
基于改进残差学习的东巴象形文字识别
2022-02-18 08:13骆彦龙毕晓君吴立成李霞丽
智能系统学报 2022年1期
骆彦龙,毕晓君,吴立成,李霞丽
(1.哈尔滨工程大学 信息与通信工程学院, 黑龙江 哈尔滨 150001; 2.中央民族大学 信息工程学院, 北京100081)
东巴象形文字由纳西族祖先创造,至今已有两千多年的历史。2003年,东巴古籍文献被联合国教科文组织列为“世界记忆遗产”名录,成为人类共同拥有的宝贵财富。东巴象形文字的识别一直是研究的热点和重点。早期的东巴象形文字识别研究一般采用传统算法提取东巴象形文字特征进行识别,关键步骤一般包括图像去噪、特征提取和分类器识别3个步骤。常用的图像去噪方法有中值去噪、自适应去噪和小波去噪[1];在特征提取方面,方向元素、粗网格[2-3]等统计特征比分析东巴象形文字的结构、笔画等结构特征取得的效果更好;常用的分类器模型包括支持向量机[4]、随机森林[5]等。代表性的研究有2017年徐小力等采用拓扑特征法和投影法相结合的特征提取方法,取得了84.4%的识别准确率[6]。2019年杨玉婷等通过结合东巴象形文字的结构和形态,提出了基于网格分辨率的东巴象形文字相似度测量算法,能够检索和识别不同形状的东巴象形文字[7]。上述研究虽然取得了一定的成果,但实现过程复杂且效率较低,算法的识别准确率有待提高。直到2019年,随着人工智能技术的发展,国内外开始出现基于深度学习的东巴文识别文章,2019年张泽晖建立了包含30 592张图片的东巴象形文字数据集,设计了孪生网络并协同进行文字语义识别,对956个东巴象形文字测试,取得了85.6%识别准确率[8];同年,Wu[9]在训练集图像3 800张,测试集图像200张的条件下,使用VGGNet取得了95.8%的识别准确率;2021年谢裕睿等提出了基于ResNet网络的东巴象形文字识别方法,建立了包含536个东巴象形文字的数据集,并对94个东巴象形文字测试,取得了93.58%的识别准确率[10]。
以上研究对东巴象形文字识别做出较大的贡献,但目前还存在一些问题:1)东巴象形文字大多包含多个异体字,且在东巴经典中广泛存在;但现有的数据集都没有涉及异体字,导致东巴经典中的大量文字不能识别;2)现有的东巴象形文字数据集规模较小,影响了算法识别的准确率;3)所采用的深度学习模型较为初级,无法适应东巴象形文字的随机性和手写不确定性,识别准确率有待进一步提高。
为了解决上述问题,本文主要做了以下两个方面的工作:
1)根据东巴象形文字字典[11-12],采用人工仿写的方法建立了1 387个东巴象形文字(包括异体字)、图像规模达22万余张的东巴象形文字数据集,有效解决了异体字问题,大幅增加了可识别东巴象形文字的数量,并有效扩充了数据集的规模。2)根据东巴象形文字的图像特点,选择应用效果最好的ResNet模型作为改进的网络结构,设计了残差跳跃连接方式和卷积层的数量,并通过加入最大池化层实现了下采样的改进,有效提高了算法识别的准确率。
1 东巴象形文字数据集建立
1.1 东巴象形文字图像获取
深度学习模型能够取得较好的识别效果,其前提是需要大量带标注的训练数据。为此本文首先研究如何建立大规模的东巴象形文字数据集,来保证识别的东巴象形文字更多,并可辅助提高算法识别的准确率。
东巴象形文字的特点可总结如下。1)内容广泛、字数多。按照属性可分为天文、地理、建筑等十八大类,共有2000余字(包括异体字)[11]。2)相似度高。结构相似的东巴象形文字因其细节部分不同,其字义亦不同。3)书写随意性较大。不同人书写的东巴象形文字都会有不规则的形变。4)异体字多。大多数东巴象形文字都有多个异体字。
上述特点增加了东巴象形文字的识别难度,因此为了获得更好的识别效果,数据集中每个东巴象形文字大约需要150张图像,才能满足训练的要求。但是仅通过东巴古籍来获取远远不能达到数量的要求,常用的数据增强方法主要是几何变换[13-15],但由于东巴文本身象形字的图画特点,相近的形状可表达不同的含义,通过几何变换可能变成其他文字,所以这种数据增强的方法难以适用东巴象形文字。
为此本文根据东巴象形文字手写或刀刻的书写习惯,提出采用人工仿写东巴象形文字字典的方法建立大规模数据集,再通过图像预处理方法提高数据集的图片质量,这样可以保证数据集中东巴象形文字的数量足够多,既可以最大幅度地增加算法可识别的东巴象形文字字数,又可以辅助提高算法识别的准确率。本文建立的东巴象形文字数据集示例如图1所示,其中每一行的5幅图片同属异体字,共有相同的释义,第一列为统一的文字释义,从中可以看出异体字之间的差别较大。

