
基于DCGAN和改进YOLOv5s的桥梁表面缺陷检测识别
2022-02-18 03:22何金宝胡秋宝付志超刘知远
江西师范大学学报(自然科学版) 2022年6期
何金宝,胡秋宝,付志超,赖 毅*,刘知远
(1.江西省港口集团有限公司,江西 南昌 330008;2.江西省路港检测中心有限公司,江西 南昌 330200)
0 引言
桥梁作为在现代综合立体交通体系中至关重要的一项基础设施,在运营过程中经常受到外部荷载冲击和基础不均匀沉降等因素的影响,表面容易出现裂缝缺陷,当裂缝宽度过大时会直接降低桥梁承载能力,对桥梁结构安全和长期性能带来隐患,若不及时处理则可能会引发垮塌事故[1].然而目前中国对桥梁表面缺陷的检测大多还是通过人工定期巡检,不仅消耗大量的人力、物力和财力,而且还对日常交通造成影响,且检测效率低下、误检率高,很难满足桥梁日常养护的需求[2].因此,亟需建立一种桥梁表面缺陷智能识别模型,提升桥梁管理养护水平.
基于传统机器学习的桥梁表面缺陷检测算法主要是通过提取有效特征,再输入到分类器中进行模式识别[3].陈飞飞等[4]先提取灰度直方图、颜色矩及纹理等统计特征,再输入到支持向量机进行桥梁裂缝的识别,结果表明:图像干扰噪声越少,其识别精度越高.魏武等[5]引入高幅小波系数比、高频能量比、Radon变换最大值和概率统计参数作为特征值,利用BP神经网络对桥梁缺陷图像进行分类.Peng Xiong等[6]利用桥梁裂缝图像的形状特征和灰度特征,结合Softmax分类器检测桥梁裂缝.但由于裂缝缺陷形态各异且背景噪声干扰较大,选择的特征在较大程度上取决于先验知识,因此,传统方法提取的特征代表性不足,这导致模型识别准确率较低.
深度学习技术近年来不断发展,已经在目标检测与模式识别等问题上得到了广泛的运用,目前基于深度学习的目标检测算法根据预测流程可分为2类[7].1)以R-CNN[8]、Faster R-CNN等[9]为代表的基于候选区域的2级目标检测算法,此类算法包括2个阶段:(a)使用区域建议算法创建可能包含检测对象的候选区域,并对部分背景区域进行剔除;(b)使用CNN对候选区域进行置信度和位置修正,采用非极大值抑制算法对其进行处理,得到最终的检测框.A. Reghukumar等[10]将R-CNN模型用于从桥梁裂缝图像中有效地提取多样化的特征,已经证明了其在检测大型建筑物和结构裂缝方面的可行性.Deng Jianghua等[11]将faster R-CNN应用于具有复杂背景的混凝土桥梁图像,使用包含复杂干扰信息的图像来评估建立的网络模型性能,实现自动从原始图像中定位裂缝.2)以YOLO[12]、SSD等[13]为代表的基于分类回归的单级目标检测算法,通过使用多个尺度的特征图来弥补感受野的影响,将特征提取和定位一体化完成,识别速度要比前一类算法快很多,但精度略有不足.周清松等[14]提出一种改进YOLOv3的桥梁表观病害检测识别方法,通过添加固定池化模块和引入DenseNet结构,相较于原始模型进一步提高了检测精度.孙朝云等[15]设计了深度残差网络和SSD卷积神经网络融合的模型,并根据损失函数的收敛程度优化在模型中的超参数,得到了较好的分类效果.
在主流的目标检测算法中,YOLO网络在不同对象的检测任务中均表现出色,国内外学者对其提出了不同的改进方案[16].本文提出了一种基于深度卷积生成式对抗网络和改进YOLOv5s的桥梁表面缺陷检测识别模型.为有效解决模型在训练时样本不均衡的问题,将DCGAN网络用于训练自主采集的小样本裂缝图像数据,生成桥梁表面缺陷图像数据集;再以YOLOv5s为基础网络框架,集成CBAM注意力机制模块,增强重要特征的表征能力,从而进一步提升模型检测的准确率.实验结果表明:在对不同类型的桥梁表面缺陷的检测任务中,本文所提出的模型能有效识别缺陷并达到较好的效果.
