
基于深度强化学习的医用设备应急调度优化技术研究
2022-02-17 12:11夏天,黄冠,李颖
电子设计工程 2022年3期
夏 天,黄 冠,李 颖
(湖北省肿瘤医院设备科,湖北武汉 430079)
随着我国医疗体制改革的不断推进,医用直线加速器、麻醉机、CT、RI 等大型医用设备在大多数省市地区医院被广泛配置[1-2]。然而,不合理配置医用设备或者使用效率低等现象愈发严重,造成大型医用设备资源日趋紧张。因此,合理、高效地进行大型医用设备管理变得尤为重要[3-4]。而当有突发公共卫生危机时,如何在保障常规基础卫生需求的同时,快速调度大型医疗设备是当前的研究热点。
在我国,针对医用大型设备配置、管理的研究开展较晚,且由于研究方法的标准不一致,导致设备配置的公平性、适宜性无法进行对比[5-8]。近年来,物联网技术开始被应用在医疗设备的日常管理中[9-11]。该技术融合了智能感知、无线通信和智能识别技术,是信息技术的重要组成部分。其基于互联网汇总各类数据,形成综合物联网。强化学习算法源于心理学,是一种机器学习算法,其目的在于通过分析智能体产生的数据来学习系统最佳行为[12-16]。
文中使用物联网技术采集设备日志数据,将其作为调度优化算法的数据源。以马尔可夫决策过程为调度优化算法的基础模型,进而定义了各类函数。通过使用贪婪策略和Tanh 函数作为强化学习的动作探索策略和激活函数,提高了对非线性复杂数据的学习能力。最终,基于DDPG 算法获得了价值估计和行为估计。
1 医用设备应急调度优化技术
文中所提的医用设备应急调度优化技术主要用于医用直线加速器、GE、麻醉机等大型或者急救相关的医疗设备的日常管理、调度,以实现医疗设备资源的高效率利用;同时当有紧急需要时,可以科学、合理地调动这些医疗设备资源。由于这些设备涉及多种精密元器件和技术,并且诸多功能并不能经常用到,因此全面监控各个医用设备的关键参数对设备的维护也较为重要。
文中所提的医用设备应急调度优化技术涉及两个方面:一方面利用物联网技术和云计算技术进行大型医用设备底层关键参数的实时采集,实现对医用设备即时状态的监控;另一方面利用深度强化学习算法分析采集到的数据,以得到该设备的使用效率,以便合理安排设备的使用方式。其中,分别从年检查人数、检查项目数量等指标来考察大型设备的使用情况,进而评估设备配置是否合理,是否可被应急征调,其具体架构如图1 所示。
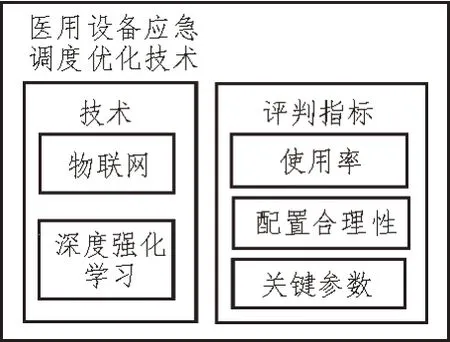
图1 医用设备应急调度优化技术结构框架
2 基于深度强化学习的调度优化算法
