可以学习高次非线性特征的神经网络组合在一起.Guo[6]等人提出了深度分解机模型,模型并行地将分解机和深度网络结合,可以同时学习低阶特征和高阶特征.
3 分解机深度网络模型
本文提出了分解机深度网络模型,在这一部分中,首先进行问题描述,然后详细介绍FMN模型,FMN可以分成4部分:嵌入层、分解机融合层、多层感知机层和最后的输出层.FMN模型结构如图1所示.最后给出损失函数的表示及其优化方法.
3.1 问题描述
用户的集合U有m个用户,U={u1,u2,…,um},∀u∈U.项目的集合I有n个项目,I={i1,i2,…,in},∀i∈I.用户和项目组成了一个交互矩阵R,其中R∈{m×n}.R中的每一个元素yui表示用户u对项目i的交互行为,交互行为可以是评分、浏览、收藏、点赞等行为.其中:
(4)
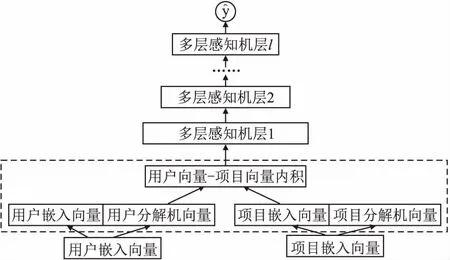
图1 FMN模型结构Fig.1 FMN model structure
分解机深度网络模型的目标是根据交互矩阵R,对每一个用户推荐固定数量的项目,根据命中率等指标来判断用户对推荐项目的满意程度.合理充分地利用交互矩阵R,可以达到理想的推荐效果.
3.2 嵌入层
经过独热(one-hot)编码可以将文本信息或者连续值用0和1表示,转化成机器学习可以接受的形式.用户与项目之间的交互行为往往具有稀疏性,直接用独热编码表示会导致要学习的权重参数过多而难以学习,嵌入层的主要作用就是用一个密集的向量来表示稀疏的独热编码向量,它们之间是一一映射的关系.
用vu表示用户u经过独热编码的输入特征向量,用vi表示项目i经过独热编码的输入特征向量.它们不仅可以唯一标识用户项目的id,还可以支持额外信息的标识,例如用户的年龄、职业,电影的题材等.对用户和项目进行独热编码后,通过线性变换得到它们的嵌入向量,也叫做隐向量.用户的嵌入向量为pu=PTvu,项目的嵌入向量为qi=QTvi,其中P∈m×k,Q∈n×k,分别表示用户和项目的隐因子矩阵权重,m和n分别为用户和项目的数量,k表示嵌入向量的隐因子的数量.
3.3 分解机融合层
分解机融合层是FMN的核心部分.首先利用分解机技术分别求出用户和项目嵌入向量的分解机向量.然后将用户嵌入向量和用户分解机向量连接起来,将项目嵌入向量和项目分解机向量连接起来,分别组成用户表示向量和项目表示向量.最后对用户表示向量和项目表示向量做内积.
(5)
得到用户分解机向量pfm,pfm是长度为f的向量.pfm的长度可以与pu的长度不一致.得到用户的分解机向量pfm和项目的分解机向量qfm后,连接嵌入向量和分解机向量得到用户表示向量p向量和项目的表示向量为q:
(6)
(7)
其中向量p和向量q的长度均为h,其中h=k+f.对p和q内积得到了多层感知机层的输入向量a:
a=p·q=(p1q1,p2q2,…,phqh)
(8)
把嵌入向量和分解机向量连接起来,组成的表示向量具有一阶线性特征和特征之间的二阶组合特征.
3.4 多层感知机层和输出层
多层感知机层(也就是深度网络层)是由数个全连接层组成的,每一层的每个向量值是由前一层的所有向量值和权重参数经过线性组合并通过激活函数决定.全连接层的公式为:
a(l+1)=σ(w(l)a(l)+b(l))
(9)
其中l是层的深度,σ是激活函数.a(l),w(l),b(l)分别是l层的输入,权重和常量值,a(l+1)是l层的输出.在FMN模型中,σ使用relu激活函数,relu激活函数在反向传播求梯度误差时会节省很多计算量,因为relu函数会使一部分神经元的输出为0,增加网络的稀疏性,减少参数的学习,同时缓解了过拟合问题,sigmoid函数在反向传播时,会出现梯度消失的情况.
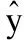
(10)
3.5 损失函数

(11)
其中Y表示正例的集合,Y-表示负例的集合,Y∪Y-为整个集合.Adam是一种计算高效,适用于大规模的数据及参数场景的优化算法,FMN使用Adam优化算法计算公式(11)的最小值.
4 实 验
4.1 数据集
·Movielens-1M 数据集在推荐系统中广泛使用,由100万个交互行为组成,其中有6040个用户和3883个项目.具体的交互行为是评分,有1分-5分5个等级.对于Top-N推荐,本文把用户对项目的评分行为作为感兴趣的标志,记为1,其余就记为0.