1 深度卷积生成式对抗网络
深度卷积生成式对抗网络(DCGAN)是在生成对抗网络GAN[17]的基础上,引入卷积神经网络CNN衍生出的一种深度学习模型.GAN模型的基本框架主要由生成器G和判别器D构成,其中生成器G通过学习真实数据X的分布,再输入随机噪声Z就能生成新的样本数据G(z);判别器D能够区分输入样本是真实数据样本还是网络生成样本,其作用类似于二分类器.GAN结构如图1所示.

图1 DCGAN结构
DCGAN的基本原理与GAN类似,只是在以下方面进行优化:1)对GAN中生成器G和判别器D的结构使用CNN拓展,上采样由生成网络通过反卷积完成,在判别网络中引入具有stride的卷积替换池化;2)同时使用全局池化层替代全连接层,使模型训练更加稳定;3)通过添加批量归一化等操作提高样本的质量和收敛的速度;4)生成网络使用ReLU激活函数,输出层使用Tanh函数;5)判别网络使用LeakyReLU激活函数,有效防止梯度稀疏.
生成网络G的作用是使生成的样本G(z)尽可能地接近真实样本,从而通过判别网络D判定为真实数据,即最小化目标函数V(D,G);判别网络D的作用是将生成的G(z)数据判别为假,真实数据输入判别为真,即最大化目标函数V(D,G).因此DCGAN模型训练的本质就是生成网络G和判别网络D通过不断地进行动态的博弈对抗学习,最终达到纳什均衡.由此可知,目标函数是最大化D(x)和最小化D(G(z)),即
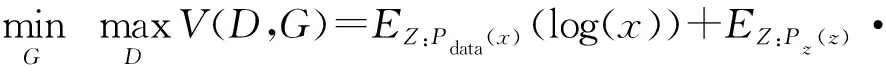
其中x为真实样本,z为随机噪声,Pdata(x)为真实样本分布,Pz(z)为随机噪声分布,G(z)为生成网络生成的样本;D(x)和D(G(z))分别表示判别网络对输入图像判别为真实图像和生成图像的预测概率,取值在0~1之间,其中0表示判定为生成图像,1表示判定为真实图像.
将采集的小样本桥梁表面缺陷图像分类输入搭建好的DCGAN模型中,生成网络和判别网络的学习率均设置为0.001,Momentum为0.9,图2显示了在经过800次迭代后的输出结果.从图2可以看出:DCGAN模型生成的桥梁表面缺陷图像形态和尺寸位置以及大小都具有较高的随机性,且具备较好的纹理信息,其灰度信息和轮廓信息与真实图像相似度较高,能有效扩充样本并解决深度学习模型训练样本不足的问题.

图2 DCGAN生成图像
2 YOLOv5s网络模型改进
2.1 YOLOv5s模型
YOLOv5s网络模型是在YOLOv5系列检测模型中的一种,具有检测精度高、体积小和运行速度快等特点,非常适合部署到嵌入式的设备中[18].本文对YOLOv5s网络结构进行改进和优化,实现在不影响正常交通的场景下对桥梁表面缺陷进行自动化检测识别.YOLOv5s的结构主要由Input、Backbone、Neck和Output等4个部分组成,网络模型整体结构框架如图3所示.

图3 YOLOv5s模型结构
Input输入端实现Mosaic数据增强、自适应图像缩放和自适应锚框计算的功能,完成输入数据的预处理任务.Backbone主干网络包含Focus、CSP、CBL和SPP结构.Focus结构进行切片操作,目的是减少模型层数、提高运行速度.CBL(Conv+BN+Leaky_Relu)基础模块用于特征提取.CSP(CBL+Resuit+Concat +Leaky_Relu)基础模块在特征提取过程中优化在网络中的梯度信息,减少推理运算量,并加快网络运算速度.SPP空间金字塔模块拓展了特征图的感受野,解决了输入图像尺寸不统一的问题.Neck颈部网络在FPN特征金字塔网络的基础上参照了PAN金字塔注意力网络,形成了FPN+PAN结构的多尺度特征融合网络.FPN层自上向下对图像进行上采样,并通过引入的CSP网络模块将提取的语义特征与主干网络中提取的特征进行特征融合;PAN层自下向上对图像进行下采样,将提取到的定位特征和FPN层提取的特征进行融合,从而实现不同尺度的目标特征融合,进一步提升检测网络性能.Output输出端通过CONV卷积模块输出3种不同的检测尺度,并用CIoU_Loss作为Bounding box损失函数优化边界框不相交问题,同时引入NMS非极大值抑制机制筛选多目标框.
