
基于数据挖掘技术的电网时序数据质量维护研究
2022-02-18 01:34谢瀚阳彭泽武唐重阳肖啸魏理豪
电测与仪表 2022年2期
谢瀚阳,彭泽武,唐重阳,肖啸,魏理豪
(1.广东电网有限责任公司信息中心, 广州 510062; 2.深圳市康拓普信息技术有限公司,广东 深圳 518034)
0 引 言
随着科学技术的不断进步,电网的智能化水平也越来越高,也因此在电网运行和设备监测的过程中产生了大量的数据[1-2],例如系统运行数据、设备状态数据、用户需求数据等等。另外,物联网技术和云计算的蓬勃发展,也进一步增强了电网数据的体量和复杂度。如此庞大的数据体系难免会带来一些数据质量问题,如数据缺失、数据冗余、数据异常等。数据质量的好坏不仅关乎电网应用分析的可靠性与正确性,还会对电力系统的稳定运行产生影响[3-4]。所以,进行高效可靠的数据质量管理对电力系统具有重要意义。
数据质量维护是数据质量管理的重要组成部分[5],可以有效检测出问题数据并进行筛除,是改善数据质量的重要组成部分。不少学者在数据质量维护方面作出了相关的贡献。
文献[6]以CIM/E文本为载体,改进多源数据筛选较优质量数据的手段,由借助主站状态估计对现场数据进行反馈,提高了电网调度系统的整体数据质量;文献[7]从多源多时空角度出发,基于配网SCADA数据提出一种用于综合检测与修正电压数据质量的策略,并通过算例证明了所提方法能有效检测出不满足精度要求的电压数据;文献[8]设计一种考虑多维度电网调度数据质量的综合分析与评价系统,为电网调度人员提供更为直观的综合数据考核与评价手段。
近年来,数据挖掘技术在电网数据管理中的应用也越来越广泛[9-10]。文献[11]针对电能质量检测问题,应用数据挖掘技术,提出了一种的电能质量数据分析处理体系,并应以某城市电网为例,获得了良好的效果;文献[12]建立基于数据挖掘的营销分析方法模型,成功用于分析给定市场环境中各种因素之间价格变化的层次关系。文献[13]对模糊角力分析进行改进,并用于电网不良数据的检测与辨识,获得良好成效。
关于电力数据质量检测已有不少研究,但仍存在以下问题:
(1)大多检测方法对全部样本进行统一分析,但随着数据量的不断增长,逐渐出现检测效率低下的问题;
(2)对数据的质量好坏评价已有较多研究,但对于数据的问题定位研究相对较少。
基于数据挖掘技术,针对不同系统的数据结构特点有所不同的特点,结合使用决策树算法与数据离群检测两种方法,提高数据检测的效率的同时,快速定位数据的问题类型,便于开展数据修复与改进。
1 智能电网时序数据质量分析
1.1 电力数据传输过程分析
科学技术的不断发展使电网的智能化和信息化水平大大提高,对电网数据的需求量也逐渐增大。智能电网系统可以通过数据采集与监控系统、能量管理系统等,实时获取相关生产和运行数据。智能电网将获取的源头数据存储进入数据库,并进行相关管理。与此同时,用户则可通过用户访问接口、手机APP等访问所需数据[14]。该数据逻辑结构如图1所示。

图1 电力数据传输逻辑结构图Fig.1 Logical structure diagram of power data transmission
1.2 电力统计数据问题
随着电网体系规模的不断扩大,其运行过程中产生的数据量也越来越丰富,这其中蕴含着大量的信息,是可以影响发电、输配电、用户用电管理的决策指标的基础。但由于设备故障、认为原因等,电力数据可能会存在一些误差甚至是错误,这不仅不能为电力系统提供可靠的数据分析基础,而且可能因此带来决策错误,影响整个系统的良好运行。图2指出电力数据传输过程中可能会遇到的问题。