表1 实验数据集Table 1 Data sets
·Tafeng 数据集是一个杂货店购物数据集,产品众多.此数据集有80多万个交互行为,其中有32266个用户和23812个项目.与Movielens数据集一样,本文把评分行为记为1,其他行为记为0.把评分信息转变成隐式信息的二元数据集合{0,1}.数据集的具体信息如表1所示.
4.2 对比方法
本文用以下的几种方法作为对比实验.
·DeepCF:把用户嵌入向量和项目嵌入向量做内积后输入到深度网络中.
·DeepFM[6]:将分解机和深度网络结合起来的并行结构,通过分解机可以学习到低维特征,通过深度网络可以学习到高维特征.
·Wide&Deep[19]:既可以通过广度线性模型学习到稀疏特征的交叉积,又可以通过深度网络学习到低维特征难以捕捉到的特征.
·NCF[4]:将矩阵分解和深度网络结合起来的并行结构,深度网络部分把用户和项目嵌入向量连接起来通过多层感知机学习高维特征.
4.3 参数设置
实验环境基于keras深度学习框架.随机为每一个超参数进行标准化分布的赋值,以保证赋值不会对结果有影响.使用Adam优化算法.设置批次大小为256.
对于用户和项目的嵌入向量,通过从{8,16,32,64,128}中测试评估,在两个数据集中选出效果最好的向量长度32.深度网络的结构经过多次的实验,对于Movielens数据集设置为3层,每一层的神经元数为96-64-32,对于Tafeng数据集设置为两层,每一层的神经元数为64-32.
关于分解机向量的设置,通过从{8,16,32,64}中测试评估,对于Movielens数据集,选择效果最好的分解机向量长度64,对于Tafeng数据集,选择效果最好的分解机向量长度32.由于每个数据集的数据量不一样,Movielens数据集的学习率为0.001,Tafeng数据集的学习率为0.005.
关于负采样问题,在用户项目的交互矩阵中,绝大多数的项是0,导致数据稀疏问题,对训练效果产生影响.同时为了降低正负样本的不平衡,FMN通过负采样策略采集一些负样本.对于每1个正例,FMN随机的取4个负例,在一定程度会提升模型的效果.这也是单点对数损失函数优于成对目标函数的地方,可以有灵活的负例采样比例[17,18].
4.4 评估指标
对于Top-N推荐,使用留一法:随机的或者按时间序列先后的对每一个用户在与他有关的交互中选择最后一个项目作为测试数据,此用户其余的交互关系作为训练数据.在测试数据中,再随机选择与此用户无交互关系的99个项目,将它们与有交互关系的1个项目组成100个项目.这样对于每一个用户就有100个项目作为测试数据,进而评估性能.实验选择Top-K命中率(Hit Ratio,HR)和归一化折损累计增益(Normalized Discounted Cummulative Gain,NDCG)作为评估指标.HR和NDCG值均是越大表示效果越好.
·HR@K:一种召回的方法.用来表示测试的项目是否在Top-K的推荐列表之中,注重“准确性”:
(12)
·NDCG@K:一种排序的方法.在Top-K排序中越靠前面,得分越高,注重“顺序性”:
(13)
其中K表示推荐的项目数,GT表示测试项目的集合,reli是项目位置为i的等级相关值,i位置的项目在前K个序列中,reli为1,否则为0,Z是归一值.
4.5 实验结果及分析
Movielens和Tafeng数据集的Top-10项目推荐结果如表2所示.为了更全面的证明FMN模型效果,实验也测试了Top-K(K从1~10)的项目推荐,如图2、图3所示.

图2 K从1~10的HR@K项目推荐Fig.2 HR@K items recommendation where K ranges from 1 to 10
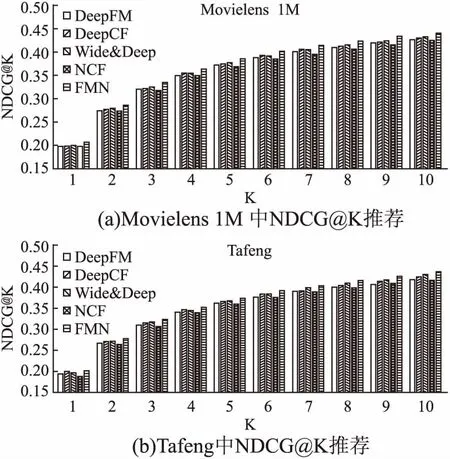
图3 K从1~10的NDCG@K项目推荐Fig.3 NDCG@K items recommendation where K ranges from 1 to 10
表2的结果显示FMN在两个数据集的HR和NDCG指标均优于对比实验.在HR方面,FMN在Movielens数据集比DeepFM平均提升了2.7%,比DeepCF平均提升了1.4%,FMN在Tafeng数据集比DeepFM平均提升了3.2,比Wide&Deep平均提升了1.1%.在NDCG方面,FMN在Movielens数据集比NCF平均提升了3.8%,比Wide&Deep平均提升了1.8%,FMN在Tafeng数据集比DeepFM平均提升了5.3%,比Wide&Deep平均提升了2.1%.