2.2 YOLOv5s网络模型的改进
注意力机制可以根据特征的重要性,将计算资源更多地集中在检测目标最具信息性的部分,以增强对检测任务贡献度更大的特征的表征能力[19].为实现同时在通道维度和空间维度上强化重要特征并抑制无用特征,W. Sanghyun等融合了通道注意力机制(channel attention module,CAM)和空间注意力机制(spatial attention module,SAM),于2018年提出了卷积注意力机制(convolutional block attention module,CBAM),CBAM模块示意图如图4所示.

图4 CBAM模块
CAM和SAM通过串联的方式从通道域和空间域2个维度考虑特征相关性,从而计算出注意力权重,在经过2轮卷积操作后,依次生成通道注意力图和空间注意力图,最后空间注意力图与空间注意力模块的输入相乘,得到CBAM模块的输出.CBAM注意力机制的处理过程为F′=MC(F)F,F″=MS(F′)F,其中F为输入特征图,MC为在通道维度上的注意力映射计算,MS为在空间维度上的注意力映射计算.
MC(F)=σ(MLP(Avgpool(F)))+σ(MLP(Maxpool(F))),
其中σ表示Sigmoid激活函数,MLP表示多层感知机模型,W0∈RC/(rC)、W2∈RC/(rC)分别为MLP 2个隐藏层的参数.
SAM机制将通道注意力模块的输出特征进行空间上的最大池化和平均池化,分别得到F′Savg和F′Smax2个空间通道描述符,拼接后得到通道数为2的空间特征图,通过激活函数为Sigmoid的7×7卷积层进行卷积,就能得到2维空间注意力MS.计算过程如下:
MS(F′)=σ(f7×7((Avgpool(F′);Maxpool(F′)))),
MS(F′)=σ(f7×7((F′Savg;F′Smax))),
其中σ为Sigmoid函数,f7×7表示卷积核为7×7卷积运算.
注意力机制最重要的功能是对特征图进行注意力重构,突出在特征图中的重要信息,抑制一般信息,而Backbone网络就是在YOLOv5s模型中提取特征最关键的部分.本文将CBAM模块集成在Backbone网络之后,而在Neck网络进行特征融合之前,这主要是因为YOLOv5s模型是在Backbone网络中完成的特征提取,然后经过Neck网络特征融合之后在不同的特征图上预测输出.因此CBAM模块在此处进行注意力重构,可以突出重要特征并抑制无效特征,从而提高检测精度.改进后的模型具体结构如图5所示.
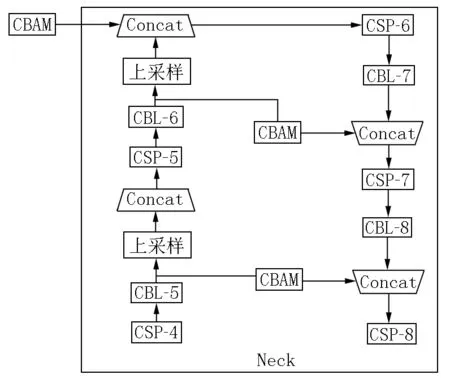
图5 改进YOLOv5s模型结构
3 实验结果与分析
3.1 实验数据
本文实验平台由2部分组成:图像采集系统和图像处理系统.图6显示了本文用于采集桥梁表面缺陷的图像采集设备.该系统由大众朗逸汽车、支架、GoPro运动相机组成.图像处理系统是在Windows10操作系统下,基于TensorFlow-gpu1.14.0和Pytorch1.2.0搭建的深度学习框架,硬件环境为Intel core i5-8500,16 GB显示内存.

图6 图像采集装置
在自然光条件下,使用GoPro HERO 6 BLACK全向运动相机通过线性扫描的方式采集桥桥梁表面图像,获得共计1 781幅像素为1 920×1 080的桥梁表面缺陷图像,其中横向裂缝610幅、纵向裂缝584幅、交叉裂缝308幅、网状裂缝279幅,部分数据集样本如图7所示.为提高模型的识别精度和泛化能力,避免因样本数量不均而导致过拟合的问题,使用DCGAN进行数据增强,每类缺陷数据扩充到1 000幅,并将数据集按4∶1的比例划分为训练集和测试集.