2.1 医用设备应急调度问题的转化
深度强化学习包含了两种模块:深度学习模块和强化学习模块。两种模块分工各不相同,深度学习模块被用来进行马尔科夫决策过程的环境感知;而强化学习模块则被用来确定决策控制的方向。深度强化学习智能训练过程如图2 所示。
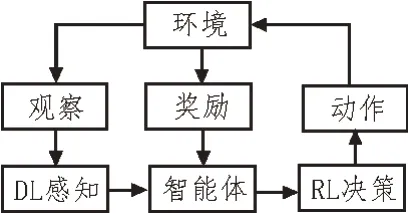
图2 深度强化学习智能训练过程
医用设备应急调度问题可通过建模转化为马尔可夫决策过程。在该决策过程中,各个医用设备被当作智能体,这些智能体在不同时刻产生的信息通过状态空间进行描述。每当智能体执行完一个动作时,均会得到系统一个奖励。深度强化学习算法的目的在于,通过分析一系列智能体动作与奖励的对应关系来推断使智能体得到最大奖励的动作形式。
由于大型医疗设备数量和种类较多,并且每类医用设备具有多种功能,因此,医用设备调度问题属于多智能体、多状态问题。文中将医用设备调度马尔可夫建模,转化成多个智能体马尔可夫决策过程。使用深度强化学习算法作为调度优化算法的关键在于状态空间、动作空间及奖惩函数的定义。文中状态空间被定义为3 个矩阵的形式:使用时间矩阵、任务分配布尔矩阵以及状态布尔矩阵。矩阵的行代表不同的检查项目,列代表不同的患者。第一行左边的矩阵为使用时间矩阵,表示不同检查项目使用该设备的时间;中间的矩阵为任务分配布尔矩阵,表示待检查项目;右边的矩阵表示该设备已经完成的检查项目。当该设备下一状态选择患者1 进行第二个检查项目时,状态空间将会更新。以3×3(3 台设备,3 个患者)医用设备调度为例进行说明,如图3所示。

图3 状态空间
动作空间表示的是设备在当前状态下,选择任意患者的任意待测项目的行为。医用设备应急调度优化技术应根据事先定义的规则实现为每一个决策点的待检测项目分配优先级。求解完成设备调度问题的候选待测项目规则如表1 所示。

表1 候选待测项目规则
奖惩函数用来评判智能体所选择动作的优劣,可调控医用设备应急调度算法的偏向。奖惩函数应满足下列3 个要求:
1)反映智能体行为的即时奖励;
2)选择优化目标作为奖惩函数,以修正深度强化学习算法的收敛方向;
3)奖惩函数应满足不同规模的调度应用,具有良好的普适通用性。
基于以上分析,文中将患者的检查时间和所有检查项目最小完成时间的组合作为奖惩函数,其具体为:
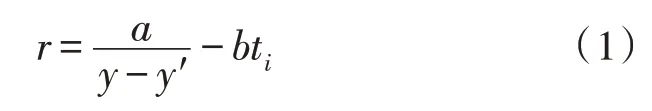
式中,a、b分别为调节常数,y为事例的最优解,y′为深度强化学习算法预测的最小检查完成时间。
2.2 基于深度强化学习的调度优化算法介绍