图2 电力数据主要问题Fig.2 Main problems of power data
(1)格式错误。所获取的数据格式应是统一的,不满足格式的数据组应视为不合格。另外在数据传送过程中,可能会出现乱码等错误,这也是格式检查的重要方向;
(2)精度错误。在数据获取和传输过程中,所有数据的精度都应保持一致,精度与规定不一致的数据应为不合格;
(3)数据越限。每个数据都有自身约束范围,数据应在规定范围内;
(4)数据冗余。数据传输过程中可能存在重复记录的问题,因此会产生数据冗余;
(5)数据缺失。在数据获取和用户访问端,所获取的数据量应一致,不能存在缺失记录或缺失字段;
(6)合理性问题。所获取数据都应满足电力系统运行要求,各数据之间互相约束,数据段不满足运行条件的为不合格数据段。
2 时序数据质量维护体系构建
为了快速准确地筛选质量差的数据,结合使用数据挖掘技术中的决策树法和离群检测法,充分利用决策树的快速分类和离群检测法在数据相关性检测的优势,可操作性和准确度更高。
2.1 决策树算法
决策树算法是分类算法的一种。它首先要预处理原始数据,然后通过对原始数据的初步分析建立分类规则,分类规则一般以树的形式出现,通过建立的树对样本训练集进行实质的分析[15-16]。
采用最经典的ID3算法建立相关决策树。在该算法中,各类别的不确定性是判断分类效果的标准。这里用信息增益值描述该标准,其中信息增益值越高,不确定性越低。具体的步骤如下:
设S是包含m个数据样本的集合,分类特性共n个,记为Bi(1,2...n),其中Bi所包含的样本数为mi,则对于S的总信息熵为:
(1)

令Sj是集合S中特性Bi类别中有j个数据点的子集,则属性Bi的信息熵为:
(2)
式中I(Sj)是Sj分至各个属性的信息熵。
属性Bi在集合S的信息增益G(S,Bi)为:
G(S,Bi)=I(D)-I(D,Bi)
(3)
G(S,Bi)越大,说明属性Bi对分类起到的作用越大。所以,决策树的分支节点应是信息增益最大的特性。
构建时序数据质量检测顺序决策树时,决策树算法需要使用历史数据训练集。选取某地区的典型历史数据,并形成数据训练集,具体如表1所示。
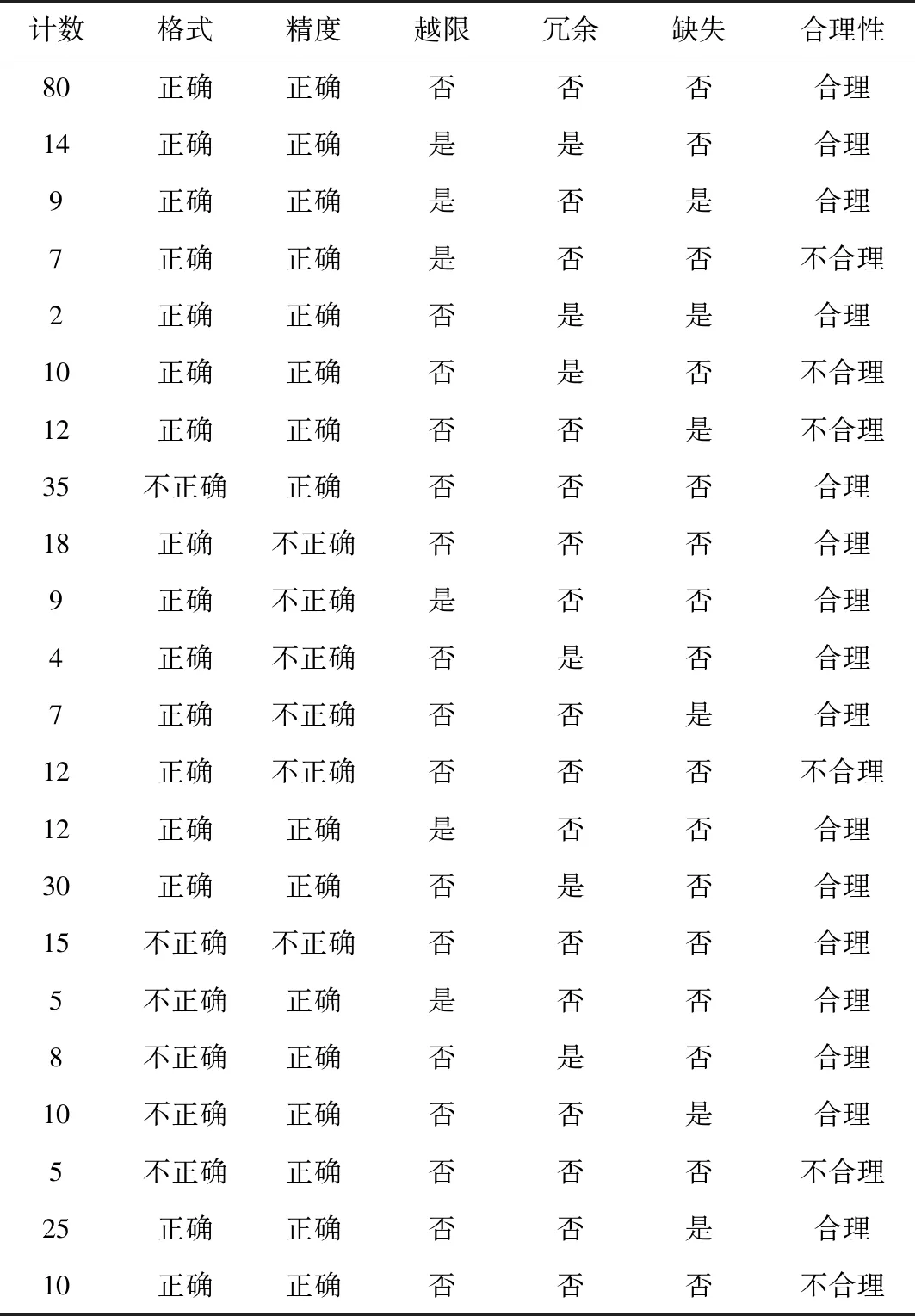
表1 电网数据训练集Tab.1 Power grid data training set
输入训练集经过决策树算法可形成初始决策流程,指标检测顺序如图3所示。