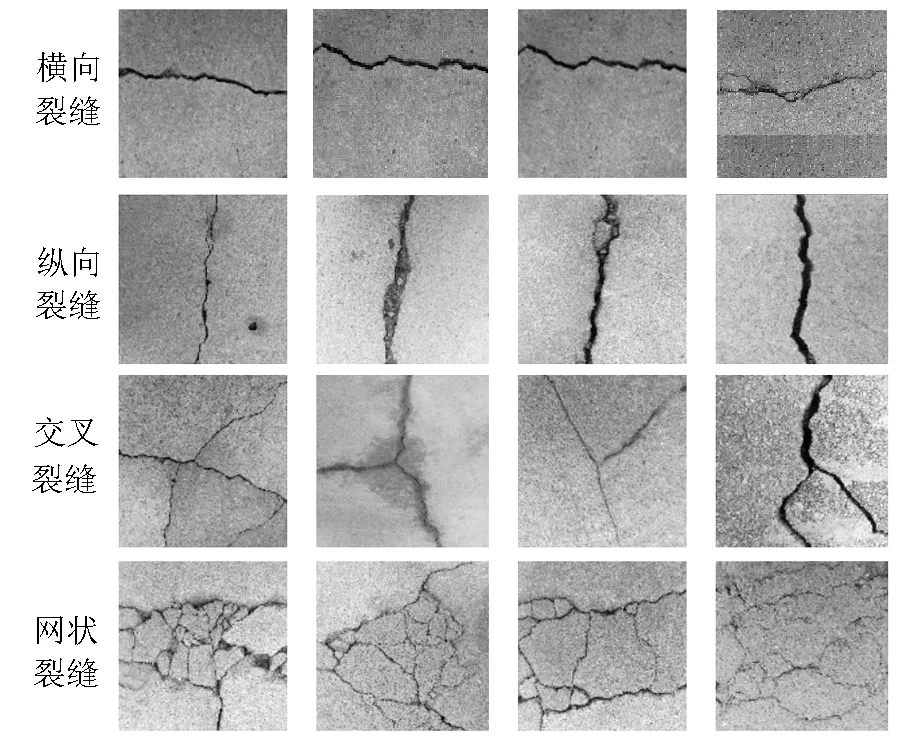
图7 桥梁表面缺陷数据集
3.2 评价指标
本文选取了平均精度AP(average precision)、平均精度均值mAP(mean average precision)和帧率FPS(frames per second)等指标对改进后的网络模型进行评价.AP用于评估模型在单个检测类别中的性能,通过计算网络模型的PR曲线所围成的面积得出;mAP能直观反映模型整体性能,将每个类别的AP平均后就可得到;FPS用于衡量网络模型处理图像的速度,表示模型每秒能处理图像的数量.AP和mAP的计算如下所示:
其中精确率P(precision)和召回率R(recall)的计算如下所示:
P=TP/(TP+FP)×100%,
R=TP/(TP+FN)×100%,
这里TP表示输入为真且判定为真的样本个数,FP表示输入为假且判定为真的样本个数,FN表示输入为真且判定为假的样本个数,NC为在数据集中的类别数.
3.3 实验结果与分析
对YOLOv5s模型和改进的YOLOv5s模型分别进行训练,参数设置如下:优化器为SGD,初始学习率为0.01,Batch为128,动量参数为0.9,衰减系数为0.000 5,最大迭代次数为300次.图8显示了YOLOv5s原始模型和在嵌入CBAM模块改进后的YOLOv5s模型的识别准确率和损失值.从图8可以看出:随着训练轮数的增加,改进的YOLOv5s模型的识别准确率逐渐高于原始模型;前期损失值下降较快,改进后收敛速度明显要优于原始模型的收敛速度.