通过以上分析可知,深度强化学习由深度学习和强化学习构成。深度学习用于表征学习,强化学习则用于提供控制目标和选择策略。经过多次与周围环境的交互,深度强化学习可实现自主学习,不断增强控制能力。
文中选择用贪婪策略作为强化学习的动作探索策略,通过设定探索阈值p来进行动作的选择。选定随机数x,若x>p,则使用式(2)进行动作探索:

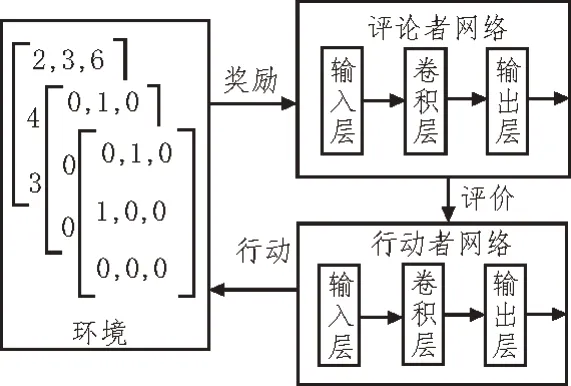
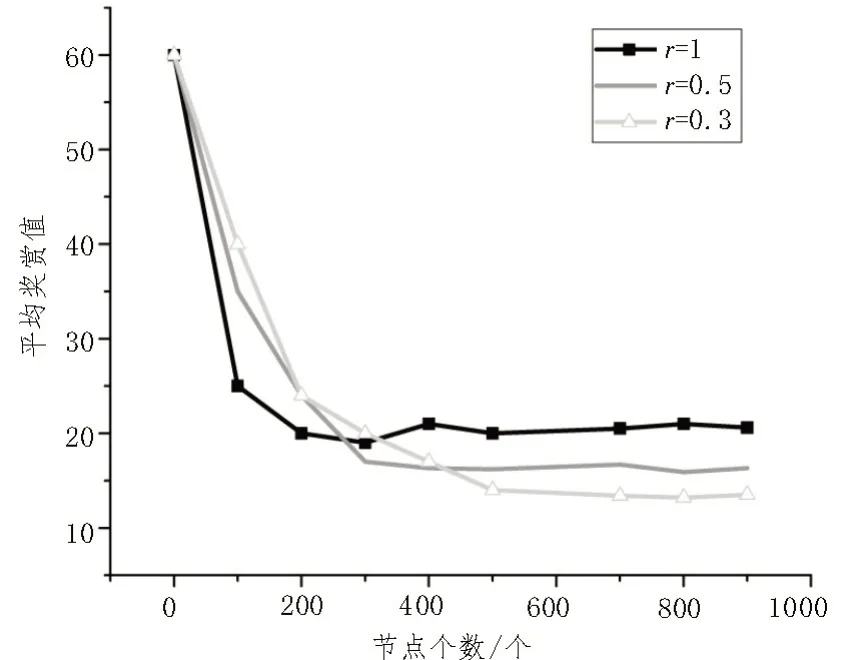
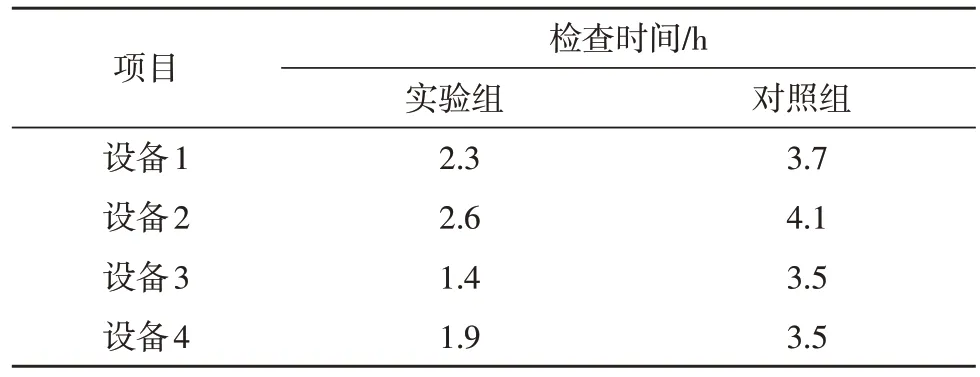
式中,n为动作空间的大小。当g(t)=0 时,表明医用设备没有可执行的检查项目;当g(t)=n时,表明医用设备可执行的检查项目为n。若x 式中,h(a|s)为行为策略。 由于医用设备应急调度问题涉及较多的特殊环境,其模型并不能用简单的线性模型进行拟合。文中使用Tanh 函数作为激活函数,以提高对非线性复杂数据的学习能力。Tanh函数的表达式如式(4)所示: 该函数的取值范围为[-1,1],适用于输入数据特征相差较大的求解问题。 文中使用DDPG 算法进行经验数据采样,以获得价值估计和行为估计。针对医用设备应急调度问题,基于DDPG 算法的深度强化学习智能体被拆解为评论者网络和行动者网络,这两种网络均使用卷积神经网络来搭建。在评论者网络中,智能体通过评估动作的值来判断该动作执行后状态的优劣;而行动者网络依据评论者网络给出的估值作出相应的反应,DDPG 算法更新形式如图4 所示。 图4 DDPG算法更新形式 为了使深度强化学习算法的效果最佳,该算法需要根据学习情况不断修正参数。深度强化学习算法通过损失函数的计算得到评论者网络的损失和行动者网络的损失。评论者网络的损失函数如式(5)所示: 式中,w为评论者网络的参数,r为即时奖励,Q(s′,w)为下一状态的估计值。 在涉及多个智能体调度问题时,当某个智能体因采取某个行动而引起自身状态改变后,其他智能体的状态也会受到影响。因此,需要从所有智能体的状态来考虑整体的调度问题。多智能体异步DDPG 训练形式及训练过程如图5 所示。 图5 多智能体异步DDPG训练形式及训练过程 所有智能体状态构成全局网络模型,每一个智能体都从全局网络中复制网络参数,并在该智能体所在的环境中单独训练。全局网络参数的更新取决于所有智能体的累计梯度。通过让智能体在其所处的环境中训练网络参数,来避免智能体之间的状态改变而影响网络训练。 