表2 Top-10项目推荐的HR@10和NDCG@10Table 2 Top-10 items recommendation with HR@10 and NDCG@10
从FMN与Wide&Deep模型和NCF模型的比较结果来看,FMN模型加入了因式分解机技术后比直接把特征向量简单连接起来后输入到深度网络的模型有较明显的提升.从FMN与DeepCF模型和DeepFM模型的比较结果来看,相比DeepCF,FMN在嵌入层连接了分解机向量,表达出了更多的隐性特征组合;相比DeepFM,FMN的上下串行结构能够将包含分解机向量的信息输入到深度网络进行高次的非线性学习,从实验结果来看有较明显的提升.
图2和图3分别展示了评价指标HR和NDCG在两个数据集的Top-K(K从1~10)项目推荐结果.首先可以看到,随着K值的增加,所有的模型的HR和NDCG指标均呈现上升的趋势,说明随着K值的大小会影响最终的推荐效果,当K=1时,效果最差.但是K值不能无限的增加,当K值到达一定值后,虽然由于推荐项目增加使HR和NDCG值增加,但是会使用户面对海量的推荐项目,降低有效信息的“密度”,失去了推荐系统的意义.其次,FMN在不同的K值下均具有较高的HR和NDCG.相比HR指标,FMN的NDCG指标更优于对比方法,说明FMN的“排序”效果比“命中”效果更好.图2和图3直观的展示出FMN模型不仅在HR@10和NDCG@10指标优于对比方法,而且在推荐项目数为K(K从1~9)的情况下,HR和NDCG指标均不同程度优于对比方法.
图4和图5展示出不同的分解机向量长度对FMN模型的影响.为了不受到其他参数的影响,将用户和项目的嵌入向量长度都设为32,深度网络的结构从输入层到输出层统一设置成64-32-1的网络结构.首先,可以看到不同的分解机向量长度对HR@10和NDCG@10指标有着不同的影响,这说明在用户和项目的嵌入向量基础上加入分解机向量对FMN模型有一定的提升.其次,随着分解机向量的长度增加,HR@10和NDCG@10指标在两个数据集整体上是先上升,在factors=32的时候达到最大,之后呈下降的趋势,这说明一开始增加分解机向量的长度,模型的指标会有提升,但是当分解机的长度超过一定的长度后,推荐效果反而会下降.Movielens的HR指标则表现出一直上升的趋势,说明增加分解机向量的长度可能导致NDCG指标上升,HR指标下降,两者在一定的条件下并不是正相关的.

图4 Movielens 1M中分解机向量长度对HR@10和NDCG@10影响Fig.4 Influence of the vector length of factorization machine in movielens 1M on HR@10 and NDCG@10

图5 Tafeng数据集分解机向量长度对HR@10和NDCG@10影响Fig.5 Influence of the vector length of factorization machine in tafeng on HR@10 and NDCG@10
通过对实验结果分析,首先可以看到FMN模型训练出的结果在HR@10和NDCG@10均高于对比模型,不仅如此,在HR@K和NDCG@K(K从1~9)的表现中也不同程度的优于对比模型,说明特征与特征之间的交互对深度网络有重要影响.最后通过FMN模型的分解机向量因子数量实验,证明了分解机向量长度对模型的推荐结果有影响.
5 结 论
本文提出了分解机深度网络(FMN)模型,在深度神经网络的嵌入层中加入了基于嵌入向量的分解机向量,使嵌入层向量可以表示特征之间的低阶交互.FMN模型是深度网络和分解机的上下串行结构.模型不仅可以学习特征之间的低阶表示,而且还可以通过深度网络学习分解机向量的高阶非线性表示,充分利用交互信息,达到更好的推荐效果.现实数据集的实验结果表明,FMN模型可以达到更好的推荐效果.
在未来,下一步工作有两个方向:1) 本文对于深度神经网络的探索才刚开始,未来计划选择或者构建出其他的网络结构来提升模型本身的拟合能力;2) 推荐系统的数据不仅包含了用户与项目的交互关系,还有很多额外辅助的信息没有被模型考虑进去,未来计划把这些信息吸纳进模型当中,来进一步提升模型的可拓展性.
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
新高考·高一数学(2022年3期)2022-04-28
福建基础教育研究(2019年6期)2019-05-28
读与写·教育教学版(2017年10期)2017-11-10
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