图3 指标决策顺序Fig.3 Order of indicator decision
由上述分析可知,电力数据的格式错误、精度错误、数据越限、数据冗余、数据缺失等问题的检测方式相对简单,可对该数据点独立进行检测。但数据的合理性问题需要综合考虑整体运行情况,检测相对更为复杂,引入离群检测法对数据合理性进行分析。
2.2 离群检测法
离群点检测用于检测数据样本中明显偏离于其他数据的样本,该类样本不能满足数据的普遍特征或行为,是数据挖掘技术的重要研究方向[17-18]。离群点检测方法按照数据挖掘技术的不同可分为基于统计的离群检测、基于深度的离群检测、基于聚类的离群检测等。本文采用基于距离的利离群检测对数据合理性问题进行分析,筛选出不合格的数据。
聚类的思想主要是利用数据样本和各类别间的相互关系[19-20],通过把样本划分为不同的类,使得同一分类内的数据点相似性最大,而不同分类之间的差异性最高。所采用的离群检测方法主要分为两个阶段:首先采用K-means将数据进行聚类;然后针对每个数据样本,计算其到距其最近类中心的距离,将该距离记为离群度量值。如果该数据样本的离群度量值偏大,则为离群数据;反之,就是正常数据。
假设数据样本X={x1,x2, …,xi, …,xn},设定分类数目为M,形成M个簇T={tm,m=1, 2, …,M}
步骤1:首先随机选择M个数据序列作为初始聚类中心c1,c2,…cM;
步骤2:计算每个数据序列和每个聚类中心的距离,把数据序列分配给距它距离最小的聚类中心,直到全部数据序列都被分配。计算各类聚类中心cm到所有属于tm簇的元素xi的距离平方和为:
(4)
步骤3:计算各类数据序列距其所在类别中心cm的距离平方和L(T)。
(5)
式中rmi表示类别判定系数,当xi∈tm,rmi=1;反之,rmi=0。聚类中心更新为各类别中全部数据序列的平均值;
步骤4:返回步骤2,直至各聚类中心都不发生改变且L(T)小于设定参考值,聚类结束。
引入BMP指标来确定数据样本的最佳分类数和评估聚类结果[21-22]。BWP是描述某样本分类和它相邻类别关系的指标,数学表达式如下:
(6)
式中Dw为聚类距离,表示最小类间距离和类内距离之和;Dn为聚类离差距离,表示最小类间距离和类内距离之差。
BWP基于样本几何结构对数据进行分析,BWP数值越大,说明数据样本的聚类效果越准确。
2.3 数据质量维护总流程
数据质量维护流程图如图4所示。