图1 东巴象形文字数据集示例Fig.1 Samples of Dongba pictographs datasets
1.2 东巴象形文字图像预处理
人工仿写的东巴象形文字受光照以及拍照设备等的影响,往往会产生极大的噪声,影响东巴象形文字数据集的质量,因此必须对其进行一系列的图像预处理。图2给出了本文建立东巴象形文字数据集的技术路线,具体步骤如下。

图2 东巴象形文字数据集建立技术路线Fig.2 Technical route for Dongba pictographs dataset establishment
1)字符裁剪。对人工仿写的原始图像进行字符裁剪,使得每张图像中仅包含一个东巴象形文字。具体过程如算法1所示。
算法1符裁剪算法
输入未裁剪的手写东巴象形文字图像X;
输出仅包含一个东巴象形文字的图像Y。
①Xh←图像X的高度;
②Xw←图像X的宽度;
③Yh←1/3Xh−2/3Xh;
④Yw←1/3Xw−2/3Xw;
⑤Y←Yh−Yw。
2)灰度化。黑白两种颜色反差较大,可提高东巴象形文字识别的效果。为此,使用加权平均值法进行图像灰度化,去除图像的颜色信息,将三通道的彩色图像转换成单通道的灰度图像。灰度化公式如式(1)所示:

式中:Ri,j、Gi,j、Bi,j分别代表图像在 (i,j)处的红、绿、蓝3种颜色分量像素值; G rayi,j代表图像在(i,j)处的灰度值。
3)二值化。为了极大程度减少图像数据量,通过全局阈值二值化减少图像无关像素信息,并使整个图像呈现出明显的黑白效果,凸显东巴象形文字轮廓,图像二值化公式如式(2)所示:

式中bi,j表示图像二值化后图像在 (i,j)处的像素值。
4)尺寸归一化。常用的图像尺寸归一化方法是双线性插值法,但是当原图像与尺寸归一化图像尺寸相差过大时,尺寸归一化后的图像纹理特征易损坏,不利于深度学习模型识别。而像素区域关系重采样法能够保留完整图像信息的条件下,将输入图像尺寸最大程度减小,大幅度减少图像像素数以及数据量,在保证深度学习模型识别准确率不变的前提下,加快模型的训练速度。根据其他数据集图像尺寸大小设置的经验以及多次对比实验验证,我们发现当图像尺寸归一化为64×64时,可以取得最好的识别效果,并且模型训练速度快。本文对像素区域关系重采样法和双线性插值法在东巴文字图像上的效果进行了简单的实验对比,分别将图像尺寸归一化为 6 4×64。图3给出了实验结果。

图3 两种尺寸归一化方法示例Fig.3 Samples of two size normalization methods
从图3中可以看出,双线性插值法后的东巴象形文字纹理特征有残缺,而像素区域关系重采样可获得更好的尺寸归一化效果。
因此本文选择像素区域关系重采样法进行尺寸归一化操作,其公式如式(3)所示:
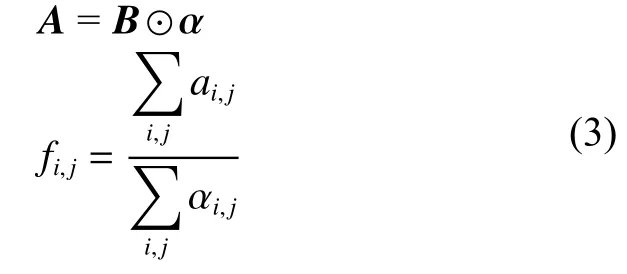
式中:B表示图像某区域内像素值矩阵; α 是与B相对应的像素值系数矩阵,其取值取决于原图像与尺寸归一化图像的尺寸大小关系; ⊙ 表示Hadamard积;fi,j表示图像B区域通过尺寸归一化后的像素值。
5)数据标注。通过数据编码标注,将第i个东巴象形文字的所有图像I统一编码为i,使计算机将图像和编码相互对应,如式(4)所示:

式中F(·)表示编码标注算法,具体过程如算法2所示。
算法2编码标注算法
输入train,test (其中有命名为i(包含图像I)的文件夹)
输出图像I与其编码i相互对应的txt文档
① fori∈train,test;
②forI∈i;
③将I的绝对地址和i写入txt文档;
④换行;
⑤重复迭代2)~4);
⑥返回图像I与其编码i相互对应的txt文档
通过上述一系列的图像预处理,本文建立了东巴象形文字数据集,该数据集包含1 387个东巴象形文字(包括异体字),每个东巴象形文字对应160余张书写各异的图片,数据集图片总量为223 050张。
2 改进残差学习神经网络
近年来,深度学习成功应用于图像识别[16-19]领域,提出了一系列性能优异的网络模型,其中ResNet模型首次提出残差跳跃连接(residual shortcut connection)结构[20],解决了网络加深带来的梯度消失问题以及神经网络深度与识别准确度之间的矛盾,可有效提取更多的图像细节特征,目前已成为图像识别的主流深度学习模型。
考虑到东巴象形文字识别的具体问题,不仅字数多、书写随意性较大,而且有些字形较为相似,因此需要提取细节特征能力强的网络结构,为此本文选择ResNet模型作为本文改进的网络结构,设计了残差跳跃连接方式和卷积层的数量,并通过加入最大池化层实现了对下采样的改进,更好地提取了东巴象形文字的纹理分布特征。本文设计的网络主要框架如图4所示。下面将详细介绍设计思路和改进方法。

图4 东巴象形文字识别网络结构Fig.4 Network structure of Dongba pictographs recognition
2.1 残差跳跃连接
残差跳跃连接可以解决神经网络随着深度增加出现性能退化的问题。深层神经网络难以拟合的原因是恒等映射H(x)=x的学习比较困难,但当把网络设计为H(x)=F(x)+x时,可以把学习恒等映射转化为更加容易学习的残差映射F(x)=H(x)−x,并且F(x)对输出变化更加敏感,参数的调整幅度更大,从而可以加快学习速度,提高网络的优化性能。残差跳跃连接的一般定义如式(5)所示:

其中Ws主要是用1 ×1卷积[21]来匹配残差跳跃连接输入x和输出y的通道维度。F(x,{Wi})为网络需要学习的残差映射。而当残差跳跃连接输入和输出维度相同时,可将其定义如式(6)所示:

文献[22]证明了越是接近当前卷积层的前层输出对当前层的特征提取效果影响越大,可以使网络更容易训练。为此本文仅将相邻堆叠的卷积层组成残差跳跃连接结构,在有效重复利用特征图的同时,降低网络参数量和复杂度。本文残差跳跃连接结构如图5所示。图5中残差映射F(x)如式(7)所示,输出y和输入x的关系式如式(8)所示:

图5 本文残差跳跃连接模块Fig.5 Residual skip connection module of this paper


式中:σ均表示ReLU激活函数,W1和W2分别表示卷积层学习的参数。
2.2 卷积层的选择
网络模型卷积核的选择与网络计算量大小密切相关。尽管大的卷积核可以直接增大感受野,但是会带来网络计算量的暴增,而多个 3 ×3卷积核可以在降低计算量的前提下实现 5 ×5或 7 ×7乃至更大卷积核的效果。由式(9)可以发现,3个3×3卷积核实现 7 ×7卷积核效果时,其参数量可以减少到55%。

其中C指输入和输出的通道数。
除了能够降低网络模型的计算量,单个3×3卷积核还可以捕获特征图像素四周的信息,多个3×3卷积核的叠加还可以直接增加网络深度[23],使网络模型的特征提取能力更强,从而取得更好的识别效果。
东巴象形文字具有字数多、字形相似等特点,因此需要提取特征能力强的网络结构,而多个卷积层的叠加能够在参数量最少的前提下实现最好的特征提取能力。因此本文设计了32层 3 ×3的卷积层,再加1层全连接层,构成33层网络模型,用以获得东巴象形文字最好的识别效果。
同时,为了防止网络过拟合,加快网络训练速度,本文对每一个卷积层执行批量归一化(batch normalization)[24]操作。然后再使用修正线性单元ReLU[25](rectified linear units)f(x)=max(0,x)作为激活函数,增强网络的非线性表达能力,在x>0时保持梯度不衰减,从而缓解网络出现的梯度消失问题。
2.3 下采样改进
下采样可以降低特征图维度,保留图像主要特征的同时减少网络模型的参数量,防止过拟合现象的发生。在ResNet模型中通常采用令卷积步长 S tride=2来实现下采样的效果,但是由于本文建立的东巴象形文字数据集经过灰度归一化后,其前景像素值远远大于背景像素值,用这种方法实现下采样获得的东巴象形文字纹理特征不够丰富,影响了识别效果,因此有必要对下采样进行改进。
最大池化层通过提取特征图局部区域内的像素最大值,可以最大程度降低特征图背景的无关信息,使网络模型提取更多有用的前景特征,降低背景特征干扰。因此,本文对ResNet模型中的下采样方式进行了改进,通过采用最大池化层来获得丰富的纹理特征。最大池化层的公式如式(10)所示:

其中:rk(k=1,2,···,K)为特征图所 划分的多个区域,ai表示第i区域内的像素值。
而网络深层的平均池化层通过提取特征图的像素加权值,可以保留更加完整的特征图信息。并且通过平均池化将特征图下采样为1 ×1后再与全连接层相连接,可以减少网络参数。池化层的池化区域为特征图中的连续区域,对小的形态改变具有不变性,不仅能够逐步减少特征图的空间大小、参数数量、内存占用和计算量,而且拥有更大的感受野,可有效控制过拟合现象的发生。
3 实验结果及分析
为验证本文创新工作的有效性与先进性,实验部分主要做了3个方面的工作:1)本文建立的东巴象形文字数据集对比实验及分析;2)本文提出的东巴象形文字识别方法对比实验及分析,包括网络改进前后的对比实验;3)结合实验结果,分析归纳了目前仍存在的问题。
3.1 实验条件
实验中所有对比实验均在表1所示的实验平台上运行。

表1 实验环境配置Table 1 Experimental environment configurations
实验epoch设置为80,初始学习率设置为0.001,每50个epoch将学习率降低为原来的三分之一,直到运行结束所有epoch。
本文梯度优化函数选择Adam函数,损失函数使用交叉熵函数,交叉熵函数定义如式(11)所示:

其中xj代表全连接层第j个网络节点输出值。
本文改进的ResNet模型具体参数如表2所示。

表2 本文网络参数设计Table 2 Network configurations of this paper
3.2 本文建立的数据集验证
目前关于东巴象形文字的数据集较少,文献[8-10]是目前已知的3个东巴象形文字数据集,因此将本文的数据集与上述3种数据集都进行了对比实验。
3.2.1 数据集有效性验证
这里选取在图像识别领域表现优异的Res-Net18、ResNet34、VGGNet以及本文的改进网络模型在本文建立的东巴象形文字数据集上进行识别效果对比。在数据集中随机选取5 000张图像计算其均值和方差,然后将图像归一化处理后输入网络。随机选取数据集图片总数的80%作为训练集,即178 223张图片,其余44 827张图片作为测试集。在训练集上训练网络模型后,在测试集上对1 387个东巴象形文字(包括异体字)进行识别准确率测试。其实验结果如表3所示。

表3 数据集有效性验证实验Table 3 Experiment of dataset validity verification
从表3中可以看出,对于不同的网络模型,本文建立的东巴象形文字数据集都获得了高于98%的识别准确率,最高可达98.65%,这说明本文建立的东巴象形文字数据集是有效的,每个东巴象形文字多达160多张书写各异的图片,其数据规模完全满足具体识别的要求。
3.2.2 数据集先进性验证
文献[8-10]分别给出了3种东巴象形文字识别方法和与之对应的3个东巴象形文字数据集,这里采用这3种识别方法在本文提出的数据集上分别进行了识别准确率方面的对比实验。表4给出了各个数据集能够识别的字数和不同模型在数据集上进行识别的准确率。
从表4中可以看出,首先本文建立的数据集能够识别的东巴象形文字最多;其次,相同的网络模型在不同的东巴象形文字数据集上取得的识别效果不同,相较于其他3个文献所建立的数据集,本文建立的数据集采用3种相对应的网络模型都取得了最高的识别准确率,说明本文建立的数据集在数据规模和数据质量上都是目前最好的,也说明优秀的数据集可辅助提高深度学习模型的性能。