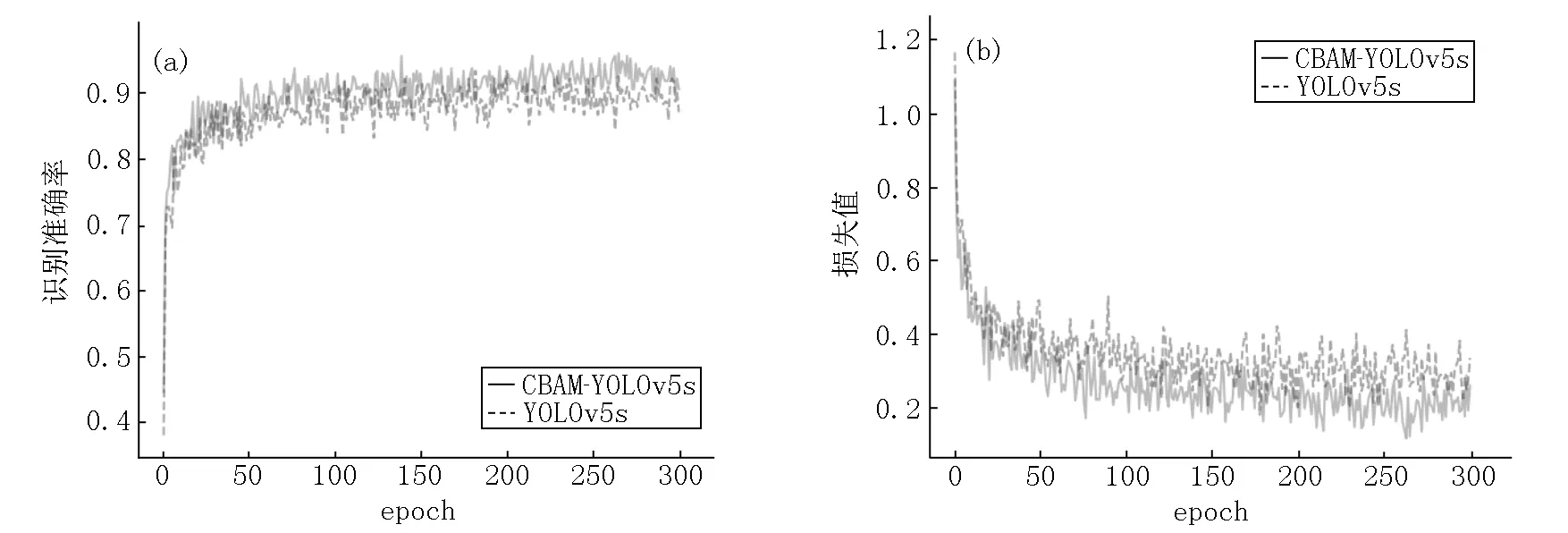
图8 迭代训练准确率和损失值
将测试集输入搭建的模型中获得桥梁表面缺陷的识别混淆矩阵(见如表1).结果表明:改进YOLOv5s模型能够正确识别不同类型的缺陷,识别准确率达到92%.
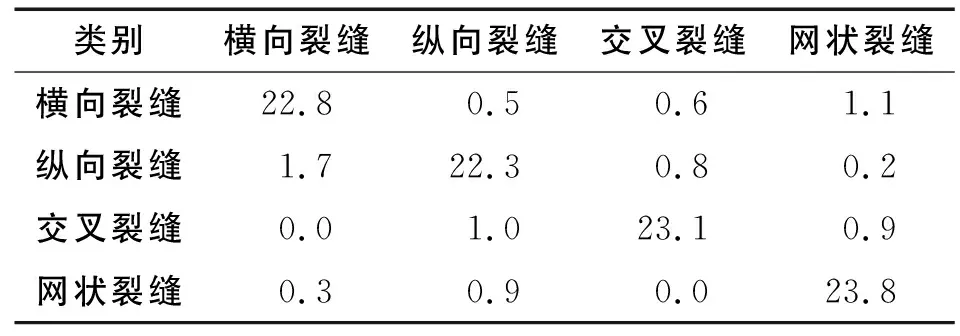
表1 准确率识别混淆矩阵
为了进一步验证本文提出的模型在桥梁表面缺陷检测识别方面要优于其他先进的检测算法,使用同样的数据集对文献[20]提出的模型(Faster-RCNN)、文献[21]提出的模型(SSD)、文献[22]提出的模型(Retinanet)进行识别任务的训练和测试.表2是本文提出的模型与主流模型进行随机试验的结果对照.通过分析可知:相较于其他主流检测算法,本文提出的方法有更好的分类性能,且mAP达到了91.7,具有重要的实际运用价值,能够有效作为桥梁表面缺陷检测识别的模型.

表2 不同模型性能比较
4 结语
本文提出一种DCGAN和改进YOLOv5s的桥梁表面缺陷检测模型,首先使用DCGAN网络对采集到的桥梁表面缺陷图像进行数据增强,然后引入CBAM注意力机制模块,提出改进后的YOLOv5s模型.实验结果表明:相比于原始YOLOv5s模型和其他主流算法,本文提出的模型在网络性能、模型识别率和模型收敛速度方面表现更为突出,能为桥梁日常维护提供更好的辅助作用.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
湖南教育·A版(2019年4期)2019-05-10
小学生学习指导(低年级)(2019年4期)2019-04-22
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
山东工业技术(2016年15期)2016-12-01
第二课堂(课外活动版)(2016年2期)2016-10-21