为了验证文中所述应急调度算法的有效性,选取某医院的8 台CT 设备一个月内的使用情况作为研究对象,采集到的数据作为深度强化学习网络的样本数据进行模型训练,使用Matlab 作为算法仿真平台。首次训练,将样本数据中的五分之四用作模型训练,其余数据用于模型验证。图6和图7 分别展示了随着网络节点个数的增加,r在不同的取值下,Q值之和以及平均奖赏值的变化趋势。图6 中,当Q值曲线趋于稳定时,代表深度强化学习算法趋于收敛。由图6 可知,随着r的增加,算法的收敛时间越来越小。图7 中,曲线取值稳定时,同样代表算法收敛。图7 中曲线稳定的数值越低,即平均奖赏值越低,代表算法时延越小、性能越好。值得注意的是,随着r的增加,平均奖赏值越大。由此可见,r的取值需要综合收敛时间和平均奖赏值来考虑。 图6 Q值之和与节点个数的关系曲线 图7 平均奖赏值与节点个数的关系曲线 表2 为4 台设备使用了文中所提应急调度优化算法和未使用调度算法时,进行相同检测人数、检查项目所使用时间的对比。从表中可以看出,实验组在使用了文中所提医用设备应急调度优化算法后,在相同患者人数、相同检查项目情况下,整体检查时间明显缩短,平均缩短31.2%的时间。 表2 使用文中所述应急调度算法与未使用调度算法的检测时间对比 文中所提基于深度强化学习算法的医用设备应急调度优化技术,将物联网技术和深度强化学习算法融入到设备调度优化算法中。一方面通过物联网技术采集大型医用设备日常使用时的各类参数,作为后续调度优化算法的样本数据;另一方面使用深度强化学习算法来分析医用设备在日常使用中的数据,给出了状态空间、动作空间以及奖惩函数的定义。同时,用贪婪策略作为强化学习的动作探索策略,使用Tanh 函数作为激活函数,以提高对非线性复杂数据的学习能力。最终,使用DDPG 算法在经验数据中采样获得价值估计和行为估计。经过仿真验证和实际测试,证明了文中方案的有效性。



3 测试与验证

4 结束语
猜你喜欢
江苏安全生产(2022年7期)2022-08-24
中学生数理化·高一版(2020年6期)2020-12-17
中学生数理化(高中版.高二数学)(2020年6期)2020-12-04
铁道通信信号(2020年10期)2020-02-07
电子制作(2019年20期)2019-12-04
北京航空航天大学学报(2019年9期)2019-10-26
计算机测量与控制(2019年6期)2019-06-27
劳动保护(2018年8期)2018-09-12
消费导刊(2018年10期)2018-08-20
劳动保护(2018年5期)2018-06-05