表4 数据集先进性验证实验Table 4 Experiment of dataset advancement verification
3.3 本文识别算法的实验验证
根据东巴象形文字识别的特点,本文对Res-Net模型进行了改进,提高了东巴象形文字的识别准确率。这里将验证本文网络模型改进的有效性。通过将其与采用残差跳跃连接加传统池化方式以及无残差跳跃连接加最大池化方式的网络模型进行消融实验。同时,将本文改进的网络模型与文献[8-10]中取得识别准确率最高的网络模型以及ResNet34进行对比实验,以验证其先进性。所有实验在本文建立的数据集上进行。
3.3.1 算法的有效性验证
为了验证本文改进ResNet模型的有效性,这里进行了改进前后的对比实验。将本文改进的网络模型(残差+最大池化)与残差加传统池化、无残差加最大池化3种网络模型进行识别效果对比,实验结果如表5所示。

表5 算法有效性验证实验Table 5 Experiment of algorithm validity verification
由表5可以看出,本文改进的残差跳跃连接加最大池化下采样网络模型取得了最高的识别准确率,相较于残差跳跃连接加传统池化的网络模型提高了0.54%;相较于无残差跳跃连接加最大池化下采样的网络模型提高了1.01%,从而验证了本文改进残差跳跃连接加最大池化网络模型的有效性。
3.3.2 算法的先进性验证
为了验证本文改进网络模型的先进性,在相同的实验环境下,本文分别与文献[8]采用的Res-Net18网络模型、文献[9]采用的VGGNet网络模型以及文献[10]采用的20层ResNet网络模型进行了对比实验,实验结果如表6所示。

表6 算法先进性验证实验Table 6 Experiment of model advancement verification
从表6中可以看出,本文改进的网络模型识别准确率最高,相较于文献[8]的方法提高了0.43%;相较于文献[9]的方法提高了0.31%;相较于文献[10]的方法提高了0.95%。充分验证了本文改进网络模型的先进性。
同时,本文又与层数有所增加的ResNet34网络进行了对比性实验。从表6中可以看出,34层网络模型的识别准确率不仅低于本文的33层网络模型,而且也低于18层的网络模型,这说明网络层数的简单叠加在具体的东巴象形文字识别中不一定获得更好的识别效果。
3.4 存在的问题
虽然本文取得了98.65%的识别准确率,但对于误识别问题我们又进行了深入分析,通过观察多次实验结果,发现错误识别的东巴象形文字都有一个共同的特点,那就是都有与之非常相似的东巴象形文字,图6给出了部分相似文字的示例。

图6 相似东巴象形文字示例Fig.6 Samples of similar Dongba pictographs
从图6可以看出,“水槽”和“水涧”,“侧视之人”和“左”或“爬”等字的区别仅仅体现在线条的弯曲程度不同;“腰”和“爬”更多体现在它们之间大小有所差异;“神山山脚”和“神山山腰”,“中”和“矛”主要体现在图像上部分所画的高度不同;“尾巴”和“树倒”的差异体现在右下角线条的长度和弯曲程度;“臂膀”和“手”则几乎相同。
可见,东巴象形文字中有很多相似乃至接近“相同”的文字,又因为东巴象形文字的手工书写形式,随意性较大,这些相似的东巴象形文字在书写过程中极容易导致差异性变小、辨识度下降,这是影响东巴象形文字识别准确率的主要原因。
4 结束语
针对现有东巴象形文字识别方法存在的识别文字数量少、识别准确率较低等问题,本文首先建立了包含1 387个东巴象形文字(包括异体字)、图片总量达到22万余张的东巴象形文字数据集,可识别的东巴象形文字大幅增加。通过扩大数据集的规模,辅助提高了算法识别的准确率;更为重要的是本文选择ResNet模型作为改进的网络结构,设计了残差跳跃连接方式和卷积层的数量,并通过加入最大池化层实现了对下采样的改进,更好地提取了东巴象形文字的纹理分布特征。通过对1 387个东巴象形文字(包括异体字)分别进行测试,实验结果表明,本文提出的改进ResNet模型识别准确率平均达到98.65%,取得了当前识别字数最多、识别准确率最高的效果。
未来将继续扩大东巴象形文字数据集的文字数量,力争包含现存的所有东巴象形文字。针对其中相似度极高的文字,将研究设计专门的网络模型来有效将它们区别开来,从而进一步提高东巴象形文字识别的准确率。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
云南档案(2021年1期)2021-04-08
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
北京航空航天大学学报(2020年10期)2020-11-14
壹读(2019年6期)2019-12-18
北京航空航天大学学报(2019年9期)2019-10-26