图4 数据质量维护流程图Fig.4 Flow chart of data quality maintenance process
2.4 数据质量异常原因
在电网运行过程中,以下几种情况可能会导致异常数据的产生:
(1)量测数据在传输过程中出现偶然性误差,可能导致数据冗余、格式不正确、数据缺失、精度不足等问题;
(2)量测或传输系统故障、受到干扰引起的异常,可能导致数据冗余、数据越限等问题;
(3)电力系统各个量测点非同时测量,可能会引起数据合理性不足等问题[23]。
3 算例分析
以某地区配电网某检测点为研究对象,结合本文提出的时序数据质量维护体系,对该地区某时段内电力数据进行分析。该点相关数据参数取值范围为:电压U∈[198,235.4],电流I∈[0,288.68],有功功率P∈[0,200],无功功率Q∈[0,120]。为了便于对比分析,本文仅列出部分样本数据,如表2所示。

表2 部分样本数据Tab.2 Partial sample data
通过文中的时序数据质量维护体系可以分析出数据是否有格式错误、精度错误、数据越限、数据冗余、数据缺失等问题,得到如表3所示结果。

表3 电网数据训练集Tab.3 Power grid data training set
在样本中,有的数据点没有上述问题,但是否存在合理性问题仍需通过离群检测法进行判断。有上述分析可知,共20个样本数据需进行离群检测。采用基于聚类的离群检测法,样本集分类个数依据BWP指标确定。不同分类数的BWP指标变化如图5所示。
由图5可知,最佳分组数为六组。当分组数为6时,结果如图6所示。

图5 不同分类数的BWP指标Fig.5 BWP indices of different classification numbers
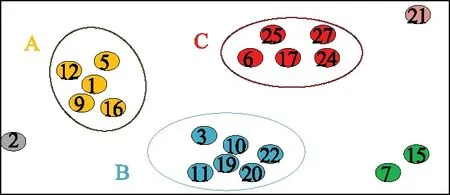
图6 离群检测结果示意图Fig.6 Schematic diagram of outlier detection results
可以看出,数据点2、7、15、21明显偏离其余大类,为不合理数据。为了验证结果的准确性,对上述四个数据点的各项数据进行深入分析,各数据点存在问题如下:
(1)数据点2的B、C两相电压和三相电流值相比于其他合理数据都明显偏低,因此作为孤立点是合理的;
(2)数据点7和数据点15相接近,但相比于B集群它们的无功功率值都偏大不少,因此作为孤立点是合理的;
(3)数据点21的C相电压和有功功率值相比于C集群的其他数据明显偏低很多,因此数据点21作为孤立点也是合理的。
为了确保未标识数据均为正确数据,根据所有样本数据间的物理关联关系进行状态估计,监测结果如图7所示,图中1表示数据异常,0表示数据正常。

图7 状态估计检测结果示意图Fig.7 Schematic diagram of state estimation detection results
由图7可知所提方法与状态估计法检测结果一致。经上述分析可知,通过文中的时序数据质量维护可有效快速发现各数据点存在的问题,定位问题数据,并确定数据的问题类型,为运行维护人员确定数据问题原因,提高数据可靠性奠定基础。
4 结束语
基于数据挖掘技术提出一种时序数据质量维护体系,通过该检测体系,可有效发现问题数据点,并进行筛除,主要结论如下:
(1)不同地区的数据特点不同,为了提高检测速度,本身首先利用决策树法对历史数据进行分析,得出适应于该地区的数据问题检测顺序,可在一定程度上提高计算效率;
(2)与其他数据问题不同,数据的合理性问题检测较为复杂。引入基于聚类的离群检测法对所获取的数据进行分析,可有效筛选出问题数据;
(3)提出一种时序数据质量维护体系,不仅可以定位问题数据,还可以确定数据出现的问题,保证用于电网分析与规划的数据的可靠性,同时也利于及时发现问题数据,快速定位问题点,便于快速修复与改进。
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
九江学院学报(自然科学版)(2022年2期)2022-07-02
世界科学技术-中医药现代化(2021年8期)2021-12-21
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
电子制作(2018年16期)2018-09-26
小型微型计算机系统(2018年8期)2018-09-07
环球市场信息导报(2017年36期)2017-12-24
电子技术与软件工程(2016年24期)2017-02-23
电子制作(2017年24期)2017-02-02
